第四次作业(Hadoop思想与原理)
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
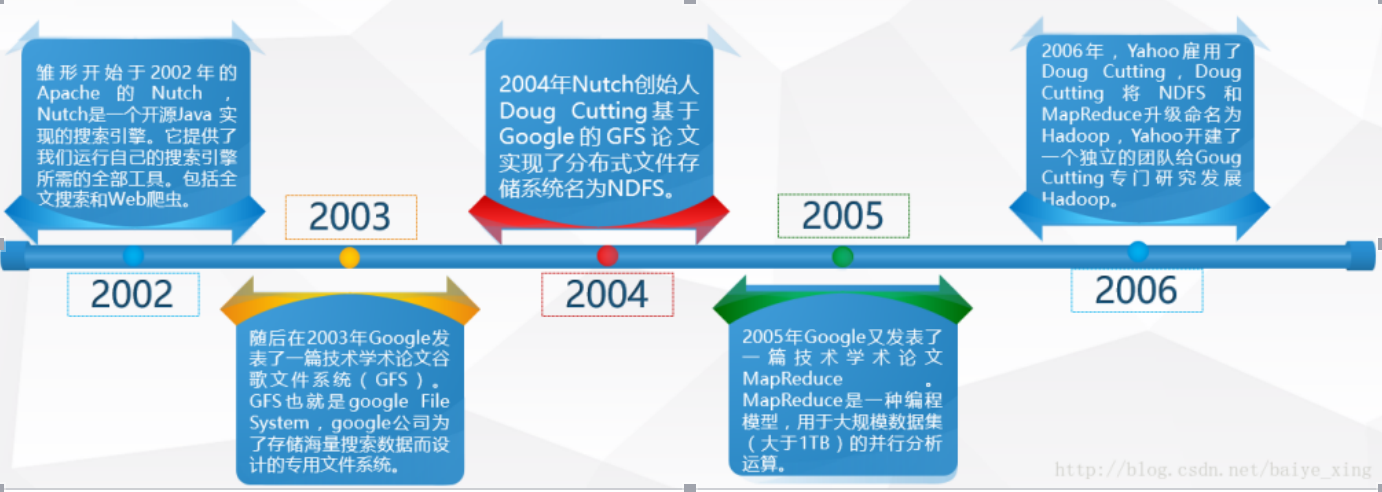
1)Lucene 是 Doug Cutting 开创的开源软件,实现与 Google 类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001 年年底成为 Apache 基金会的一个子项目
3)Google的三篇论文是 hadoop 的思想之源(Google 在大数据方面的三篇论文)
GFS --->HDFS
Map-Reduce --->MR
BigTable --->Hbase
4)2003-2004 年,Google 公开了部分 GFS 和 Mapreduce 思想的细节,以此为基础 Doug Cutting等人用了 2 年业余时间实现了 DFS 和 Mapreduce 机制
5)2006 年3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
6)名字来源于 Doug Cutting 儿子的玩具大象,Hadoop由此诞生
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系
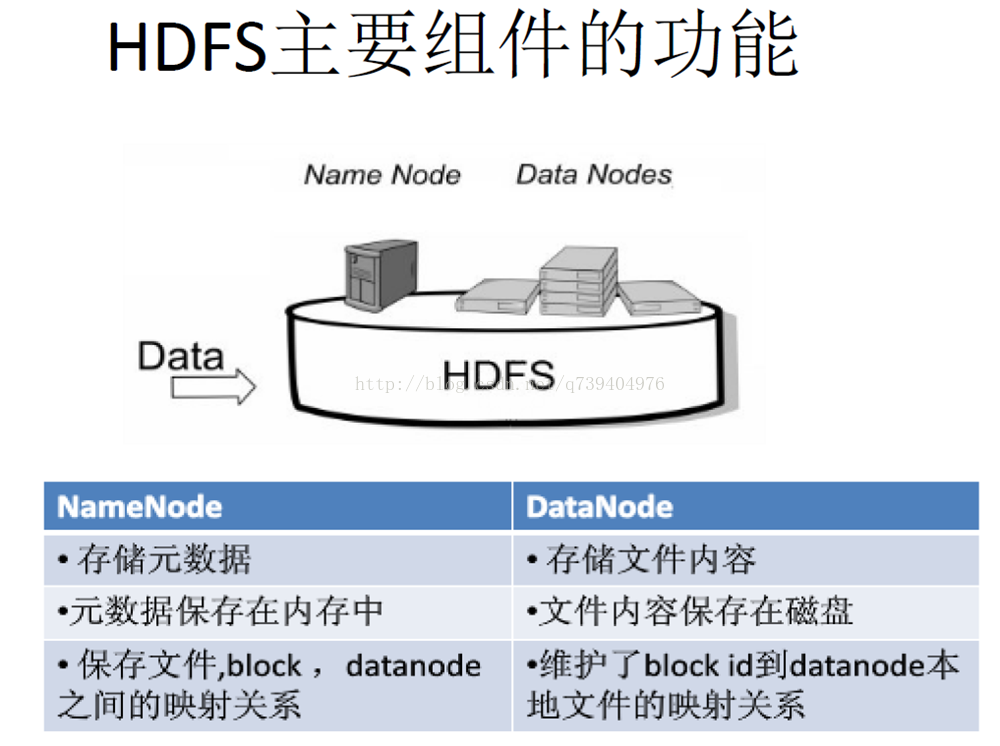
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
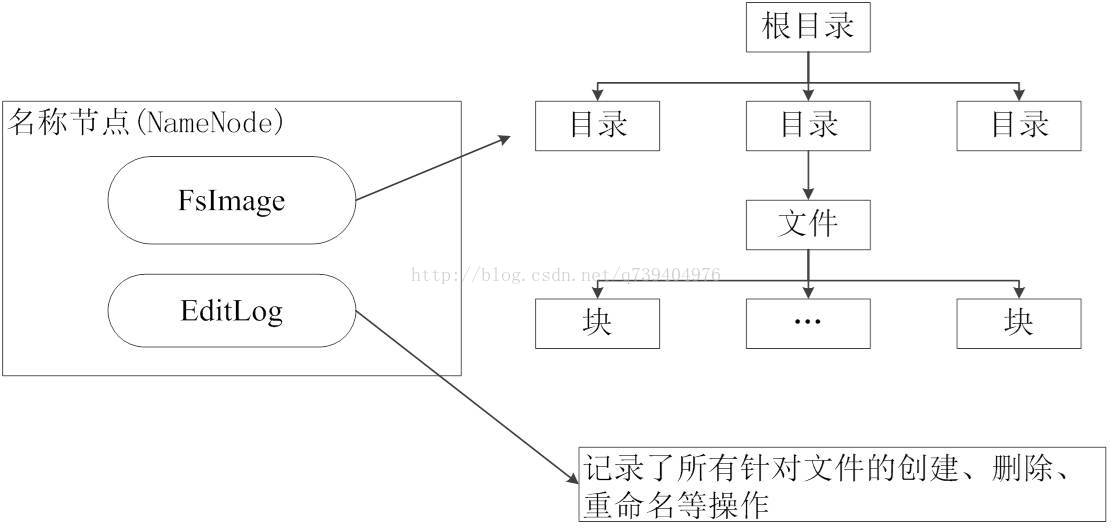
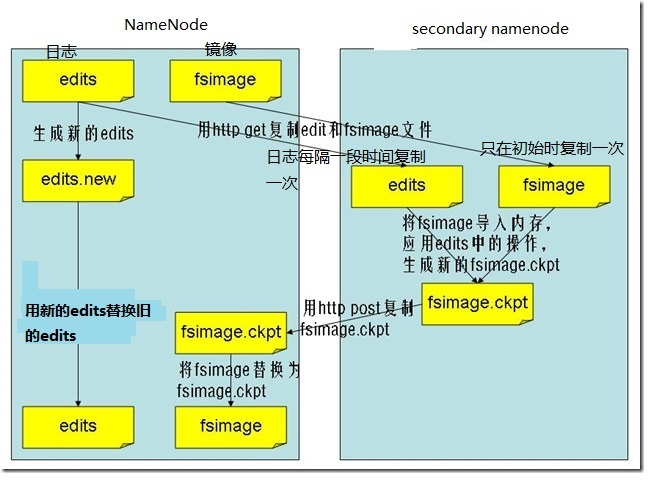
第二名称节点(SecondaryNameNode)
:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般是单独运行在一台机器上
SecondaryNameNode让EditLog变小的工作流程:
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
![]()
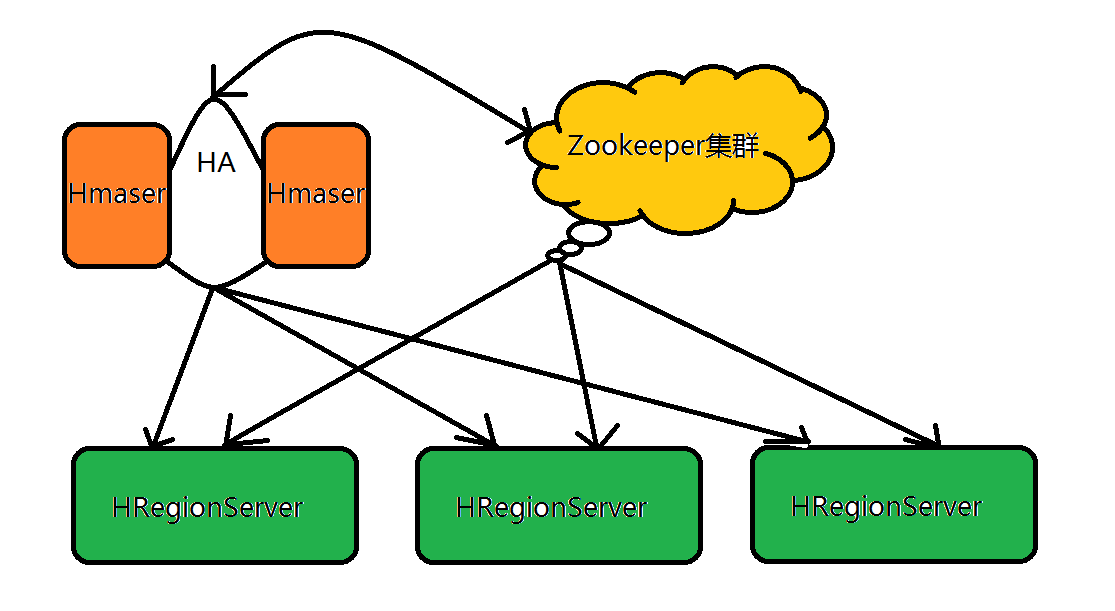
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 与HDFS的关联
Client
包含访问HBase的接口,并维护cache来加快对HBase的访问。
Zookeeper的作用
HBase依赖Zookeeper,默认情况下HBase管理Zookeeper实例(启动或关闭Zookeeper),Master与RegionServers启动时会向Zookeeper注册。
Zookeeper的作用:
保证任何时候,集群中只有一个master
存储所有Region的寻址入口
实时监控Region server的上线和下线信息。并实时通知给master
存储HBase的schema和table元数据
HMaster的作用
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region。
HDFS上的垃圾文件回收。
处理schema更新请求。
HRegionServer的作用
维护master分配给他的region,处理对这些region的io请求。
负责切分正在运行过程中变的过大的region。
注意:client访问hbase上的数据时不需要master的参与,因为数据寻址访问zookeeper和region server,而数据读写访问region server。master仅仅维护table和region的元数据信息,而table的元数据信息保存在zookeeper上,因此master负载很低。
HRegion
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
5.完整描述Hbase表与Region的关系,三级寻址原理。
6.理解并描述Hbase的三级寻址。
元数据表,又名.META.表,存储了Region和Region服务器的映射关系
当HBase表很大时, .META.表也会被分裂成多个Region。即.META表由多个Reigion存储,涉及到查找.META 的Reigion和对应Reigion服务器映射关系问题(由-ROOT表完成)
根数据表,又名-ROOT-表,记录所有元数据的具体位置。记录了.META 的Reigion和对应Reigion服务器映射关系。
-ROOT-表只有唯一一个Region,名字是在程序中被写死的
Zookeeper文件记录了-ROOT-表的位置

为了加快访问速度,.META.表的全部Region都会被保存在内存中
假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为128MB,那么,上面的三层结构可以保存的用户数据表的Region数目的计算方法是:
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数)
一个-ROOT-表最多只能有一个Region,也就是最多只能有128MB,按照每行(一个映射条目)占用1KB内存计算,128MB空间可以容纳128MB/1KB=128*1024=217行,也就是说,一个-ROOT-表可以寻址217个.META.表的Region。
同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是128MB/1KB=217。
最终,三层结构可以保存的Region数目是(128MB/1KB)
× (128MB/1KB) = 234个Region
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
三层结构可以保存的Region数目是(1024×1024MB/1KB) × (1024×1024MB/1KB) = 2的60次方个Region
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
1、Map 阶段
Map 阶段是由一定数量的 Map Task 组成。这些 Map Task 可以同时运行,每个 Map Task又是由以下三个部分组成。
1) 对输入数据格式进行解析的一个组件: InputFormat 。因为不同的数据可能存储的数据格式不一样,这就需要有一个 InputFormat 组件来解析这些数据的存放格式。默认情况下,它提供了一个 TextInputFormat 来解释数据格式。TextInputFormat 就是我们前面提到的文本文件输入格式,它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容。通常情况我们不需要自定义 InputFormat,因为 MapReduce 提供了很多种InputFormat的实现,我们根据不同的数据格式,选择不同的 InputFormat 来解释就可以了。这一点我们后面会讲到。
1) 输入数据处理: Mapper
这个 Mapper 是必须要实现的,因为根据不同的业务对数据有不同的处理。
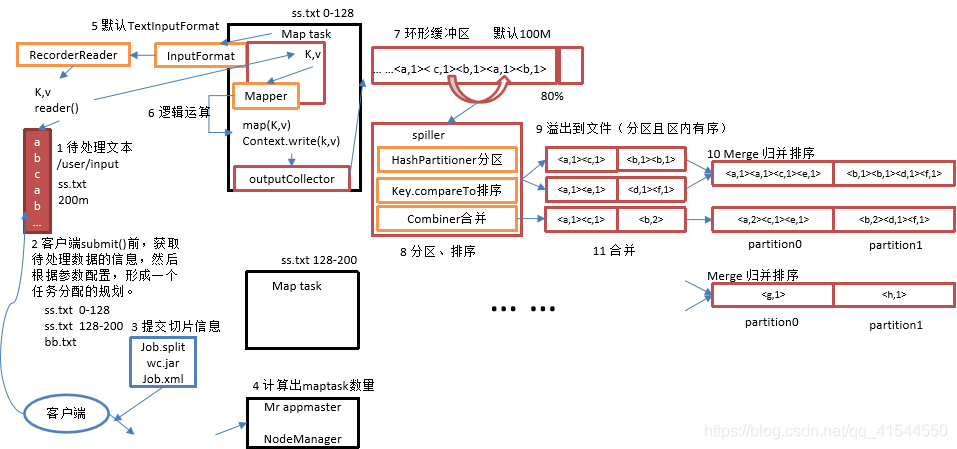
9.MapReduce的工作过程,用自己的例子,将整个过程梳理并用图形表达出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号