linux常用命令
系统信息
动态观察cpu、内存,进程情况:top
格式:top [选项]
选项:
-d number:每隔多少秒更新一次,默认5
-p:指定pid
交互:
P:按CPU使用率排序
M:按内存使用率排序
N:按PID排序
s: 改变刷新间隔(秒)
k:终止一个进程
r:重新设置进程优先级
c:显示命令名称和完整命令行
内容介绍:
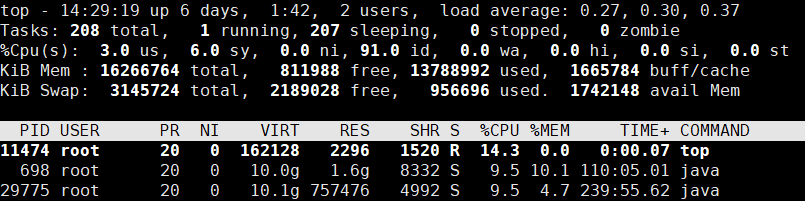
第1行:top - 时间 up 运行天数 days,运行时间(时:分),用户数 users,load average(平均负载):1秒 5秒 15秒
第2行:总进程 total,正在执行 running,休眠 sleeping,停止 stopped,僵尸 zombie
第3行:用户模式CPU占比 us,系统模式CPU占比 sy,改变过优先级的进程的CPU占比 ni,空闲CPU占比 id,因为I/O等待造成的CPU占比 wa,硬中断CPU占比 hi,软中断CPU占比 si,等待虚拟机调度的时间占比 st
第4行:物理内存总量 total,空闲 free,已使用 used,缓存内存 buff/cache(单位kb)
第5行:虚拟内存总量 total,空闲 free,已使用 used,虚拟内存 avail Mem(单位kb)
第6行:
pid:进程号;
user:归属用户;
PR:优先级(越小越高);
NI:优先值的修正数值(负值表示高优先级,正值表示低优先级);
VIRT:使用的虚拟内存;
RES:常驻内存;
SHR:使用的共享内存;
S:运行状态(S:休眠;D:不能中断睡眠;R:运行中;T:跟踪/停止;Z:僵尸;);
%CPU:CPU占用比;
%MEM:内存占用比;
TIME+:占用CPU的总时长;
COMMAND:进程名;
查看内存状态:free
格式:free [选项]
选项:-b|-k|-m|-h 以Byte|KB|MB|合适单位进行显示
内容介绍:
total:总物理内存;used:已用;free:可用;Shared:多个进程共享的内存总额;Buffers/cached:磁盘缓存的大小;available:还可以被进程使用的物理内存
查看磁盘空间:df
格式:df [选项] 文件或目录名
选项:-b|-k|-m|-h 以Byte|KB|MB|合适单位进行显示
内容介绍:
Filesystem:文件系统;Size:容量;Used:已用;Avail:可用;Use:已用占比;Mounted on:挂载点
查看目录或文件磁盘空间:du
格式:du [选项] 文件或目录名
选项:
-b|-k|-m|-h 以Byte|KB|MB|合适单位进行显示
-a:目录中所有文件和目录
-s:只显示总和
--max-depth=n:指定子目录的深度n
文本编辑(vim)
vim安装
yum -y install vim
工作模式
vim存在命令模式、输入模式、编辑模式三种工作模式。输入vim finame后默认就进入了命令模式
- 命令模式
: 进入底线命令模式
#进入输入模式
i 进入输入模式,光标在当前位置
I 进入输入模式,光标在当前行的行首
a 进入输入模式,光标在当前位置之后
A 进入输入模式,光标在当前行的行尾
o 进入输入模式,当前行下面插入一行,光标在新行行首
O 进入输入模式,当前行上面插入一行,光标在新行行首
#搜索
/abc 从光标位置向前搜索abc
/^abc 搜索以abc开头的行
/abc$ 搜索以abc结尾的行
?abc 从光标位置向后搜索abc
n 重复上次搜索指令
N 向相反方向重复上次搜索指令
:set ic 搜索忽略大小写
:set noic 搜索不忽略大小写
#删除,删除的内容在剪贴板上,按p可以粘贴
x 删除光标位置字符
dd 删除光标所在行
ndd 删除光标所在行(包含)后n行
dG 删除光标所在行(包含)后所有内容
D 删除光标位置到行尾的内容
#复制粘贴
y 复制选中文本到粘贴板
yy 复制光标所在行到粘贴板
nyy 复制光标所在行(包含)后n行到粘贴板
yw 复制光标所在位置的单词到粘贴板
p 粘贴剪贴板的内容到光标后
P(大写)粘贴剪贴板的内容到光标前
#回退
u 撤销上次指令,可连续多次撤销
Crrl+R 撤销多了...
- 输入模式
Esc 进入命令模式
- 底线命令模式
Esc 进入命令模式
w 保存不退出
w! 强制保存
q 不保存并退出
q! 不保存并强制退出
wq 保存并退出
wq! 保存并强制退出
文本处理(三剑客)
基础命令
#复制1.txt并命名为2.txt cp 1.txt 2.txt #复制/aaa/下面的所有文件以及文件夹到/bbb/ cp -r /aaa/* /bbb/ #移动1.txt并命名为2.txt mv 1.txt 2.txt #移动/aaa/下面的所有文件以及文件夹到/bbb/ mv -r /aaa/* /bbb/ #删除文件1.txt rm -f 1.txt #删除/aaa/下面的所有文件以及文件夹 rm -rf /aaa/
#查看1.txt全部内容(注意:cat会一次性输出文件全部内容,如果文件过大会导致前面的内容看不到)
cat 1.txt
#查看1.txt全部内容并显示行号
cat -n 1.txt
#查看1.txt全部内容并显示隐藏符号【回车($) Tab(^|)】
cat -A 1.txt
#将1.txt和2.txt合并输出到3.txt
cat 1.txt 2.txt>3.txt #查看1.txt中前十行内容 head -10 1.txt #查看1.txt中后十行内容 tail -10 1.txt
分页查看文件内容:more
格式:more [选项] 文件名
选项:
-f:行数以实际行数计算,不包括自动换行
-p:先清除屏幕,再显示内容
-c:先显示内容,再清除其他旧数据
-s:合并连续的空白行为一行
-u:不显示下引号
+num:从第num行显示内容
-num:一次显示num行
交互:
q:退出
:f:显示文件名和行号
回车:向下一行
空格:向下一页
.:重复上次指令
/字符串:搜索指定字符串
d:向下半页
b:向上一页
分页查看文本内容:less
已经有more了,为什么还要有less,因为more都是不断往后翻看查找,less则是随意的向前向后
格式:less [选项] 文件名
选项:
-N:显示行号
-g:只标识最后搜索的字符
-i:忽略搜索时的大小写
-m:百分比,类似more
-f:强制打开特殊文件(二进制文件,目录等)
-s:合并连续的空白行为一行
-o <文件名>:将less输出内容保存到指定文件
-x <数量>:将【Tab】键显示为指定数量的空格
交互:
q:退出
/字符串:向下搜索字符串
?字符串:向上搜索字符串
n:重复前一个搜索
N:反向重复前一个搜索
方向键【上】:向上一行
方向键【下】:向下一行
Ctrl+u:向上半页
Ctrl+d:向下半页
Ctrl+b:向上一页
Ctrl+f:向下一页
g:移动到第一行
G:移动到最后一行
文本搜索:grep
格式:grep [选项] 字符串或正则 文件名
选项:
-E:正则匹配
-o:只显示匹配到的字符串本身
-i:忽略大小写
-n:显示行号
-c:只统计行数
-w:匹配整个单词
-x:匹配整行
-R:递归
实战:
#搜索本目录下1.txt里包含error的行,忽略大小写、显示行号 grep -in 'error' 1.txt #搜索本目录下所有.txt文件里包含error的行,忽略大小写 grep -i 'error' *.txt #搜索./log目录下包含error的文件,递归、忽略大小写、显示行号 grep -Rin 'error' ./log/*
逐行输出文本:awk
格式:awk [选项] ‘脚本命令’ 文件名
选项:
-F '切割符':指定分割符,默认是用任意的空白字符切割,如空格、制表符
脚本命令:
-
- 需用单引号包裹
- 分为两部分,匹配规则和执行命令,格式:'匹配规则{执行命令}'
- 匹配规则:
- 可以是字符串 /aaa/,表示包含aaa的行
- 可以是正则表达式
- 可以是NR,NR是当前行行号,从1开始,例如NR==3会匹配第3行;NR%5==0会匹配5的整倍数行5,10,15,20...
- 可以是NF,NF是当前行切割后的总字段数,例如NF>3表示匹配切割后大于3个字段的行
- 为空会默认匹配所有行
- 执行命令:
- 需要用{}包裹
- 通常写print $n;$0表示输出整行;$1代表切割后的第1个字段;$2代表切割后的第2个字段...
- 也可写print "str",表示匹配到几行就会输出几个str
- 为空时不需要写{},会把整行输出
实战:
#按行输出文本 awk '{print}' 1.txt #输出1,3行 awk 'NR==1||NR==3{print}' 1.txt #输出以root开头的行 awk '/^root/{print}' 1.txt #按|分割,输出每行第1,3个字段 awk -F "|" '{print $1,$3}' 1.txt
#输出10的整倍数行
awk 'NR%10==0' 1.txt
流编辑:sed
格式:sed [选项] [脚本命令] 文件名
选项:
-n:sed默认执行完成后输出结果,此选项会屏蔽输出
-e 脚本:添加脚本到程序的运行列表
-f 脚本文件:添加脚本文件到程序的运行列表
-i:直接修改源文件
脚本命令:
首先介绍下方address部分,sed默认会作用于整个文本,而address就是为了限制作用于具体的行,写法有两种:
1:数字形式:行号从1开始。5代表第5行;6,10代表6到10行;10,$代表10到末尾行
2:文本模式:用//包裹。/aaa/代表包含aaa的行;也可以使用正则表达式匹配
-
- sed p:打印
格式:[address]p
与-n一起使用,可以只打印匹配到的行
-
- sed s:替换字符串
格式:[address]s/old/new/flags
address表示要操作的行,old是要替换的内容,new是替换后的内容
flags分为多重情况:
n:1-512之间的数,表示替换第几次出现的字符串,people替换成peocle,就需要写2
g:替换所有,如果不写g,那么只会替换第一次匹配成功的字符串
p:打印已处理的行,通常于-n一起使用,一起使用的效果是只输出被替换命令修改过的行
w file:将匹配结果写入到指定文件
&:用正则匹配替换
\n:匹配第n个子串,在old中定义,格式为\(..\)
-
- sed c:替换整行
格式:[address]c\new
new为新字符串
-
- sed y:替换单个字符
格式:[address]y/123/abc/
与s整个字符串替换不同,y是按照单个字符替换的,123和abc的关系是,1替换成a,2替换成b,3替换成c,例如2023会替换成a0ac,所以123和abc的长度也需要一样
-
- sed d:删除行
格式:[address]d
会将匹配到的行整行删除
-
- sed a:在后面附加一行
格式:[address]a\newLine
-
- sed i:在前面插入一行
格式:[address]i\newLine
-
- sed w:将指定行写入到文件
格式:[address]w filename
-
- sed r:将文件内容插入到指定行的后面
格式:[address]r filename
-
- sed q:匹配一次后退出
格式:[address]q
实战
#查看1.txt的6到10行内容(-n表示不打印内容;p表示打印匹配到的行;两者相互不影响。如果只加-n不加p会输出全部内容;如果只加p不加-n会输出全部,其中6到10行输出两遍) sed -n '6,10 p' 1.txt
#查看1.txt中包含abc的行
sed -n '/abc/ p' 1.txt
#替换1.txt中第2个old为new(替换前:111old222old;替换后:111old222new)
sed 's/old/new/2'
#替换1.txt中全部的old为new(替换前:111old222old;替换后111new222new)
sed 's/old/new/g' 1.txt
#打印1.txt中替换的结果(上面两个替换会将1.txt内容全部输出,加上-n和p后只输出替换的行)
sed -n 's/old/new/2 p' 1.txt
#将1.txt中替换后的行写入到log.txt中(会且只会将替换后的行写入到log.txt。全部内容依旧在屏幕输出,也还是用-n控制不输出,不会写入到log.txt中)
sed 's/old/new/2 w log.txt' 1.txt
#将1.txt中每个单词加上【】
sed 's/\w\+/【&】/g' 1.txt
#将1.txt中的ip用【】括起来(替换前:ip:127.0.0.1 name:zhangsan ip:192.168.1.1 name:lisi 替换后:ip:【127.0.0.1】 name:zhangsan ip:【192.168.1.1】 name:lisi)
#s是替换;\([a-z]\+\)是\(..\)格式的子串;按照\(..\)出现顺序是第一个所以可以用\1表示;g表示全部替换
sed 's/ip:\([0-9.]\+\)/ip:【\1】/g' 1.txt
#将1.txt中ip用【】括起来,name用<>括起来(替换后:ip:【127.0.0.1】 name:<zhangsan> ip:【192.168.1.1】 name:<lisi>)
#上一条基础上加上了name,多了个\(..\)格式子串,顺序是第2个,所以用\2表示
sed 's/ip:\([0-9.]\+\) name:\([a-z]\+\)/ip:【\1】 name:<\2>/g' 1.txt
#将1.txt中第3行替换成new
sed '3c\new' 1.txt
#将1.txt中第2行到第4行替换成new(是2,3,4行换成了一行new,要是想换成三行new就加\n换行sed '2,4c\new\nnew\nnew' 1.txt)
sed '2,4c\new' 1.txt
#将1.txt中所有包含old的行换成new(每一个包含old行都会换成一行new)
sed '/old/c\new' 1.txt
#将1.txt中的1换成a,2换成b,3换成c(替换前:111222333123;替换后:aaabbbcccabc)
sed 'y/123/abc' 1.txt
#将1.txt中包含old的行删除
sed '/old/d' 1.txt
#在1.txt中,插入一行new line到第3行后
sed '3a\new line' 1.txt
#在1.txt中,每个包含error的行前插入一行this is head
sed '/error/i\this is head' 1.txt
#将1.txt中第5行到最后一行的内容写入到2.txt中
sed '5,$ w 2.txt' 1.txt
#将2.txt的全部内容插入到1.txt第5行后
sed '5r 2.txt' 1.txt
#查找1.txt中abc第一次出现的位置
sed '/abc/q' 1.txt
#修改源文件,将1.txt中abc替换成123
sed -i 's/abc/123/g' 1.txt
#备份修改源文件,将1.txt中123替换成abc(同目录下会出现一个1.txt.bak文件,内容是修改前的内容)
sed -i.bak 's/123/abc/g' 1.txt
搭配:grep+awk
实战1:统计链接到服务器的ip
#查看ip链接情况 netstat -ntu #输出其中的ip和端口号 netstat -ntu | awk '{print $5}' #去除端口号,只剩ip地址 netstat -ntu | awk '{print $5}' | awk -F ":" '{print $1}' #将上面的ip进行排序 netstat -ntu | awk '{print $5}' | awk -F ":" '{print $1}' | sort #将相邻行重复的ip进行合并,并将数量显示到前面 netstat -ntu | awk '{print $5}' | awk -F ":" '{print $1}' | sort | uniq -c #再次排序sort -t分隔符,-n数值从小到大,-r逆序,-k按照第几列排序 netstat -ntu | awk '{print $5}' | awk -F ":" '{print $1}' | sort | uniq -c | sort -t ' ' -nrk 1 #只统计80端口的ip netstat -ntu | grep -E ':80 ' | awk '{print $5}' | awk -F ":" '{print $1}' | sort | uniq -c | sort -t ' ' -nrk 1
实战2:统计日志文件访问最频繁的前十个ip
日志内容:
ip:192.168.1.1 user:张三 action:add
ip:192.168.1.6 user:李四 action:up
...
ip:192.168.1.9 user:王五 action:select
#查找1.txt中(ip:******)格式的字符串 grep -o -E "ip:[0-9.]+" 1.txt #用:切割,输出第二部分也就是纯ip grep -o -E "ip:[0-9.]+" 1.txt | awk -F ":" '{print $2}' #将上面的ip进行排序 grep -o -E "ip:[0-9.]+" 1.txt | awk -F ":" '{print $2}' | sort #将相邻行重复的ip进行合并,并将数量显示到前面 grep -o -E "ip:[0-9.]+" 1.txt | awk -F ":" '{print $2}' | sort | uniq -c #再次排序sort -t分割符,-n数值从小到大,-r逆序,-k按照第几列排序 grep -o -E "ip:[0-9.]+" 1.txt | awk -F ":" '{print $2}' | sort | uniq -c | sort -t ' ' -nrk 1 #取出前十个 grep -o -E "ip:[0-9.]+" 1.txt | awk -F ":" '{print $2}' | sort | uniq -c | sort -t ' ' -nrk 1 | head -10
搭配:sed+grep
实战:批量更改文件夹下内容(old改为new)
#递归查找包含old的文件 grep -r 'old' ./* #只列出文件 grep -rl 'old' ./* #查看替换结果(grep用``包起来) sed 's/old/new/g' `grep -rl 'old' ./*` #实际替换(可以用-i.bak设置备份源文件) sed -i 's/old/new/g' `grep -rl 'old' ./*`
用户&用户组
#新增用户zw,不能登陆,还需设置密码 useradd zw #为用户zw设置密码,回车输入两次密码,完成后可以登陆 passwd zw #锁定zw用户,锁定后不能登陆 passwd -l zw #解锁zw用户 passwd -u zw #修改用户zw名称为newzw usermod -l newzw zw #删除newzw用户 userdel -r newzw #新增用户组tech groupadd tech #修改用户组tech为newtech groupmod -n newtech tech #删除用户组newtech groupdel newtech #将zw用户加入到tech用户组 gpasswd -a zw tech #将zw用户移出tech用户组 gpasswd -d zw tech
权限
使用 ll 命令可以查看本目录下文件权限
[root@localhost test]# ll total 12 -rw-r--r--. 1 zw tech 5 Aug 16 14:21 1.txt -rw-r--r--. 1 root root 5 Aug 16 14:22 2.txt
drwxr-xr-x. 2 root root 6 Aug 18 14:39 a
第一列表示用户权限,共11位,第1位表示类型,第2,4表示所有者权限,第5,7表示所属组权限,第8,10表示其他人权限,第11表示此文件受 SELinux 的安全规则管理
第二列表示所有者,第三列表示所属组
文件/目录的所有者/所属组
#修改文件/目录的所属组 chgrp 所属组 文件名/目录名 #修改目录以及子目录所有文件的所属组 chgrp -R 所属组 目录名 #修改文件/目录的所有者 chown 所有者 文件名/目录名 #修改目录以及子目录所有文件的所有者 chown -R 所有者 目录名 #同时修改文件/目录的所有者和所属组 chown 所有者:所属组 文件名/目录名 #同时修改目录以及子目录所有文件的所有者和所属组 chown -R 所有者:所属组 目录名
文件/目录的权限
介绍:
读:字符表示为r、数字表示为4
写:字符表示为w、数字表示为2
执行:字符表示为x、数字表示为1
#数字方式修改权限 #共3位数字,每个数字为1,2,4的组合相加,列如7就是读&写&执行,6就是读&写,4就是读 #第一个数字代表所有者,第二个代表所属组,第三个代表其他人 #递归修改加上-R
#所有者:读&写&执行;所属组:读&写;其他人:读 chmod 764 文件名/目录名 #字母方式修改权限 #u:所有者;g:所属组;o:其他;a:全部 #+:加入;-:删除;=:设定 #递归修改加上-R #所有者加上读&写权限 chmod u+rw 文件名/目录名 #所属组删除写权限 chmod g-w 文件名/目录名 #所有人都可以读&写,不能执行,且修改子目录和所有文件 chmod -R a=rw 目录名
防火墙
状态:systemctl status firewalld 开启:systemctl start firewalld 关闭:systemctl stop firewalld 重启:systemctl restart firewalld 开机启动:systemctl enable firewalld 开机禁用:systemctl disable firewalld #查看已开启端口列表 firewall-cmd --zone=public --list-ports #开启80端口 firewall-cmd --zone=public --add-port=80/tcp --permanent #关闭80端口 firewall-cmd --zone=public --remove-port=80/tcp --permanent
#禁止某个ip(192.168.1.1)访问
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.1" reject' #开放某个IP(192.168.1.1)访问某个(6379)端口 #IP写192.168.1.0/24代表这个ip段 #端口写100-200代表100,101...,199,200这些端口都开放 firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.1" port protocol="tcp" port="6379" accept' #限制某个IP(192.168.1.1)访问某个(80)端口 firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.1" port protocol="tcp" port="80" reject' #删除已设置的访问规则 firewall-cmd --permanent --remove-rich-rule='rule family="ipv4" source address="192.168.1.1" port protocol="tcp" port="6379" accept' #查看已有的访问规则 firewall-cmd --zone=public --list-rich-rules #配置后记得重启防火墙 firewall-cmd --reload

 浙公网安备 33010602011771号
浙公网安备 33010602011771号