大数据学习笔记——Spark完全分布式完整部署教程
Spark完全分布式完整部署教程
继Mapreduce之后,作为新一代并且是主流的计算引擎,学好Spark是非常重要的,这一篇博客会专门介绍如何部署一个分布式的Spark计算框架,在之后的博客中,更会讲到Spark的基本模块的介绍以及底层原理,好了,废话不多说,直接开始吧!
1. 安装准备
部署Spark时,我们使用的版本如下所示:

2. 正式安装
1. 将spark-2.4.3-bin-hadoop2.7.tgz文件使用远程传输软件发送至/home/centos/downloads目录下
2. 将spark-2.4.3-bin-hadoop2.7.tgz解压缩至/soft目录下
tar -xzvf spark-2.4.3-bin-hadoop2.7.tgz -C /soft
3. 进入到/soft目录下,配置spark的符号链接
cd /soft
ln -s spark-2.4.3-bin-hadoop2.7 spark
4. 修改并生效环境变量
nano /etc/profile
在文件末尾添加以下代码:
#spark环境变量
export SPARK_HOME=/soft/spark
export PATH=$PATH:$SPARK_HOME/bin
生效环境变量后保存退出
source /etc/profile
5. 规划集群部署方案
根据现有的虚拟机配置,集群部署方案为:s101节点作为master节点,s102 - s104作为worker节点
6. 使用脚本分发spark软件包以及/etc/profile文件到所有节点
cd /soft
xsync.sh spark-2.4.3-bin-hadoop2.7
xsync.sh /etc/profile
7. 使用ssh连接到除s101外的其他所有节点创建符号链接
ssh s102
cd /soft
ln -s spark-2.4.3-bin-hadoop2.7 spark
exit
其他节点同理
8. 配置spark的配置文件并分发到所有节点
cd /soft/spark/conf
cp spark-env.sh.template spark-env.sh
nano spark-env.sh
在文件末尾处添加后保存退出:
export JAVA_HOME=/soft/jdk
export HADOOP_CONF_DIR=/soft/hadoop/etc/hadoop
准备好如下文件,避免每次提交spark job上传spark类库:
![]()
先用WinScp将spark的类库放到/home/centos目录下
将spark的类库上传到HDFS文件系统上去:hdfs dfs -put /home/centos/spark_lib.zip /
修改spark-defaults配置文件:
cp spark-defaults.conf.template spark-defaults.conf
nano spark-defaults.conf
在文件末尾处添加后保存退出:
spark.yarn.archive hdfs://mycluster/spark_lib.zip
cp slaves.template slaves
nano slaves
在文件中末尾处删除localhost并添加以下命令后后保存退出:
s102
s103
s104
分发上述三个个配置文件
xsync.sh spark-env.sh
xsync.sh spark-defaults.conf
xsync.sh slaves
9. 启动spark集群
/soft/spark/sbin/start-all.sh
10. 查看进程
xcall.sh jps
出现以下画面:

11. 查看WebUI
http://s101:8080
配置大功告成!!!

12. 结合hadoop启动spark的各种模式检测是否都能正常启动
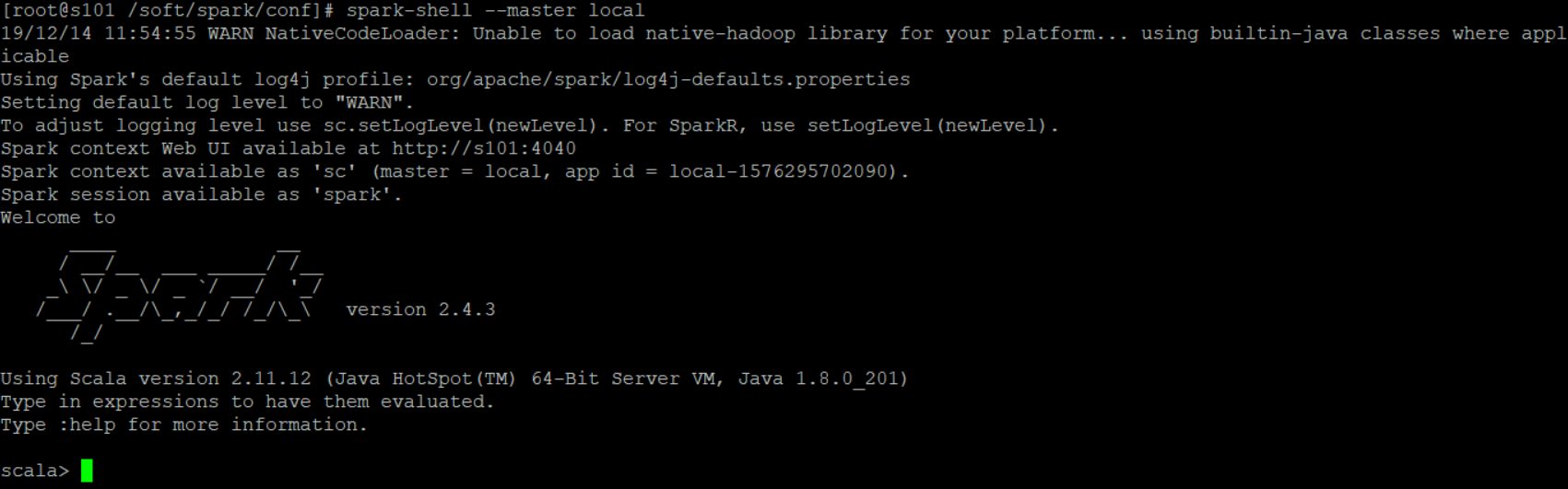
启动local模式:spark-shell --master local
启动hadoop集群:
xzk.sh start
start-all.sh
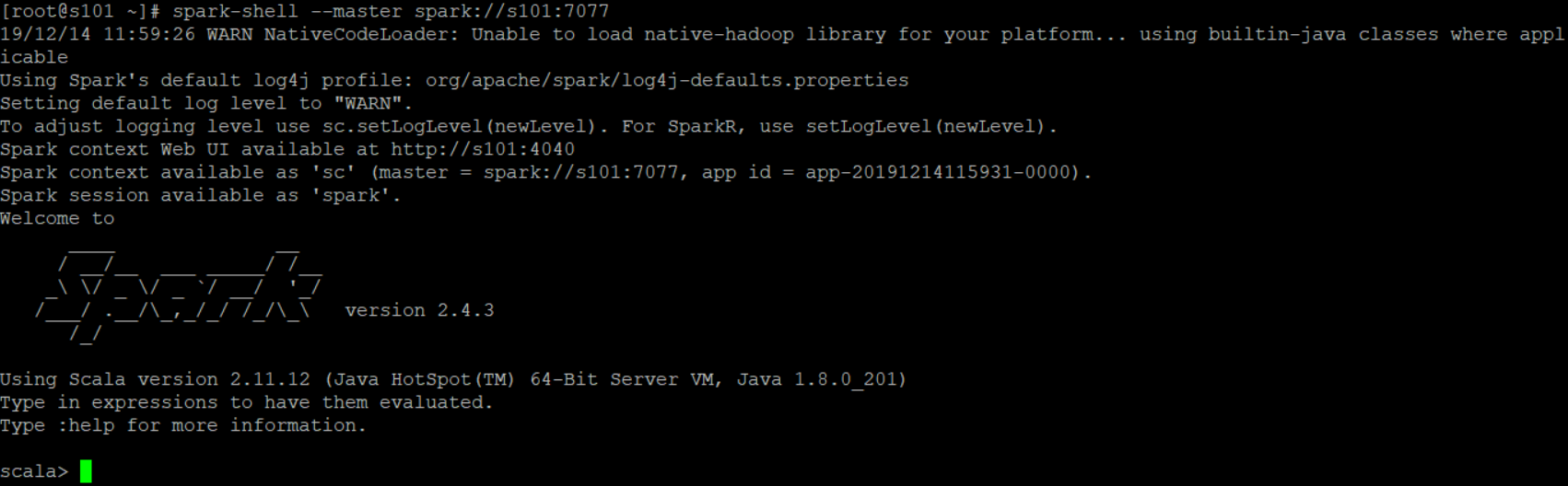
然后启动standalone模式:spark-shell --master spark://s101:7077
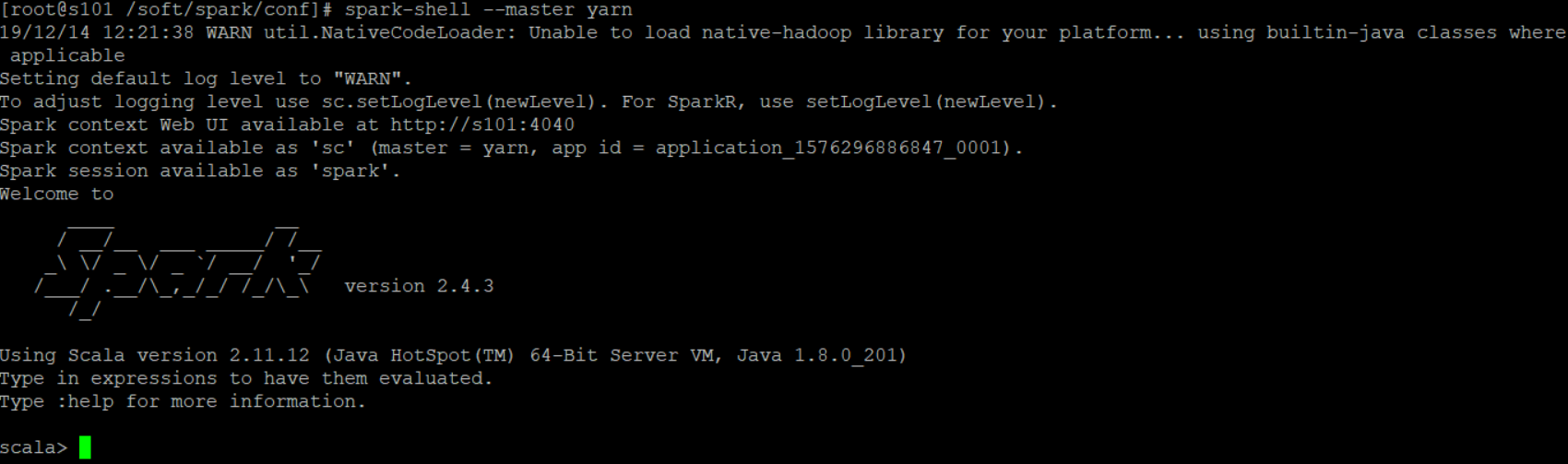
最后测试yarn模式是否能连接成功:spark-shell --master yarn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号