
常见的函数--帆软(2)
常用的函数
主页:https://www.cnblogs.com/wan-ge1212/p/10256341.html
帆软全面网址介绍
函数列表
1. 描述
在函数使用说明中,我们提到FineReport支持多种公式
常用函数
1. SUM
SUM(number1,number2,…):求一个指定单元格区域中所有数字之和。Number1,number2,…:1到30个参数或指定单元格区域中所有数字。
注: 函数将直接键入参数中的数值、逻辑值及文本表达式计算在内.若参数是数组或引用,则只有数组或单元格引用中的数值进行计算。
示例:
SUM(70,80)等于150。
SUM("70",80,TRUE)等于151。逻辑值“TRUE”作为1来计算;“FALSE”作为0计算;文本“70”作为70来计算。
2. COUNT
COUNT(value1,value2,…):计算数组或数据区域中所含数字项的个数。Value1,value2,…:可包含任何类型数据的参数,但此函数只将数字类型的数据计算在内。
注: 数字、日期或以文字代表的数字参数将被计算在内;但无法转换成数字的错误值或文本值参数将忽略不计。如果数组或引用参数中包含可解析文本值、逻辑值、零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。
3. AVERAGE
AVERAGE(number1,number2,…):返回指定数据的平均值。 Number1,number2…:用于计算平均值的参数。
注: 参数必须是数字,或是含有数字的名称,数组或引用。 如果数组或引用参数中含有文字,逻辑值,或空白单元格,这些值将被忽略;但是,单元格中的零值则参与计算。
示例:
如果A1:A6被命名为“ages”,分别等于10,23,14,24,33及25,则:
AVERAGE(A1:A6)等于21.5。
AVERAGE(ages)等于21.5。
如果还有一个年龄为18的,求所有年龄的平均值为:
AVERAGE(A1:A6,18)等于21。
4. CHAR
CHAR(number):根据指定数字返回对应的字符。CHAR函数可将计算机其他类型的数字代码转换为字符。Number:用于指定字符的数字,介于1-65535之间(包括1和65535)。
示例:
CHAR(88)等于“X”。
CHAR(45)等于“-”。
5. DATE
DATE(year,month,day):返回一个表示某一特定日期的系列数。 Year:代表年,可为一到四位数。Month:代表月份。
若month<12,则函数把参数值作为月;若month>12,则函数从年的一月份开始往上累加。
例如: DATE(2000,25,2)等于2002年1月2日的系列数。
Day:代表日。 若日期小于等于某指定月的天数,则函数将此参数值作为日;若日期大于某指定月的天数,则函数从指定月份的第一天开始往上累加;若日期大于两个或多个月的总天数,则函数把减去两个月或多个月的余数加到第三或第四个月上,依此类推。例如:DATE(2000,3,35)等于2000年4月4日的系列数。
注: 若需要处理公式中日期的一部分,如年或月等,则可用此公式。 若年,月和日是函数而不是函数中的常量,则此公式最能体现其作用。
示例:
DATE(1978, 9, 19)等于1978-9-19。
DATE(1211, 12, 1)等于1211-12-1。
6. MAX
MAX(number1,number2,…):返回参数列表中的最大值。 Number1,number2,…:1到30个需要找出最大值的参数。
注: 参数可以是数字、空白单元格、逻辑值或数字的文本表达式。 如果数组或引用参数中包含可解析文本值,逻辑值,零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。 如果参数中没有任何数字,MAX将返回0。
示例:
MAX(0.1,0,1.2)等于1.2。
7. MIN
MIN(number1,number2,…):返回参数列表中的最小值。 Number1,number2,…:1到30个需要找出最小值的参数。
注: 若参数中没有数字,函数MIN将返回0。 参数应为数字、空白单元格、逻辑值或是表示数值的文本串。如果参数是错误值时,MIN将返回错误信息。 如果数组或引用参数中包含可解析文本值,逻辑值,零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。
示例:
如果B1:B4包含3,6,9,12,则:
MIN(B1:B4)等于3。
MIN(B1:B4,0)等于0。
8. TIME
TIME(hour,minute,second):返回代表指定时间的小数。介于0:00:00(12:00:00 A.M.)与23:59:59(11:59:59 P.M.)之间的时间可返回0到0.99999999之间的对应数值。
Hour:介于0到23之间的数。 Minute:介于0到59之间的数。 Second:介于0到59之间的数。
示例:
TIME(14,40,0)等于2018-7-25 14:40:00。
TIME(19,43,24)等于2018-7-25 19:43:24。
9. RANGE
RANGE(from,to,step):函数表示从整数from开始,以step为每一步的示例:直到整数to的一个数字序列。
注: RANGE函数有三种参数形式 RANGE(to),缺省默认from为1,step为1 RANGE(from,to),默认的step为1 RANGE(from,to,step),个参数的情况参照上面的注释。
示例:
RANGE(4)返回[1,2,3,4]。
RANGE(-5)返回[]。
RANGE(-1,3)返回[-1,0,1,2,3]。
RANGE(0,5)返回[0,1,2,3,4,5]。
RANGE(6,-1,-2)返回[6,4,2,0]。
RANGE(4,1,1)返回[]。
10. ARRAY
ARRAY(arg1,arg2...):返回一个由arg1,arg2,...组成的数组。 ar1,ar2,...字符串或者数字。
示例:
ARRAY("hello","world")返回[hello,world]。
ARRAY("hello",98)返回[hello,98]。
ARRAY(67,98)返回[67,98]。
ARRAY("hello")返回[hello]。
数学和三角函数
1. ABS
ABS(number):返回指定数字的绝对值。绝对值是指没有正负符号的数值。 Number:需要求出绝对值的任意实数。
示例:
ABS(-1.5)等于1.5。
ABS(0)等于0。
2. ACOS
(1)ACOS(number):返回指定数值的反余弦值。反余弦值为一个角度,返回角度以弧度形式表示。 Number:需要返回角度的余弦值。
注: 函数的参数必须在-1和1之间,包括-1和1。 返回的角度值在0和Pi之间。 如果要把返回的角度用度数来表示,用180/PI()乘返回值即可。
示例:
ACOS(1)等于0(弧度)。
ACOS(0.5)等于1.047197551(Pi/3弧度)。
ACOS(0.5)*180/PI()等于60(度)。
(2)ACOSH
ACOSH(number):返回给定数值的反双曲余弦。 Number:返回值的双曲余弦。
注: 参数number的值必须大于或等于1。 ACOSH(COSH(number))=number。
示例:
ACOSH(1)等于0。
ACOSH(8)等于2.768659383。
ACOSH(5.5)等于2.389526435。
3. ASIN
ASIN(number):返回指定数值的反正弦值。反正弦值为一个角度,返回角度以弧度形式表示。 Number:需要返回角度的正弦值。
注: 指定数值必须在-1到1之间(含1与-1)。 返回角度在-pi/2到pi/2之间(含-pi/2与pi/2)。 用角度形式返回数值时,可以用返回数值乘以180/PI()。
示例:
ASIN(0.5)等于0.523598776(pi/6弧度)。
ASIN(1)等于1.570796327(pi/2弧度)。
ASIN(0.5)*180/PI()等于30(度)。
4. ASINH
ASINH(number):返回指定数值的反双曲正弦值。反双曲正弦值的双曲正弦等于指定数值。即: ASINH(SINH(number))=number。 Number:任意实数。
示例:
ASINH(-5)等于-2.312438341。
ASINH(8)等于2.776472281。
ASINH(16)等于3.466711038。
5. ATAN
ATAN(number):计算指定数值的反正切值。指定数值是返回角度的正切值,返回角度以弧度形式表示。 Number:返回角度的正切。
注: 返回角度在-pi/2到pi/2之间。 如果返回角度等于-pi/2或pi/2,ATAN将返回错误信息*NUM!。 用角度形式返回数值时,返回数值乘以180/PI()。
示例:
ATAN(-1)等于-0.785398163(-pi/4弧度)。
ATAN(0)等于0(弧度)。
ATAN(2)*180/PI()等于63.43494882(度)。
6. ATAN2
ATAN2(x_num,y_num):返回x、y坐标的反正切值。返回角度为x轴与过(x_num,y_num)与坐标原点(0,0)的一条直线形成的角度。该角度以弧度显示。 X_num:指定点的x坐标。 Y_num:指定点的y坐标。
注: 正值表示从x轴开始以逆时针方式所得的角度;负值表示从x轴开始以顺时针方式所得的角度。 ATAN2(a,b)=ATAN(b/a),a为0时除外。 当x_num与y_num都为0时,ATAN2返回错误信息*DIV/0!。 用角度制显示返回数值时,把返回数值乘以180/PI()。 返回值以弧度表示(返回值大于-pi且小于等于pi)。
示例:
ATAN2(-2,2)等于2.356194490(弧度制的3*pi/4)。
ATAN2(2,2)等于0.785398163(弧度制的pi/4)。
ATAN2(-2,2)*180/PI()等于135(角度制)。
7. AVERAGE
AVERAGE(number1,number2,…):返回指定数据的平均值。 Number1,number2…:用于计算平均值的参数。
注: 参数必须是数字,或是含有数字的名称,数组或引用。 如果数组或引用参数中含有文字,逻辑值,或空白单元格,这些值将被忽略;但是,单元格中的零值则参与计算。
示例:
如果A1:A6被命名为“ages”,分别等于10,23,14,24,33及25,则:
AVERAGE(A1:A6)等于21.5。
AVERAGE(ages)等于21.5。
如果还有一个年龄为18的,求所有年龄的平均值为:
AVERAGE(A1:A6,18)等于21。
(即对数组:10,23,14,24,33,25,18进行取平均值运算)
8. BITNOT
BITNOT(int):将一个十进制整数进行二进制取反运算。 int:需要进行转换的十进制数。
示例:
BITNOT(3)等于-4。
BITNOT(12)等于-13。
9. BITOPERATION
BITOPERATIOIN(int,int,op):位运算,返回两个整数根据op进行位运算后的结果。 int:十进制整数。 op:位运算操作符,支持"&"(与),"|"(或),"^"(异或),"<<"(左移),">>"(右移)。
示例:
BITOPERATION(4,2,"&")等于0。(表示4与2进行"与"运算。)
BITOPERATION(4,2,"|")等于6。(表示4与2进行"或"运算。)
BITOPERATION(4,2,"^")等于6。(表示4与2进行"异或"运算。)
BITOPERATION(4,2,"<<")等于16。(表示4按位左移2位。4的二进制为:100,左移2位变成:10000;即十进制16)
BITOPERATION(4,2,">>")等于1。(表示4按位右移2位。4的二进制100右移2为变成:1;即十进制1)
BITOPERATION(4,2,"^~")等于-7。(表示4与2进行"同或"运算。)
10. CEILING
CEILING(number):将参数number沿绝对值增大的方向,舍入为最接近的整数
示例:
CEILING(-2.5)等于-3。
CEILING(0.5)等于1。
11. COMBIN
COMBIN(number,number_chosen):返回若干个指定对象的组合数。函数中的number指对象总数,number_chosen指对象总数中某一组合的数量。该函数与数学表达式为Cnk功能相同, 数学表达式中的"n"指对象总数。,"k"指在对象总数中某一组合的数量。
注: Number与number_chosen必须是非负整数,且Number>=number_chosen.否则返回*VALUE?。 对象组合是对象总体的子集。与排列不同的是,组合不涉及对象内部排序。 假设number=n,number_chosen= k,则:COMBIN(n,k)=Cnk=n!/(k!(n-k)!)。
示例:
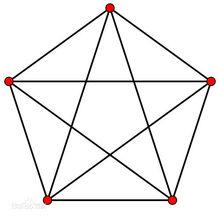
COMBIN(5,2)等于10。
意思是5个元素进行排列组合,每组2个元素,共有10种排法。如下图所示:
12. COS
COS(number):返回一个角度的余弦值。 Number:以弧度表示的需要求余弦值的角度。
注:要把一个角度转换成弧度值,将角度乘于PI()/180。 COS(n*2*PI()+number)=COS(number)(其中n为整数,number从-pi到pi)。
示例:
COS(0.5)等于0.877582562。
COS(30*PI()/180)等于0.866025404。
13. COSH
COSH(number):返回一个数值的双曲线余弦值。 Number:需要求其双曲线余弦值的一个实数。
注: 双曲线余弦值计算公式为:,其中e是自然对数的底,e=2.71828182845904。
示例:
COSH(3)等于10.06766200。
COSH(5)等于74.20994852。
COSH(6)等于201.7156361。
14. COUNT
COUNT(value1,value2,…):计算数组或数据区域中所含数字项的个数。 Value1,value2,…:可包含任何类型数据的参数,但此函数只将数字类型的数据计算在内。 备注:数字、日期或以文字代表的数字参数将被计算在内;但无法转换成数字的错误值或文本值参数将忽略不计。 如果数组或引用参数中包含可解析文本值、逻辑值、零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。
注: 数字、日期或以文字代表的数字参数将被计算在内;但无法转换成数字的错误值或文本值参数将忽略不计。 如果数组或引用参数中包含可解析文本值、逻辑值、零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。
COUNT(0,0,0,0,0,0)等于6。
15. DEGREES
DEGREES(angle):将弧度转化为度。 Angle:待转换的弧度角。
示例:
DEGREES(PI()/2)等于90。
DEGREES(3.1415926)等于180。
16. EVEN
EVEN(number):返回沿绝对值增大方向取整后最接近的偶数。使用该函数可以处理那些成对出现的对象。 number:所要取整的数值。
注: 不论正负号如何,数值都朝着远离0的方向舍入。如果number恰好是偶数,则不须进行任何舍入处理。
示例:
EVEN(1.5)等于 2。
EVEN(3)等于 4。
EVEN(2)等于 2。
EVEN(-1)等于 -2。
17. EXP
EXP(number):返回e的n次幂。常数e为自然对数的底数,等于2.71828182845904。 Number:为任意实数,作为常数e的指数。
注: 如果要返回其他常数作为底数的幂,可以使用指数运算符(^)。例如:在4^2中,4是底数,而2是指数。 EXP函数与LN函数互为反函数。
示例:
EXP(0)等于1。
EXP(3)等于20.08553692。
EXP(LN(2))等于2。
18. FACT
FACT(number):返回数的阶乘,一个数的阶乘等于0!*1*2*3*...*number(其中0!=1)。 number:要计算其阶乘的非负数。如果输入的 number不是整数,则截尾取整。
示例:
FACT(1)等于 1 。
FACT(1.9)等于 FACT(1) 等于 1。
FACT(5)等于 1*2*3*4*5 等于 120。
19. FLOOR
FLOOR(number):将参数number去尾舍入,即舍弃掉参数number后面的小数部分的数值。
注: 当number为非数值型的参数时,函数FLOOR返回0。
示例:
FLOOR(2.5)等于2。
FLOOR(-3.5)等于-3。
FLOOR(0.143,0.03)等于0。
FLOOR(hello)等于0。
20. INT
INT(number):返回数字下舍入(数值减小的方向)后最接近的整数值。 Number:需要下舍入为整数的实数。
示例:
INT(4.8)等于4。
INT(-4.8)等于-5。
INT(4.3)等于4。
公式INT(A1)将返回A1单元格中的一个正实数的整数数部分
21. LN
LN(number):返回一个数的自然对数。自然对数以常数项 e(2.71828182845904)为底。 number:是用于计算其自然对数的正实数。
示例:
LN(86)等于4.45437。
LN(2.7182818)等于1。
LN(EXP(3))等于3。
22. LOG
LOG(number,base):按指定的任意底数,返回数值的对数。 Number:需要求对数的正实数。 Base:对数的底数。缺省默认值为10。
示例:
LOG(16,2)等于4。
LOG(10)等于1。
LOG(24,3)等于2.892789261。
23. LOG10
LOG10(number):LOG10(number):返回以 10 为底的对数。number: 用于常用对数计算的正实数。
示例:
LOG10(86)等于1.934498451。
LOG10(10)等于1。
24. MAX
MAX(number1,number2,…):返回参数列表中的最大值。 Number1,number2,…:1到30个需要找出最大值的参数。
注: 参数可以是数字、空白单元格、逻辑值或数字的文本表达式。 如果数组或引用参数中包含可解析文本值,逻辑值,零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。 如果参数中没有任何数字,MAX将返回0。
示例:
MAX(0.1,0,1.2)等于1.2。
25. MIN
MIN(number1,number2,…):返回参数列表中的最小值。 Number1,number2,…:1到30个需要找出最小值的参数。
注: 若参数中没有数字,函数MIN将返回0。 参数应为数字、空白单元格、逻辑值或是表示数值的文本串。如果参数是错误值时,MIN将返回错误信息。 如果数组或引用参数中包含可解析文本值,逻辑值,零值或空白单元格,这些值都将参与计算,而不可解析的文本值忽略不计。
示例:
如果B1:B4包含3,6,9,12,则:
MIN(B1:B4)等于3。
MIN(B1:B4,0)等于0。
26. MOD
MOD(number,divisor):返回两数相除的余数。结果的正负号与除数相同。 number:为被除数。 divisor:为除数。
示例:
MOD(3, 2)等于 1 。
MOD(-3, 2)等于 1 。
MOD(3, -2)等于 -1 。
MOD(-3, -2)等于 -1。
注:小数的情况比较特殊。例:mod(49.5, 5.5)=4,并非我们的期望值0,我们可以采取其变通的方法:mod(49.5*10, 5.5*10)=0;mod(49.6, 5.5)=4,并非我们的期望值0.1,同理:mod(49.6*10, 5.5*10)/10=0.1 //将其先取整再求余!
27. ODD
ODD(number):是将一个不是奇数的数值向上舍入为最接近的奇数。 number:是要舍入求奇的数值。
注:不论正负号如何,数值都朝着远离0的方向舍入。如果 number恰好是奇数,则不须进行任何舍入处理。
示例:
ODD(1.5)等于3。
ODD(3)等于3。
ODD(2)等于3。
ODD(-1)等于 -1。
28. PI
PI:是一个数学常量,函数返回精确到15位的数值3.141592653589793。
示例:
SIN(PI()/2)等于1。( 计算圆的面积的公式: S=PI()*(r^2),其中S为圆的面积,R为圆的半径。)
29. POWER
POWER(number,power):返回指定数字的乘幂。 Number:底数,可以为任意实数。 Power:指数。参数number按照该指数次幂乘方。
注: 可以使用符号“^”代替POWER,如: POWER(5,2)等于5^2。
示例:
POWER(6,2)等于36。(6^2=6*6)
POWER(14,5)等于537824。(14^5=14*14*14*14*14)
POWER(4,2/3)等于2.519842100。(=3√(4^2)即3√16)
POWER(3,-2.3)等于0.079913677。(3√(1/9))
30. PRODUCT
PRODUCT(number1,number2, ...):将所有以参数形式给出的数相乘,并返回乘积值。 number1, number2, ...:为 1到 n个需要相乘的数字参数。(参数个数的上限为30) 。
示例:
PRODUCT(3,4)等于 12。(3*4)
PRODUCT(3,4,5)等于 60。(3*4*5)
31. PROMOTION
PROMOTION(value1,value2):返回value2在value1上提升的比例.
示例:
PROMOTION(12, 14)等于0.166666666(即提升了16.6666666%.)。=(14-12)/12
PROMOTION(-12, 14)等于2.166666666(即提升了216.6666666%)。=(14-(-12))/12
32. RADIANS
RADIANS(angle):将角度转换成弧度。 Angle:需要转换为弧度的角度。
示例:
RADIANS(90)等于1.570796327(Pi/2弧度)。
33. RAND
RAND():返回一个随机数。数值位于区域[0,1],每计算一次工作表,函数都会返回一个新的随机数值。
注: 要生成一个位于a和b之间的随机数,可以使用以下的公式: =RAND()*(b-a)+a。
示例:
RAND()*60(生成一个大于等于0,小于60的随机数。)
RAND()*19(生成一个大于等于0,小于19的随机数。)
RAND()*50(生成一个大于等于0,小于50的随机数。)
其他变形生成方法:
①生成A与B之间的随机数字(A≤随机数<b)< span="">
在第一个格子中输入:RAND()*(B-A)+A
如,生成1到10之间的随机数字,输入:=RAND()*9+1
②生成A与B之间的随机整数(A≤随机数<b)< span="">
在第一个格子中输入:=INT(RAND9()*(B-A)+A)
如,生成1到10之间的随机整数,输入:=INT(RAND()*9+1)
其余数字,将鼠标置于该格子右下角,变为十字时,向下拖拉即可。
③生成A与B之间的随机整数的另一种方法(A≤随机数≤B)
在第一个格子中输入:RANDBETWEEN(A,B)即可。
如,生成1到10之间的随机整数,输入:=RANDBETWEEN(1,10)
如想得到1位随机小数,则输入:=RANDBETWEEN(1,100)/10,2位、3位依此类推=RANDBETWEEN(1,1000)/100,=RANDBETWEEN(1,10000)/1000
34. RANDBETWEEN
RANDBETWEEN(value1,value2):返回value1和value2之间的一个随机整数。
示例:
RANDBETWEEN(12.333, 13.233)只会返回13。
RANDBETWEEN(11.2, 13.3)有可能返回12或者13。
35. ROUND
ROUND(number,num_digits):返回某个数字按指定位数四舍五入后的数字。 number:需要进行四舍五入的数字。 num_digits:指定的位数,按此位数进行四舍五入。 如果 num_digits大于 0,则四舍五入到指定的小数位。 如果 num_digits等于 0,则四舍五入到最接近的整数。 如果 num_digits小于 0,则在小数点左侧进行四舍五入。
示例:
ROUND(2.15, 1)等于2.2。
ROUND(2.149, 1)等于2.1。
ROUND(-1.475, 2)等于 -1.48。
ROUND(21.5, -1)等于20。
36. ROUND5
ROUND5(number,num_digits):这个是四舍五入,奇数进位偶数不进位。number:需要进行舍入的数字。num_digits:指定的位数,按此位数进行舍入。
如果 num_digits 大于 0,则舍入到指定的小数位。
如果 num_digits 等于 0,则舍入到最接近的整数。
如果 num_digits 小于 0,则在小数点左侧进行舍入。
示例:
ROUND5(2.125, 2)等于 2.12。
ROUND5(2.135, 2) 等于 2.14。
37. ROUNDDOWN
ROUNDDOWN(number,num_digits):靠近零值,向下(绝对值减小的方向)舍入数字。 number:为需要向下舍入的任意实数。 num_digits:舍入后的数字的位数。
注: 函数 ROUNDDOWN和函数 ROUND功能相似,不同之处在于函数 ROUNDDOWN总是向下舍入数字。
示例:
ROUNDDOWN(3.2, 0)等于 3 。
ROUNDDOWN(76.9,0)等于 76。
ROUNDDOWN(3.14159, 3)等于 3.141 。
ROUNDDOWN(-3.14159, 1)等于 -3.1 。
ROUNDDOWN(31415.92654, -2)等于 31,400。
38. ROUNDUP
ROUNDUP(number,num_digits):远离零值,向上(绝对值增大的方向)舍入数字。 number:为需要向上舍入的任意实数。 num_digits:舍入后的数字的位数。 备注:函数 ROUNDUP和函数 ROUND功能相似,不同之处在于函数 ROUNDUP总是向上舍入数字。
示例:
ROUNDUP(3.2,0)等于 4
ROUNDUP(76.9,0)等于 77
ROUNDUP(3.14159, 3)等于 3.142
ROUNDUP(-3.14159, 1)等于 -3.2
ROUNDUP(31415.92654, -2)等于 31,500
39. SIGN
SIGN(number):返回数字的符号。当数字为正数时返回 1,为零时返回 0,为负数时返回 -1。 Number:为任意实数。
示例:
SIGN(10)等于 1。
SIGN(4-4)等于 0 。
SIGN(-0.00001)等于 -1。
40. SIN
SIN(number):计算给定角度的正弦值。 Number:待求正弦值的以弧度表示的角度。
注: 如果参数的单位是度,将其乘以PI()/180即可转换成弧度。
示例:
SIN(10)等于-0.544021111。
SIN(45*PI()/180)等于0.707106781。
41. SINH
SINH(number):返回某一数字的双曲正弦值。 number:为任意实数。
示例:
SINH(1)等于 1.175201194 。
SINH(-1)等于 -1.175201194。
42. SQRT
SQRT(number):返回一个正数的平方根。 Number:要求平方根的数。
注: Number必须是一个正数,否则函数返回错误信息NAN。
示例:
SQRT(64)等于8。
SQRT(-64)返回NaN。
43. SUM
SUM(number1,number2,…):求一个指定单元格区域中所有数字之和。 Number1,number2,…:1到30个参数或指定单元格区域中所有数字。
注: 函数将直接键入参数中的数值、逻辑值及文本表达式计算在内。 若参数是数组或引用,则只有数组或单元格引用中的数值进行计算。
示例:
SUM(70,80)等于150。
SUM("70",80,TRUE)等于151。(逻辑值“TRUE”作为1来计算;“FALSE”作为0计算;文本“70”作为70来计算。)
SUM(A1:A5)对A1到A5之间的格子中的数值求和。
SUM(A1:A5,50)对A1到A5之间的格子中的数值和数值50求和。
44. SUMSQ
SUMSQ(number1,number2, ...):返回所有参数的平方和。 number1, number2, ...:为 n个需要求平方和的参数(n的上限为30),也可以使用数组或对数组的引用来代替以逗号分隔的参数。
示例:
SUMSQ(3, 4)等于 25。(3^2+4^2=9+16)
45. TAN
TAN(number):返回指定角度的正切值。 Number:待求正切值的角度,以弧度表示。如果参数是以度为单位的,乘以Pi()/180后转换为弧度。
示例:
TAN(0.8)等于1.029638557。
TAN(45*Pi()/180)等于1。
46. TANH
TANH(number):返回某一数字的双曲正切值。 number:为任意实数。
示例:
TANH(-2)等于 -0.96403。
TANH(0)等于 0。
TANH(0.5)等于0.462117。
47. TOBINARY
TOBINARY(int):将一个十进制整型数转换成二进制表示的字符串。 int:表示需要进行转换的十进制整数。
示例:
TOBINARY(10)等于"1010"。
TOBINARY(20)等于"10100"。
48. TOHEX
TOHEX(int):将一个十进制整型数转换成十六进制表示的字符串。 int:表示需要进行转换的十进制整数。
示例:
TOHEX(15)等于"f"。
TOHEX(20)等于"14"。
49. TOOCTAL
TOOCTAL(int):将一个十进制整型数转换成八进制表示的字符串。 int:表示需要进行转换的十进制整数。
示例:
TOOCTAL(10)等于"12"。
TOOCTAL(20)等于"24"。
50. TRUNC
TRUNC(number,num_digits):取整。将数字的小数部分截去,返回整数。 number:需要截尾取整的数字。 num_digits:用于指定取整精度的数字。
示例:
TRUNC(8.9)等于 8。
TRUNC(-8.9)等于 -8。
TRUNC(PI())等于 3。
51. WEIGHTEDAVERAGE
WEIGHTEDAVERAGE(A1:A4,B1:B4): 返回指定数据的加权平均值。加权平均数是不同比重数据的平均数,加权平均数就是把原始数据按照合理的比例来计算。 A1:A4,B1:B4:用于计算平均值的参数,A1~A4为数据,B1~B4为权值。
示例:
如果A1:A4为10,9,8,7,B1:B4为0.2,0.1,0.3,0.4则:
WEIGHTEDAVERAGE(A1:A4,B1:B4)等于8.1。(10*0.2+9*0.1+8*0.3+7*0.4)/(0.2+0.1+0.3+0.4)
文本函数
1. CHAR
CHAR(number):根据指定数字代码返回对应的字符。CHAR函数可将计算机其他类型的数字代码转换为字符。
Number:用于指定字符的数字,介于1和65535之间(包括1和65535)。
示例:
CHAR(88)等于“X”。
CHAR(45)等于“-”。
2. CNMONEY
CNMONEY(number,unit)返回人民币大写。
number:需要转换的数值型的数。
unit:单位,"s","b","q","w","sw","bw","qw","y","sy","by","qy","wy"分别代表“拾”,“佰”,“仟”,“万”,“拾万”,“佰万”,“仟万”,“亿”,“拾亿”,“佰亿”,“仟亿”,“万亿”。
注:单位可以为空,如果为空,则直接将number转换为人民币大写,否则先将number与单位的进制相乘,然后再将相乘的结果转换为人民币大写。
示例:
CNMONEY(1200)等于壹仟贰佰圆整。
CNMONEY(12.5,"w")等于壹拾贰万伍仟圆整。
CNMONEY(56.3478,"bw")等于伍仟陆佰叁拾肆万柒仟捌佰圆整。
CNMONEY(3.4567,"y")等于叁亿肆仟伍佰陆拾柒万圆整。
3. CODE
CODE(text):计算文本串中第一个字符的数字代码。返回的代码对应于计算机使用的字符集。
Text:需要计算第一个字符代码的文本或单元格引用。
示例:
CODE("S")等于83。
CODE("Spreadsheet")等于83。
4. CONCATENATE
CONCATENATE(text1,text2,...):将数个字符串合并成一个字符串。
Text1,text2,...:需要合并成单个文本的文本项,可以是字符,数字或是单元格引用。
注: 也可以用"+"来代替CONCATENATE函数对文本项进行合并,"+"对数字无法合并,只能直接加法计算。
示例:
CONCATENATE("Average ","Price")等于“Average Price”。
CONCATENATE("1","2")等于12。
5. ENDWITH
ENDWITH(str1,str2):判断字符串str1是否以str2结束。 备注: str1和str2都是大小写敏感的。
示例:
ENDWITH("FineReport","Report")等于true
ENDWITH("FineReport","Fine")等于false。
ENDWITH("FineReport","report")等于false。
6. ENMONEY
ENMONEY(value):将给定的BigDemical类型的数字转换成英文金额字符串。
示例:
ENMONEY(23.49)等于TWENTY THREE AND CENTS FORTY NINE。
7. ENNUMER
ENNUMBER(value):将给定的BigDecimal类型的数字(100以内)取整后转化成英文金额的字符串。
示例:
ENNUMBER(23.49)等于TWENTY THREE。
注:若出现结果为空,需要将数字强制转换为BigDecimal类型,例如:ENNUMBER(TOBIGDECIMAL(80))
8. EXACT
EXACT(text1,text2):检测两组文本是否相同。如果完全相同,EXACT函数返回TRUE;否则,返回FALSE。EXACT函数可以区分大小写,但忽略格式的不同。同时也可以利用EXACT函数来检测输入文档的文字。
Text1:需要比较的第一组文本。
Text2:需要比较的第二组文本。
示例:
EXACT("Spreadsheet","Spreadsheet")等于TRUE。
EXACT("Spreadsheet","S preadsheet")等于FALSE。
EXACT("Spreadsheet","spreadsheet")等于FALSE。
9. FIND
FIND(find_text,within_text,start_num):从指定的索引(start_num)处开始,返回第一次出现的指定子字符串(find_text)在此字符串(within_text)中的索引。
Find_text:需要查找的文本或包含文本的单元格引用。
Within_text:包含需要查找文本的文本或单元格引用。
Start_num:指定进行查找字符的索引位置。within_text里的索引从1开始。如果省略start_num,则假设值为1。
注: 如果find_text不在within_text中,FIND函数返回值为0。
如果start_num不大于0,FIND函数返回错误信息*VALUE!。
如果start_num大于within_text的长度,FIND函数返回值为0。
如果find_text是空白文本,FIND函数将在搜索串中匹配第一个字符(即编号为start_num或1的字符)。
示例:
FIND("I","Information")等于1。
FIND("i","Information")等于9。
FIND("o","Information",2)等于4。
FIND("o","Information",12)等于0。
FIND("o","Information",-1)等于*VALUE!。
10. FORMAT
FORMAT(object,format) : 返回object的format格式。
object 需要被格式化对象,可以是String,数字,Object(常用的有Date, Time)。
示例:
FORMAT(1234.5, "#,##0.00") 等于 1234.50
FORMAT(1234.5, "#,##0") 等于 1234
FORMAT(1234.5, "¥#,##0.00") 等于 ¥1234.50
FORMAT(1.5, "0%") 等于 150%
FORMAT(1.5, "0.000%") 等于 150.000%
FORMAT(6789, "##0.0E0") 等于 6.789E3
FORMAT(6789, "0.00E00") 等于 6.79E03
FORMAT(date(2007,1,1), "EEEEE, MMMMM dd, yyyy") 等于 星期一,一月 01,2007
FORMAT(date(2007,1,13), "MM/dd/yyyy") 等于 01/13/2007
FORMAT(date(2007,1,13), "M-d-yy") 等于 1-13-07
FORMAT(time(16,23,56), "h:mm:ss a") 等于 4:23:56 下午
注:format对日期的操作,日期的大小写必须按照年份小写yy或yyyy,月份大写M或MM,日期小写d或dd。
11. INDEXOF
INDEXOF(str1,index):返回字符串str1在index位置上的字符。
注: index是从0开始计数的。
示例:
INDEXOF("FineReport",0)等于'F'。
INDEXOF("FineReport",2)等于'n'。
INDEXOF("FineReport",9)等于't'。
12. LEFT
LEFT(text,num_chars):根据指定的字符数返回文本串中的第一个或前几个字符。
Text:包含需要选取字符的文本串或单元格引用。
Num_chars:指定返回的字符串长度。
注: Num_chars的值必须等于或大于0。
如果num_chars大于整个文本的长度,LEFT函数将返回所有的文本。
如果省略num_chars,则默认值为1。
示例:
LEFT("Fine software",8)等于“Fine sof”。
LEFT("Fine software")等于“F”。
如果单元格A3中含有“China”,则:
LEFT(A3,2)等于“Ch”。
13. LEN
LEN(text):返回文本串中的字符数。
Text:需要求其长度的文本,空格也计为字符。
示例:
LEN("Evermore software")等于17。
14. LOWER
LOWER(text):将所有的大写字母转化为小写字母。
Text:需要转化为小写字母的文本串。LOWER函数不转化文本串中非字母的字符。
示例:
LOWER("A.M.10:30")等于“a.m.10:30”。
LOWER("China")等于“china”。
15. MID
MID(text,start_num,num_chars):返回文本串中从指定位置开始的一定数目的字符,该数目由用户指定。
Text:包含要提取字符的文本串。
Start_num:文本中需要提取字符的起始位置。文本中第一个字符的start_num为1,依此类推。
Num_chars:返回字符的长度。
注:
如果start_num大于文本长度,MID函数返回“”(空文本)。
如果start_num小于文本长度,并且start_num加上num_chars大于文本长度,MID函数将从start_num指定的起始字符直至文本末的所有字符。
如果start_num小于1,MID函数返回错误信息*VALUE!。
如果num_chars是负数,MID函数返回错误信息*VALUE!。
示例:
MID("Finemore software",10,8)返回“software”。
MID("Finemore software",30,5)返回“”(空文本)。
MID("Finemore software",0,8)返回*VALUE!。
MID("Finemore software",5,-1)返回*VALUE!。
16. NUMTO
NUMTO(number):返回number的中文表示。
示例:
NUMTO(2345)等于二千三百四十五。
17. PROPER
PROPER(text):将文本中的【第一个字母】和【空格后】的第一个字母转化成大写,其他字母变为小写。
Text:需要转化为文本的公式、由双引号引用的文本串或是单元格引用。
示例:
PROPER("Finemore Integrated Office")等于“Finemore Integrated Office”。
PROPER("100 percent")等于“100 Percent”。
PROPER("SpreaDSheEt")等于“Spreadsheet”。
18. REGEXP
(1)REGEXP(str, pattern):字符串str是否与正则表达式pattern相匹配。
示例:
REGEXP("aaaaac","a*c")等于true。
REGEXP("abc","a*c")等于false。
(2)REGEXP(str, pattern, intNumber):字符串str是否与具有给定模式 intNumber 的正则表达式pattern相匹配。
注:intNumber的模式如下所示
CASE_INSENSITIVE = 0 ——启用不区分大小写的匹配。
标志来启用 Unicode感知的、不区分大小写的匹配。 默认情况下,不区分大小写的匹配假定仅匹配 US-ASCII字符集中的字符。可以通过指定 UNICODE_CASE
MULTILINE = 1 ——启用多行模式。
DOTALL = 2 ——启用 dotall模式。
在 dotall模式中,表达式可以匹配任何字符,包括行结束符。默认情况下,此表达式不匹配行结束符。
UNICODE_CASE = 3——启用 Unicode感知的大小写折叠
指定此标志后,由CASE_INSENSITIVE标志启用时,不区分大小写的匹配将以符合 Unicode Standard的方式完成。
CANON_EQ = 4——启用规范等价。
指定此标志后,当且仅当其完整规范分解匹配时,两个字符才可视为匹配。
UNIX_LINES = 5——启用 Unix行模式。
在此模式中,.、^和 $的行为中仅识别 '\n'行结束符。
LITERAL = 6——启用模式的字面值解析。
指定此标志后,指定模式的输入字符串就会作为字面值字符序列来对待。输入序列中的元字符或转义序列不具有任何特殊意, 标志 CASE_INSENSITIVE和 UNICODE_CASE在与此标志一起使用时将对匹配产生影,其他标志都变得多余了。
COMMENTS = 7——模式中允许空白和注释。
此模式将忽略空白和在结束行之前以 #开头的嵌入式注释。
示例:
REGEXP("Aaaaabbbbc","a*b*c", 3)等于true
REGEXP("Aaaaabbbbc","a*b*c", 1)等于false。
19. REPLACE
(1)REPLACE(text, texttoreplace, replacetext):根据指定文本,用其他文本来替换原始文本中的内容。【文本:指不含格式信息的字符和字符串】
text:原始文本或单元格引用。
texttoreplace:被替换的文本。
replacetext: 替换的文本。
示例:
REPLACE("abcd", "a", "re")等于"rebcd"。即:将abcd中字符a用re来替换,形成新的字符串rebcd。
如果单元格a1为【saasas】,则:
REPLACE(a1,"a","B")等于【sBBsBs】。
(2)REPLACE(old_text,start_num,num_chars,new_text):根据指定长度,用其他文本来替换原文本中指定位置和长度的内容。
Old_text:原始文本或单元格引用。
Start_num: 替换的起始位置。
Num_chars:: 替换的长度,即被替换文本的字符数。
New_text: 替换的文本。
示例:
REPLACE("0123456789",5,4,"*")等于“0123*89”
REPLACE("1980",3,2,"99")等于“1999”。
注:
单元格引用、代表位置和长度的数字不能带引号;原始、替换和被替换的文本必须带英文引号(不区分单,双引号)。
第一种将替换所有符合条件的文本,第二种只替换指定位置的文本。
20. REPEAT
REPEAT(text,number_times): 根据指定的次数重复显示文本。REPEAT函数可用来显示同一字符串,并对单元格进行填充。
Text:需要重复显示的文本或包含文本的单元格引用。
Number_times:指定文本重复的次数,且为正数。如果number_times为0,REPEAT函数将返回“”(空文本)。如果number_times不是整数,将被取整。REPEAT函数的最终结果通常不大于32767个字符。
注: 该函数可被用于在工作表中创建简单的直方图。
示例:
REPEAT("$",4)等于“$$$$”。
如果单元格B10的内容为“你好”,则:
REPEAT(B10,3)等于“你好你好你好”。
21. RIGHT
RIGHT(text,num_chars):根据指定的字符数从右开始返回文本串中的最后一个或几个字符。
Text:包含需要提取字符的文本串或单元格引用。
Num_chars:指定RIGHT函数从文本串中提取的字符数。Num_chars不能小于0。
如果num_chars大于文本串长度,RIGHT函数将返回整个文本。如果不指定num_chars,则默认值为1。
示例:
RIGHT("It is interesting",6)等于“esting”。
RIGHT("Share Holder")等于“r”。
RIGHT("Huge sale",4)等于“sale”。
22. SPLIT
SPLIT(String1,String2):返回由String2分割String1组成的字符串数组。
String1:以双引号表示的字符串。
String2:以双引号表示的分隔符。例如逗号","
注:
如果只有一个参数,则返回一个错误。
如果有多个参数,则只有前两个起作用。
示例:
SPLIT("hello,world,yes",",") = ["hello","world","yes"]。
SPLIT("this is very good"," ") = ["this","is","very","good"]。
23. STARTWITH
STARTWITH(str1,str2):判断字符串str1是否以str2开始。
注: str1和str2都是大小写敏感的。
示例:
STARTWITH("FineReport","Fine")等于true。
STARTWITH("FineReport","Report")等于false。
24. SUBSTITUTE
SUBSTITUTE(text,old_text,new_text,instance_num):用new_text替换文本串中的old_text。
Text:需要被替换字符的文本,或含有文本的单元格引用。
Old_text:需要被替换的部分文本。
New_text:用于替换old_text的文本。
Instance_num:指定用new_text来替换第几次出现的old_text。如果指定了instance_num,则只有指定位置上的old_text被替换,否则文字串中出现的所有old_text都被new_text替换。
示例:
SUBSTITUTE("data base","base","model")等于“data model”。
SUBSTITUTE("July 28, 2000","2","1",1)等于“July 18, 2000”。
SUBSTITUTE("July 28, 2000","2","1")等于“July 18, 1000”。
SUBSTITUTE("July 28, 2000","2","1",2)等于“July 28, 1000”。
25. TODOUBLE
TODOUBLE(text):将文本转换成Double对象。
Text:需要转换的文本。
示例:
TODOUBLE("123.21")等于 new Double(123.21)。
26. TOINTEGER
TOINTEGER(text):将文本转换成Integer对象。
Text:需要转换的文本。
示例:
TOINTEGER("123")等于 123。
27. TRIM
TRIM(text):清除文本中所有空格,单词间的单个空格除外,也可用于带有不规则空格的文本。
Text:需要清除空格的文本。
示例:
TRIM(" Monthly Report")等于Monthly Report。
28. UPPER
UPPER(text):将文本中所有的字符转化为大写。
Text:需要转化为大写字符的文本,或是包含文本的单元格引用。
示例:
UPPER("notes")等于“NOTES”。
如果单元格E5的值为“Examples”,则:
UPPER(E5)等于“EXAMPLES”。
日期和时间函数
1. DATE
DATE(year,month,day):返回一个表示某一特定日期的系列数。
Year:代表年,可为一到四位数。
Month:代表月份。
若1<=month<= 12,则函数把参数值作为月。
若month>12,则函数从年的一月份开始往上累加。例如:DATE(2000,25,2)等于2002年1月2日的系列数。
Day:代表日。
若日期小于等于某指定月的天数,则函数将此参数值作为日。
若日期大于某指定月的天数,则函数从指定月份的第一天开始往上累加。若日期大于两个或多个月的总天数,则函数把减去两个月或多个月的余数加到第三或第四个月上,依此类推。
如:DATE(2000,3,35)等于2000年4月4日的系列数。
示例:
DATE(1978, 9, 19)等于1978年9月19日。
DATE(1211, 12, 1)等于1211年12月1日。
其中月和日为1到9之间的数字时,不需要在前面加上0而直接写数字如DATE(2011, 2, 1)即可。
2. DATEDELTA
DATEDELTA(date, deltadays):返回一个日期——date后deltadays的日期。deltaDays可以为正值,负值,零。
示例:
DATEDELTA("2008-08-08", -10)等于2008-07-29。
DATEDELTA("2008-08-08", 10)等于2008-08-18。
3. DATEDIF
DATEDIF(start_date,end_date,unit):返回两个指定日期间的天数、月数或年数。
Start_date:代表所指定时间段的初始日期。
End_date:代表所指定时间段的终止日期。
Unit:函数返回信息的类型。
若unit=“Y”,则DATEDIF返回指定时间段的年差数。
若unit=“M”,则DATEDIF返回指定时间段的月差数。
若unit=“D”,则DATEDIF返回指定时间段的日差数。
若unit=“MD”,则DATEDIF忽略年和月,返回指定时间段的日差数。
若unit=“YM”,则DATEDIF忽略年和日,返回指定时间段的月差数。
若unit=“YD”,则DATEDIF忽略年,返回指定时间段的日差数。
示例:
DATEDIF("2001/2/28","2004/3/20","Y")等于3,即在2001年2月28日与2004年3月20日之间有3个整年。
DATEDIF("2001/2/28","2004/3/20","M")等于36,即在2001年2月28日与2004年3月20日之间有36个整月。
DATEDIF("2001/2/28","2004/3/20","D")等于1116,即在2001年2月28日与2004年3月20日之间有1116个整天。
DATEDIF("2001/2/28","2004/3/20","MD")等于8,即忽略月和年后,2001年2月28日与2004年3月20日的差为8天。
DATEDIF("2001/1/28","2004/3/20","YM")等于2,即忽略日和年后,2001年1月28日与2004年3月20日的差为2个月。
DATEDIF("2001/2/28","2004/3/20","YD")等于21,即忽略年后,2001年2月28日与2004年3月20日的差为21天。
4. DATEINMONTH
DATEINMONTH(date, number):函数返回在某一个月当中第几天的日期。
示例:
DATEINMONTH("2008-08-08", 20)等于2008-08-20。
5. DATEINQUARTER
DATEINQUARTER(date, number):函数返回在某一个季度当中第几天的日期。
示例:
DATEINQUARTER("2009-05-05", 20)等于2009-04-20。
6. DATEINWEEK
DATEINWEEK(date, number):函数返回在某一个星期当中第几天的日期。
示例:
dateInWeek("2008-08-28", 2)等于2008-08-26。
7. DATEINYEAR
DATEINYEAR(date, number):函数返回在某一年当中第几天的日期。
示例:
dateInYEAR("2008/12/03", 300)等于2008-10-26。
8. DATESUBDATE
DATESUBDATE(date1, date2, op):返回两个日期之间的时间差。
op表示返回的时间单位:
"s",以秒为单位。
"m",以分钟为单位。
"h",以小时为单位。
"d",以天为单位。
"w",以周为单位。
示例:
DATESUBDATE("2008-08-08", "2008-06-06","h")等于1512。
9. DATETONUMBER
DATETONUMBER(date):返回自 1970 年 1月 1日 00:00:00 GMT经过的毫秒数。
示例:
DATETONUMBER("2008-08-08")等于1218124800000。
10. DAY
DAY:(serial_number)返回日期中的日。DAY是介于1和31之间的一个数。
Serial_number:含有所求的年的日期。
注: FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。
在1900年日期系统中,FineReport电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3,将1900年1月3日保存为系列数4……依此类推。如在1900年日期系统,1998年1月1日存为系列数35796。
示例:
DAY("2000/1/1")等于1。
DAY("2006/05/05")等于5。
DAY("1997/04/20")等于20。
DAY(35796)等于1。
11. DAYS360
DAYS360(start_date,end_date,method):按照一年 360天的算法(每个月以 30天计,一年共计 12个月),返回两日期间相差的天数,这在会计计算中将会用到的。如果财务系统是基于一年 12个月,每月 30天,可用此函数帮助计算支付款项。
Start_date和 end_date :是用于计算期间天数的起止日期。
Method:它指定了在计算中是采用欧洲方法还是美国方法。
Method定义:FALSE或忽略 美国方法 (NASD)。如果起始日期是一个月的 31号,则等于同月的 30号。如果终止日期是一个月的31号,并且起始日期早于 30号,则终止日期等于下一个月的 1号,否则,终止日期等于本月的 30号。
TRUE欧洲方法。无论是起始日期还是终止日期为一个月的 31号,都将等于本月的 30号。
注: FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。
在1900年日期系统中,FineReport电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3,将1900年1月3日保存为系列数4……依此类推。如在1900年日期系统,1998年1月1日存为系列数35796。
示例:
DAYS360("1998/1/30", "1998/2/1")等于 1
12. DAYSOFMONTH
DAYSOFMONTH(date):返回从1900年1月后某年某月包含的天数。
示例:
DAYSOFMONTH("1900-02-01")等于28
DAYSOFMONTH("2008/04/04")等于30
13. DAYSOFQUARTER
DAYSOFQUARTER(date):返回从1900年1月后某年某季度的天数。
示例:
DAYSOFQUARTER("2009-02-01")等于90
DAYSOFQUARTER("2009/05/05")等于91
14. DAYSOFYEAR
DAYSOFYEAR(year):返回1900年以后某年包含的天数。
示例:
DAYSOFYEAR(2008)等于366
15. DAYVALUE
DAYVALUE(date_text):返回代表date_text的一个系列数。此函数可用来把一个文本形式的日期转化为一个系列数。
Date_text:是在电子表格日期格式中代表日期的文本格式。例如“2000/2/28”
注: FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。在1900年日期系统中,永中Office电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3,将1900年1月3日保存为系列数4……依此类推。如在1900年日期系统,1998年1月1日存为系列数35796。
示例:
DAYVALUE("2000/1/1")等于36526。
16. HOUR
HOUR(serial_number):返回某一指定时间的小时数。函数指定HOUR为0(0:00)到23(23:00)之间的一个整数。
Serial_number:包含所求小时的时间。
示例:
HOUR("11:32:40")等于11。
17. MINUTE
MINUTE(serial_number):返回某一指定时间的分钟数,其值是介于0与59之间的一个整数。
Serial_number:包含所求分钟数的时间。
示例:
MINUTE("15:36:25")等于36。
18. MONTH
MONTH:(serial_number)返回日期中的月,月是介于1和12之间的一个数。
Serial_number:含有所求的月的日期。
注: FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。
在1900年日期系统中,FineReport电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3, 将1900年1月3日保存为系列数4……依此类推。
如:在1900年日期系统,1998年1月1日存为系列数35796。
示例:
MONTH("2004/5/5")等于5。
MONTH(35796)等于1。
19. MONTHDELTA
MONTHDELTA(date,delta):返回指定日期date后delta个月的日期。
示例:
MONTHDELTA("2008-08-08", 4)等于2008-12-08。
20. NOW
NOW():获取当前时间。
示例:
如果系统时间是2017-06-27 14:58:06, 则:
NOW()等于2017-06-27 14:58:06。
21. SECOND
SECOND(s erial_number):返回某一指定时间的秒数,其值是介于0与59之间的一个整数。
Serial_number:包含所求秒数的时间。
示例:
SECOND("15:36:25")等于25。
SECOND("15:36:25", "HH:mm:ss")等于25。
22. TIME
TIME(hour,minute,second):返回代表指定时间的小数。介于0:00:00(12:00:00 A.M.)与23:59:59(11:59:59 P.M.)之间的时间可返回0到0.99999999之间的对应数值。
TIME(19,43,24)等于7:43 PM
Hour:介于0到23之间的数。
Minute:介于0到59之间的数。
Second:介于0到59之间的数。
示例:
TIME(14,40,0)等于2:40 PM。
23. TODATE
TODATE()函数可以将各种日期形式的参数转换为日期类型。
它有三种参数的形式:
1)参数是一个日期型的参数,那么直接将这个参数返回。
示例:
TODATE(DATE(2007,12,12))返回2007-12-12组成的日期。
2)参数是以从1970年1月1日0时0分0秒开始的毫秒数,返回对应的时间。
示例:
TODATE("1023542354746")返回2002-6-8 21:19:14。
3)参数是日期格式的文本,那么返回这个文本对应的日期。
示例:
TODATE("2007/10/15")返回2007-10-15组成的日期。
TODATE("2007-6-8")返回2007-6-8组成的日期。
4)有两个参数,第一个参数是一个日期格式的文本,第二个参数是用来解析日期的格式。
示例:
TODATE("1/15/07","MM/dd/yy")返回2007-01-15组成的日期.
注:此处的格式中月份必须大写MM,年份小写:yy(不可以为yyyy)。天份小写:dd
24. TODAY
TODAY():是获取当前的日期。
示例:
如果系统日期是2011-06-20,则:
TODAY()等于2011-06-20。
25. WEEKDAY
WEEKDAY(Serial_number):获取日期并返回星期数。返回值为介于0到6之间的某一整数,分别代表星期中的某一天(从星期日到星期六)。
Serial_number:输入的日期。
注: FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。
在1900年日期系统中,FineReport电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3,将1900年1月3日保存为系列数4……依此类推。如在1900年日期系统,1998年1月1日存为系列数35796。
示例:
WEEKDAY("2005/9/10")等于6(星期六)。
WEEKDAY("2005/9/11")等于0(星期日)。
WEEKDAY(35796)等于4(星期四)。
26. WEEK
WEEK(serial_num):返回一个代表一年中的第几周的数字。
1)默认周开始于星期日时,此时系统中周的范围为星期日到星期六。
Serial_num:表示输入的日期。
注:FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。
在1900年日期系统中,FineReport电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3,将1900年1月3日保存为系列数4……依此类推。
如在1900年日期系统,1998年1月1日存为系列数35796。
示例:
WEEK("2005/1/1")等于52。
WEEK("2005/1/6")等于1。
WEEK(35796)等于52。
2010-01-01是星期五,那么2010-01-01就不能算在2010年的第一个星期里面,只算在2009年的最后一个星期里。
2010年的第一个星期的第一天应该是2010-01-03,因为2010-01-03是2010年的第一个星期日。
2)当设置周开始于星期一时,此时系统中周的范围为星期一到星期日。
2010年的第一个星期的第一天应该是2010-01-04,因为2010-01-04是2010年的第一个星期一。
27. WEEKDATE
WEEKDATE(year,month,weekOfMonth,dayOfWeek):返回指定年月的指定周的周几的具体日期。
1)默认周开始于星期日时,此时系统中周的范围为星期日到星期六。
示例:
WEEKDATE(2009,10,2,1)返回的是2009年的10月的第二个周的第一天即星期天的日期,返回的是2009-10-04;
最后一个参数dayOfWeek为-1时,表示这个周的最后一天。
示例:
WEEKDATE(2009,12,1,-1)返回的是2009年的12月的第一个周的最后一天即星期六的日期,返回的是2009-12-05。
2)当设置周开始于星期一时,此时系统中周的范围为星期一到星期日。
28. YEAR
YEAR:(serial_number)返回日期中的年。Year是介于1900和9999之间的一个数。
Serial_number:含有所求的年的日期。
注: FineReport将日期保存为系列数,一个系列数代表一个与之匹配的日期,以方便用户对日期进行数值式计算。
在1900年日期系统中,FineReport电子表格将1900年1月1日保存为系列数2,将1900年1月2日保存为系列数3,将1900年1月3日保存为系列数4……依此类推。
如:在1900年日期系统,1998年1月1日存为系列数35796。
示例:
YEAR("2000/1/1")等于2000。
YEAR("2006/05/05")等于2006。
YEAR("1997/04/20")等于1997。
YEAR(35796)等于1998。
29. YEARDELTA
YEARDELTA(date, delta):返回指定日期后delta年的日期。
示例:
YEARDELTA("2008-10-10",10)等于2018-10-10。
30. LUNAR
LUNAR(year,day,month): 返回当前日期对应的农历时间。year,month,day:分别对应年月日。
示例:
如果需要查询2011年7月21日对应的农历时间,则:
LUNAR(2011,7,21)结果将显示为:辛卯年六月廿一。
LUNAR(2001,7,21)结果显示:辛巳年六月初一 。
逻辑函数
1. AND
AND(logical1,logical2,…):当所有参数的值为真时,返回TRUE;当任意参数的值为假时,返回FALSE。 Logical1,logical2,…:指1到30个需要检验TRUE或FALSE的条件值。
注: 参数必须是逻辑值,或是含有逻辑值的数组或引用。 如果数组或引用中含有文本或空的单元格,则忽略其值。 如果在指定的单元格区域中没有逻辑值,AND函数将返回错误信息*NAME?。
示例:
AND(1+7=8,5+7=12)等于TRUE。
AND(1+7=8,5+7=11)等于FALSE。
如果单元格A1到A4的值分别为TRUE、TRUE、FALSE和TRUE,则:
AND(A1:A4)等于FALSE。
如果单元格A5的值在0~50之间,则:
AND(A5<50)等于TRUE。
2. BITNOT
BITNOT(int):将一个十进制整数进行二进制取反运算。
int:需要进行转换的十进制数。
示例:
BITNOT(3)等于-4。
BITNOT(12)等于-13。
3. BITOPERATIOIN
BITOPERATIOIN(int,int,op) 位运算,返回两个整数根据op进行位运算后的结果。
int:十进制整数。
op:位运算操作符,支持"&"(与),"|"(或),"^"(异或),"<<"(左移),">>"(右移)。
示例:
BITOPERATION(4,2,"&")表示4与2进行"与"运算,结果等于0。
BITOPERATION(4,2,"|")表示4与2进行"或"运算,结果等于6。
BITOPERATION(4,2,"^")表示4与2进行"异或"运算,结果等于6。
BITOPERATION(4,2,"<<")表示4按位左移2位,结果等于16。
BITOPERATION(4,2,">>")表示4按位右移2位,结果等于1。
BITOPERATION(4,2,"^~")表示4与2进行"同或"运算,结果为-7。
4. IF
IF(boolean,number1/string1,number2/string2):判断函数,boolean为true时返回第二个参数,为false时返回第三个。 boolean:用于判断的布尔值,true或者false。 number1/string1:第一个参数,如果boolean为ture,返回这个值。 number2/string2:第二个参数,如果boolean为false,返回这个值。
示例:
IF(true,2,8)等于2。
IF(false,"first","second")等于second 。
IF(true,"first",7)等于first。
5. OR
OR(logical1,logical2,…): 当所有参数的值为假时,返回FALSE;当任意参数的值为真时,返回TRUE。
Logical1,logical2,…:指1到30个需要检验TRUE或FALSE的条件值。
备注:
参数必须是逻辑值,或是含有逻辑值的数组或引用。
如果数组或引用中含有文本或空的单元格,则忽略其值。
如果在指定的单元格区域中没有逻辑值,AND函数将返回错误信息*NAME?。
示例:
OR(1+7=9,5+7=11)等于FALSE。
OR(1+7=8,5+7=11)等于TRUE。
6. REVERSE
REVERSE(value):返回与value相反的逻辑值。
示例:
REVERSE(true)等于false。
7. switch
switch(表达式, 值1, 结果1, 值2, 结果2, ...)
如果表达式的结果是值1,整个函数返回结果1
如果表达式的结果是值2,整个函数返回结果2
如果表达式的结果是值3,整个函数返回结果3
等等
数组函数
1. ADD2ARRAY
ADD2ARRAY(array, insertArray, start):在数组array的第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADD2ARRAY([3, 4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7]。
ADD2ARRAY([3, 4, 1, 5, 7], "测试", 3)返回[3, 4, "测试", 1, 5, 7]。
注:如果start为小于1的数或者不写start参数,则默认从数组的第一位开始插入数组元素。
2. ARRAY
ARRAY(arg1,arg2...):返回一个由arg1,arg2,...组成的数组. [arg1,arg2,...]可以由字符串或者数字构成。
示例:
ARRAY("hello")返回[hello]。
ARRAY("hello","world")返回[hello,world]。
ARRAY("hello",98)返回[hello,98]。
ARRAY(67,98)返回[67,98]。
3. GREPARRAY
GREPARRAY(array,fn):通过fn过滤array数组,返回过滤后的新数组。过滤函数必须返回 true 以保留元素或 false 以删除元素。
array为待过滤数组,fn为过滤函数。
示例:
GREPARRAY([3,4,2,3,6,8,7], item != 3)返回[4,2,6,8,7] 。
4. INARRAY
INARRAY(co, array):返回co在数组array中的位置,如果co不在array中,则返回0。
示例:
如果String[] arr = {"a","b","c","d"} ,则:
INARRAY("b", arr)返回2。
INARRAY("e", arr)返回0。
5. INDEXOFARRAY
INDEXOFARRAY(array, index):返回数组array的第index个元素。
示例:
INDEXOFARRAY(["第一个", "第二个", "第三个"], 2)返回"第二个"。
6. MAPARRAY
MAPARRAY(array, fn):批量处理数组,通过fn对数组中的元素进行转换。 array:要转换的数组;fn:处理数组项目的函数 。
示例:
MAPARRAY([3,4,2,3,6,8,7], item != 3)返回[false,true,true,false,true,true,true]。
MAPARRAY([3,4,2,-3,6,8,-5],if(item>0,1,0)),返回[1,1,1,0,1,1,0]。
7. RANGE
RANGE(from,to,step)函数表示从整数from开始,以step为每一步的示例:直到整数to的一个数字序列。
注: RANGE函数有三种参数形式,第一种RANGE(to),缺省默认from为1,step为1 ;第二种RANGE(from,to),默认的step为1;第三种RANGE(from,to,step),参数的情况参照上面的注释。
示例:
RANGE(4)返回[1,2,3,4]。
RANGE(-5)返回[]。
RANGE(-1,3)返回[-1,0,1,2,3]。
RANGE(0,5)返回[0,1,2,3,4,5]。
RANGE(6,-1,-2)返回[6,4,2,0]。
RANGE(4,1,1)返回[]。
8. REMOVEARRAY
REMOVEARRAY(array, start, deleteCount):从数组array中删除从第start个元素开始的deleteCount个数组元素,并返回删除后的数组。
示例:
REMOVEARRAY([3, 4, 4, 2, 6, 7, 87], 4, 2)返回[3, 4, 4, 7, 87]。
9. REVERSEARRAY
REVERSEARRAY(array):返回数组array的倒序数组。
示例:
REVERSEARRAY(["第一个", "第二个", "第三个"])返回["第三个", "第二个", "第一个"]
注:使用REVERSEARRAY函数时,参数必须是数组,如果参数不是数组,必须使用SPLIT函数将其转换为数组,SPLIT函数使用参见SPLIT。
10. SLICEARRAY
SLICEARRAY(array, start, end):返回数组从第start个到第end个元素(包括第end个元素)。
示例:
SLICEARRAY([3, 4, 4, 5, 1, 5, 7], 3, 6)返回[4, 5, 1, 5]。
SLICEARRAY([3, 4, 4, 5, 1, 5, 7], 3)返回[4, 5, 1, 5, 7]。
注:当不使用end参数时,返回从start开始到数组结束之间的元素。
11. SORTARRAY
SORTARRAY(array):返回数组array排过序的数组 ,默认升序排列。
示例:
SORTARRAY([3, 4, 4, 5, 1, 5, 7])返回[1, 3, 4, 4, 5, 5, 7]。
注:数组array的元素类型必须一样,并且要可比较。
12. UNIQUEARRAY
UNIQUEARRAY(array):去重,去掉数组array中的重复元素,以保留第一次出现的元素为序,返回去重之后的数组。
示例:
UNIQUEARRAY([14, 2, 3, 4, 3, 2, 5, 6, 2, 7, 9, 12, 3])返回[14, 2, 3, 4, 5, 6, 7, 9, 12]。
报表函数
1. CNMONEY
CNMONEY(number,unit)返回人民币大写。
number:需要转换的数值型的数。 unit:单位,"s","b","q","w","sw","bw","qw","y","sy","by","qy","wy"分别代表“拾”,“佰”,“仟”,“万”,“拾万”,“佰万”,“仟万”,“亿”,“拾亿”,“佰亿”,“仟亿”,“万亿”。
注: 单位可以为空,如果为空,则直接将number转换为人民币大写,否则先将number与单位的进制相乘,然后再将相乘的结果转换为人民币大写。
示例:
CNMONEY(1200)等于壹仟贰佰圆整。
CNMONEY(12.5,"w")等于壹拾贰万伍仟圆整。
CNMONEY(56.3478,"bw")等于伍仟陆佰叁拾肆万柒仟捌佰圆整。
CNMONEY(3.4567,"y")等于叁亿肆仟伍佰陆拾柒万圆整。
2. COL
COL()返回当前单元格的列号。
示例:
如果当前单元格是A5,在A5中写入:
=col()返回1。
如果当前单元格是C6,在C6中写入:
=col()返回3。
3. COLCOUNT
COLCOUNT(tableData):返回tableData中列的个数。 tableData:tableData的名字,字符串形式的。
注: 先从私有数据源中查找,然后再从公有数据源中查找,返回的是第一个查找到的tableData中列数。
示例:
以我们提供的数据源FRDemo为例:
新建数据集ds1:SELECT * FROM CUSTOMER
COLCOUNT("ds1")等于6。
4. COLNAME
COLNAME(tableData,colIndex)返回的是tableData中列序号colIndex的列名。 tableData:表示TableData的名字,字符串形式。 colIndex:表示列序号。
注: TableData先从私有数据源中查找,再从公有数据源中查找。
示例:
以我们提供的数据源FRDemo为例:
新建数据集ds1:SELECT * FROM CUSTOMER
COLNAME("ds1",3)等于CITY。
5. FIELDS
FIELDS(connectionName,tableName):返回tableName这个表中的所有字段名。
示例:
以我们提供的数据源FRDemo为例:
FIELDS("FRDemo","CUSTOMER")等于CUSTOMERID,CUSTOMERNAME,CITY,COUNTRY,TEL,DISTRICT
6. MAP
MAP(object, string, int, int):四个参数分别是索引值,数据集的名字,索引值所在列序号,返回值所在列序号。
提醒:后两个参数也可以写列名代替。
根据数据集的名字,找到对应的数据集,找到其中索引列的值为key所对应的返回值。
数据集的查找方式是依次从报表数据集找到服务器数据集。
索引列序号与返回值序列号的初始值为1
示例:
MAP(1001, "employee", 1, 2)返回employee数据集,第1列中值为1001那条记录中第2列的值。
MAP(1001, "employee", "name", "address")返回employee数据集,name列中值为1001那条记录中address列的值。
7. RECORDS
RECORDS(connection, table,field):返回数据库表table中字段名field下的所有元素。
示例:
数据库BASE中有个名叫task的表的内容如下:
|
name
|
start
|
end
|
|
a
|
2008
|
2009
|
|
b
|
2009
|
2012
|
那么RECORDS("BASE","task","end")等于[2009,2012].
RECORDS(connection, table,field,row)返回table中field字段下的第row行的记录,field可以为列名也可以为列号。
RECORDS("BASE","task","end",2)等于2012.
RECORDS("BASE","task",2,2)等于2009.
8. REVERSE
REVERSE(value):返回与value相反的逻辑值。
示例:
REVERSE(true)等于false。
9. ROW
ROW()返回当前单元格的行号。
示例:
如果当前单元格为A5,在A5中写入"=ROW()"则返回5。
如果当前单元格为B8,在B8中写入"=ROW()"则返回8。
具体示例:见条件属性专题章节中,条件属性中的Row()函数的内容。
10. ROWCOUNT
ROWCOUNT(tableData):返回tableData的行数。
tableData:TableData的名字,字符串形式的。
备注:
先从私有数据源中查找,然后再从公有数据源中查找,返回的是tableData的行数。
示例:
以我们提供的数据源FRDemo为例
新建数据集ds1:SELECT * FROM CUSTOMER
ROWCOUNT("ds1")等于20。
11. TABLEDATAFIELDS
TABLEDATAFIELDS(tableData):返回tableData中所有的字段名。
注: 先从报表数据集中查找,然后再从服务器数据集中查找,返回的是tableData的列名组成的数组。
示例:
以我们提供的数据源FRDemo为例
新建数据集ds1:SELECT * FROM CUSTOMER
TABLEDATAFIELDS("ds1")等于CUSTOMERID,CUSTOMERAME,CITY,COUNTRY,TEL,DISTRICT。
12. TABLEDATAS
TABLEDATAS():返回报表数据集和服务器数据集名字。
示例:
服务器数据集有:ds1,ds2,ds3;报表数据集有dsr1,dsr2,则:
TABLEDATAS()等于[dsr1,dsr2,ds1,ds2,ds3]。
而TABLEDATAS(0)返回服务器数据集名字;TABLEDATAS(1)返回报表数据集名字;
TABLEDATAS(0)等于[ds1,ds2,ds3]。
TABLEDATAS(1)等于[dsr1,dsr2]。
13. TABLES
TABLES(connectionName):返回名为connectionName的数据库中的所有表名。
示例:
假设在FRDemo这个数据库中,有3个表:a,b,c,则:
TABLES("FRDemo")等于[a,b,c]。
14. VALUE
VALUE(tableData,col,row):返回tableData中行号为row,列号为col的值。 tableData:tableData的名字,字符串形式的。 row:行号。 col:列号。
注: 先从私有数据源中查找,然后再从公有数据源中查找,返回的是tableData的符合条件的值。
示例:
VALUE("country",5,3)等于South America。
VALUE("Simple",8,3)等于jonnason。
VALUE(tableData,col)返回tableData中列号为col的一列值。
VALUE(tableData,targetCol, orgCol, element)返回tableData中第targetCol列中的元素,这些元素对应的第orgCol列的值为element。
示例:
tableData : co
|
国家
|
省份
|
|
中国
|
江苏
|
|
中国
|
浙江
|
|
中国
|
北京
|
|
美国
|
纽约
|
|
美国
|
新泽西
|
VALUE("co",2, 1, "中国")等于["江苏", "浙江", "北京"]。
注:列号也可以写为列名。
VALUE(tableData,targetCol, orgCol, element, idx)返回VALUE(tableData,targetCol, orgCol, element)数组的第idx个值。
注:idx的值小于0时,会取数组的第一个值,idx的值大于数组长度时,会取数组的最后一个值。
其他函数
1. CLASS
CLASS(object):返回object对象的所属的类。
2. CORREL
CORREL(array1,array2): 求两个相同长度数据系列的相关系数(与Excel的同名函数作用相同)。如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。 函数计算结果出现负数表示负相关。相关系数的取值范围是[-1,1]之间的数。相关系数的绝对值越大,表示误差越小。 Array1 和 Array2 的数据点的个数必须相同。
示例:
CORREL([1,2,3],[2,4,6])等于1。
3. DECODE
deocde(string):使用指定的编码机制(UTF-8)对application/x-www-form-urlencoded字符串解码。给定的编码用于确定任何 “%xy”格式的连续序列表示的字符。
示例:
decode("%E5%B8%86%E8%BD%AF")等于帆软。
4. ENCODE
encode(string):使用指定的编码机制(UTF-8)将字符串转换为application/x-www-form-urlencoded格式。该方法使用提供的编码机制获取不安全字符的字节。
示例:
encode("帆软")等于 “%E5%B8%86%E8%BD%AF”。
5. EVAL
EVAL(exp):返回表达式exp计算后的结果。 exp:一个表达式形式字符串。备注:只要EVAL中的参数exp最终可以转化成一表达式形式的字符串。
注: 只要EVAL中的参数exp最终可以转化成一表达式形式的字符串,比如"sum(2,4)","2+7"等等,那么它就可以被计算。
示例:
EVAL("2+5")等于7。
EVAL("count(2,3)")等于2。
EVAL("sum"+"(2,3,5)")等于10。
EVAL(IF(true, "sum", "count") + "(1,2,3,4)")等于10。
EVAL(IF(false, "sum", "count") + "(1,2,3,4)")等于4。
6. INDEX
INDEX(key,val1,val2,...):返回key在val1,val2,...所组成的序列中的位置,不存在于序列中则返回参数的个数。
注: key和valn可以是任意类型。
示例:
INDEX(2,2)等于1。
INDEX(2,1,2)等于2。
INDEX(2,4,5,6)等于4。
INDEX("b","b","o","y")等于1。
7. ISNULL
ISNULL(object):判断对象中所有的值是否全部都是NULL或者为空字符串。
8. LET
LET(变量名,变量值,变量名,变量值,..., 表达式):局部变量赋值函数,参数的个数N必须为奇数, 最后一个是表达式,前面是N-1(偶数)为局部变量赋值对。 变量名: 必须是合法的变量名,以字母开头,可以包括字母,数字和下划线。 表达式: 根据前面的N-1个参数赋值后计算出来的结果,这些变量赋值只在这个表达式内部有效
示例:
LET(a, 5,b, 6, a+b)等于11。
9. MEDIAN
MEDIAN(array1):返回数据系列的中值(与Excel的同名函数作用相同)。
1)当数据元素数量是奇数时,取最中间的元素。
示例:
MEDIAN([1,2,3])等于2。
2)当数据元素数量是偶数时,取最中间两个元素的算术平均值。
示例:
MEDIAN(1,2,3,-1)等于1.5。
注:在报表服务器版本为8.0及以上时,先将数据元素进行排序,再取中位数,结果为1.5,这样的结果正确;而在报表服务器为8.0之前,报表不进行排序,直接去掉左右两边的值,结果为2.5,这样的结果不正确
10. NVL
NVL(value1,value2):返回第一个不为null的value值,如果value1不为null,则返回value1的值,否则返回value2的值,如果value1和value2都是null,则返回null。 value1:可以为任意数,也可以为null。 value2:可以为任意数,也可以为null。
注: 此处的NVL(value1,value2)为短路运算符。即当第一个不为空的情况下,直接返回第一个的值,对后面的将不再运算。也可以为null。
示例:
NVL(12,20)等于12。
NVL(null,12)等于12。
11. RANK
RANK(number,ref,order):返回一个数在一个数组中的秩。(如果把这个数组排序,该数的秩即为它在数组中的序号。) Number 所求秩的数。(可以是Boolean型,true=1,false=0) ,Ref 可以是数组,引用,或一系列数,非实数的值被忽略处理(接受Boolean型,true=1,false=0)。 Order 指定求秩的参数,非零为升序,零为降序。
注: RANK对重复的数返回相同的秩,但重复的数影响后面的数的秩,比如,在一组升序排列的整数中,如果5出现了2次,并且秩为3,那么6的秩为5 (没有数的秩是4)。
示例:
如果,A1:A5 = 6, 4.5, 4.5, 2, 4 则:
RANK(A1,A1:A5,1) 等于5。(即 :升序排列时,A1中的6的秩为 5)
RANK(3,1,2,"go",3,4,1)等于3.("go"被忽略。)
12. SEQ
SEQ():返回数值,在整个报表执行过程中,返回该函数被第几次执行了。
示例:
SEQ()在第一次执行时,结果为1。
SEQ()在第二次执行时,结果为2。
13. STDEV
STDEV(array1):计算数据系列的标准偏差(与Excel的同名函数作用相同)。
示例:
STDEV([1,2,3])等于1。
14. TOIMAGE
TOIMAGE(path):显示指定路径下的图片。此处默认开启了图片缓存功能以加速报表的生成。如不需要缓存,请在参数后面追加值FALSE。
示例:
TOIMAGE("D:/fr.png",false)
15. WEBIMAGE
WEBIMAGE(path):显示网页上的图片。可以提升web图片加载速度。
示例:
WEBIMAGE('http://www.fanruan.com/images/index2.jpg')
16. UUID
UUID():返回随机的UUID。
目前只支持两种位数的随机数,如下:
UUID()返回36位随机机器数。
UUID(32)返回32位随机机器数。
层次坐标函数
1. CIRCULAR
循环引用, =CIRCULAR(A1, B1, C1, D1)等同于=IF(&A1 = 1, 0, B1[A1:-1] + C1[A1:-1] – D1[A1:-1]);
如需横向, 则传递第五个参数false,=CIRCULAR(A1, B1, C1, D1,false)
具体使用场景请参考循环引用
2. CROSSLAYERTOTAL
跨层累计, =CROSSLAYERTOTAL(A1, B1, C1, D1)等同于=IF(&B1 >1, D1[B1:-1] + C1, D1[A1:-1,B1:!-1] + C1);
如需横向, 则传递第五个参数false,=CROSSLAYERTOTAL(A1, B1, C1, D1,false)
具体使用场景请参考跨层累计
3. HIERARCHY
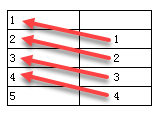
层次坐标简写,=HIERARCHY(A1)等同于=A1[A1:-1],表示获取当前单元格(即A1)往上偏移一个单元格的值;若需=B1[A1:-1],则HIERARCHY(A1, B1),表示当前单元格(即B1),所在的A1单元格往上偏移一个位置对应的B1单元格。若为横向,偏移量为-1,则写成HIERARCHY(A1, B1, -1,false),等同于=B1[;A1:-1]。公式中最后一个参数表示横纵向,默认不传递,表示纵向扩展,若横向扩展,则需要加上最后一个参数FALSE来区分。
示例:
在A1单元格中输入=range(5),扩展方向选择纵向,在B1单元格输入公式HIERARCHY(A1),预览效果如下:
4. LAYERTOTAL
逐层累计, =LAYERTOTAL(B1, C1, D1)等同于=D1[B1:-1] + C1;
如需横向, 则传递第四个参数false,=LAYERTOTAL(B1, C1, D1, false)
具体使用场景请参考逐层累计
5. MOM
环比公式,=MOM(A1, B1)等同于=IF(&A1 > 1, B1 / B1[A1:-1],0);
其中如果需要指定偏移量x,则传递第三个参数x,第四个参数表示横纵向,=MOM(A1, B1, -2, false)等同于=IF(&A1 > 1, B1 / B1[;A1:-2], 0)。
示例:
MOM(A1, B1, -2,true)表示当&A1>1时,B1单元格的值比上该B1单元格对应的上一个B1单元格的值,否则显示为0,等同于=IF(&A1 > 1, B1 / B1[A1:-2])。
具体使用场景请参考环比
6. PROPORTION
占比公式, =PROPORTION(A1)等同于=A1/sum(A1[!0])
具体使用场景请参考占比
7. SORT
排名公式, =SORT(A1)等同于=COUNT(A1[!0]{A1 > $A1}) + 1, 默认升序排列,;
如需要降序, 则传递参数false,=SORT(A1, false)等同于=COUNT(A1[!0]{A1 < $A1}) + 1.
拥有自信,努力奋斗,保持乐观积极地情绪,逆着阳光,成功就在前方。自己选择的路,放弃者绝不会成功,成功者绝不放弃。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?