
HDFS v1.0学习笔记
hdfs是一个用于存储大文件的分布式文件系统,是apache下的一个开源项目,使用java实现。它的设计目标是可以运行在廉价的设备上,运行在大多数的系统平台上,高可用,高容错,易于扩展。
适合场景
- 存储大文件:G级别或者以上
- 离线数据分析
- 非结构化数据
- 一次写多次读
不适合的场景
- 存储小文件
- 文件需要修改(hdfs只能追加,如果需要修改,删除后,再重新上传)
- 低延迟服务
- 多用户写
- 大量随机读
整体架构
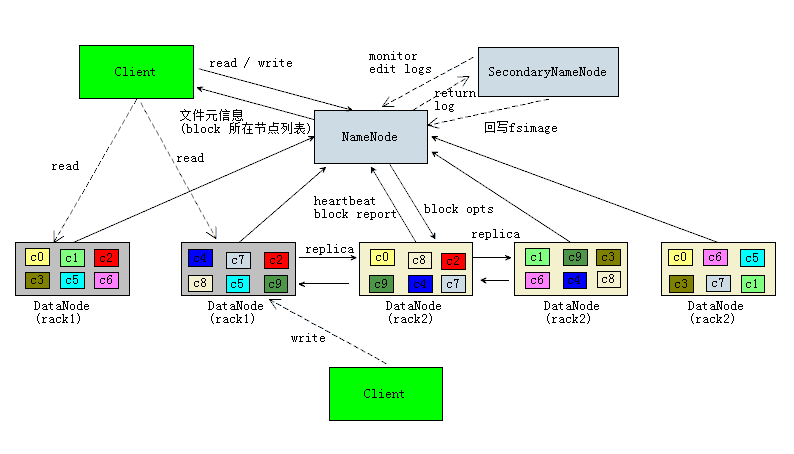
各组件含义以及关系
| 组件 | 含义 | 备注 |
|---|---|---|
| NameNode | 名字节点,Master节点,仲裁者 | 管理和存储命名空间元数据信息,维护文件路径和block的映射,维护block和DataNode节点的映射,根据制定的策略和集群DataNode节点情况确定block数据真实存储的数据节点列表,维护和监控已存在的block列表,根据实际情况指示数据节点增删block,负责客户端文件元数据的请求响应 |
| SecondaryNameNode | 辅助名字节点的节点 | 负责维护NameNode元数据的镜像文件fsimage,周期性的合并NameNode产生的事物日志(edit log)到自己的fsimage,并且回写到NameNode节点,保证NameNode节点的镜像文件不会非常过时 |
| DataNode | 数据节点 | 按块存储真实的文件数据,周期性的发送心跳包到NameNode,告知相关状态信息(heartbeat)以及上报块列表信息(安全模式下),负责客户端数据的读取和写入,负责处理NameNode发出的指令,负责数据节点间块数据的同步 |
| Client | 客户端 | 负责发起读写请求,负责数据完整性效验,写数据时,负责根据相关配置切割数据,然后分块上传到指定的节点,提供的客户端类型有:shell,java api,c api, web ui,http接口 |
副本存储策略
采用机架感知策略,兼顾性能和容灾的平衡。通过dfs.replication配置block副本数,一般设置3个。如果是三个副本具体怎么确定单个数据块的存储位置呢?采用如下方式:以客户端所在的数据节点为第一个副本的节点(如果客户端在集群外,则随机选择一个数据节点),从另外一个机架随机选择一个节点作为第二个副本的存储节点,从第二个节点所在的机架随机选择一个数据节点存储第三个副本。
读数据流程
- dfs客户端向NameNode发起读文件请求,检查是否有权限,如果有访问权限,返回文件block所在节点列表(根据近地原则返回)
- 根据返回的数据节点列表,并发发起获取文件数据请求,对返回数据按切割的块进行完整性效验,最后合并数据成一个文件,保存到本地
写数据流程
- dfs客户端向NameNode发起写文件请求,检查是否有写权限,如果有权限,NameNode根据制定的策略和数据节点的状态情况确定block存储的数据节点列表,然后返回给客户端
- dfs客户端对本地文件按块规则进行切分,每一个数据块上传到指定的数据节点。对数据块进一步切割成更小的块,带上完整性效验码,一块接着一块上传到数据节点。
- 数据节点之间互相拷贝数据,一个小块接着一个小块数据在节点之间传输,收到小块数据后,进行完整性效验,节点之间类似管道一样传输数据
- 当数据传输完成,dfs客户端告知NameNode完成,NameNode落地这次修改的事物日志(通过NameNode上报),同时更新内存中元数据信息
数据完整性
- 读写文件效验码(crc32)验证
- DataNode启动一个DataBlockScanner线程周期性扫描block是否损坏
启动流程
通过脚本启动集群中所有的节点,整个集群进入安全模式(safe mode),安全模式下只能读不能写。NameNode读取元数据镜像文件(fsimage)以及合并为合并过的事物日志文件(edit log),然后产生一个最新的fsimage文件并覆盖到本地硬盘,并且清空事物日志文件。NameNode启动完成后,等待DataNode上报块列表信息。综合上报的信息,检查集群是否健康,上报的可用块列表信息中是否达到了最小健康标准百分比(通过一个配置设置,默认是90%),如果未达到,会一直处在安全模式。如果有块数据丢失,从新指示某机器复制副本,以达到副本数的要求。如果配置副本数有更改,则根据要求自动增删副本。当判断集群处于健康状态时,等待30秒左右,集群退出安全模式,进入可服务状态。
分布式文件系统以及权限
- 类似于linux文件系统,也是一个树状结构
- 类似于linux文件系统,只有读写权限
- 启动服务的用户默认属于集群超级用户组,拥有所有的权限
- 上传和创建目录时,文件用户归属和组归属是当前用户和当前用户所在的组
- 删除有回收站模式,防止文件会被误删,删除时会移动到集群/trash目录,超过有效期,会定时删除,此功能默认是关闭的,需要通过配置打开
客户端 - WEB UI
只能查看
默认地址是:http://master:50070
客户端 - Shell
通过 hadoop fs 命令 参数 方式启动
显示帮助信息
[wadeyu@master ~]$ hadoop fs -help
hadoop fs is the command to execute fs commands. The full syntax is:
hadoop fs [-fs <local | file system URI>] [-conf <configuration file>]
[-D <property=value>] [-ls <path>] [-lsr <path>] [-du <path>]
[-dus <path>] [-mv <src> <dst>] [-cp <src> <dst>] [-rm [-skipTrash] <src>]
[-rmr [-skipTrash] <src>] [-put <localsrc> ... <dst>] [-copyFromLocal <localsrc> ... <dst>]
[-moveFromLocal <localsrc> ... <dst>] [-get [-ignoreCrc] [-crc] <src> <localdst>
[-getmerge <src> <localdst> [addnl]] [-cat <src>]
[-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>] [-moveToLocal <src> <localdst>]
[-mkdir <path>] [-report] [-setrep [-R] [-w] <rep> <path/file>]
[-touchz <path>] [-test -[ezd] <path>] [-stat [format] <path>]
[-tail [-f] <path>] [-text <path>]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-chgrp [-R] GROUP PATH...]
[-count[-q] <path>]
[-help [cmd]]
列出/目录下所有的文件
[wadeyu@master ~]$ hadoop fs -ls /
Found 22 items
-rw-r--r-- 2 root supergroup 632207 2018-09-03 18:16 /The_Man_of_Property.txt
-rw-r--r-- 2 root supergroup 495 2018-09-04 10:54 /a.txt
-rw-r--r-- 2 root supergroup 404 2018-09-04 10:54 /b.txt
-rw-r--r-- 2 root supergroup 2541 2018-09-04 12:48 /cookie_ip.txt
-rw-r--r-- 2 root supergroup 12224421 2018-09-04 12:48 /ip.lib.txt
drwxr-xr-x - root supergroup 0 2018-09-03 12:59 /output
drwxr-xr-x - root supergroup 0 2018-09-03 19:29 /output_cachearchive_result
drwxr-xr-x - root supergroup 0 2018-09-03 18:47 /output_cachefile_result
drwxr-xr-x - root supergroup 0 2018-09-04 09:36 /output_compresss_result
drwxr-xr-x - root supergroup 0 2018-09-04 09:44 /output_decompress_cat
drwxr-xr-x - root supergroup 0 2018-09-04 10:03 /output_decompress_cat2
drwxr-xr-x - root supergroup 0 2018-09-03 18:48 /output_file_result
drwxr-xr-x - root supergroup 0 2018-09-04 12:49 /output_ip_lib
drwxr-xr-x - root supergroup 0 2018-09-04 11:41 /output_sort_multi_reduce
drwxr-xr-x - root supergroup 0 2018-09-04 10:55 /output_sort_one_reduce
-rw-r--r-- 3 root supergroup 847 2018-09-01 11:44 /passwd
drwxr-xr-x - root supergroup 0 2018-09-04 09:13 /test
-rw-r--r-- 3 root supergroup 0 2018-09-01 20:03 /test.txt
drwxr-xr-x - root supergroup 0 2018-09-04 09:12 /usr
-rw-r--r-- 2 root supergroup 165 2018-09-03 19:11 /w.tar.gz
drwxr-xr-x - wadeyu wadeyu 0 2018-09-04 21:03 /wadeyu
-rw-r--r-- 2 root supergroup 24 2018-09-03 18:36 /white_list
显示/a.txt文件内容
[wadeyu@master ~]$ hadoop fs -cat /a.txt | head -1
1 hadoop
# 如果是压缩文件,会解压后再输出
[wadeyu@master ~]$ hadoop fs -text /a.txt | head -1
1 hadoop
删除/test.txt文件
[root@master wadeyu]# hadoop fs -rmr -skipTrash /test.txt
Deleted hdfs://192.168.1.15:9000/test.txt
参考资料
【0】八斗学院内部hdfs学习资料
【1】HDFS Architecture Guide
http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
出处:http://www.cnblogs.com/wadeyu/
本文版权归本人和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号