

CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建
前期准备
1.配置hostname(可选,了解)
在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(pretty)。“静态”主机名也称为内核主机名,是系统在启动时从/etc/hostname自动初始化的主机名。“瞬态”主机名是在系统运行时临时分配的主机名,例如,通过DHCP或mDNS服务器分配。静态主机名和瞬态主机名都遵从作为互联网域名同样的字符限制规则。而另一方面,“灵活”主机名则允许使用自由形式(包括特殊/空白字符)的主机名,以展示给终端用户(如Linuxidc)。
在CentOS7以前,配置主机的静态hostname是在/etc/sysconfig/network中配置HOSTNAME字段值来配置,而CentOS7之后若要配置静态的hostname是需要在/etc/hostname中进行。
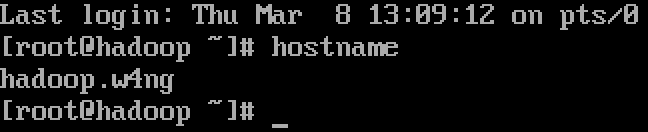
进入Linux系统,命令行下输入hostname可以看到当前的hostname,而通常默认的hostname是local.localadmin。
本次试验环境在CentOS7下,所以我们编辑/etc/hostname文件,试验hostname为:hadoop.w4ng,填入其中,重启Linux,可以看到已经生效。
2.配置静态IP
同样,在CentOS7以后,其网卡配置已经有原先的/etc/sysconfig/network/network-scripts下面的ifcfg-eth0等改名为乐ifcfg-enpXsY(en表示ethnet,p表示pci设备,s表示soket)

本人这里有两个ifcfg文件是因为配置了两块网卡分别做NAT以及与虚拟机Host-Only两个功能,实现双网卡上网
打开ifcfg-enp0s8,配置如下:
DEVICE=enp0s8 #设备名
HWADDR=08:00:27:10:6B:6B #硬件地址
TYPE=Ethernet #类型
BOOTPROTO=static #静态IP(必备)
IPADDR=192.168.56.88 #IP地址
NETMASK=255.255.255.0 #子网掩码
ONBOOT=yes #设备开机自动启动该网卡
3.配置hosts
打开/etc/hosts
配置为如下的:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.88 hadoop.w4ng
配置hosts的理由是后期hadoop配置中相关的主机填写我们都是使用域名的形式,而IP地址与域名的转换在这里进行查询(还有DNS,但是这里不讨论)。
4.关闭防火墙
CentOS7与6的防火墙不一样。在7中使用firewall来管理防火墙,而6是使用iptables来进行管理的。当然,我们可以卸载7的firewall安装6的iptables来管理。本人就切换回了6的防火墙管理方式。
[root@localhost ~]#servcie iptables stop # 临时关闭防火墙
[root@localhost ~]#chkconfig iptables off # 永久关闭防火墙
5.JDK与Hadoop的安装
下载JDK8
下载Hadoop3-binary
下载完毕将文件传到主机中。
在/usr/local/下创建java文件夹,并将JDK解压至该文件夹下。
在根目录下创建/bigdata文件夹,并将Hadoop解压至其中。
解压命令 tar -zxv -f [原压缩文件.tar.gz] -C [目标文件夹目录] # 实际命令没有中括号,其次,命令参数重-z对应gz压缩文件,若为bz2则使用-j
在JDK解压完成后,在~/.bash_profile中配置环境变量 点这里看/etc/bashrc、/.bashrc、/.bash_profile关系
export JAVA_HOME=/usr/local/java/jdkx.x.x_xxx
export PATH=$PATH:$JAVA_HOME/bin
配置完成,保存退出并 source ~/.bash_profile
hadoop无需配置环境变量
6.配置hadoop
在hadoop的home下,进入etc文件夹,有五个主要的文件需要进行配置:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
基本配置如下
1.配置 hadoop-env.sh
export JAVA_HOME
#找到该处,填写上上面配置的JAVA_HOME,因为hadoop是基于Java的,需要Java的环境
2.配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hostnameXXX:9000</value>
</property>
<!-- 配置hadoop文件系统目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigData/tmp</value>
</property>
</configuration>
3.配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.配置 yarn-site.xml
<configuration>
<property>
<name>yarn.resourecemanager.hostname</name>
<value>hostnameXXX</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
然后配置相关服务启动过程中需要的配置变量:
进入${HADOOP_HOME}/sbin中,在start-dfs.sh与stop-dfs.sh中添加字段:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh与stop-yarn.sh中添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置完成以后,进行hadoop的文件系统格式化,执行
${HADOOP_HOME}/bin/hdfs namenode -format
最后是启动服务:
执行${HADOOP_HOME}/sbin/start-all.sh # 他会去调用start-dfs.sh与start-yarn.sh
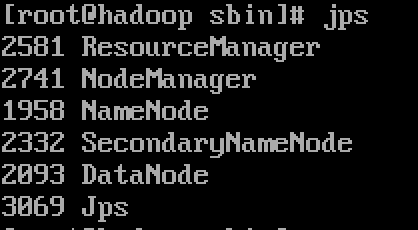
根据配置中我们都是配置的root用户,显然需要我们以root身份进行,且过程中需要root密码。当然,通过ssh免密可以方便很多。启动完成以后,命令行中使用jps命令打印Java进程,会看到下图五个进程(忽略Jps进程):
当然,Hadoop在服务启动以后以提供web端:
visit hdfs manage page
xxx.xxx.xxx.xxx:50070
visit yarn manage page
xxx.xxx.xxx.xxx:8088


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!