
常见的函数--帆软(3)
常见函数列表
-- -- -- -- ---- -- -- -- ---- -- -- -- ---- -- -- -- ---- -- -- -- --
常用的函数
主页:https://www.cnblogs.com/wan-ge1212/p/10256341.html
常见的函数--帆软(2) - 倾晴雨轩 - 博客园 (cnblogs.com)
帆软全面网址介绍
常见函数列表
1. 概述
1.1 预期效果
用户有时候需要将字符串依据某个符号进行分列显示,即将字符串转换为数组。
例如单元格 A1 中有为「苹果汁,牛奶,柳橙汁,巧克力,牛肉干」的字符串,希望将该字符串中的每个值在不同单元格中分列显示,如下图所示:

或者将不同单元格中的字符串拼接在一起,即将数组转成字符串。
例如单元格 A1:A6 值为「苹果汁」「牛奶」「柳橙汁」「巧克力」「牛肉干」的数组,希望将其转为“;”分隔的字符串,如下图所示:

1.2 实现思路
使用 SPLIT 函数实现分割扩展单元格。
使用 JOINARRAY 函数实现将不同单元格中的字符串(数组)拼接在一起。
2. 用 SPLIT 函数分割扩展单元格-字符串转换为数组
2.1 模板设计
创建普通报表,在 A2 单元格输入「苹果汁,牛奶,柳橙汁,巧克力,牛肉干」,使用“,”作为分隔符,然后在 B2 单元格输入公式=split(A2,","),如下图所示:
注:有时字符串数据如“苹果汁|牛奶|柳橙汁|巧克力|牛肉干”,用“|”分隔,此时需要对“|”进行转义,即公式为=split(A1,"\\|")。 (\\|为转义字符)
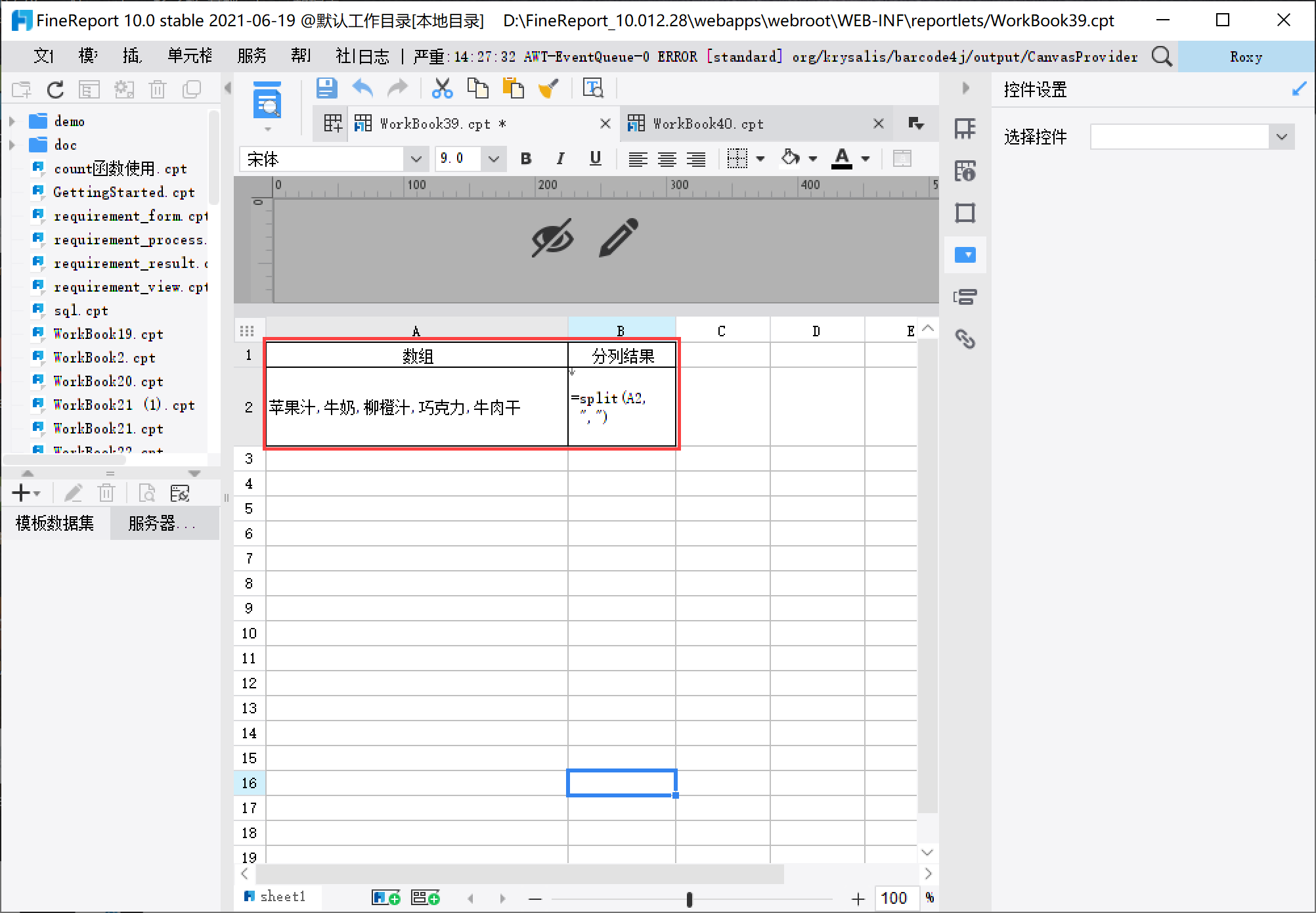
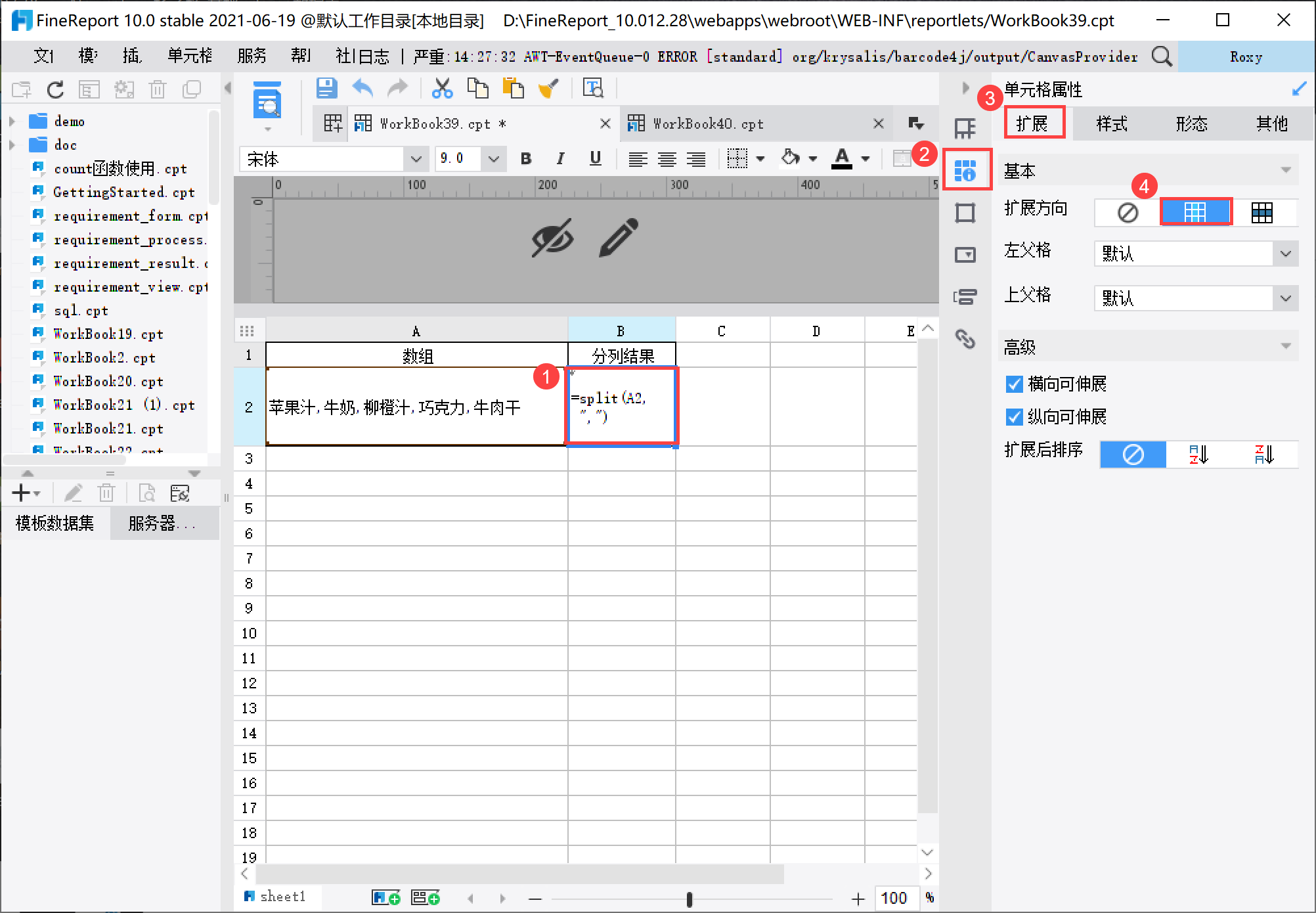
设置 B2 单元格的扩展方向为纵向扩展,即将分割的数据中每个元素显示在不同单元格中,形成数组,如下图所示:
2.2 效果查看
保存模板并预览。
3. 用 joinarray 函数将数组转换为字符串
3.1 模板设计
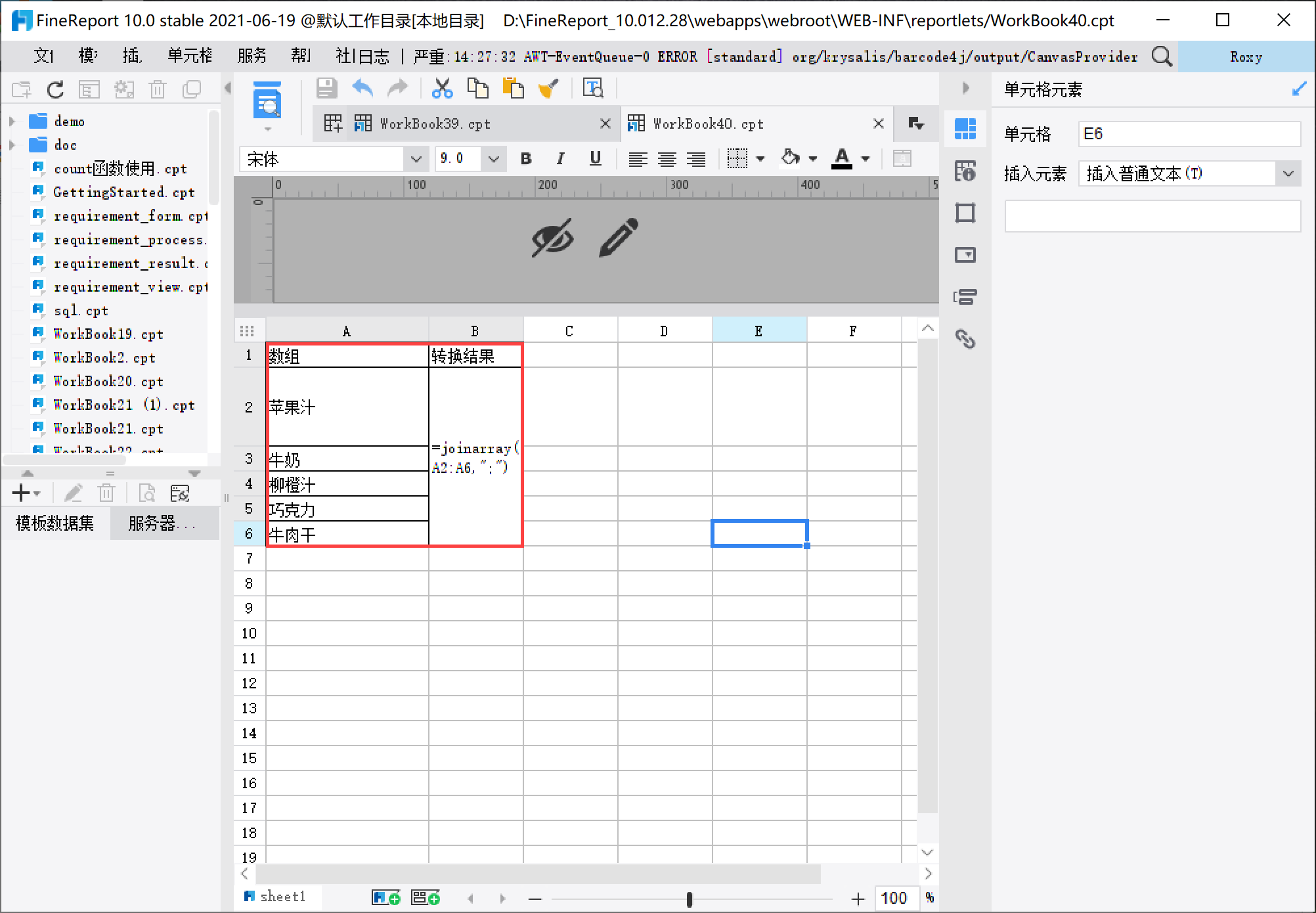
创建普通报表,分别在 A2、A3、A4、A5、A6 单元格输入「苹果汁」「牛奶」「柳橙汁」「巧克力」「牛肉干」,合并 B2:B6 单元格,并输入公式=joinarray(A2:A6,";"),如下图所示:
3.2 效果查看
保存模板并预览


1. 概述1.1 预期效果
在对于分组模板进行页码统计时,希望页码统计只在当前分组进行,即分组了就重新进行编码。
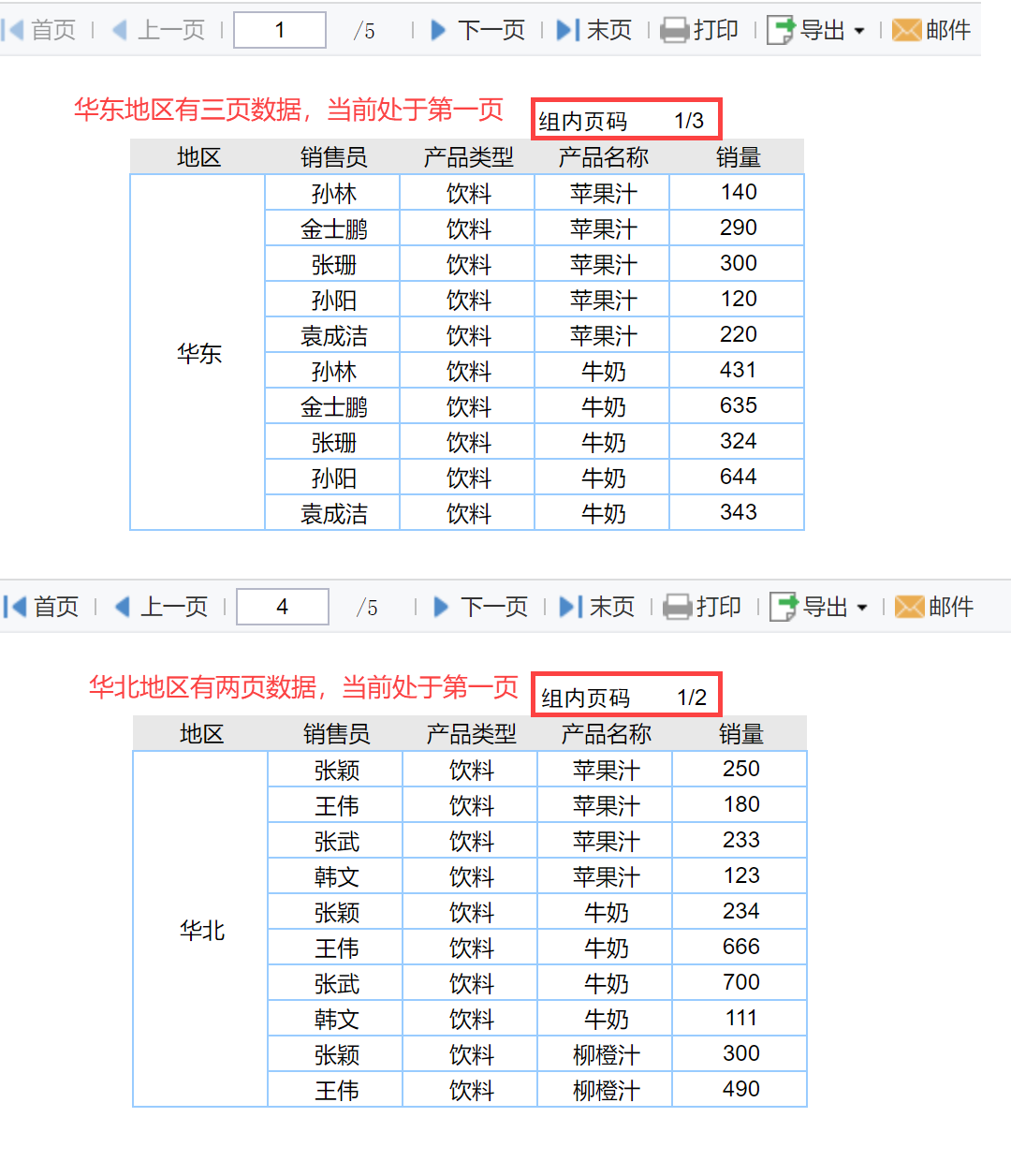
例如华东地区这个组内有三页数据而华北地区这个组内有两页数据,则分别标记「组内页码」,如下图所示:
1.2 实现思路
首先通过「每页固定行数」来计算每组所需的总页数,如上图中华东 3 页,华北 2 页;
其次使用当前页 $$page_number 减去之前组的总页数获得该页在当前组的页码,如上图华北的第一页数据所在 $$page_number为 4,减去之前组总页数 3,就是该页在华北组的页码。
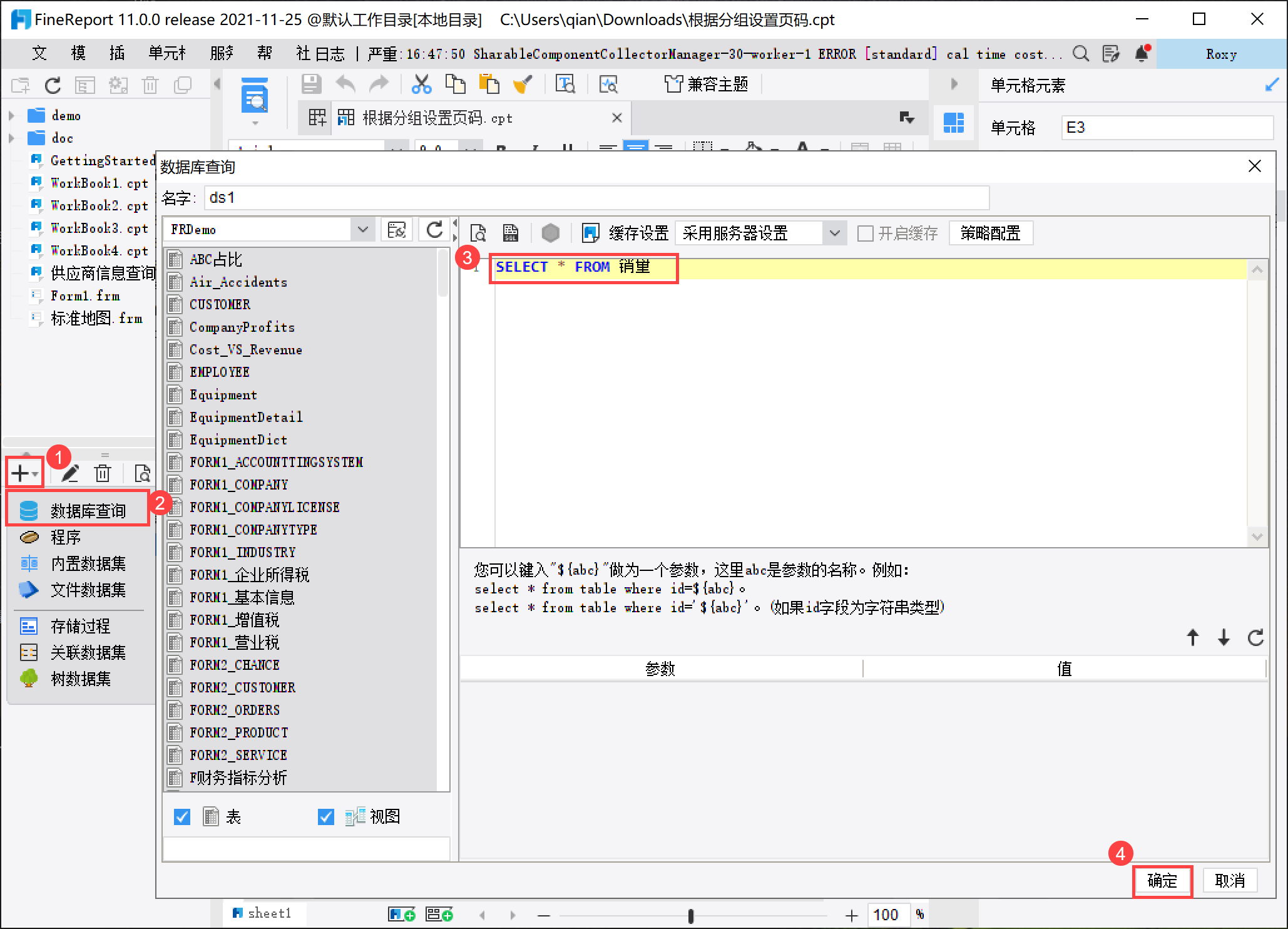
2. 操作步骤使用内置 DEMO 数据「销量」。2.1 报表设计
添加模板数据集 ds1,输入SQL 语句SELECT * FROM 销量,如下图所示:
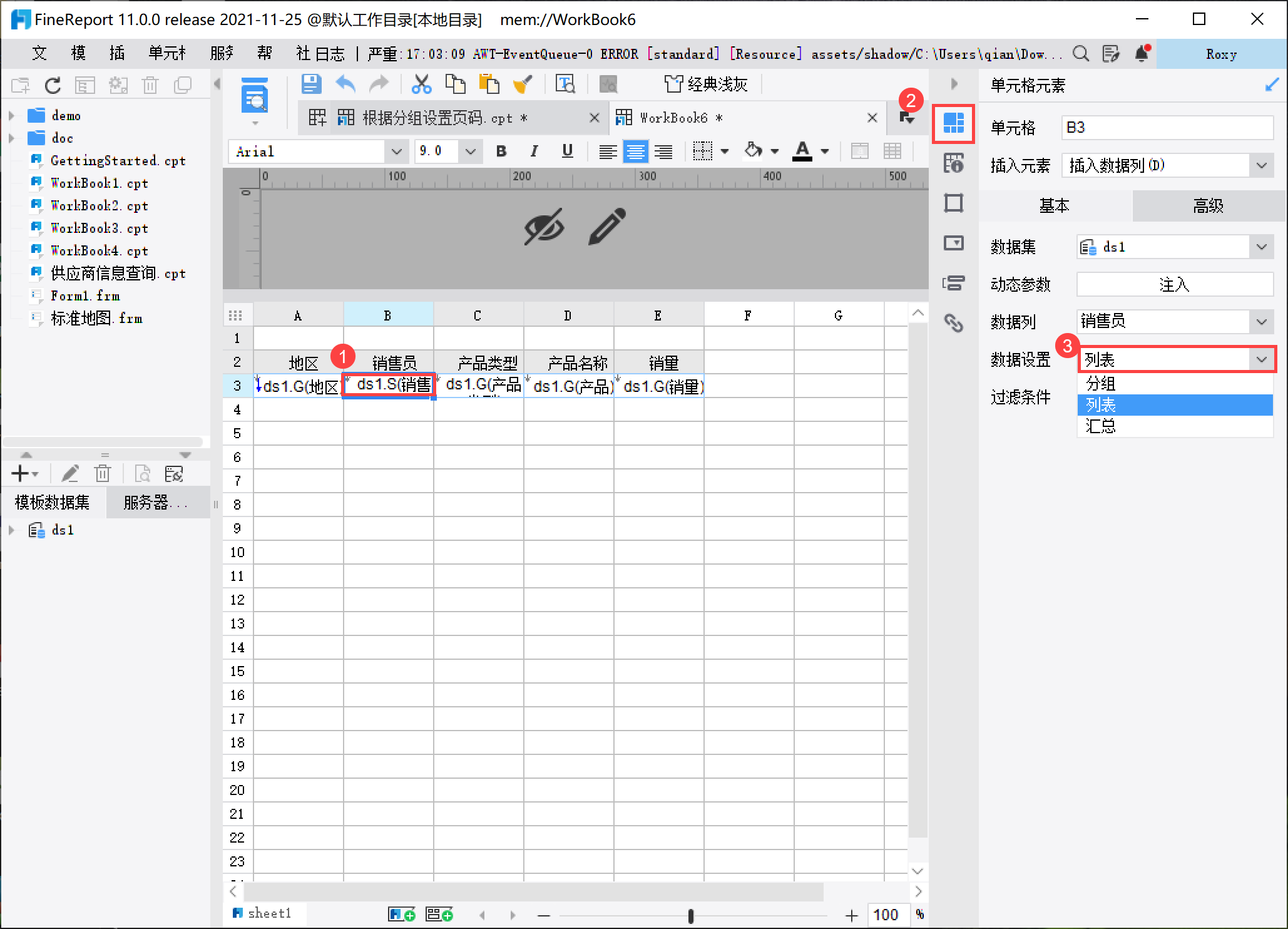
新建报表,并将 B3 单元格设置为列表展示,如下图所示:
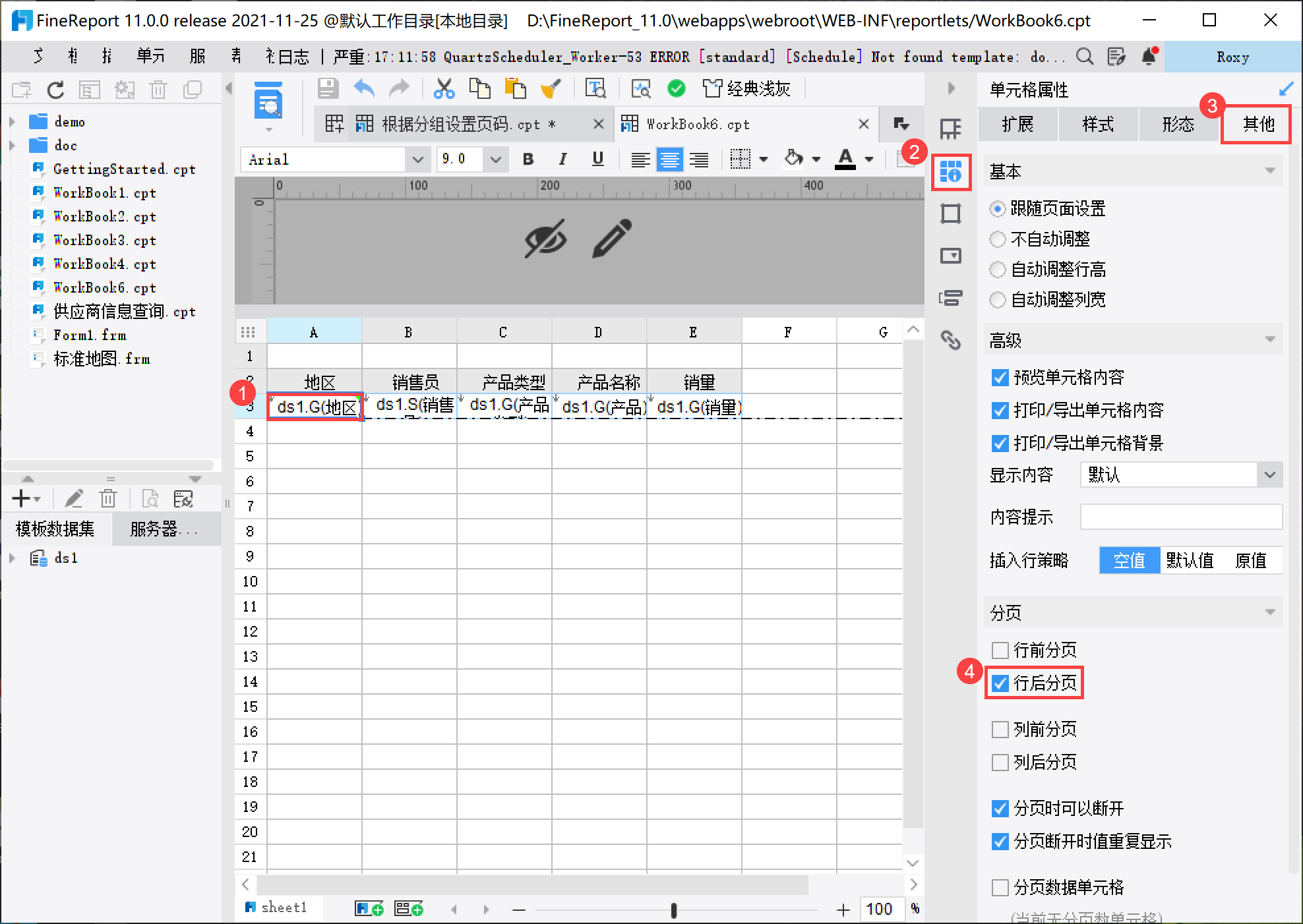
2.2 设置按组分页
右击 A3 单元格,选择单元格属性>其他>行后分页,如下图所示:
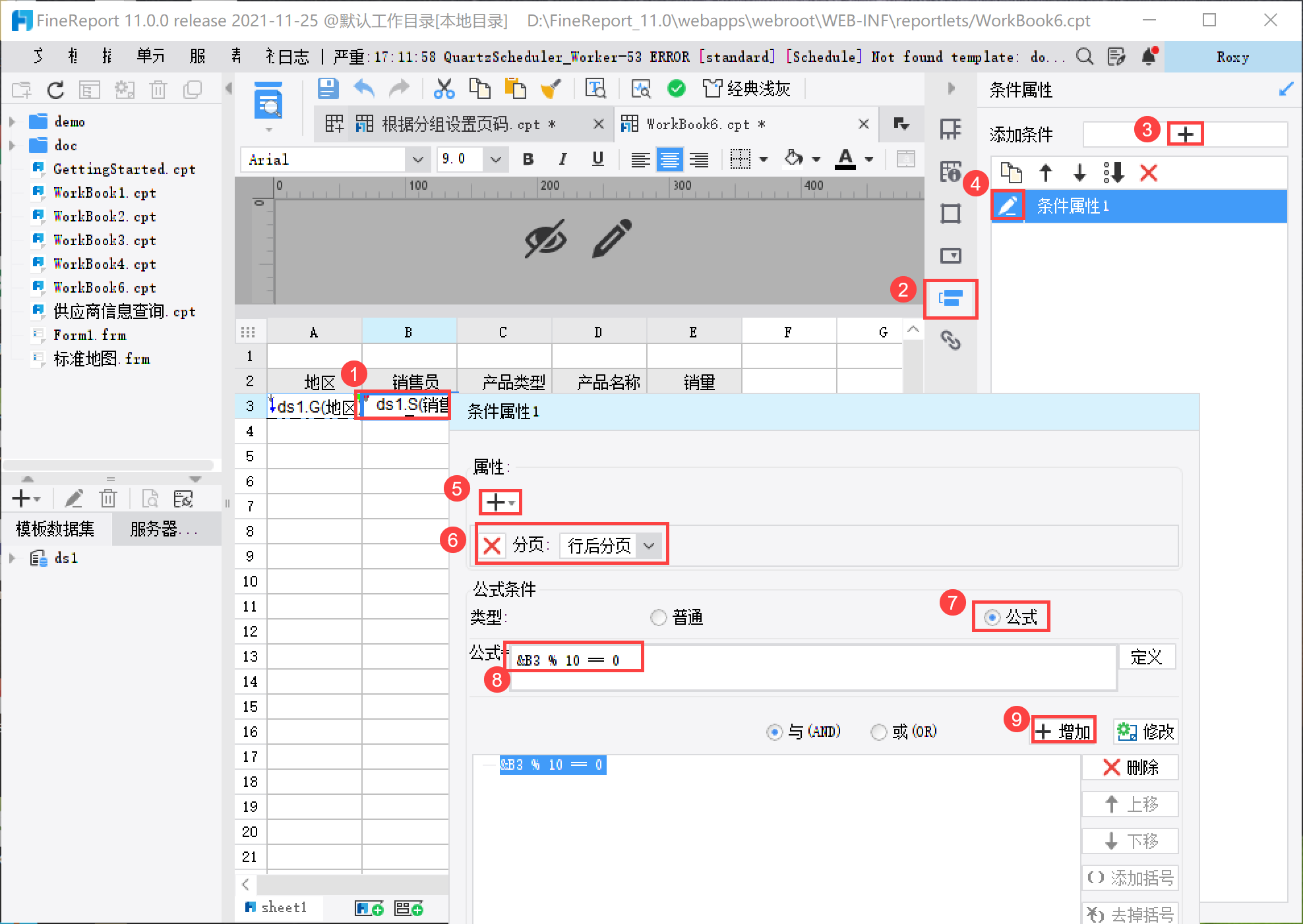
2.3 设置每页显示固定行数
右击 B3 单元格,选择条件属性>添加条件>行后分页,当满足公式&B3 % 10 == 0时,该属性起作用,如下图所示:
将 1-2 行设为重复标题行,使其在翻页时,每页重复显示,如下图所示:
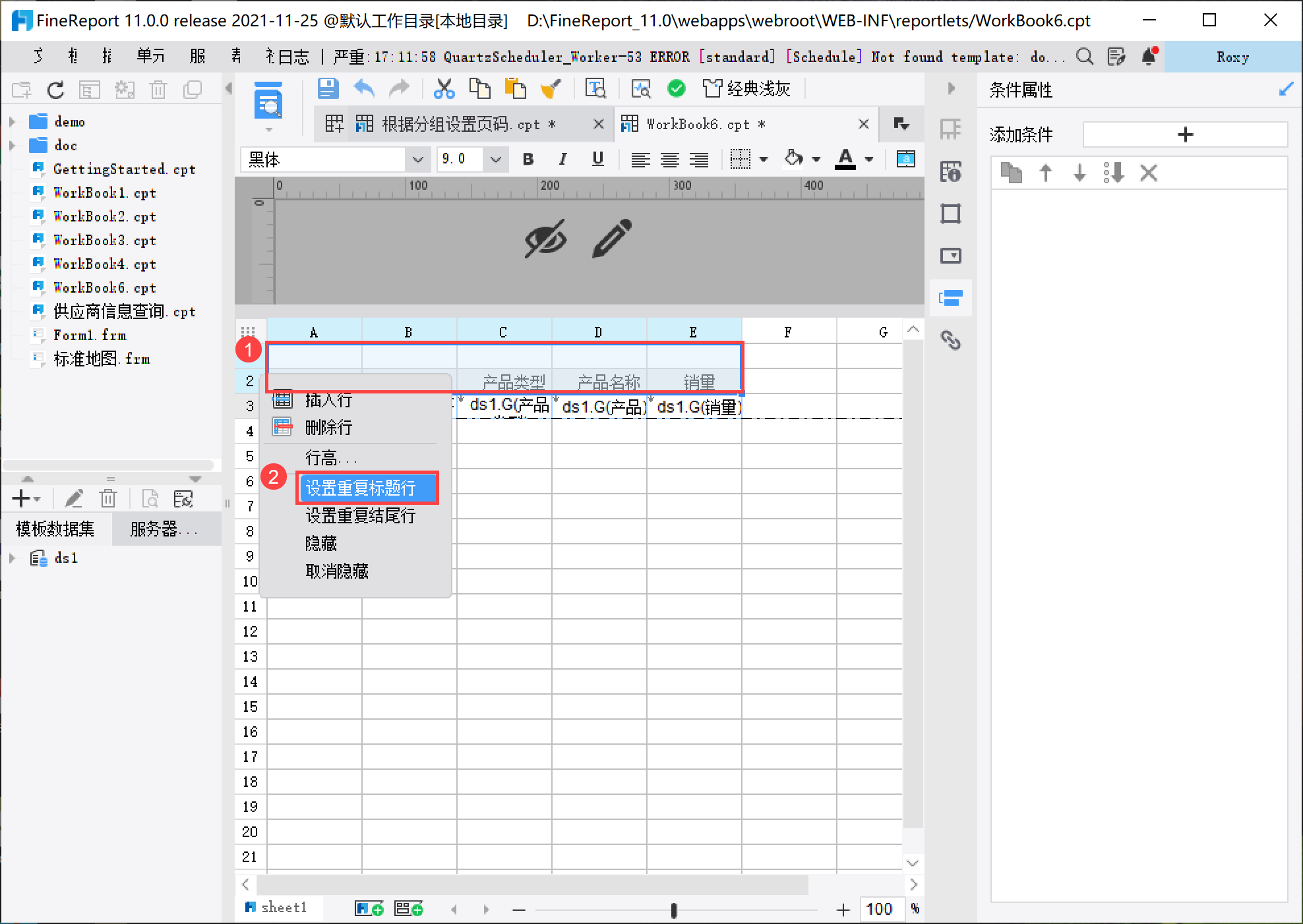
2.4 进行页码设置
2.4.1 当前分组的页码与上个分组的页码之和
首先要获取当前分组为第几个分组,在 A1 单元格中输入公式:=&A3,并将其左父格设置为 A3 单元格。
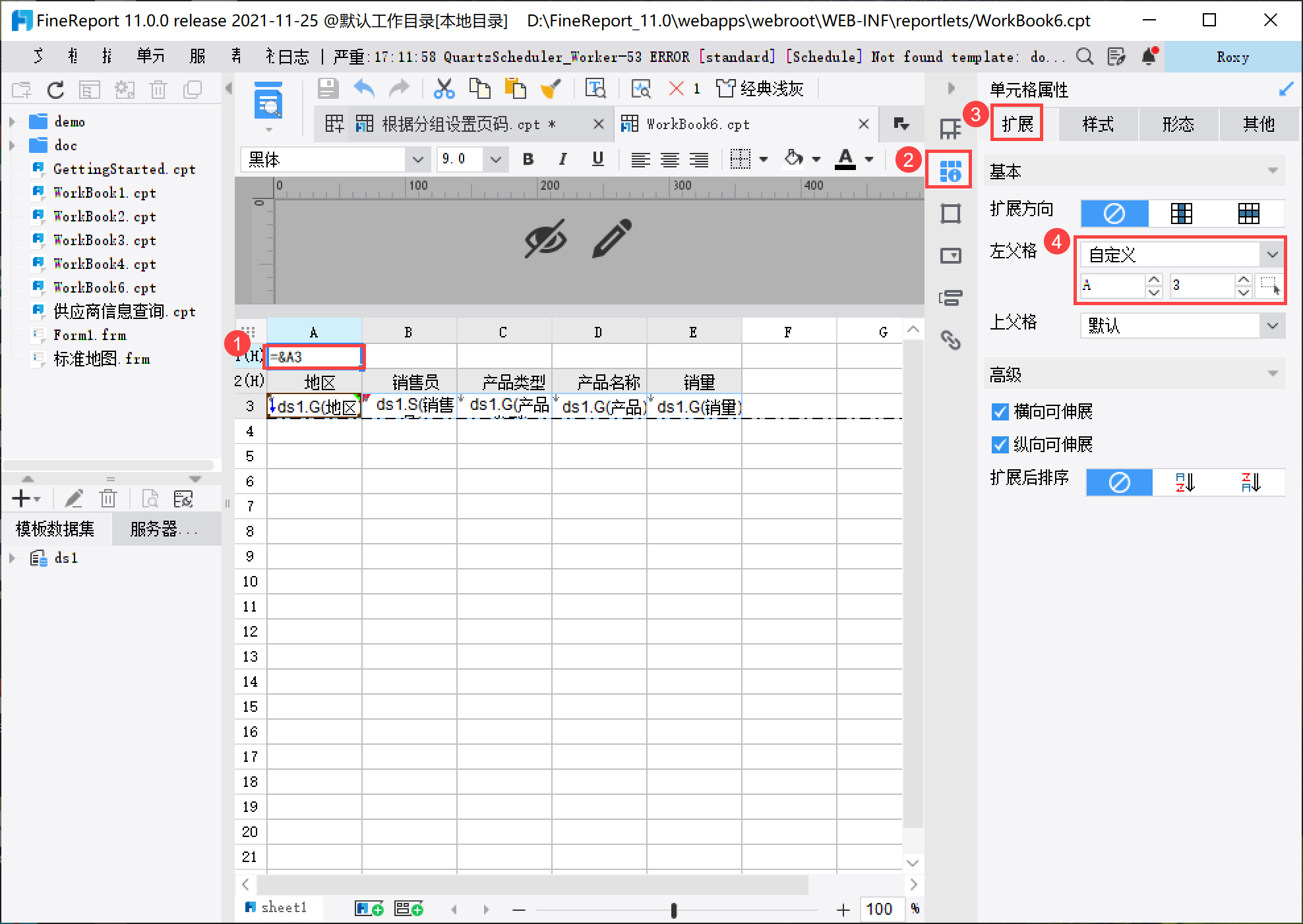
在 B1 单元格中输入公式:=roundup(count(B3) / 10, 0) + B1[A3:-1],获取当前分组的页码与上个分组的页码的总页码,如下图所示:
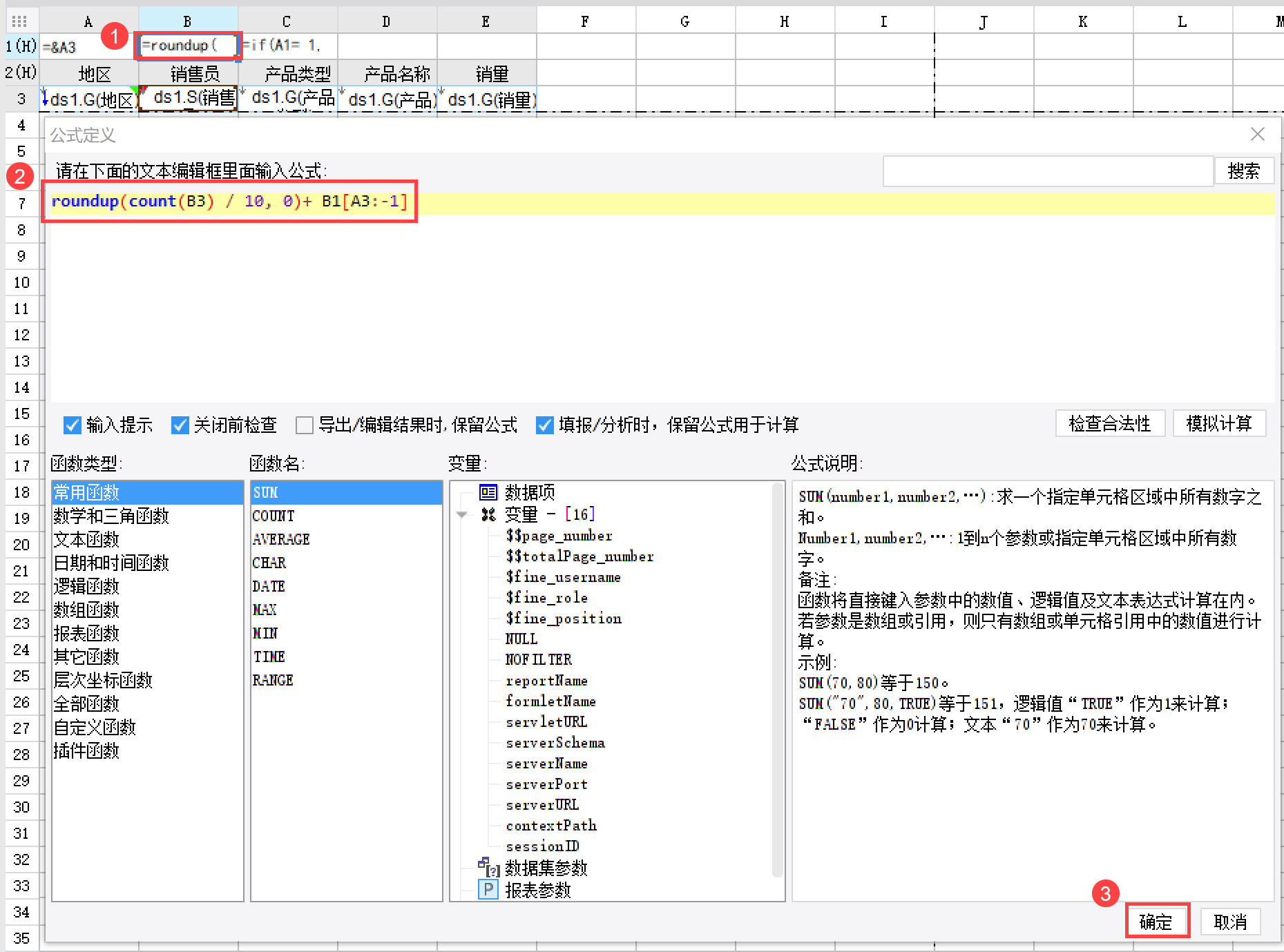
公式说明:
| 公式 | 说明 |
|---|---|
| B1[A3:-1] | 获取上一个 A3 分组内 B1 单元格的值 |
| roundup(count(B3) / 10, 0) | roundup 为向上取整,由于我们设置了 10 行为一页,因此计算结果为当前分组(例如华北)共有几页 |
| roundup(count(B3) / 10, 0) + B1[A3:-1] | 获取当前分组的页码与上个分组的页码之和 |
2.4.2 显示当前页在当前分组中的页数
在 E1 单元格中输入公式:=if(A1= 1, $$page_number + "/" + roundup(count(B3) / 10, 0), $$page_number - B1[A3:-1] + "/" + roundup(count(B3) / 10, 0)),如下图所示:
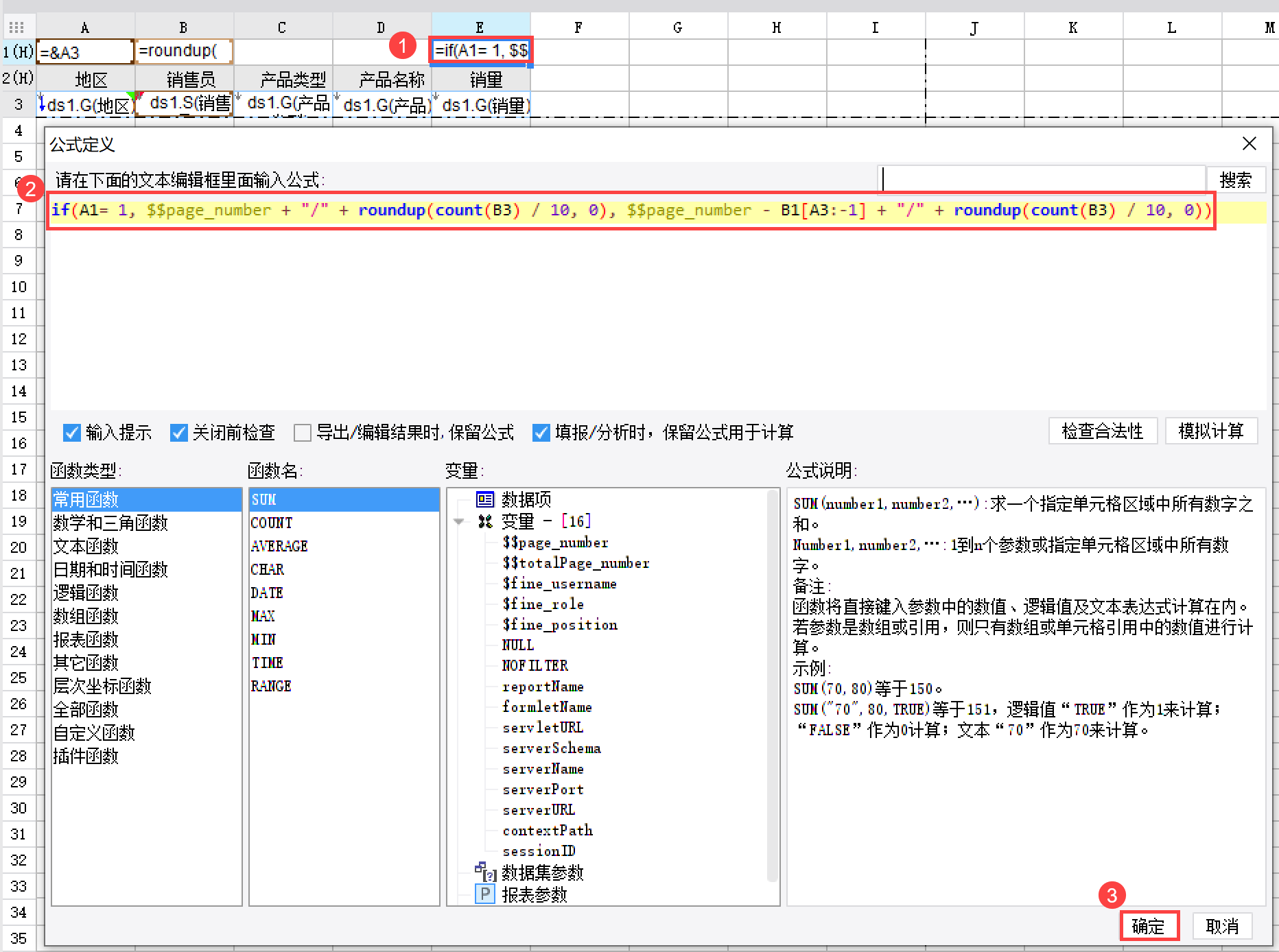
公式说明:
| 公式 | 说明 |
|---|---|
| $$page_number | 当前页码 |
| roundup(count(B3) / 10, 0) | 当前分组(例如华北)共有几页 |
| $$page_number + "/" + roundup(count(B3) / 10, 0) |
用 + 符号进行字符串拼接 表示当前页在当前分组的第几页 如果 A1 即当前分组为 1,就直接为当前页/当前分组总页数;如果不为 1,则当前页码减去之前所有分组的总页数和。 |
A1、B1 都为中间运算结果,可以设置单元格格式>其他属性>不预览单元格内容,如下图所示:
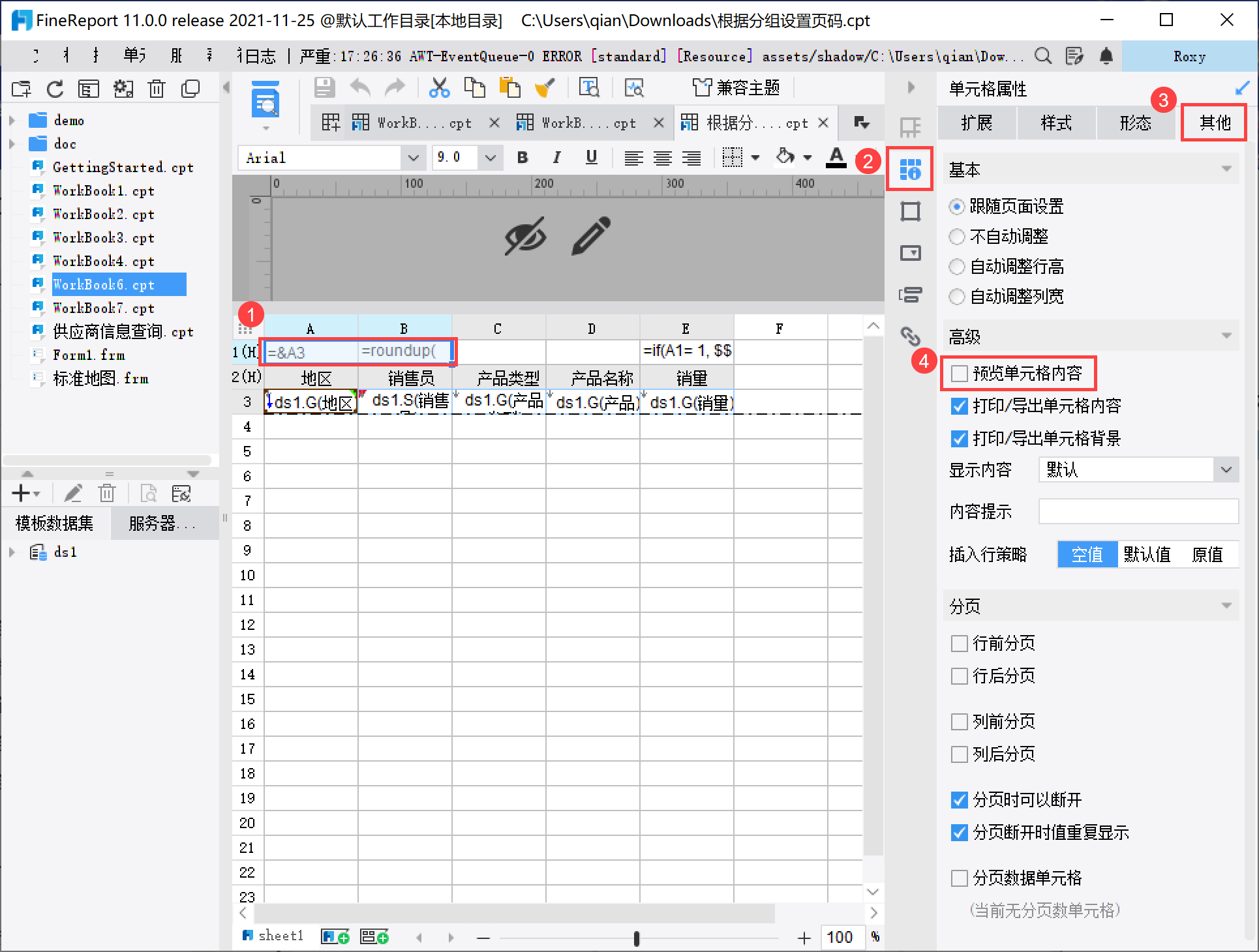
同时可以在 D1 单元格输入「组内页码」,如下图所示:
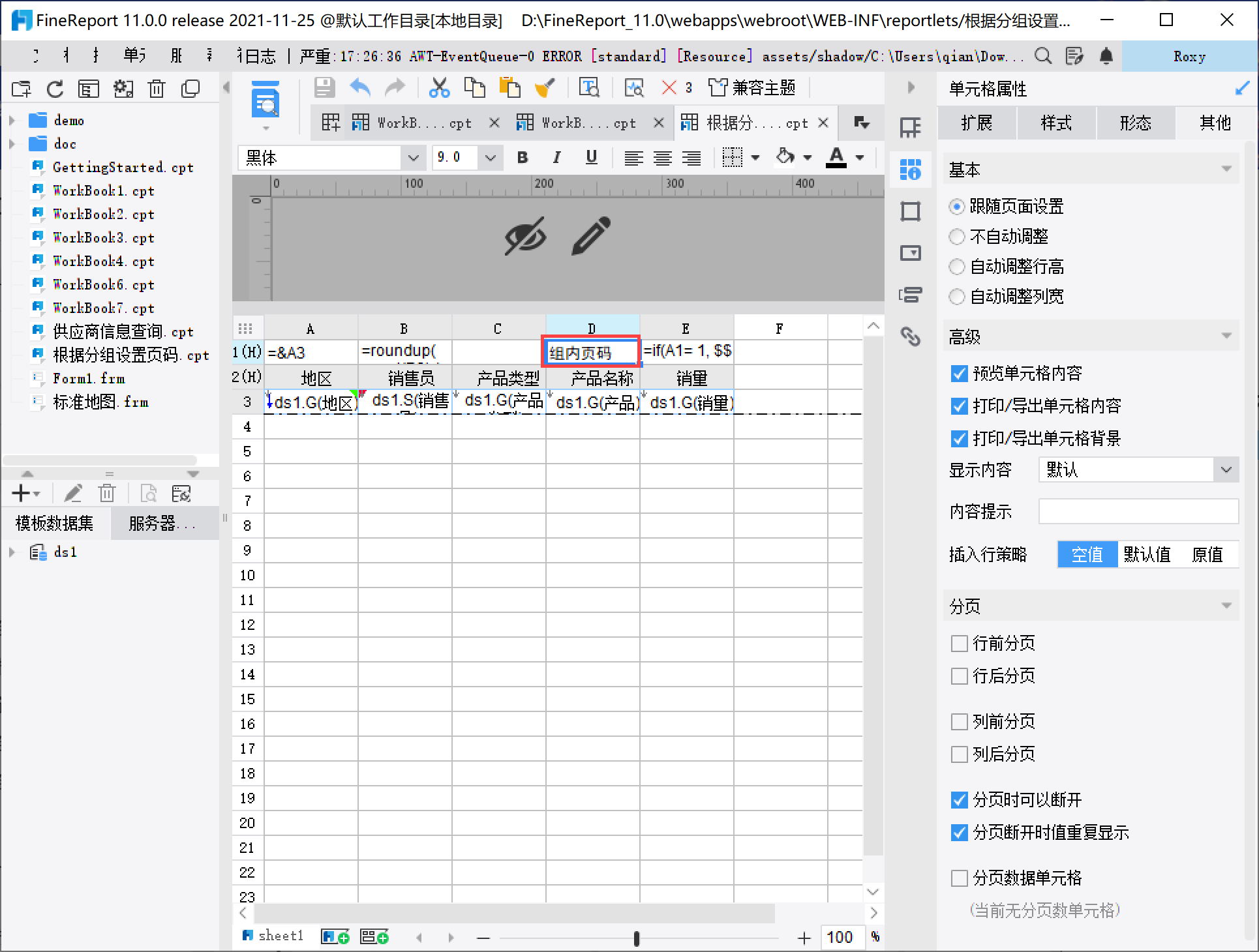
2.5 效果查看
保存模板后,点击「分页预览」,3. 模板下载
点击下载模板:根据分组设置页码.cpt
Count函数
1. 概述
1.1 函数作用
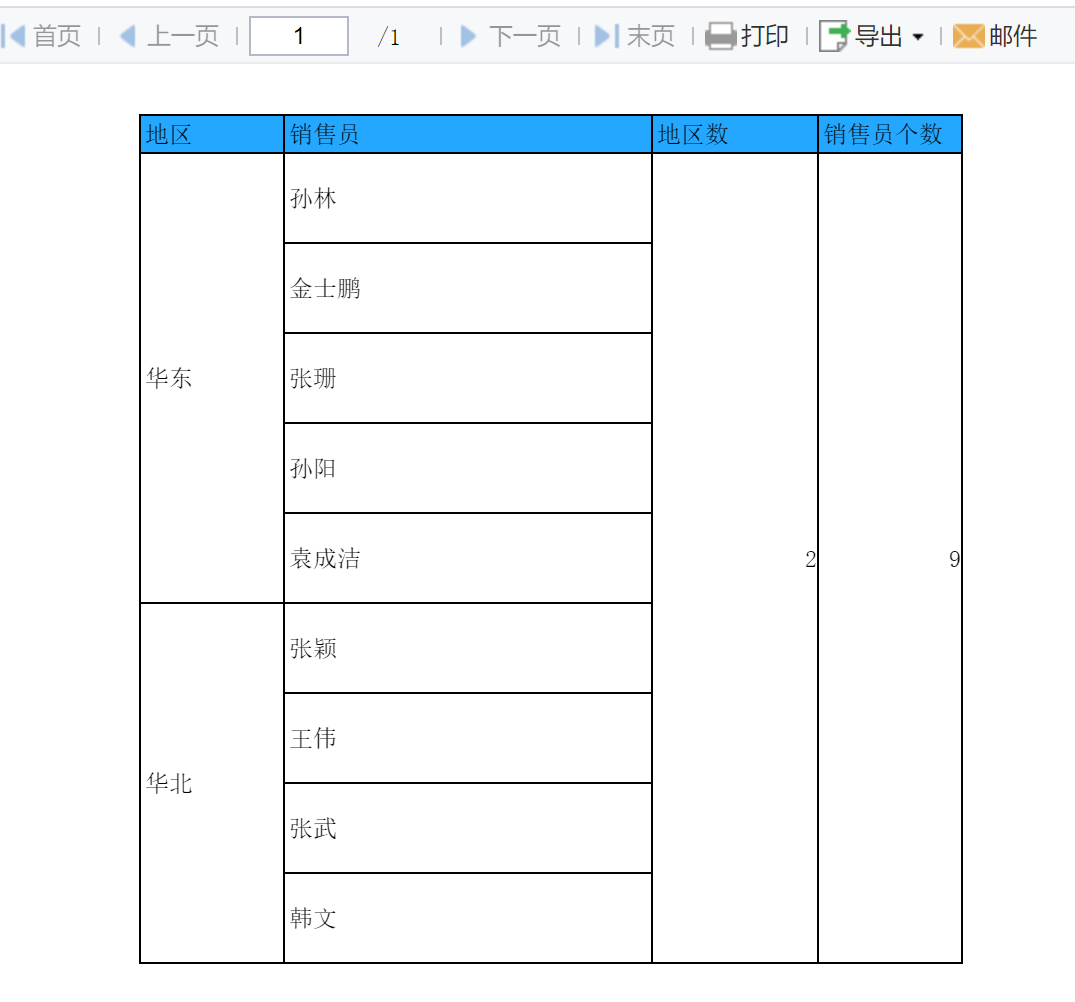
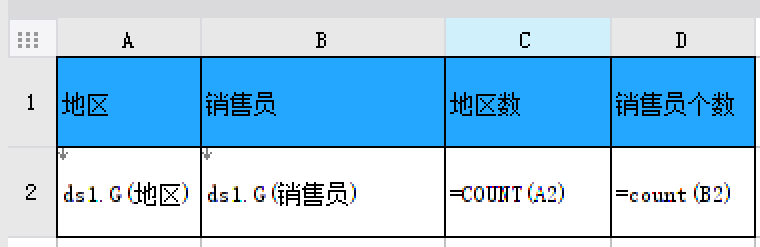
计算数组或数据区域中所含项的个数,例如统计「地区数」和「销售员个数」,如下图所示:
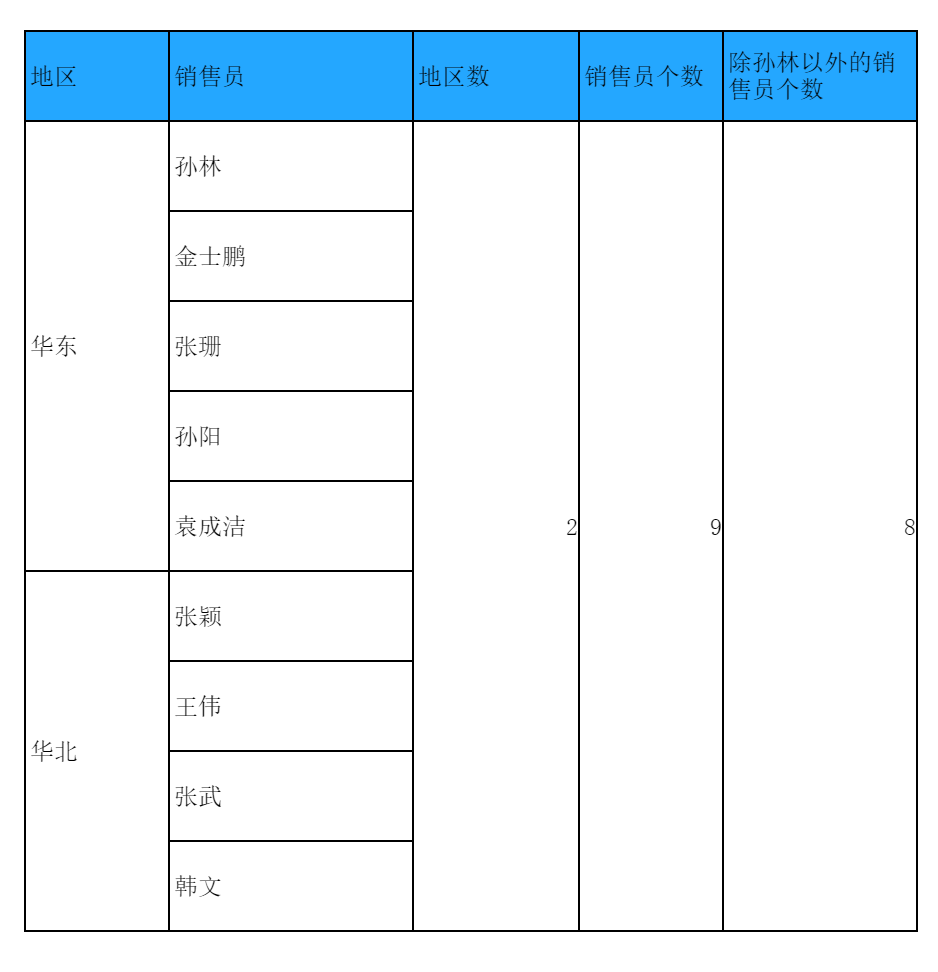
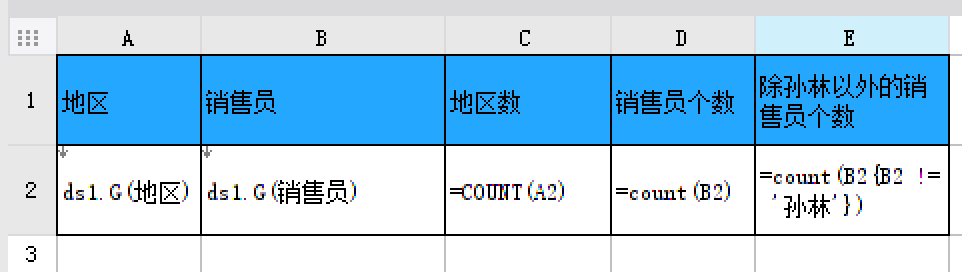
也可与其他函数嵌套使用,例如进行「条件计数」,计算除孙林以外的销售员个数,如下图所示:
在报表设计中,count 函数可以对单元格的个数计数,可以计算某个单元格扩展出来的个数,也可以求数组中元素的个数。
注:去重计数可通过组合 count 函数和 UNIQUEARRAY()函数实现 ,例如:count(UNIQUEARRAY(A1))。
1.2 函数解释
| 语法 | count(value1,value2,…) | 计算数组或数据区域中所含项的个数 |
|---|---|---|
| 参数1 | value1,value2,… |
可包含任何类型数据的参数 |
示例:
若 A1 单元格扩展了 5 个格子且都有数据, count(A1) 等于 5。
若 A1-A8 单元格中都有数据,count(A1:A8) 等于 8 。
count(2,3,4,5,7) 等于 5 。
1.3 注意事项
-
count 函数会对空字符串引起的空值计数;但对 NULL 值引起的空值不计数。
-
需要统计个数可以是数组、单元格,单元格可以是单元格区域,也可以是扩展单元格。
2. 去重计数
2.1 模板准备
新建模板,新建数据集ds1 ,sql 语句为 SELECT * FROM 销量,设置如下模板样式,并将「ds1.地区」字段拽入 A2 单元格,将「ds1.销售员」拽入 B2 单元格。在 C2 单元格输入公式 =count(A2) ,在 D2 单元格输入公式 =count(B2)。如下图所示:
2.2 设置数据列展示方式
count 只统计单元格的个数,由于「地区」和「销售员」数据列都有重复数据,因此如果需要统计地区个数和销售员个数,则需要设置「ds1.地区」A2单元格和「ds1.销售员」B2单元格单元格显示格式为「分组」,相当于进行去重计数,如下图所示:

注:如果以「列表」格式展示数据,但却希望统计去重计数个数,则可使用 count(UNIQUEARRAY())公式。
2.3 设置单元格扩展方式
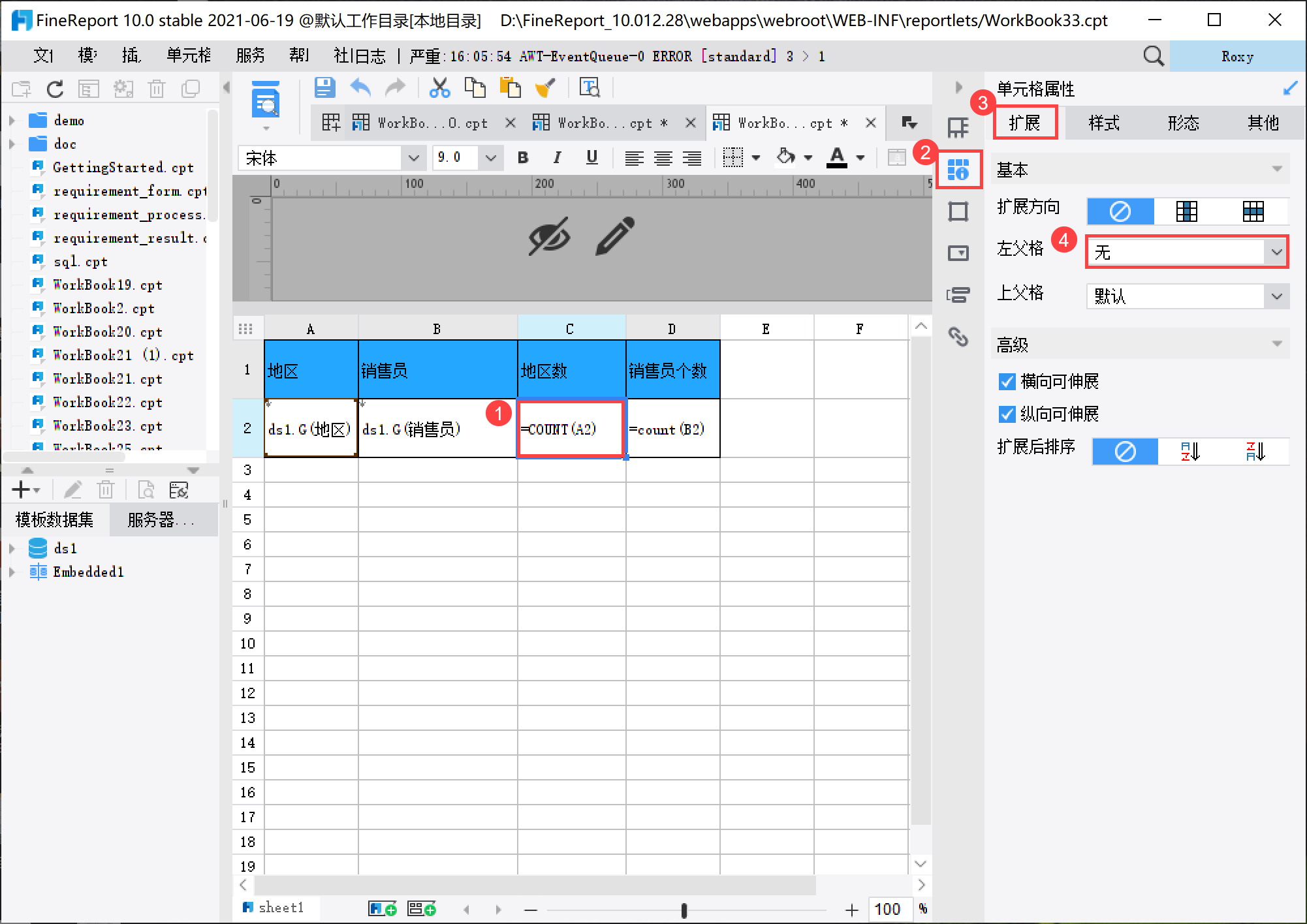
设置 C2 单元格的左父格为「无」,否则 C2 和 D2 单元格将跟随 B2 单元格扩展,无法正确计数,设置方法如下图所示:
2.4 效果查看
保存模板,效果见本文 1.1 节。
3. 条件计数count 函数中的参数为扩展单元格时,也可以与其他函数嵌套实现条件计数,格式为:count({}) ,其中 {} 内为计数条件。例如:count(A1{A1!=0}) 统计 A1 单元格扩展出来的数据中不为 0 的个数。 count(A1{len(A1) != 0})统计 A1 单元格扩展出来的数据中不为空的个数。本文第二节示例中,在模板 E2 单元格加入公式:=count(B2{B2!='孙林'}),如下图所示:
保存模板,效果见本文 1.1 节。
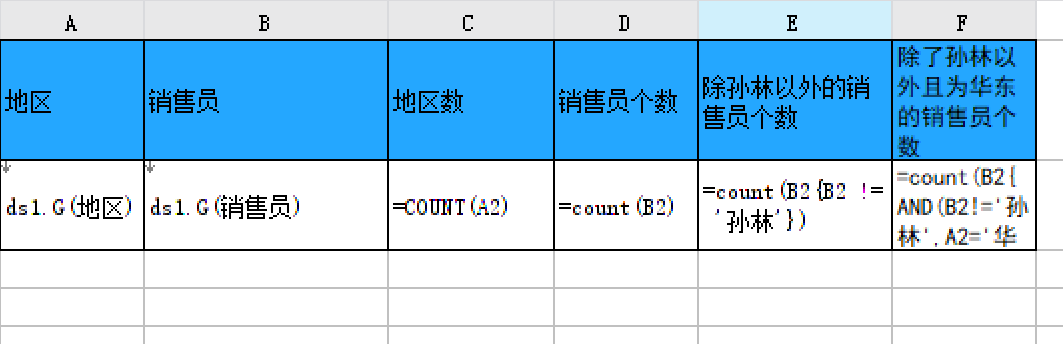
若需要进行多条件判断,可嵌套公式,例如想要计算除了「孙林」并且销售地区为「华东」的销售员个数,可以使用公式:count(B2{B2!='孙林'&&A2='华东'}) 或者 count(B2{AND(B2!='孙林',A2='华东')}),如下图所示:
公式说明:
| 公式 | 说明 |
|---|---|
| B2!='孙林'&&A2='华东' 或者 AND(B2!='孙林',A2='华东') | 同时满足不是「孙林」并且销售地区为「华东」的销售员 |
|
count(B2{B2!='孙林'&&A2='华东'}) 或者 count(B2{AND(B2!='孙林',A2='华东')}) |
同时满足不是「孙林」并且销售地区为「华东」的销售员个数 |
注1:若需要多个条件中任一条件符合即计数,可使用 OR 函数。
注2:11.0.4 版本支持使用COUNTIFS 函数。
4. 模板下载
点击下载模板:count函数使用.cpt
| 参数 | 含义 | 参数格式 |
|---|---|---|
| from | 起始值,可以省略,省略默认是 1 | 整数 |
| to | 结束值,不能省略 | 整数 |
| step | 步长,可以省略,省略默认为 1 | 整数 |
注:form,to,step 三个参数不能为空字符串,且 to 参数必须有值。
示例:
Range(1,3,1) 返回 [1,2,3]
Range(3) 返回 [1,2,3]
Range(6,-1,-2) 返回 [6,4,2,0]
2. 应用场景
Range() 函数可以用来生成数字序列,也可以通过一些转化方法生成日期序列和小数序列。
2.1 数字序列
2.1.1 Range(to)
新建模板,在任意单元格中,写入公式:=Range(3),并将其单元格属性设置为向下扩展、居中显示,预览模板后结果返回 1、2、3,效果如下图所示:
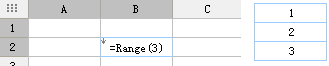
2.1.2 Range(from,to)
新建模板,在任意单元格中,写入公式:=Range(2,6),并将其单元格属性设置为向下扩展、居中显示,预览模板后结果返回 2、3、4、5、6,效果如下图所示: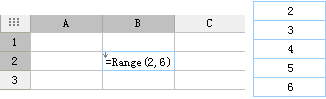
2.1.3 Range(from,to,step)
新建模板,在任意单元格中,写入公式:=Range(1,7,2),并将其单元格属性设置为向下扩展、居中显示,预览模板后结果返回 1、3、5、7,效果如下图所示:
2.2 日期序列
2.2.1 Range(from,to)
新建模板,在任意单元格中,写入公式:=Range(Date(2016,10,20),Date(2016,10,24)),并将其单元格属性设置为向下扩展、居中显示,预览模板后结果返回 2016-10-20、2016-10-21、2016-10-22、2016-10-23、2016-10-24,效果如下图所示:

注:Range 函数生成日期序列,必须使用 date 函数将数字格式或者字符串格式转化为日期格式,日期格式默认为'yyyy-MM-dd'格式,也可以在单元格属性中修改其他日期显示方式。
2.2.2 Range(from,to,step)
新建模板,在任意单元格中,写入公式:=Range(Date(2016,10,16),Date(2016,10,24),2),并将其单元格属性设置为向下扩展、居中显示,预览模板后结果返回 2016-10-16、2016-10-18、2016-10-20、2016-10-22、2016-10-24,效果如下图所示: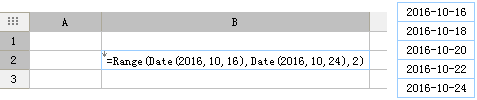
2.3 小数序列
Range 函数中 step 的步长要求为整数,若想得到小数序列,可以将 Range 中的 form,to,step 三个参数都扩大倍数使其成为一个整数,再将 Range () 后的结果缩小对应的倍数即可得到。
如想得到一个从 0 到 90,step 为 22.5 的小数序列,可先按 0 到 900,step 为 225 取序列,再将取得的序列除以10 得到期望的小数序列。
新建模板,在任意单元格中,写入公式:=Range(0,900,225)/10,将其单元格属性设置为向下扩展、居中显示,预览模板后结果返回0、22.5、45、67.5、90,效果如下图所示:

单元格显示图片(Toimage函数)
TOIMAGE函数显示单元格图片
1. 概述
1.1 版本
| 报表服务器版本 | 功能变动 |
|---|---|
| 11 | - |
| 11.0.4 | 支持 jpg、png、bmp 常用格式的图片,分别缓存为该格式下的文件,不会出现导出文件时体积暴涨的情况 |
1.2 函数作用
TOIMAGE 函数用于在报表中显示某一路径下的图片。支持 jpg、png、bmp 常用格式的图片,图片可以存储在本地磁盘,也可以存储在远程服务器,也可以为网页中图片。
1.3 函数解释
TOIMAGE(path),显示指定路径下的图片。此处默认开启了图片缓存功能以加速报表的生成.如不需要缓存,请在参数后面追加值FALSE。
| 参数 | 含义 | 参数格式 |
|---|---|---|
| path | 图片路径,不可省略 |
"F:/FineReport_10.0/webroot/logo.png" 注:斜杠必须为 / |
| 布尔 | 是否开启图片缓存功能,可省略,省略默认开启 | true 开启,false 关闭 |
| width | 图片宽度,可省略,省略默认图片原宽度 |
整数:图片宽度像素 百分比:图片宽度缩放比 |
| height | 图片高度,可省略,省略默认图片原高度 |
整数:图片高度像素 百分比:图片高度缩放比 |
示例:
TOIMAGE("D:/1.jpg")
TOIMAGE("D:/1.jpg",false)
TOIMAGE("D:/1.jpg",true,200,300)
TOIMAGE("D:/1.jpg",true,"50%","200%")
1.4 注意事项
1)使用 TOIMAGE 函数显示单元格图片的模板,在选择菜单栏「文件>输出>模板(内置数据)」时,图片不会伴随输出。
2)若使用 TOIMAGE 函数的单元格属性设置了「样式>段间距」,那么导出或打印报表时,设置的「段间距」不生效。
3)使用 TOIMAGE 函数返回的图片,「图片布局」为「默认」。可以在「单元格属性>样式>对齐>图片布局」处选择其他布局方式。
4)不支持模拟计算,模拟计算详情参见:2.4节。
5)不支持 gif 格式。
2. 应用场景
TOIMAGE 函数中可以直接输入图片路径,也可以引用存储在数据库的图片路径字段。
2.1 直接输入
图片可以存储在本地磁盘,也可以存储在远程服务器上。图片存储的位置不同,path 路径的写法不同。
| 图片存储位置 | path 路径 | 公式 |
|---|---|---|
| 本地磁盘 |
图片绝对路径,如 E:/图片/logo-fanruan.png |
TOIMAGE("E:/图片/logo-fanruan.png") |
|
报表服务器 webroot 目录下 |
省略工程所在目录的简化路径,如 help/logo-fanruan.png |
TOIMAGE("help/logo-fanruan.png") |
| 网页中图片 |
图片网络地址,如 https://www.fanruan.com/images/logo-fanruan.png |
TOIMAGE("https://www.fanruan.com/images/logo-fanruan.png") 注:显示网页中图片时推荐使用 WEBIMAGE(path) ,可以提升 Web 图片加载速度。 |
注:报表服务器 webroot 为远程服务器时,设计器必须切换到对应远程服务器工作目录下。
2.2 引用数据库中的字段
1)若图片存储在本地磁盘 E 盘,路径为:E:/图片/logo-fanruan.png,将图片路径存在数据库表中,如下图所示:

2)将字段「path」拖到报表单元格中,右侧单元格属性选择「高级」,在「显示值」位置,输入公式 TOIMAGE($$$),$$$ 表示当前单元格值,步骤如下图所示:

3)若存储在数据库的图片路径不完整,需要补全路径使图片显示。
如上述 E 盘中的图片,若在数据库中存储的路径为 :logo-fanruan.png ,需要将「显示值」的公式修改为 :TOIMAGE("E:/图片/"+$$$) 。
注:如果用户数据库服务器和报表应用服务器分开的话,图片应该存放在报表应用服务器上,而不是数据库服务器上。
1. 概述
1.1 函数作用
有时用户希望能直接在数据集中取出满足条件的行列数据,不必再将数据集字段拖拽到单元格后添加过滤条件取数,此时可以使用 value 函数。
1.2 函数解释
value 函数有多种写法,不同的参数组合对应不同的取数规则。
最简形式为:Value(设计器中的数据集名称,数据集列号)
例如:
=value("ds1",3) 取 ds1 数据集中第 3 列的数据,返回一个数组。
语法:
| 语法 | VALUE(tableData,col) | 返回tableData中列号为col的一列值。 |
|---|---|---|
| 参数1 | tableData |
必填 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 |
| 参数2 | col |
必填 列序号,整型; |
1.3 注意事项
-
value 函数参数设定有多种形式,可以直接在函数中输入,也可以引用单元格和模板参数。
例如:
value("ds1",1,2) 取 ds1 数据集中第 1 列第 2 行的数据。
value("ds1",A1,A2) 取 ds1 数据集中第 A1 单元格中值对应的列,第 A2 单元格中值对应的行的数据。
value('ds1',1,2,"牛肉干") 取 ds1 数据集中第 1 列数据,对应的第 2 列数据是 "牛肉干" 的值,返回第一列数据对应值。其中「牛肉干」可换成单元格数据。
value($p1,1,$p2) 取 p1 数据集中第 1 列第 p2 行的数据,其中 p1、p2 为模板参数,将 p1 赋值为数据集名称。
-
暂时不支持 value("数据集",1,-1) 写法,-1不生效。若您需要获取最后一行数据,可以使用类似公式VALUE('ds1',COUNT(value("ds1",3,4,"America")))替代实现。
2. 应用场景
示例数据:内置数据「CUSTOMER」
2.1 创建模板
新建一张模板,新建数据库查询 ds1:SELECT * FROM CUSTOMER,如下图所示:
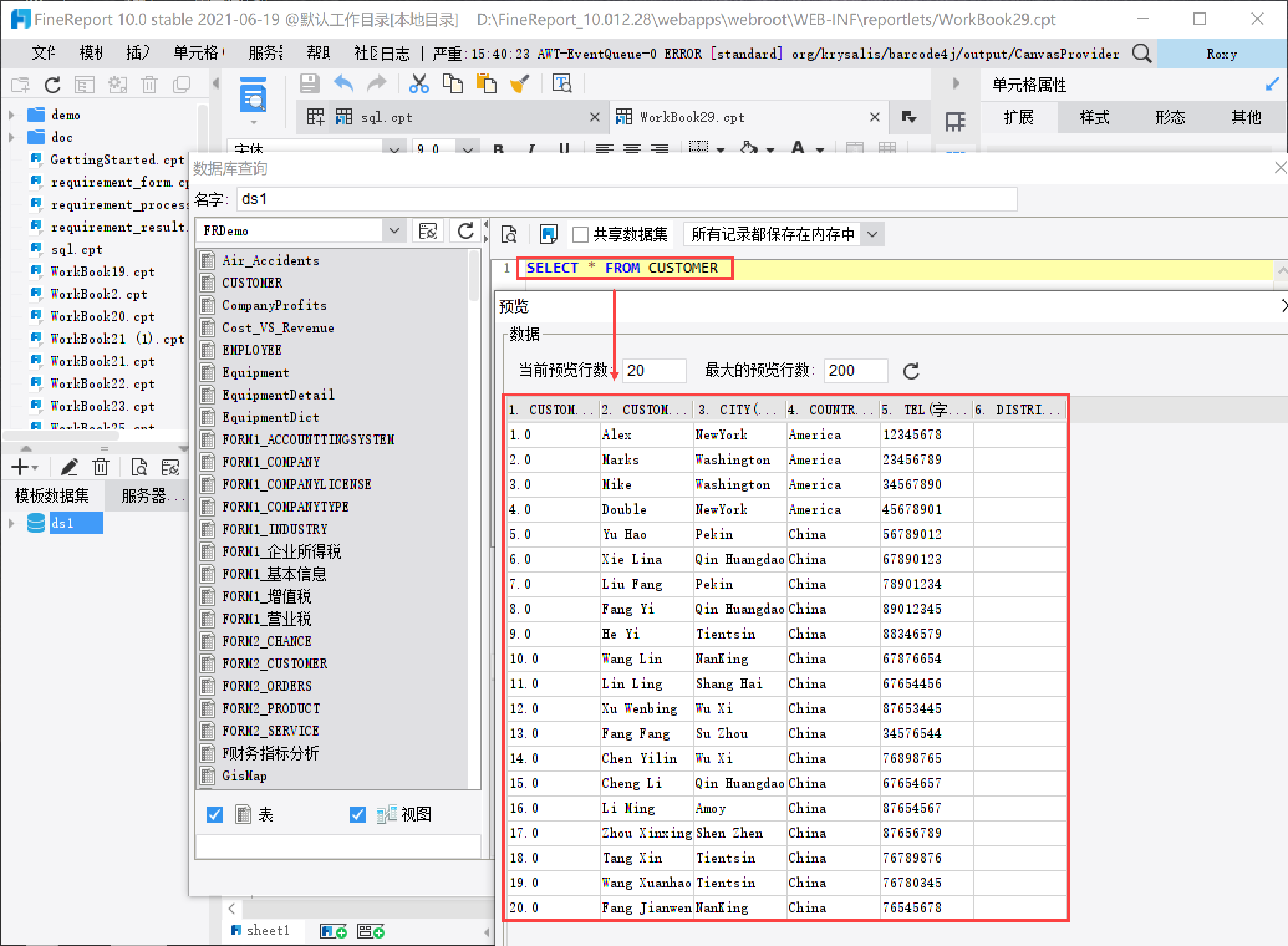
2.2 使用公式取数
分别在单元格中输入如下公式:
| 输入公式 | 返回数值 | 效果 | 公式写法 | 写法说明 |
|---|---|---|---|---|
| = value("ds1",3,2) | 将返回 customer 表中的第三列第二行的数据 Washington |  |
Value(tabledata,col,row) | 返回 TableData 中列号为 col,行号为 row 的值。 |
|
=value("ds1",3) 注:由于返回的是数组,因此设置扩展属性为从上向下扩展。 |
将返回数据表中的第三列数据 | 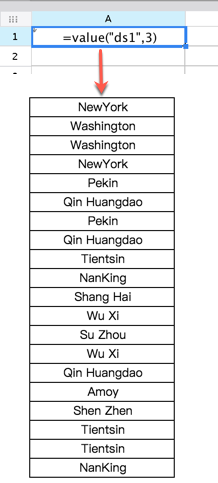 |
Value(tableData,col) | 返回 TableData 中列号为 col 的一列值 |
|
=value("ds1",3,4,"America") 注:由于返回的是数组,因此设置扩展属性为从上向下扩展。 |
返回数据表中第三列元素,且该列元素对应的第四列元素的值是 America 的所有数据 |  |
Value(tableData,targetCol,orgCol,element) | 返回 TableData 中第 targetCol 列中的元素,这些列元素对应的第 orgCol 列的值为 element。 |
| =value("ds1",3,4,"America",1) | 返回数据表中第三列元素,且该列元素对应的第四列元素的值是 America 的所有数据中第一个值 |  |
Value(tableData,targetCol,orgCol,element,idx) | 返回 Value(tableData,targetCol, orgCol, element)数组的第 idx 个值 |
数据集函数概述
1. 概述
1.1 应用场景
将数据集中的数据列直接拖拽到单元格中使用时,如果想要「条件显示」某些数据列的值,那么可以使用数据集函数。
1.2 注意事项
1)参数面板中不支持使用。
2)不支持模拟计算,模拟计算详情参见:2.4节。
3)决策报表填报事件不支持使用数据集函数。
2. tablename.select
1)概述
| 语法 | tablename.select(colname,筛选条件1&&筛选条件2&&......) |
筛选出数据集某列中符合条件的数据,返回结果是一个数组,相同数据不会合并 注:当仅返回一条数据时,数据类型是「字符串」而不是数组。 |
|---|---|---|
| 参数1 | tablename | 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 |
| 参数2 | colname | 表示列名,不区分大小写。 |
2)注意事项
-
筛选条件中的判断既可以使用单等号,也可以使用双等号;
-
字符串也同时可以使用单引号或者是双引号,对结果均没有影响;
-
tablename.select() 与 sql() 的区别主要在于 tablename.select() 是从数据集取数,sql() 是从数据库取数,不需要先定义一个数据集。详情参见 SQL 函数
-
在公式中,以 0 开头的字符串在匹配判断时,例如:ds1.select(colname,ID="003") 结果会返回对应 ID 为 0、03、003…… 的结果。若只希望返回 003 ,可以使用 EXACT 来做匹配判断。例如:ds1.select(colname,exact(ID,"003"))
-
如果想要进行模糊查询,可通过与 Find 函数 嵌套实现,例如公式:ds1.select(产品名称,FIND("苹果",产品名称)!=0),如下图所示:
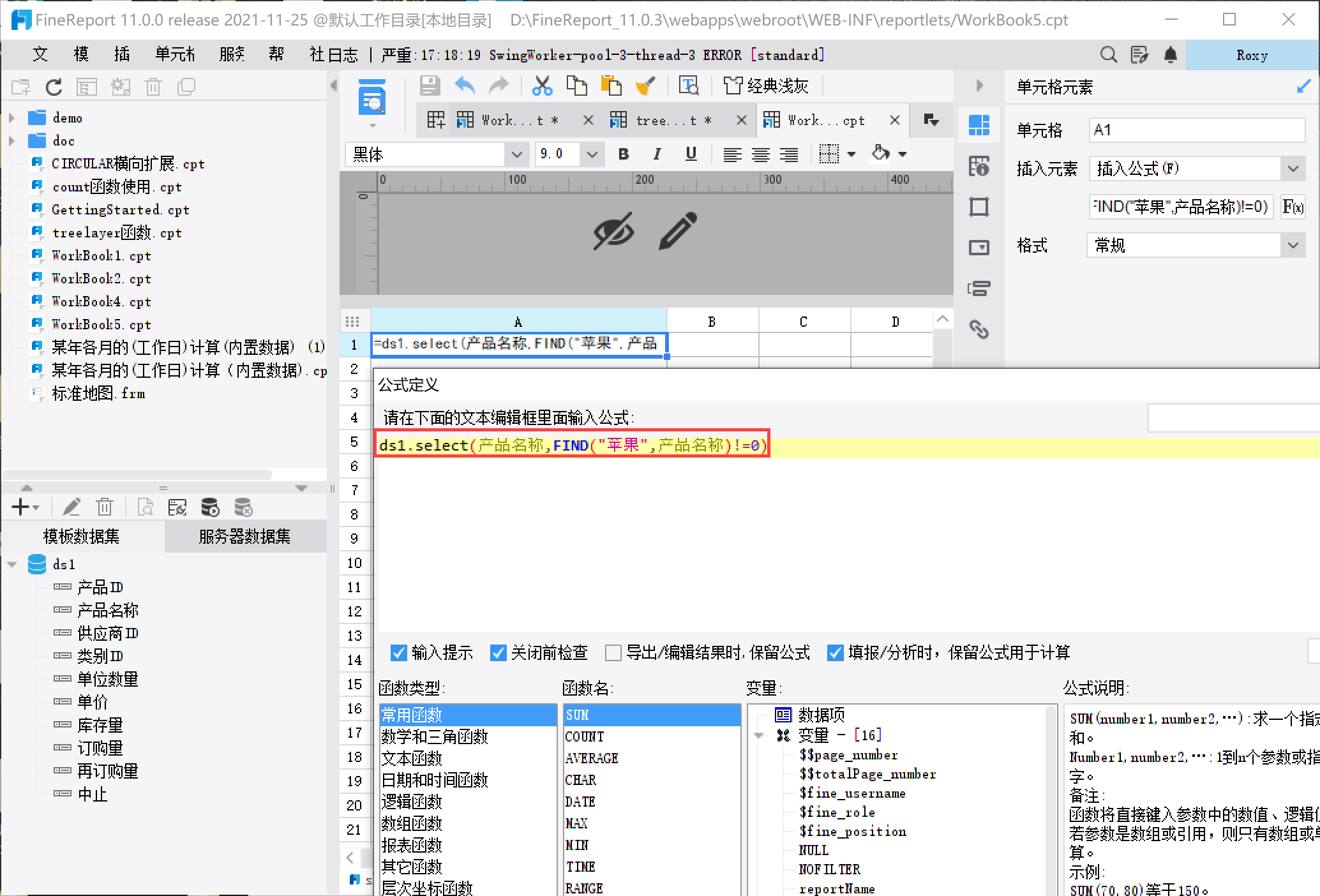
3)示例
例如数据集 ds1 取出内置 FRDemo 数据库中的「S产品」表,分别在单元格中输入以下公式:

| 公式 | 结果 |
|---|---|
| 在 A2 单元格中输入=ds1.select(产品名称) |
返回数据集 ds1 产品名称列中的所有产品名称。
|
| 在 B2 单元格中输入=ds1.select(产品名称,库存量>20&&订购量 > 30) |
返回数据集 ds1 库存量大于 20 且订购量大于 30 的产品。
|
| 在 C2 单元格中输入=ds1.select(产品名称,供应商="1"||库存量>30) |
返回数据集 ds1 供应商为1或者库存量大于 30 的产品。
|



3. tablename.group
1)概述
| 语法 | tablename.group(colname,筛选条件 1 && 筛选条件 2,升降序) | 筛选出数据集某列中符合条件的数据,若相邻数据相同则进行合并,还可以按照该列进行升降序排列。 |
|---|---|---|
| 参数1 | tablename | 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 |
| 参数2 | colname | 表示列名,不区分大小写。 |
| 参数3 | 升降序 |
为布尔值,true 表示升序,false 表示降序。 注:若使用升降序参数,那么必须写筛选条件参数,若没有筛选条件,可以用 true 或者空格代替:例如=ds1.group(销售员,true,false)或者=ds1.group(销售员, ,false) |
2)示例
如数据集 ds1 取出内置 FRDemo 数据库中的「销量」表:
| 公式 | 说明 |
|---|---|
| 在单元格中输入=ds1.group(销售员) | 返回数据集 ds1 销售员列中的值,并且相邻数据若相同会进行合并。 |
| 在单元格中输入=ds1.group(销售员,地区 = "华东"&&销量 > 200) |
返回数据集 ds1 华东地区销售总额超过 200 的销售员,并且相邻数据若相同会进行合并。
|
| 在单元格中输入=ds1.group(销售员,true,false)或=ds1.group(销售员,,false) |
返回数据集 ds1 销售员列中的值,并且其中只要数据相同就会进行合并,结果为降序排列,中间的参数为过滤条件,若没有条件,可以用空替代或者使用 true 。
|
| 在单元格中输入=ds1.group(销售员,地区=="华东") |
返回数据集 ds1 华东地区的销售员,并且相邻数据若相同会进行合并。
|
| 在单元格中输入=ds1.group(销售员,地区=="华东",true) | 返回数据集 ds1 华东地区的销售员,并且会合并所有相同项,结果为升序排列。 |


4. tablename.select(#数字)
1)概述
| 语法 | tablename.select(#数字) | 返回数据集中的行号或者对应列数据 |
|---|---|---|
| 参数1 | tablename | 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 |
| 参数2 | 数字 |
表示列号。 如果tablename.select(#0)则输出数据表行号数组(数据条数) tablename.select(#1)则输出数据库表中第一列的数组数据 |
2)注意事项
-
填报场景下 ds1.select(#0) 这个公式如果联动计算有异常,需要检查父子格关系。例如出现下图所示的计算结果时:

-
remoteEvaluate(String) 方法不支持 tablename.select 函数。
3)示例
例如数据集 ds1 取出内置 FRDemo 数据库中的「销量」表:
| 公式 | 结果 |
|---|---|
| 在单元格中输入=ds1.select(#0) |
返回数据集中的行号
|
| 在单元格中输入=ds1.select(#1) |
返回数据集中对应列数据
|


5. tablename.value(row,col/colname)
1)概述
| 语法 | tablename.value(row,col/colname) | 获取数据集 ds1 中某行某列的值。 |
|---|---|---|
| 参数1 | tablename | 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 |
| 参数2 | row |
表示行号 |
| 参数3 | col/colname | 表示列号或者列名 |
2)注意事项
-
报表的图表标题不支持该函数。
-
决策报表里的图表块不支持该函数。
-
JavaScript 中不支持该函数。
3)示例
例如数据集 ds1 取出内置 FRDemo 数据库中的「销量」表:
| 公式 | 说明 |
|---|---|
| 在单元格中输入=ds1.value(3,2) | 返回数据集 ds1 中第 3 行第 2 列的值 |
| 在单元格中输入=ds1.value(3,"销售员") | 返回数据集 ds1 中第 3 行销售员列的值 |
6. 应用
6.1 根据不同条件选择使用哪个字段
在单元格中输入如下公式:
=if(条件,ds1.group(customerid),ds2.group(customerid))
并设置其扩展属性为从上到下。
公式说明:
| 公式 | 说明 |
|---|---|
| =if(条件,ds1.group(customerid),ds2.group(customerid)) |
条件为真,单元格使用数据集 ds1 中的 customerid 列,否则使用 ds2 中的 customerid 列 。
|
6.2 对数据集函数返回的数据再进行运算
在单元格输入公式=sum(ds1.select(销量)),返回数据集 ds1 销量列的总和。
sum 求和公式也可以换用其他如 count、max 等。
7. 注意事项
7.1 数据集函数返回的数据进行扩展
直接将数据列拖拽到单元格时会自动从上到下扩展。但是使用数据集函数获得数据为一个数组,是显示在一个单元格中的,需要另外给单元格设置扩展属性,数据才会进行扩展。
例如在单元格输入公式=ds1.group(销售员,地区=="华东",true),设置扩展房方向为「纵向」,如下图所示:

预览报表如下图所示:

将日期型转化为中文形式
1. 描述
因政府、事业单位的正式文件中的落款日期都是中文的。
如:在 FineReport 中制作填报模板,使用了日期控件,希望在做填报时,将当前日期控件中选择的日期值(FR 中默认是yyyy-MM-dd的日期格式),能够以中文的方式输出显示,然后再入库,但入库的数据还是默认的数值型的 yyyy-MM-dd 的日期格式。
实现效果如下图:

2. 思路
使用NUMTO()函数,通过字符转化方式,将其转化为中文输出即可。
NUMTO(number,bool):返回 number 的中文表示。
注:其中 bool 用于选择中文表示的方式,当没有 bool 时,采用默认方式(false)显示。
-
示例:NUMTO(2345,true)返回值为二三四五
-
示例:NUMTO(2345,false)返回值为二千三百四十五
-
示例:NUMTO(2345)返回值为二千三百四十五
3. 示例
3.1 控件设置
新建一张普通报表,右击任意单元格,选择控件设置,选择控件为日期控件,格式为 yyyy-MM-dd。如下:
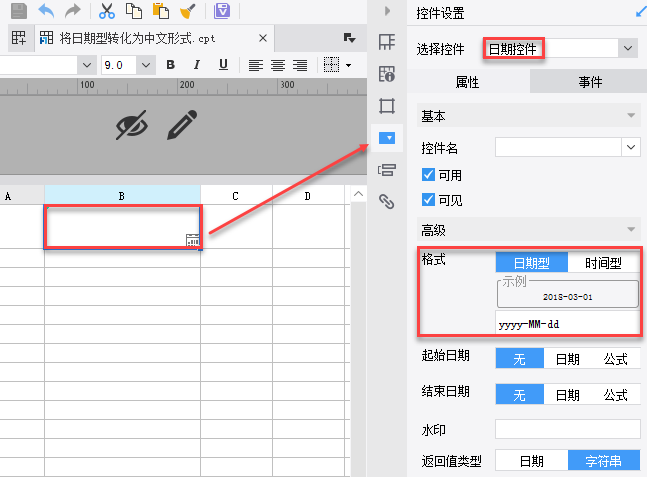
3.2 属性设置
再右击此单元格,选择形态>公式形态,输入公式:REPLACE(NUMTO(YEAR($$$), true), "零", "〇") + "年" + NUMTO(MONTH($$$), false) + "月" + NUMTO(DAY($$$), false) + "日"
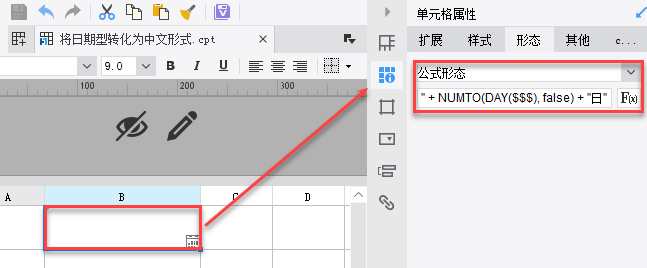
注:REPLACE(NUMTO(YEAR($$$),true),"零","〇"),表示将其中输出的中文的零替换为特殊字符 〇。
注:REPLACE 函数的具体使用,可参见文本函数。
4. 保存预览
保存模板后,选择填报预览。
在日期控件中选择好日期后,点击其他处,显示效果如上图所示。
注:有些日期的中文形式还想含有星期,公式如下所示。
示例:
【REPLACE(NUMTO(YEAR(today()),true),"零","〇")+"年"+format(today(),'MMMMM')+NUMTO(DAY(today()),false)+"日"+format(today(),'EEEEE')】返回值为【二O一八年二月十八日星期天】
5. 模板下载
点击下载模板:将日期型转化为中文形式.cpt
字符串与数组相加1. 问题描述
字符串与数组的相加有两种方式,一是直接使用+号,另外一种是使用字符串连接函数 concatenate,那么这两个有区别吗?
2. 使用+号连接字符串及数组
字符串会和每个数组元素分别进行相加。
如公式:="a"+[1,2,3]+"b",其结果是:a1b,a2b,a3b。
3. 使用 concatenate 函数连接字符串及数组
数组会被作为字符串与其他字符串串联。
如公式:=concatenate("a",[1,2,3],"b"),其结果是 a1,2,3b。
SQL函数
1. 概述
1.1 函数作用
数据集函数 能够从数据集中直接进行条件取数,但是有的时候用户希望某个单元格能够直接获取到数据库中的某个值,而不是先要定义一个数据集后,再去取数据。
这时就可以用 SQL 函数。
1.2 函数解释
| 语法 | SQL(connectionName,sql,columnIndex,rowIndex) | 返回的数据是从 connectionName 数据库中获取的 SQL 语句的表中的第 columnIndex 列第 rowIndex 行所对应的元素。 |
|---|---|---|
| 参数1 | connectionName | 数据连接名字,字符串形式,需要用引号如"FRDemo"; |
| 参数2 | sql | SQL 语句或者数据库存储过程,字符串形式,传参数、条件等可以在此拼接实现; |
| 参数3 | columnIndex | 列序号,整型; |
| 参数4 | rowIndex | 行序号,整型。 |
注:行序号可以省略,这样返回值为数据列。
1.3 注意事项
仅支持查询 sql 语句。
2. 取数据库中不带参数的指定内容
示例数据:内置数据库 FRDemo 中的 STSCORE 数据表。
从内置数据库「FRDemo」里的 STSCORE 表取第三行第三列数据值。
从表 STSCORE 中,可看到第 3 行第 3 列的值为 Alex,如下图所示:
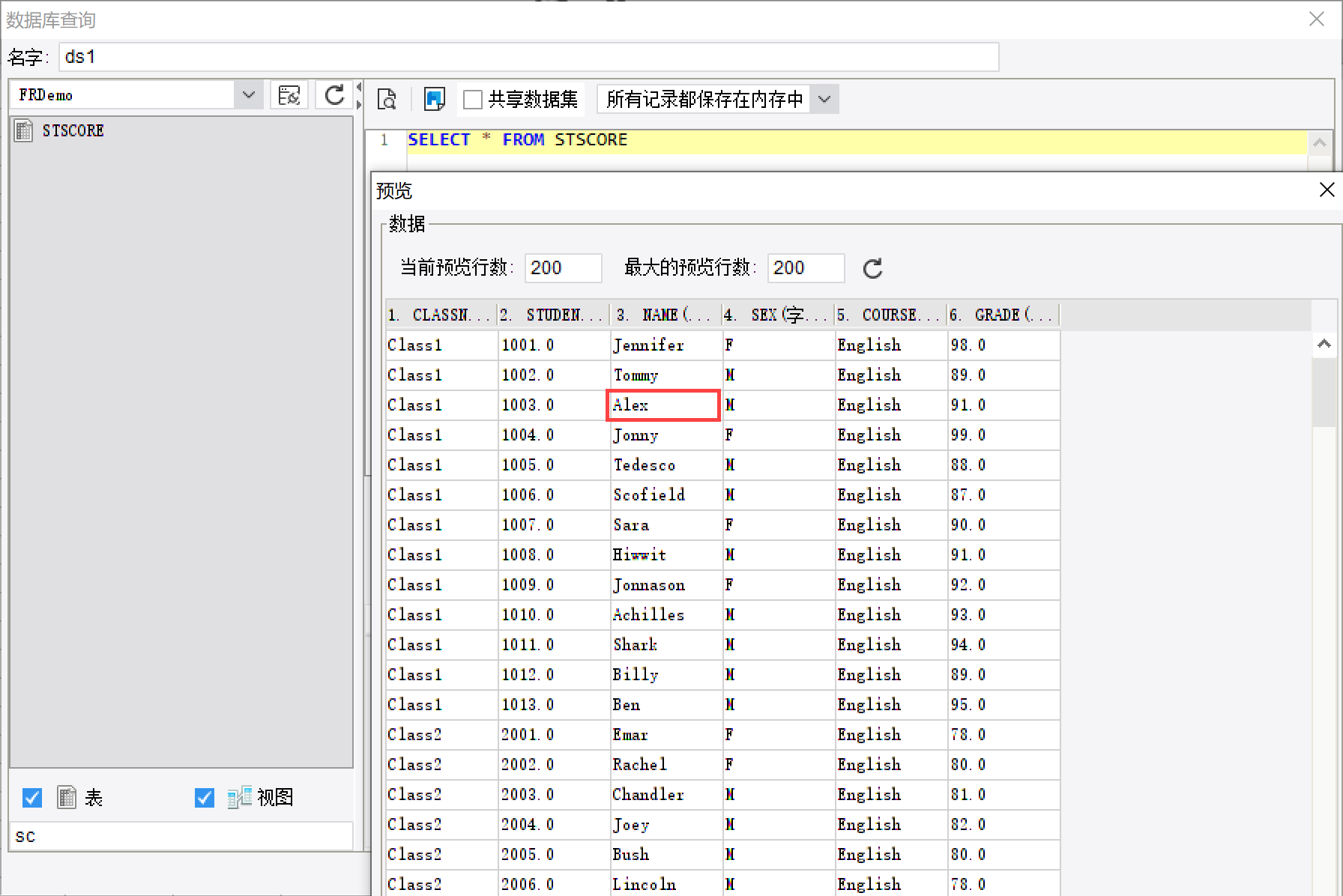
现在若要直接在报表的单元格中显示数据值:Alex,而不是通过先定义一个数据集后,再去取数据的方式,使用 sql() 公式,此时只需在单元格中输入:=sql("FRDemo","SELECT * FROM STSCORE",3,3)即可,预览就可看到 Alex 值,如下图所示:

3. 取数据库中带有参数的指定内容
示例数据:内置数据库 FRDemo 中的 STSCORE 数据表。
3.1 SQL 参数为普通参数
需要取出班级为 Class1 的第 3 列所有值。
在单元格中输入:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = 'Class1' ",3),显示效果(班级为 Class1 的第 3 列所有值),如下图所示:

公式说明:
| 公式 | 说明 |
|---|---|
| "FRDemo" | 数据连接名 |
| "SELECT * FROM STSCORE where CLASSNO = 'Class1' " | SQL 语句;查询 CLASSNO 为 Class1 的数据 |
| 3 | 列序号,第三列的数据 |
若需要显示某个具体值,如显示 Jonny (即班级为 Class1 的第 3 列第 4 行的值),写法如下:
=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = 'Class1' ",3,4)
3.2 SQL 参数为变量
若参数值为变量如为报表参数或者是某个单元格,则写法如下:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$class+"' ",3,4) 或=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+A1+"' ",3,4)
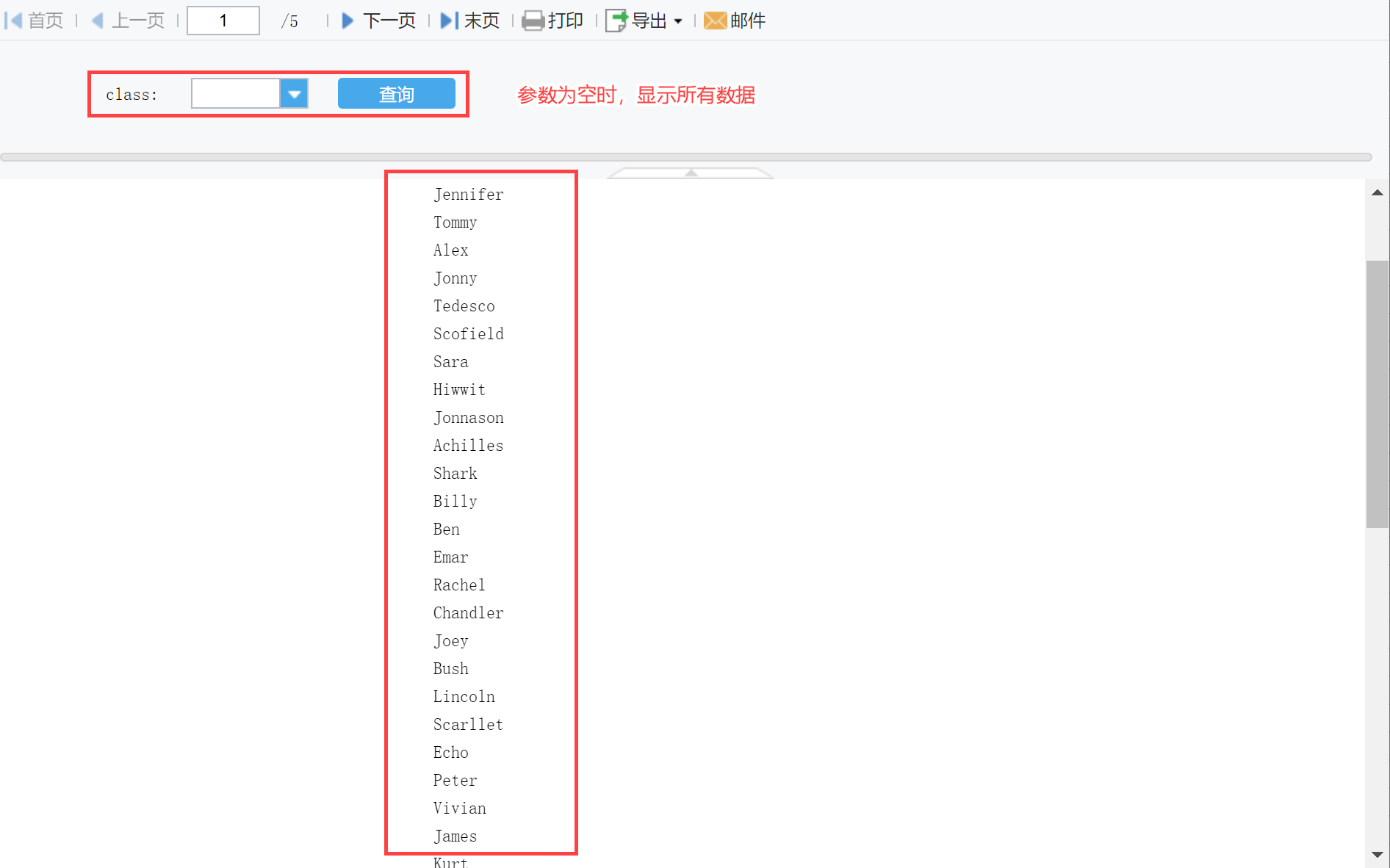
例如希望过滤控件选择不同班级,显示不同班级下所有的同学的名字。
首先设置模板参数「class」,然后在单元格中输入公式:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$class+"' ",3),如下图所示:

显示效果如下图所示:

如果传递的参数是获取当前单元格的值,即用 $$$ 作为参数时,字符串类型同样需要拼接单引号,例如:
=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$$$+"' ",3,4)
注1:如果参数或者单元格值有多个,那么 SQL 函数的写法如下:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO in ('"+$class+"') and COURSE in ('"+$COURSE+"') ",3,4)
注2:class 参数返回值的分隔符需为',',具体请查看下拉复选框参数联动。
3.3 SQL 参数为变量且需要拼接
在 SQL 中还可以使用 IF 函数进行判断并拼接模板参数,例如希望实现当参数 class 为空时,选择全部学生姓名,可输入公式:
=sql("FRDemo","SELECT * FROM STSCORE where 1=1 "+if(len(class)== 0,"","and CLASSNO = '"+class+"'"),3)
公式说明:
| 公式 | 说明 |
|---|---|
| "SELECT * FROM STSCORE where 1=1 " | 将 SQL 语句两边加上引号作为字符串 |
| +if(len(class)== 0,"","and CLASSNO = '"+class+"'" |
这里的+是指字符串拼接符号 将前面的 SQL 语句通过+进行拼接 当参数「class」为空,查询语句相当于:SELECT * FROM STSCORE 当参数「class」不为空时,查询语句相当于:SELECT * FROM STSCORE WHERE 1=1 and CLASSNO ='"+$class+"' |
| sql("FRDemo","SELECT * FROM STSCORE where 1=1 "+if(len(class)== 0,"","and CLASSNO = '"+class+"'"),3) |
当参数「class」为空,相当于:sql("FRDemo","SELECT * FROM STSCORE",3) 当参数「class」不为空时,查询语句相当于:sql("FRDemo","SELECT * FROM STSCORE WHERE 1=1 and CLASSNO ='"+$class+"'",3) |
如果在 SQL 中参数为模糊查询时,可使用如下公式:
=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO like '%"+$class+"%' ",3,4)









1. 概述
1.1 问题描述
当需要判断条件多的时候,使用 IF 函数 可能会觉得用要对每种情况都进行判断,比较麻烦,那么可以使用 switch 函数与NVL函数结合进行多条件赋值。
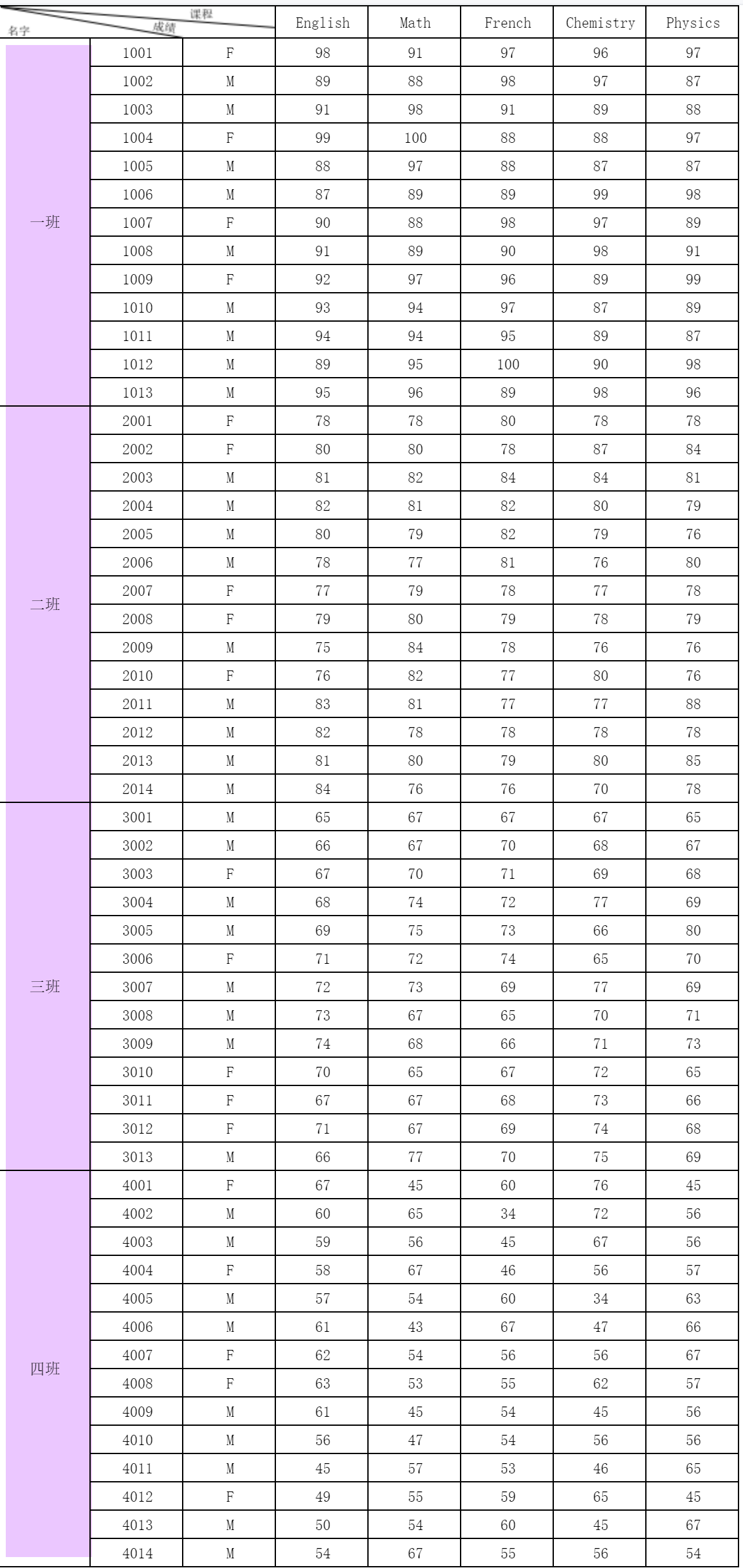
例如希望对班级进行设置:当前值是 Class1 则显示一班,如果是 Class2,则显示二班,如果是 Class3,则显示三班,否则则显示四班,如下图所示:
1.2 实现思路
2. 操作步骤
3.1 报表设计
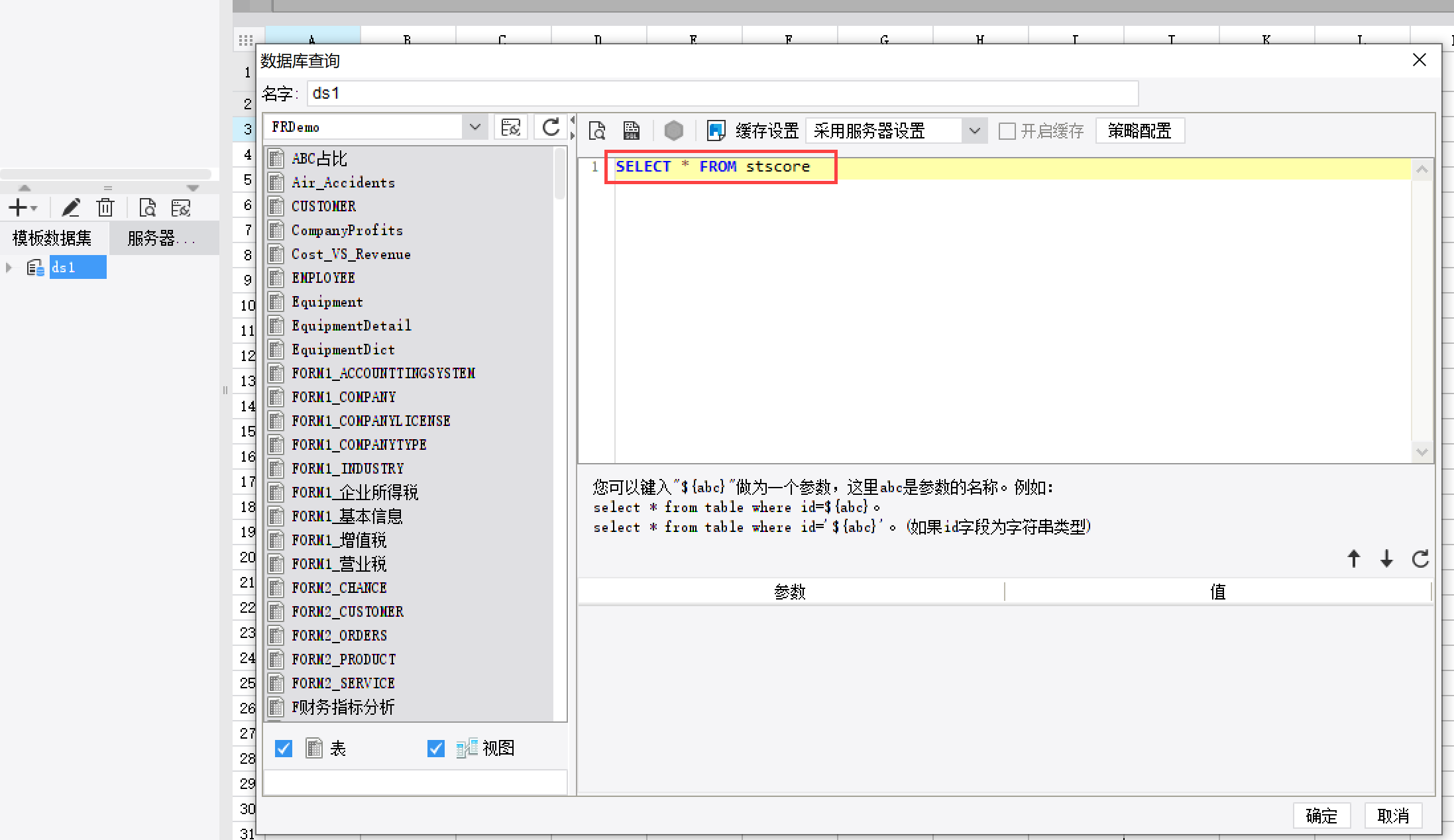
3.1.1 数据准备
新建数据查询 ds1,数据查询语句如下:SELECT * FROM stscore,如下图所示:
3.1.2 模板设计
1)设置模板样式,如下图所示:
注:插入斜线可参见 插入 2.7 节。
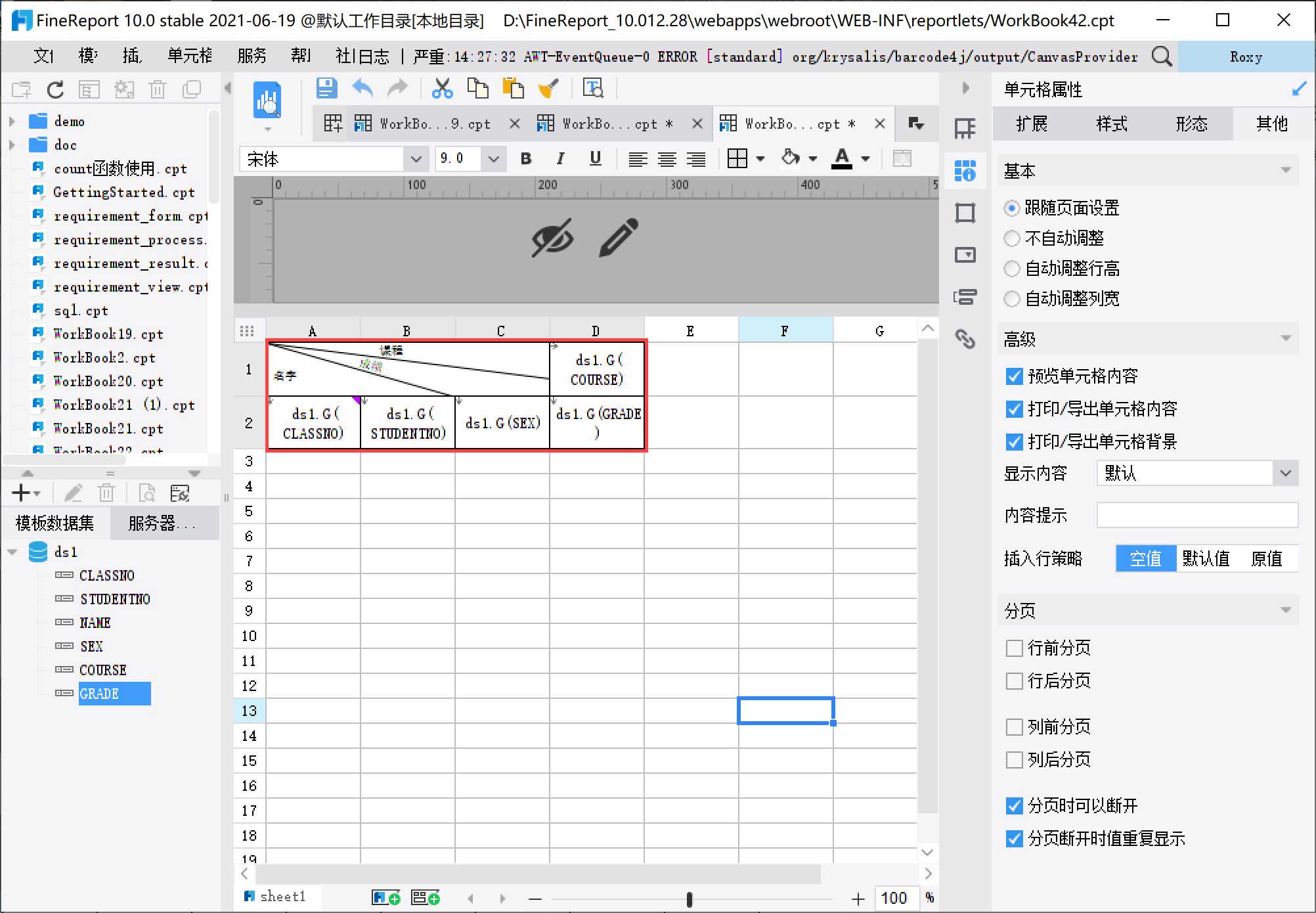
2)设置公式
单击 A2 单元格,右键单击「单元格元素>插入数据列>高级」,或者双击单元格,点击「高级」,在
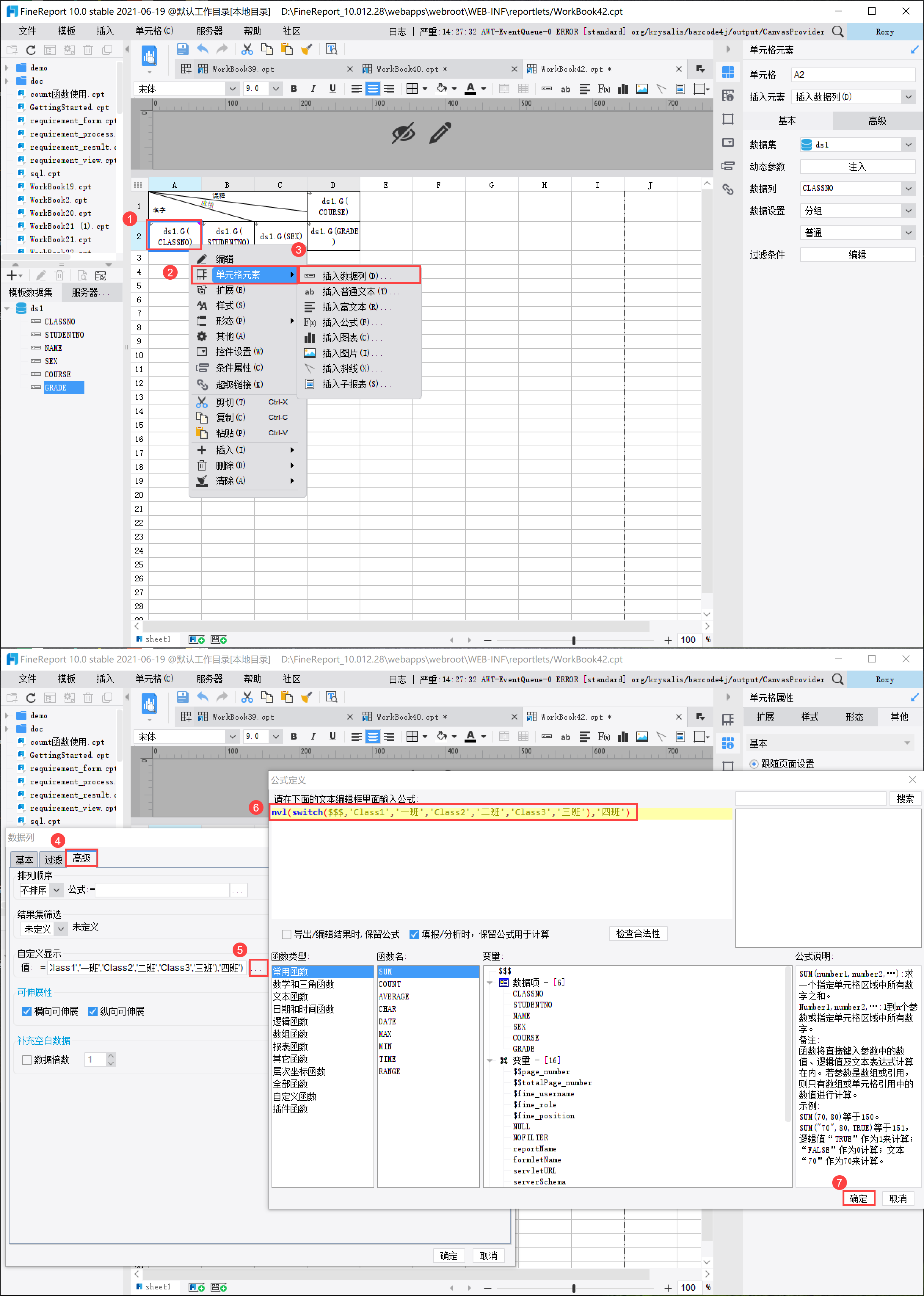
公式说明:
| 公式 | 说明 |
|---|---|
| switch($$$,'Class1','一班','Class2','二班','Class3','三班') | 如果数据为 Class1,则赋值为一班,Class2 则赋值为二班,Class 三则赋值为三班 |
| nvl(switch($$$,'Class1','一班','Class2','二班','Class3','三班'),'四班') | 返回第一个不是空的字段,即数据如果不是一班、二班或者三班,则返回「四班」 |
3.2 效果查看
1)PC端
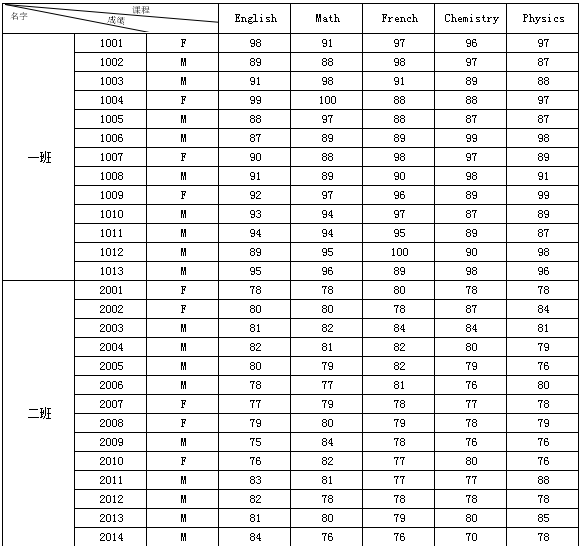
保存模板,点击分页预览,如下图所示:
注:若希望不分页展示,可以选择「数据分析预览」。
2)移动端
NVL函数
1. 函数用法
NVL 函数的使用方法:NVL(value1,value2,value3,...):在所有参数中返回第一个不是 null 的值。
注:6.5 之前的版本 NVL 只支持 2 个参数,现在升级到支持多个参数。
下面以填报的示例来说明 NVL 多参数的用法。
2. 需求
填报应用中,可能会遇到一组单元格中,只需将其中不为空的值保存至数据库的某个字段,如下图所示,对于语文成绩级别这个字段,可能有四个值,入库的时候只保存选择的级别。
3. 示例
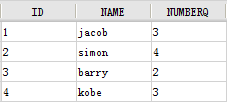
3.1 创建数据
在数据库中新建一个表,表名为 C,新建如下数据:
然后,添加其报表数据集 ds1,SQL 语句为:select * from C
3.2 表样设计
如下图所示,拖动字段到对应单元格并做相应合并:

3.3 控件设置
设置 B5、C5、E5、E6、E7、E8 为文本类型控件即可。

3.4 条件属性设置
对 E5 单元格,设置条件属性:不等于 4 时,公式为$$$!=4,赋新值为空,如下:
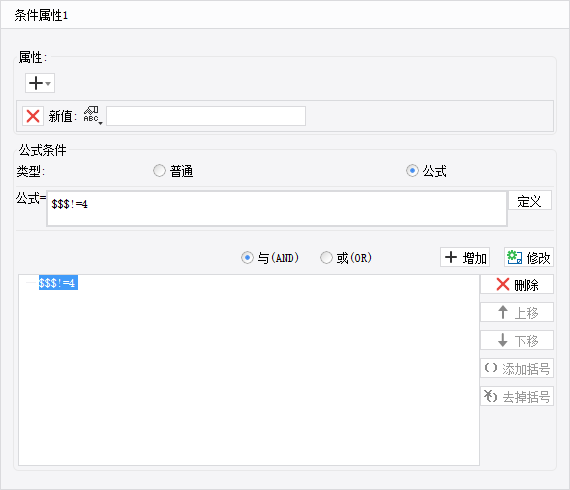
对 E6 单元格:设置为不等于 3 时,公式为$$$!=3,赋新值为空;
对 E7 单元格:设置为不等于 2 时,公式为$$$!=2,赋新值为空;
对 E8 单元格:设置为不等于 1 时,公式为$$$!=1,赋新值为空。
3.5 其他属性设置
为了保证“优秀”等不设置控件的单元格在添加记录时能默认添加,可设置单元格属性表-其他属性>插入行策略>原值,如下图:

3.6 报表填报属性设置
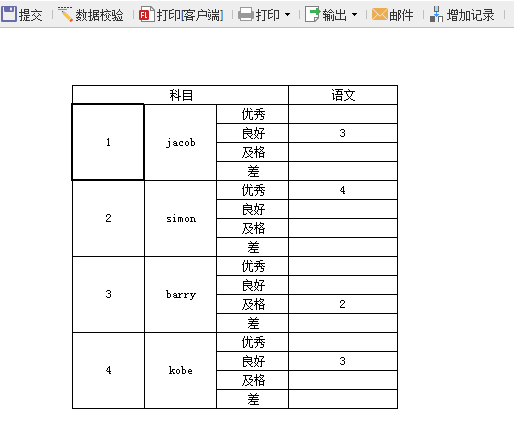
在 NUMBERQ 的值中,输入=NVL(E5,E6,E7,E8),取出第一个不为空的值进行填报,如下:

3.7 保存与预览模板
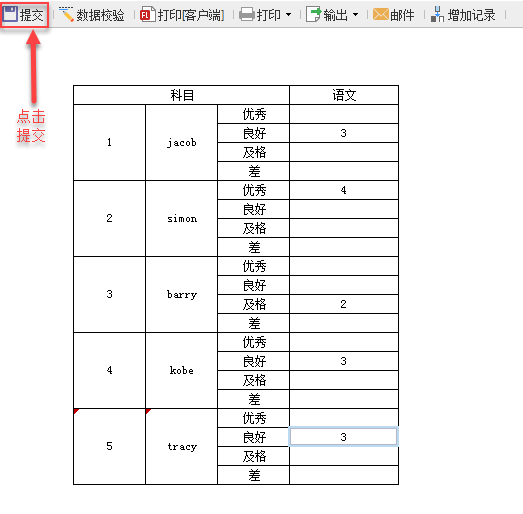
在设计器中,点击填报预览,效果:
点击增加记录后,点击提交,如下: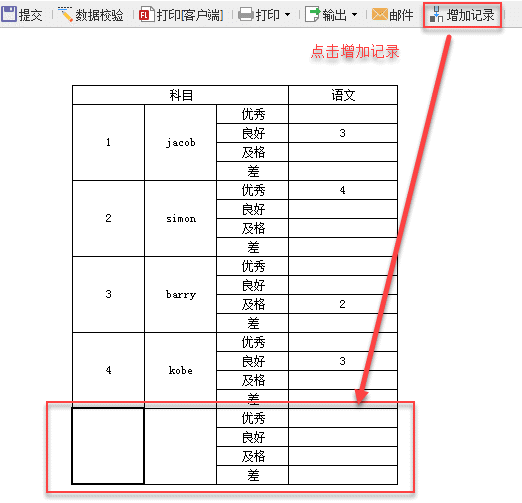
提交成功时,效果如下: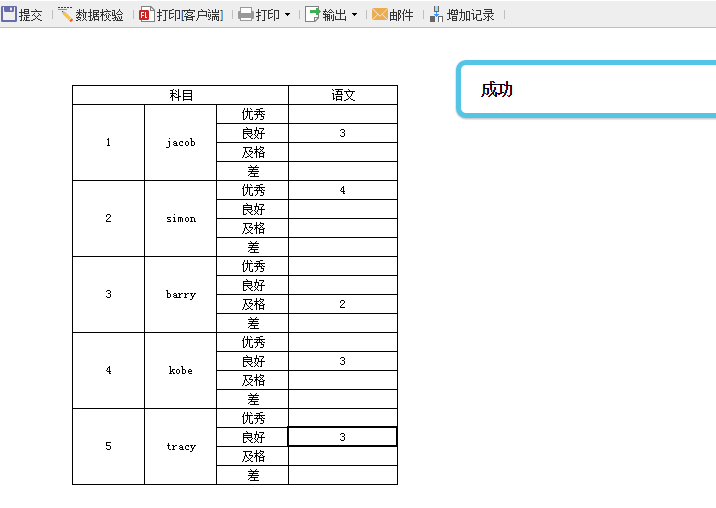
刷新页面,可见提交成功,提交值就是第一个不为空的值 3,如下: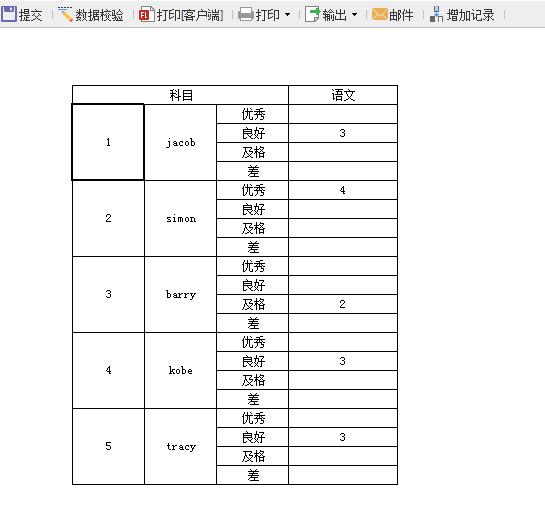
4. 模板下载
点击下载模板:NVL函数.cpt
Let函数
1. 函数作用
报表中,若使用到复杂的FR脚本表达式,如:=if (很长很长的公式 > 0,执行语句 1(很长很长的公式),执行语句 2(很长很长的公式)),首先想到的是:将很长很长的公式先放在一个单元格(如:A1)中,然后在另一个单元格中,输入=if(a1>0, 执行语句1(a1), 执行语句2(a1))。对于这样的很长公式,一般公式中还会有部分内容是一些其他的简单运算,若再使用单元格去求算一下,最终求算最终结果时就得引用多个单元格。这样的赋值方式,不但多占用空间内存使得重复计算,其性能往往也不是很好。据此 FR 已增加 LET 公式,可将其很长的公式直接赋值,且可直接使用此公式求解最终结果(复杂的脚本表达式),还可提高其性能。
2. 使用说明
2.1 LET()函数说明
LET(变量名,变量值,变量名,变量值,...,表达式):局部变量赋值函数,参数的个数 N 必须为奇数, 最后一个是表达式,前面是 N-1(偶数)为局部变量赋值对。
-
变量名:必须是合法的变量名,以字母开头,可包括字母,数字和下划线。
-
表达式:根据其前面的 N-1 个参数赋值后,需计算的结果表达式,且这些变量赋值只在这个表达式内部有效。
示例:
LET(a, 5,b, 6, a+b)等于 11。
2.2 示例
下面根据如上所遇的情况示例介绍,您可根据实际情况,参照示例使用此公式。
1)一个很长的公式为((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1),若将其赋给 a,需计算 IF(a>1000,(a+200)/a,(a-200)*a)的结果表达式。
2)通常的做法:在任意单元格(如:A1)中,输入((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1),然后在另一个单元格(如:B1)中,输入=IF(A1>1000,(A1+200)/A1,(A1-200)*A1)。
3)而计算时是将 A1 中的值,对应带入其结果表达式中的。如这边带入的话就是计算=IF((((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))>1000,((((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))+200)/(((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1)),((((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))-200)*(((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1)))
不仅多占用单元格且使得表达式重复计算,其性能往往也不是很好。
4)LET 公式的写法:只需在单元格中直接赋值和写入结果表达式。在一个单元格中,直接输入=LET(a, ((10 + 20 + 30) * MAX(10, 20, 30) + DATEDIF("2001/2/28", "2004/3/20", "D")) * COS(0.5) / ROUND(2.15, 1), IF(a> 1000, (a+ 200) / a, (a - 200) * a))即可执行结果表达式,从而得出最终结果。
2.3 总结
对比可看出,使用 LET 公式明显比通常的做法来得简单,且公式中若再有其他简单运算,如:最大值、平均值等等,也可不必再次占用其他单元格然后再引用此类单元格,这边可直接一步到位求算结果(亦可在 LET 中直接写一些常用的计算公式),这样也大大地提高了性能。
Round函数
1. 概述
1.1 应用场景
在制作报表时,某数据列如收入金额是数字类型,其中数据包含小数,且小数位数不超过 2 位,对该列进行求和(使用公式 sum)等处理时,会发现最终的结果如:123456.409999996,即小数位数超过 2 位。
此时您可能会有疑问,为什么小数位数不是 2 位?若您的报表对有效位数比较敏感,如金额汇总,总金额最多精确到分,即小数位数最多 2 位,该怎么办?
1.2 功能简介
此情况时,可使用 round() 函数对计算后的结果按指定位数四舍五入来解决。
2. 示例
2.1 函数说明
1)概述
| 语法 | ROUND(number,num_digits, boolean) |
返回某个数字按指定位数舍入后的数字。 |
|---|---|---|
| 参数1 | number |
需要进行舍入的数字
|
| 参数2 | num_digits |
指定的位数,按此位数进行舍入。 如果 num_digits 大于 0,则舍入到指定的小数位。 如果 num_digits 等于 0,则舍入到最接近的整数。 如果 num_digits 小于 0,则在小数点左侧进行舍入。 |
| 参数3 | boolean |
因浮点数存在精度计算丢失问题,导致计算结果里可能带上 9999、0000 这些,因此加入第三个参数来控制是否需要去除 9999、0000。 false 表示需要过滤 9999、0000 这些数据;true 表示保留,参数为空则默认为 false。
|
2)注意事项
-
2020-07-08 及之后版本的 JAR 包才会有第三个参数。
-
2020-07-08 及之后版本的 JAR 包 number 参数支持字符串。
3)示例
| 公式 | 结果 |
|---|---|
| ROUND(2.15, 1) | 2.2 |
| ROUND(2.149, 1) | 2.1 |
| ROUND(-1.475, 2) | -1.48 |
| ROUND(21.5, -1) | 20 |
| ROUND(1.99999999, 8) | 2 |
| ROUND(1.99999999, 8, true) | 1.99999999 |
2.2 操作步骤
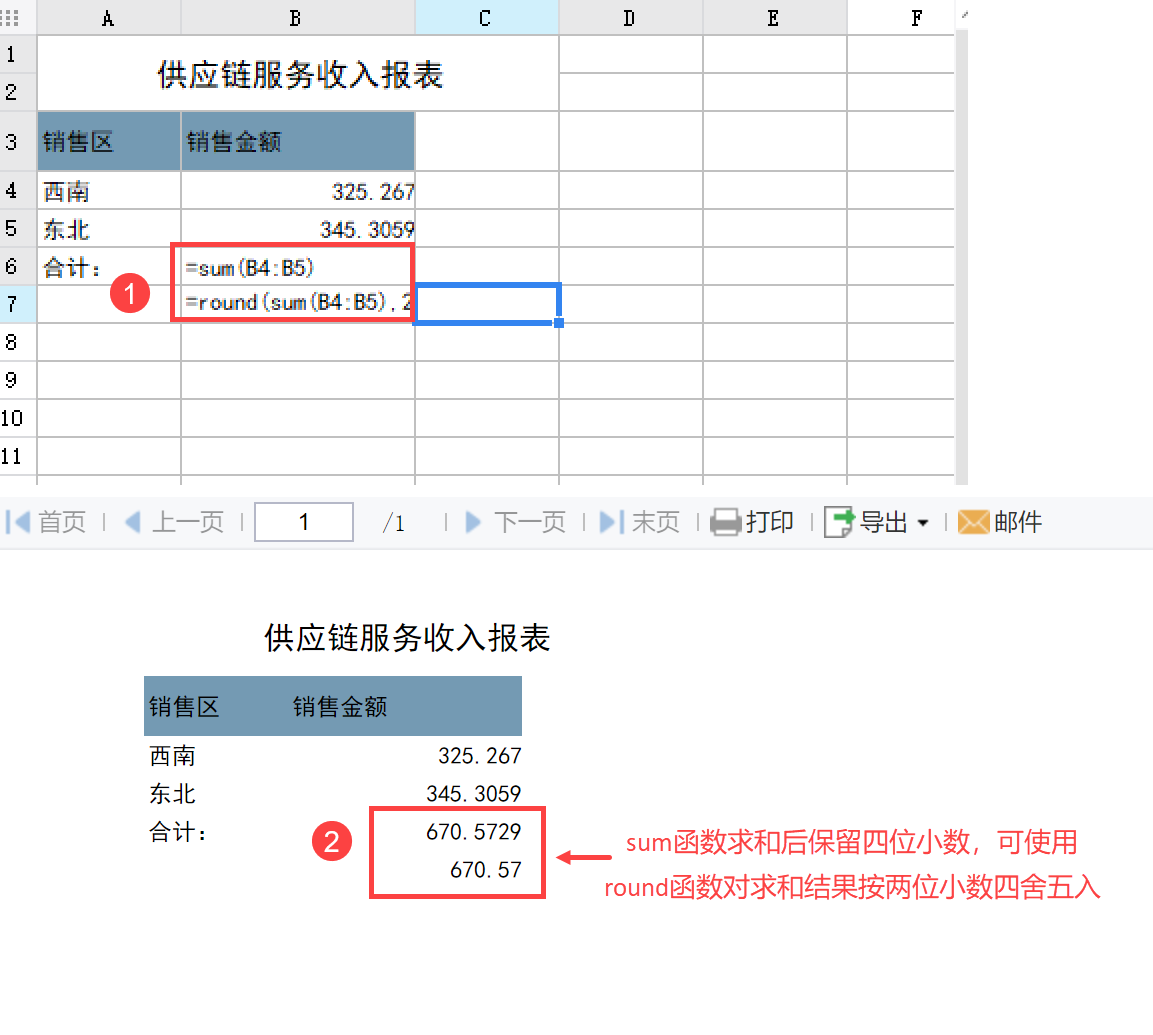
报表中的销量列求和,设计如下:
如上对收入 sum 求和后精度变大了。
遇到这样的情况时,可使用 round 函数对求和结果按 2 位小数位四舍五入,即 B5 单元格中的使用方法。
Map函数
1. 函数作用
在制作报表时,我们可能需要根据某一单元格的值对数据集进行检索并返回对应的值。
此情况时,可使用 map() 函数,根据数据集的名字,找到对应的数据集,找到其中索引列的值为 key 所对应的返回值。 map() 函数首先检索模板数据集,再检索服务器数据集。
示例:
MAP(1001,"employee",1,2)返回 employee 数据集,第 1 列中值为 1001 那条记录中第 2 列的值。
MAP(1001,"employee","name","address")返回 employee 数据集,name 列中值为 1001 那条记录中 address 列的值。注:只返回第一个找到的值。
2. 使用说明
MAP(object,string,int,int):根据数据集的名字,找到对应的数据集,找到其中索引列的值为 key 所对应的返回值。
object:索引值,需要查询的内容。
string:数据集的名字,定义的数据查询的名字。
int:索引值所在列序号。
int:返回值所在列序号。
注:后两个参数也可以写列名代替。根据数据集的名字,找到对应的数据集,找到其中索引列的值为key所对应的返回值。数据集的查找方式是依次从报表数据集找到服务器数据集。索引列序号与返回值序列号的初始值为1。
3. 示例
3.1 报表设计
3.1.1 数据准备
新建数据查询 ds1 ,SQL 语句如下SELECT * FROM 供应商,如下图所示:

3.1.2 模板设计
新建普通报表,分别给 A1~A5 单元格赋值,单击 A2 单元格,右键选择单元格元素,选择插入公式,公式如下:
MAP(A1, "ds1", "公司名称", "供应商ID")返回 ds1 数据集,“公司名称”列中值为 A1 那条记录中“供应商 ID”列的值。
MAP(A1, "ds1", 2, 1)返回 ds1 数据集,第 2 列中值为 A1 那条记录中第1列的值。
MAP("妙生", "ds1", "公司名称", "供应商ID")返回 ds1 数据集,“公司名称”列中值为“妙生”那条记录中“供应商 ID”列的值。
MAP("妙生", "ds1", 2, 1)返回 ds1 数据集,第2列中值为“妙生”那条记录中第1列的值。

3.2 效果预览
1)PC端
保存模板,点击分页预览,如下图所示:

2)移动端

4. 模板下载
点击下载模板:Map函数.cpt
treelayer函数
1. 概述
语法:treelayer(TreeObject, Int, Boolean, String)
定义:返回一个树对象 TreeObject 第 n 层的值,一般为树数据集,或下拉树、视图树等树对象,并且可以设置返回值类型及分隔符。
详细解释:
| 对象 | 定义 | 值 |
|---|---|---|
| TreeObject | tree 对象 | 例如:$tree |
| Int | 想要获得层级的数值 |
最上层为 1 ,第二层为 2 ,依此类推,若无则返回最底层 |
| Boolean | 返回值类型 |
false:返回值类型为数组,默认值 true:返回值类型为字符串 |
| String | 当返回值类型为字符串时的分隔符 |
以双引号表示,默认为逗号:"," |
2. 示例
以一个下拉树控件展示 FRDemo 数据库中的部门层级树为例,来讲解 treelayer 函数的作用。
2.1 新建数据集
2.1.1 新建数据库查询
新建普通报表,新建数据集 ds1,SQL 语句为:select * from department,如下图所示:

2.1.2 新建树数据集
新建一个树数据集 Tree1,数据集为 ds1,依赖字段为 did,父标记字段为 fid,如下图所示:

2.1.3 数据集预览
树数据集效果预览如下图所示:

2.2 添加控件
在参数栏添加两个控件:一个下拉树控件和一个文本控件,如下图所示:

2.2.1 下拉树控件
下拉树控件的控件名称修改为 tree。勾选 多选和结果返回完整层次路径。
数据字典选择自动构建,依靠树数据集 Tree1 构建,实际值和显示值都选择 department。如下图所示:

2.2.2 文本控件
文本控件的控件值选择公式:treelayer($tree, true, "\',\'"),如下图所示:

2.4 效果预览
保存模板,点击预览,勾选总部>人力资源部>人力资源文员、总部>市场部>业务员,如下图所示:

根据文本控件值中填入的公式,预览时的返回值和分隔符也会有所不同,详情如下表所示:
| 公式 | 返回值 | 分隔符 | 图示 |
|---|---|---|---|
| treelayer($tree, true, "\',\'") |
人力资源文员 业务员 |
',' | |
| treelayer($tree, 2) |
人力资源部 市场部 |
, | |
| treelayer($tree, 2, true, "\',\'") |
人力资源部 市场部 |
',' |
3. 模板下载
点击下载模板:treelayer函数.cpt
日期函数应用
1. 概述
在使用 FineReport 进行可视化展示时,经常会需要对日期数据进行处理,本文介绍几种日期类型数据的处理应用场景。
2. 获取月份或日期的时候显示 2 位
2.1 问题描述
在使用公式month()或者是day()时,如果月份或日期是一位数,则显示出来的也只有一位数,比如说 1 月 9 号,获取月份时显示的是 1,而不是 01,获取日期时,显示的是 9,而不是 09,如果需要获取到 01 或者是 09,这个该如何通过公式实现呢?
2.2 解决方案
通过公式或者自定义函数实现。
2.3 操作步骤
2.3.1 公式实现
1)使用 RIGHT、CONCATENATE、MONTH 组合函数实现。
例如显示当前时间(2021-08-31)对应的月份和天数且以两位数字显示。
在单元格分别输入:
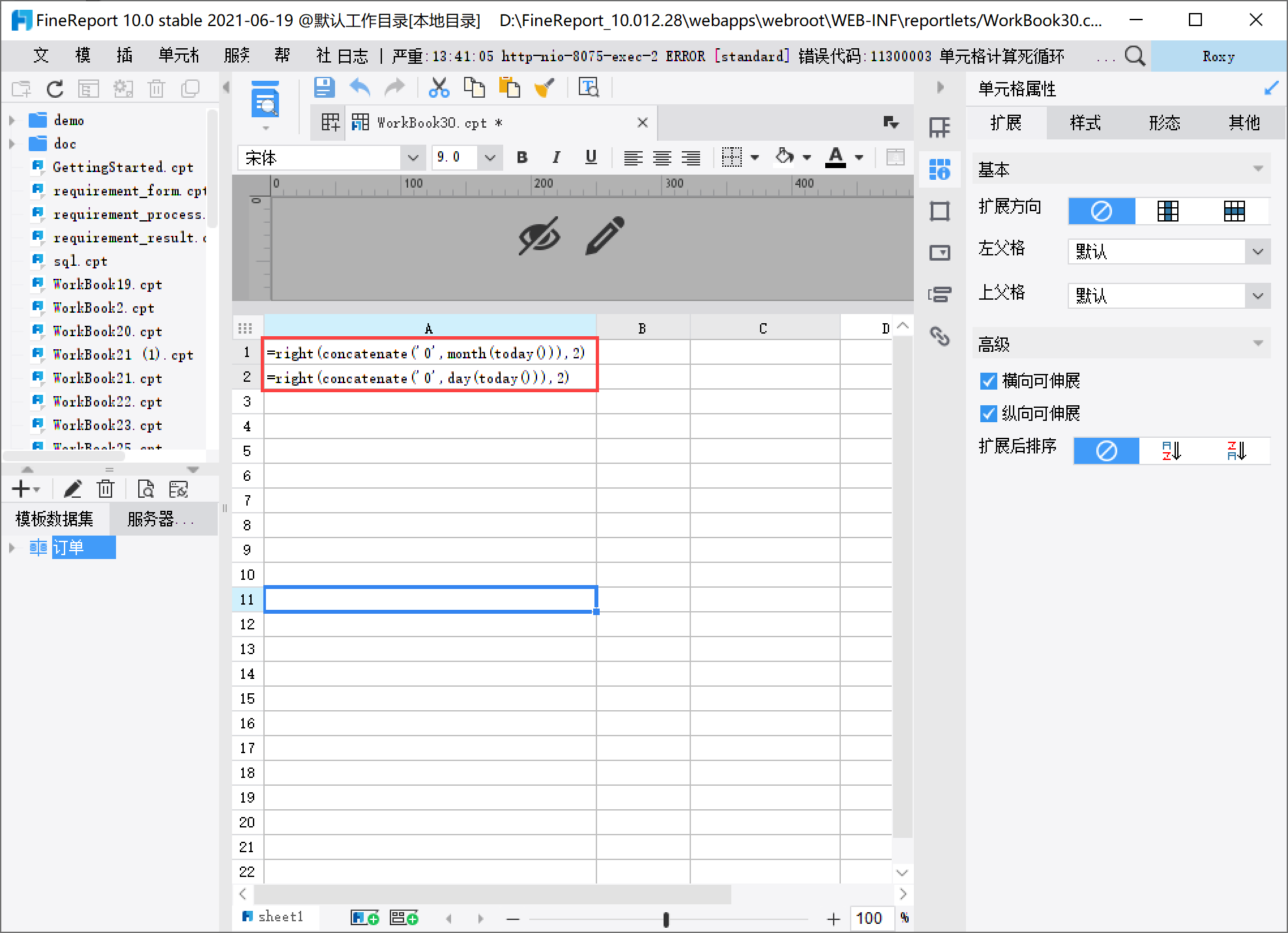
月份公式:=right(concatenate('0',month(today())),2)
天数公式:=right(concatenate('0',day(today())),2)
公式说明:
| 公式 | 说明 |
|---|---|
|
concatenate('0',month(today())) concatenate('0',day(today())) |
通过 concatenate 将获取到的月份或者天数前面拼接一个 0,比如说 11 月,则显示 011,如果是 2 月,则显示 02;如果是 31 号,则显示 031 |
|
right(concatenate('0',month(today())),2) right(concatenate('0',day(today())),2) |
通过 right 方法,获取右边的 2 位数字,比如说 2 月,截取 2 位数字,则为 02,比如 12 月,截取右边的两位,则为 12;比如 31号,则截取右边的两位 31 |
效果查看:

2)通过 FORMAT 来格式化字符串。
在单元格分别输入:
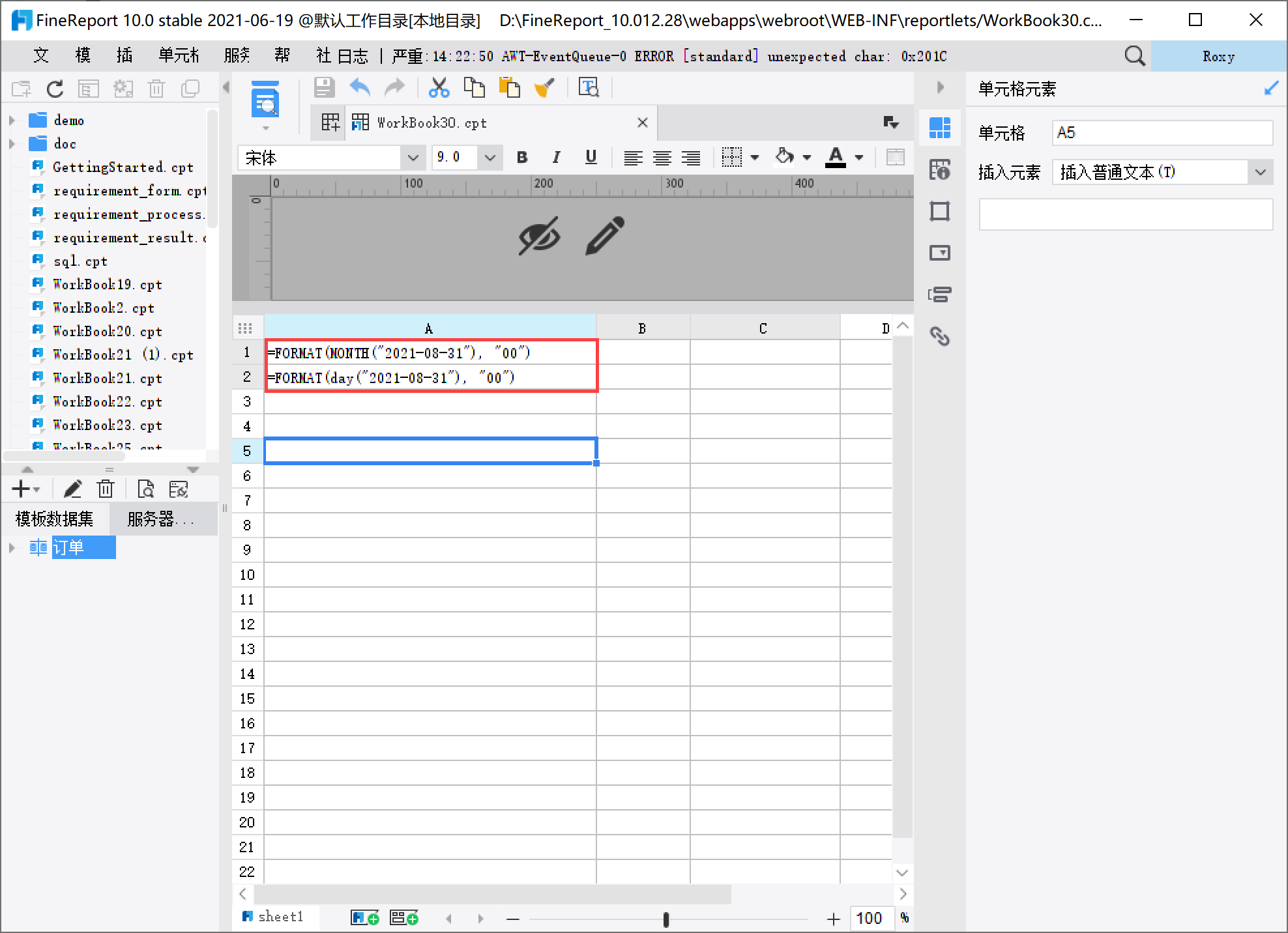
月份公式:=FORMAT(MONTH("2021-08-31"), "00")
天数公式:=FORMAT(day("2021-08-31"), "00")
公式说明:
| 公式 | 说明 |
|---|---|
|
MONTH("2021-08-31") day("2021-08-31") |
返回月份数字:8 返回天数数字:31 |
|
FORMAT(MONTH("2021-08-31"), "00") FORMAT(day("2021-08-31"), "00") |
返回 format 格式,也就是 |
效果查看:

2.3.2 自定义函数实现
如果觉得公式比较复杂,则可以通过自定义函数实现,代码如下:
1 2 3 4 5 6 7 8 9 10 | package com.fr.function;import com.fr.script.AbstractFunction;public class Add0 extends AbstractFunction { public Object run(Object[] args) { String result = args[0].toString(); if(result.length() == 1) result = '0' + result; return result; }} |
自定义函数的详细定义步骤请参照 自定义函数。
3. 利用日期函数生成特定编号
有些情况下需要生成特定字符且带「年月日时分秒」这样的字符串,类似 china20170726144516 这样的编号,可以直接利用时间公式和字符串拼接函数来实现。
在单元格中写入公式:="china" + FORMAT(now(), "yyyMMddhhmmss") 结果为:china20180101124516,即字符串“china”后面加当前的「年月日时分秒」。
注:一般编号非必要的情况下,不要全用数字,因为在导入导出到 EXCEL 时数字有可能出错。


- select a.*, group_concat(lesson) as LESSONNAME from t2 a, t1 b where find_in_set(b.id, lessonid) group by name

- ;with tb as ( select a.*, lesson as lessonname from t2 a, t1 b where charindex(','+b.id+',',','+lessonid+',')>0 ) select id,name,lessonid, [val]=stuff( (select ',' +[lessonname] from tb as kb where kb.id = ka.id for xml path('')),1,1,'') from tb as ka group by id,name,lessonid




- select 总部门, wmsys.wm_concat(部门名称) as 部门名称 from 部门 group by 总部门
- SELECT 总部门, stuff((select ','+部门名称 from 部门 b where a.总部门=b.总部门 for xml path('')),1,1,'') as 部门名称 FROM 部门 a group by a.总部门
- select 总部门, group_concat(部门名称) from 部门 group by 总部门

- DROP TABLE [dbo].[test_a] GO CREATE TABLE [dbo].[test_a] ( [id] int NULL , [name] varchar(255) NULL ) GO -- ---------------------------- -- Records of test_a -- ---------------------------- INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'1', N'苹果') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'2', N'橘子') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'3', N'菠萝') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'4', N'香蕉') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'5', N'西瓜') GO GO ----------------------------------------------------------- DROP TABLE [dbo].[test_b] GO CREATE TABLE [dbo].[test_b] ( [id] int NULL , [name] varchar(255) NULL ) GO -- ---------------------------- -- Records of test_b -- ---------------------------- INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'1', N'梨子') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'2', N'苹果') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'3', N'草莓') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'4', N'桃子') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'5', N'香蕉') GO GO
- SELECT * FROM test_a INNER JOIN test_b ON test_a.name = test_b.name

- SELECT * FROM test_a FULL OUTER JOIN test_b ON test_a.name = test_b.name

- SELECT * FROM test_a LEFT OUTER JOIN test_b ON test_a.name = test_b.name

- SELECT * FROM test_a LEFT OUTER JOIN test_b ON test_a.name = test_b.name WHERE test_b.name IS NULL

- SELECT * FROM test_a RIGHT OUTER JOIN test_b ON test_a.name = test_b.name

- SELECT * FROM test_a LEFT OUTER JOIN test_b ON test_a.name = test_b.name UNION SELECT * FROM test_a RIGHT OUTER JOIN test_b ON test_a.name = test_b.name
- SELECT * FROM test_a RIGHT OUTER JOIN test_b ON test_a.name = test_b.name WHERE test_a.name IS NULL

- SELECT * FROM test_a FULL OUTER JOIN test_b ON test_a.name = test_b.name WHERE test_a.name IS NULL OR test_b.name IS NULL



- -- ---------------------------- -- Table structure for test_table -- ---------------------------- DROP TABLE [dbo].[test_table] GO CREATE TABLE [dbo].[test_table] ( [name] varchar(255) NULL , [cp] varchar(255) NULL , [price] int NULL ) GO -- ---------------------------- -- Records of test_table -- ---------------------------- INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小明', N'香蕉', N'20') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小明', N'苹果', N'25') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小明', N'梨', N'30') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小明', N'菠萝', N'24') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小兰', N'香蕉', N'5') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小兰', N'苹果', N'16') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小兰', N'梨', N'9') GO GO INSERT INTO [dbo].[test_table] ([name], [cp], [price]) VALUES (N'小兰', N'菠萝', N'33') GO GO

- SELECT * FROM test_table PIVOT ( MAX (price) FOR cp IN (香蕉, 苹果, 梨, 菠萝) ) a

- declare @ck varchar(8000) set @ck='' --初始化变量@ck select @ck=@ck+','+ cp from test_table group by cp -- 变量多值赋值,将结果 ,香蕉,苹果,梨,菠萝 赋值给变量@ck set @ck=stuff(@ck,1,1,'') --去掉首个',' 将 香蕉,苹果,梨,菠萝 赋值给变量@ck --第一个字符串 apple 中删除从第 2 个位置(字符 b)开始的3个字符,然后在删除的起始位置插入第二个字符串,从而创建并返回一个新的字符串。 --例:SELECT STUFF('apple', 2, 3, 'test'); 返回ateste set @ck='select * from test_table pivot (max(price) for cp in ('+@ck+'))a' --拼接sql并赋值给变量@ck exec(@ck) --执行sql语句

- -- ---------------------------- -- Table structure for test_table_2 -- ---------------------------- DROP TABLE [dbo].[test_table_2] GO CREATE TABLE [dbo].[test_table_2] ( [name] varchar(255) NULL , [香蕉] int NULL , [苹果] int NULL , [梨] int NULL , [菠萝] int NULL ) GO -- ---------------------------- -- Records of test_table_2 -- ---------------------------- INSERT INTO [dbo].[test_table_2] ([name], [香蕉], [苹果], [梨], [菠萝]) VALUES (N'小明', N'85', N'75', N'65', N'55') GO GO INSERT INTO [dbo].[test_table_2] ([name], [香蕉], [苹果], [梨], [菠萝]) VALUES (N'小兰', N'90', N'80', N'70', N'60') GO GO

- SELECT name,产品,数值 FROM test_table_2 UNPIVOT ( 数值 FOR 产品 IN ( [香蕉], [苹果], [梨], [菠萝] ) ) t

- declare @ck nvarchar(3000) select @ck= isnull(@ck+',','')+quotename(Name) from syscolumns where ID= object_id('test_table_2') and Name not in('name') order by Colid --获取到表test_table_2中除了字段name的所有字段名(以’,’)隔开并将结果赋值给@ck --@ck=香蕉,苹果,梨,菠萝 set @ck='select name,[产品],[数值] from test_table_2 unpivot ([数值] for [产品] in('+@ck+'))b' --@ck=select name,[产品],[数值] from test_table_2 unpivot ([数值] for [产品] in(香蕉,苹果,梨,菠萝))b exec(@ck) --执行sql语句

- -- ---------------------------- -- Table structure for test_c -- ---------------------------- DROP TABLE [dbo].[test_c] GO CREATE TABLE [dbo].[test_c] ( [cp] varchar(255) NULL , [price] int NULL , [numb] int NULL ) GO -- ---------------------------- -- Records of test_c -- ---------------------------- INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'苹果', N'80', N'20') GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'橘子', N'35', null) GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'菠萝', N'45', N'0') GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'香蕉', N'24', null) GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'西瓜', N'60', N'15') GO GO
|
cp
|
price
|
numb
|
|
苹果
|
80
|
20
|
|
橘子
|
35
|
|
|
菠萝
|
45
|
0
|
|
香蕉
|
24
|
|
|
西瓜
|
60
|
15
|
- SELECT cp, price, numb, price * isnull(numb, 1) AS priceb --isnull(numb, 1) 当numb的值为空值时,就返回1 FROM test_c;

- select cp, price, numb, price * nvl(numb, 1) as priceb --nvl(numb, 1) 当numb的值为空值时,就返回1 from test_c;

- SELECT cp, price, numb, price * coalesce(numb, 1) AS priceb -- coalesce(numb, 1) 当numb的值为空值时,就返回1 FROM test_c;

- SELECT cp, price, numb, price /numb AS priceb FROM test_c;
- [SQL]SELECT cp, price, numb, price /numb AS priceb FROM test_c [Err] 22012 - [SQL Server]遇到以零作除数错误。
- SELECT cp, price, numb, price / CASE WHEN numb = 0 THEN Null ELSE numb END AS priceb --CASE WHEN numb = 0 THEN Null ELSE numb END 解释:当numb = 0时,返回null FROM test_c;

- -- ---------------------------- -- Table structure for zsh_0220 -- ---------------------------- DROP TABLE [dbo].[zsh_0220] GO CREATE TABLE [dbo].[zsh_0220] ( [t_time] int NULL , [code] int NULL , [name] varchar(255) NULL , [cl] int NULL ) GO -- ---------------------------- -- Records of zsh_0220 -- ---------------------------- INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'110000', N'北京市', N'7631') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'120000', N'天津市', N'3861') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'130000', N'河北省', N'7631') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'140000', N'山西省', N'6651') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'150000', N'内蒙古自治区', N'4030') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'210000', N'辽宁省', N'4448') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'110000', N'北京市', N'8122') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'120000', N'天津市', N'3524') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'130000', N'河北省', N'9006') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'140000', N'山西省', N'6288') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'150000', N'内蒙古自治区', N'7787') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'210000', N'辽宁省', N'6288') GO GO

- SELECT t_time, code, name, CL, row_number () OVER (partition BY t_time ORDER BY cl) AS 组内排名1, --T_time组内,cl排名 row_number () OVER (ORDER BY cl) AS 排名1_1, --所有cl的排名 rank () OVER (partition BY t_time ORDER BY cl) AS 组内排名2, --T_time组内,cl排名 rank () OVER (ORDER BY cl) AS 排名2_1, --所有cl的排名 dense_rank () OVER (partition BY t_time ORDER BY cl) AS 组内排名3, --T_time组内,cl排名 dense_rank () OVER (ORDER BY cl) AS 排名3_1 --所有cl的排名 FROM zsh_0220 ORDER BY t_time,code;
- OVER (partition BY t_time ORDER BY cl)

- -- ---------------------------- -- Table structure for zsh_0220 -- ---------------------------- DROP TABLE [dbo].[zsh_0220] GO CREATE TABLE [dbo].[zsh_0220] ( [t_time] int NULL , [code] int NULL , [name] varchar(255) NULL , [cl] int NULL ) GO -- ---------------------------- -- Records of zsh_0220 -- ---------------------------- INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'110000', N' 北京市', N'7631') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'120000', N'天津 市', N'3861') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2015', N'130000', N'河北省 ', N'7631') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'110000', N'北京市', N'8122') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'120000', N' 天 津 市', N'3524') GO GO INSERT INTO [dbo].[zsh_0220] ([t_time], [code], [name], [cl]) VALUES (N'2016', N'130000', N'河北省', N'9006') GO GO

- SELECT * FROM dbo.[zsh_0220] where LTRIM (name) ='${dq_r}' --dq_r 默认值:北京市 --LTRIM():返回删除了前空格之后的字符表达式。

- select LTRIM(' 我的前面有空格') --返回:‘我的前面有空格’
- SELECT * FROM dbo.[zsh_0220] where LTRIM (name) ='${dq_r}' --dq_r 默认值:河北省 --RTRIM():返回删除了后空格之后的字符表达式。

- select RTRIM('我的前面有空格 ') --返回:‘我的后面有空格’
- --TRIM():将把 [要移除的字串] 从字串的起头、结尾,或是起头及结尾移除。如果我们没有列出 [要移除的字串] 是什么的话,那空白就会被移除。 SELECT TRIM( '.' FROM '. test .') AS Result; --返回:删除了首尾的’.’的结果’ test ’

- SELECT TRIM(' zsh ') --返回:’zsh’ 默认是删除首尾空格
- SELECT * FROM dbo.[zsh_0220] where replace(name,' ','') ='${dq_r}' --dq_r 默认值:天津市 -- replace(name,' ','')会替换掉name中所有的空格,然后与$dq_rj(天津市)进行匹配。

- SELECT REPLACE('abcdefghicde','cde','xxx'); --返回:'abxxxfghixxx' --解释:用’xxx’替换掉了'abcdefghicde'中所有的’cde’
- -- ----------------------------
- -- Table structure for ZSH_170222
- -- ----------------------------
- DROP TABLE [dbo].[ZSH_170222]
- GO
- CREATE TABLE [dbo].[ZSH_170222] (
- [PART] varchar(255) NULL ,
- [NAME_C] varchar(255) NULL ,
- [PAY] int NULL
- )
- GO
- -- ----------------------------
- -- Records of ZSH_170222
- -- ----------------------------
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'小明', N'9741')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'小兰', N'6908')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'李东', N'6336')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'杨澜', N'9089')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'黄伟', N'1646')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'赵丽', N'4486')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'技术部', N'张军', N'3538')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'刘伟', N'2143')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'张强', N'6522')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'黄渤', N'1247')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'赵丽', N'7975')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'刘东', N'2990')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'张伟', N'4266')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'黄俊', N'4815')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'黄伟', N'7788')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'刘康', N'4605')
- GO
- GO
- INSERT INTO [dbo].[ZSH_170222] ([PART], [NAME_C], [PAY]) VALUES (N'综合部', N'刘冰', N'6184')
- GO
- GO

- SELECT
- part,
- name_c,
- pay,
- CUME_DIST () OVER (ORDER BY pay) AS cat_1,
- CUME_DIST () OVER (PARTITION BY part ORDER BY pay) AS cat_2
- FROM
- ZSH_170222
- ORDER BY
- part,
- pay

- -- ---------------------------- -- Table structure for zsh_170225 -- ---------------------------- DROP TABLE [dbo].[zsh_170225] GO CREATE TABLE [dbo].[zsh_170225] ( [name] varchar(255) NULL , [sex] varchar(255) NULL ) GO -- ---------------------------- -- Records of zsh_170225 -- ---------------------------- INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'张三', N'1') GO GO INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'李四', N'2') GO GO INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'王五', null) GO GO INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'赵六', N'1') GO GO
|
Name
|
Sex
|
|
张三
|
1
|
|
李四
|
2
|
|
王五
|
|
|
赵六
|
1
|
- Select name,sex, CASE sex WHEN '1' THEN '男' --如果sex字段值为1就sex=’男’ WHEN '2' THEN '女' --如果sex字段值为2就sex=’女’ ELSE '其他' END --否则sex=’其他’ AS sex_n FROM zsh_170225

- SELECT name, sex, CASE WHEN sex = '1' THEN '男' --如果sex字段值为1就sex=’男’ WHEN sex = '2' THEN '女' --如果sex字段值为2就sex=’女’ ELSE '其他' END --否则sex=’其他’ AS sex_n FROM zsh_170225

- --比如说,下面这段SQL,你永远无法得到“K2”这个结果 CASE WHEN col_1 IN ( 'a', 'b') THEN 'K1' WHEN col_1 IN ('a') THEN 'K2' ELSE'其他' END
- SELECT ProductNumber, Category = CASE ProductLine WHEN 'R' THEN 'Road' -- 当ProductLine =’R’ 时, Category=’ Road’ WHEN 'M' THEN 'Mountain' -- 当ProductLine =’M’ 时, Category='Mountain' WHEN 'T' THEN 'Touring' -- 当ProductLine =’T’ 时, Category='Touring' WHEN 'S' THEN 'Other sale items' -- 当ProductLine =’S’ 时, Category=' Other sale items ' ELSE 'Not for sale' --否则Category=' Not for sale ' END, Name FROM Production.Product ORDER BY ProductNumber;
- SELECT ProductNumber, Name, "Price Range" = CASE WHEN ListPrice = 0 THEN 'Mfg item - not for resale' WHEN ListPrice < 50 THEN 'Under $50' WHEN ListPrice >= 50 and ListPrice < 250 THEN 'Under $250' WHEN ListPrice >= 250 and ListPrice < 1000 THEN 'Under $1000' ELSE 'Over $1000' END FROM Production.Product ORDER BY ProductNumber ;
- SELECT BusinessEntityID, SalariedFlag FROM HumanResources.Employee ORDER BY CASE SalariedFlag WHEN 1 THEN BusinessEntityID END DESC ,CASE WHEN SalariedFlag = 0 THEN BusinessEntityID END; --如果SalariedFlag=1时按照BusinessEntityID字段的降序排 --如果SalariedFlag=0时按照BusinessEntityID字段的升序排
- SELECT BusinessEntityID, LastName, TerritoryName, CountryRegionName FROM Sales.vSalesPerson WHERE TerritoryName IS NOT NULL ORDER BY CASE CountryRegionName WHEN 'United States' THEN TerritoryName ELSE CountryRegionName END; -- 当CountryRegionName= 'United States'时, 按TerritoryName字段的升序排,否则就按照CountryRegionName字段的升序排
- UPDATE HumanResources.Employee SET VacationHours = ( CASE WHEN ((VacationHours - 10.00) < 0) THEN VacationHours + 40 ELSE (VacationHours + 20.00) --如果VacationHours - 10.00) < 0时, VacationHours= VacationHours + 40否则VacationHours = VacationHours + 20.00 END ) OUTPUT Deleted.BusinessEntityID, Deleted.VacationHours AS BeforeValue, Inserted.VacationHours AS AfterValue WHERE SalariedFlag = 0;
- SELECT JobTitle, MAX(ph1.Rate)AS MaximumRate FROM HumanResources.Employee AS e JOIN HumanResources.EmployeePayHistory AS ph1 ON e.BusinessEntityID = ph1.BusinessEntityID GROUP BY JobTitle HAVING (MAX(CASE WHEN Gender = 'M' THEN ph1.Rate ELSE NULL END) > 40.00 -- Gender = 'M'时, ph1.Rate字段,否则null OR MAX(CASE WHEN Gender = 'F' THEN ph1.Rate ELSE NULL END) > 42.00) ---- Gender = 'F'时, ph1.Rate字段,否则null ORDER BY MaximumRate DESC;
- -- ----------------------------
- -- Table structure for test_table
- -- ----------------------------
- DROP TABLE [dbo].[test_table]
- GO
- CREATE TABLE [dbo].[test_table] (
- [id] int NOT NULL IDENTITY(1,1) ,
- [name] nvarchar(50) NULL ,
- [price] nvarchar(50) NULL
- )
- GO
- -- ----------------------------
- -- Records of test_table
- -- ----------------------------
- SET IDENTITY_INSERT [dbo].[test_table] ON
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'141', N'香蕉', N'20')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'142', N'苹果', N'25')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'143', N'梨', N'17')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'144', N'菠萝', N'24')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'145', N'西瓜', N'24')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'146', N'油桃', N'16')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'147', N'哈密瓜', N'9')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'148', N'水蜜桃', N'33')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'149', N'柚子', N'10')
- GO
- GO
- INSERT INTO [dbo].[test_table] ([id], [name], [price]) VALUES (N'150', N'橘子', N'8')
- GO
- GO
- SET IDENTITY_INSERT [dbo].[test_table] OFF
- GO
- SELECT name, price, ROW_NUMBER () OVER (ORDER BY price DESC) AS '排名1', --ROW_NUMBER直接分组,前面的序号唯一且连续 RANK () OVER (ORDER BY price DESC) AS '排名2', --RANK()并列排序,值相同序号并列,后面的值跳跃 DENSE_RANK () OVER (ORDER BY price DESC) AS '排名3', --DENSE_RANK并列排序,值相同序号并列,后面的值连续 NTILE (4) OVER (ORDER BY price DESC) AS '排名4' --不常用,NTILE(4)将所有的行分为4组,然后10/4=2余2,表示每组2行,前面的2行+1(3行) FROM test_table;



- CASE NTILE (N) OVER (ORDER BY GRADE DESC) WHEN 1 THEN 'A' WHEN 2 THEN 'B' WHEN 3 THEN 'C' WHEN 4 THEN 'D' . . . WHEN N THEN 'X' END

- SELECT STUDENTNO AS 学号, GRADE AS 科目, CASE NTILE (4) OVER (ORDER BY GRADE DESC) WHEN 1 THEN '优' WHEN 2 THEN '良' WHEN 3 THEN '较差' WHEN 4 THEN '不及格' END AS '级别' FROM "STSCORE" WHERE COURSE = 'Chemistry' ORDER BY STUDENTNO;



- SELECT [年份], [月份], [销量], NULLIF (lag ([销量], 1, 0) OVER ( partition BY [年份] ORDER BY [月份] ),0) AS 上月销量, round( ( [销量] - NULLIF ( lag ([销量], 1, 0) OVER ( partition BY [年份] ORDER BY [月份] ), 0 ) ) / NULLIF ( lag ([销量], 1, 0) OVER ( partition BY [年份] ORDER BY [月份] ), 0 ) * 100, 2, 3 ) AS '环比(%)' FROM 大陆车辆销售;
- NULLIF():如果两个指定的表达式相等,则返回空值。语法NULLIF ( expression1 , expression2 ) LAG ([销量], 1, 0):组内前一个月的的销量值。 ROUND(a,b):通常用于四舍五入求值,通常函数中会传入两个参数,第一个参数是要四舍五入的数字,第二个参数就是位数。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?