锁的算法,隔离级别的问题
锁的算法
InnoDB存储引擎有3中行锁的算法设计,分别是:
- Record Lock:单个行记录上的锁。
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身。
- Next-Key Lock:Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身。
Record Lock总是会去锁住索引记录。如果InnoDB存储引擎表建立的时候没有设置任何一个索引,这时InnoDB存储引擎会使用隐式的主键来进行锁定。
Next-Key Lock是结合了Gap Lock和Record Lock的一种锁定算法,在Next-Key Lock算法下,InnoDB对于行的查询都是采用这种锁定算法。对于不同SQL查询语句,可能设置共享的(Share)Next-Key Lock和排他的(exlusive)Next-Key Lock。
可以通过一个例子来演示Next-Key Lock的锁定算法,建立一张表t,插入值为1、2、3、4、7、8的6条记录。
create table t(a int,primary key(a))ENGINE=InnoDB;
begin;
insert into t select 1;
insert into t select 2;
insert into t select 3;
insert into t select 4;
insert into t select 7;
insert into t select 8;
commit;
select * from t;
接着开启两个会话,会话A在一个事务中执行select * from t where a<6 lock in share mode,会话B中,插入小于6或者等于6的记录,如下所示:

在这种情况下,不论插入的记录是5还是6,都会被锁定。因为在Next-Key Lock算法下,锁定的是(-∞,6)这个数值区间的所有数值。但是插入9这个数值是可以的,因为该记录不在锁定的范围内,而对于单个值的索引查询,不需要用到Gap Lock,只要加一个Record Lock即可,因此InnoDB存储引擎会自己选一个最小的算法模型。同样,对于上面的表t,进行如下操作:

这时插入记录5或6都是可行的了。需要注意的是,上面演示的两个例子都是在InnoDB的默认配置下,即事务的隔离级别为REPEATABLE READ的模式下。因为在REPEATABLE READ模式下,Next-Key Lock算法是默认的行记录锁定算法。
隔离级别的问题
通过锁可以实现事务的隔离性的要求,使得事务可以并发地工作。锁提高了并发,但是却会带来问题。不过,好在因为事务隔离性的要求,锁只会带来3种问题。如果可以防止这3种情况的发生,那将不会产生并发异常。
丢失更新
丢失更新(lost update)是一个经典的数据库问题。实际上,所有多用户计算机系统环境下有可能产生这个问题。简单说来,出现下面的情况时,就会发生丢失更新:
(1)事务T1查询一行数据,放入本地内存,并显示给一个终端用户User1。
(2)事务T2也查询该行数据,并将取得的数据显示给终端用户User2。
(3)User1修改这行记录,更新数据库并提交。
(4)User2修改这行记录,更新数据库并提交。
显然,这个过程中用户User1的修改更新操作“丢失”了。这可能会发生一个恐怖的结果。设想银行丢失了更新操作:一个用户账户中有10 000元人民币,他用两个网上银行的客户端转账,第一次转9 000人民币,因为网络和数据的关系,这时需要等待。但是如果这时用户可以操作另一个网上银行客户端,转账1元。如果最终两笔操作都成功了,用户的账号余款是9 999人民币,第一转的9 000人民币并没有得到更新。也许有人会说,不对,我的网银是绑定USB Key的,不会发生这种情况——通过USB Key登录也许可以解决这个问题,但是更重要的是,要在数据库层解决这个问题,以避免任何可能发生丢失更新的情况。
要避免丢失更新发生,其实需要让这种情况下的事务变成串行操作,而不是并发的操作。即在上述四种的第(1)种情况下,对用户读取的记录加上一个排他锁,同样,发生第(2)种情况下的操作时,用户也需要加一个排他锁。这种情况下,第(2)步就必须等待第(1)、(3)步完成,最后完成第(4)步,如以下所示:

我发现,程序员可能在了解如何使用SELECT、INSERT、UPDATE、DELETE语句后就开始编写应用程序。因此,丢失更新是程序员最容易犯的错误,也是最不易发现的一个错误,特别是由于这种现象只是随机的、零星的出现,但其可能造成的后果却十分严重。
脏读
理解脏读之前,需要理解脏数据的概念。脏数据和脏页有所不同。脏页指的是在缓冲池中已经被修改的页,但是还没有刷新到磁盘,即数据库实例内存中的页和磁盘的页中的数据是不一致的,当然在刷新到磁盘之前,日志都已经被写入了重做日志文件中。而所谓脏数据,是指在缓冲池中被修改的数据,并且还没有被提交(commit)。
对于脏页的读取,是非常正常的。脏页是因为数据库实例内存和磁盘的异步同步造成的,这并不影响数据的一致性。并且因为是异步的,因此可以带来性能的提高。而脏数据却不同,脏数据是指未提交的数据。如果读到了脏数据,即一个事务可以读到另外一个事务中未提交的数据,则显然违反了数据库的隔离性。
脏读指的就是在不同的事务下,可以读到另外事务未提交的数据,简单来说,就是可以读到脏数据。比如下面的例子所示:
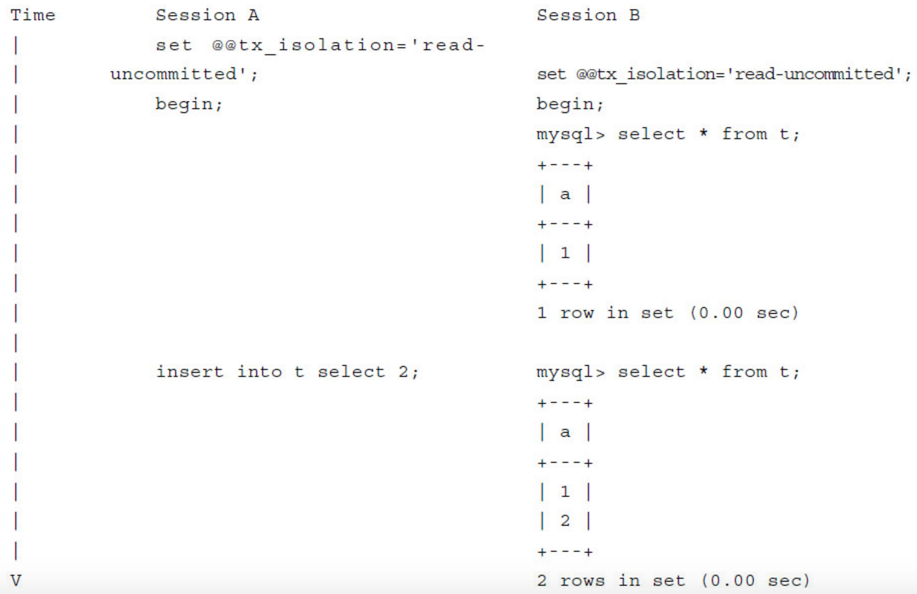
事务的隔离级别进行了更换,由默认的REPEATABLE READ换成了READ UNCOMMITTED,因此在会话A中事务并没有提交的前提下,会话B中两次SELECT操作取得了不同的结果,并且这两个记录是在会话A中并未提交的数据,即产生了脏读,违反了事务的隔离性。
脏读现象在生产环境中并不常发生。从上面的例子中就可以发现,脏读发生的条件是需要事务的隔离级别为READ UNCOMMITTED,而目前绝大部分的数据库都至少设置成READ COMMITTED。InnoDB存储引擎默认的事务隔离级别为READ REPEATABLE,Microsoft SQL Server数据库为READ COMMITTED,Oracle数据库同样也是READ COMMITTED。
不可重复读
不可重复读是指在一个事务内多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务的两次读数据之间,由于第二个事务的修改,第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读。
不可重复读和脏读的区别是:脏读是读到未提交的数据;而不可重复读读到的确实是已经提交的数据,但是其违反了数据库事务一致性的要求。
可以通过下面一个例子来观察不可重复读的情况:

会话A中开始一个事务,第一次读取到的记录是1;另一个会话B中开始了另一个事务,插入一条2的记录。在没有提交之前,会话A中的事务再次读取时,读到的记录还是1,没有发生脏读的现象。但会话2中的事务提交后,在对会话A中的事务进行读取时,这时读到的是1和2两条记录。这个例子的前提是,在事务开始前,会话A和会话B的事务隔离级别都调整为了READ COMMITTED。
一般来说,不可重复读的问题是可以接受的,因为其读到的是已经提交的数据,本身并不会带来很大的问题。因此,很多数据库厂商(如Oracle、Microsoft SQL Server)将其数据库事务的默认隔离级别设置为READ COMMITTED,在这种隔离级别下允许不可重复读的现象。
InnoDB存储引擎中,通过使用Next-Key Lock算法来避免不可重复读的问题。在MySQL官方文档中,将不可重复读定义为Phantom Problem,即幻象问题。在Next-Key Lock算法下,对于索引的扫描,不仅仅是锁住扫描到的索引,而且还锁住这些索引覆盖的范围(gap)。因此对于这个范围内的插入都是不允许的。这样就避免了另外的事务在这个范围内插入数据导致的不可重复读的问题。因此,InnoDB存储引擎的默认事务隔离级别是READ REPEATABLE,采用Next-Key Lock算法,就避免了不可重复读的现象。

