
mysql 对指定字段进行去重并返回最新一条记录
源表数据结构
CREATE TABLE `c_org_index_score` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`org_name` varchar(255) DEFAULT NULL COMMENT '部门编码',
`org_code` varchar(255) DEFAULT NULL COMMENT '部门名称',
`index_code` varchar(255) DEFAULT NULL COMMENT '指标编码',
`score` int(11) DEFAULT NULL COMMENT '评分',
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=76 DEFAULT CHARSET=utf8 COMMENT='部门指标评分表';
插入数据
INSERT INTO `c_org_index_score`(`org_name`, `org_code`, `index_code`, `score`, `create_date`) VALUES ('纪委监委', 'GO_yb8ptad3itmc9', 'index_1', 90, '2021-12-09 16:12:16');
INSERT INTO `c_org_index_score`(`org_name`, `org_code`, `index_code`, `score`, `create_date`) VALUES ('市委办', 'GO_nex86hpyof9ozy', 'index_1', 92, '2021-12-09 16:12:16');
INSERT INTO `c_org_index_score`(`org_name`, `org_code`, `index_code`, `score`, `create_date`) VALUES ('纪委监委', 'GO_yb8ptad3itmc9', 'index_2', 90, '2021-12-09 16:12:16');
INSERT INTO `c_org_index_score`(`org_name`, `org_code`, `index_code`, `score`, `create_date`) VALUES ('市委办', 'GO_nex86hpyof9ozy', 'index_2', 90, '2021-12-09 16:12:16');
INSERT INTO `c_org_index_score`(`org_name`, `org_code`, `index_code`, `score`, `create_date`) VALUES ('纪委监委', 'GO_yb8ptad3itmc9', 'index_1', 85, '2021-12-10 09:12:16');
INSERT INTO `c_org_index_score`(`org_name`, `org_code`, `index_code`, `score`, `create_date`) VALUES ('市委办', 'GO_nex86hpyof9ozy', 'index_1', 86, '2021-12-10 09:12:14');
源表数据如下,当我需要查询本周各部门index_1的分数时,只需要获取最新的记录。
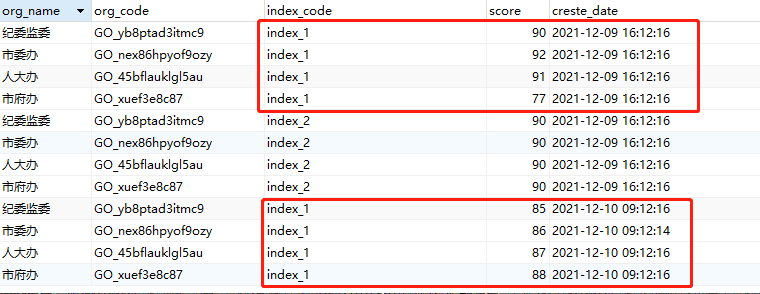
目标数据内容:index_code 为 ‘index_1’的score应该获取日期为2021-12-10的数据
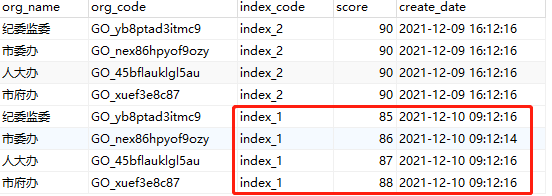
方案一
SELECT * FROM c_org_index_score
WHERE
id NOT IN (SELECT min_id FROM ( SELECT min( id ) AS min_id, index_code, org_name, create_date FROM c_org_index_score GROUP BY org_name ) t );
思路:
一般数据表设计会定义id自增,这时先对数据分组,查询分组中最小的id,并排除相应数据即可。
1)以分组字段进行分组,获取分组中最小的id内容;
2)查询条件设为排除“分组后最小的一组id”。
该方案的缺陷是,如果按照org_name进行分组时,存在一部分org_name原本就只有一组,那么在使用id not in() 方式时,会将仅有的一组org_name排除在外。
方案二:
SELECT
id,
org_name,
org_code,
SUBSTRING_INDEX(GROUP_CONCAT( index_code ORDER BY create_date DESC ), ',', 1) AS index_code,
SUBSTRING_INDEX( GROUP_CONCAT( score ORDER BY create_date DESC ), ',', 1 ) AS score,
max(create_date) create_date
FROM
c_org_index_score
GROUP BY
org_code,
create_date
ORDER BY
create_date DESC;
思路:
将需要去重的字段,先按照降序排列,然后通过 GROUP_CONCAT() 函数进行连接,通过SUBSTRING_INDEX() 截取第一个数值。全表通过指定字段和时间字段进行分组。
这种方式需要注意将对应的字段值,也通过同样的方式取值,以达到字段值的匹配。
该方案存在的缺陷是,字段数很多且都需要获取最新记录的时候,SUBSTRING_INDEX() 函数、GROUP_CONCAT()函数在每个字段中都要拼接,SQL语句繁琐、组织麻烦。
方案三:
SELECT * FROM (SELECT * FROM c_org_index_score ORDER BY create_date desc limit 10)t GROUP BY t.org_name,t.index_code
思路:
通过EXPLAIN 执行后可以看到, 该方案在搜索过程中使用了临时表,即 order by 与limit 一起使用时,mysql在排序结果中找到最初的row_count行之后就会完成这条语句,而不是对整个结果集进行排序。
EXPLAIN SELECT * FROM (SELECT * FROM c_org_index_score ORDER BY create_date desc limit 4)t GROUP BY t.org_name,t.index_code;

相关函数说明
1)substring_index(str,delim,count) 将str字段按指定分隔符进行分割,截取分割后的count个字段内容。
substring_index(str,delim,count)
str:要处理的字符串
delim:分隔符
count:计数
例如:
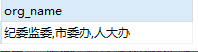
① SELECT SUBSTRING_INDEX( '纪委监委,市委办,人大办,公安厅', ',', 3 ) org_name;
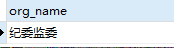
② SELECT SUBSTRING_INDEX( '纪委监委,市委办,人大办,公安厅', ',', 1 ) org_name
运行结果:
①
②
2)group_concat( [DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Separator ‘分隔符’] )
默认分割符是逗号
例如:
SELECT GROUP_CONCAT( org_name ORDER BY create_date DESC ) org_name_all FROM c_org_index_score;
运行结果


