

查出用户UID最大值的用户名、UID及shell类型
1) 查出用户UID (/etc/passwd)
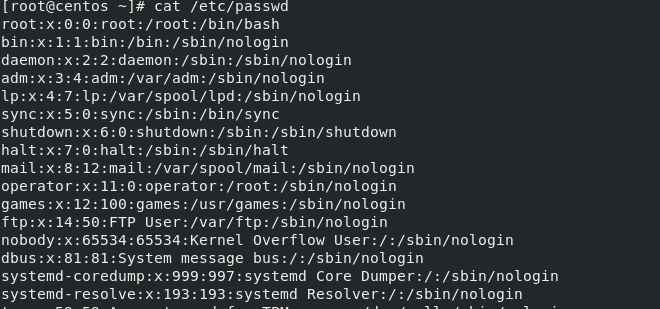
2)查出用户UID的用户名、UID及shell类型
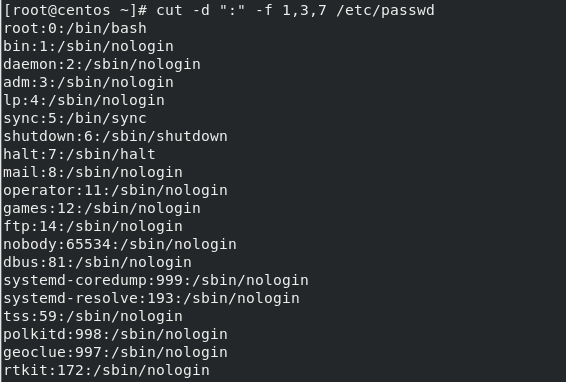
3)查出用户UID的用户名、UID及shell类型并倒序排出
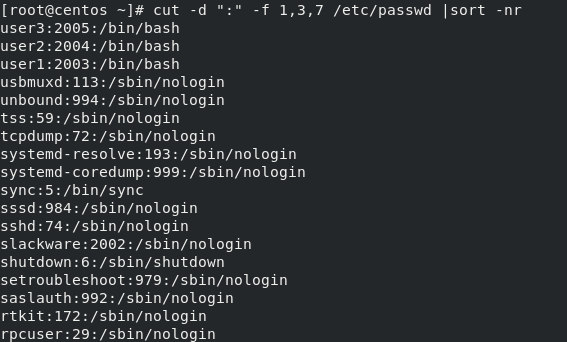
4)查出用户UID最大值的用户名、UID及shell类型
cut -d ":" -f 1,3,7 /etc/passwd | sort -nr | head -n1

语法: sort [option] [file(s) ]
用途:将输入行按照键值字段与数据类型选项以及locale 排序
主要选项:
-b 忽略开头的空白
-c 检查输入是否已正确排序,如输入未经排序,但退出码(exit code)为非零值,则不会有任何输出
-d 字典顺序:仅文字数字与空白才有意义
-g 一般数值:以浮点数字类型比较字段。这个选项的运作有点类似 -n.差别仅在于这个选项的数字可能有小数点及指数。(仅GNU版本提供此功能)
-f 以不管字母大小写的方式排序
-i 忽略无法打印的字符
-k 定义排序键值字段(该选项后接一个字段编号,或则是一对数字。有时-k之后可用空白分隔。每个编号后都可以接一个点号的字符位置,及/ 或 修饰符(modifier)字母之一
.且当出现多个-k选项时候,会先从第一个键值开始排序,找出匹配该键值的记录后,再进行第二个键值字段的排序,以此类推。)
-m 将以排除的输入文件,合并为一个排序后的输出数据流。
-n 以整数类型比较字段
-o outfile 将输入写到指定文件,而非标准输出。如果该文件为输入文件之一,则sort 在进行配需与写到输入文件之前,会先将它复制到一个临时文件
-r 倒置排序的顺序为 由大至小(descending),而非默认的由小至大(ascending)
-t char 使用单个字符char作为默认的字段分割字符,取代默认的空白字符。
-u 只有唯一的记录,丢弃所有具有相同键值的记录,只留其中的第一条。只有键值字段是重要的,也就是说:被丢弃的记录其他部分可能是不同值。
paste的格式为:
paste <-d> <-s> file1 file2
选项的含义如下:
-d: 制定不同于空格或tab键的域分隔符。比如使用@分隔符,就可以-d@
-s: 将每个文件合并成行,而不是按行合并。(即每个文件中的内容占一行。)

