

Map Reduce 论文阅读
Map Reduce 是 Google 在 2004 年发表的一篇论文,原文链接 在这 后来 Hadoop 直接内置了这一框架。
读完之后记录一下心得。
主要背景:MapReduce 的出现很具有工程特性,在海量数据出现后,面临的问题是我们如何利用大量的,性能不是很强的服务器对数据进行处理。
主要思想:主要思想也很简单,分治的思想解决问题。把大量的数据划分成较小的,单机可处理的数据,对不同的主机进行任务划分,最终合并结果。主机之间的连接通过。
主要模型:
整个 Map Reduce 阶段如下图所示,先做数据的划分,然后由一个 master 节点划分出不同的 worker,然后分配给不同的 worker 进行 Map 或者 Reduce 操作。Map 后的结果进行 Reduce 操作,得到最终的结果。
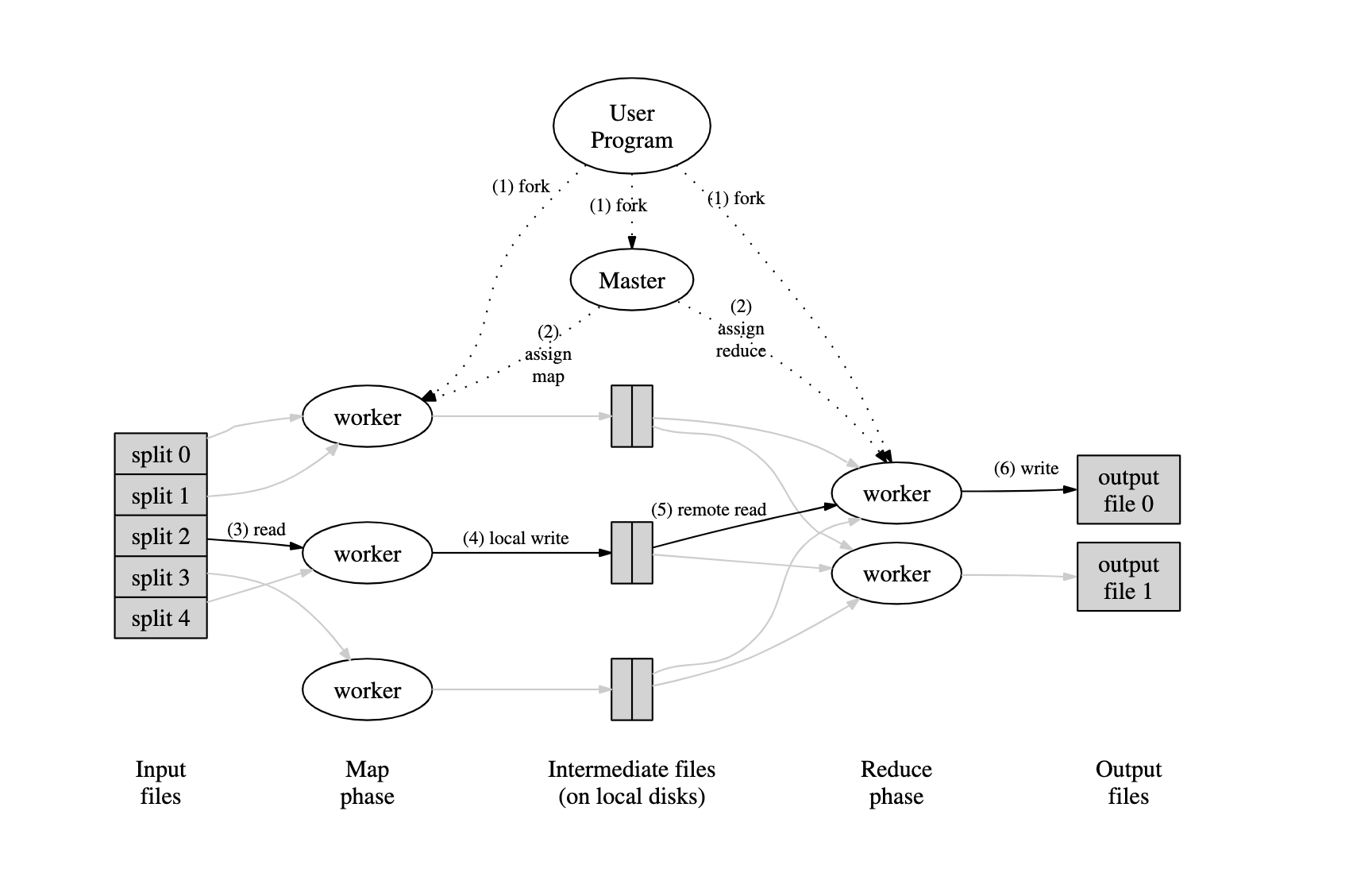
可以看到,主要完成的计算有两个: Map() 和 Reduce() ,这两个函数从语义上已经很好理解,Map 函数的 input 是一组 key-value 对,output 也是一组 key-value 对。主要功能是把原先的大数据量下的 k-v 映射到一个新的空间下的 k-v 。
Reduce 函数的 input 基于 Map 函数产出的 k-v,output 是处理后的结果,但基本都是在原先的数据上做汇总处理。也就是 reduce 的语义。
Google 给出的Map-Reduce 函数模型如下:
map (k1, v1) -> list (k2, v2)
reduce(k2, list(v2)) -> list(v2)
给个栗子,现在有十副牌已经混乱,现在需要在其中找出一副牌,用 MapReduce 的思想来处理这个问题,就可以分成两个阶段,Map 阶段,把 10 副牌进行划分,对每一个划分而言做 Map 操作,这里的 Map 操作可以为把手中的牌分为4类 ♥️,♣️,♦️,♠️这四类。然后对这四类的结果做 Reduce 操作,即从每个花色找到13张不同的牌,这样,就可以找到一副完整的扑克牌。
map(list pokers) :
for poker in pokers:
dic[getClass(poker)].append(poker)
return dic;
reduce(list hearts, list diamonds, list clubs, list spades):
finish(hearts)
finish(diamonds)
finish(clubs)
finish(spades)
整个过程在理论上而言很简单,也很容易理解。难点主要集中在下面几个部分
- 如何做数据的划分
- 如何对大量的主机做调度
- 如果某一个主机出现了失败如何处理
- 主机间的通信如何管理
失败的处理:
Master 通过心跳机制来维护对 worker 的管理,由于单机的 worker 会先把 Map 的结果存在本地,所以,如果一个 worker A失去维护,那么这个 worker 的任务将会被重新进行编排分给 worker B。并且,所有进行 Reduce 操作的 worker 都会收到通知,因为 Reduce 需要的数据可能会从 A 读,所以,需要通知所有进行 Reduce 操作的 worker。
如果 Master 失败,由于 Master 只有一个,所以 Master 会定期进行状态存储,如果 Master 失败,则人工恢复到最新状态。
一些优化:
Backup Task:因为总的时间会受耗时最长的任务影响,而对于某个耗时最长任务而言,可能不是其任务本身带来的负面影响导致其处理时间延长,而是执行这个任务的机器自身的影响。所以,对于一个快要结束的任务,Master 会为其分配一个 backup 的操作,这个 backup 状态和之前的一样,只是在不同的机器上执行。如果这两个任务中任何一个完成,那么就视为这个任务已经完成。而这个 backup 操作提升时间也是非常显著的,大概能有44%的提升。
Ordering Guarantee:在一个 map 操作完成后,进行 sort 操作,保证其的顺序,这样对于 reduce 而言,在进行查找的时候,会变得非常高效。
Combiner Function:在 map 操作完成后,在本地进行 combine 操作,可以减少数据的传输,也可以减少 Reduce 的数据量。
