数据分析 - pandas
简介
pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。
Pandas的主要功能:
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
-
安装
>: pip install pandas
-
引用方法:
import pandas as pd
Series
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
创建方式
-
普通创建
将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取

-
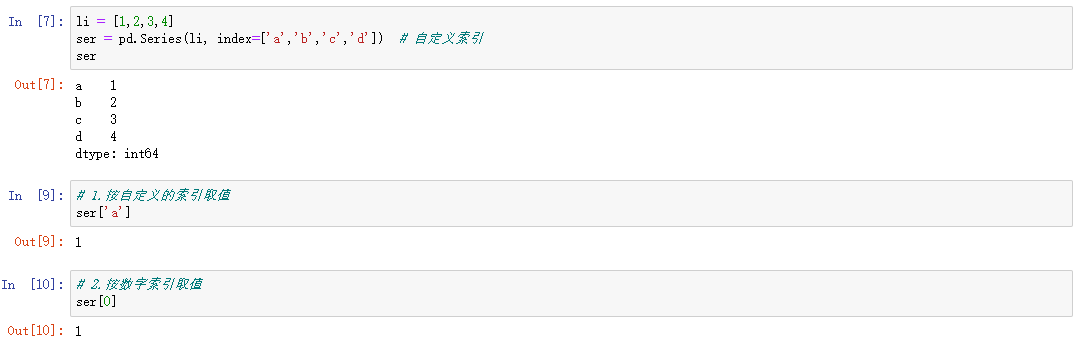
自定义索引0.1
index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
-
自定义索引0.2

-
其他创建
创建一个值都是0的数组
对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series
缺失数据处理
- dropna() # 过滤掉值为NaN的行
- fillna() # 填充缺失数据
- isnull() # 返回布尔数组,缺失值对应为True
- notnull() # 返回布尔数组,缺失值对应为False
缺失值数据

-
处理方式一: dropna
dropna默认过滤值为NaN的行,不修改原数据,若指定inplace=True,则修改原数据

-
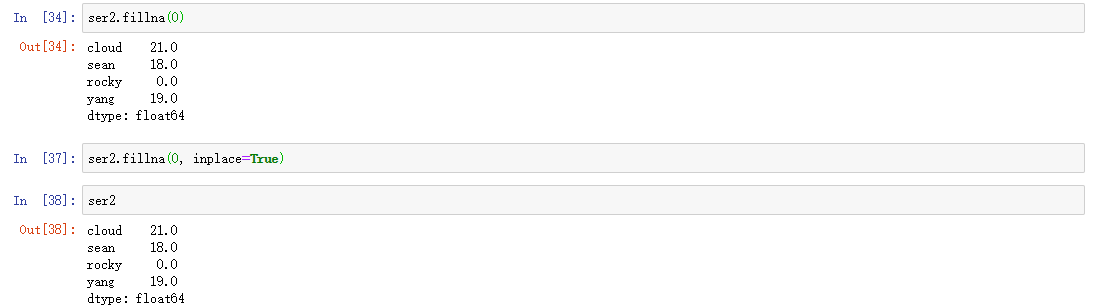
处理方式二: fillna
fillna可以将NaN修改为数字0(一般修改为0),不修改原数据,若指定inplace=True,则修改原数据
-
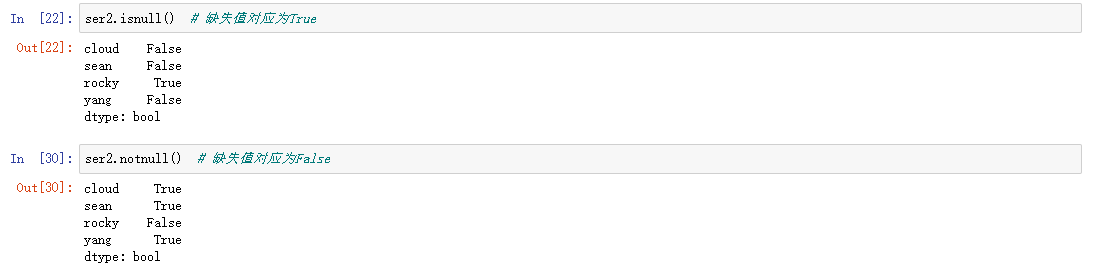
判断缺失值: isnull,notull
Series特性
因为pandas是基于Numpy构建的,所以Series支持ndarray的特性:
- 从ndarray创建Series:Series(arr)
- 与标量(数字):sr * 2
- 两个Series运算
- 通用函数:np.ads(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean()、sum()、cumsum()
支持字典的特性:
- 从字典创建Series:Series(dic),
- In运算:'a'in sr、for x in sr
- 键索引:sr['a'],sr[['a','b','d']]
- 键切片:sr['a':'c']
- 其他函数:get('a',default=0)等
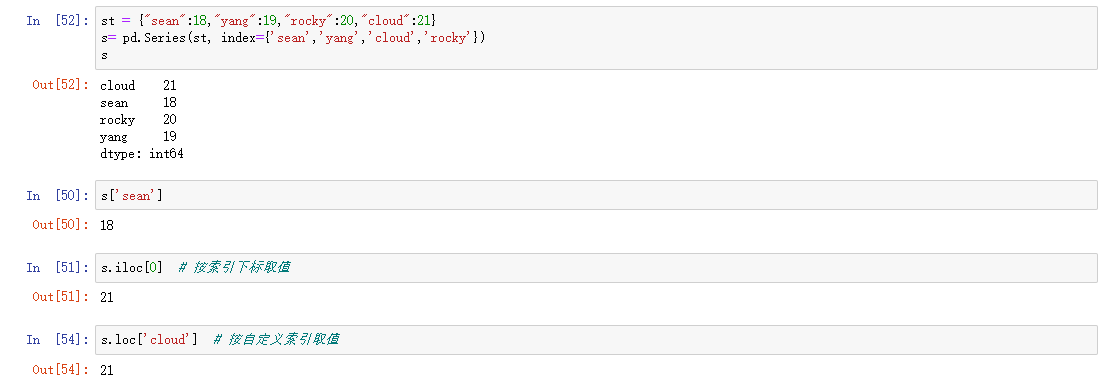
索引取值
- loc属性 # 以标签解释
- iloc属性 # 以下标解释
Series数据对齐
pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引值是NaN。
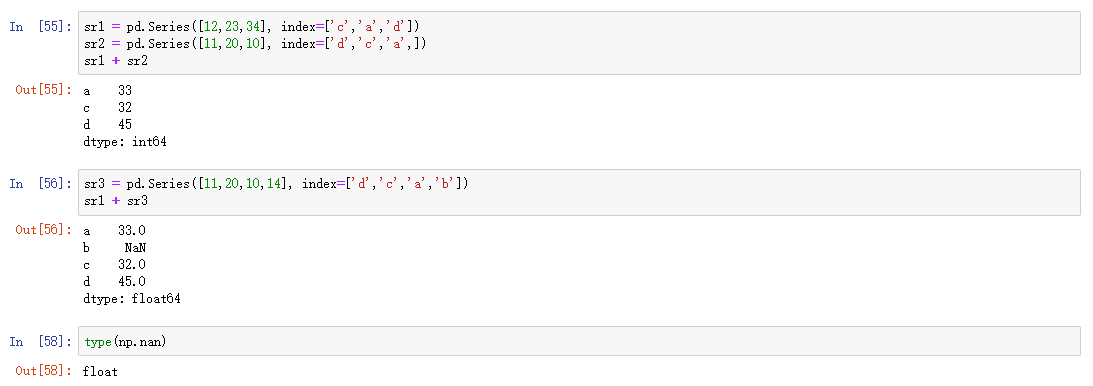
将两个Series对象相加时将缺失值设为0:
将缺失值设为0,所以最后算出来b索引对应的结果为14
补充: 灵活的算术方法:add,sub,div,mul
DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
创建方式
-
方式一
产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列

-
方式二:
自定义行索引,源于Series的自定义索引

查看数据
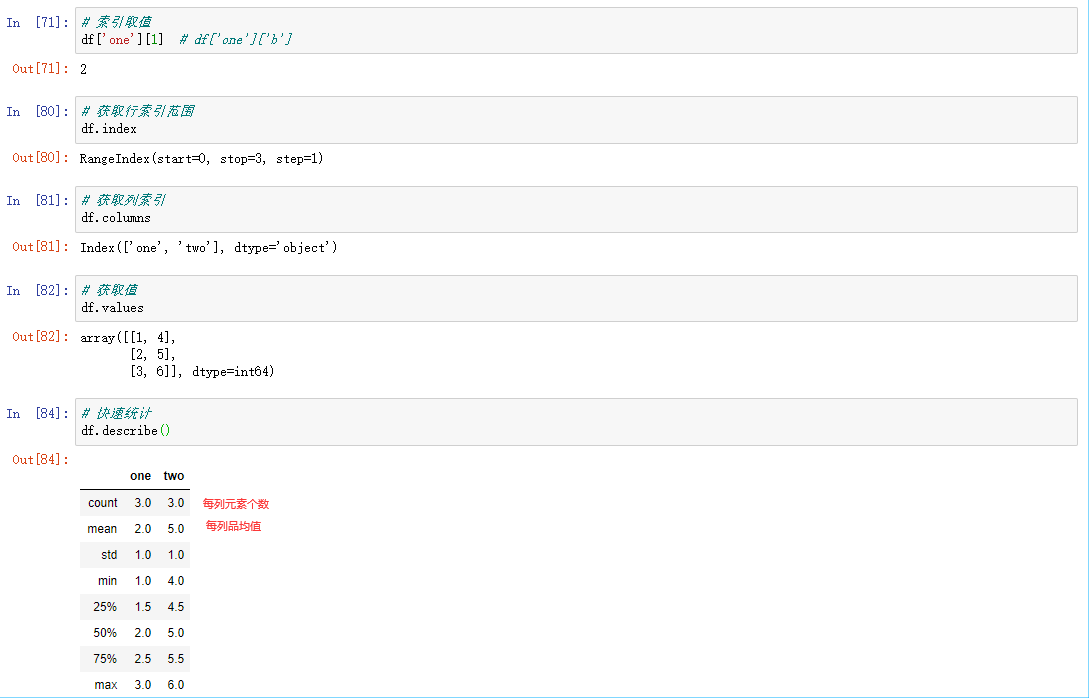
常用属性和方法:
- index 获取行索引
- columns 获取列索引
- T 转置
- columns 获取列索引
- values 获取值索引
- describe 获取快速统计
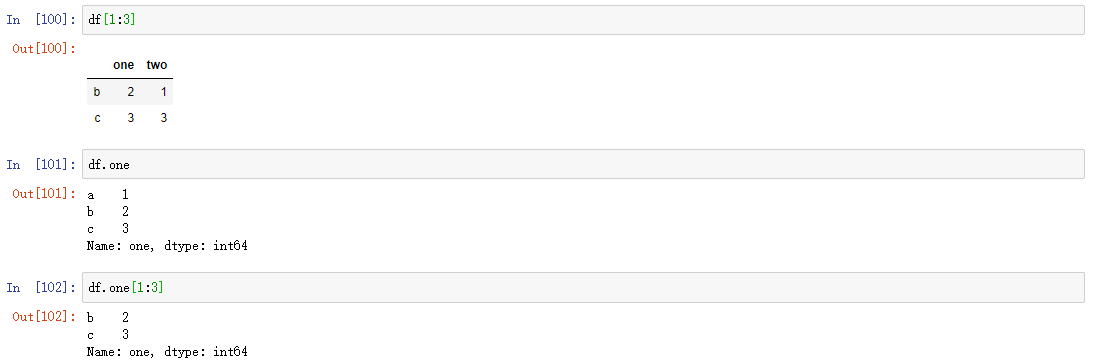
索引和切片
- DataFrame有行索引和列索引。
- DataFrame同样可以通过标签和位置两种方法进行索引和切片。
DataFrame使用索引切片:
- 方法1:两个中括号,先取列再取行。 df['A'][0]
- 方法2(推荐):使用loc/iloc属性,一个中括号,逗号隔开,先取行再取列。
- loc属性:解释为标签
- iloc属性:解释为下标
- 向DataFrame对象中写入值时只使用方法2
- 行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配。(注意:两部分都是花式索引时结果可能与预料的不同)

常见的获取数据方式
-
read_文件后缀 读取数据

-
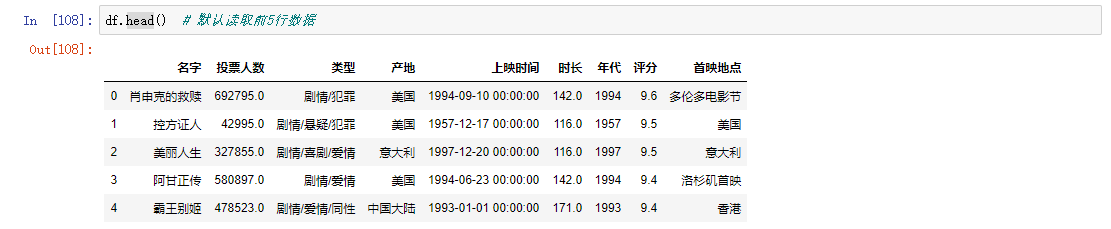
head 读取指定行数
-
to_文件后缀 保存数据

-
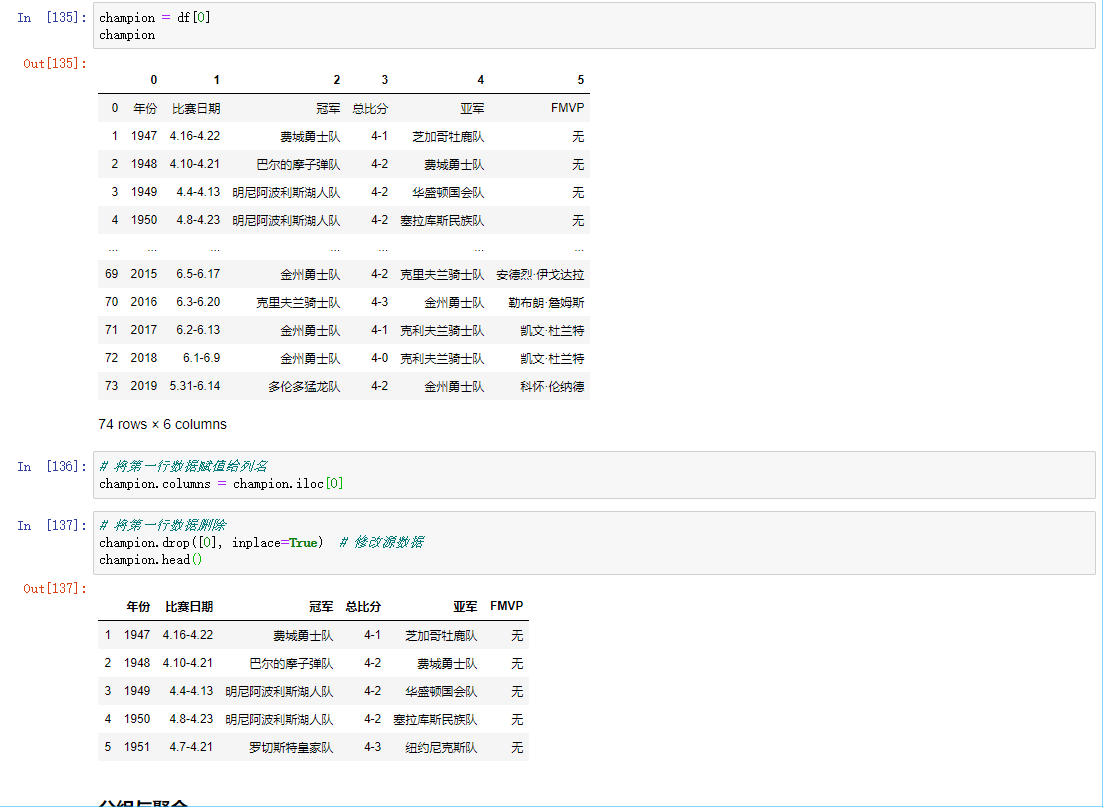
read_html
读取页面中的表格数据

数据分组
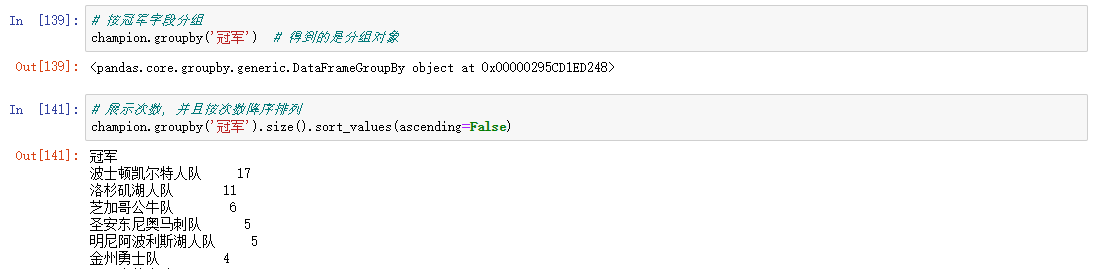
在数据分析当中,我们有时需要将数据拆分,然后在每一个特定的组里进行运算,这些操作通常也是数据分析工作中的重要环节。
GroupBY
数据的聚合
聚合是指任何能够从数组产生标量值的数据转换过程。刚才上面的操作会发现使用GroupBy并不会直接得到一个显性的结果,而是一个中间数据,可以通过执行类似mean、count、min等计算得出结果,常见的还有一些:
| 函数名 | 描述 | |
|---|---|---|
| sum | 非NA值的和 | |
| median | 非NA值的算术中位数 | |
| std、var | 无偏(分母为n-1)标准差和方差 | |
| prod | 非NA值的积 | |
| first、last | 第一个和最后一个非NA值 |
事件对象处理
时间序列类型
- 时间戳:特定时刻
- 固定时期:如2019年1月
- 时间间隔:起始时间-结束时间
python库:datetime
- date、time、datetime、timedelta
- dt.strftime()
- strptime()
灵活处理事件对象 : dateutil包
- dateutil.parser.parse()

成组处理时间对象 to_datetime

- 时间范围对象 date_range
start 开始时间
end 结束时间
periods 时间长度
freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…


 浙公网安备 33010602011771号
浙公网安备 33010602011771号