强化学习笔记1
强化学习(1)
作者:hschen
写于:16-4-13
强化学习简介
监督学习在机器学习中取得了重大的成功,然而在顺序决策制定和控制问题中,比如无人直升机、无人汽车等,难以给出显式的监督信息,因此这类问题中监督模型无法学习。
强化学习就是为了解决这类问题而产生的。在强化学习框架中,学习算法被称为一个agent,假设这个agent处于一个环境中,两者之间存在交互。agent通过与环境交互不断增强对环境的适应力,故得名强化学习。
这个过程可以用下图来理解:
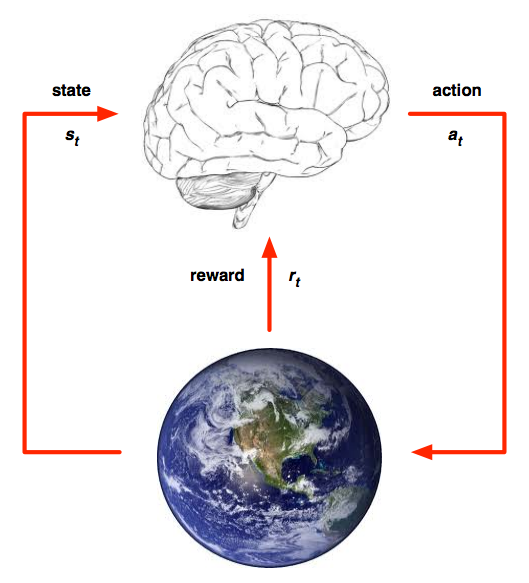
在每个时间步\(t\),agent:
- 接受状态\(s_t\)
- 接受标量回报\(r_t\)
- 执行行动\(a_t\)
环境:
- 接受动作\(a_t\)
- 产生状态\(s_t\)
- 产生标量回报\(r_t\)
MDP
通常我们都是从MDP(马尔科夫决策过程)来了解强化学习的。MDP问题中,我们有一个五元组:\((S,A,P,\gamma,R)\)
- \(S\):状态集,由agent所有可能的状态组成
- \(A\):动作集,由agent所有可能的行动构成
- \(P(s,a,s')\):转移概率分布,表示状态\(s\)下执行动作\(a\)后下个时刻状态的概率分布
- \(\gamma\):折扣因子,\(0\leq \gamma\leq 1\),表示未来回报相对于当前回报的重要程度。如果\(\gamma=0\),表示只重视当前立即回报;\(\gamma=1\)表示将未来回报视为与当前回报同等重要。
- \(R(s,a,s')\):标量立即回报函数。执行动作\(a\),导致状态\(s\)转移到\(s'\)产生的回报。可以是关于状态-动作的函数\(S\times A\to \mathbb{R}\),也可以是只关于状态的函数\(S\to \mathbb{R}\)。记\(t\)时刻的回报为\(r_t\),为了后续表述方便,假设我们感兴趣的问题中回报函数只取决于状态,而状态-动作函数可以很容易地推广,这里暂不涉及。
注:这里阐述的MDP称为discounted MDP,即带折扣因子的MDP。有些MDP也可以定义为四元组:\((S,A,P,R)\),这是因为这类MDP中使用的值函数不考虑折扣因子。
MDP过程具有马尔科夫性质,即给定当前状态,未来的状态与过去的状态无关。但与马尔科夫链不同的是,MDP还考虑了动作,也就是说MDP中状态的转移不仅和状态有关,还依赖于agent采取的动作。举个下棋的例子来说,我们在局面(状态\(s_{t-1}\))走了一步(动作\(a_{t-1}\)),导致棋盘状态变为\(s_{t}\),这时对手只需要根据当前棋盘状态\(s_t\)思考,作出应对\(a_t\),导致局面变为\(s_{t+1}\),而不需要考虑再之前的棋盘状态\(s_{t-i},(i=1,2,...)\)。由于对手会采取什么行动我们无法预测,因此\(s_{t+1}\)是随机的,依赖于当前的局面\(s_t\)和对手的落子行动\(a_t\)。
我们可以通过下面表格了解各种马尔科夫模型的区别:
|_|不考虑动作|考虑动作|
|:|:|:|
|状态可观测|马尔科夫链(MC)|马尔科夫决策过程(MDP)|
|状态不完全可观测|隐马尔科夫模型(HMM)|不完全可观察马尔可夫决策过程(POMDP)|
MDP的运行过程:
我们从初始状态\(s_0\)出发,执行某个动作\(a_0\),根据转移概率分布确定下一个状态\(s_1\sim P_{s_{0}a_{0}}\),接着执行动作\(a_1\),再根据\(P_{s_{1}a_{1}}\)确定\(s_2\)...。
一个discounted MDP中,我们的目标最大化一个累积未来折扣回报:
具体地,我们希望学得一个策略(policy),通过执行这个策略使上式最大化。策略一般可以表示为一个函数,它以状态为输入,输出对应的动作。策略函数可以是确定的\(\pi(s)=a\),也可以是不确定的\(\pi(s,a)=p(a|s)\)(这时策略函数是一个条件概率分布,表示给定状态\(s\)下执行下一个动作\(a\)的概率)。当agent执行一个策略时,每个状态下agent都执行策略指定的动作。
强化学习通常具有延迟回报的特点,以下围棋为例,只有在最终决定胜负的那个时刻才有回报(赢棋为1,输棋为-1),而之前的时刻立即回报均为0。这种情况下,\(R_t\)等于1或-1,这将导致我们很难衡量策略的优劣,因为即使赢了一盘棋,未必能说明策略中每一步都是好棋;同样输了一盘棋也未必能说明每一步都是坏棋。因此我们需要一个目标函数来刻画策略的长期效用。
为此,我们可以为策略定义一个值函数(value function)来综合评估某个策略的好坏。这个函数既可以是只关于状态的值函数\(V^{\pi}(s)\),也可以状态-动作值函数\(Q^\pi(s,a)\)。状态值函数评估agent处于某个状态下的长期收益, 动作值函数评估agent在某个状态下执行某个动作的长期收益。
本文后续都将以状态值函数为例,进行阐述。一般常用的有三种形式:
- \(V^{\pi}(s) = E_\pi[\sum\limits_{k=0}^{\infty}r_{t+k+1}|s_t=s]\)
- \(V^{\pi}(s) = E_\pi[\lim\limits_{k\to\infty}\frac{1}{k}\sum\limits_{i=0}^{k}r_{t+i+1}|s_t=s]\)
- \(V^{\pi}(s) = E_\pi[\sum\limits_{k=0}^{\infty}\gamma^k r_{t+k+1}|s_t=s]\)
其中\(E_\pi[\cdot|s_t=s]\)表示从状态\(s\)开始,通过执行策略\(\pi\)得到的累积回报的期望。有些情况下,agent和环境的交互是无止境的,比如一些控制问题,这样的问题称为continuing task。还有一种情况是我们可以把交互过程打散成一个个片段式任务(episodic task),每个片段有一个起始态和一个终止态(或称为吸收态,absorbing state),比如下棋。当每个episode结束时,我们对整个过程重启随机设置一个起始态或者从某个随机起始分布采样决定一个起始态。下面的部分我们只考虑片段式任务。
上面三种值函数中,我们一般常用第三种形式,我把它叫做折扣值函数(discounted value function)。下一篇将介绍计算折扣值函数三种方法:动态规划、蒙特卡洛、时间差分。
参考:
1.wiki
2.强化学习二
3.Reinforcement Learning: An Introduction


 浙公网安备 33010602011771号
浙公网安备 33010602011771号