第十五章 复制
使用SLAVEOF命令或者设置slaveof选项,让一个服务器复制另一个服务器
15.1 旧版复制功能的实现
Redis的复制功能分为同步和命令传播
- 同步操作用于将从服务器的数据库状态更新为主服务器的数据库状态
- 当主服务器数据库状态被更改,会将执行的写命令传给从服务器执行
15.1.1 同步
客户端向从服务器发送SLAVEOF命令,要求从服务器同步主服务器的数据库状态,从服务器接收命令后
- 向主服务器发送SYNC命令
- 主服务器收到命令后执行BGSAVE命令,保存当前数据库状态。并使用缓冲区保存写入RDB期间产生的新的写命令
- 主服务器将RDB文件发送给从服务器,从服务器载入RDB文件
- 主服务器将缓冲区的写命令发送给从服务器,从服务器执行这些写命令
15.1.2 命令传播
当主服务器执行写命令后,为保证主从服务器状态一致,会将命令传递给从服务器执行
15.2 旧版复制功能的缺陷
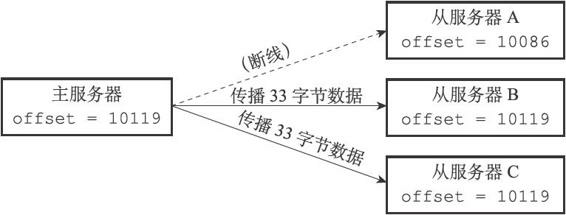
在Redis2.8之前,如果主从服务器在命令传播阶段,连接断开,当再次连接后,会进行主从服务器的同步操作,确保数据库状态的一致。在断开连接阶段,主服务器可能只执行了少量的写操作,但是同步阶段,会将全部的数据库状态同步给从服务器。
SYNC操作是一个很耗费资源的命令,生成RDB文件会占用主服务器大量的CPU,内存和磁盘I/O资源。而传输RDB文件会耗费网络带宽和流量。写入RDB文件会导致从服务器阻塞不接受命令
15.3 新版复制功能的实现
PSYNC命令代替SYNC命令。PSYNC命令有完整重同步和部分重同步俩种模式
- 完整重同步处理初次复制的情况,和SYNC一样
- 部分重同步处理断线重连后的同步情况,主服务器将断线时间内的写操作传递给从服务器执行
15.4 部分重同步的实现
- 主服务器的复制偏移量和从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 服务器的运行ID
15.4.1 复制偏移量
执行复制的双方,分别维护一个复制偏移量(坐标)。
当主服务器每次想从服务器发送N个字节的数据时,将字节的复制偏移量的值加上N。当从服务器接收主服务器发送的N个字节的数据,将自身的复制偏移量加N
15.4.2 复制积压缓冲区
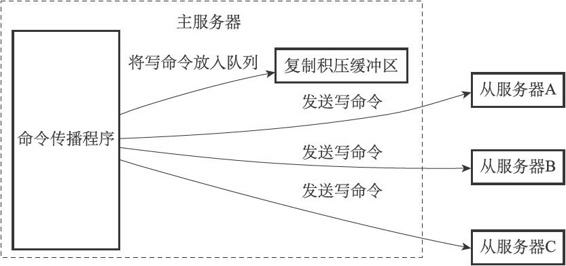
主服务器会维护一个固定长度,先进先出的队列,默认大小为1MB,称为复制积压缓冲区。
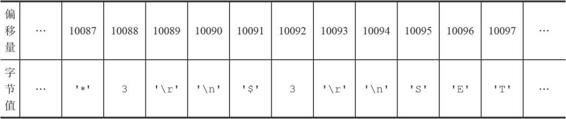
主服务器在命令传播阶段,不仅向从服务器发送写命令,还会将命令写入复制积压缓冲区,在缓冲区每个字节都有一个对应的偏移量。当从服务器端断线重连请求同步(PSYNC),会将自己的复制偏移量发送给主服务器,主服务器判断是否在复制积压缓冲区的范围内,如果在,则将这部分之后的命令发送给从服务器;否则进行全同步。
15.4.3 服务器运行ID
当从服务器断线重连,如何确定连接的是之前的主服务器?
每个服务器在初始化时都会设置一个运行ID,由40个随机的是十六进制字符组成。当主从服务器首次复制时,主服务器会将自己的运行ID发送给从服务器,从服务器会保存起来。当断线重连后,从服务器会向当前主服务器发送保存的运行ID
- 当前主服务器运行ID和保存ID一致,主服务器会进行部分同步
- 当前主服务器运行ID和保存ID不一致,主服务器会进行全同步
15.5 PSYNC命令的实现
PSYNC命令的调用方式有两种:
- 当从服务器从未进行复制过任何主服务器,在首次复制时,发送 "PSYNC ? -1"命令,请求全同步
- 当从服务器并非首次复制,发送"PSYNC <runid> <offset>"命令:其中runid是上次复制的主服务器的运行ID,offset是从服务器的复制偏移量
主服务器视情况有如下回复:
- 全同步,"+FULLRESYNC <runid> <offset>",其中runid是主服务器的运行ID,offset是主服务器的复制偏移量。从服务器将会保存runid作为下次PSYNC时使用,并将offset作为自己的复制偏移量
- 部分同步,"+CONTINUE",主服务器稍后会将缺失的部分写命令传递给从服务器
- 不支持,"-ERR",主服务器版本低于2.8不支持PSYNC,从服务器将向主服务器发送SYNC,完成全同步
15.6 复制的实现
15.6.1 步骤1 设置主服务器的地址和端口
当客户端向服务器发送同步指令
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
从服务器将目标服务器的IP地址和端口保存到服务器状态的masterhost属性和masterport属性,SLAVEOF命令是异步命令,从服务器设置完这两个属性后,即向客户端发送"OK"回复
struct redisServer{ //主服务器地址 char *masterhost; //主服务器端口 int masterport; //.... }
15.6.2 步骤2 建立套接字连接
从服务器根据主服务器的地址和端口,创建向主服务器的套接字连接,如果套接字连接能成功连接到主服务器
- 从服务器会替这个套接字关联一个专门用于处理复制事件的处理器,用于处理后续的复制工作
- 主服务器接收套接字连接后,替这个套接字创建一个客户端状态,将从服务器看成是客户端对待
15.6.3 步骤3 发送PING命令
在确认连接完毕后,需要检查连接通道和主服务器是否可用。因此从服务器会使用PING命令进行试探。
主服务器可能返回回复但从服务器读取超时,代表当前连接通道质量不佳,从服务器会断开并重新创建向主服务器的套接字
主服务器返回一个错误,表示当前无法处理请求,从服务器会断开并重新创建连接向主服务器的套接字
主服务器回复PONG,表示状态ok,将继续进行后续步骤
15.6.4 步骤4 身份验证
如果从服务器设置masterauth选项,那么进行身份验证
如果从服务器没有设置masterauth选项,那么不进行身份验证
如果需要进行身份验证,从服务器将向主服务器发送AUTH命令,命令的参数为从服务器的masterauth选项
15.6.5 步骤5 发送端口信息
确认身份后,从服务器将向主服务器发送监听端口号,主服务器收到后,将其存储在从服务器对应的客户端状态的slave_listening_port属性中,目前该属性只用于打印从服务器的端口号
typedef struct redisClient{ //从服务器的监听端口号 int slave_listening_port; //.... }redisClient;
15.6.6 步骤6 同步
当同步操作开始之后,主服务器也成为从服务器的客户端,只有这样,才能向从服务器发送缓冲区中的写命令(写入RDB文件期间产生的写操作),或是向从服务器发送复制积压缓冲区中的写命令
15.6.7 步骤7 命令传播
同步完成之后,主从服务器进入命令传播阶段,主服务器将写命令传递给从服务器执行
15.7 心跳检测
在命令传播阶段,从服务器默认每秒一次的频率,向主服务器发送命令:
REPLCONF ACK <replication_offset>,其中replication_offset是从服务器当前的复制偏移量
15.7.1 检测主从服务器的网络连接状态
主从服务器通过接收和回复REPLCONF ACK命令确认两者之间的连接状态,如果主服务器超过1秒没有收到命令,则表明两者之间出现连接问题
15.7.2 辅助实现min-slaves配置选项
Redis的min-slaves-to-write和min-slaves-max-lag配置确保主服务器不会在不安全的情况执行写命令
min-slaves-to-write:最小写命令执行从服务器数量 //譬如3
min-slaves-max-lag:最大写命令执行服务器延迟 //譬如10
如果当前连接的从服务器数量小于3或者连接的从服务器延迟(最后一次心跳检测时间)都大于等于10秒时,上面的配置含义是最少保证3个从服务器的延迟时间不能超过10秒,否则主服务器将拒绝执行写命令。这个是为了解决脑裂的问题,即这个主服务器被哨兵误认为下线,从而另选取了新的主节点,此时主服务器已经跟整个组单独分隔开了。但是原主服务器自己不自知,仍然处理写请求的话,会导致数据丢失。
15.7.3 检测命令丢失
主服务器可以检测从服务器发送心跳时的复制偏移量,确认是否需要向从服务器同步缺失的写操作
后记:
1. 持久化通过将数据保存到硬盘,保证了服务重启也不会丢失数据。主从复制保证了单个服务器硬盘损坏的情况下,也能通过其他服务器还原,同时在一个服务器发生故障时,不影响使用。避免了单点故障
数据丢失:
1. 产生的原因
(1)主从切换,丛机尚未完全同步
(2)集群脑裂,客户请求到旧主机
2. 解决方案
对于主机突然下线的情况,此时无解,因为主从的数据同步是异步执行的。可以通过15.7.2的配置来降低出现脑裂时,数据丢失量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号