

Data Deduplication Workflow Part 1
Data deduplication provides a new approach to store data and eliminate duplicate data in chunk level.
A typical data deduplication workflow can be explained like this.
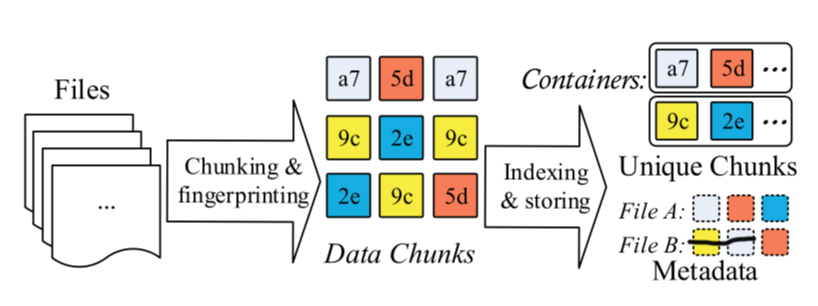
File metadata describes how to restore the file use unique chunks.
Chunk level deduplication approach has five key stages.
- Chunking
- Fingerprinting
- Indexing fringerprints
- Further compression
- Storage management
Different Stage has its own challenges, which may become the bottleneck for restoring file or compressing files.
Chunking
At the chunking stage, we should split the data stream into chunks, which can be presented at the fingerprints.
The different method splitting data streaming has different result and different efficiency.
The splitting method can be divided into two categories:
Fixed Size Chunking, which just split the data stream into fixed size chunk, simply and easily .
Content Defined Chunking, which split the data into variable size chunk, depending on the content.
Although fixed size chunking is simple and quick, the biggest problem is Boundary Shift. Boundary Shift Problem is when little part of data stream is modified, all the subsequent chunks will be changed, because of the boundary is shifted.
Content defined chunking uses a sliding-window technique on the content of data stream and computes a hash value of the window. If the hash value is satisfied some predefined conditions, it will generate a chunk.
Chunk's size can also be optimized. If we use CDC (content defined chunking), the size of chunking can not be in charge. On some extremely condition, it will generate too large or too small chunking. If a chunking is too large, the compression ratio will decrease. Because the large chunk can hide duplicates from being detected. If a chunking is too small, the file metadata will increase. What's more, it can cause indexing fingerprints problem. So we can define the max and min chunk size.
Chunking still has some problems such as how to detect the deduplicate accurately, how to accelerate computing time cost.
