解密 MySQL 的索引是怎么组织的?
作者:@万明珠
喜欢这篇文章的话,就点个关注吧,会持续分享高质量Python文章,以及其它相关内容。
楔子
如果查询比较慢的话,大部分人应该都会说:"字段加索引了没?"。那么问题来了,索引到底是个什么东西呢,它为什么能够加快查询的速度呢,下面就来好好地聊一聊。
表的存储结构
介绍索引之前需要先来回顾一下表的存储结构,前面说过表在磁盘上会以一个 .ibd 文件的格式存在,而文件则由一个个数据页构成。所谓数据页本质上就是 16kb 的内存,而相邻的数据页之间会使用双向链表串起来,也就是说每个数据页里面除了数据之外还会包含两个指针,一个指针指向上一个数据页的地址,一个指针指向下一个数据页的地址。
然后是数据页里的数据,我们往表里面插入的一行一行数据,在数据页里面都是紧密排列在一起的。每个数据页内部的数据都按照主键大小排序存储,同时每一行数据都有指针指向下一行数据的位置,数据之间组成单向链表。
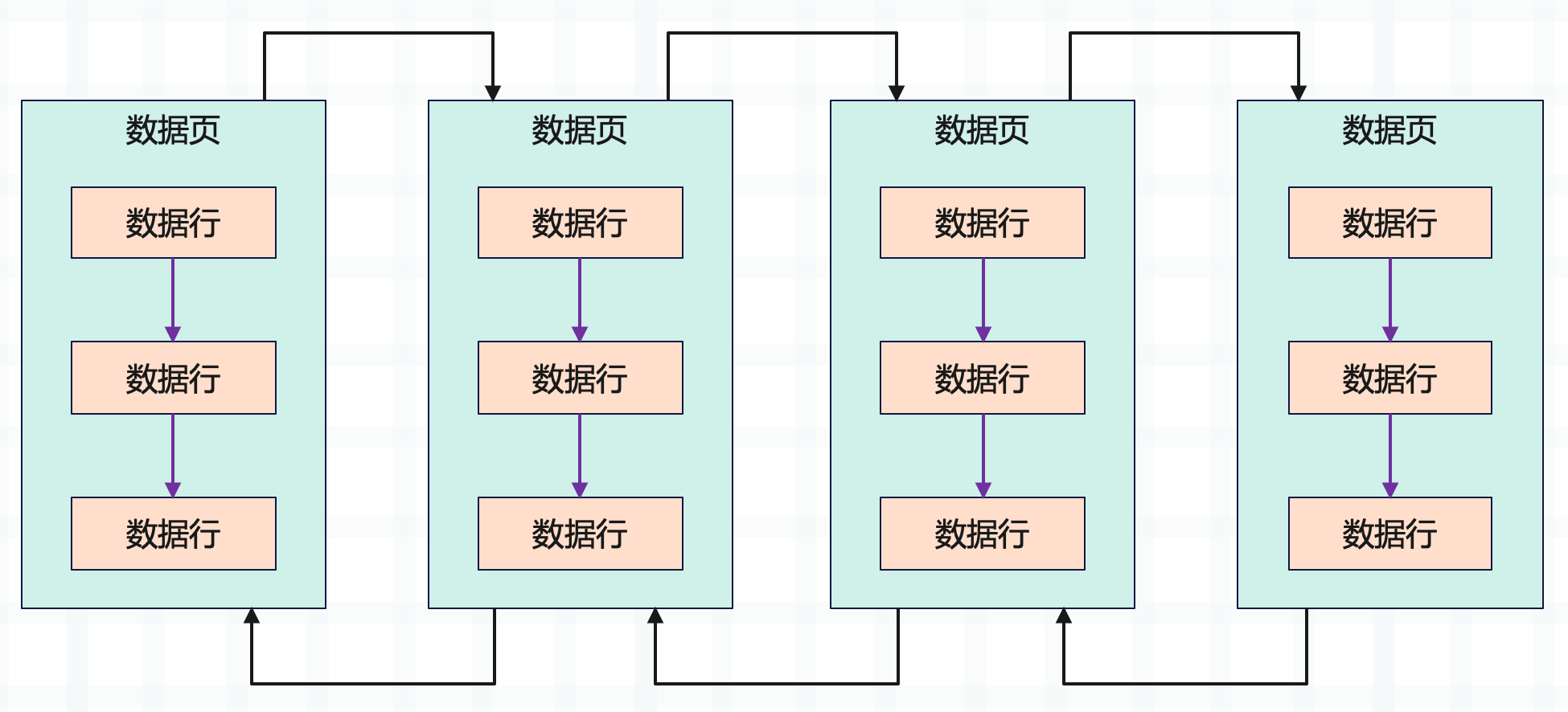
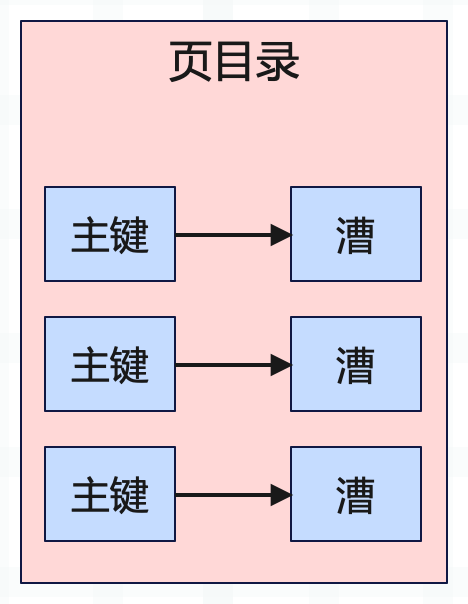
另外还有一点需要注意,数据页里面不是有很多的数据行吗,多个数据行被划分为一个漕。也就是说,每个数据页里面有多个槽,每个槽里面有多行数据。然后数据页里面还包含了页目录,页目录存放了主键到槽之间的映射。
应该不难理解,那么下面先来看看,在没有索引的情况下是如何查询数据的。
无索引的数据查询
如果要根据主键查找一条数据,假设此时表里面只有一个数据页,那么会怎么做呢?首先到数据页的页目录里根据主键进行二分查找,能够以 log(N) 的时间复杂度定位到主键对应的数据属于哪一个槽,然后在指定的槽里面遍历即可。
如果根据非主键字段查找数据,就比较尴尬了,此时无法基于页目录进行二分查找,只能从第一个数据行开始往后遍历,也就是从头开始遍历单向链表。而且上面是假设表里面只有一个数据页,如果有大量的数据页,那么就从第一个数据页开始,每个数据页都重复相同的动作。
而这个过程就是全表扫描,在没有使用索引的时候,无论如何查找数据,都是一个全表扫描的过程。通过双向链表依次把磁盘上的数据页加载到缓存页里去,然后在每个缓存页内部遍历查找指定数据。最坏的情况下,可能得把所有数据页里的每条数据都遍历一遍,才能找到需要的那条数据,这就是全表扫描。
什么是页分裂
数据表在物理层面对应一个 .ibd 文件,每个文件由多个数据页组成,数据页之间构成了一个双向链表。每个数据页内部有很多数据行,数据行之间组成单向链表。然后多个数据行属于一组槽,数据页里面还包含一个页目录,页目录里面记录了主键和槽的对应关系。
如果没有索引,那么查询的时候就会依次扫描每个数据页里面的每个数据行,而这就是全表扫描,这个效率是非常低下的。所以才需要有索引,但是目前暂时还不能进入索引的部分,我们还需要了解一下页分裂,了解完它之后会更容易理解索引。
我们知道在一个数据页内部,数据都是按照主键大小顺序存储,并且是升序。以及下一个数据页里面主键的最小值,要大于上一个数据页里面主键的最大值,所以数据整体也是按主键顺序存储的。
如果主键是自增的,那没有问题,但如果不是,就容易破坏这个规则,出现页分裂。
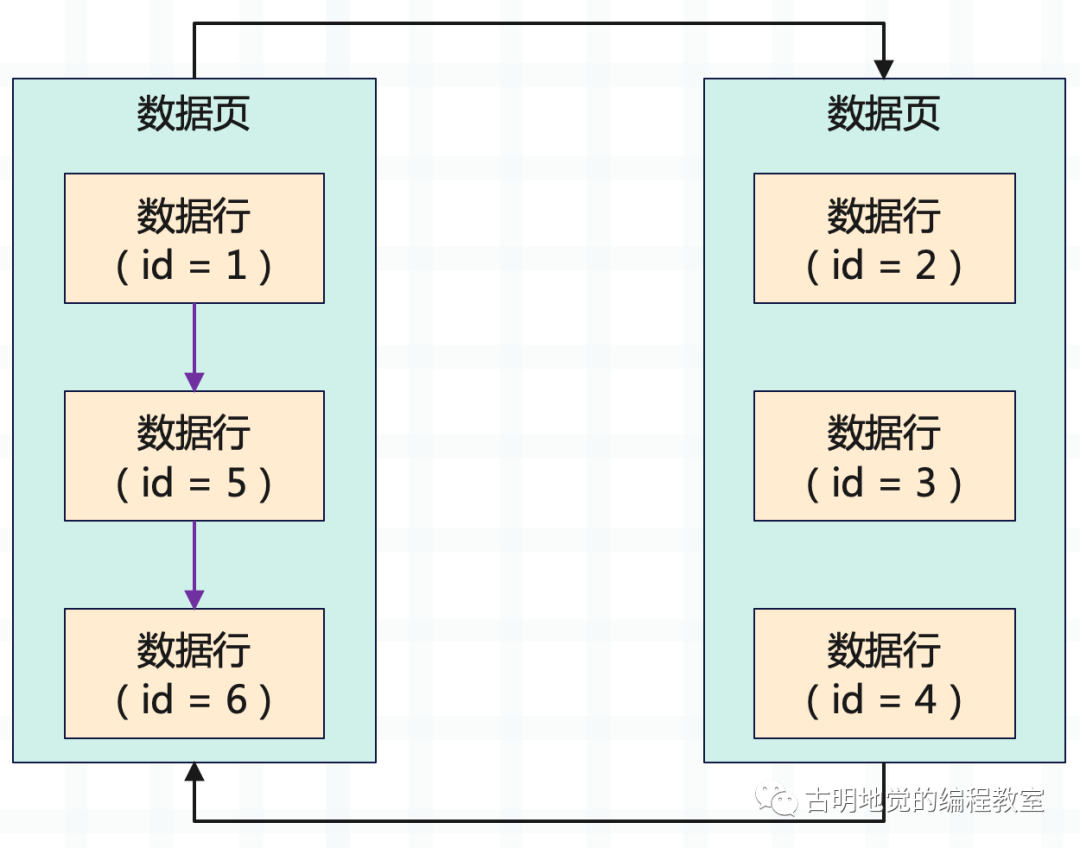
第一个数据页里有 id 为 1 5 6 三条数据,第二个数据页里有 id 为 2 3 4 三条数据,明显第二个数据页里数据的主键值比第一个数据页里的 5 和 6 两个主键都小,所以这个是不行的。此时就会出现页分裂的行为,把新数据页里的两条数据挪动到上一个数据页,上一个数据页里挪两条数据到新数据页里去。
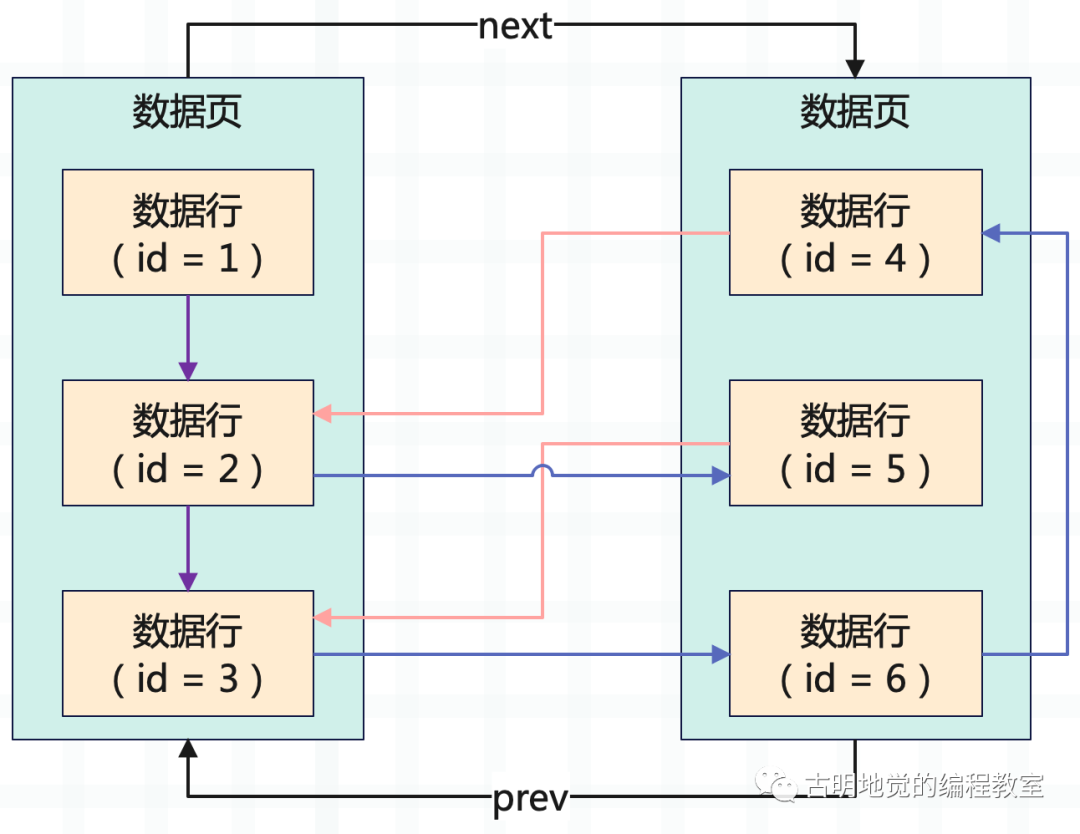
上述就是一个页分裂的过程,核心目标就是保证下一个数据页里的主键值都比上一个数据页里的主键值要大。
基于主键的索引查询
前面我们说如果数据页很多,基于非索引字段查询要遍历所有数据页的每一行数据,这个效率很差,因为是全表扫描。而基于主键查询,仍要遍历每个所有的数据页(事实却并非如此),只不过每个数据页内可以基于页目录实现二分查找,效率要高一些。
但即便如此,你会发现这么做效率并没有提升多少,因为它还是遍历了所有的数据页。所以基于主键查询的真实情况并非如此,如果一个字段是主键,那么它也一定是唯一性索引,所以基于主键的查询不会这么傻,要去遍历每一个数据页。
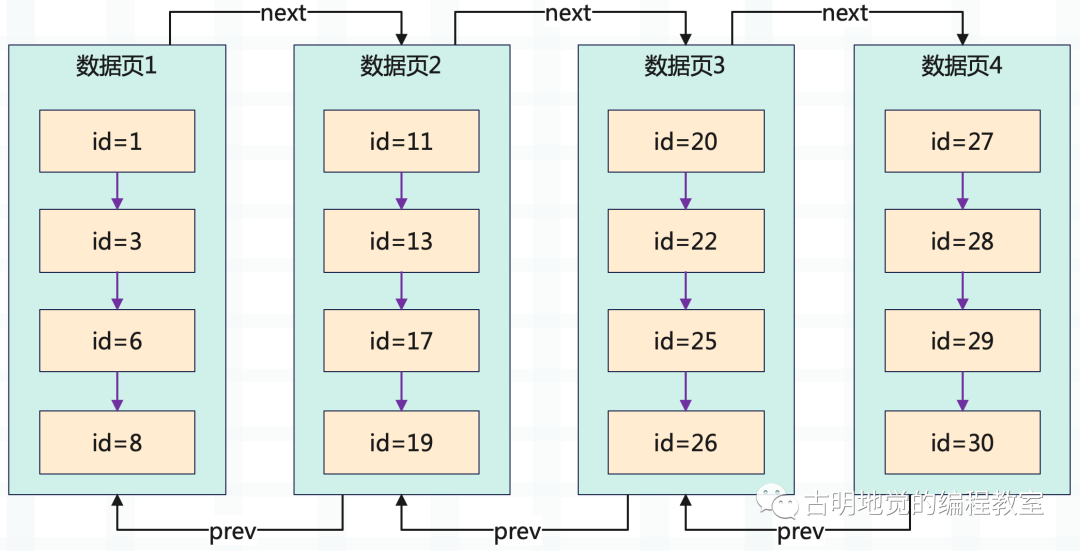
为了表达方便,我们就用 id 来代替数据行了,id 为主键。假设现在要找 id = 22 的数据行,那么会怎么做呢?主键也是索引,针对主键的索引叫做主键目录,而主键目录里面维护了每个数据页里最小的主键值和对应数据页页号之间的一个映射。
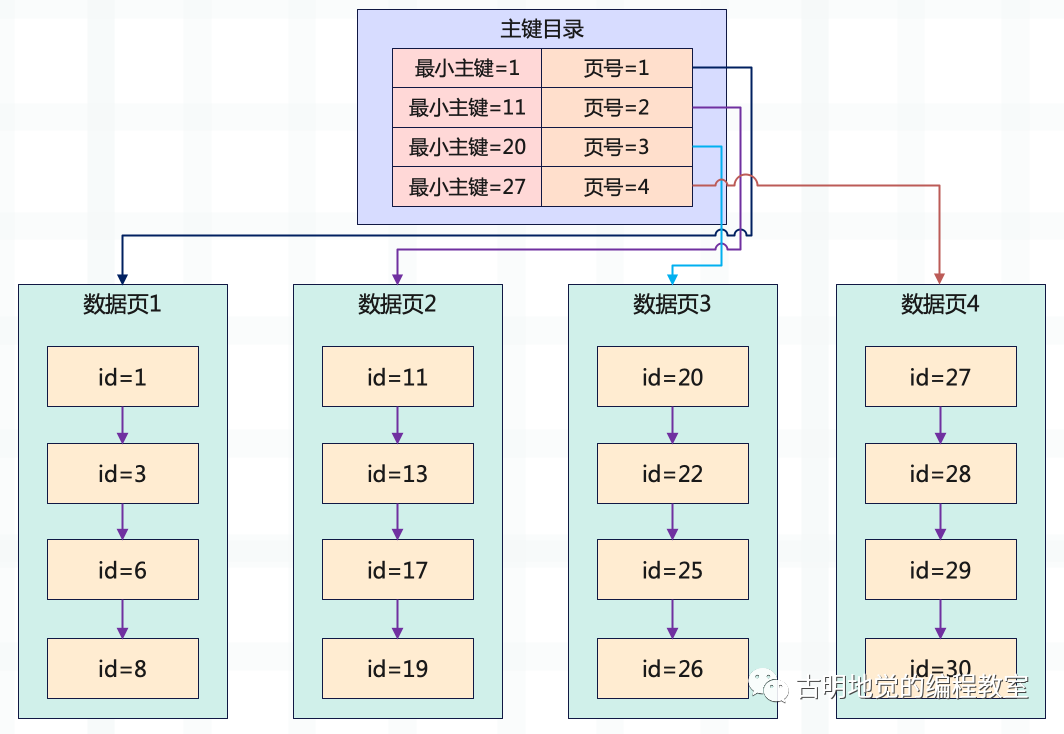
有了主键目录就方便多了,假设寻找 id=22 的数据,只需要在主键目录里进行一次二分查找,即可确定对应的数据页。然后在页目录里再进行一次二分查找,即可找到指定的数据。
这个过程是相当快的,因为通过主键目录可以快速定位到指定的数据页,而不需要遍历每一个数据页。而找到数据页之后,只需要遍历这一个数据页即可。当然啦,对于主键字段来说单个数据页的遍历仍是二分查找(就算不是,效率也没有问题,因为只有一个数据页)。
以上只是索引的一个最简单和最基础的概念,而 B+ 树组成的索引结构才是真正的索引。
基于 B+ 树构成的索引
上面说了,只要在一个主键索引里包含最小主键值和对应的数据页页号,就可以组成一个索引目录。后续基于主键查询时,就可以在索引目录中通过二分查找快速定位到指定的数据页。
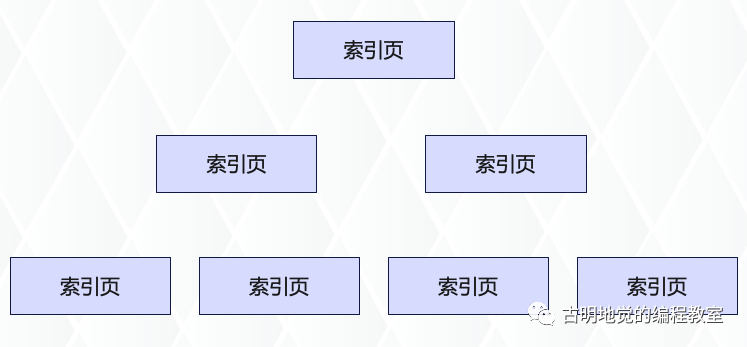
那么这些索引数据存在什么地方呢?正如表数据存在数据页里面,索引数据也是以页为单位存储的,只不过它叫索引页。如果表数据非常多,比如几千万行,那么索引数据也会很大,此时就会有多个索引页。
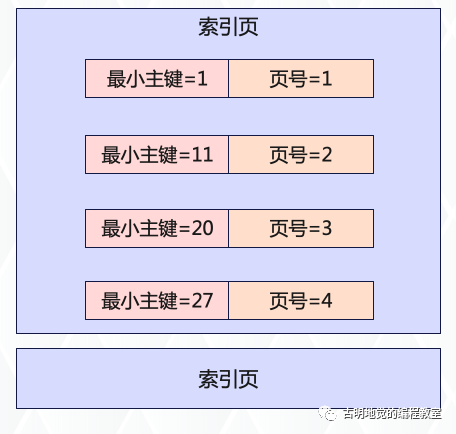
但是问题来了,由于此时有很多的索引页,那么给定一个主键值之后,怎么确定要去哪个索引页里面找呢?很简单,在索引页的基础上再抽象一层即可,而高层的索引页不再保存数据页页号,而是保存索引页页号。
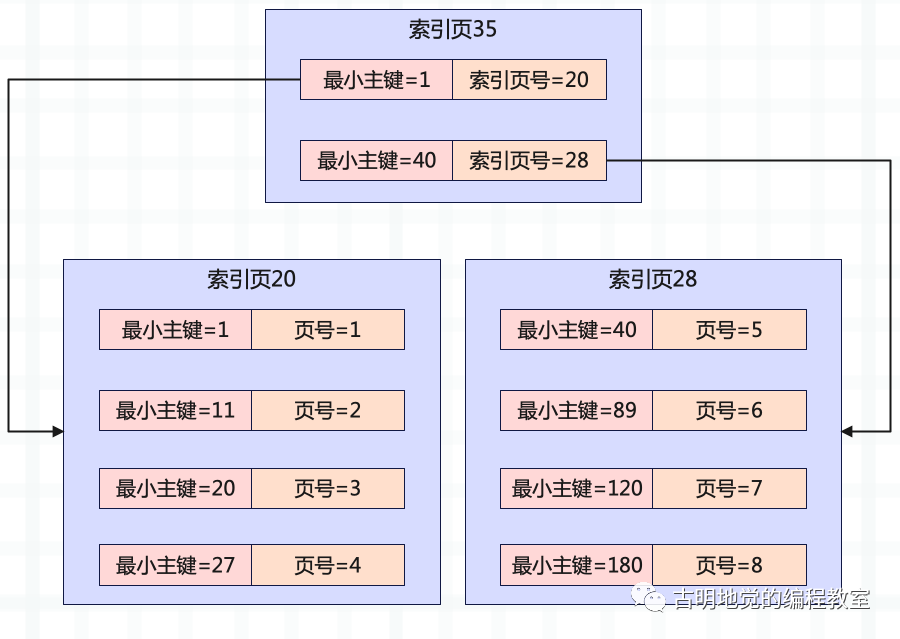
假设现在要找 id=46 的,先在最顶层的索引页进行二分查找,可以迅速定位下一步应该去 28 号索引页查找。在 28 号索引页继续二分查找,可以定位到 5 号数据页。最后遍历 5 号数据页,即可找到指定的数据。
当然这里第二层只有两个叶子节点,但实际上节点可以有很多。如果两层不够,那么继续分裂。
一般来说,2 层索引页可以对应几千万条数据。如果表字段不多的话,那么支持上亿条数据也不成问题。估计你应该听过业界有这么一个结论,MySQL 单表数据量不应该超过两千万,因为平均下来 2 层索引页大概支持的数据量就是两千万,再多可能就需要第 3 层了,这样 IO 次数会增加。
但实际上这和你的表字段数量有关系,如果表字段数量不多,那么即使上亿条数据,2 层的索引页也可以支持。所以这个视业务而定,有的公司单表存储了上亿条数据,查询速度依旧不慢。
注意:我们上面说索引页有 2 层,但还有一层数据页,它们整体组成一个树形结构,该树就叫做 B+ 树。然后当根据主键来查数据的时候,直接从 B+ 树的顶层开始二分查找,一层层往下定位,最终定位到一个数据页里,在数据页内部找到那条数据。所以对于 B+ 树而言,它的叶子节点就是数据页。如果将图画的再完整一些:
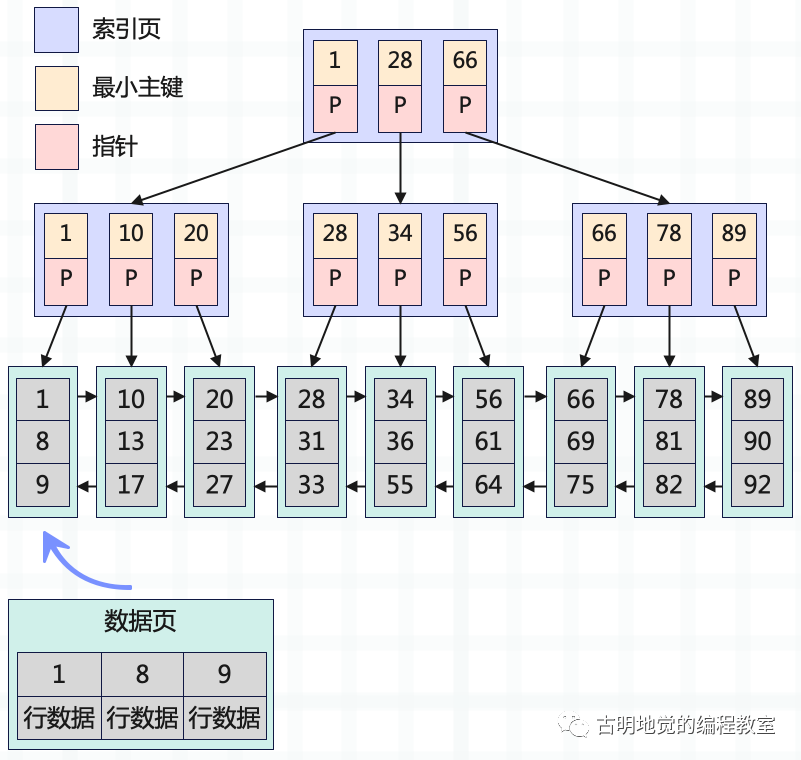
为了理解方便,我们一开始说索引页里面保存的是页号,但其实不是的,里面保存的是指针。顶端的索引页里面的指针,指向下一层索引页;第二层索引页里面的指针,则指向数据页。数据页之间组成一个双向链表,每个数据页里面保存了数据行,数据行之间组成单向链表。
这就是一个三层 B+ 树的基础结构。
然后不知道你有没有注意到,数据页和索引页居然是存储在一起的,这样的索引我们称之为聚簇索引。聚簇索引对应的 B+ 树,其叶子节点就是数据页,数据页里面存储的是行数据,非叶子节点(索引页)存储的则是主键和指针。
如果数据页开始页分裂了,MySQL 会调整各个数据页内部的行数据,保证数据页内的主键值都是有顺序的,下一个数据页的所有主键值大于上一个数据页的所有主键值。同时在页分裂的时候,还会维护上层索引数据结构,以及在上层索引页里维护相应的最小主键值和指针指向。
以上就是聚簇索引,它默认是按照主键来组织的,并且会自动建立。在增删改数据的时候,一边更新数据页,一边自动维护 B+ 树结构的聚簇索引。
使用非主键字段建立索引
聚簇索引是基于主键组织的,但我们还可以在其它字段上建索引,而在非主键字段上建立的索引叫非聚簇索引,或者二级索引。
比如基于 name 字段建索引,同样会生成一棵 B+ 树,其规则和聚簇索引一模一样,比如下一个数据页 name 字段的值都大于上一个数据页。但不同的是,聚簇索引的叶子节点存储了完整的数据,而二级索引的叶子节点存储的是相应的主键值。
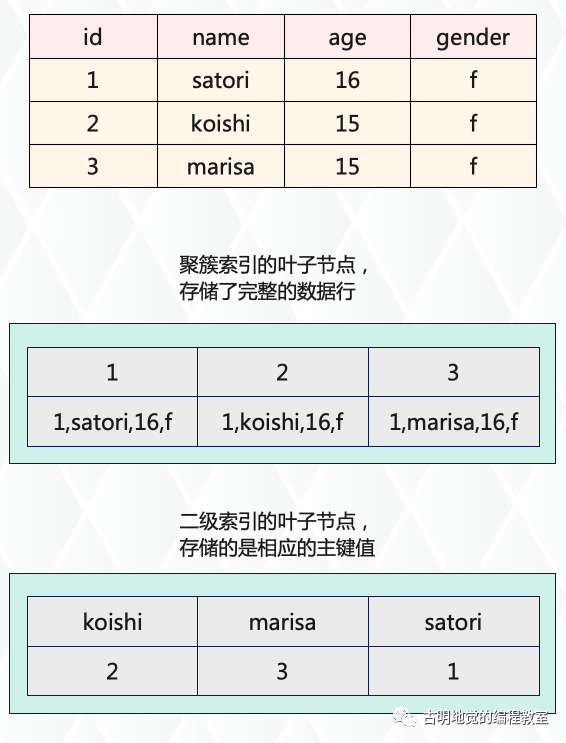
这里的二级索引是基于 name 字段建立的,排序之后顺序是 koishi, marisa, satori,因此和聚簇索引一样,都要保证顺序。但不同的是,聚簇索引的叶子节点存储的是完整的行数据,二级索引只存储了主键值。
比如 select * from t where name = 'marisa' 这行语句,由于 name 字段建立了索引,那么能快速找到对应的主键值为 3。拿到主键值之后,再根据主键值到聚簇索引里面查找,即可拿到完整的数据,而这个过程就叫做回表。
也就是说,光靠二级索引是拿不到完整数据的,只能拿到主键和作为索引的字段本身。如果想获取完整数据,或者说其它字段的数据,那么还要基于主键再到聚簇索引里面查询一次。而用二级索引拿到的主键值,再去聚簇索引里面查询的这个过程就是回表。
当然啦,如果我们只获取 name 字段,那么需不需要回表呢?显然此时是不需要的,因为索引就是基于 name 字段建立的,这棵 B+ 树里面包含了 name 字段。但如果想同时获取 name 和 gender 字段,那么就需要回表了。
相信现在你应该明白索引的原理了,说白了就是可以让我们通过二分查找快速定位到指定的数据页,然后只需要遍历这一个数据页即可。
而索引就是一棵 B+ 树组成的数据结构,一张表如果有多个索引,那么就有多棵 B+ 树。而数据页(具体数据)位于聚簇索引(基于主键组织)的叶子节点上,其它的二级索引的叶子结点只保存了主键值。那么问题来了,为什么二级索引不保存数据页呢?这样查询的时候就不用回表了。好吧,这个问题问的有点傻了,因为如果二级索引页保存数据页,那么就意味着有多少个二级索引,一张表就要被拷贝多少次,显然这是非常不明智的。
所以总结一下:
- 数据页不是孤立存在的,它是和索引结合在一起的,而这样的索引叫做聚簇索引。也就是说不管我们有没有建立索引,一定至少会有一个默认的聚簇索引,它基于主键组织,叶子节点存放了具体的数据页。
- 索引可以有多个,我们自己建立的索引叫二级索引,它的叶子节点存放的是主键值。
- 通过二级索引只能查询到主键值和作为索引的字段本身,如果想获取其它字段的数据,那么还需要基于主键值再去聚簇索引当中查找,这个过程叫做回表。
复合索引
我们可以在一个字段上建索引,但也可以同时给多个字段建索引,而这样的索引叫做复合索引。比如有一张表,我们基于里面的 name、age、salary 三个字段建立复合索引。
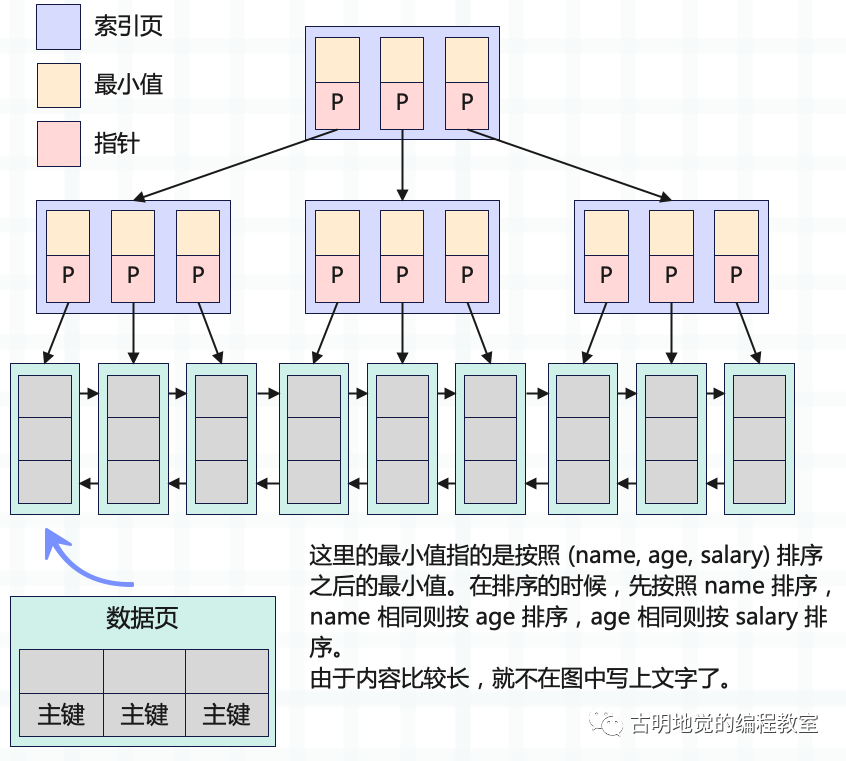
所以本质上,复合索引和二级索引、聚簇索引没有什么不同,它们的规则都是一样的。
索引越多越好吗
基于索引查询的优点我们知道了,可以快速定位到某个数据页,而不需要全表扫描,效率很高。但是有没有坏处呢?当然有,主要有两个,一个是空间上的,一个是时间上的。
空间上而言,如果给很多字段都建立索引,那么必定会有很多棵索引 B+ 树,而每一棵 B+ 树都要占用磁盘空间。所以要是搞的索引太多了,是很耗费磁盘空间的。其次,要是搞了很多索引,那么在进行增删改查的时候,每次都需要维护各个索引的数据有序性。因为每个 B+ 树都要求页内是按照值大小排序的,页之间也是有序的,下一个页的所有值必须大于上一个页的所有值。
所以不停地增删改,必然会导致各个数据页之间的值大小顺序遭到破坏,比如下一个数据页里插入的值,比上一个数据页里的值小。那么为了维护索引的有序性,只能进行数据页的挪动,维护页之间的顺序。再或者是你不停地插入数据,各个索引的数据页就要不停的分裂,不停地增加新的索引页,这个过程都是耗费时间的。
所以一个表里搞的索引太多了,也许查询速度会提高,但是增删改就会受到影响。因此通常来说,我们是不建议一个表里建过多的索引,而且像某些字段建立索引压根就没有意义。
那么我们怎么才能用最少的索引满足最多的查询请求(换句话说就是应该给哪些字段建索引),还不至于让索引占用太多磁盘空间,影响增删改性能呢?显然这就需要我们深入理解索引的使用规则了,我们的 SQL 语句要怎么写,才能用上 B+ 树来查询。
索引使用规则
下面介绍几个最常见和最基本的几个索引使用规则,也就是说,当我们建立好一个索引之后,SQL语句要怎么写,才能让查询使用到建立好的索引呢?
等值匹配:
where 语句中的字段和索引字段一样,而且是等值匹配,那么百分百会使用到索引。复合索引也是同理,并且即使 where 语句里的字段顺序和复合索引里的字段顺序不一致也没关系,MySQL 会自动优化为复合索引的字段顺序去找。
最左侧列匹配:
这个针对的是复合索引,假设索引是 KEY(name, age, addr),那么不一定非要同时根据这三个字段来查,用一个或两个也是可以的。但查询的时候,必须要使用最左侧的字段去查。
比如根据 name 和 age 去查,那么 name 和 age 可以走索引;但根据 name 和 addr 去查,那么只有 name 会走索引,addr 无法走索引;要是根据 age 和 addr 去查,那么这两个字段都无法走索引。当前复合索引有三个字段,那么可以看成是桥头、桥中、桥尾,只能从左往右,如果中间出现了断层,那么断层后面的字段就无法走索引了。
最左前缀匹配:
这个说的是 like 语法,比如:
SELECT * FROM t
WHERE name LIKE 'sa%'
如果给 name 字段建了索引,那么此时可以走索引。但如果改成 '%sa' 就走不了索引了,因为不知道最左前缀是什么。
我们应该怎么设计索引
在针对业务需求建立好一张表之后,就知道这张表有哪些字段,每个字段是什么类型,会包含哪些数据。那么这个时候,第一个索引设计原则就来了,针对未来 SQL 语句里的 where 条件、order by 条件以及 group by 条件去设计索引。也就是说,你的 where 条件里要根据哪些字段来筛选数据?order by 要根据哪些字段来排序?group by 要根据哪些字段来分组聚合?
此时就可以设计一个或者两三个联合索引,每一个联合索引都尽量包含上你的 where、order by、group by 里的字段。接着你就要仔细审查每个SQL语句,是不是每个 where、order by、group by 后面跟的字段顺序,都是某个联合索引的最左侧字段开始的部分字段?
所以在设计索引的时候,第一个原则就是保证你的每个 SQL 语句的 where、order by 和 group by 都可以用上索引。
设计索引的第二个原则就是尽量使用那些基数比较大的字段,这样才能发挥 B+ 树的优势,什么意思呢?比如一个字段它只包含两种值,要么是 0 要么是 1,那么该字段的基数就是 2,因为它就只有 0 和 1 两个选择。
如果你要是针对上面这种字段建索引的话,其实还不如全表扫描,因为你的索引树里就包含 0 和 1 两种值,根本没法进行快速地二分查找,也就没有太大的意义了。所以这个时候,选用这种基数很低的字段放索引里意义就不大了,因此真正的做法是不对这样的字段建索引。
其次的话,尽量对那些类型比较小的字段来建索引,比如 tinyint 之类的,因为字段类型比较小,说明这个字段自己本身的值占用磁盘空间小,此时搜索的时候性能也会比较好一点。当然啦,这个所谓的类型小一点的字段,也不是绝对的。很多时候我们就是要针对varchar(255) 这种字段建立索引,哪怕多占用一些磁盘空间,其实比较关键的还是尽量别把基数太低的字段包含在索引里,因为意义不大。
另外,如果你真的觉得给 varchar(255) 类型的字段建索引太耗费空间,那么完全可以换一种策略,比如给它的前 20 个字符建索引。假设该字段叫 name,那么建索引的时候就可以指定 name(20)。然后在 where 条件里根据 name 字段搜索时,会先到索引树里根据 name 字段的前 20 个字符去搜索,定位到之后前 20 个字符匹配的部分数据之后,再回到聚簇索引提取出来完整的 name 字段值进行比对就可以了。
以上这种索引被称为前缀索引,where 子句可以使用,但是 group by 和 order by 就用不上了。
设计索引的第三个原则,就是不要对那些需要使用函数的字段建索引。比如在 SQL 语句里面这么写:where some_func(a) = xx,我们给索引字段 a 套上了一个函数,你觉得还能用上索引吗?很明显用不上了。
最后很关键一点,主键最好是自增的,别用 UUID 之类的。因为主键自增,起码聚簇索引不会频繁的分裂,主键值都是有序的,只会自然地新增一个页而已。但如果你用的是 UUID,那么会频繁导致聚簇索引的页分裂。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏 
支付宝赞赏 



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· 【.NET】调用本地 Deepseek 模型
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)
· DeepSeek “源神”启动!「GitHub 热点速览」