Mapreduce实战-求每年最高气温
1.项目文件:
2014010114
2014010216
2014010317
2014010410
2014010506
2012010609
2012010732
2012010812
2012010919
2012011023
2001010116
2001010212
2001010310
2001010411
2001010529
2013010619
2013010722
2013010812
2013010929
2013011023
2008010105
2008010216
2008010337
2008010414
2008010516
2007010619
2007010712
2007010812
2007010999
2007011023
2010010114
2010010216
2010010317
2010010410
2010010506
2015010649
2015010722
2015010812
2015010999
2015011023
2.源代码


import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Temperature { /** * 四个泛型类型分别代表: * KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...) * ValueIn Mapper的输入数据的Value,这里是每行文字 * KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份” * ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温” */ static class TempMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 打印样本: Before Mapper: 0, 2000010115 System.out.print("Before Mapper: " + key + ", " + value); String line = value.toString(); String year = line.substring(0, 4); int temperature = Integer.parseInt(line.substring(8)); context.write(new Text(year), new IntWritable(temperature)); // 打印样本: After Mapper:2000, 15 System.out.println( "======" + "After Mapper:" + new Text(year) + ", " + new IntWritable(temperature)); } } /** * 四个泛型类型分别代表: * KeyIn Reducer的输入数据的Key,这里是每行文字中的“年份” * ValueIn Reducer的输入数据的Value,这里是每行文字中的“气温” * KeyOut Reducer的输出数据的Key,这里是不重复的“年份” * ValueOut Reducer的输出数据的Value,这里是这一年中的“最高气温” */ static class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; StringBuffer sb = new StringBuffer(); //取values的最大值 for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); sb.append(value).append(", "); } // 打印样本: Before Reduce: 2000, 15, 23, 99, 12, 22, System.out.print("Before Reduce: " + key + ", " + sb.toString()); context.write(key, new IntWritable(maxValue)); // 打印样本: After Reduce: 2000, 99 System.out.println( "======" + "After Reduce: " + key + ", " + maxValue); } } public static void main(String[] args) throws Exception { //输入路径 String dst = "hdfs://localhost:9000/intput.txt"; //输出路径,必须是不存在的,空文件加也不行。 String dstOut = "hdfs://localhost:9000/output"; Configuration hadoopConfig = new Configuration(); hadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName() ); hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName() ); Job job = new Job(hadoopConfig); //如果需要打成jar运行,需要下面这句 //job.setJarByClass(NewMaxTemperature.class); //job执行作业时输入和输出文件的路径 FileInputFormat.addInputPath(job, new Path(dst)); FileOutputFormat.setOutputPath(job, new Path(dstOut)); //指定自定义的Mapper和Reducer作为两个阶段的任务处理类 job.setMapperClass(TempMapper.class); job.setReducerClass(TempReducer.class); //设置最后输出结果的Key和Value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //执行job,直到完成 job.waitForCompletion(true); System.out.println("Finished"); } }
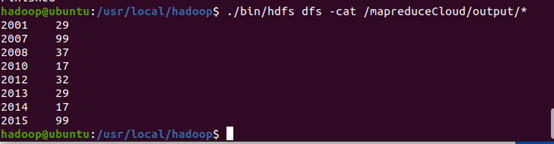
3.运行页面