
re模块与正则
一.正则
正则就是用来筛选字符串中的特定的内容
正则表达式与re模块的关系:
1.正则表达式是一门独立的技术,任何语言都可以使用
2.python中药想使用正则表达式需要通过调用re模块
正则应用场景:
1.爬虫
2.数据分析


# 纯python代码校验 while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码') # 正则表达式校验 import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码') # 正则在所有语言中都可以使用 不是python独有的 # 匹配大段文本中特定的字符
1.正则字符:
| 元字符 | 匹配内容 |
| . | 除 换行符 以外的任意字符 |
| \n | 换行符 |
| \w | 字母 或 数字 或 下划线 |
| \s | 任意的空白字符 |
| \d | 数字 |
| \W | 非 字母 或 数字 或下划线 |
| \S | 非 空白字符 |
| \D | 非 数字 |
| \t | 制表符 |
| ^ | 字符串的开始 |
| $ | 字符串的结尾 |
| \b | 单词的结尾 |
| a|b | 字符 a 或 b |
| () | 匹配括号内的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配出了字符中的所有字符 |
| 量词 | 说明 |
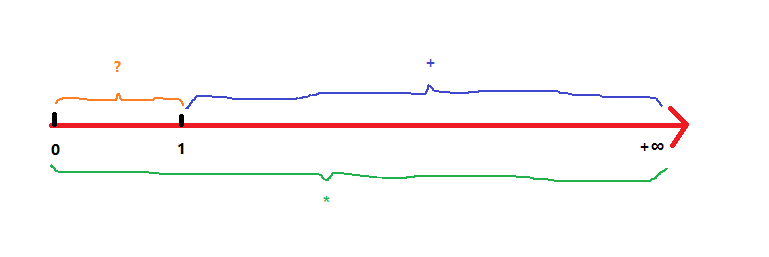
| * | 重复 零次 或 多次 |
| + | 重复 一次 或 多次 |
| ? | 重复 零次 或 一次 |
| {n} | 重复 n 次 |
| {n,} | 重复 n 次 或 多次 |
| {n,m} | 重复 n 到 m 次 |
2.字符组概念
在同一位置可能出现各种字符 组成了一个字符组,在正则表达式中用[ ]表示,一个字符组内每次只能匹配一个字符,[ ]内的字符是或的关系
例:
- 匹配0-9数字 : [0123456789] 或 [1-9]
- 匹配A-Z字母 : 同上
- 匹配a-z字母 : 同上
ps: 字符组内范围必须从小到大必须按ASCII码表排序
-
^:以什么开头
- ^[1-9] : 匹配字符是否以1-9其中的数字为开头
- $:以什么结尾
- [a-z]$ : 匹配的字符是否以a-z其中的字母结尾
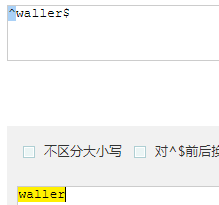
- ^...$:精准匹配固定长度的目标字符
- ^waller$ : 匹配waller
![]()
-
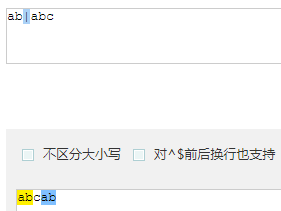
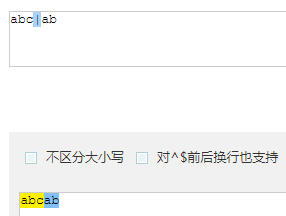
| :或
- ab|abc 优先匹配 | 前面的内容,若前面内容匹配上 | 后面的内容不再匹配(在书写时把长的写在 | 前面)
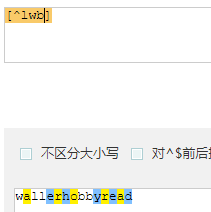
- [^...] : 除括号内的内容其他都匹配
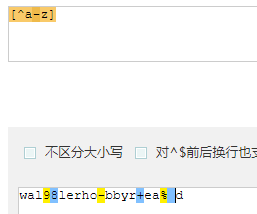
3.量词
只能和元字符配合使用,且只能限制紧挨着它的那个符号,并且是贪婪匹配
-
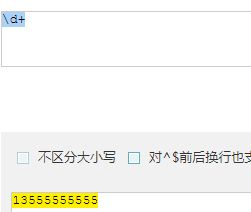
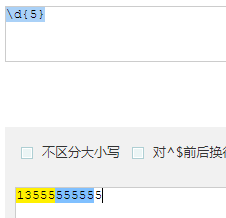
+ : 匹配1次或多次
- 匹配 13555555555 ,用 \d 每次只能匹配单个数字,要想把数字一次都匹配上要用 \d+
![]() 匹配到 1 条结果
匹配到 1 条结果
- * : 匹配零次或多次
-
![]() 匹配到 2 条结果
匹配到 2 条结果
-
- {n} : 指明重复个数
![]()
 匹配到 1 条结果
匹配到 1 条结果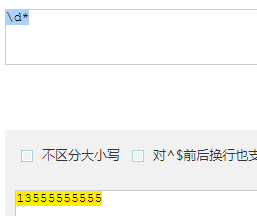 匹配到 2 条结果
匹配到 2 条结果
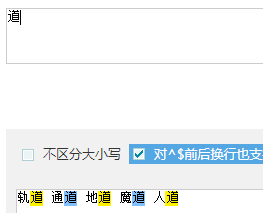
题:
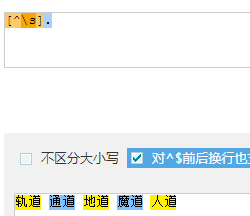
- 轨道 通道 地道 魔道 人道
- 逐个匹配出后面的道:
-
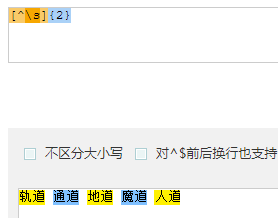
- 取出词:
- [^\s]{2} : 去掉空格,每次取两个字符
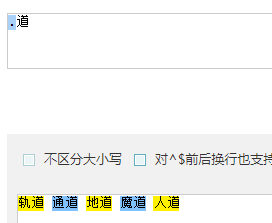
- .道 : 取出 .和道组成的词
- [^\s]. : [^\s]本身占了一个位置 加 . 共取两个位置
![]()
![]()
![]()
- 匹配人名: 海燕海娇海东
-
海. 取 海和.组成的词 海燕海娇海东 匹配所有"海."的字符 ^海. 只取以 海和.为开头 海燕 只从开头匹配"海." 海.$ 只取以 海和.为结尾 海东 只匹配结尾的"海.$"
-
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
4.分组 ()与 或 |[^]
- 身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配这串数字,但这并不是一个正确的身份证号码,它是一个16位的数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
现在不会匹配错误的身份证号了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
|
5.转义符 \
-
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。 在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。
-
正则 待匹配字符 匹配
结果说明 \n \n False 因为在正则表达式中\是有特殊意义的字符,所以要匹配\n本身,用表达式\n无法匹配
\\n \n True 转义\之后变成\\,即可匹配
"\\\\n" '\\n' True 如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次
r'\\n' r'\n' True 在字符串之前加r,让整个字符串不转义
6.贪婪匹配与非贪婪匹配
-
正则在匹配的时候默认是贪婪匹配,可以在量词后面加上一个 ? 号,将贪婪匹配转成非贪婪匹配(惰性匹配)-
正则 待匹配字符 匹配
结果说明 通俗理解 <.*> <script>...<script>
<script>...<script> 默认为贪婪匹配模式,会匹配尽量长的字符串
<.*?> r'\d' <script>
<script>加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串
先拿着?后面的>去匹配符合条件的最少的内容,然后把匹配的结果返回
-
- 解释 .*?:
- . 是任意字符(除换行符)
- * 是取零 或 无限长
- ? 在量词后面是非贪婪模式
- 合在一起是 取尽量少的字符
例: .*?x
就是取前面任意长度的字符,直到一个x出现
- 常用的非贪婪模式写法:
-
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
-
二.re模块的使用
findall ('正则表达式','待匹配的字符串')
search ('正则表达式','待匹配的字符串')
match ('正则表达式','待匹配的字符串')
split ('正则表达式','待切分的字符串',n) 切分
sub ('正则表达式','新的内容','待替换的字符串',n) 替换
compile (正则表达式) 将正则表达式编译成一个正则表达式对象
分组 () 正则表达式中()内可以自定义别名: (?P<name>...)
findall
找出字符串中符合正则表达式的内容,
1.当查找内容存在时,返回一个列表,列表中的元素就是匹配结果
2.当查找的内容不存在时,不报错 返回一个空列表
search
1.只依据正则查一次,查到了结果就会停止查找
2.search不会直接返回匹配的结果,而是返回一个对象
3.需要调用group才能看到结果
4.当查找的结果不存在时,返回None, stopIteration
match
1.match只匹配字符串的开头
2.match不会直接返回匹配结果,而是返回一个对象
3.需要调用group才能看到结果
4.当匹配结果不存在 返回 None ,继续调用会报错
findall:
res1 = re.findall('[a-z]+','waller age hobby') print(res1) # >>> ['waller', 'age', 'hobby'] res1 = re.findall('\d','waller age hobby') print(res1) # >>> []
search: res2 = re.search('a','waller age hobby') print(res2) # >>> <_sre.SRE_Match object; span=(1, 2), match='a'> print(res2.group()) # >>> a if res2: # 判断有匹配结果再打印 print(res2.group()) res2 = re.search('[a-z]+','waller age hobby') print(res2) # >>> <_sre.SRE_Match object; span=(0, 6), match='waller'> print(res2.group()) # >>> waller
match: res3 = re.match('[a-z]','waller age hobby') print(res3) # >>> <_sre.SRE_Match object; span=(0, 1), match='w'> print(res3.group()) # >>> w res3 = re.match('a','waller age hobby') print(res3) # >>> None print(res3.group()) # 报错 if res3: # 判断有匹配结果再打印 print(res3.group())
es = re.split('[ab]','abcd') # 先按'a'切分得到' '和'bca',再对' '和'bca'分别按'b'切分 print(res) # >>> ['', '', 'cd'] res = re.sub('\d','H','waller3age5hobby6',2) # 将数字替换成 H ,参数 2 是替换次数 print(res) # >>> wallerHageHhobby6 # 先通过这正则表达式找到所有符合的内容,统一替换,可以指定替换个数 res = re.subn('\d','H','waller3age5hobby6') print(res) # >>> ('wallerHageHhobbyH', 3) res = re.subn('\d','H','waller3age5hobby6',2) print(res) # >>> ('wallerHageHhobby6', 2) # 按正则将数字替换成 H 返回的是一个元组,元组第二个元素是替换的个数 obj = re.compile('\d{3}') # 将正则表达式编译成一个正则表达式对象 规则是匹配3三个数字 res1 = obj.search('waller123hobby') # 正则表达式对象调用search方法 参数是 待匹配字符串 print(res1.group()) # >>> 123 res2 = obj.findall('8946518w4651') print(res2) # >>> ['894', '651', '465']
#正则表达式中()内可以自定义别名: (?P<name>...) res = re.search('^[1-9]\d{14}(?P<name>\d{2}[0-9x])?$','110105199812067023') print(res.group()) # >>> 110105199812067023 print(res.group('name'))# >>> 023 ret1 = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') # 忽略分组优先的机制 print(ret1,ret2) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret1=re.split("(\d+)","eva3egon4yuan") print(ret1) #结果 : ['eva', '3', 'egon', '4', 'yuan']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号