

【8】分块学习笔记
前言
分块是一种重要的高级数据结构思想,核心为大段维护,局部朴素。
顺带一提,由于个人技术水平,本篇博客的难度并没有标题所述的 级。分块还是很难的。
分块
分块,是“优雅的暴力”。
分块的基本思想是把数据分为若干个块(一般块长为 ),一个块内的数据在操作中具有相同的属性,对于整块,可以直接设置一个变量表示变化。由于块数为 ,整块更新的复杂度最多为 。对于非整块,可以朴素更新。由于一个块的块长为 ,朴素更新的复杂度最多为 。综上,省略常数,一次操作的时间复杂度就被降低为了 。所以分块的时间复杂度大约为 ,属于根号数据结构。
具体实现方式见下面的代码。(例题 和 是两种不同的实现方式)
分块例题
例题 :
对于操作 或 ,是分块的经典模板。
设块号为 的块表示范围为
首先预处理出每个位置处于的块,记作 ,然后输入 后,令 。同时记录两个数组: ,表示第 块的增量标记。 ,表示第 块的整块和。
对于 ,是前面不完整的一段,朴素更新。
对于 ,是后面不完整的一段,朴素更新。
对于 ( 为块号),是整块完整更新的块,更新标记 。
查询的时候,不完整的两段朴素更新,中间的整块直接查询整块和。注意都要加上增量标记。
对于其他操作,可以直接单点修改,记得更新增量标记。
#include <bits/stdc++.h>
using namespace std;
long long n,f,a[2000001],op,l,r,k,lb[2000001],rb[2000001],sum[2000001],pos[2000001],add[2000001];
inline long long read()
{
long long x=0,f=1;char ch=getchar();
while (ch<'0'||ch>'9'){if (ch=='-') f=-1;ch=getchar();}
while (ch>='0'&&ch<='9'){x=x*10+ch-48;ch=getchar();}
return x*f;
}
void adde()
{
l=read();r=read();k=read();
int p=pos[l],q=pos[r];
if(p==q)
for(int i=l;i<=r;i++)a[i]+=k,sum[p]+=k;
else
{
for(int i=l;i<=rb[p];i++)a[i]+=k,sum[p]+=k;
for(int i=lb[q];i<=r;i++)a[i]+=k,sum[q]+=k;
for(int i=p+1;i<=q-1;i++)add[i]+=k;
}
}
void ask()
{
long long ans=0;
l=read();r=read();
int p=pos[l],q=pos[r];
if(p==q)
{
for(int i=l;i<=r;i++)ans+=a[i];
printf("%lld\n",ans+(r-l+1)*add[p]);
}
else
{
for(int i=l;i<=rb[p];i++)ans+=a[i];
ans+=(rb[p]-l+1)*add[p];
for(int i=lb[q];i<=r;i++)ans+=a[i];
ans+=(r-lb[q]+1)*add[q];
for(int i=p+1;i<=q-1;i++)ans+=sum[i],ans+=add[i]*(rb[i]-lb[i]+1);
printf("%lld\n",ans);
}
}
int main()
{
n=read();f=read();
int kl=sqrt(n);
for(int i=1;i<=kl;i++)
{
lb[i]=(i-1)*kl+1;
rb[i]=i*kl;
}
if(rb[kl]<n)kl++,lb[kl]=rb[kl-1]+1,rb[kl]=n;
for(int i=1;i<=n;i++)
a[i]=read();
for(int i=1;i<=kl;i++)
for(int j=lb[i];j<=rb[i];j++)
{
pos[j]=i;
sum[i]+=a[j];
}
for(int i=0;i<f;i++)
{
op=read();
if(op==1)adde();
else if(op==2)
{
k=read();
a[1]+=k,sum[1]+=k;;
}
else if(op==3)
{
k=read();
a[1]-=k,sum[1]-=k;
}
else if(op==4)ask();
else if(op==5)printf("%lld\n",a[1]+add[1]);
}
return 0;
}
例题 :
问题 B: 分块2(站外题,提供题面展示)
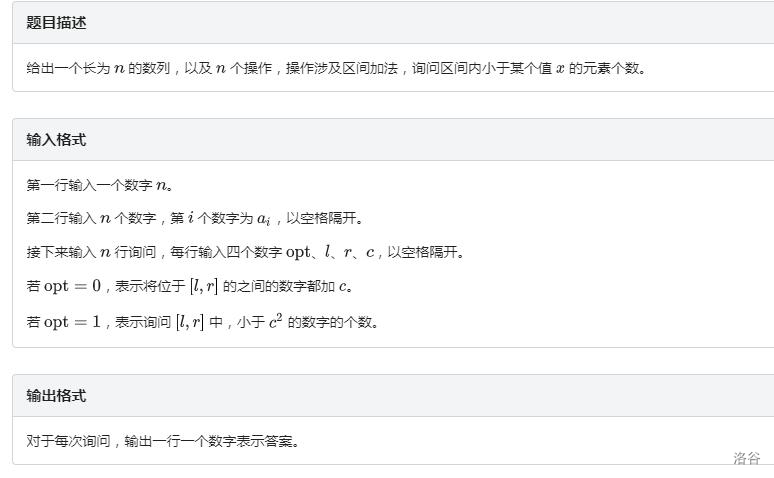
设块号为 的块表示范围为
首先预处理出每个位置处于的块,记作 。预处理时记录每一块的元素数量,同时记录每一块的每个元素的值与在原数组中的位置,用于块内排序。同时记录两个数组: ,表示第 块的增量标记。 ,表示原数组中第 项对应块内编号为 。
修改操作
对于 ,是前面不完整的一段,朴素更新,更新之后依据每块位置 的信息更新块内信息。然后重新块内排序,更新 数组。
对于 ,是后面不完整的一段,朴素更新,更新之后依据每块位置 的信息更新块内信息。然后重新块内排序,更新 数组。
对于 ( 为块号),是整块完整更新的块,更新标记 。由于块内元素同增同减,顺序不变,不需要块内重排或更新 数组
时间复杂度:
询问操作
对于 ,是前面不完整的一段,朴素查询,比较每个元素加上其对应的组的 值与 的大小,如果小于, 自增。
对于 ,是后面不完整的一段,朴素查询,比较每个元素加上其对应的组的 值与 的大小,如果小于, 自增。
对于 ( 为块号),是整块完整更新的块,由于块内元素有序,可以在每一块内部二分查找最大的小于 减去对应 值的元素,得到编号后就可以计算出小于 的元素个数。
时间复杂度:
总的复杂度为(忽略低次项和常数):
#include <bits/stdc++.h>
using namespace std;
struct node
{
int val,p;
}nei[250][250];
long long n,k,op,l,r,c,a[50010],id[50010],add[50010],num[50010],d[50010];
bool cmp(struct node a,struct node b)
{
return a.val<b.val;
}
void adde()
{
long long p=id[l],q=id[r];
if(p==q)
{
for(long long i=l;i<=r;i++)
{
a[i]+=c;
nei[p][d[i]].val+=c;
}
sort(nei[p]+1,nei[p]+num[p]+1,cmp);
for(int j=1;j<=num[p];j++)d[nei[p][j].p]=j;
}
else
{
for(long long i=p+1;i<=q-1;i++)
add[i]+=c;
for(long long i=l;i<=p*k;i++)
{
a[i]+=c;
nei[p][d[i]].val+=c;
}
sort(nei[p]+1,nei[p]+num[p]+1,cmp);
for(int j=1;j<=num[p];j++)d[nei[p][j].p]=j;
for(long long i=(q-1)*k+1;i<=r;i++)
{
a[i]+=c;
nei[q][d[i]].val+=c;
}
sort(nei[q]+1,nei[q]+num[q]+1,cmp);
for(int j=1;j<=num[q];j++)d[nei[q][j].p]=j;
}
}
long long search(long long z,long long key)
{
long long l=0,r=num[z];
while(l<r)
{
long long mid=(l+r+1)/2;
if(nei[z][mid].val<key)l=mid;
else r=mid-1;
}
return l;
}
long long ask()
{
long long p=id[l],q=id[r],ans=0;
if(p==q)
{
for(long long i=l;i<=r;i++)if(a[i]+add[p]<c*c)ans++;
return ans;
}
else
{
for(long long i=p+1;i<=q-1;i++)ans+=search(i,c*c-add[i]);
for(long long i=l;i<=p*k;i++)if(a[i]+add[p]<c*c)ans++;
for(long long i=(q-1)*k+1;i<=r;i++)if(a[i]+add[q]<c*c)ans++;
return ans;
}
}
int main()
{
scanf("%lld",&n);
k=sqrt(n);
for(long long i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
id[i]=(i-1)/k+1;num[id[i]]++;
nei[id[i]][i-(id[i]-1)*k].val=a[i];
nei[id[i]][i-(id[i]-1)*k].p=i;
}
for(long long i=1;i<=id[n];i++)
{
sort(nei[i]+1,nei[i]+num[i]+1,cmp);
for(int j=1;j<=num[i];j++)d[nei[i][j].p]=j;
}
for(long long i=1;i<=n;i++)
{
scanf("%lld%lld%lld%lld",&op,&l,&r,&c);
if(op==0)adde();
else if(op==1)printf("%lld\n",ask());
}
return 0;
}
例题 :
问题 C: 分块3(站外题,提供题面展示)
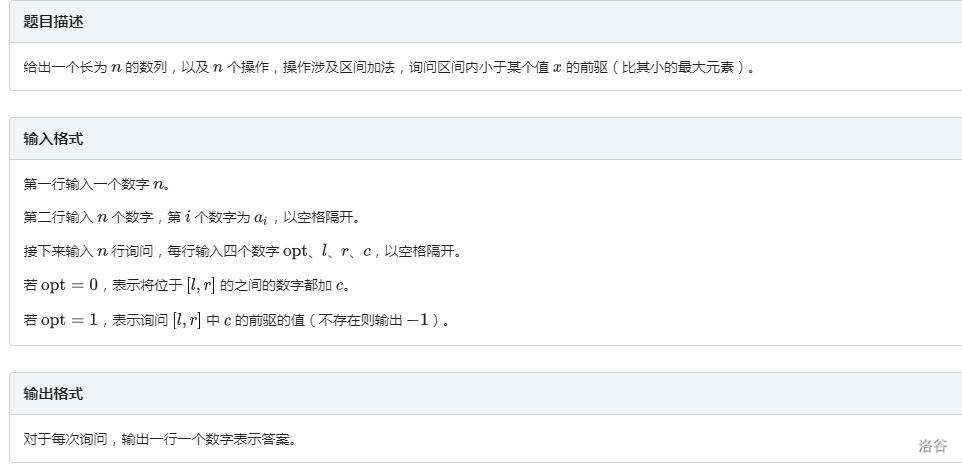
修改操作同例题 。
询问操作
对于 ,是前面不完整的一段,朴素查询,比较每个元素加上其对应的组的 值与 的大小,如果小于,比较查询结果加上对应 值与 的大小,如果大于,更新 的值。
对于 ,是后面不完整的一段,朴素查询,比较每个元素加上其对应的组的 值与 的大小,如果小于,比较查询结果加上对应 值与 的大小,如果大于,更新 的值。
对于 ( 为块号),是整块完整更新的块,由于块内元素有序,可以在每一块内部二分查找最大的小于 减去对应 值的元素,得到结果后就可以计算出小于 的元素的最大值,然后和 取 即可。
注意:如果查询结果为不存在,应当返回负无穷,否则会WA掉。
时间复杂度:
总的复杂度为(忽略低次项和常数):
#include <bits/stdc++.h>
using namespace std;
struct node
{
int val,p;
}nei[500][500];
long long n,k,op,l,r,c,a[100010],id[100010],add[100010],num[100010],d[100010];
bool cmp(struct node a,struct node b)
{
return a.val<b.val;
}
void adde()
{
long long p=id[l],q=id[r];
if(p==q)
{
for(long long i=l;i<=r;i++)
{
a[i]+=c;
nei[p][d[i]].val+=c;
}
sort(nei[p]+1,nei[p]+num[p]+1,cmp);
for(int j=1;j<=num[p];j++)d[nei[p][j].p]=j;
}
else
{
for(long long i=p+1;i<=q-1;i++)
add[i]+=c;
for(long long i=l;i<=p*k;i++)
{
a[i]+=c;
nei[p][d[i]].val+=c;
}
sort(nei[p]+1,nei[p]+num[p]+1,cmp);
for(int j=1;j<=num[p];j++)d[nei[p][j].p]=j;
for(long long i=(q-1)*k+1;i<=r;i++)
{
a[i]+=c;
nei[q][d[i]].val+=c;
}
sort(nei[q]+1,nei[q]+num[q]+1,cmp);
for(int j=1;j<=num[q];j++)d[nei[q][j].p]=j;
}
}
long long search(long long z,long long key)
{
long long l=0,r=num[z];
while(l<r)
{
long long mid=(l+r+1)/2;
if(nei[z][mid].val<key)l=mid;
else r=mid-1;
}
if(l==0)return -99999999;
else return nei[z][l].val;
}
long long ask()
{
long long p=id[l],q=id[r],ans=-1;
if(p==q)
{
for(long long i=l;i<=r;i++)if(a[i]+add[p]<c)ans=max(ans,a[i]+add[p]);
return ans;
}
else
{
for(long long i=p+1;i<=q-1;i++)ans=max(search(i,c-add[i])+add[i],ans);
for(long long i=l;i<=p*k;i++)if(a[i]+add[p]<c)ans=max(ans,a[i]+add[p]);
for(long long i=(q-1)*k+1;i<=r;i++)if(a[i]+add[q]<c)ans=max(ans,a[i]+add[q]);
return ans;
}
}
int main()
{
scanf("%lld",&n);
k=sqrt(n);
for(long long i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
id[i]=(i-1)/k+1;num[id[i]]++;
nei[id[i]][i-(id[i]-1)*k].val=a[i];
nei[id[i]][i-(id[i]-1)*k].p=i;
}
for(long long i=1;i<=id[n];i++)
{
sort(nei[i]+1,nei[i]+num[i]+1,cmp);
for(int j=1;j<=num[i];j++)d[nei[i][j].p]=j;
}
for(long long i=1;i<=n;i++)
{
scanf("%lld%lld%lld%lld",&op,&l,&r,&c);
if(op==0)adde();
else if(op==1)printf("%lld\n",ask());
}
return 0;
}
例题 :
有一个很显然的 BFS,对于每一个吸到的新磁力块,遍历序列,把所有它能吸到的磁力块加入一个队列进行扩展。这样时间复杂度是 ,不能通过。
考虑影响是否能吸到的两个因素,一个是利用 计算出的距离,另一个是质量 。对于这种问题,经典的做法是排序维护第一个变量,数据结构维护第二个变量。
由于本题需要取出可以吸到的磁力块入队,故 数据结构在本题中不好用。我们考虑分块。把所有磁力块按照距离升序排序,每 个元素分成一块。块内按照 升序排序,并记录距离的最大值。
当我们扩展一个磁力块时,从小到大遍历序列中的每一块。
对于一个最大距离小于等于吸引半径的块,所有磁力块均处于吸引半径之内。可以对于每一块记录一个 ,表示块中已经前 个磁力块已经被吸引。我们只需要利用 ,遍历到第 个元素,使这个元素的 大于当前吸力即可。由于 升序排序,所以这一块中所有可以被吸走的磁力块要么在之前被吸走,要么在这一次被吸走,满足条件。之后,令 。
对于第一个最大距离大于吸引半径的块,根据遍历顺序以及距离升序排序,之后的块中所有元素距离必然大于吸引半径,可以处理完这一块之后退出循环。这一块之中有的磁力块可以被吸走,有的磁力块不可以被吸走。我们暴力求出每一个能够吸走的磁力块,标记已经被吸走,之后排序重构。均衡复杂度之后为 ,可以通过。
事实上,可以继续优化。在处理第一个最大距离大于吸引半径的块时,我们不进行排序重构。改为在处理最大距离小于等于吸引半径的块时,如果遇到一个被吸走的磁力块,直接跳过到下一个。由于 升序排序,依旧满足要求。时间复杂度 。
#include <bits/stdc++.h>
using namespace std;
struct val
{
long long m,p,r;
double d;
}a[300000];
long long xq,yq,x,y,p,r,n,k,qp[300000],qr[300000],h=1,t=0,id[300000],la[300000],lc[300000],rc[300000],ans=-1;
double mx[300000];
bool cmp1(struct val a,struct val b)
{
return a.d<b.d;
}
bool cmp2(struct val a,struct val b)
{
return a.m<b.m;
}
double dist(long long x1,long long y1,long long x2,long long y2)
{
return sqrt((x1-x2)*(x1-x2)+(y1-y2)*(y1-y2));
}
void expand(long long p,long long r)
{
for(int i=1;i<=(n+k-1)/k;i++)
if(mx[i]<=r)
while(a[la[i]].m<=p&&la[i]<=rc[i])
{
if(a[la[i]].m!=-1e10)qp[++t]=a[la[i]].p,qr[t]=a[la[i]].r,a[la[i]].m=-1e10;
la[i]++;
}
else
{
la[i]=lc[i];
for(int j=lc[i];j<=rc[i];j++)
if(a[j].m!=-1e10&&a[j].m<=p&&a[j].d<=r)qp[++t]=a[j].p,qr[t]=a[j].r,a[j].m=-1e10;
break;
}
}
int main()
{
scanf("%lld%lld%lld%lld%lld",&xq,&yq,&p,&r,&n);
qp[++t]=p,qr[t]=r,k=sqrt(n);
for(int i=1;i<=n;i++)
{
scanf("%lld%lld%lld%lld%lld",&x,&y,&a[i].m,&a[i].p,&a[i].r);
a[i].d=dist(xq,yq,x,y);
}
sort(a+1,a+n+1,cmp1);
for(int i=1;i<=(n+k-1)/k;i++)lc[i]=1e10;
for(long long i=1;i<=n;i++)id[i]=(i-1)/k+1,lc[id[i]]=min(lc[id[i]],i),rc[id[i]]=max(rc[id[i]],i),mx[id[i]]=max(mx[id[i]],a[i].d);
for(int i=1;i<=(n+k-1)/k;i++)la[i]=lc[i],sort(a+lc[i],a+rc[i]+1,cmp2);
while(h<=t)ans++,expand(qp[h],qr[h]),h++;
printf("%lld\n",ans);
return 0;
}
后记
我发现自己其实有学习数据结构的天赋,别人平均 的题目我通过优化做到了 ,还是很有成就感的。
2022/3/31 省选前夜 22:33


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探