Python中if __name__=="__main__" 语句在调用多进程Process过程中的作用分析
2018年2月27日 于创B515
引言
最近准备学习一下如何使用Python中的多进程。在翻看相关书籍、网上资料时发现所有代码都含有if __name__=="__main__",在实验的过程中发现如果在运行代码过程中,没有这句话Python解释器就会报错。虽然Python对于multiprocessing的文档第17.2.1.1节中【1】提到必须如此使用,但是我觉得并没有根本上解释清楚。因此我决定从源码来解释我的疑惑。
# 代码0.1错误代码
import multiprocessing as mp import os def do(): print("pid is : %s ..." % os.getpid()) print("parent id is : %s ..." % os.getpid()) p = mp.Process(target=do, args=()) p.start()
# 代码0.2正确代码 import multiprocessing as mp import os def do(): print("pid is : %s ..." % os.getpid()) if __name__ == '__main__': print("parent id is : %s ..." % os.getpid()) p = mp.Process(target=do, args=()) p.start()
问题描述
问题
在运行代码-0.1时,会出现RuntimeError,错误提示如下。但是运行代码0.2时就不会,一切顺利。
An attempt has been made to start a new process before the current process has finished its bootstrapping phase. This probably means that you are not using fork to start your child processes and you have forgotten to use the
proper idiom in the main module: if __name__ == '__main__': freeze_support() ... The "freeze\_support()" line can be omitted if the program is not going to be frozen to produce an executable.
问题产生的环境
| 运行环境: | Win10 |
| IDE | Sublime Text3 |
简单解释
由于Python运行过程中,新创建进程后,进程会导入正在运行的文件,即在运行代码0.1的时候,代码在运行到mp.Process时,新的进程会重新读入改代码,对于没有if __name__=="__main__"保护的代码,新进程都认为是要再次运行的代码,这是子进程又一次运行mp.Process,但是在multiprocessing.Process的源码中是对子进程再次产生子进程是做了限制的,是不允许的,于是出现如上的错误提示。
详细解释
先谈一谈if__name__=="__main__"
在Python有关__main__的文档中【2】说明“__main__”是代码执行时的最高的命名空间(the name of the scope in which top-level code executes),当代码被当做脚本读入的时候,命名空间会被命名为“__main__”,对于在脚本运行过程中读入的代码命名空间都不会被命名为“__main__”。这也就是说创建的子进程是不会读取__name__=="__main__"保护下的代码。
再谈一谈multiprocessing(win32下的源码分析)
multiprocessing根据平台不同会执行不同的代码:在类UNIX系统下由于操作系统本身支持fork()语句,win32系统由于本身不支持fork(),因此在两种系统下multiprocessing会运行不同的代码,如图1 UNIX平台、图2 win32平台(包含在context.py文件中,Process的定义也是在context.py文件中)。

图1 对于类UNIX系统平台

图2 对于win32系统平台
Process是一个高度依赖继承的类———其父类是BaseProcess,如图3 Process类的定义。在使用过程中先初始化一个Process实例,然后通过Process.start()来启动子进程。我们继续看关于Process.start()的定义,如图4 BaseProcess类中的start()定义。在其中第105行,调用了self._Popen(self),该函数重定义定义于Process类。该函数按调用顺序最后会跳转到 popen_spwan_win32.py 文件中的Popen类,如图5 Popen类的定义。Popen类在初始话过程中首先调用windows相关接口,生成一个管道(38行),取得对管道读写的句柄,然后生成一个命令行的字符串列表——cmd,如下:
['C:\\Program Files\\Python35\\python.exe', '-B', '-c', 'from multiprocessing.spawn import spawn_main;spawn_main(pipe_handle=928, parent_pid=9292)', '--multiprocessing-fork']

图3 Process类的定义
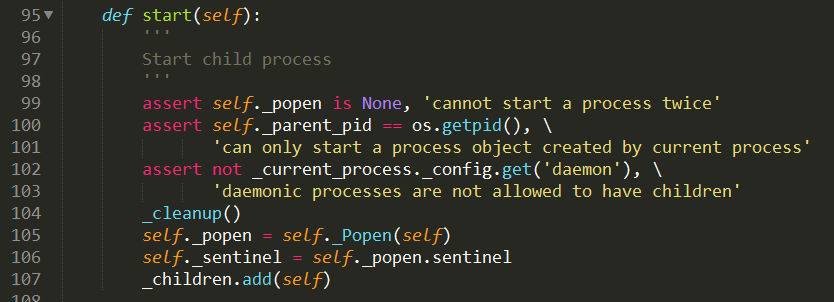
图4 BaseProcess类中的start()定义

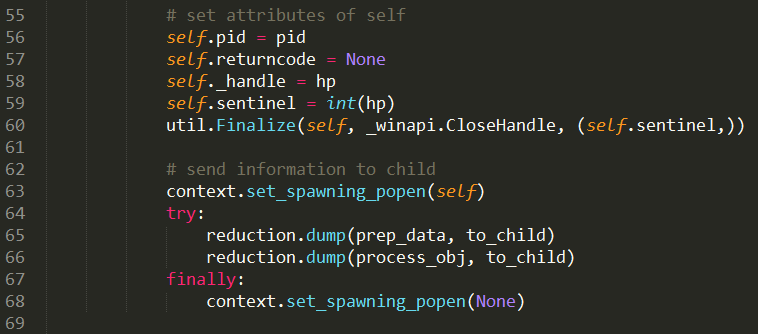
图5 Popen类的定义
这个字符串列表之后通过命令行送入系统,得到相应的子进程和子线程的句柄及子进程和子线程的ID号。在第65、66行是通过pickle方法将必要的数据从父进程传输给子进程。新进程是调用spawn.py文件中的spawn_main函数,如图6 spawnmain的定义。其中第100行的steal_handle()的作用是子进程获取父进程生成的句柄,用于后续通信——使用pickle方法从父进程中读取必要数据。而问题的出现就是在这之后出现!该代码在第106行调用_main(),其次在第115行调用prepare(),再次运行到223行时,运行_fixup_main_from_name(),而此时该函数会运行父进程的脚本。因此对于没有if__name__=="__main__"保护的代码都是要运行的,而此时在第二次运行Process创建新进程的时候在第123行 if getattr(process.current_process(), '_inheriting', False): 时,由于子进程是具有_inheriting属性,因此会激发出上述错误代码。
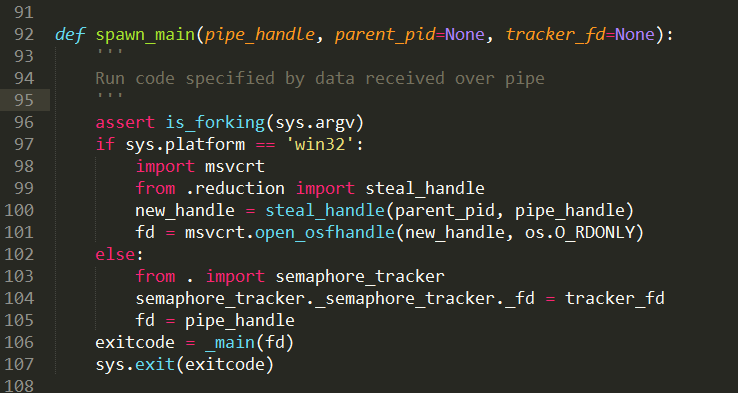
图6 spawn_main的定义
对于代码中生成新子进程时所用到的两个技术我觉很有趣也很苦恼,因此决定继续看下去。下面简单描述一下两个技术的概况。
—— pickle模块
首先是pickle模块。pickle模块是一个Python中特有的数据格式,与JSON等不同,是不能被其他语言识别的格式。在Python中的官方文档【3】中比较了pickle模块与JSON的不同之处,以及介绍了pickle的使用条件。简单摘录如下:
|
|
—— 管道(Pipe)
这里理解管道是从类UNIX系统理解,因为其理解起来更方便。管道在类UNIX系统中也是一种文件,在生成新的子进程的时候将两个进程都关联至同一个管道上,这样就是双工通信(父子进程相互可读可写)。如果要实现单工通信,就关闭相应的通道(一方写一方读)【4】。
参考文献
- Python3.5 关于multiprocessing的文档 https://docs.python.org/3.5/library/multiprocessing.html
- Python3.5 关于__main__的文档 https://docs.python.org/3.5/library/__main__.html
- Python3.5 关于pickle的文档 https://docs.python.org/3.5/library/pickle.html?highlight=pickle#module-pickle
- 网上一片关于pipe的介绍 http://www.cnblogs.com/qiaoyanlin/p/7576085.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号