pytorch 笔记
numpy中匹配一个shape是3,4,5的array中的最后一维==(0,0,0,0,1)的数量,就是这12个长度为5的子array里面有几个等于目标小array
注意(a==b).sum()会返回错误结果,因为broadcast的结果是b被扩充后,单个元素相同则返回1,就不是整个array的匹配了。
((a==b).sum(3)==5).sum()才能返回需要的结果,
pdb.set_trace = lambda: 1忽略pdb.set_trace 继续运行
one-hot形式的坐标的使用方式:
You can use broadcasting -
(np.array(s)[:,None]==np.arange(num_classes))+0
numpy的两端加维度的方式:
a.shape=[1,2,3]
a[:,None].shape=[1,2,3,1]
就是用None去填充新的维度。肯定有更深刻的indexing原理来解释这个事情,涉及broadcast操作。
torch的argmax再所有数都相同的时候,会返回最后一个坐标。
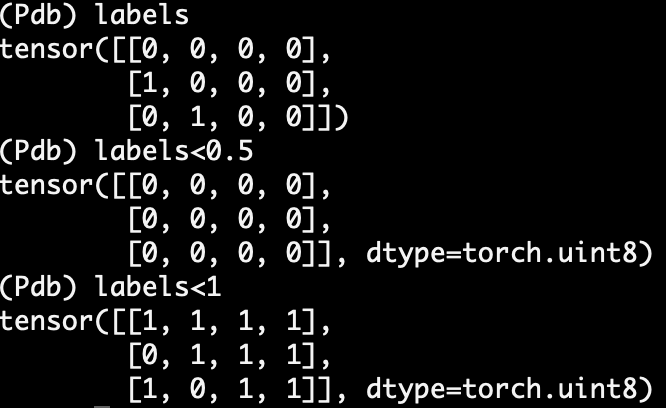
不同类型比较:
tensor如果是int类型的话,不能直接和float做比较,如下图,真弱智。
numpy上就能得到自己想要的
DataParallel 几个gpu同时运行,每个处理不同的样例,而不是每个在同一个样例的不同阶段,然后一同把梯度加起来作为最终结果。这样子,如果一个batch是128,4个gpu,哪个一个batch分成4份喂到gpu里面,这样其实和一个gpu是一样结果的。
torch.cuda()会把现在创建的tensor都创建在当前选择的device里面。
b = torch.tensor([1., 2.]).cuda()这是两步动作,先在cpu创建,后放到gpu中。一步动作:
b2 = torch.tensor([1., 2.]).to(device=cuda)
python打印module路径
import torchvision
print(torchvision.__file )
python中,class内部的属性变量不用非要在__init__中做一个self.才算。只要在class生命下有一个变量声明就行了:
class t:
train=3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号