八种架构设计模式及其优缺点概述(下)
在上篇文章中,介绍了八种架构设计模式中的三种,既:查询分离模式、微服务模式、多级缓存模式,没有读过的同学请手动微信关注“码农原创”公众号,在历史消息中寻找。接下来继续介绍最后的三种架构模式,分别是:分库分表模式、弹性伸缩模式、多机房模式。
1. 分库分表模式
这种模式主要解决单表写入、读取、存储压力过大,从而导致业务缓慢甚至超时,交易失败,容量不够的问题。一般有水平切分和垂直切分两种,这里主要介绍水平切分。这个模式也是技术架构迭代演进过程中的必经之路。
这种模式的一般设计见下图:

如上图所示红色部分,把一张表分到了几个不同的库中,从而分担压力。是不是很笼统?哈哈,那我们接下来就详细的讲解一下。首先澄清几个概念,如下:
主机:硬件,指一台物理机,或者虚拟机,有自己的CPU,内存,硬盘等。
实例:数据库实例,如一个MySQL服务进程。一个主机可以有多个实例,不同的实例有不同的进程,监听不同的端口。
库:指表的集合,如学校库,可能包含教师表、学生表、食堂表等等,这些表在一个库中。一个实例中可以有多个库。库与库之间用库名来区分。
表:库中的表,不必多说,不懂的就不用往下看了,不解释。
那么怎么把单表分散呢?到底怎么个分发呢?分发到哪里呢?以下是几个工作中的实践,分享一下:
主机:这是最主要的也是最重要的点,本质上分库分表是因为计算与存储资源不够导致的,而这种资源主要是由物理机,主机提供的,所以在这里分是最基本的,毕竟没有可用的计算资源,怎么分效果都不是太好的。
实例:实例控制着连接数,同时受OS限制,CPU、内存、硬盘、网络IO也会受间接影响。会出现热实例的现象,即:有些实例特别忙,有些实例非常的空闲。一个典型的现象是:由于单表反应慢,导致连接池被打满,所有其他的业务都受影响了。这时候,把表分到不同的实例是有一些效果的。
库:一般是由于单库中最大单表数量的限制,才采取分库。
表:单表压力过大,索引量大,容量大,单表的锁。据以上,把单表水平切分成不同的表。
大型应用中,都是一台主机上只有一个实例,一个实例中只有一个库,库==实例==主机,所以才有了分库分表这个简称。
既然知道了基本理论,那么具体是怎么做的呢?逻辑是怎么跑的呢?接下来以一个例子来讲解一下。
这个需求很简单,用户表(user),单表数据量1亿,查询、插入、存储都出现了问题,怎么办呢?
首先,分析问题,这个明显是由于数据量太大了而导致的问题。
其次,设计方案,可以分为10个库,这样每个库的数据量就降到了1KW,单表1KW数据量还是有些大,而且不利于以后量的增长,所以每个库再分100个表,这个每个单表数据量就为10W了,对于查询、索引更新、单表文件大小、打开速度,都有一些益处。接下来,给IT部门打电话,要10台物理机,扩展数据库......
最后,逻辑实现,这里应该是最有学问的地方。首先是写入数据,需要知道写到哪个分库分表中,读也是一样的,所以,需要有个请求路由层,负责把请求分发、转换到不同的库表中,一般有路由规则的概念。
怎么样,简单吧?哈哈,too 那义务。说说这个模式的问题,主要是带来了事务上的问题,因为分库分表,事务完成不了,而分布式事务又太笨重,所以这里需要有一定的策略,保证在这种情况下事务能够完成。采取的策略如:最终一致性、复制、特殊设计等。再有就是业务代码的改造,一些关联查询要改造,一些单表orderBy的问题需要特殊处理,也包括groupBy语句,如何解决这些副作用不是一句两句能说清楚的,以后有时间,我单独讲讲这些。
该总结一下这种模式的优缺点的了,如下:
优点:减少数据库单表的压力。
缺点:事务保证困难、业务逻辑需要做大量改造。
2. 弹性伸缩模式
这种模式主要解决突发流量的到来,导致无法横向扩展或者横向扩展太慢,进而影响业务,全站崩溃的问题。这个模式是一种相对来说比较高级的技术,也是各个大公司目前都在研究、试用的技术。截至今日,有这种思想的架构师就已经是很不错了,能够拿到较高薪资,更别提那些已经实践过的,甚至实现了底层系统的那些,所以,你懂得......
这种模式的一般设计见下图:
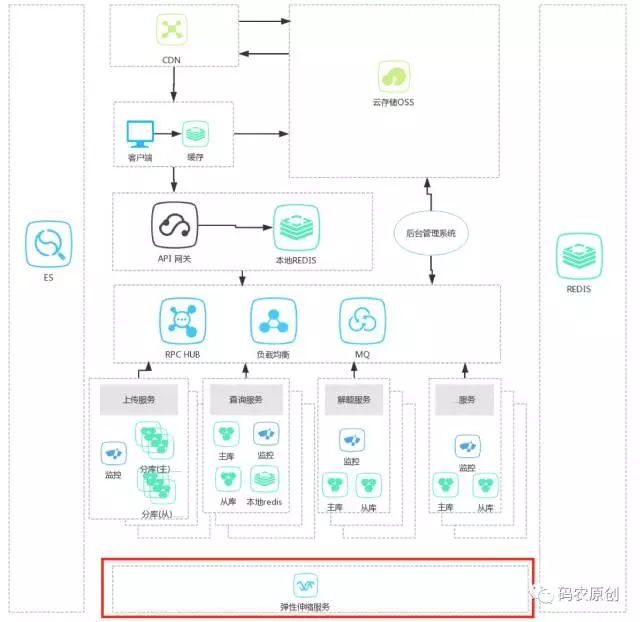
如上图所示,多了一个弹性伸缩服务,用来动态的增加、减少实例。原理上非常简单,但是这个模式到底解决什么问题呢?先说说由来和意义。
每年的双11、六一八或者一些大促到来之前,我们都会为大流量的到来做以下几个方面的工作:
-
提前准备10倍甚至更多的机器,即使用不上也要放在那里备着,以防万一。这样浪费了大量的资源。
-
每台机器配置、调试、引流,以便让所有的机器都可用。这样浪费了大量的人力、物力,更容易出错。
-
如果机器准备不充分,那么还要加班加点的重复上面的工作。这样做特别容易出错,引来领导的不满,没时间回家陪老婆,然后你的老婆就......(自己想)
在双十一之后,我们还要人工做缩容,非常的辛苦。一般一年中会有多次促销,那么我们就会一直这样,实在是烦!
最严重的,突然间的大流量爆发,会让我们触不及防,半夜起来扩容是在正常不过的事情,为此,我们偷懒起来,要更多的机器备着,也就出现了大量的cpu利用率为1%的机器。
我相信,如果你是老板一定很震惊吧!!!
哈哈,那么如何改变这种情况呢?请接着看
为此,首先把所有的计算资源整合成资源池的概念,然后通过一些策略、监控、服务,动态的从资源池中获取资源,用完后在放回到池子中,供其他系统使用。
具体实现上比较成熟的两种资源池方案是VM、docker,每个都有着自己强大的生态。监控的点有CPU、内存、硬盘、网络IO、服务质量等,根据这些,在配合一些预留、扩张、收缩策略,就可以简单的实现自动伸缩。怎么样?是不是很神奇?深入的内容我们会在的码农原创的公众号文章中详细介绍。
该总结一下这种模式的优缺点的了,如下:
优点:弹性、随需计算,充分优化企业计算资源。
缺点:应用要从架构层做到可横向扩展化改造、依赖的底层配套比较多,对技术水平、实力、应用规模要求较高。
3. 多机房模式
这种模式主要解决不同地区高性能、高可用的问题。
随着应用用户不断的增加,用户群体分布在全球各地,如果把服务器部署在一个地方,一个机房,比如北京,那么美国的用户使用应用的时候就会特别慢,因为每一个请求都需要通过海底光缆走上个那么一秒钟(预估)左右,这样对用户体验及其不好。怎么办?使用多机房部署。
这种模式的一般设计见下图:
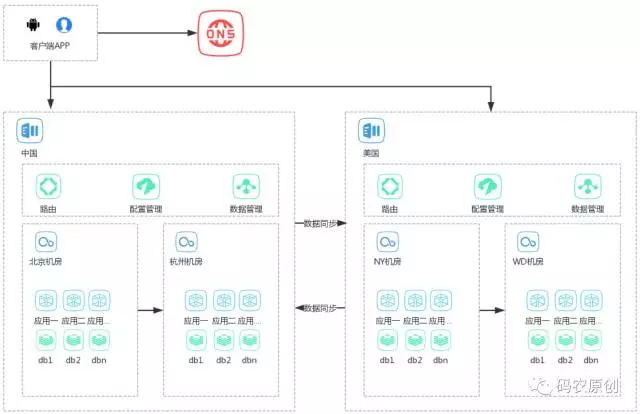
如上图所示,一个典型的用户请求流程如下:
-
用户请求一个链接A
-
通过DNS智能解析到离用户最近的机房B
-
使用B机房服务链接A
是不是觉得很简单,没啥?其实这里面的问题没有表面这么简单,下面一一道来。
首先是数据同步问题,在中国产生的数据要同步到美国,美国的也一样,数据同步就会涉及数据版本、一致性、更新丢弃、删除等问题。
其次是一地多机房的请求路由问题,典型的是如上图,中国的北京机房和杭州机房,如果北京机房挂了,那么要能够通过路由把所有发往北京机房的请求转发到杭州机房。异地也存在这个问题。
所以,多机房模式,也就是异地多活并不是那么的简单,这里只是起了个头,具体的有哪些坑,会在另一篇文章中介绍。
该总结一下这种模式的优缺点的了,如下:
优点:高可用、高性能、异地多活。
缺点:数据同步、数据一致性、请求路由。
呵呵,至此,整个关于八种架构设计模式及其优缺点概述就介绍完了,大约1W字左右。最后,我想说的是没有银弹、灵活运用,共勉!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号