
软工第二次作业
软工个人项目之词频统计
GitHub仓库地址:https://github.com/waaaafool/081600410
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 440 | 1000 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 50 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| · Design | · 具体设计 | 50 | 30 |
| · Coding | · 具体编码 | 300 | 400 |
| · Code Review | · 代码复审 | 40 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 300 |
| Reporting | 报告 | 90 | 70 |
| · Test Repor | · 测试报告 | 60 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 |
需求分析
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
-
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
-
输出的格式为
characters: number
words: number
lines: number
<word1>: number
<word2>: number
思路
拿到题目后,进行分析,发现统计行数,输出文件,以及字母数,都只需要从文件流中读出数据,就可以进行统计。而统计单词则需要进行单词的判定,同时统计最高频率的十个单词不仅需要判定单词,还需要对单词出现的次数进行hash处理。所以就想到了,从文档流中读出string类型,然后进行分割出单词,接着则是对单词放入hash_map中,最后用遍历hash_map,放入容量为十的优先队列。最后对这剩下的十个进行按字符串的比较大小排列,输出。
测试文档
input
a
a
a
a
file123
file123
file123
123file
123file
what should i do?i donot like you.
what should i do?i donot like you.
what should i do?i donot like you.
what should i do?i donot like you.
output
characters:190
words: 19
line:13
<donot>:4
<file123>:3
<like>:4
<should>:4
<what>:4
分析:123file不是单词,以及未满四个字符的单词均未被统计入内。空行也没被统计入行数。
代码规范
对于.h和.cpp文件,均使用每个单词的第一个字母大写来命名,而函数和重要变量使用驼峰法命名。
实现
首先确定文件的组织结构

其中Frequency是用来统计单词的数量,而WordCount是用来统计频率最高的十个单词。
主要算法
统计频率最高的十个单词
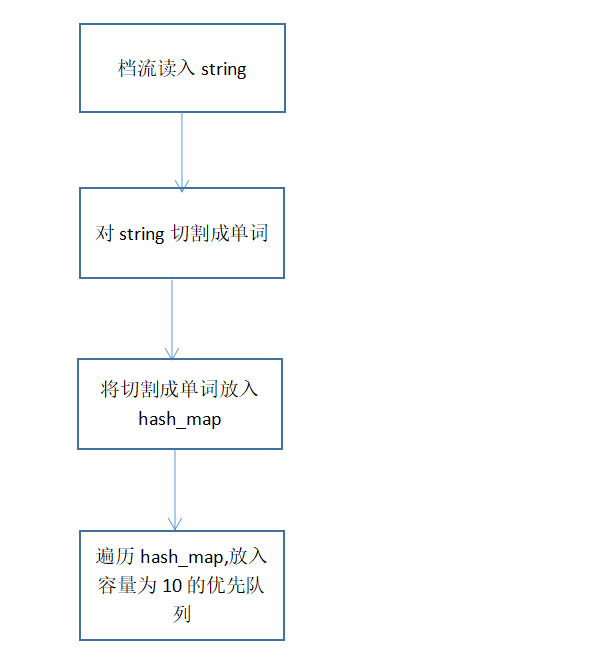
算法关键
引入hash_map,来使查询的时间复杂度变成o(1),以及引入优先队列(堆模型),来使遍历hash_map后,储存以及更新频率最大的单词的时间变为o(lgn);
编码 过程
struct node {
int num;
string s;
};
node result[10];
bool cmp(node a, node b) {
return a.s < b.s;
}
using namespace std;
int number = 0;
void wordCount(const char* file){
ifstream fin;
ofstream fout;
fout.open("..//result.txt", ios::out | ios::app);
fin.open(file);
if (!fout) {
cout << "The File cannot open.1111" << endl;
}
if (!fin) {
cout << "The File cannot open." << endl;
}
string s;
hash_map<string, int> wordList;
while (true) {
fin >> s;
string tem="";
int len = s.length();
int pre = -1;//记录本单词上一个字母的位置,初始为-1
//进行文档流读出的string类型的单词切割
for (int i = 0; i < len; i++) {
if ('A' <= s[i]&&s[i] <= 'Z') s[i] += 32;
if (s[i] > 'z' || (s[i]<'a'&&s[i]>'9') || s[i] < '0') {
if (i - pre > 4&&(s[pre+1]<='z'&&s[pre + 1]>='a')) {
for (int j = pre + 1; j < i; j++)
tem += s[j];
wordList[tem]++;
tem = "";
}
pre = i;
}
else if (i == len - 1 && i - pre >=4 && (s[pre + 1] <= 'z'&&s[pre + 1] >= 'a')) {
for (int j = pre + 1; j <= i; j++)
tem += s[j];
wordList[tem]++;
tem = "";
}
}
if (fin.eof()) {
break;
}
}
priority_queue<pair<int, string>, vector<pair<int, string>>,greater<pair<int, string>>> maxList;
//遍历hash_map,加入优先队列
for (hash_map<string, int>::const_iterator i = wordList.begin(); i != wordList.end(); i++) {
maxList.push(make_pair(i->second, i->first));
if (maxList.size() > 10) {
maxList.pop();
}
}
int i = 0;
//取出队列里面的值,放入result结构数组中
while (!maxList.empty()) {
result[i].num = maxList.top().first;
result[i].s = maxList.top().second;
maxList.pop();
i++;
}
//排序输出
sort(result, result + i, cmp);
for (int j = 0; j < i; j++) {
cout << "<" << result[j].s << ">" << ":" << result[j].num << endl;
fout << "<" << result[j].s << ">" << ":" << result[j].num << endl;
}
fin.close();
fout.close();
}
分析:代码使用循环来分割单词,使得性能比较慢,可以改用正则表达式来改进。
性能分析报告
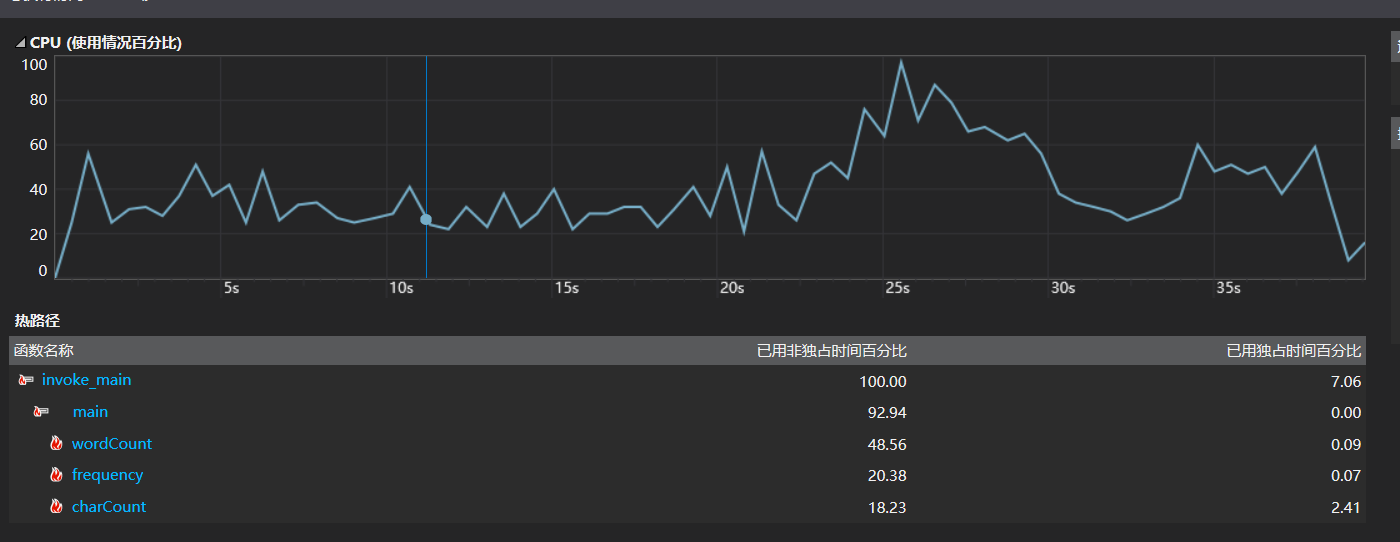
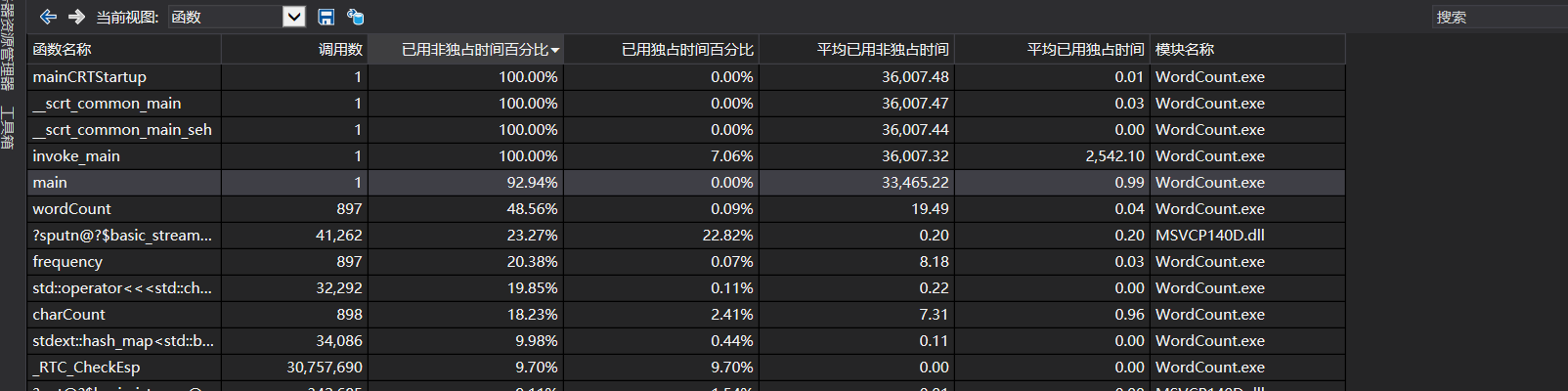

分析:对main函数进行大量循环,发现除了那几个自己定义的函数之外,输入输出流占用的cpu比例很大,以前写一些算法题的时候也发现使用C++的输入输出流会超时。所以改用c的输入输出会好很多,因为c++的输入输出流封装了太多c的东西。
单元测试
设计:
1、传入一个空文件;
2、传入只有123file等的文件;
3、传入只有空格,\t,\n等字符;
4、传入一个文件,其中包含空行的;
5、传入一个文件,里面有类似adc.fef类似的非空白符为终结符的;
6、传入一个文件,里面不超过十个有效单词的。
7、输入一个文件,里面单词有类似window2002,window1001fa类似的,看输出排列。
通过该变文件类型,证明成功,但由于VS未能找到对应的test,所以没有工程化测试,有点遗憾。
代码覆盖率
下载插件OpenCppCoverage
代码覆盖率的截图如下:

分析:总体而言覆盖率还是很不错的。
异常处理
1、在一开始进行main函数整合的时候,如果文件为空,发现会直接返回错误信息
于是加了一个判断
if (argv == NULL) {
cout << "请输入文件名" << endl;
return 0;
}
总结和感想
经过这次软工实践,让我感受到了为什么说退课率这么高了。很多人不一定是因为坚持不下来,而是在衡量坚持下来和换个其他东西坚持,哪个性价比更高。因为软工确实太耗时间了,真的非常耗时间。
通过这次,最直观的就是感受到自己对各种工具的使用能力的匮乏,这次题目,编码不难,难的是在后面插件的下载与使用。
现在想着,如果最后坚持下来,那一定能学到很多东西的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号