如何高效驾驭海量任务处理的艺术
场景
在支付业务中,我们需要对接很多渠道,再与渠道交易的过程中,因为网络超时,或者渠道返回订单状态结果未知,这是我们一般都需要主动去调用渠道的查询结果去查询订单的最终结果,如果因为某些异常原因积压了大批量这样的订单,我们怎么如何高速快速的查询这种订单?
MySQL 扫表方案
通常最简单的方法就是扫描数据库,建立 status +craeated_at (状态+创建时间)索引,根据异常状态+时间范围去扫描数据库中异常的数据,然后进行业务操作。这里面有几个注意点需要说明:
-
建立状态索引是否有效?
通常状态值都是固定几个值,区分度不是很高,比如支付订单表中,一般就成功、失败、异常。订单的最终结果要么是成功,要么是失败,如果查成功或者失败的订单,通过状态索引和全表查询效果没什么区别,状态索引不会生效,但是,如果我们查询异常状态的订单,效果就不一样,因为异常状态的订单占比非常少,区分度很高,这是用状态索引去查就会很快。
-
如何加速处理的速度?
-
每次查询到异常状态的订单使用线程池去处理
-
数据分片,开启多个线程同时去查mysql 数据
-
分片拉取数据,再使用线程池去消费处理
数据分片拉取处理和线程池消费时,需要考虑MySQL 数据库连接数使用的情况和系统资源开多少线程合适
elastic-job+redis 方案
由于查询Mysql 即使走索引,查询耗时还是要毫秒级别,如何异常订单有大百万的时候,并发查询MysqL 数据库的压力会很大,另一方面处理的速度也还是不是很理想。为了减少MySQL 的查询压力和用更少的资源订单处理速度,我们使用 elastic-job 任务分片 和 redis 分片的 方案
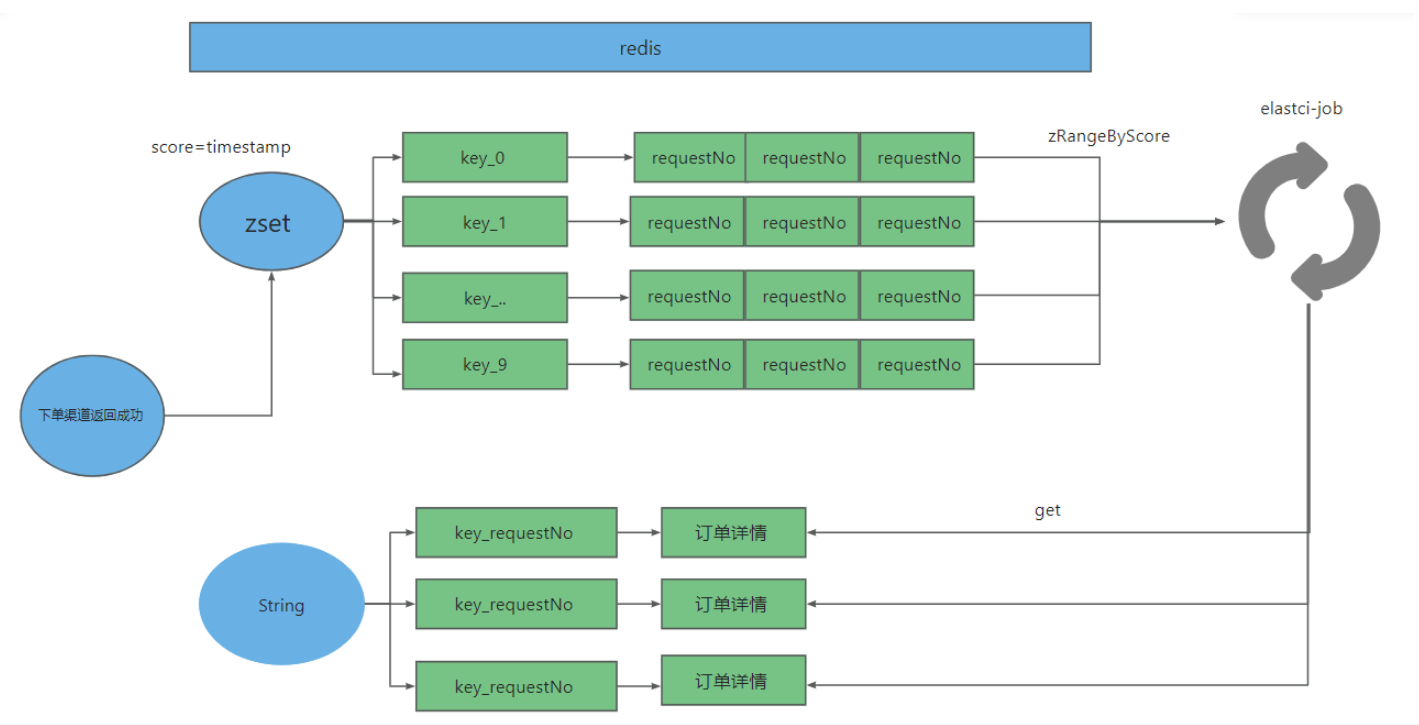
最主要的就是依靠 redis zrangeByScore 命令 ,大概步骤如下:
-
将需要需要补单的订单哈哈希取模得到一个分片号,然后存入分片数据
redis.zadd(key+“_”+hash(订单号)%(redis 分片数)),订单号,时间戳)。哈希取模是为了避免一个key存储的数据量太大
reids.set(key_detail_"订单号,"订单详情");
-
配置elasetic-job 分片任务
每个分片处理 redis.ranngetByScore(key+“_”+hash(订单号)%(redis 分片数),0,当前时间戳)的数据
生产经验
正常情况使用 elastic-job+redis ,同时为了避免 redis 异常导致数据丢失的情况,需要再配合 mysql 扫描任务进行补偿或者二次确认

 浙公网安备 33010602011771号
浙公网安备 33010602011771号