理解 Roslyn 中的红绿树(Red-Green Trees)
Roslyn 的 API 是非常易用的。即便如此复杂的 C# 语法,建立的复杂的 C# 语法树,还有其复杂的树遍历和修改过程,也都被其 API 包装得干净简洁。
而这背后是它的重要设计思路 —— 红绿树。
红绿树的影子
如果你是通过搜索找到这篇文章的,那么至少证明你调试过 Roslyn API 的使用,或者阅读过 Roslyn 的源码。因为正常使用 Roslyn 的 API 时你是看不到红绿树的,这是 Roslyn 的实现细节。但你在调试的时候可能会看到 Green 属性,或者在阅读源码时看到 GetRed 方法。
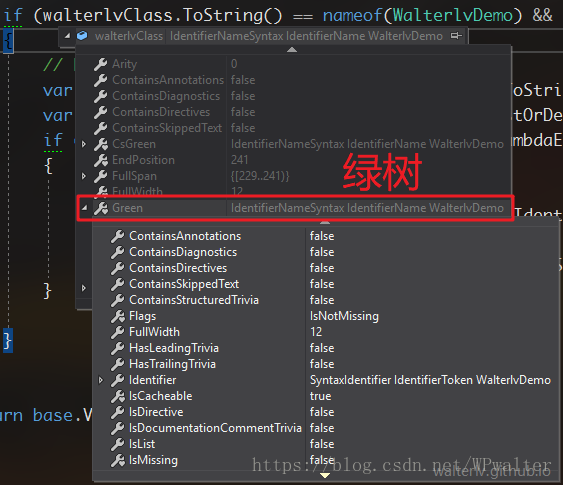
▲ 调试时看到的绿树
protected T GetRed<T>(ref T field, int slot) where T : SyntaxNode
{
var result = field;
if (result == null)
{
var green = this.Green.GetSlot(slot);
if (green != null)
{
Interlocked.CompareExchange(ref field, (T)green.CreateRed(this, this.GetChildPosition(slot)), null);
result = field;
}
}
return result;
}▲ Roslyn 中获取红树的源代码
源代码摘抄自:roslyn/SyntaxNode.cs at master · dotnet/roslyn。
Roslyn 的设计理念
Roslyn 一开始就将漂亮的 API 作为目标的一部分,同时还要非常高的性能;所以 Roslyn 的开发团队需要找到一种特殊的数据结构来描述语言(如 C#)的语法。这种数据结构要满足这些期望的要求:
- 不可变(Immutable)
- 树的形式
- 可以容易地访问父节点和子节点
- 可以非常容易地将任何一个节点对应到源代码文件的一段文本区间
- 可重用(Persistent)
最后一个的英文说法是 Persistent,单词的原本意思是“可持久的,连续的”,我把它翻译为“可重用”(Reusable)。Roslyn 的设计中有一个重要的业务需求,希望能够分析源代码文件并在开发者编辑的过程中不断提供建议。也就是说,当我们连续不断地去修改源代码中的文本内容时,Roslyn 也需要具备很高的性能。如果每次编辑代码都去重新解析一次整份源代码,然后全部重新生成整个数据结构,那将是大量的性能浪费;更不可能实时去分析开发者编辑的源码。所以,在 Roslyn 的设计中,希望源代码文本改变时,整棵树中的大多数节点都是能够重复使用的(无需重新生成)。
而如果将数据结构设计成不可变的(Immutable),那么重用这些节点将会非常容易。当然不止对于 Roslyn,对其它数据来说,不可变也一样有各种好处;比如可以随时重用这份数据的实例而不用担心可能被各个不同的业务模块意外修改,比如天然是线程安全的。
那么问题来了,到底什么样的数据结构能够在同时满足以上所有的特点的前提下,同时还能设计出简单易用的 API 呢?
- 既然要容易地访问到父节点和子节点,那么我们是先构造父节点还是子节点呢?如果先构造父节点,那子节点还没有创建出来;而先构造子节点,那父节点就没构造出来。我们要求这样的数据结构具有不可变性,所以我们不可能先把它们都构造出来再去修改它们的父子关系。
- 还有,我们也不能随意地去为任何子节点指定新的父节点,因为子节点是不可变的。然而我们同时有希望能够在连续修改的情况下具备较高的性能,如果连修改父节点都不能办到,那也很难重用之前的节点,最终不得不再次重新生成所有的子节点。
- 另外,如果你在源代码文件中插入了一个字符,那么这个字符后面的每一个节点对应的源代码区间都需要改变。然而这非常不利于连续修改,因为随便一个字符的插入都将导致更新大量节点中的文本区间信息。而由于不可变性,我们只能重新生成这些节点而没法儿重用它们。
于是 Roslyn 团队就折腾出了“红绿树”(Red-Green Trees)。
红绿树
红绿树并不是一棵树,而是两棵树。
绿树(the green tree)是不可变的,可重用的,没有父节点的引用。绿树的构建是自下而上的,每一个节点都保存它在文本区间中的字符个数(说通用点是宽度)。如果源代码的内容被编辑,我们只需要重新创建受编辑影响的绿树的部分;相比于重新分析整棵树,其时间复杂度只有 O(log n)。
红树(the red tree)也是不可变的,是围绕绿树而建的外观(参见 外觀模式)。红树的构建是自上而下的,但红树只在需要时才会创建,而一旦编辑了源代码文件,红树就直接丢弃不用了。如果有需要,红树就会开始创建;它会根据绿树自上而下计算最新的父节点引用,计算节点最新对应的文本区间。
这两棵树设计起来协同工作,前者负责解决 Roslyn 语法分析的性能问题,后者负责对开发人员提供友好的 API 调用。由于最开始 Roslyn 团队的大佬们在会议室讨论时,前者是用红笔画的,后者是用绿笔画的,于是就合在一起称作“红绿树”。
自此,Roslyn 团队设计出的这种数据结构满足了以上所有的要求。不过,如果红树太大,每次重新生成依然会耗费比较多的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号