

神经网络激活函数学习要点记录
如下图所示,在神经元中,输入通过加权,求和后,还被作用于一个函数,这个函数就是激活函数/激励函数 Activation Function。激活函数的作用是为了增加神经网络的非线性。

常用的激活函数:
1、Sigmoid函数:
![]()

特点:能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
缺点:在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
其输出并不是以0为中心的。会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。 产生的一个结果就是:如果数据进入神经元的时候是正的,那么计算出的梯度也会始终都是正的。
不建议在网络中使用。
2、tanh函数:
![]()

它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
不建议在网络中使用。
3、ReLU函数(Rectified Linear Unit,修正线性单元):
![]()

优点:解决了梯度消失(gradient vanishing)问题 (在正区间)
计算速度非常快,只需要判断输入是否大于0
收敛速度远快于sigmoid和tanh
缺点:随着训练的进行,可能会出现神经元死亡、权重无法更新的情况。可以通过设置learning rate来缓解。
4、PReLU(Parametric Rectified Linear Unit)函数:
f(x) = max(ax, x) 一般来说a为很小的系数,在训练中取一定范围内的随机值,在测试时固定。当a=0.01时为Leaky ReLU。
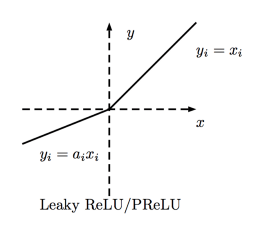
有ReLU函数的优点,解决了神经元死亡的问题。
Softmax 函数:
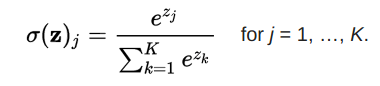
多用于输出层,计算分类概率。
结论:
选择激活函数时,优先选择ReLU及其变体,而不是sigmoid或tanh。ReLU及其变体训练起来更快。如果ReLU导致神经元死亡,使用Leaky ReLU或者ReLU的其他变体。sigmoid和tanh受到消失梯度问题的困扰,不应该在隐藏层中使用。隐藏层使用ReLU及其变体较好。使用容易求导和训练的激活函数。

