一、内存管理原理
在java中,有java程序、虚拟机、操作系统三个层次,其中java程序与虚拟机交互,而虚拟机与操作系统间交互!这就保证了java程序的平台无关性!下面我们从程序运行前,程序运行中、程序运行内存溢出三个阶段来说一下内存管理原理!
1、程序运行前:JVM向操作系统请求一定的内存空间,称为初始内存空间!程序执行过程中所需的内存都是由java虚拟机从这片内存空间中划分的。
2、程序运行中:java程序一直向java虚拟机申请内存,当程序所需要的内存空间超出初始内存空间时,java虚拟机会再次向操作系统申请更多的内存供程序使用!
3、内存溢出:程序接着运行,当java虚拟机已申请的内存达到了规定的最大内存空间,但程序还需要更多的内存,这时会出现内存溢出的错误!
至此可以看出,Java 程序所使用的内存是由 Java 虚拟机进行管理、分配的。Java 虚拟机规定了 Java 程序的初始内存空间和最大内存空间,开发者只需要关心 Java 虚拟机是如何管理内存空间的,而不用关心某一种操作系统是如何管理内存的。
二、内存空间逻辑划分
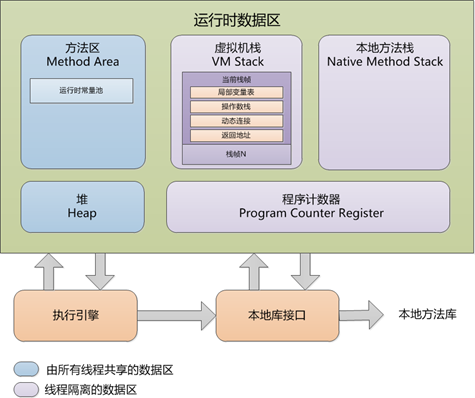
JVM 会把申请的内存从逻辑上划分为三个区域,即:方法区、堆与栈。
方法区:方法区默认最大容量为64M,Java虚拟机会将加载的java类存入方法区,保存类的结构(属性与方法),类静态成员等内容。
堆:默认最大容量为64M,堆存放对象持有的数据,同时保持对原类的引用。可以简单的理解为对象属性的值保存在堆中,对象调用的方法保存在方法区。
栈(虚拟机栈):栈默认最大容量为1M,在程序运行时,每当遇到方法调用时,Java虚拟机就会在栈中划分一块内存称为栈帧(Stack frame),栈帧中的内存供局部变量(包括基本类型与引用类型)使用,当方法调用结束后,Java虚拟机会收回此栈帧占用的内存。
运行时常量池:是方法区的一部分。用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法去的运行时常量池中。
程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。如果线程正在执行的是一个Java方法,这个计数器
记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它
三、java数据类型

1、基本数据类型:没封装指针的变量。
声明此类型变量,只会在栈中分配一块内存空间。
2、引用类型:就是底层封装指针的数据类型。
他们在内存中分配两块空间,第一块内存分配在栈中,只存放别的内存地址,不存放具体数值,我们也把它叫指针类型的变量,第二块内存分配在堆中,存放的是具体数值,如对象属性值等。
3、下面我们从一个例子来看一看:
public class Student {
String stuId;
String stuName;
int stuAge;
}
public class TestStudent {
public static void main(String[] args) {
Student zhouxingxing = new Student();
String name = new String("旺旺");
int a = 10;
char b = 'm';
zhouxingxing.stuId = "9527";
zhouxingxing.stuName = "周星星";
zhouxingxing.stuAge = 25;
}
}
(1)类当然是存放在方法区里面的。
(2)Student zhouxingxing = new Student();
这行代码就创建了两块内存空间,第一个在栈中,名字叫zhouxingxing,它就相当于指针类型的变量,我们看到它并不存放学生的姓名、年龄等具体的数值,而是存放堆中第二块内存的地址,第二块才存放具体的数值,如学生的编号、姓名、年龄等信息。
(3)int a = 10; 这是 基本数据类型 变量,具体的值就存放在栈中,并没有只指针的概念!
四、值传参和引用传参
(1)参数根据调用后的效果不同,即是否改变参数的原始数值,又可以分为两种:按值传递的参数与按引用传递的参数。
按值传递的参数原始数值不改变,按引用传递的参数原始数值改变!这是为什么呢?其实相当简单:
我们知道基本数据类型的变量存放在栈里面,变量名处存放的就是变量的值,那么当基本数据类型的变量作为参数时,传递的就是这个值,只是把变量的值传递了过去,不管对这个值如何操作,都不会改变变量的原始值。而对引用数据类型的变量来说,变量名处存放的地址,所以引用数据类型的变量作为传参时,传递的实际上是地址,对地址处的内容进行操作,当然会改变变量的值了!
五、内存区域调节参数
-Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
-Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
-Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小 + 老生代大小 + 永久代大小。
在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-XX:SurvivorRatio:新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。
-Xss:每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了。
-XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。
-XX:MaxPermSize:设置持久代最大值。物理内存的1/4。
参考:
http://liu1227787871.blog.163.com/blog/static/205363197201263103320466/
http://www.blogjava.net/chhbjh/archive/2012/01/28/368936.html
http://www.cnblogs.com/gw811/archive/2012/10/18/2730117.html