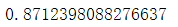课后作业——新闻文本分类
引言:
本次任务是做一个新闻文本分类的算法,算法选择朴素贝叶斯实现。可以实现对新闻内容的一个具体分类。
环境:jupter nookbook,py3.8
1.导入数据
df_new= pd.read_excel('./data/123.xlsx').astype(str) df_news=pd.DataFrame(df_new) df_news.head()

2.用jieba分词进行分词
content_S = [] for line in content: current_segment = jieba.lcut(line) if len(current_segment) > 1 and current_segment != '\r\t': content_S.append(current_segment)
content_S[1000]

3.加载停用词,并遍历去除停用词
def drop_stopwords(contents,stopwords): contents_clean = [] all_words = [] for line in contents: line_clean = [] for word in line: if word in stopwords or word==' ': continue line_clean.append(word) all_words.append(word) contents_clean.append(line_clean) return contents_clean,all_words contents = df_content.content_S.values.tolist() stopwords = stopwords.stopword.values.tolist() contents_clean,all_words = drop_stopwords(contents,stopwords)
df_content = pd.DataFrame({'contents_clean':contents_clean})
df_content.head()

4.提取关键词
import jieba.analyse index = 2500 print(df_news['content'][index]) content_S_str = ''.join(content_S[index]) print(' '.join(jieba.analyse.extract_tags(content_S_str,topK=10,withWeight=False)))

5.lab向量化
df_train = pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
df_train.tail()
df_train.label.unique()
6.使用sklearn模型训练数据集
from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(df_train['contents_clean'].values,df_train['label'].values,random_state = 1) print(x_test) from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer(analyzer='word',max_features=4000,lowercase=False,ngram_range=(1,3)) vec.fit(words) cv=vec.fit_transform(words) from sklearn.naive_bayes import MultinomialNB classifier = MultinomialNB() classifier.fit(vec.transform(words),y_train) test_words = [] for line_index in range(len(x_test)): try: #x_train[line_index][word_index] = str(x_train[line_index][word_index]) test_words.append(' '.join(x_test[line_index])) except: print (line_index,word_index)
7.算法准确率
classifier.score(vec.transform(test_words),y_test)