七,一:django orm分组
day07-0-Django框架学习初阶(六)
聚合查询
aggregate()
"""
聚合aggregate()是QuerySet的一个终止语句,意思是,它返回了一个包含一些键值对的字典。其中,键的名称是聚合值的标识符,值是计算出来的聚合值,键的名称默认是按照字段和聚合函数的名称自动生成的。
"""
示例:
# 计算出所有书的平均价格
from django.db.models import Avg
from app01 import models
res = models.Book.objects.aggregate(Avg('price'))
"""
{'price__avg': 431.316667}
"""
如果你想给聚合值指定一个名称,可以向聚合子句提供它:
# 计算出所有书的平均价格、最高价格、最低价格、价格,以及书的个数
from django.db.models import Avg, Max, Min, Sum, Count
from app01 import models
res = models.Book.objects.aggregate(
average_price=Avg('price'),
max_price=Max('price'),
min_price=Min('price'),
sum_price=Sum('price'),
count_book=Count('pk'),
)
print(res)
"""
{'average_price': 431.316667, 'max_price': Decimal('1024.80'), 'min_price': Decimal('100.65'), 'sum_price': Decimal('1293.95'), 'count_book': 3}
"""
分组查询
annotate
mysql分组查询的特点:
"""
严格模式下,分组之后默认只能获取到分组的依据,组内其他字段无法获取直接获取了。
ONLY_FULL_GROUP_BY
"""
先准备几张表
book
| id | name | price | publish_id |
|---|---|---|---|
| 2 | 野性的呼唤 | 168.50 | 1 |
| 3 | 钢铁是怎样炼成的 | 100.65 | 2 |
| 4 | 聊斋 | 1024.80 | 3 |
author
| id | name | gender | age | author_detail_id |
|---|---|---|---|---|
| 1 | 奥斯特洛夫斯基 | 男 | 60 | 1 |
| 2 | 马克吐温 | 男 | 44 | 2 |
| 3 | 蒲松龄 | 男 | 18 | 3 |
book_authors
| id | book_id | author_id |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 2 |
| 4 | 3 | 3 |
| 5 | 4 | 3 |
author_details
| id | phone | addr | |
|---|---|---|---|
| 1 | 16519409444 | 16519409444@163.com | 海参崴北海镇 |
| 2 | 17053613666 | 17053613666@163.com | 夏威夷 |
| 3 | 17001842555 | 17001842555@163.com | 上海浦东 |
publish
| id | name | addr | |
|---|---|---|---|
| 1 | 花旗出版社 | 加利福利亚 | huaqi123@163.com |
| 2 | 远东出版社 | 海参崴 | yuandong666@126.com |
| 3 | 中华出版社 | 上海 | shanghai777@163.com |
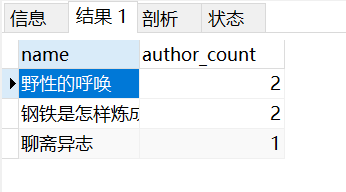
(1)统计每本书的作者个数
ORM
res = models.Book.objects.annotate(author_num=Count('authors')).values('name','author_num')
"""
<QuerySet [{'name': '野性的呼唤', 'author_num': 2}, {'name': '钢铁是怎样炼成的', 'author_num': 2}, {'name': '聊斋异志', 'author_num': 1}]>
"""
原生的 SQL语句查询
SELECT app01_book.`name`,COUNT(app01_book_authors.author_id) as 'author_count' FROM app01_book INNER JOIN app01_book_authors ON (app01_book.id=app01_book_authors.book_id) GROUP BY app01_book.id;
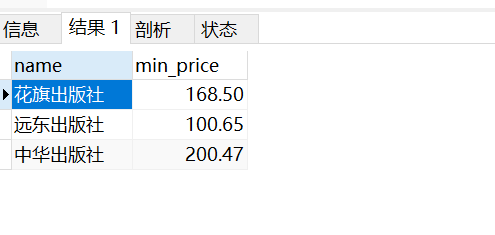
(2)统计每个出版社卖的最便宜的书的价格
ORM
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price')
"""
<QuerySet [{'name': '花旗出版社', 'min_price': Decimal('168.50')}, {'name': '远东出版社', 'min_price': Decimal('100.65')}, {'name': '中华出版社', 'min_price': Decimal('200.47')}]>
"""
原生的SQL语句查询
SELECT app01_publish.`name`,MIN(app01_book.price) AS 'min_price' FROM app01_publish INNER JOIN app01_book ON (app01_publish.id=app01_book.publish_id) GROUP BY app01_publish.id;
(3) 统计不止一个作者的图书
ORM
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('name','author_num')
"""
<QuerySet [{'name': '野性的呼唤', 'author_num': 2}, {'name': '钢铁是怎样炼成的', 'author_num': 2}, {'name': '青苹果乐园', 'author_num': 2}, {'name': '总统语录--普哥实训', 'author_num': 2}]>
"""
__gt >
__gte >=
__lt <
__lt <=
原生的SQL语句查询
SELECT app01_book.`name`,COUNT(app01_book_authors.author_id) as 'author_num' FROM app01_book INNER JOIN app01_book_authors ON (app01_book.id=app01_book_authors.book_id) GROUP BY app01_book.id HAVING COUNT(app01_book_authors.author_id) > 1;

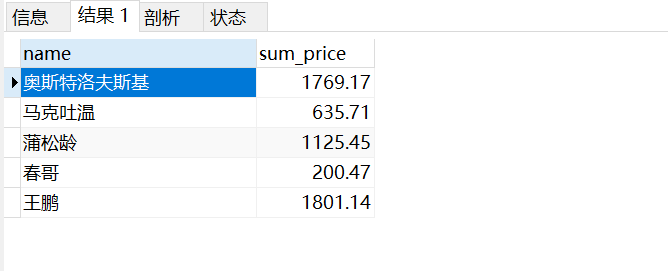
(4)查询每个作者出书的总价格
ORM
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
"""
<QuerySet [{'name': '奥斯特洛夫斯基', 'sum_price': Decimal('1769.17')}, {'name': '马克吐温', 'sum_price': Decimal('635.71')}, {'name': '蒲松龄', 'sum_price': Decimal('1125.45')}, {'name': '春哥', 'sum_price': Decimal('200.47')}, {'name': '王鹏', 'sum_price': Decimal('1801.14')}]>
"""
原生的SQL语句查询
SELECT app01_author.`name`,SUM(info.price) as 'sum_price' FROM app01_author INNER JOIN (SELECT app01_book.price,app01_book_authors.author_id FROM app01_book INNER JOIN app01_book_authors ON app01_book.id = app01_book_authors.book_id) AS info ON app01_author.id = info.author_id GROUP BY app01_author.id;
但是,如果我们想按照指定的字段分组,应该如何处理了?
res = models.Book.objects.values('price').annotate()
"""
<QuerySet [{'price': Decimal('168.50')}, {'price': Decimal('100.65')}, {'price': Decimal('1024.80')}, {'price': Decimal('200.47')}, {'price': Decimal('366.56')}, {'price': Decimal('1600.67')}]>
"""
等价于
SELECT `app01_book`.`price` FROM `app01_book`;
F&Q查询
"""
(1)当查询需要用字段和字段作比较的时候,用F查询
(2)当查询条件中含有"and or not"的时候,用Q查询
"""
F查询
(1)查询卖出大于库存的商品
from django.db.models import F
from app01 import models
res = models.Book.objects.filter(sell_out__gt=F('stock'))
print(res)
"""
<QuerySet [<Book: 书籍名:野性的呼唤>, <Book: 书籍名:钢铁是怎样炼成的>, <Book: 书籍名:聊斋异志>, <Book: 书籍名:青苹果乐园>]>
"""
sql原生语句:
"""
SELECT * FROM app01_book WHERE app01_book.sell_out > app01_book.stock;
"""
(2)将所有的书籍的库存都增加1024本
from django.db.models import F
from app01 import models
res = models.Book.objects.update(stock=F('stock')+1024)
"""
6
"""
sql原生语句:
"""
UPDATE `app01_book` SET `stock` = (`app01_book`.`stock` + 1024);
"""
(3)把所有的书名后面加上"(新款666)"
from django.db.models import F
from django.db.models import Value
from django.db.models.functions import Concat
models.Book.objects.update(name=Concat(F('name'),Value('(新款666)')))
sql原生语句:
"""
UPDATE `app01_book` SET `name` = CONCAT_WS('', `app01_book`.`name`, '(新款666)');
"""
注意:
(1)在操作字符串数据的时候,F查询并不能做到字符串的拼接;
(2)需要借助Concat和Value,例如:name=Concat(F('name'),Value('(新款666)'));
(3)如果直接使用name=F('name')+'(新款666)',那么所有的名称将变为空白。
Q查询
"""
(1)Q查询可以组合使用“&”,“|”操作符,当一个作用符是用于两个Q对象,它将产生一个新的Q对象;
(2)Q对象可以用“~”操作符放在前面表示否定,也可允许否定与不否定形式的组合;
(3)Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
"""
(1)查询卖出大于600或者价格小于200的书籍
'|'`作用等价于`sql中的'or'
from django.db.models import Q
from app01 import models
res =models.Book.objects.filter(Q(sell_out__gt=600)|Q(price__lt=200))
print(res)
"""
<QuerySet [<Book: 书籍名:野性的呼唤(新款666),价格:168.50>, <Book: 书籍名:钢铁是怎样炼成的(新款666),价格:100.65>, <Book: 书籍名:聊斋异志(新款666),价格:1024.80>, <Book: 书籍名:青苹果乐园(新款666),价格:200.47>]>
"""
原生的sql语句:
"""
SELECT * FROM app01_book WHERE app01_book.sell_out > 600 OR app01_book.price < 200;
"""
(2)Q逗号分割,还是and关系
res = models.Book.objects.filter(Q(sell_out__gt=600),Q(price__lt=200))
"""
<QuerySet [<Book: 书籍名:野性的呼唤(新款666),价格:168.50>]>
"""
原生sql语句:
"""
SELECT * FROM app01_book WHERE app01_book.sell_out > 600 AND app01_book.price < 200;
"""
,`的作用等价于`&
(3)'~'表示'not'关系
res = models.Book.objects.filter((~Q(sell_out__gt=600))|Q(price__lt=200))
"""
<QuerySet [<Book: 书籍名:野性的呼唤(新款666),价格:168.50>, <Book: 书籍名:钢铁是怎样炼成的(新款666),价格:100.65>, <Book: 书籍名:拿破仑时代(新款666),价格:366.56>, <Book: 书籍名:总统语录--普哥实训(新款666),价格:1600.67>]>
"""
原生的sql语句:
"""
SELECT * FROM app01_book WHERE (NOT (app01_book.sell_out > 600 AND app01_book.sell_out IS NOT NULL) OR app01_book.price < 200)
"""
Q的高阶用法
# 能够将查询条件的左边也变成字符串的形式
q = Q() # 创建一个空对象Q
q.connector = 'or' # 修改查询条件关系,默认为and
q.children.append(('sell_out__gt', 600)) # 添加筛选条件,卖出大于600
q.children.append(('price__lt', 200)) # 添加筛选条件,价格小于200
res = models.Book.objects.filter(q) # filter支持传Q对象,默认还是and关系
Django中如何开启事务
# 回顾
事务的四大特性(ACID):
"""
(1)原子性(Atomicity):事务中的所有操作是不可再分割的原子单元。事务中的所有操作要么都执行成功,要么都执行失败;
(2)一致性(Consistency):事务必须使得数据库从一个一致性状态变成另外一个一致性状态;
(3)隔离性(Isolation):事务的操作是互不干扰的,多个并发事务之间是相互隔离的;
(4)持久性(Durability):指的是一个事务一旦提交了,那么对于数据库的更改是永久性的。
"""
事务的回滚操作:rollback
事务的确认:commit
Django中开启事务的两种方式
(1)方式1
from django.db import transaction
try:
with transaction.atomic():
# sql1
# sql2
...
# 在with代码快内书写的所有orm操作都是属于同一个事务
except Exception as e:
print(e)
print('执行其他操作')
(2)方式2
@transaction.atomic
def post(self,request):
...
sid=transaction.savepoint() #开启事务
...
transaction.savepoint_rollback(sid) # 回滚
...
transaction.savepoint_commit(sid) # 提交
ORM中的常用字段及参数
AutoField(primary_key=True) 主键字段
CharField(max_length=32) 字符串字段
"""
verbose_name 字段的注释
max_length 字段的长度
"""
IntegerField() int
BigIntegerField() bigint
DecimalField(max_digits=8,decimal_places=2)
EmailField() varchar(254)
DateField() date
DateTimeField() datetime
"""
auto_now=True 每次修改后会自动更新为当前的时间
auto_now_add=True 只在创建数据的时候记录创建时间,后续不会自动更改
"""
BooleanField(Field) -布尔值类型
该字段传布尔值(False/True) 对应数据库中的0和1
比如is_delete字段
TextField(Field) -文本类型
该字段可以用来存储大段的内容(文章,博客) 没有字数的限制
FileField(Field) -字符串类型
upload='/data/%Y/%m/%d/'
给该字段传递一个文件对象,会自动将文件保存到'/data/%Y/%m/%d/'文件夹下,然后将文件路径保存到数据库中
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认为# django.core.files.storage.FileSystemStorage
ImageField(FileField) -字符串类型
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认#django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
其他一些字段,参考博客:https://www.cnblogs.com/Dominic-Ji/p/9203990.html
orm与mysql字段的对应关系
"""
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
"""
Django支持自定义字段
from django.db import models
class MyCharField(models.Field):
"""
自定义char类型的字段
"""
def __init(self,max_length,*args,**kwargs):
self.max_length = max_length
super(MyCharField,self).__init__(max_length=max_length,*args,**kwargs)
def db_type(self,connection):
"""
限定生成的数据库表字段类型char,长度为max_length指定的值
:param connection:
:return:
"""
return 'char(%s)'%self.max_length
# 自定义字段的使用
myfield = MyCharField(max_length=16,null=True)
外键字段及参数
unique=True
ForeignKey(unique=True) ===> OneToOneField()
# 你在用前面字段创建一对一, orm会有一个提示信息, orm推荐你使用后者但是前者也能用
db_index
如果db_index=True 则代表着为此字段设置索引
(复习索引是什么)
to_field
设置要关联的表的字段 默认不写关联的就是另外一张的主键字段
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
"""
django2.X及以上版本 需要你自己指定外键字段的级联更新级联删除
"""
数据库查询优化(面试的重点)
orm语句的特点:
# 惰性查询:
如果你仅仅是书写了orm,后面根本没有用到该语句查询出来的参数,那么ORM会地洞识别,直接不执行。
(1)defer与only的区别
defer('name') 对象出了'name'属性,其它都有
only('name') 对象只有'name'属性,其它属性没有
example:
from app01 import models
res = models.Book.objects.only('name')
for item in res:
print(item.name)
print(item.price)
"""
野性的呼唤(新款666)
(0.003) SELECT `app01_book`.`id`, `app01_book`.`price` FROM `app01_book` WHERE `app01_book`.`id` = 2; args=(2,)
168.50
...
"""
"""
only会将括号内对应的字段对应的值,封装到返回给你的对象中,点该字段不需要走数据库;点其它字段会频繁的走数据库查询
"""
defer与only相反:
from app01 import models
res = models.Book.objects.defer('name')
for item in res:
print(item.name)
print(item.price)
"""
(0.003) SELECT `app01_book`.`id`, `app01_book`.`name` FROM `app01_book` WHERE `app01_book`.`id` = 2; args=(2,)
野性的呼唤(新款666)
168.50
...
"""
"""
defer与only相反,会将除括号内字段之外的其它字段对应的值封装到返回给你的对象中,对象点其它属性不需要走数据库,点该字段会频繁的走数据库查询。
"""
(2)select_related与prefetch_related
# res = models.Book.objects.select_related('publish')
res1 = models.Author.objects.select_related('author_detail')
# res = models.Book.objects.all()
for r in res1:
print(r.author_detail)
print(r.author_detail.phone)
print(r.author_detail.addr)
上面查询走了几次数据库?1次
(1)select_related会自动帮你做联表操作(inner join),然后将连表之后的数据全部查询出来封装给对象;
(2)select_related括号内只能放外键对象,并且多对多的不能放,因为多对多存在第三张表,他没办法通过第三个表去连表。会直接报错;
(3)如果括号内外键字段所关联的表中还有外键字段 还可以继续连表select_related(外键字段__外键字段__外键字段...)。
相当于两张表变成了一个表,然后所有的数据都存在了对象里面。一次查询就全部拿到了。
prefetch_related
res = models.Book.objects.prefetch_related('publish')
# print(res)
for r in res:
print(r.publish.name)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号