

redis雪崩问题解决
缓存雪崩
出现的场景
- 缓存服务器宕机,没有设置持久化
介绍:缓存服务器宕机,没有设置持久化,导致缓存数据全部丢失,请求全部转发到数据库,造成数据库短时间内承受大量请求而崩掉。

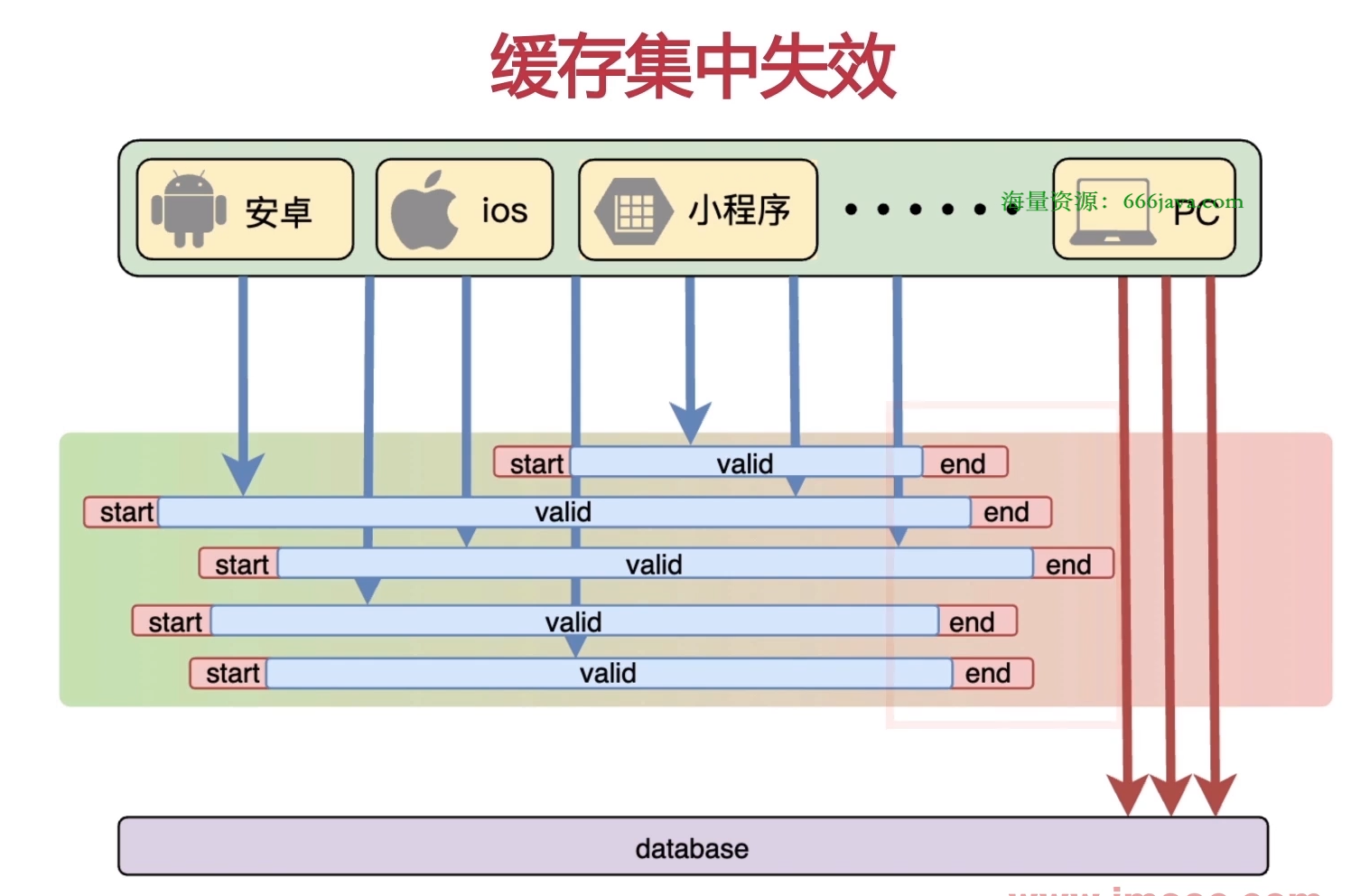
- 缓存集中失效
缓存的key设置了相同的过期时间,导致在某一时刻,大量的key同时失效,请求全部转发到数据库,造成数据库短时间内承受大量请求而崩掉。
- 内存不足
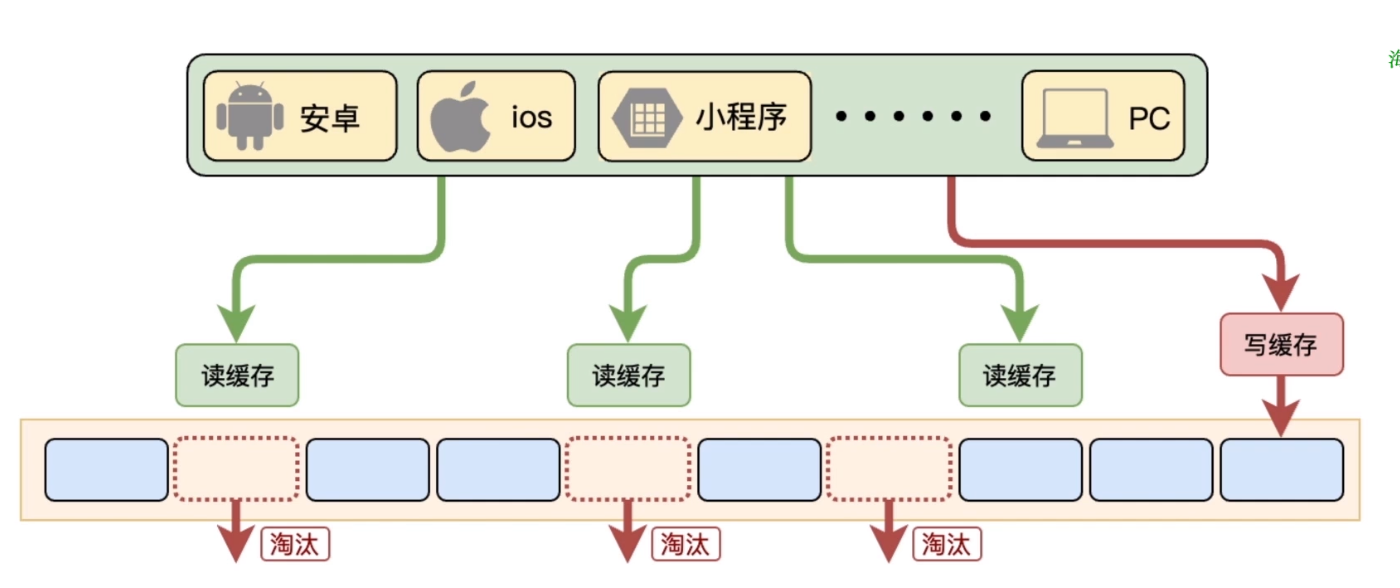
缓存服务器内存不足或者淘汰策略不合理,导致缓存数据被清理,请求全部转发到数据库,造成数据库短时间内承受大量请求而崩掉。
redis淘汰策略

解决方案
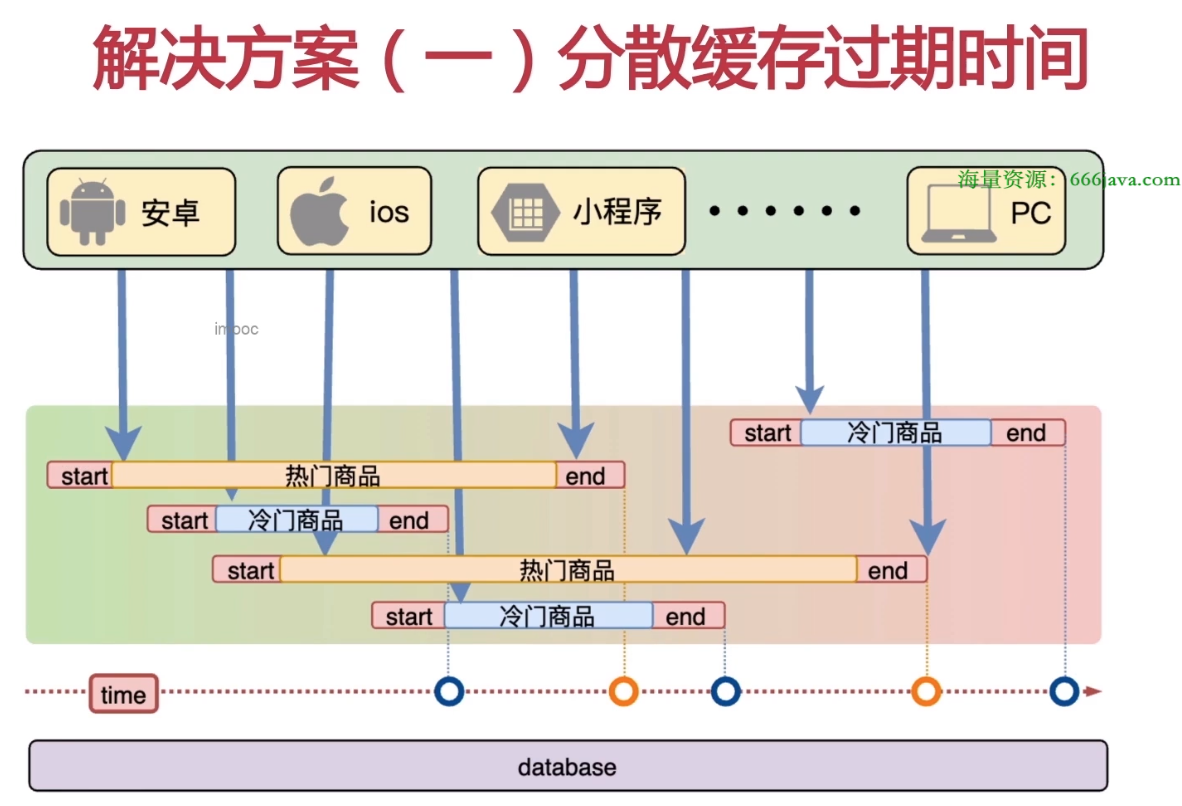
分散缓存失效时间
根据数据类型,设置不同的过期时间,避免缓存集中失效。
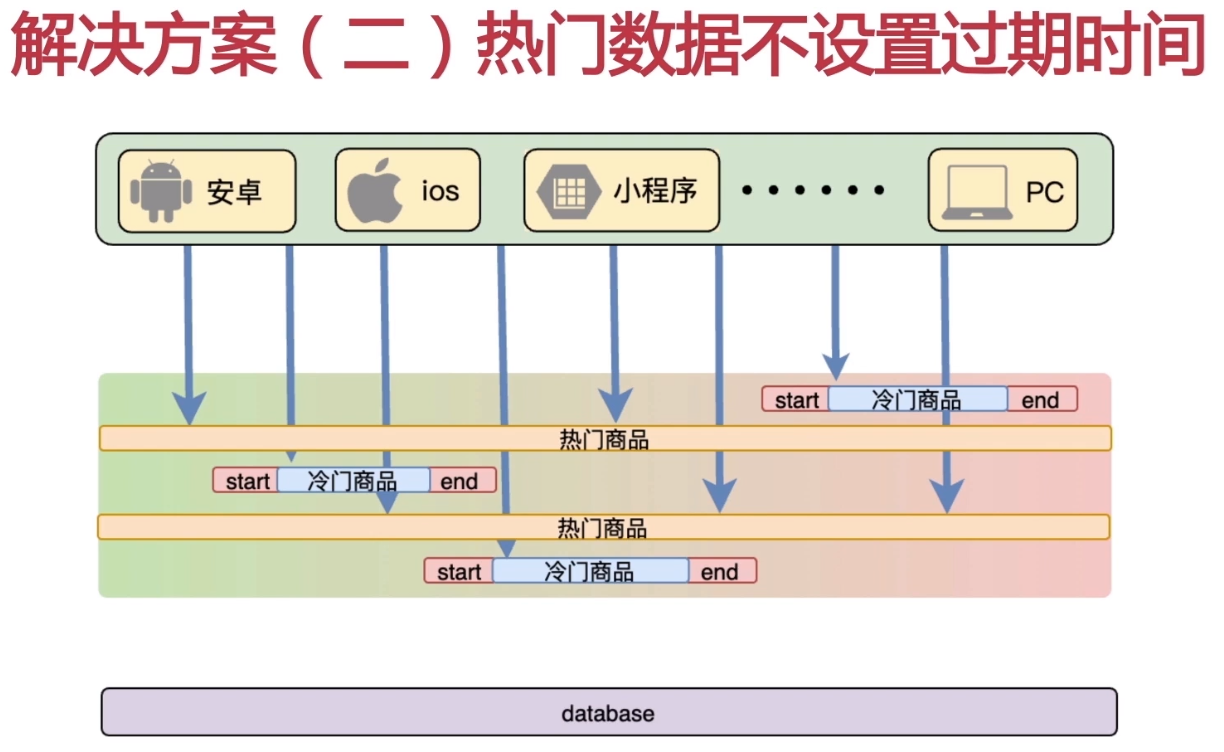
热门数据永不过期
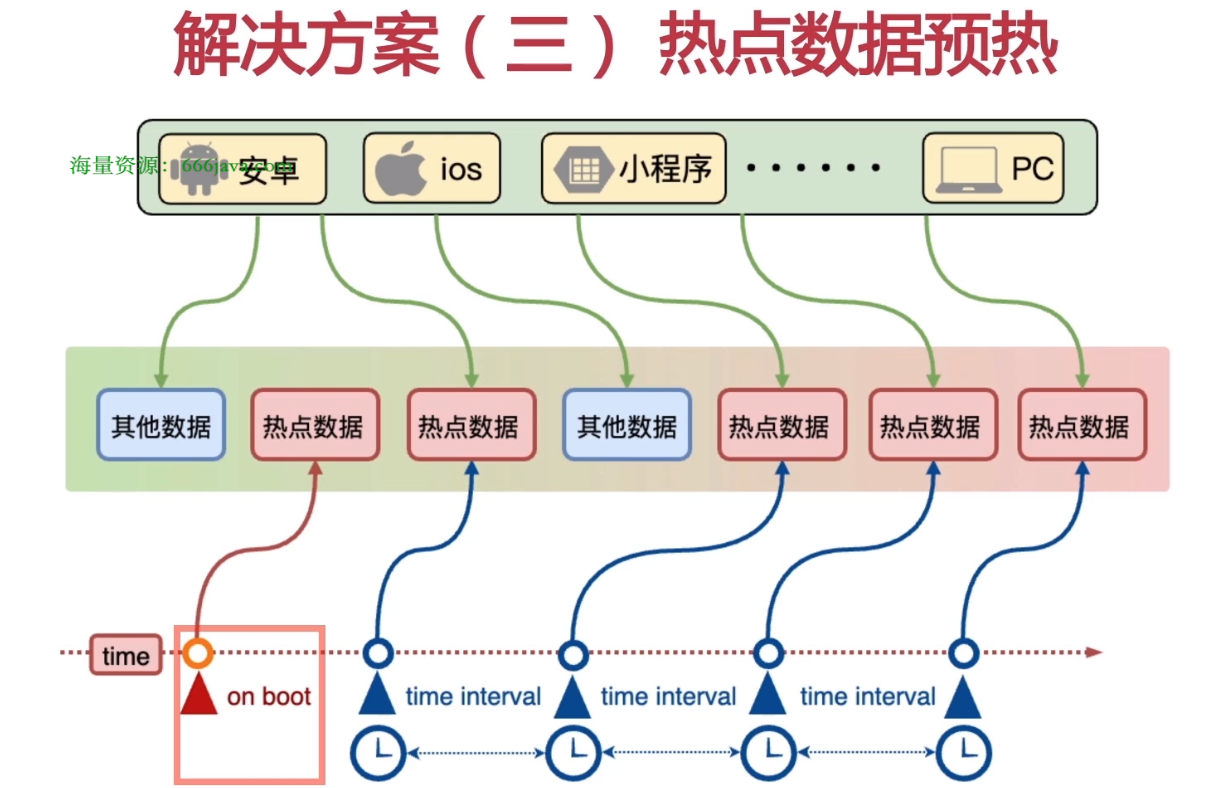
热点数据预热
介绍:在系统上线的时候,主动将一些热点数据加载到缓存中,避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。此外,还可以使用定时刷新缓存的方式,定时的将缓存中的数据重新刷新一下。
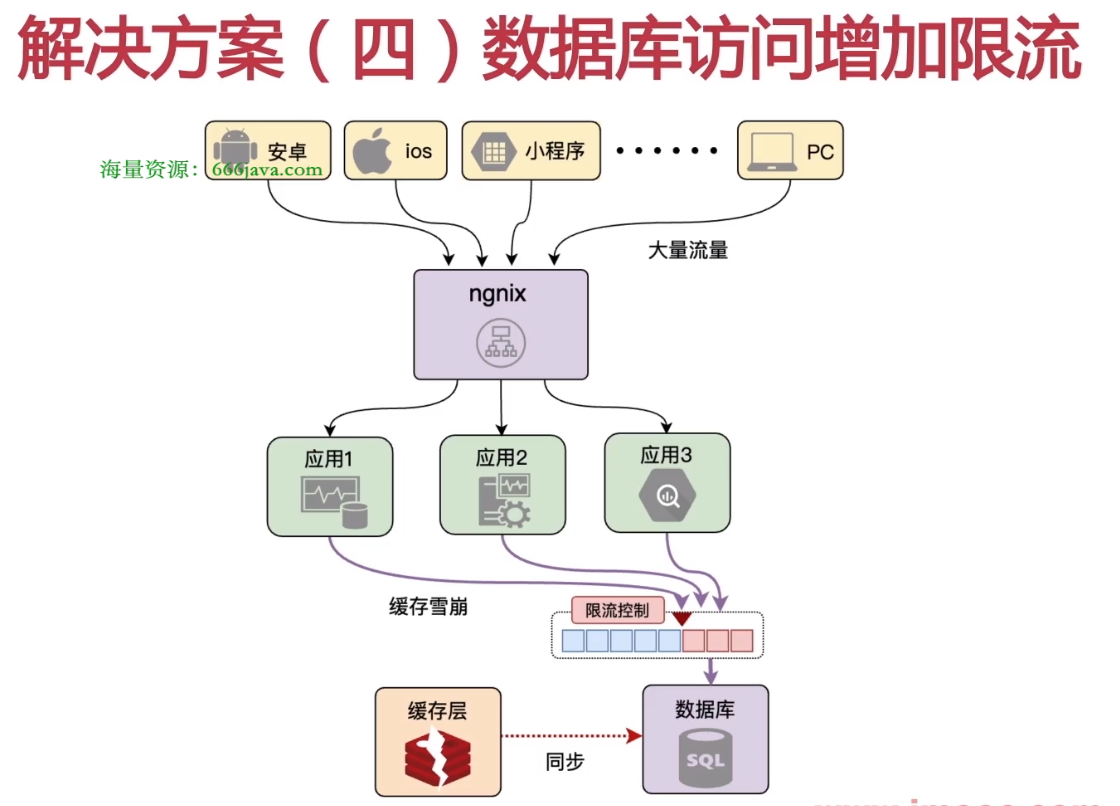
数据库增加访问限流
数据库限流介绍:在高并发的情况下,对数据库的访问进行限流,避免数据库短时间内承受大量请求而崩掉。
MYSQL与Redis的最大连接数介绍:
- MYSQL数据库的最大连接数是由max_connections参数控制的,max_connections参数的默认值是151,这个值是不够用的,一般我们都会将这个值设置的大一些,比如设置为500,这样就可以支持500个并发连接了。
- Redis数据库的最大连接数是由maxclients参数控制的,maxclients参数的默认值是10000,这个值是不够用的,一般我们都会将这个值设置的大一些,比如设置为100000,这样就可以支持100000个并发连接了。
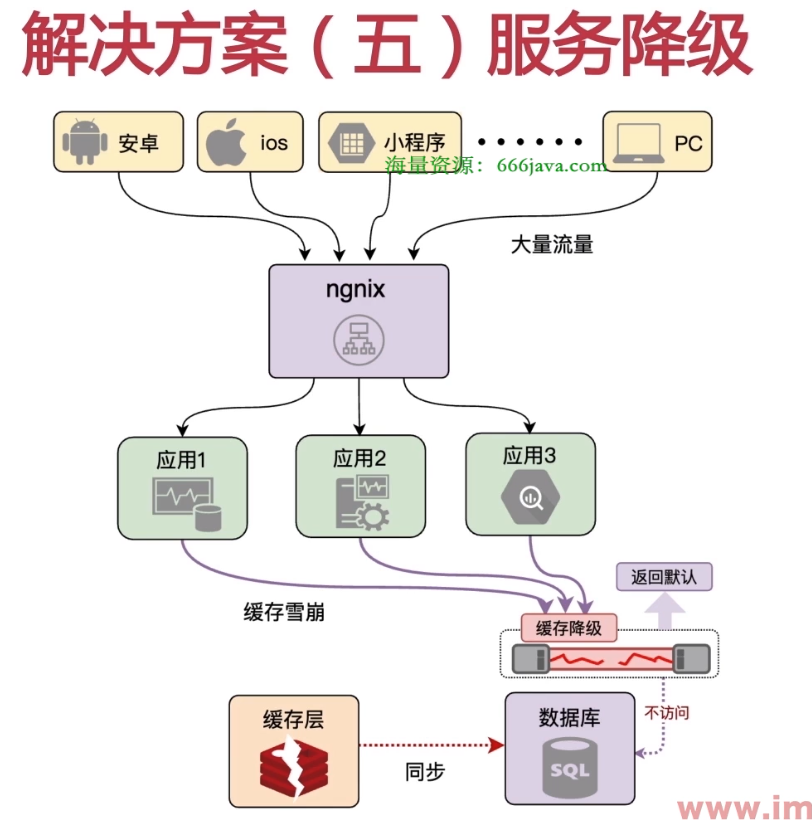
服务降级
介绍:当缓存服务器宕机或者缓存集中失效的时候,可以通过服务降级的方式,将部分非核心服务进行降级(比如返回提示暂时不可用等),从而保证核心服务的正常运行。
MYSQL限流
实现方式:我们可以通过自定义注解,结合AOP的方式,对数据库的访问进行限流。具体来讲,可以使用令牌桶算法,设定一个固定的令牌桶,每次请求数据库的时候,从令牌桶中获取一个令牌,如果获取到令牌,则可以访问数据库,如果获取不到令牌,则提示用户访问太频繁,请稍后再试。
注解定义
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyCache {
String cacheName() default "";
String key();
int expireInSeconds() default 0;
/**
* 限流器获取令牌超时时间
* @return
*/
int waitInSeconds() default 0;
}
切面实现
具体逻辑:首先从配置文件中加载限流配置map,然后在@PostConstruct中初始化RateLimiter,然后在@Around中获取RateLimiter,如果获取到令牌,则执行方法,如果获取不到令牌,则提示用户访问太频繁,请稍后再试。
private Map<String, RateLimiter> rateLimiterMap = Maps.newHashMap();
public void setMap(Map<String, Double> map) {
this.map = map;
}
/**
* key 需要限流的方法
* value 限流的速率
*/
private Map<String, Double> map;
@PostConstruct
private void initRateLimiterMap(){
if(!CollectionUtils.isEmpty(map)){
for(Map.Entry<String, Double> entry : map.entrySet()){
logger.info(String.format("create ratelimiter for %s , speed is %f", entry.getKey(), entry.getValue()));
rateLimiterMap.put(entry.getKey(), RateLimiter.create(entry.getValue()));
}
}else{
logger.error("RateLimiter config error ");
}
}
@Around("@annotation(myCache)")
public Object odAround(ProceedingJoinPoint joinPoint, MyCache myCache) throws Throwable {
// 获取缓存Key
String cacheKey = getCacheKey(joinPoint, myCache);
// 判断缓存是否存在
Object value = redisTemplate.opsForValue().get(cacheKey);
if(value != null){
logger.info("缓存命中,直接返回 key:{}, value:{}", cacheKey, value);
return value;
}
//限流处理
rateLimit(joinPoint, myCache);
// 缓存不存在,查询数据库
value = joinPoint.proceed();
logger.info("缓存未命中,查询数据库 key:{}, value:{}", cacheKey, value);
if(myCache.expireInSeconds() > 0){
redisTemplate.opsForValue().set(cacheKey, value, myCache.expireInSeconds(), TimeUnit.SECONDS);
}else{
redisTemplate.opsForValue().set(cacheKey, value);
}
return value;
}
private void rateLimit(ProceedingJoinPoint joinPoint, MyCache myCache) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
RateLimiter rateLimiter = rateLimiterMap.get(signature.getMethod().getName());
System.out.println("method: "+ signature.getMethod().getName() +" rate limiter :" +rateLimiter.getRate());
if(rateLimiter != null){
int timeout = myCache.waitInSeconds();
if(timeout <= 0){
// 获取不到令牌就阻塞
rateLimiter.acquire();
}else{
boolean acquired = rateLimiter.tryAcquire(timeout, TimeUnit.SECONDS);
if(!acquired){
throw new BusinessException(ResponseEnum.SYSTEM_BUSY);
}
}
}
}
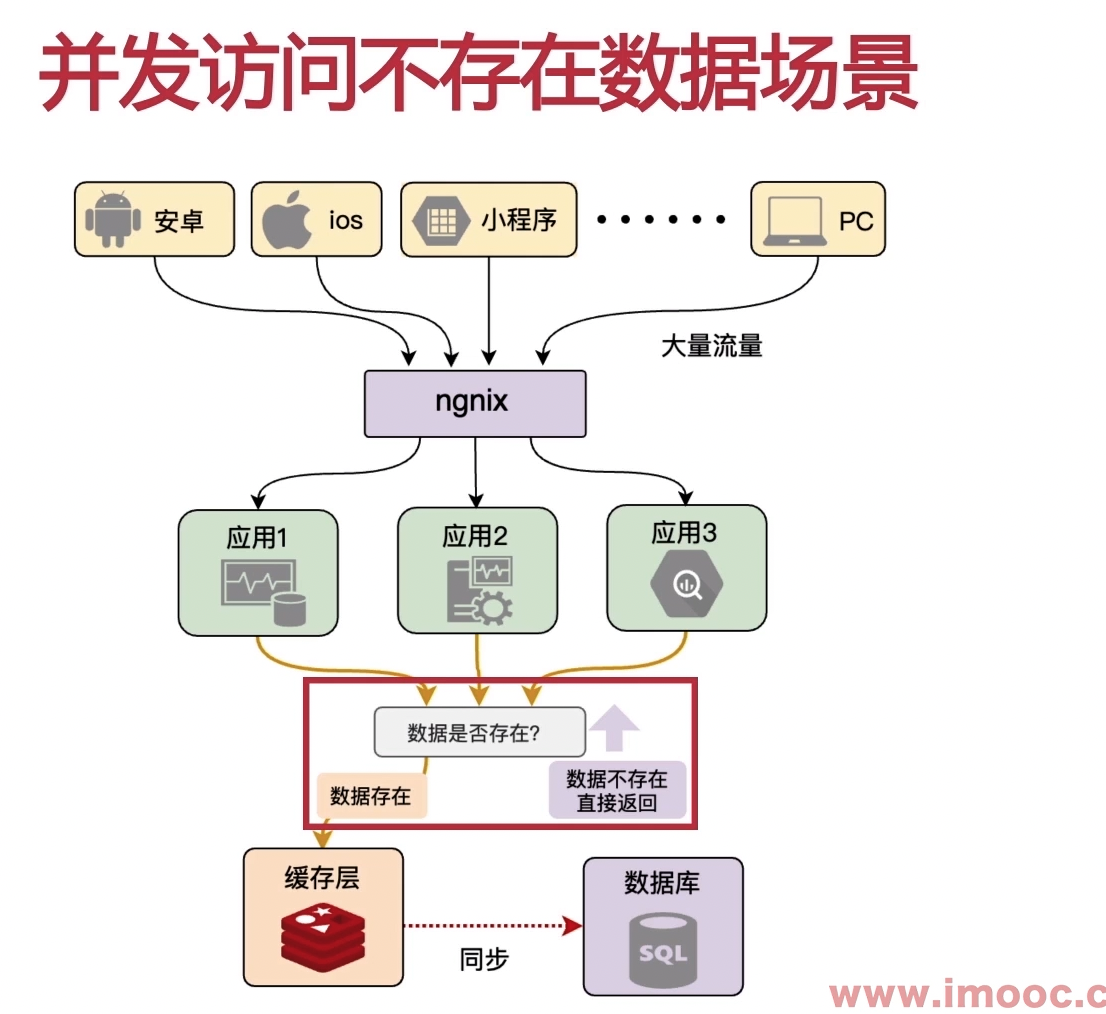
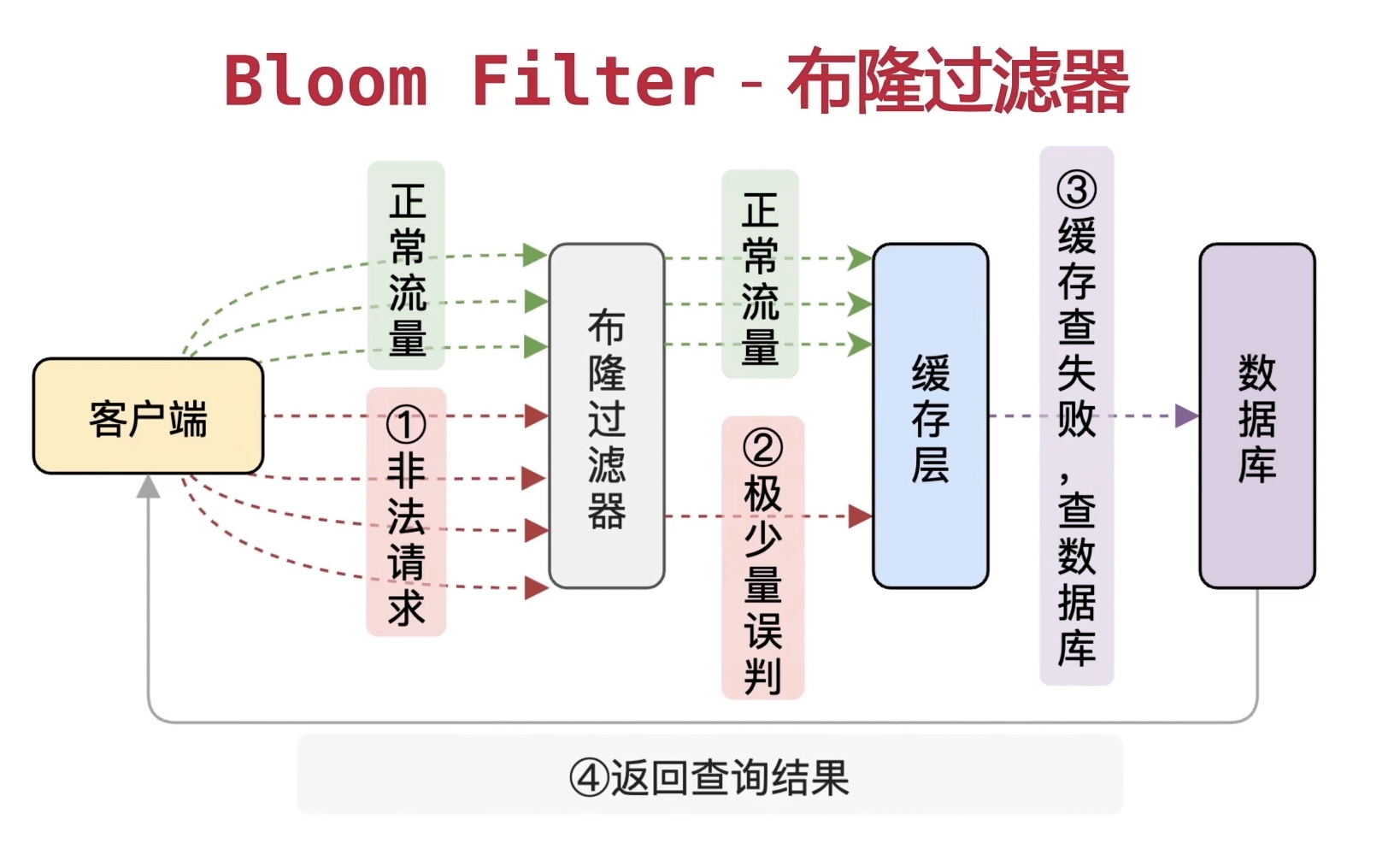
如何应对大量的请求访问存在的数据
在这种情况下,由于数据库里不存在该数据,所以无法走缓存,数据会直接打到数据库。
如何解决这一问题
当然可以考虑采用限流的方法,但是当恶意请求过多时,令牌数不够也会导致服务器无法响应正常的请求。
为此,理想的情况就是,我们找到一种方法来识别恶意请求,将恶意请求拦截掉,这样就可以保证正常的请求可以正常访问。为实现这个功能我们可以采用bloom filter算法。
bloom filter算法

Guava 的方法
缺点:只能用于单个JVM的环境,不适用于分布式的场景
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.junit.Before;
import org.junit.Test;
public class MyGuavaBloomTest {
/**
* 预期数据量
*/
private int size = 1000;
/**
* 期望的误差率
*/
private double fpp = 0.001;
/**
* Funnel 用于指定bloom过滤器中存的是什么数据
*/
private BloomFilter<Integer> bloomFilter =
BloomFilter.create(Funnels.integerFunnel(), size, fpp);
@Before
public void initBloomFilter() {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
}
@Test
public void testGuavaBloomFilter() {
int count = 0;
int st = size, ed = size * 10;
for (int i = st; i < ed; i++) {
if(bloomFilter.mightContain(i)){
count++;
System.out.println(i+" 误判为存在");
}
}
System.out.println("误判个数 "+count);
System.out.println("误判率: "+((double) count) / (ed - st));
}
}
redis 手动的方法
使用redis位图来实现,缺点:需要占用大量的内存空间

import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
public class MyBloomFilter {
/**
* 预期数据量
*/
private int size = 1000;
private static final String BLOOM_FILTER_NAME = "goodsBloomFilter";
@Autowired
public RedisTemplate redisTemplate;
private long getOffset(int i) {
long hashCode = Math.abs((BLOOM_FILTER_NAME+i).hashCode());
long offset = (long) (hashCode % Math.pow(2, 32));
System.out.println("Index = "+i+"\t"+
"HashCode = "+hashCode+"\t"+
"offset = "+offset+"\t");
return offset;
}
@Before
public void init() {
for (int i = 0; i < size; i++) {
redisTemplate.opsForValue().setBit(BLOOM_FILTER_NAME, this.getOffset(i), true);
}
}
@Test
public void testRedisBloomFilter() {
int count = 0;
int st = size, ed = size * 10;
for (int i = st; i < ed; i++) {
boolean match = redisTemplate.opsForValue().getBit(BLOOM_FILTER_NAME, this.getOffset(i));
if(match){
count++;
System.out.println(i+" 误判为存在");
}
}
System.out.println("误判个数 "+count);
System.out.println("误判率: "+((double) count) / (ed - st));
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构