

PB对Unicode的支持
版权说明
本系列文章在博客园发表,除允许在互联网上自由转载外,不允许以其它任何方式拷贝、编辑、印刷出版、制作发行及传播,包括不允许在笔者未知晓的情况下制作成各种格式的电子文档并传播,更不得在未经笔者本人允许的情况下以任何形式的拷贝用于商业用途。笔者对本系列文章保留有追究其侵权责任的权利。
若需制成电子文档并用于非商业用途方式的传播,请保留以下版权信息,并与笔者联系邮寄副本一份。
作者:张楠
网名:SummerHeart
Email:Costware@163.com
Blog:http://summerheart.cnblogs.com/
http://blog.csdn.net/summerheart
时间:2008.5.26
Copyright: 2008
PS:转载请保留以上版权信息
第一章 PowerBuilder不容忽视的细节
1. PowerScript
PB的基础编程语言是种被称之为PowerScript的语言,由PB最先的开发商PowerSoft制定,之所以被称之为PowerScript,原因是它不同于VB,Delphi、C等语,它自成一套体系,虽然并没有成为一种标准的编程语言而得到广泛使用,但它在PowerBuilder中却发挥着无法或缺的做用。下面让我们看看它的各方面一些特点。
1.1 对Unicode的支持
以下是PB8.02的一个例子,大家可以看到调试状态下字符串a得到的是带有半个汉字的字符串,而name的长度也变为了6,说明len函数是把汉字当双字节处理,而英文字母作为单字节来处理的。这样一来,当字符中带有汉字时,字符处理函数(包括mid,right)都会出现长度与字符数不一致的情况。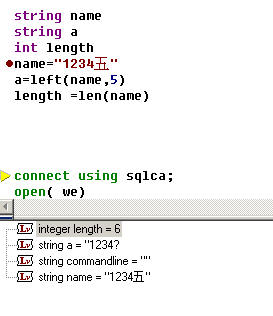
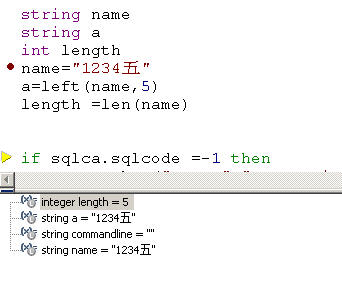
PB8.02图-1 PB11.2图-2
然而这种情况在pb11.2中得到了解决,无论是汉字还是英文字母都是被统一的当作一个字符处理,这就是国际上通用的字符编码Unicode。这种编码将世界各国不同的文字字符统一以一个字符看待,而每个字符占两个字节。这样的处理是要付出代价的,但凡用到Unicode的所有字符,都以两个字节处理了,比以前的单字节多占了一个字节的空间。然而这种付出是值得的,它的价值显而易见,消除了各种言语文字集之间处理上的不一致性。这也应该称得上是一种全球化吧。呵呵!
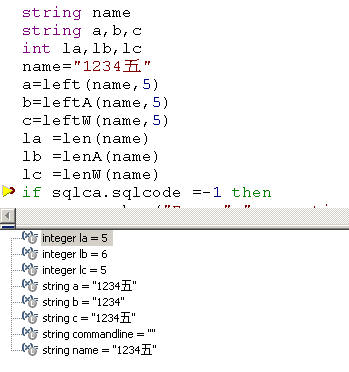
回顾下PB9时代,出现了LeftA、LenA;LeftW、LenW等等,这样的函数形式,是为了解决亚洲字符集(包括了ANSI在内的ASCII字符,即值为0-255之间的单字节编码方式的字符)的处理而增加进来的。带“A”的用于处理单字节,而带“W”的用于处理双字节。当然现在有了Unicode的出现,带“W”的函数已经被废弃了。所以建议大家在以后的编程中不要再去用这些函数,这些函数之所有还保留,只是为了兼容以前pb9版本开发的程序而存在的。而带“A”仍然可以作为处理单字节字符用。下图是PB11.2中对带“W”函数的帮助说明。

从下图中可以看出三种不同函数形式的处理结果。在PB11.2中常规函数(left、len等)已经可以完全处理双字符,所以带“W”将要被废弃是完全有必要的。然而单字节函数(带“A”)仍就按单字节处理,并且比PB8.02时更能有效的识别单双字节混合的字符串。
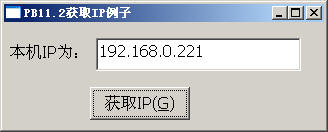
另外PB11.2对Unicode的支持可以通过一个例子看出来,对VC++写的一个API的调用,API函数原型为:
int foo(char *ip)
在PB8.02和PB11.2中调用结果图分别如下:
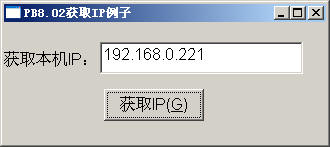
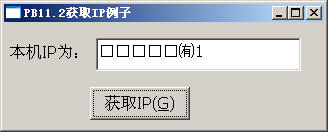
图1 图2
定义和调用都是相同的,分别如下:
1 Function uLong foo (ref String ipaddress) Library "GetIP.dll"
Function uLong foo (ref String ipaddress) Library "GetIP.dll"
2
3string ls_HostIP = space(128)
4if foo (ls_HostIP) = 0 then
5 sle_2.text=trim(ls_HostIP)
6end if
7
VC++编写的API函数带char*指针带回的是一个单字节字符指针,由上两张图可以看出,PB8.02的字符串是以单字节处理的,它不支持Unicode的;而PB11.2已经支持Unicode了,它把所有的String当Unicode字符处理,故会出现上图的乱码。
当把PB11.2中原来的定义后加上ANSI后即定义为:
Function uLong foo (ref String ipaddress) Library "GetIP.dll" ALIAS FOR "foo;ANSI"
则结果即转化为想要的值了。
那么PB11.2是如何转化的?
其实这并不是PB所为,而是两种字符集中单个字符所占的字节不同而造成的。我们来看,用LenA()看这个字符的长按理说是为13(实际在PB11.2用lenA函数已经得不出长度了,原因是PB在从API中返回的字符指针时已经把字符串当Unicode处理了),而用len则变为7了。很显然它把每两个节当成了一个Unicode字符。1的十六进制ACSII码为31,9的十六进制ACSII码为39,结合起来就是H31 39,但是字节在内存中的存放都是从右存到左,所以内存就存为H39 31,查看Unicode表可得知是个方框。即本机无此符号字体存在,所以显示不出来,以方框代替了。
注:Unicode表查询
http://www.wiki.cn/wiki/Unicode%E7%BC%96%E7%A0%81%E8%A1%A8/3000-3FFF
PB9以前对字符的解决方法
由于PB9以前没有对Unicode的支持函数,处理再汉字的字符串只能自己写函数处理了。以下给了笔者对len()自己定义了个函数f_mylen()处理带汉字字符串。代码如下:
char l_chint li_len,li_pstring ls_strls_str =a_strli_p =1do while len(ls_str)>=li_p l_ch = mid(ls_str,li_p,1) if asc(l_ch) >127 then li_p +=2 else li_p +=1 end if li_len+=1loopreturn li_len
对left()函数做了个自定义f_myleft()代替,代码如下:
char l_chint li_lenstring ls_strstring ls_rtnli_len = f_mylen(a_str)if a_len>=li_len then return a_strls_str =a_strli_len =1do while li_len <= a_len and len(ls_str)>=li_len l_ch = mid(ls_str,li_len,1) if asc(l_ch) >127 then ls_rtn = ls_rtn + mid(ls_str,li_len,2) li_len +=2 a_len+=1 else ls_rtn = ls_rtn + mid(ls_str,li_len,1) li_len +=1 end ifloopreturn ls_rtn
对于如mid,right的函数,则与f_myleft的处理类似,这里不再重复。

