第四章 Zookeeper技术内幕
4.1 重要理论
4.1.1 数据模型 znode
zk数据存储结构是一个树形结构,根节点下挂载子节点,每个节点都是一个znode,是zk中数据的最小单元,每个znode都可以保存数据
1. 节点类型
持久节点:节点被创建后一直保存,直到删除
持久顺序节点:父节点为儿子节点记录创建的顺序,即创建时在节点名字后添加数字,一共10位10进制数,从0开始计数
临时节点:临时节点的生命周期和客户端的会话绑定在一起,会话消失则被清理。临时节点只能做叶子节点
临时顺序节点:顺序含义同持久顺序节点
4.1.2 会话
客户端和服务器建立TCP连接,一旦建立完成,客户端会话开始它的的生命周期
1. 会话的状态
CONNECTING:连接中,创建一个zk对象,代表将要连接的Server
CONNECTED:已连接,将连接上的Server信息写到zk对象中
CLOSED:已关闭,删除zk对象
选择Server的源码分析,zk客户端初始化,对zk集群所有节点进行Collections.shuffle,然后轮询取出一个可以用的节点,根据节点的域名找到下面所有ip,对所有ip再次进行Collections.shuffle,取出第一个ip,进行连接
2. 会话连接超时管理——客户端维护
会话超时:连接超时、读超时
3. 会话连接事件
客户端和服务端长连接失效后,客户端进行重试,在重试过程中产生三种会话连接事件。每次建立连接,服务端会生成一个sessionId,同时服务端也会检测客户端连接状态,如果客户端连接超时,会删除sessionId
- 连接丢失
- 会话转移:sessionId未删除,客户端重新连接上其他节点,对服务端无感,客户端更新自己zk对象的ip地址和端口
- 会话失效:sessionId已删除,客户端重新连接上其他节点,服务端告知客户端连接已失效,让客户端关闭连接重新建立连接
4 会话空闲超时管理——服务端维护
服务端记录客户端每次心跳时间,如果时间超时,将删除sessionId。服务端采用分桶策略进行超时管理,并不是精确的超时管理
分桶策略
将超时时间相近的会话,放到一个同一个桶里,每个桶有上下时间边界。当当前时间超过桶下界,整个桶中的sessionId将被清除
客户端A建立连接,服务端会计算超时时间,这个超时时间将会落在某一个桶中,服务器会将sessionId放入对应的桶。
超时判定:只要客户端A下次请求的时间,在桶的下界之前,则不算超时。
重新分桶:客户端A下次请求的超时时间如果落在的下一个桶中,则将sessionId移动到对应的桶
源码
HashMap<Long,SessionSet> sessionSets; 会话桶集合,key是桶标识(桶下界时间),value是会话桶。
//会话桶类 Static class SessionSet{ HashSet<SessionImpl> sessions = new HashSet<SessionImpl>(); }
SessionTrackerImpl#touchSession,将对应的sesssionId放到桶中,并判断当前会话是否关闭或不存在。注意SessionTrackerImpl是一个线程
处理客户端连接请求:ZooKeeperServer#processConnectRequest,客户端第一次连接服务器,或者连接丢失,这两种情况下会发送连接请求
处理客户端的数据包:ZooKeeperServer#processPacket,譬如发送心跳等等
SessionTrackerImpl#run,一个无限循环,检查当前时间,是否已经到桶下界,如果没有,会在剩余时间中等待。如果时间到,则从会话桶集合中将该桶移除,并且遍历桶中所有会话,修改会话状态为关闭,并关闭会话。紧接着,获取下一个桶标识(当前桶标识+桶间距),继续循环。
4.1.4 Watcher机制
zk通过Watcher机制实现发布/订阅模式
1. 原理
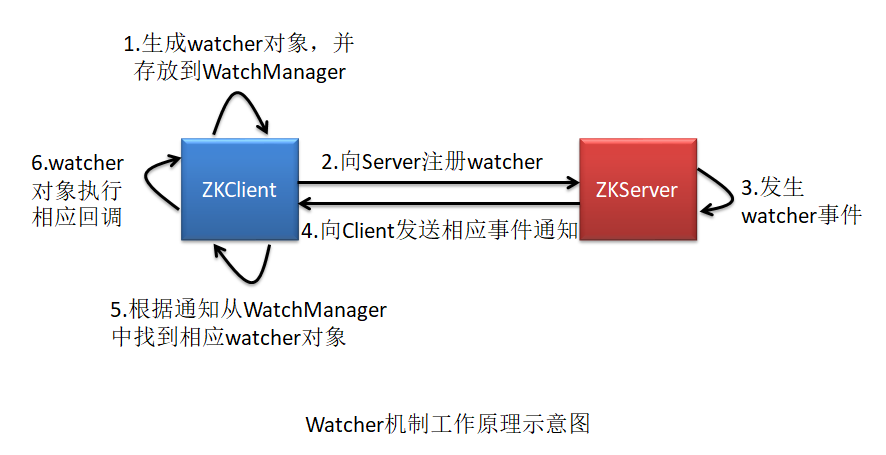
2. watcher事件
比较重要的两个事件:
NodeDataChanged,watcher监听对应数据节点的数据内容发生变化
NodeChildrenChanged,watcher监听的节点的子节点列表发生变化
3. watcher特性
一次性:watcher触发后,zk将其从客户端的watcherManager中删除,服务器端也会删除该watcher。所以watcher机制不适合监听经常变化的场景。譬如Kafka将offset的管理放到了自身
串行:一个watcher事件完全处理完(回调并删除),才能开始注册新的watcher
轻量级:传递给服务端的是简易版watcher,回调逻辑放在客户端,不在服务器
4.2 客户端
1. ZKClient
2. Curator

 浙公网安备 33010602011771号
浙公网安备 33010602011771号