Mysql优化
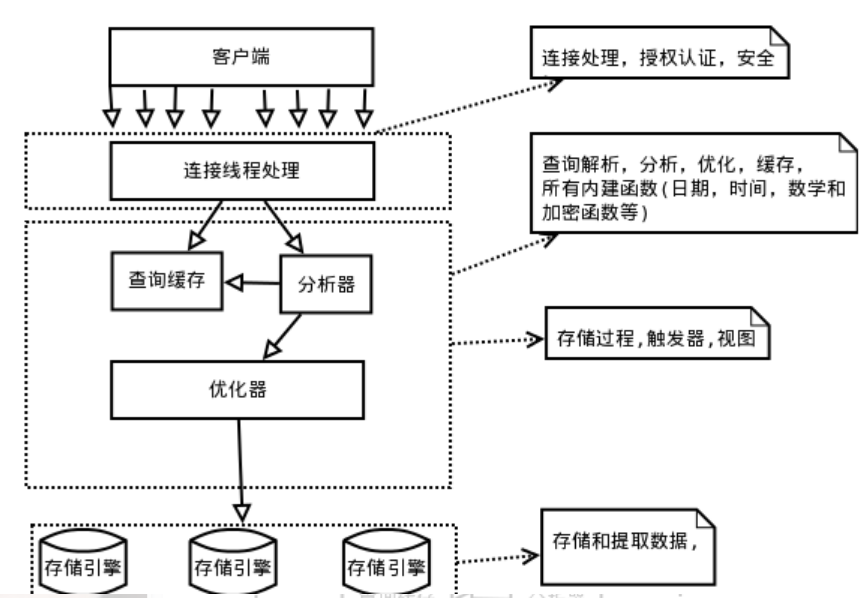
一、Mysql的逻辑架构
二、存储引擎
Mysql5.5之前,默认存储引擎是MyISAM,5.5之后默认存储引擎变成InnoDB。
MyISAM和InnoDB的区别:
1)MyISAM不支持事务、InnoDB支持事务
2)MyISAM只有表锁、InnoDB引入了行锁
3)MyISAM支持全文索引、InnoDB 5.5不支持,5.6以后支持
4)MyISAM的读写速度会优于InnoDB
三、MySQL优化(SQL优化)
· 数据类型的优化(创建表的时候,选择合适的数据类型)
· 索引优化(SQL优化成本最低并且最有效果的优化方式)
· 查询优化(SQL自带的检测工具、SQL结构)
· 库表结构优化(分库分表、读写分离)
· 硬件优化(cpu、固态硬盘、内存)
· 参数优化(系统运行参数)- DBA
四、数据类型的优化
数据类型的选择原则:
· 选择最小的数据类型,同时需要保证能够放下所存储的数据
· 选择最合适的数据类型,比如使用int表示年龄,而是不是varchar表示年龄
· 尽量让需要添加索引的列为not null
五、索引优化
什么是索引?
索引是一本书的目录,可以快速找到相应的内容。
索引是一个帮助我们快速查询内容的数据结构。
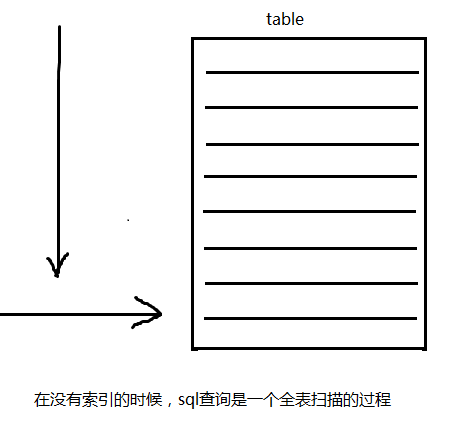
无索引的查询方式:
有索引的查询方式:
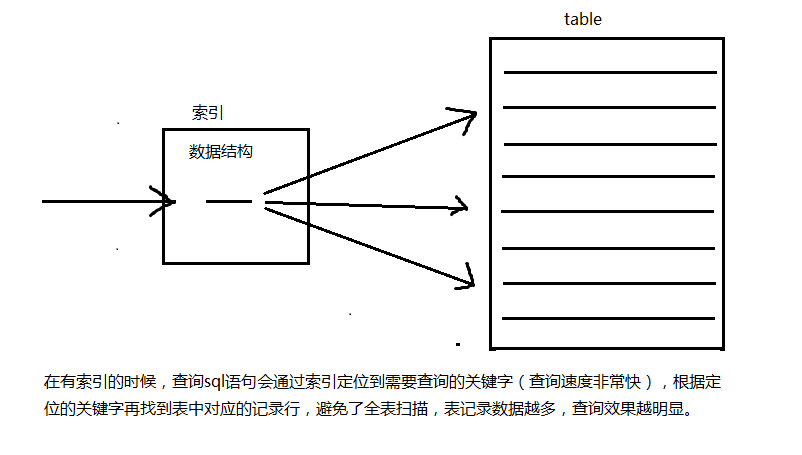
索引失效:
当写了一个索引后,开发者认为执行的sql会用上该索引,但是实际上Mysql没有使用该索引,这种情况就是索引失效。
索引的底层原理
Mysql的MyISAM和InnoDB两大存储引擎底层的索引结构采用的都是B+Tree索引。
为什么MySQL不采用查询速度更快的哈希表所谓索引结构呢?
哈希表只支持精准查询,但是范围查询无能为力,相对来说,SQL语句有可能会出现大量的范围查询,这种情况下,哈希索引就会失效,变成全表扫描。
为什么MySQL不采用搜索性能很棒,并且也支持范围查询的数据结构 - 红黑树?
BTree的结构:

B+Tree的结构:
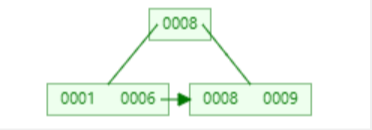
B+Tree的升级:
1)所有的非叶子节点,都会出现在叶子节点上
2)所有的叶子节点之间会形成一个双向链表
MySQL创建索引

问题:
1)多列索引在底层会生成几颗索引树? - 1颗(所有列都在一颗B+Tree上)
2)多列索引列的顺序有没有关系?- 列的顺序很重要,不同的顺序会导致索引的作用不同
注意:唯一索引会保证当前字段数据不会重复,但是又可能为null,而且有可能有多个null
模拟一个底层索引结构的创建过程(重要):
复合索引的底层B+Tree结构,会按照最左边的字段进行排序,当第一个字段相同的时候,再根据第二个字段排序,以此类推...
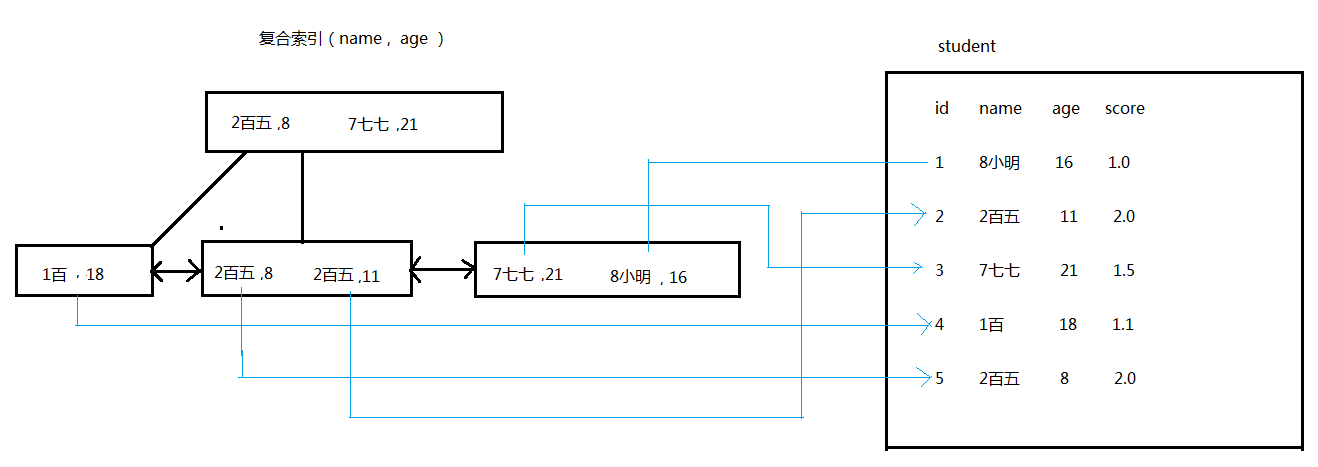
select * from student where name = "xxx" : 能够用上上述的索引(因为索引树是根据name排列)
select * from student where age = xxx:不能用上上述的索引(因为索引树不能根据age排列)
select * from student where name = "xxx" and age = xxx:完美用上上述的索引
select * from student where name like "%明%":不能用上上述索引的
select * from student where name like "8%":能用上索引的
select * from student where name > "2百五" and age = 8:name能用上索引,age不能用上索引
select * from student where name = "2百五" and age > 8: name和age都完美的用上了索引
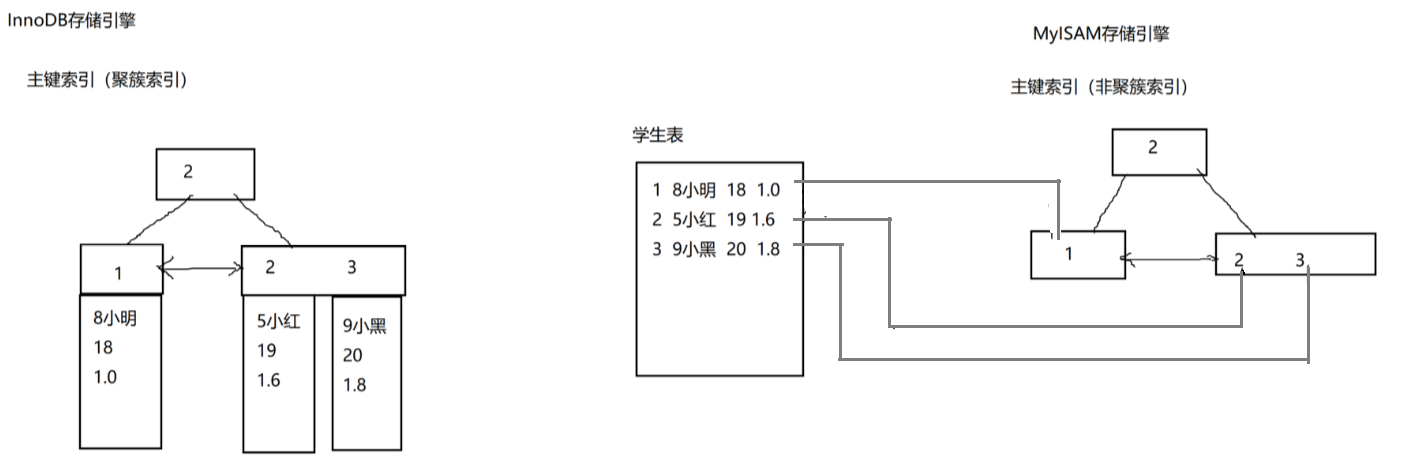
聚簇索引:
什么是聚簇索引?
InnoDB类型的表,主键索引就是聚簇索引。MyISAM类型的表,主键是非聚簇索引。
二级索引的查询方式:
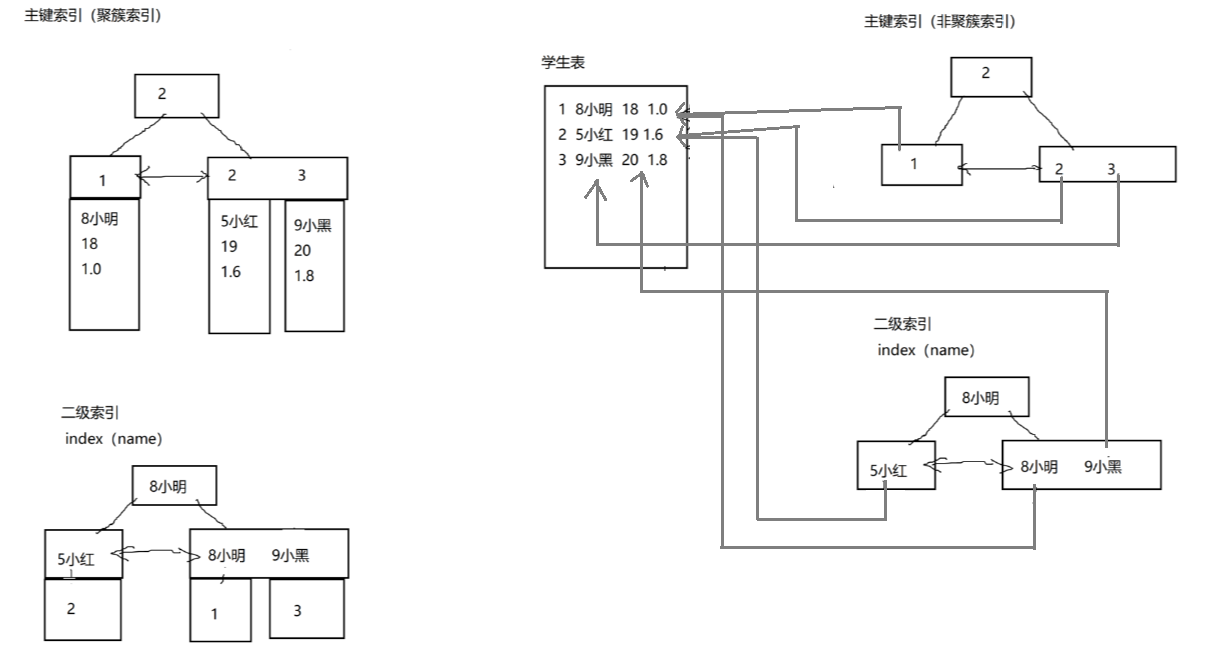
注意:根据InnoDB聚簇索引的特点,在InnoDB类型的表中,MySQL推荐我们一定要提供一个和业务无关并且自动增长的字段作为表的主键。
如果InnoDB中的表没有主键怎么办?
如果一张表没有主键,则MySQL会选择一列唯一性索引的列作为聚簇索引。如果表中没有一列上面有唯一性索引,则MySQL会自动的创建一个隐性的列,作为聚簇索引。
覆盖索引:
什么是覆盖索引?
就是查询的字段,在索引中就有保存,这种方式,就避免了查询完索引后,返回表中获取数据,性能会得到一定的提升。
六、执行计划
什么是执行计划?
一个Sql语句在经过优化器之后,会生成一个执行计划,这个执行计划就决定了MySQL最终如何执行这条SQL语句。所以分析一条SQL语句的执行计划,通常是优化这个SQL语句的第一步。
如何查询一个SQL的执行计划?
explain (查询)sql语句
字段的含义:
id:标识当前执行的sql语句的顺序
· id值相同的情况:如果id值相同,说明执行计划的顺序是从上到下
· id值不同的情况:如果id值不同,id值比较大的执行计划优先级更高
· id值相同不同同时存在:先看id大的,id相同的从上到下
· id为null:如果id为null则表示这部分最后执行
注意:MySQL中的关联原则,小表驱动大表
select_type:查询类型
· simple:说明当前的查询是一个简单查询
· primary:如果一个sql语句中间包含了子查询,则外层查询就会变成primary,primary标记的部分也可以理解成为最后执行的部分
· subquery:select或者where后面出现的子查询会被标记为subquery
· derived(衍生):标记出现在from后面的子查询
· union:union关键字后面的sql语句会被标记为该类型
mysql对查询的分类:
· 简单查询:没有子查询和union的查询语句
· 复杂查询:包含了子查询和union的查询语句
type(重要):表示当前SQL是根据什么方式访问数据行的
· all:说明当前查询数据的方式采用的是全表扫描
· index:说明当前查询是一个全索引扫描,效果和全表扫描差不多,只是说根据索引树的结构进行了全部的扫描,性能比all稍微好一些(不是绝对的)
· range:说明当前的查询是一个索引的范围查询,说明当前没有走完整个索引,只走了索引的一部分
· ref:说明当前的查询时一个精准的非唯一性的查询,查询了索引的一小部分,通常出现在对非唯一性的索引的查询上
· eq_ref:说明当前的查询是一个精准的唯一性查询,通常出现在唯一性索引、主键索引以及连接查询上
· const:说明当前的查询将条件转换成一个常量执行,通常出现在唯一性索引和主键索引的精准查询上
· system:是const的一种特殊情况,表示进准查询了唯一性索引或者主键索引并且mysql保证数据集只有一条记录
· null:这种情况说明当前的sql语句都不用进行查询,在解析的时候就能够获得结果
rows(重要):表示MySQL预估的当前SQL需要读取到的数据行数,这个值越小越好
possible_keys:表示可能运用在这个查询上的索引
keys(重要):表示当前真正用上的索引
注意:有可能发生这种情况,possible_keys里面有索引,但是keys为null;possible_keys为null,但是keys不为null;
Extra(重要):表示一些额外的信息,展示的地方
· Using Index:说明发生了覆盖索引
· Using temporary:说明查询语句用上了临时表,尽量避免(并不是看到了就一定要避免)
· Using filesort:说明当前发生了文件外排序(有可能在内存中排序,有可能用上了磁盘排序)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号