
使用kubeadm安装k8s高可用集群的一些坑 v1.18.8
架构是3台master加2台work节点。负载均衡模式使用的haproxy+keepalived。
前期的一些准备网上有很多介绍,大家可以直接参考其他的一些文章。这里主要介绍一些其他的异常报错。
- 、/var/log/message报错
Sep 15 16:47:32 k8s-master-1 kubelet: E0915 16:47:32.945920 2757 kubelet_node_status.go:92] Unable to register node "vip-k8s-master" with API server: Post https://vip-k8s-master:8443/api/v1/nodes: http: server gave HTTP response to HTTPS client Sep 15 16:47:33 k8s-master-1 kubelet: E0915 16:47:33.511767 2757 event.go:269] Unable to write event: 'Post https://vip-k8s-master:8443/api/v1/namespaces/default/events: http: server gave HTTP response to HTTPS client' (may retry after sleeping)
解决办法:haproxy配置有问题,配置文件里mode全部改为tcp,启动后查看haproxy日志,端口是否正常。
- 启动flannel插件后,coredns状态还是notreday ,/var/log/message也有对应报错
Sep 16 10:13:42 k8s-master-1 kubelet: : [plugin flannel does not support config version "" plugin portmap does not support config version ""] Sep 16 10:13:42 k8s-master-1 kubelet: W0916 10:13:42.168412 9539 cni.go:237] Unable to update cni config: no valid networks found in /etc/cni/net.d Sep 16 10:13:42 k8s-master-1 kubelet: E0916 10:13:42.460568 9539 kubelet.go:2188] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
解决办法:flannel.yaml的configmap中的cni-conf.json数据缺少cniVersion字段,因此plugin flannel does not support config version ""返回类似错误。此处flannel版本用的是v0.11.0。
在cbr0 这一行上面新增一行:"cniVersion":"0.3.1",然后重新应用一下配置文件。如果coredns还是异常,可以干掉这个pod重来。

cni-conf.json: | { "cniVersion":"0.3.1", "name": "cbr0", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] }
3、kube-scheduler和kube-controller-manager组件状态异常,显示Unhealthy
NAME STATUS MESSAGE ERROR scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: connect: connection refused etcd-0 Healthy {"health":"true"}
解决办法:ss -ntl确实没有这些端口。查看kube-scheduler和kube-controller-manager组件配置是否禁用了非安全端口。注释掉--port=0 然后重启kubelet systemctl restart kubelet
配置文件路径:/etc/kubernetes/manifests/kube-scheduler.conf 、/etc/kubernetes/manifests/kube-controller-manager.conf
spec: containers: - command: - kube-scheduler - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf - --bind-address=127.0.0.1 - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true # - --port=0 image: k8s.gcr.io/kube-scheduler:v1.18.8 imagePullPolicy: IfNotPresent
4,设置docker运行所需参数
cat > /etc/sysctl.d/k8s.conf << EOF net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF modprobe br_netfilter sysctl -p /etc/sysctl.d/k8s.conf
在/etc/docker/daemon.json这个文件中添加 "exec-opts": ["native.cgroupdriver=systemd"],
4、加载ipvs模块
cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules
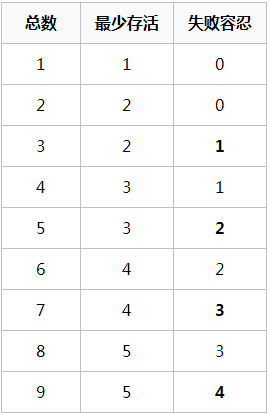
5,etcd节点必须3个及以上,这是一个失败容忍度的介绍。具体的可以去官网查看


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~