
并发编程 - 总结
并发与并行
并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发
并行:同时运行,只有具备多个cpu才能实现并行
补充: 多道技术实现了单核下实现并发
同步 、异步 | 阻塞、非阻塞
同步 、异步: 是指任务提交的方式
同步:提交任务后原地等待任务执行完毕,拿到任务的返回值才能继续下一行代码,导致程序串行
异步:提交任务后不在原地等待,任务一旦执行完毕就会触发回调函数的执行,程序是并发
阻塞 、非阻塞 : 指程序执行中的运行状态
阻塞: 出现io 非阻塞: 没有出现 io
异步非阻塞: 程序在执行过程中没有出现io,任务提交是异步,无需等待
进程
进程的概念
1.进程是指运行的应用程序,内存空间,操作系统的调度称为一个进程
2.进程是竞争计算机系统有限资源的基本单位,也是进行处理机调度的基本单位
3.进程是程序的基本执行实体
注: 进程与进程的空间是物理隔离的
创建进程 multiprocess process
#当前文件名称为test.py from multiprocessing import Process def func(): print(12345) if __name__ == '__main__': #windows 下才需要写这个,这和系统创建进程的机制有关系,不用深究,记着windows下要写就好啦 #首先我运行当前这个test.py文件,运行这个文件的程序,那么就产生了进程,这个进程我们称为主进程 p = Process(target=func,) #将函数注册到一个进程中,p是一个进程对象,此时还没有启动进程,只是创建了一个进程对象。并且func是不加括号的,因为加上括号这个函数就直接运行了对吧。 p.start() #告诉操作系统,给我开启一个进程,func这个函数就被我们新开的这个进程执行了,而这个进程是我主进程运行过程中创建出来的,所以称这个新创建的进程为主进程的子进程,而主进程又可以称为这个新进程的父进程。 #而这个子进程中执行的程序,相当于将现在这个test.py文件中的程序copy到一个你看不到的python文件中去执行了,就相当于当前这个文件,被另外一个py文件import过去并执行了。 #start并不是直接就去执行了,我们知道进程有三个状态,进程会进入进程的三个状态,就绪,(被调度,也就是时间片切换到它的时候)执行,阻塞,并且在这个三个状态之间不断的转换,等待cpu执行时间片到了。 print('*' * 10) #这是主进程的程序,上面开启的子进程的程序是和主进程的程序同时运行的,我们称为异步 2.进程同步部分 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理。 3. 进程池部分 1.进程池的概念 def __init__(self,person): super().__init__() self.person=person def run(self): print(os.getpid()) print(self.pid) print(self.pid) print('%s 正在和女主播聊天' %self.person) def start(self): #如果你非要写一个start方法,可以这样写,并且在run方法前后,可以写一些其他的逻辑 self.run() if __name__ == '__main__': p1=MyProcess('Jedan') p2=MyProcess('太白') p3=MyProcess('alDSB') p1.start() #start内部会自动调用run方法 p2.start() # p2.run() p3.start() p1.join() p2.join() p3.join()
p. join() 主进程等待子进程运行完再运行
注意: if __name__ == '__main__':下发的代码块都是主进程的代码
僵尸进程
1.子进程运行结束,但占用的空间没有让出来("死了,没死干净")
2.所有的子进程都会经历僵尸进程的阶段
3.有害:占用资源
4.僵尸进程是正常的运行过程,目的是为了让父进程查看子进程的状态
5.父进程结束前会将子进程占用的资源回收
孤儿进程
1.父进程结束,子进程没有结束
2.无害
守护进程 p.daem = True
1.当子进程执行的任务在父进程代码运行完毕后就没有存在的必要了,那么该子进程就应该设置为守护进程
2.被守护的子进程应该在p.start()之前设置
3.被守护的子进程内不能再开启子进程
体现为:主进程代码运行结束,子进程就结束
互斥锁 Lock
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理
1.锁将并发变成了串行,牺牲了运行效率,但避免了竞争
2.锁在主进程中实例化产生,在子进程中使用
3.在修改数据处加锁,修改不同的数据用不同的锁
from multiprocessing import Process,Lock import os,time def work(n,lock): #加锁,保证每次只有一个进程在执行锁里面的程序,这一段程序对于所有写上这个锁的进程,大家都变成了串行 lock.acquire() print('%s: %s is running' %(n,os.getpid())) time.sleep(1) print('%s:%s is done' %(n,os.getpid())) #解锁,解锁之后其他进程才能去执行自己的程序 lock.release() if __name__ == '__main__': lock=Lock() for i in range(5): p=Process(target=work,args=(i,lock)) p.start()
进程间通信
1.文件的方式 速度慢,要自己加锁,容易导致死锁
2.队列Queue的方式(IPC) 管道+锁,不需要自己处理锁
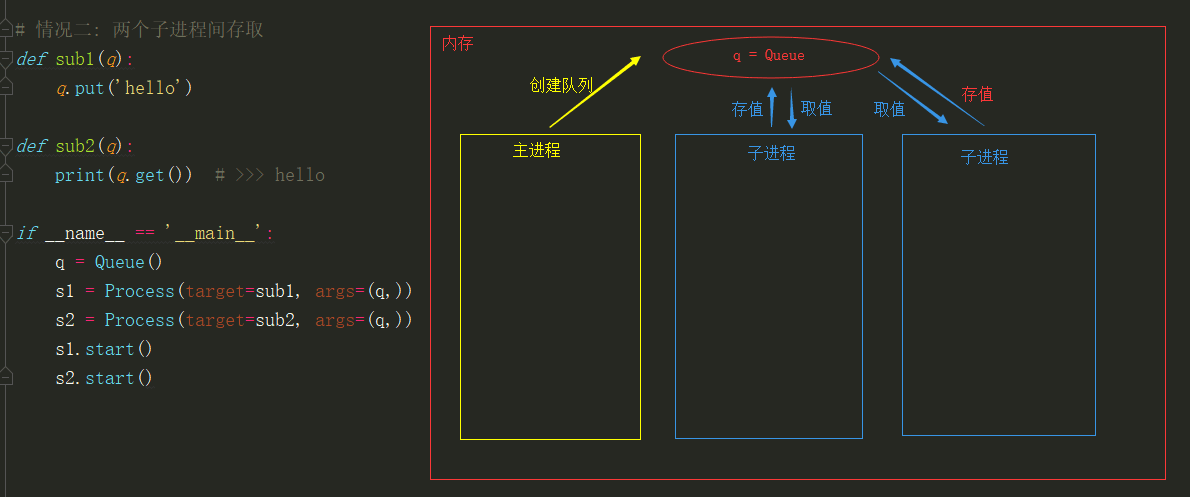
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,
直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
线程
进程是资源单位
线程是执行单位
同一进程下的线程资源共享,这些资源源自进程的空间
线程开销远远小于进程,且开线程的速度是开进程的百倍
# 线程没有父子之分
主线程的生命周期就代表着进程的生命周期(可以理解为主线程就代表着进程)
创建线程 threading Thread
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('太白',)) t.start() print('主线程')
守护线程
因为线程的运行需要进程中的资源,而主线程又代表着进程,守护线程会随着主线程的结束跟着结束,所以守护线程是主线程等到非守护线程的结束再随着主线程结束
Event事件
一个线程要等到另一个线程运行到某一时刻再运行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
GIL
同一个进程下开启的多线程,同一时间只能有一个在运行,因为线程之间共用一套资源
GIL锁的存在是因为垃圾回收机制也是一个进程中的线程,为了保证数据安全
GIL锁导致了python多线程无法利用多核优势
IO密集型?计算密集型?
递归锁 RLock
递归锁每acquire一次身上的计数就加一,只要身上的计数不为0,其他人就抢不到
信号量 Semaphore
也是一种锁,不同于互斥锁,信号量是一把锁有多把钥匙
池 concurrent
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
#submit(fn, *args, **kwargs) 异步提交任务 #map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作 #shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 #result(timeout=None) 取得结果 #add_done_callback(fn) 回调函数
协程
协程:是单线程下的并发,又称微线程,纤程。
协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
优点
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点
1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号