分布式日志搜集ELK
分布式日志搜集ELK
- github项目地址
- ELK是ElasticSearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被称为Elastic Stack。其中ElasticSearch是一个基于Lucene、分布式、通过RESTful方式进行交互的接近实时搜索平台框架。类似谷歌、百度这种大数据全文搜索引擎的场景都可以使用ElasticSearch作为底层支持框架,可见ElasticSearch提供的搜索能力确实强大,世面上很多时候我们简称ElasticSearch为es。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的的(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能
- 市面上很多开发只要提到ELK能够一直说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具代表性,并非唯一性
- 收集清洗数据---搜索,存储---Kibana
ElasticSearch
Lucene简介
概述
- Lucene是一套信息检索工具包,是jar包。不包含搜索引擎!包含索引结构、读写索引的工具、排序、搜索规则......(Solr)
- Java编写,目标是为各种中小型应用软件加入全文检索功能
与ElasticSearch关系
- ElasticSearch 是基于Lucene 做了一些封装和增强
ElasticSearch简介
概述
- ElasticSearch,简称es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,它可以扩展到上百台服务器,处理PB级别的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
- 据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过
谁在使用
- 维基百科,全文检索、高亮、搜索推荐(权重)
- 新闻网站,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对***新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他们知道他的文章的公众反馈(好文、水文、热门)
- Stack Overflow(国外程序员异常讨论论坛)
- Github(开源代码管理),搜索上千亿行代码
- 电商网站,检索商品
- 日志数据分析,logstash采集日志,ES进行复制的数据分析,ELK技术(ElasticSearch+logstash+Kibana)
- 商品价格监控网站,用户设定某商品价格的阈值,当低于该阈值时,发送通知消息给用户
- BI系统,商业智能,Business Intelligence。比如某大型商场,BI 分析一下某区域最近3年的用户消费金额的趋势以及用户群体的组成结构,产出相关的数据报表,ES执行数据分析与挖掘,kibana进行数据可视化
- 国内:站内搜索(电商、招聘、门户等等),IT系统搜索(OA、CRM、ERP等等),数据分析(ES热门的一个使用场景)
Solr和ES的差别
ElasticSearch简介
- ElasticSearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能
- 它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
- 维基百科使用ElasticSearch提供全文搜索并高亮关键字,以及输入实时搜索(Search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能
- 英国卫报使用ElasticSearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应
- Stack Overflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案
- Github使用ElasticSearch检索1300亿行代码
- ElasticSearch是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库
- 但Lucene只是一个库,想要使用它,你必须使用java代码来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的
- ElasticSearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
Solr简介
- Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器,Solr提供了比Lucene更为丰富的查询语言,同时实现可配置、可扩展、并对索引、搜索性能进行了优化
- Solr 可以独立运行,运行在jetty、tomcat等这些Servlet容器中,Solr索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据XML文档添加、删除、更新索引。Solr搜索只需要发送HTTP GET请求,然后通过对Solr返回XML、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况
- Solr是基于Lucene开发企业级搜索服务器,实际上就是封装了Lucene
- Solr是一个独立的企业级搜索应用服务器,它是对外提供类似Web-Service的API接口,用户可以通过http请求,想搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果
ElasricSearch和Solr比较
- 当单纯的对已有数据进行搜索时,Solr更快
- 当实时建立索引时,Solr会产生IO阻塞,查询性能较差,ElasticSearch具有明显的优势
- 随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化
- 转变我们的搜索基础设施后,从Solr ElasticSearch,可以发现~50倍提高搜索性能
ElasticSearch vs Solr总结
- es基本开箱即用,非常简单。Solr安装略微复杂一点点
- Solr利用Zookeeper进行分布式管理 ,而ElasticSearch自身带分布式协调管理功能
- Solr支持更多格式的数据,比如JSON、XML、CSV,而ElasticSearch仅支持json文件格式
- Solr官方提供的功能更多,而ElasticSearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要Kibana友好支撑
- Solr查询更快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用
- ES建立索引快(即查询慢),实时性查询快,用于Facebook、新浪等搜索
- Solr是传统搜索应用的有力解决方案,但ElasticSearch更适用于新兴的实时搜索应用
- Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而ElasticSearch相对开发维护这较少,更新太快,学习使用成本较高
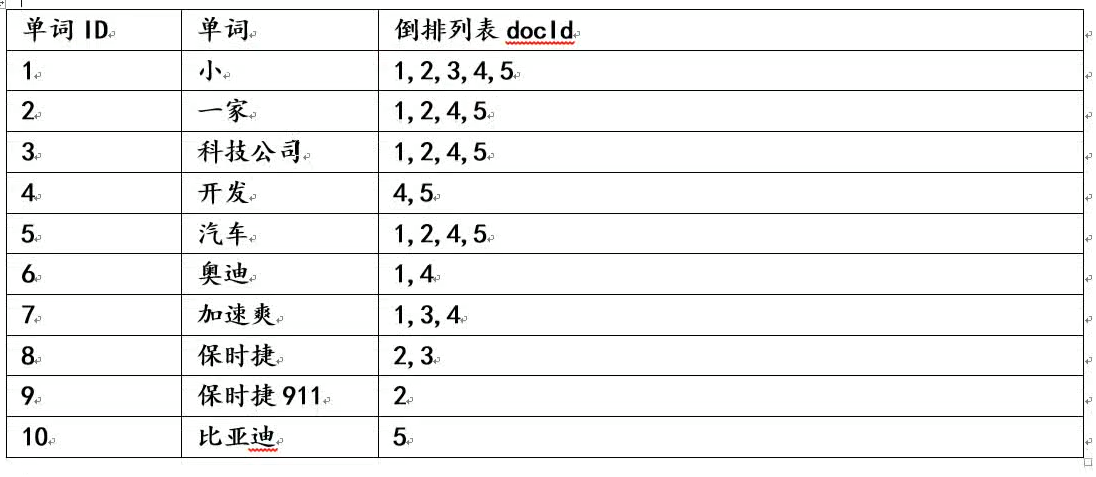
倒排索引(*)
-
传统检索 正排索引 全文检索:倒排索引
-
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)
-
倒排索引有两种不同的反向索引形式:
- 一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表
- 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置
-
如下例所示:

倒排索引会对以上文档内容进行关键字分词,可以使用关键词直接定位到文档内容
ElasticSearch安装
- 声明:JDK1.8,最低要求!ElasticSearch客户端,界面工具
- Java开发,ElasticSearch的版本和我们之后对应的java的核心jar包!版本对应,JDK环境是正常的
下载
安装ES
windows环境
-
解压
-
目录文件
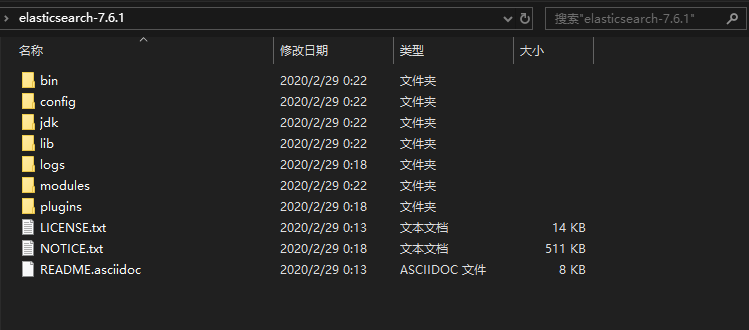
- bin 启动文件
- config 配置文件
- log4j2 日志配置文件
- jvm options java虚拟机相关的配置(默认需要1G内存)
- elasticsearch.yml elasticsearch的配置文件(默认端口9200等)
- lib 相关jar包
- logs 日志
- modules 功能模块
- plugins 插件(*)
Linux环境
-
tar.gz 安装包解压
tar -zxvf ***.tar.gz -
默认情况下 ES不支持ip访问,修改config下的elasticsearch.yml
network.host: 192.168.83.133 cluster.initial_master_nodes: ["node-1", "node-2"] -
安装包启动方式需要额外配置参数
-
修改文件句柄的限制
##修改限制 sudo vi /etc/sysctl.conf ##查看是否生效 sudo sysctl -p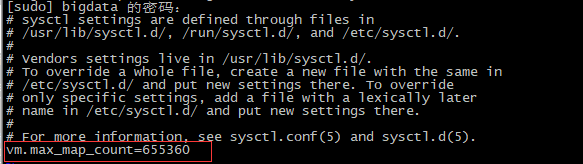
-
每个进程最大同时打开文件数太小,修改打开文件数的大小
sudo vi /etc/security/limits.conf添加内容
* soft nproc 4096 * hard nproc 4096 * soft nofile 65536 * hard nofile 65536##通过命令查看软限制大小 ulimit -Sn ##通过命令查看硬限制大小 ulimit -Hn -
重启电脑后,再重启ElasticSearch
-
启动ES
-
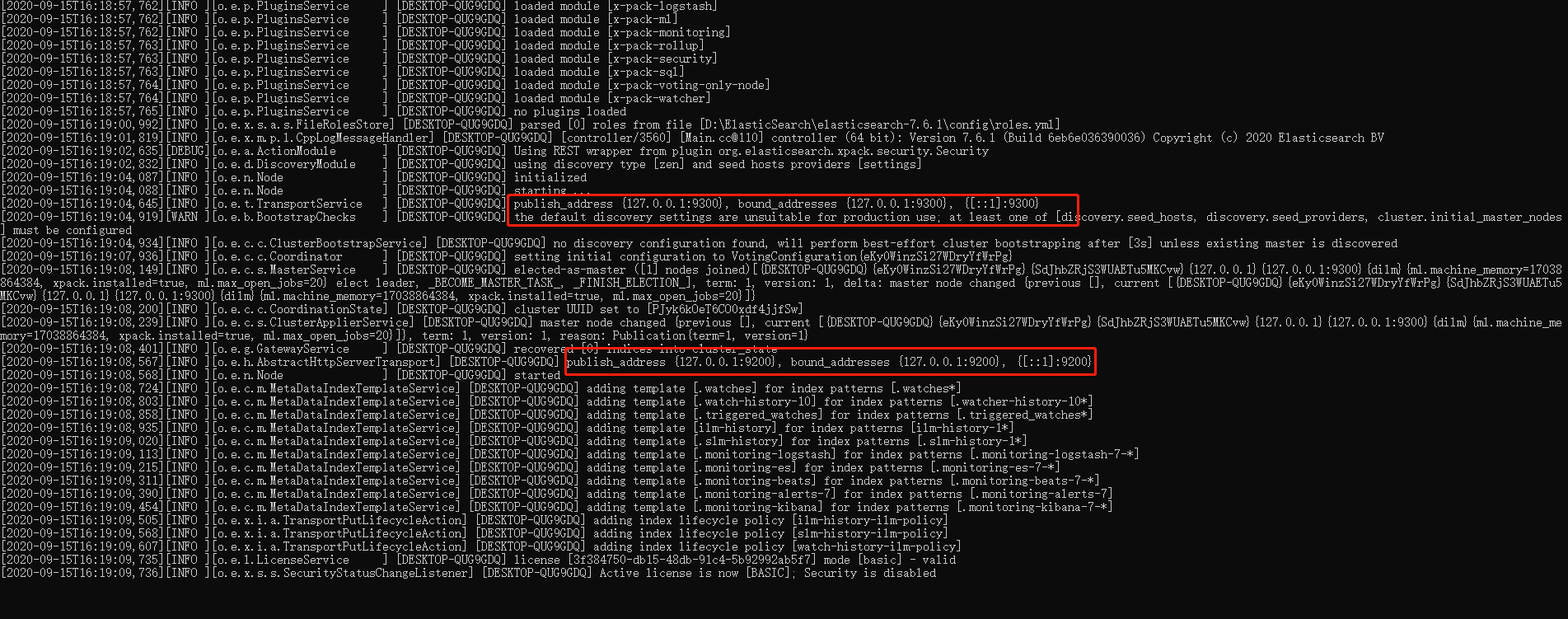
双击elasticsearch.bat 启动ElasticSearch
-
默认对外暴露的端口9200
-
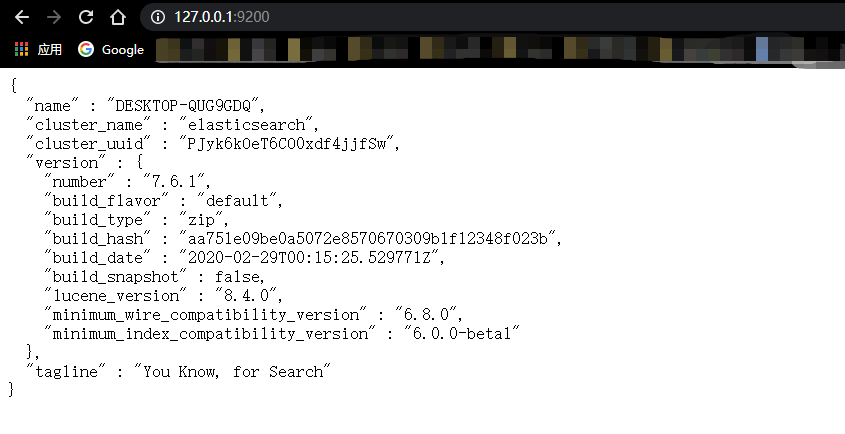
访问浏览器 127.0.0.1:9200
安装可视化界面Head
下载地址
-
需要有node环境
编译运行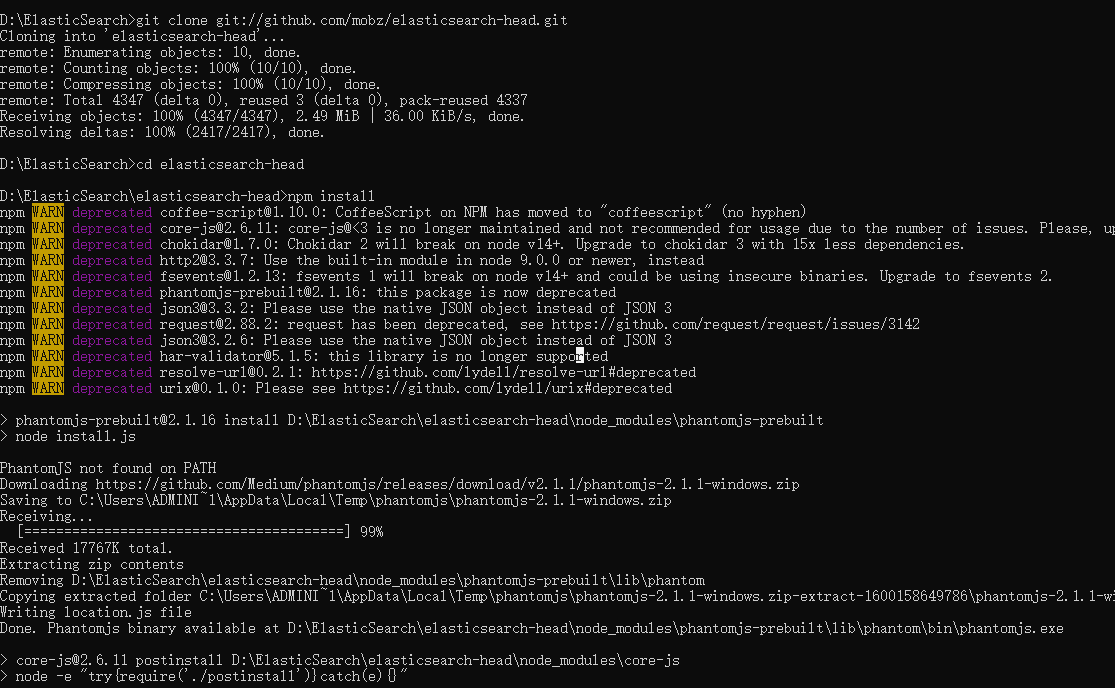

-
访问9100,出现跨域问题,导致未连接到9200
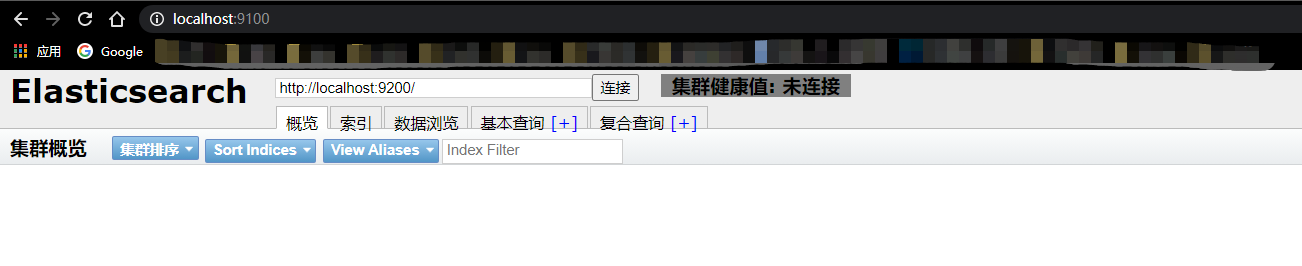
-
解决跨域问题 elasticsearch.yml添加如下配置
http.cors.enabled: true http.cors.allow-origin: "*"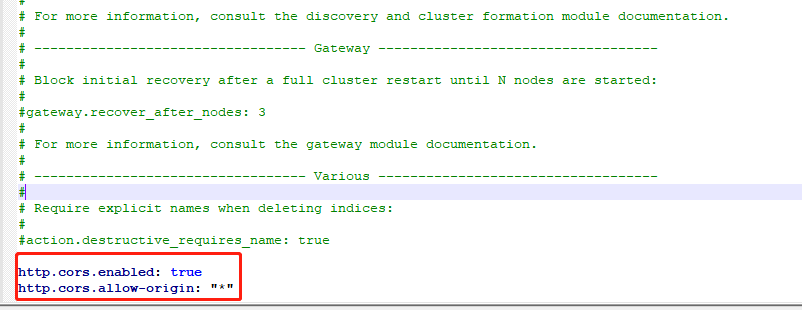
- 重启ElasticSearch

-
初学者,可以先把es看成一个数据库,可以建立索引(表),文档(表中的数据)
head 把它当做一个数据展示工具。后续所有的查询都在Kibana做
Kibana
Kibana简介
- Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解,它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就能完成Kibana安装与启动ElasticSearch索引监测
Kibana安装
下载
安装
windows环境
-
解压
-
是一个标准的工程 bin/kibana.bat
Linux环境
-
解压kibana-7.6.1-linux-x86_64.tar.gz
-
修改相关配置:vim kibana.yml

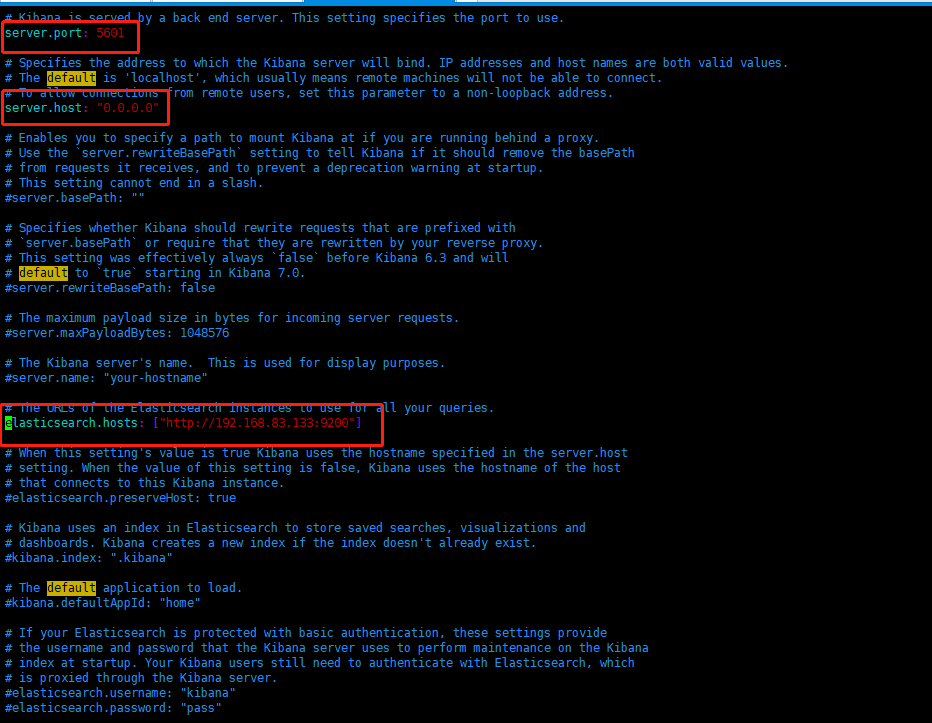
-
cd /usr/local/elk/kibana-7.6.1-linux-x86_64/bin/ #启动 ./kibana --allow-root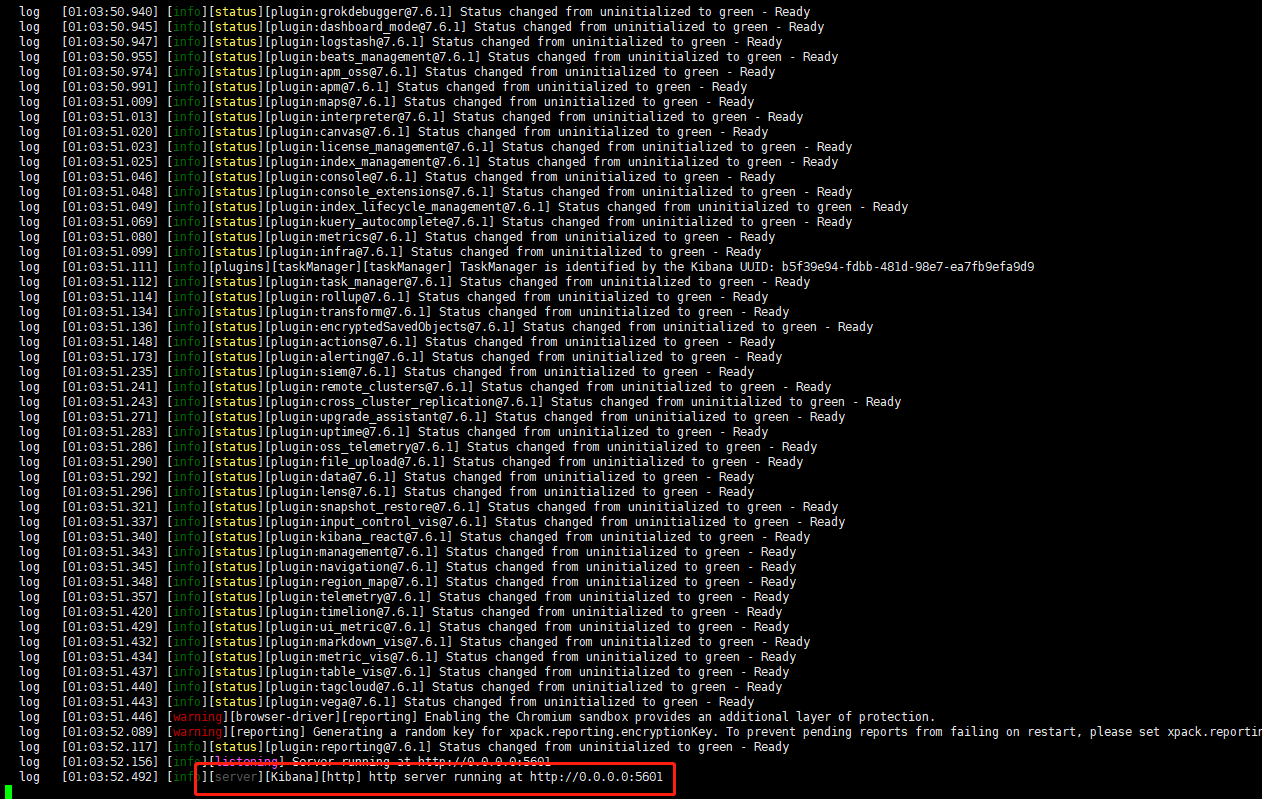
启动Kibana
-
bin/kibana.bat 双击
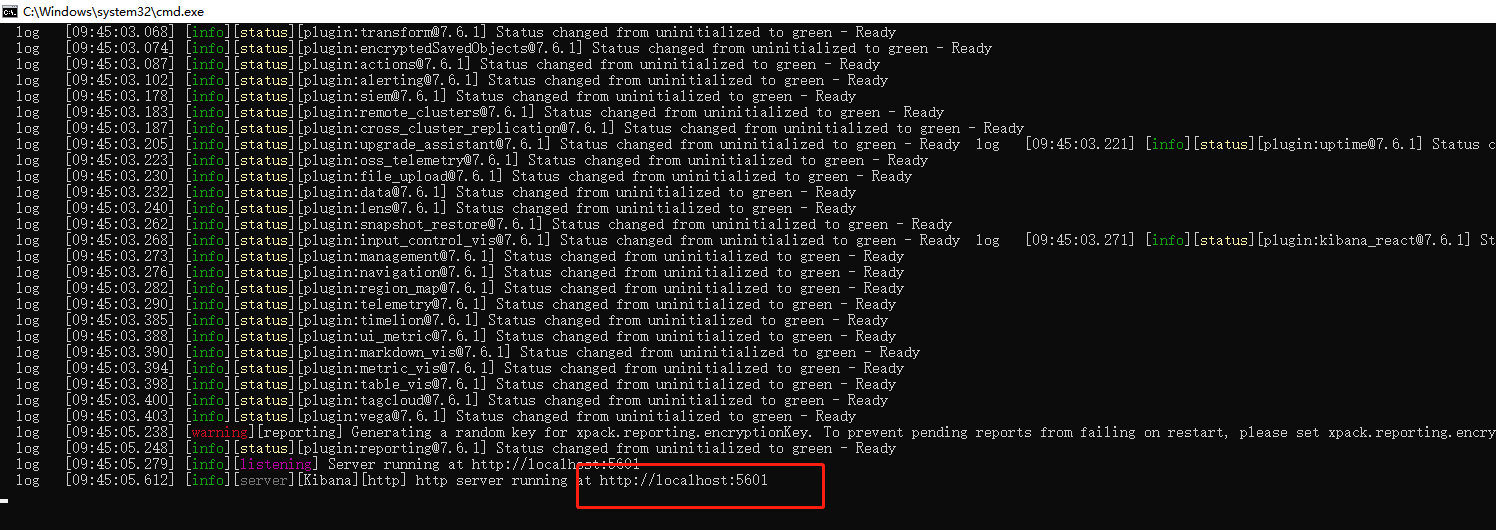
-
-
开发工具
-
PostMan
-
curl
-
head
-
谷歌浏览器插件测试(支持汉化)
之后的所有操作都在这里进行操作
-
ES核心概念
概述
- 上面内容已经知道es是什么,同时也把es的服务已经安装启动,那么es是如何存储数据,数据结构是什么,又是如何实现搜索的呢?
ES的相关概念
-
集群
-
节点
-
分片
-
节点和分片是如何工作的
-
一个集群至少有一个节点,而一个节点就是一个es的进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
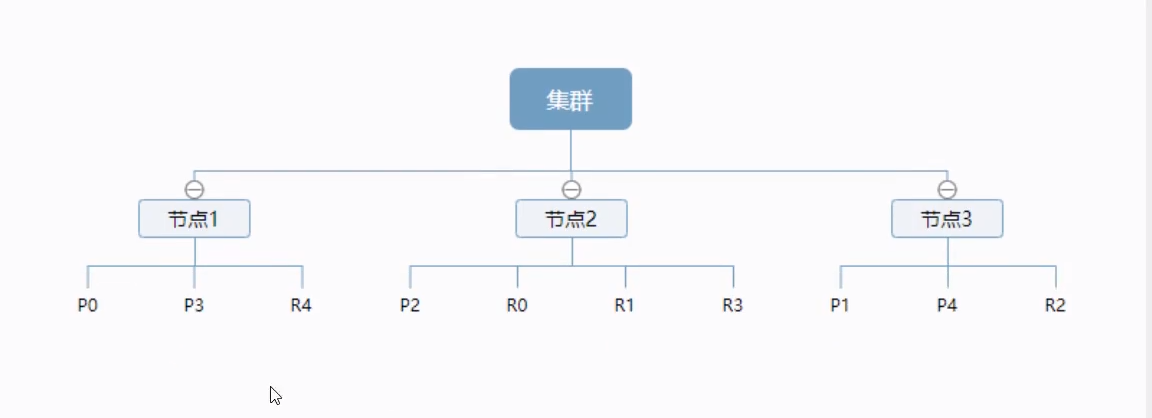
-
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样即使某个节点挂了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得es在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
-
倒排索引
es使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
Study every day,good good up to forever #文档1包含的内容 To forever,study every day,good good up #文档2包含的内容为了创建倒排索引,将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
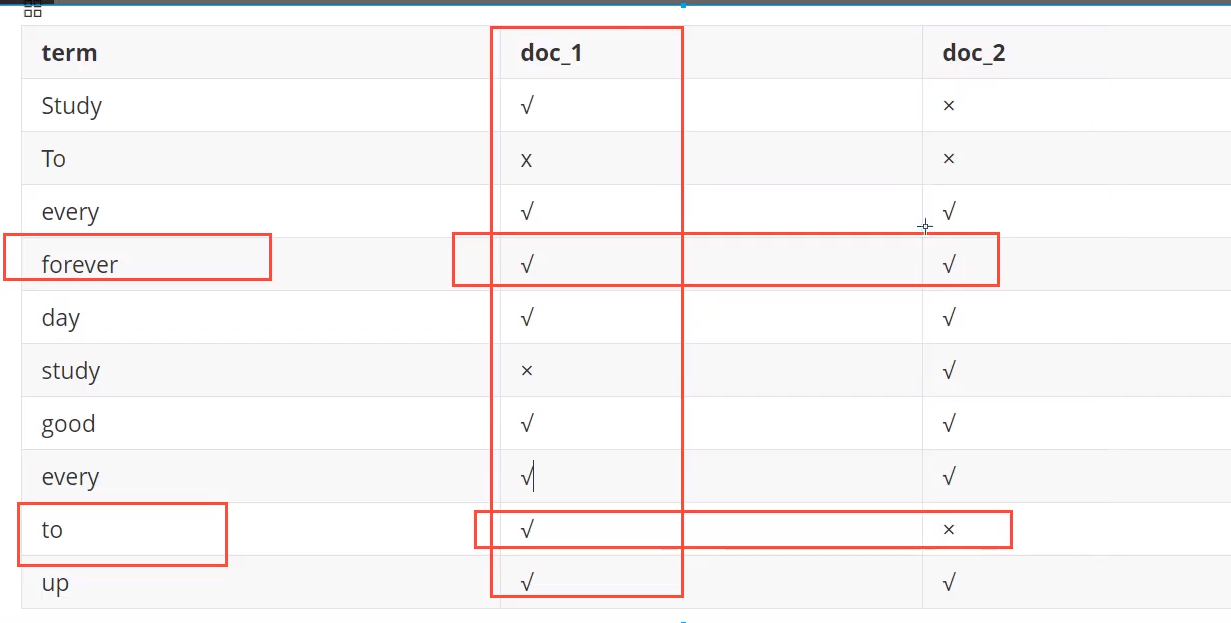
现在我们试图搜索 to forever ,只需要查看包含每个词条的文档

-
再来一个示例,比如我们通过博客标签来搜索博客文章,那么倒排索引列表就是这样的一个结构:
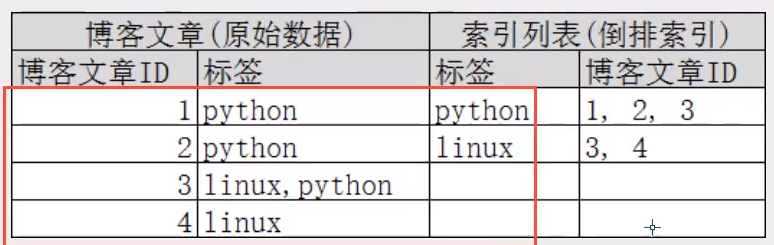
- ·如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快得多。只需要查看标签这一栏,然后获取相关的文章ID即可,完全过滤掉无关的所有数据 ,提高效率
-
elasticsearch的索引和Lucene的索引对比
- 在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的
-
-
-
索引
- 就是数据库
- 索引是映射类型的容器,es中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上
-
类型
- 类型是文档的逻辑容器。就像关系型数据库一样,表是行的容器,类型中对于字段的定义称为映射,比如name映射为字符串类型
-
文档
- 之前说es是面向文档的,那么就意味着索引和搜索数据的最小单位是文档。es中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,在关系型数据库中需要预先定义字段才能使用,在es中,对于字段是非常灵活的,有时候可以忽略该字段,或者动态的添加一个新的字段
- 尽管我们可以随意的新增或者忽略某个字段,但是,每个字段类型非常重要。比如一个年龄字段类型,可以是字符串类型也可以是整数型。因为ES会保存字段和类型之间的映射以及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也被称为映射类型
- 之前说es是面向文档的,那么就意味着索引和搜索数据的最小单位是文档。es中,文档有几个重要属性:
-
映射
MySQL和ElasticSearch对比
elasticsearch是面向文档,关系型数据库与elasticsearch的客观对比
| MySQL | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | document |
| 字段(columns) | field |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档又包含多个field(列)
物理设计
- elasticsearch在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移
逻辑设计
- 一个索引类型中,包含多个文档,比如说文档1,文档2.当我们索引一篇文档时,可以通过这样的顺序找到它:索引>>类型>>文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串
9200与9300区别
- 9300端口:ES节点之间通讯使用
- 9200端口:ES节点和外部通讯使用
- 9300是TCP协议端口号,ES集群之间的通讯端口号。9200暴露ES RESTful接口的端口号
IK分词器插件
是什么
- 分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱编程”会被分为 “我”、“爱”、“编”、“程”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题
- IK提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word 为最细颗粒度划分
IK分词器安装
下载
Windows安装
- 解压下载的文件
- 在es的plugins目录下新建文件夹ik
- 将解压的文件放入ik文件夹中
Linux安装
-
跟windows基本一致
-
将解压后的 重新命名为ik的文件夹拷贝至 plugins文件夹下

重启观察ES
-
看到ik分词器插件被加载
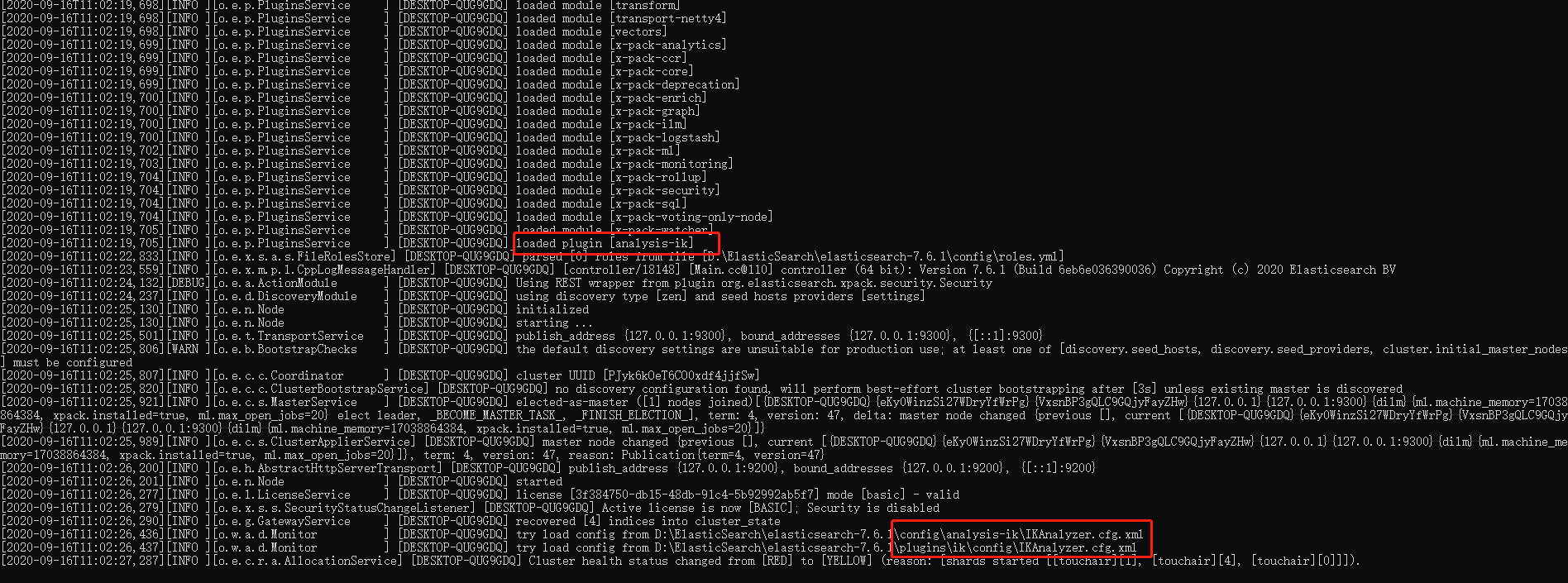
-
elasticsearch-plugin list 命令

Kibana中测试IK分词器
-
kibana Dev Tools
-
ik_smart (最少切分)
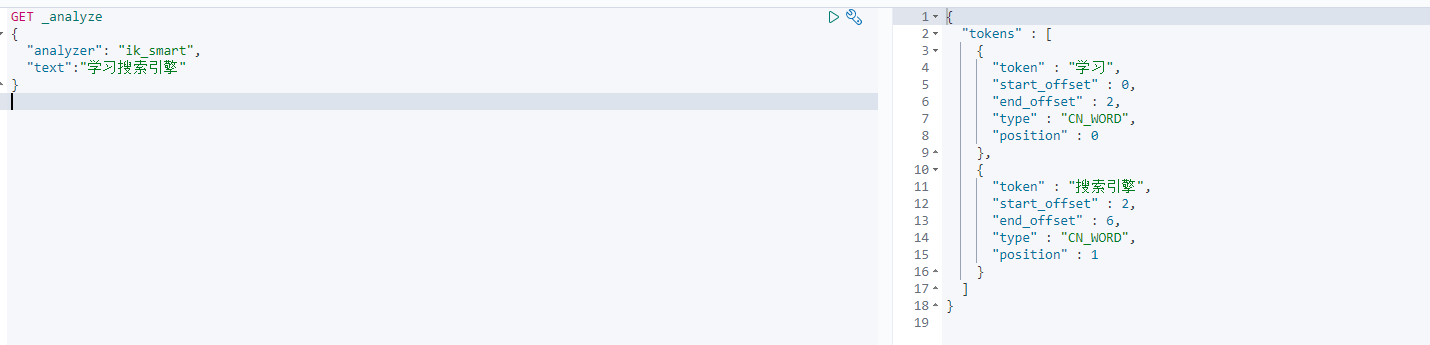
-
ik_max_word(最细粒度划分)
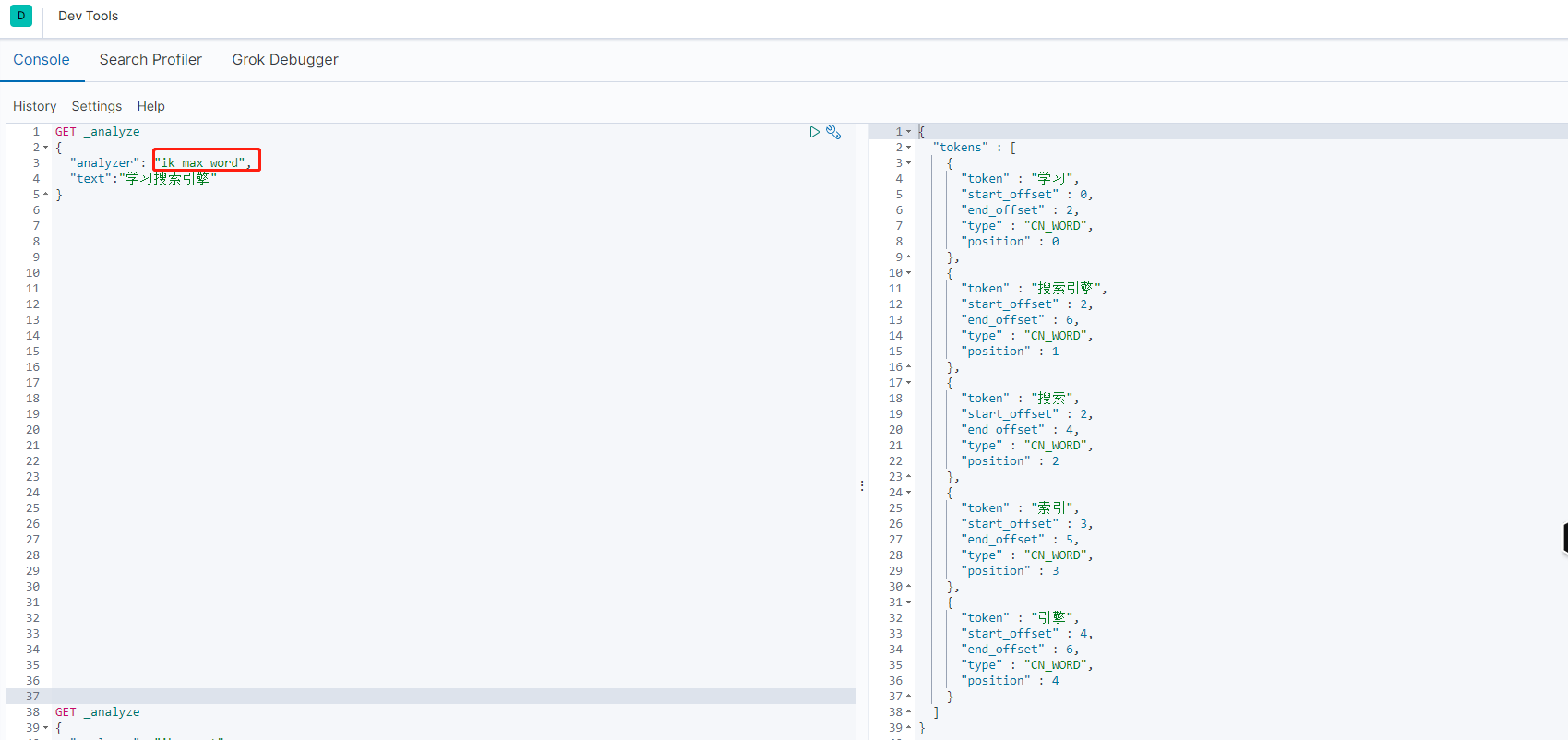
-
-
发现问题:需要组合在一起的词,可能会被拆分开。这种个性化的词,需要我们自己加到分词器的字典中
IK分词器增加自己的配置
-
ik/config/IKAnalyzer.cfg.xml
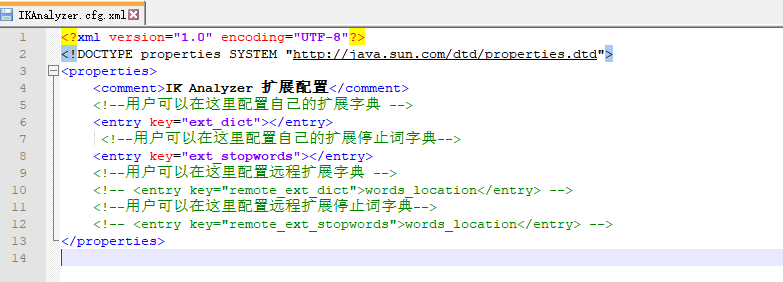
-
新增自定义字典touchair,并注入扩展配置中,然后重启ES
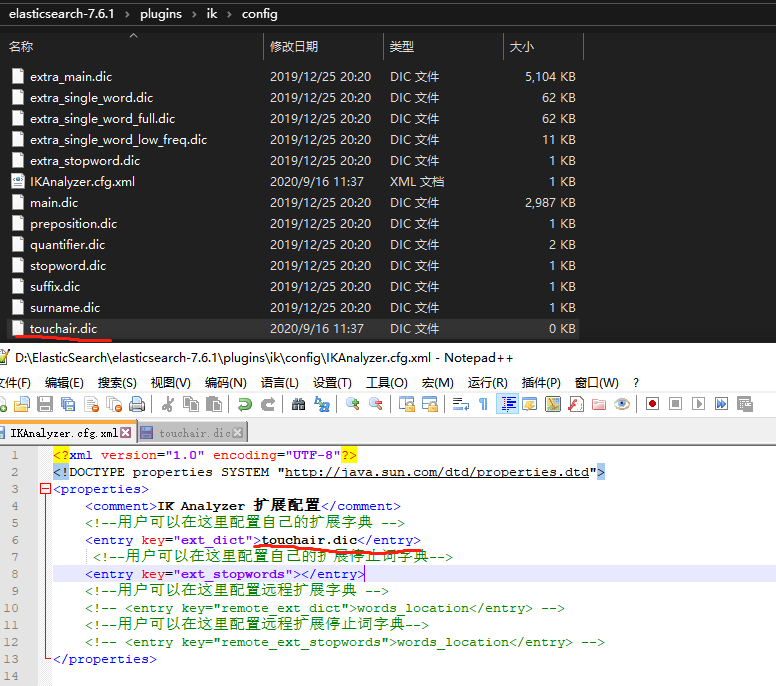
-
观察启动日志,发现加载了touchair.dic ,现在再次测试分词效果
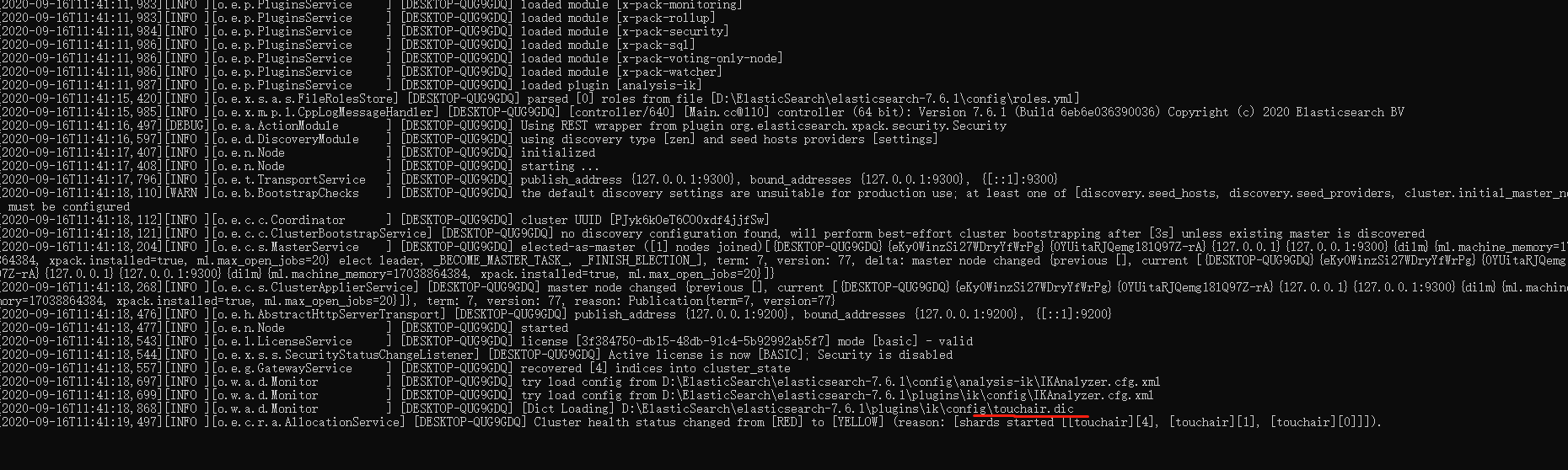
-
测试结果
- 添加自定义字典前:触达被拆分为触、达
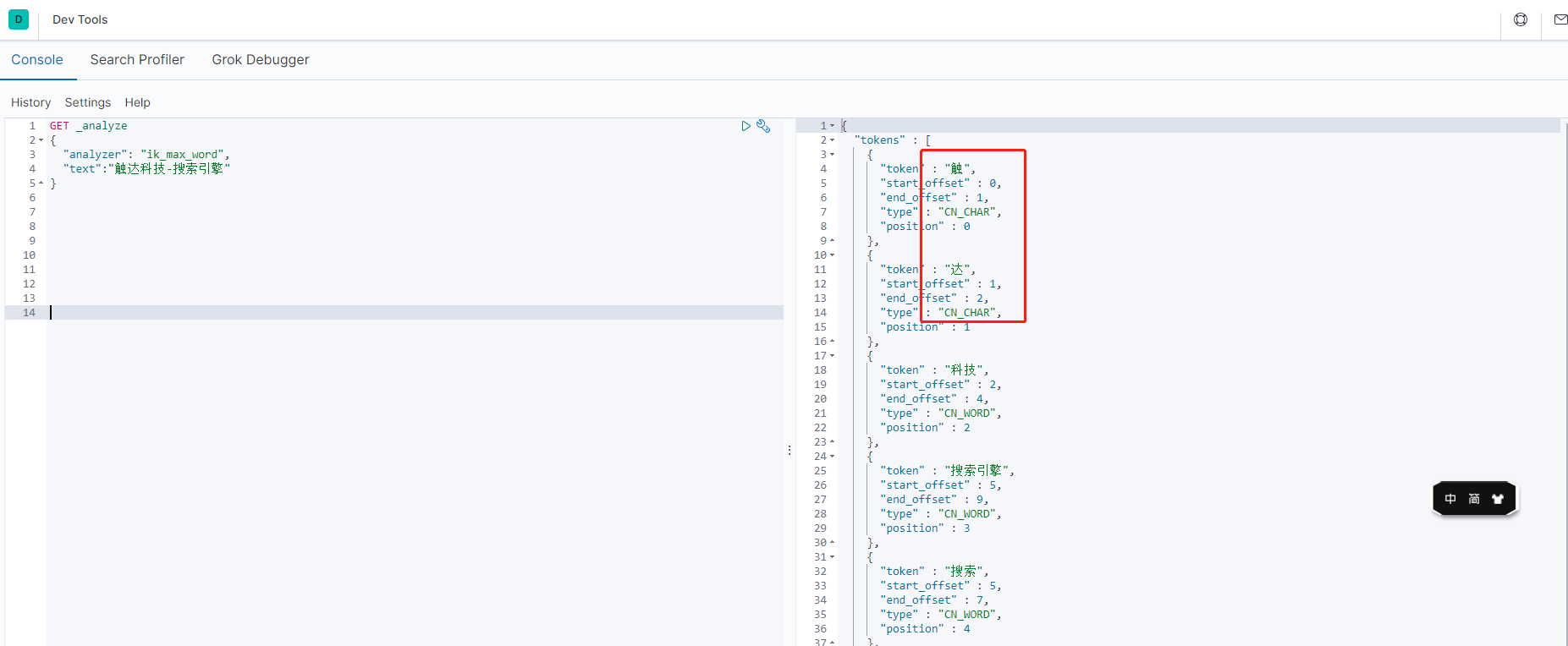
- 配置后,可以拆分成自己想要的结果
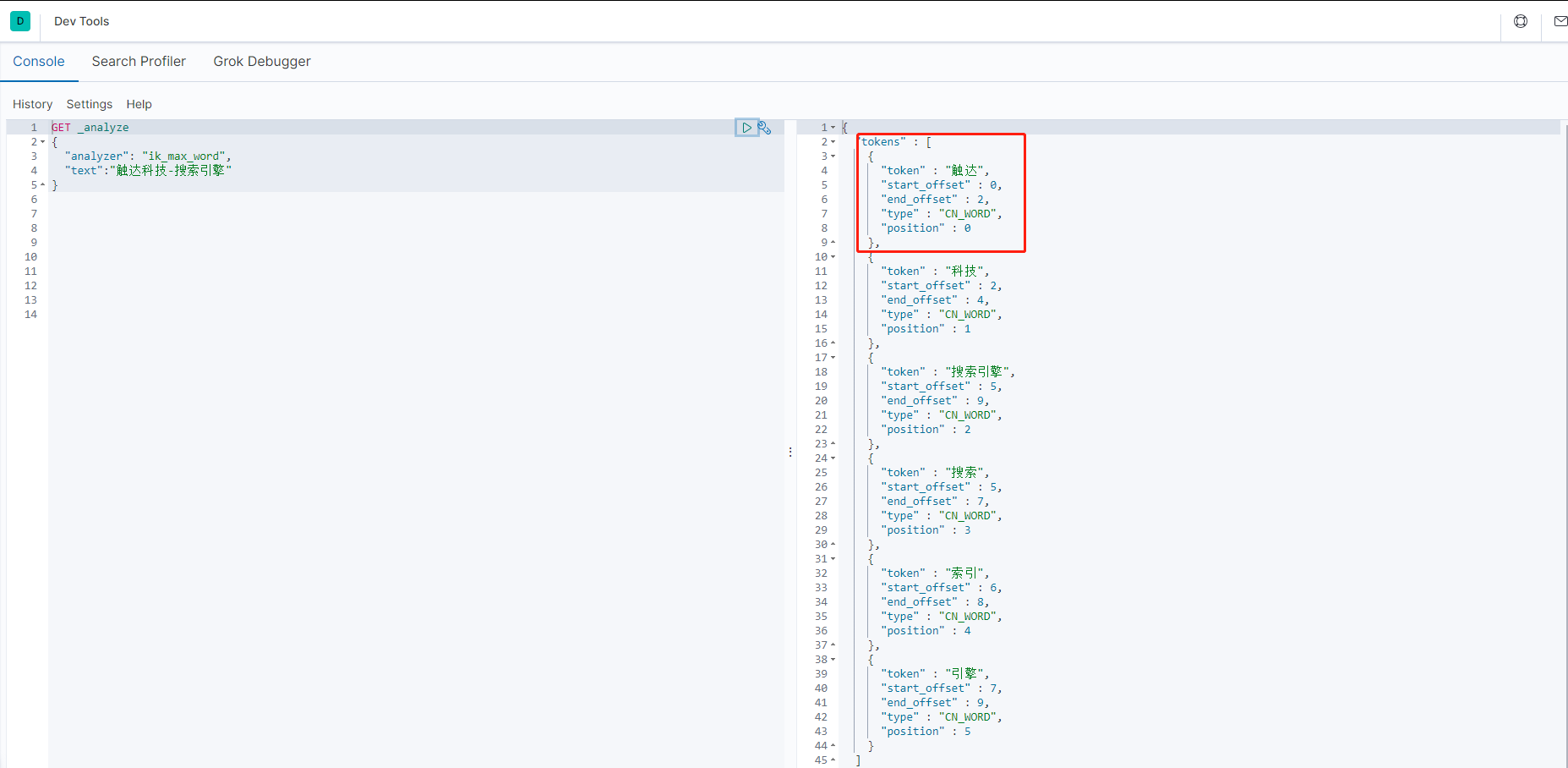
- 添加自定义字典前:触达被拆分为触、达
-
REST风格说明
-
一种软件架构风格,而不是标准,只是提供一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制
-
基本REST命令说明:
methood url 描述 PUT localhost:9200/索引名称/类型名称/文档id 创建文档(指定文档id) POST localhost:9200/索引名称/类型名称 创建文档(随机文档id) POST localhost:9200/索引名称/类型名称/文档id/_update 修改文档 DELETE localhost:9200/索引名称/类型名称/文档id 删除指定文档 GET localhost:9200/索引名称/类型名称/文档id 查询文档通过文档id POST localhost:9200/索引名称/类型名称/_search 查询所有数据
索引基本操作
-
创建一个索引(POST)
PUT /索引名/~类型名~/文档id {请求体}
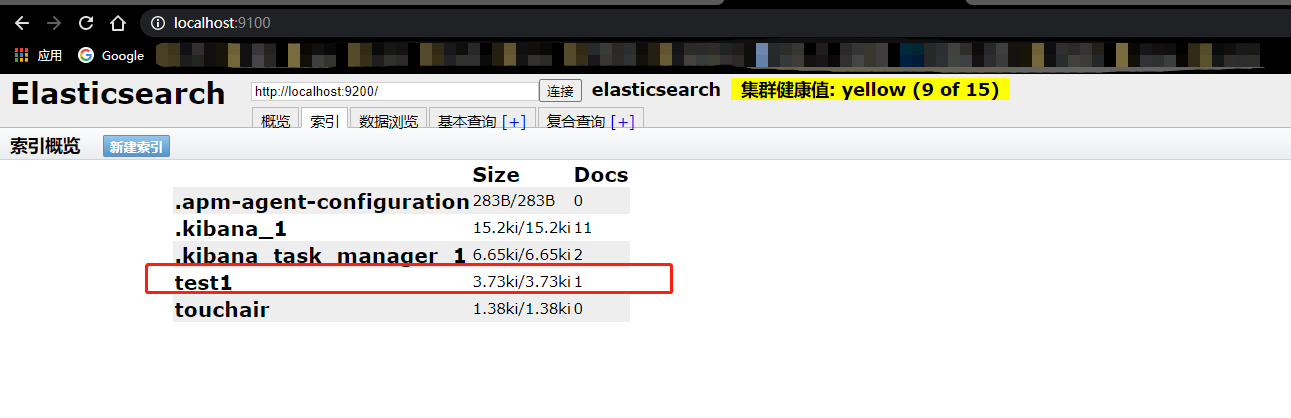
创建索引的同时,插入了一条数据

文档映射
-
动态映射:在关系型数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称为动态映射
-
静态映射:在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射
-
类型分类:
-
字符串类型:text、keyword
text类型会被分词器分割keyword不会被分割 -
数值类型:long、integer、short、byte、double、float、half、scaled、
-
日期类型:date
-
布尔值类型:boolean
-
二进制类型:binary
-
数组类型:array
-
复杂类型
- 地理位置类型(Geo datatypes)
- 地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标
- 地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状
- 特定类型(Specialised datatypes)
- Pv4 类型(IPv4 datatype):ip 用于IPv4地址
- Completion类型:completion 提供自动补全建议
- Token count 类型:用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少
- mapper-number3 类型:通过插件,可以通过_number3来计算index 的哈希值
- 附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments 索引,例如Microsoft office格式,Open Document格式,ePub,HTML等
- 地理位置类型(Geo datatypes)
-
-
创建并指定字段类型(POST)
还可以指定分词器类型
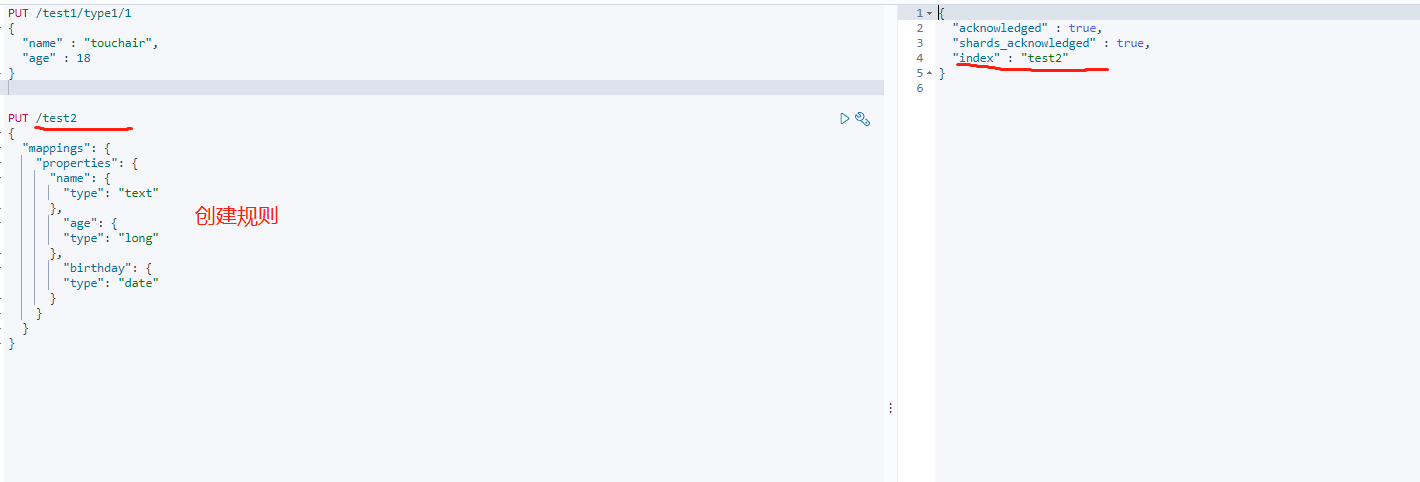
-
获得这个规则(GET)
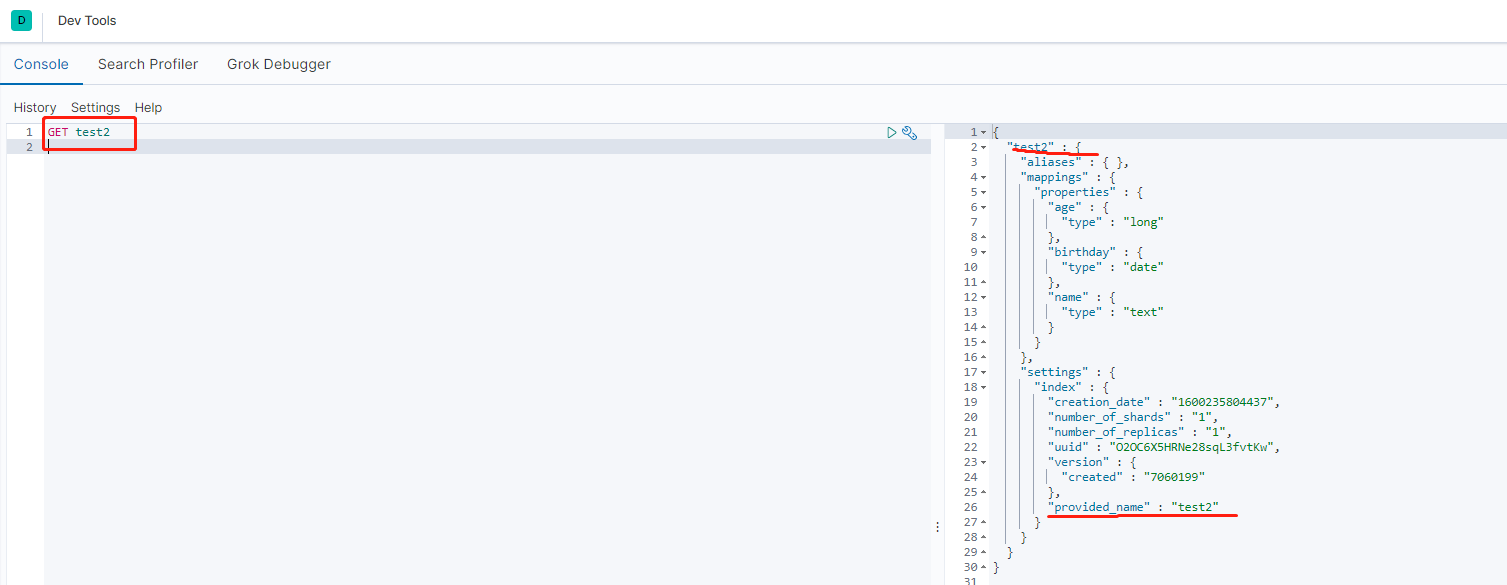
-
查看默认的信息
PUT /test3/_doc/1 #_doc 是默认类型的显示说明 ,可以省略 { "name":"touchair-3", "age":"19", "birth":"2020-09-16" }
查看
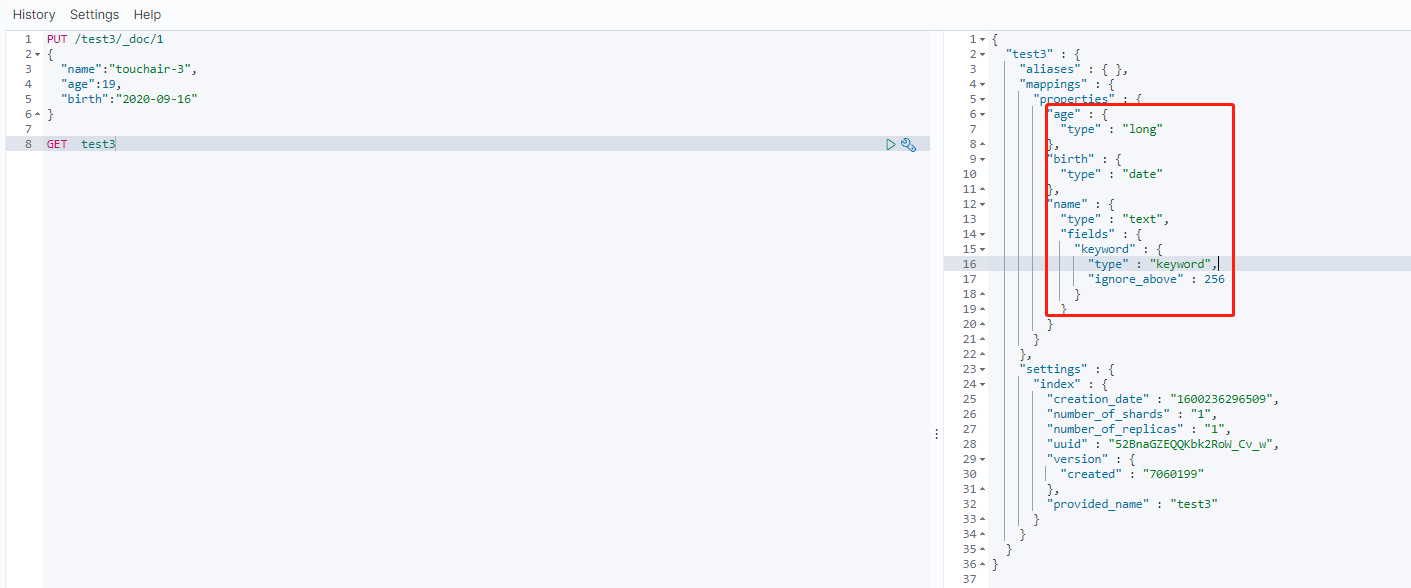
如果自己的文档字段没有指定类型,ES会给我们默认配置字段类型!
-
扩展:通过命令 GET _cat 可以获得ES的很多当前信息
- GET _cat/health 查看健康信息

-
GET _cat/indices?v 查看所有

-
修改数据(POST/PUT)
-
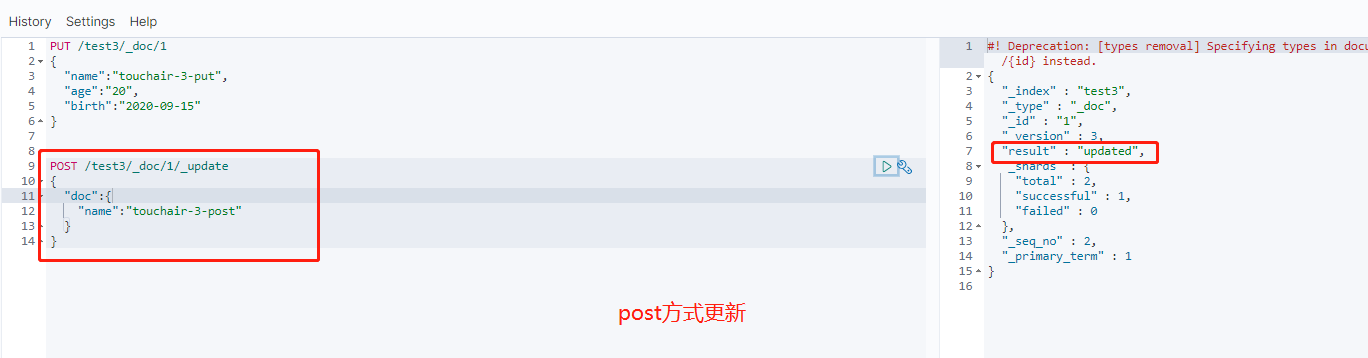
PUT /test3/_doc/1 { "name":"touchair-3-put", "age":"20", "birth":"2020-09-15" } POST /test3/_doc/1/_update { "doc":{ "name":"touchair-3-post" } } -
PUT 覆盖型

-
POST 更新
-
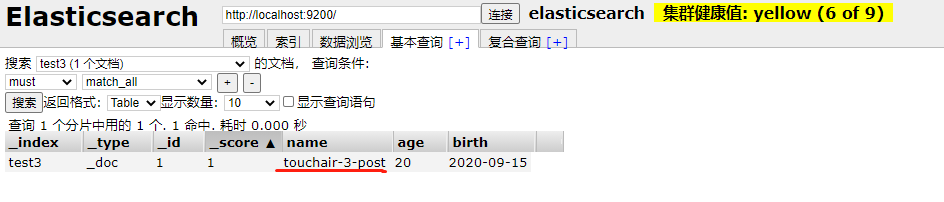
结果查看
-
-
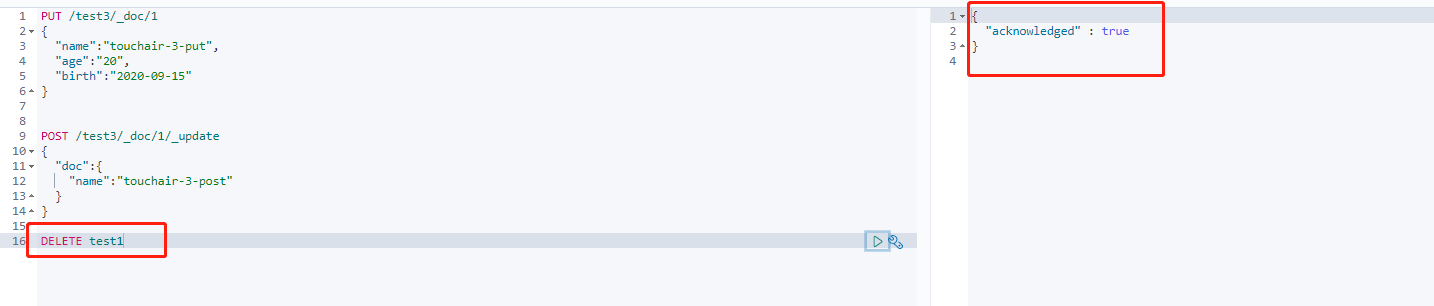
删除索引 (DELETE) 根据请求url来判断是删除索引还是删除文档记录
文档的基本操作(*)
ElasticSearch版本控制
-
version 字段
-
为什么要进行版本控制CAS无锁
为了保证数据再多线程操作下的准确性
-
悲观锁和乐观锁
- 悲观锁:假设一定会有并发冲突,屏蔽一切可能违反数据准确性的操作
- 乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性
-
内部版本控制和外部版本控制
- 内部版本:_version 自增长,修改数据后,version会自动加1
- 外部版本:为了保持version与外部版本控制的数值一致,使用version_type=external检查数据当前的version值是否小于请求中的version值
简单操作
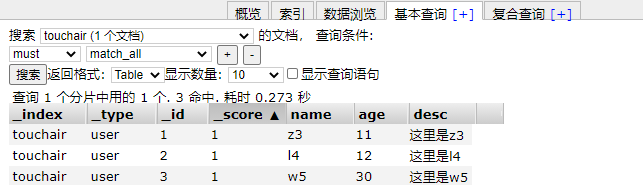
添加测试数据
PUT /touchair/user/1
{
"name":"z3",
"age": 11,
"desc":"这里是z3",
"tags":["技术宅","老直男","加班狗"]
}
PUT /touchair/user/2
{
"name":"l4",
"age": 12,
"desc":"这里是l4",
"tags":["奋斗逼","渣男","杭州"]
}
PUT /touchair/user/3
{
"name":"w5",
"age": 30,
"desc":"这里是w5",
"tags":["靓仔","扑街","旅游"]
}
PUT /touchair/user/4
{
"name":"w55",
"age": 31,
"desc":"这里是w55",
"tags":["靓女","看电影","旅游"]
}
PUT /touchair/user/5
{
"name":"学习Java",
"age": 32,
"desc":"这里是学习Java",
"tags":["钓鱼","读写","写字"]
}
PUT /touchair/user/6
{
"name":"学习Node.js",
"age": 33,
"desc":"这里是学习Node.js",
"tags":["上课","睡觉","打游戏"]
}
获取数据(GET)
GET touchair/user/1
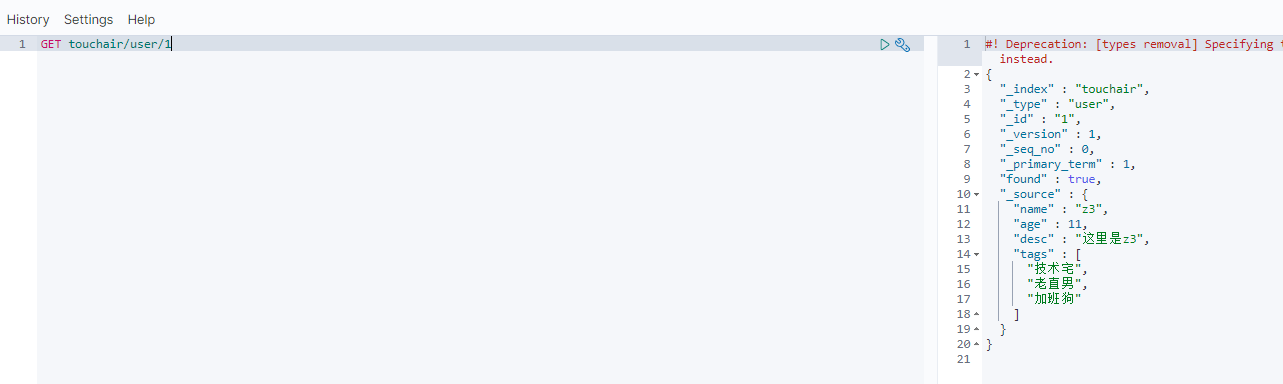
更新数据 (POST)
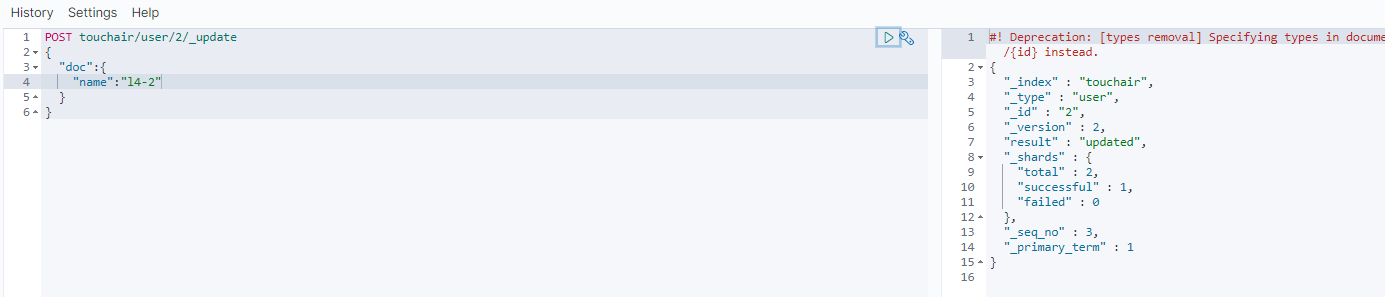
POST touchair/user/2/_update
{
"doc":{
"name":"l4-2"
}
}
GET touchair/user/2
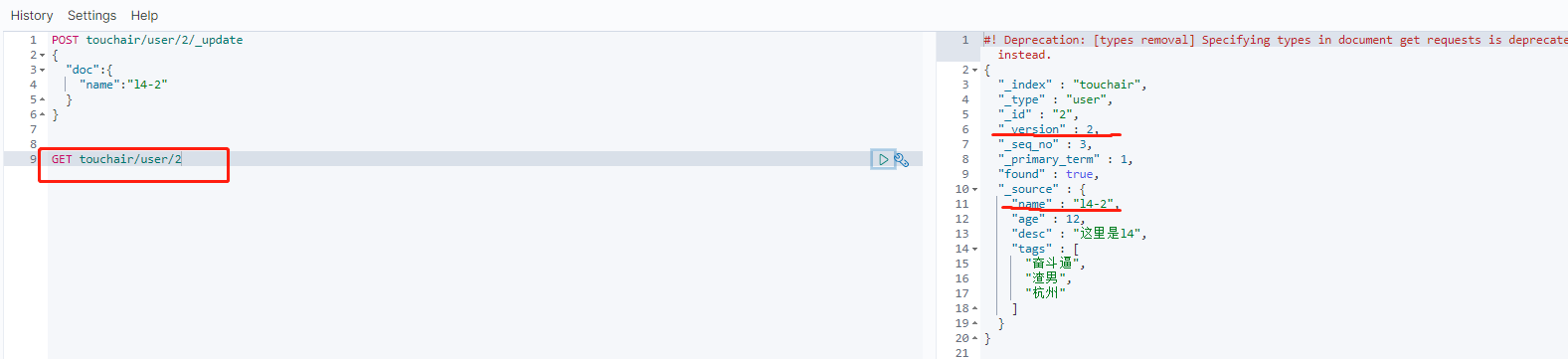
简单的查询
-
条件查询
GET touchair/user/_search?q=name:w5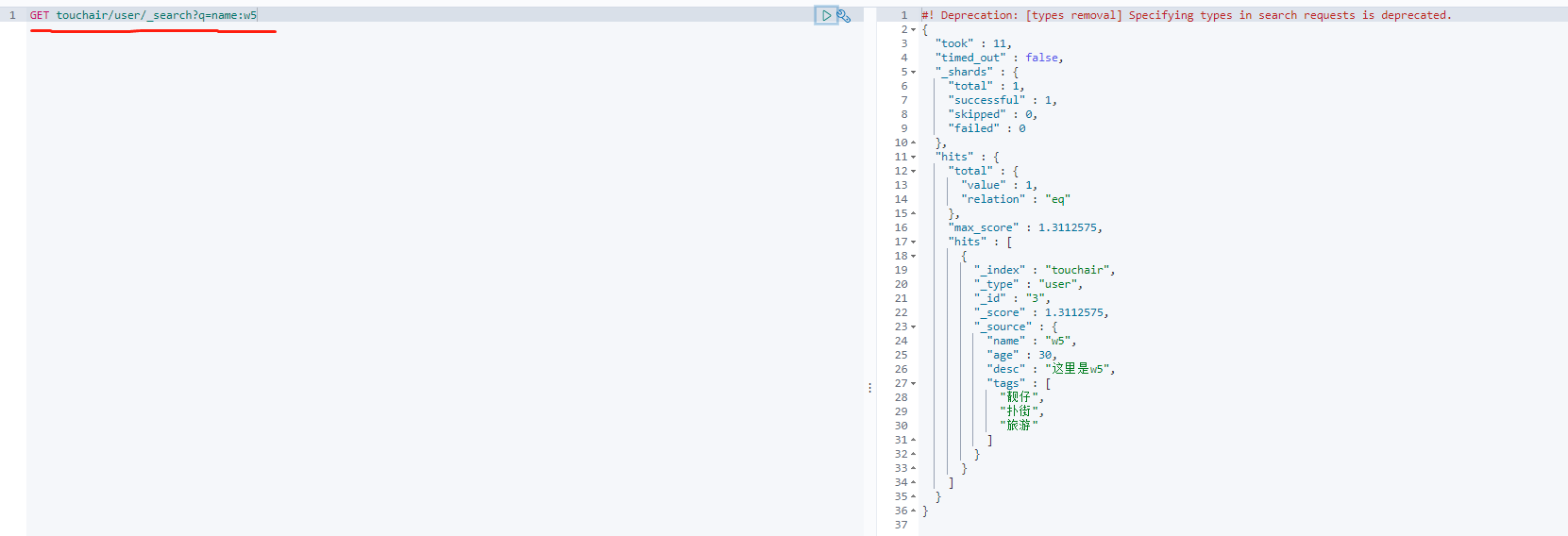
复杂操作
复杂查询 select(排序、分页、高亮、模糊查询、精准查询!)
-
hits中的属性_score代表匹配度,匹配度越高,分值越高 -
hit:- 索引和文档的信息
- 查询的结果总数
- 查询出来的具体的文档
- 都可以遍历得出
- 可以通过score,得出谁更符合条件
匹配 match
GET touchair/user/_search
{
"query": {
"match": {
"name": "w5"
}
}
}
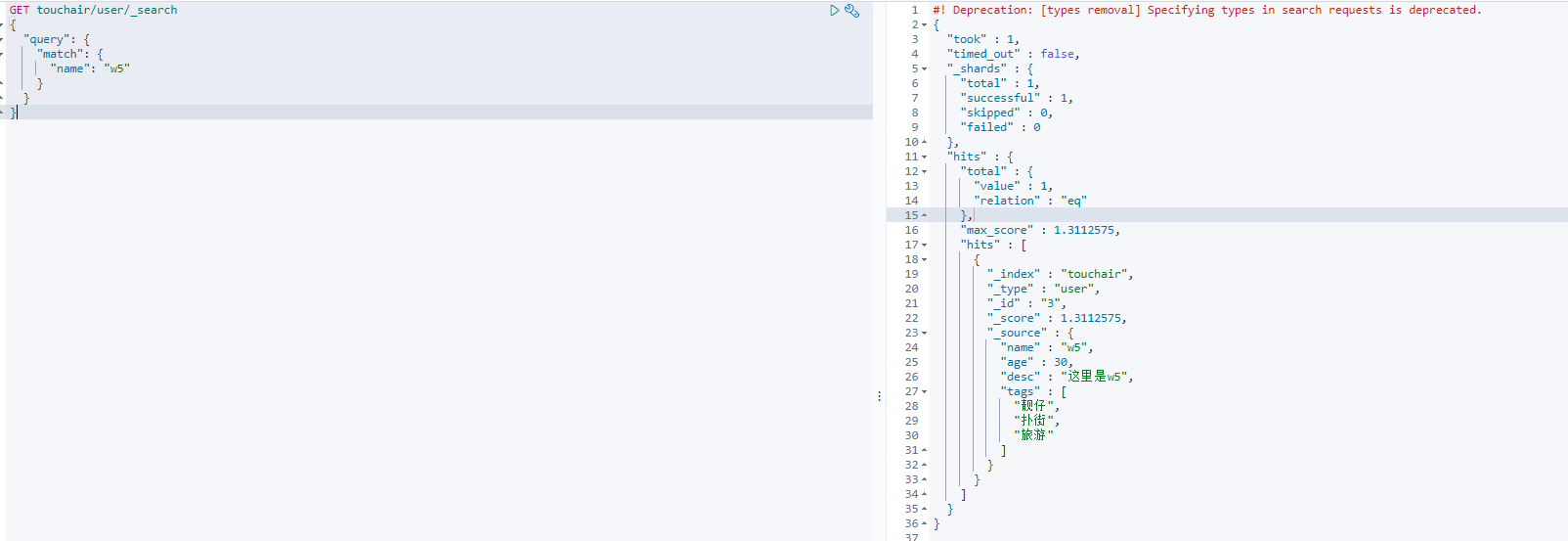
结果返回字段 不需要那么多 _source
GET touchair/user/_search
{
"query": {
"match": {
"name": "学习"
}
},
"_source": ["name","desc"]
}
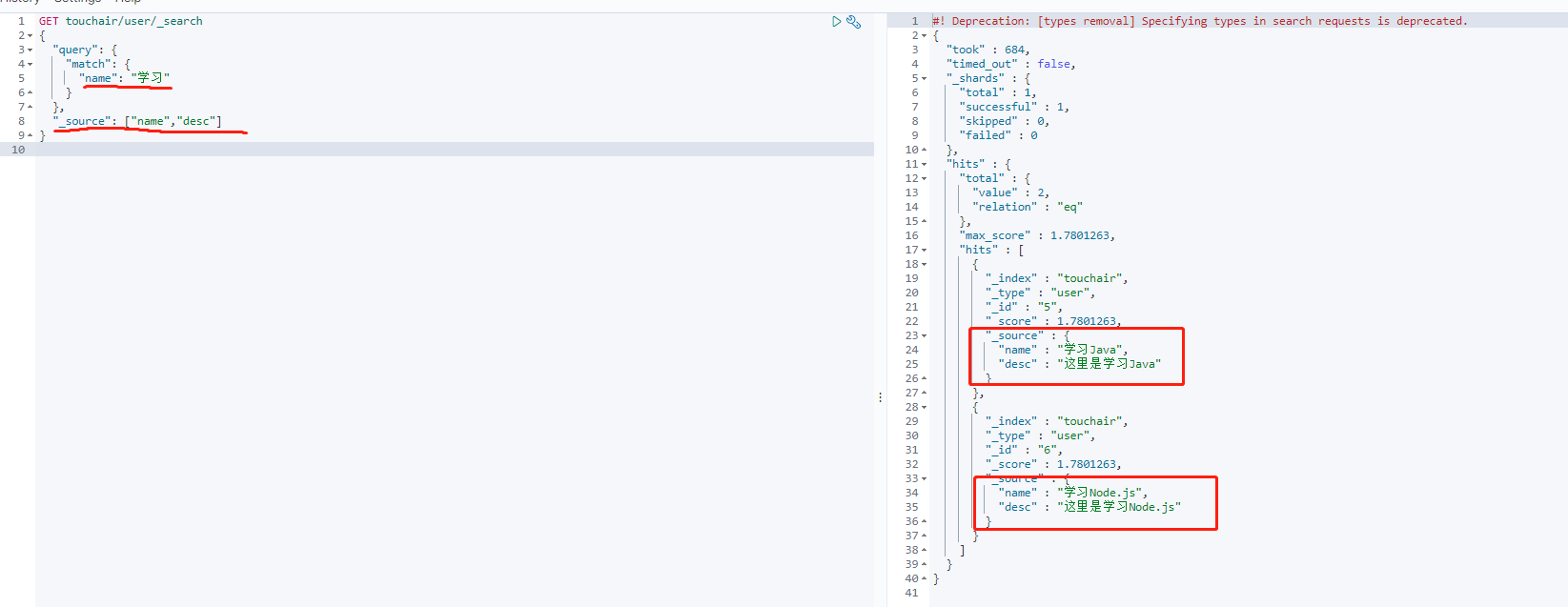
排序
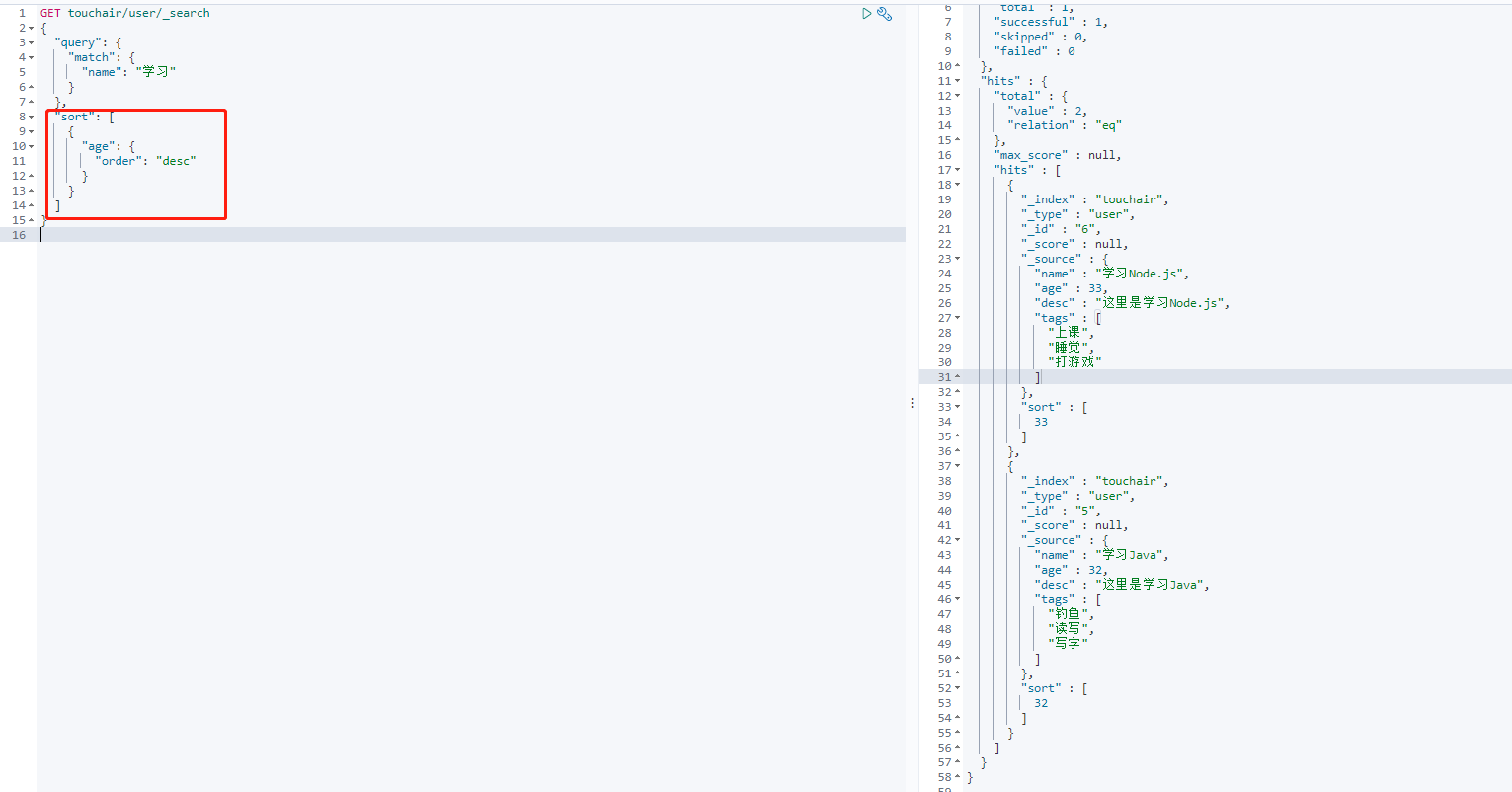
按年龄倒叙
GET touchair/user/_search
{
"query": {
"match": {
"name": "学习"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
分页
from size 相当于MySQL limit语句的两个参数
GET touchair/user/_search
{
"query": {
"match": {
"name": "学习"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
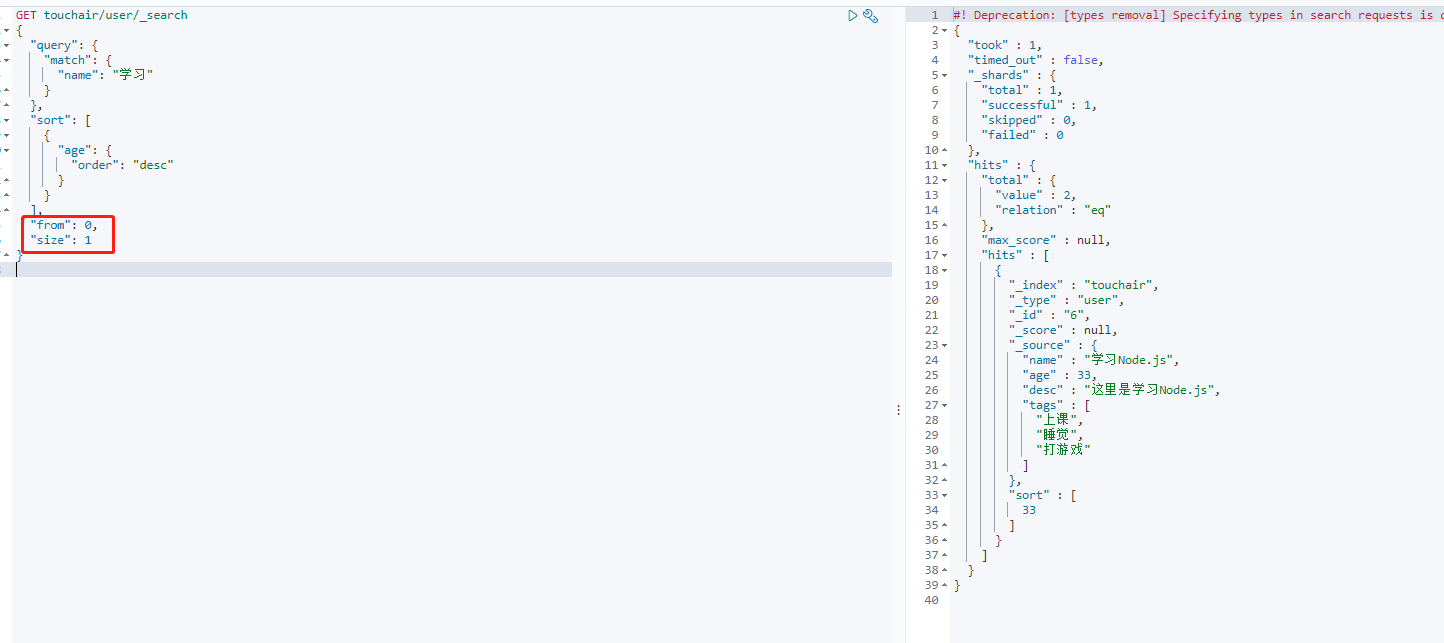
条件匹配
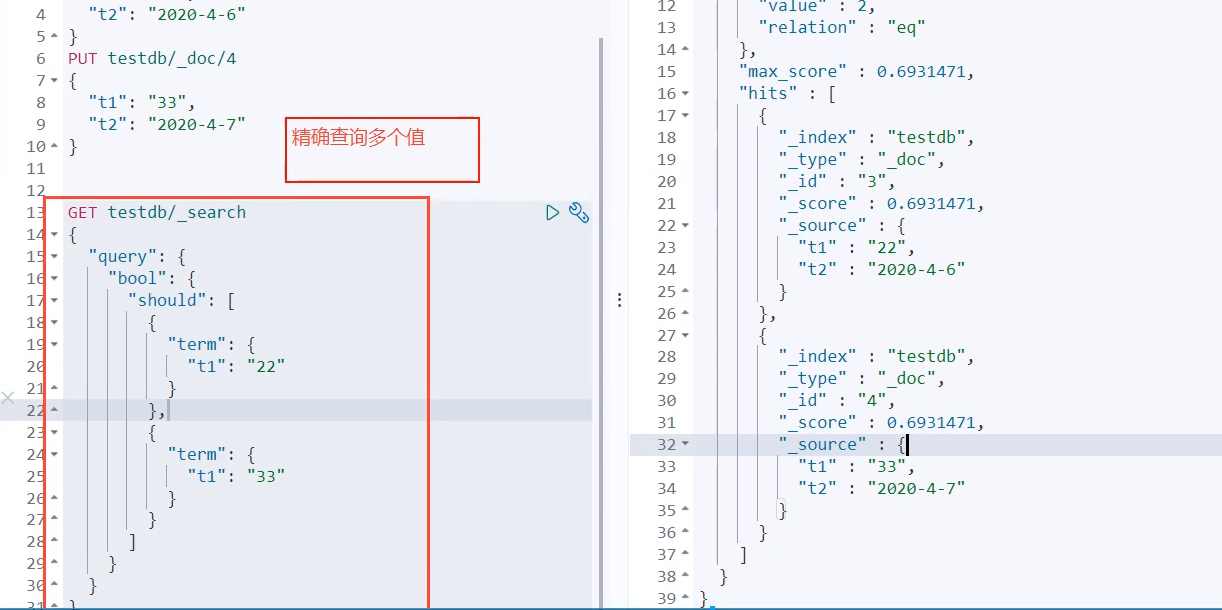
- 精确查询
must,等价于MySQL的 and 操作
GET touchair/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "学习"
}
},
{
"match": {
"age": "32"
}
}
]
}
}
}

-
should等价于MySQL的 or 操作GET touchair/user/_search { "query": { "bool": { "should": [ { "match": { "name": "学习" } }, { "match": { "age": "11" } } ] } } }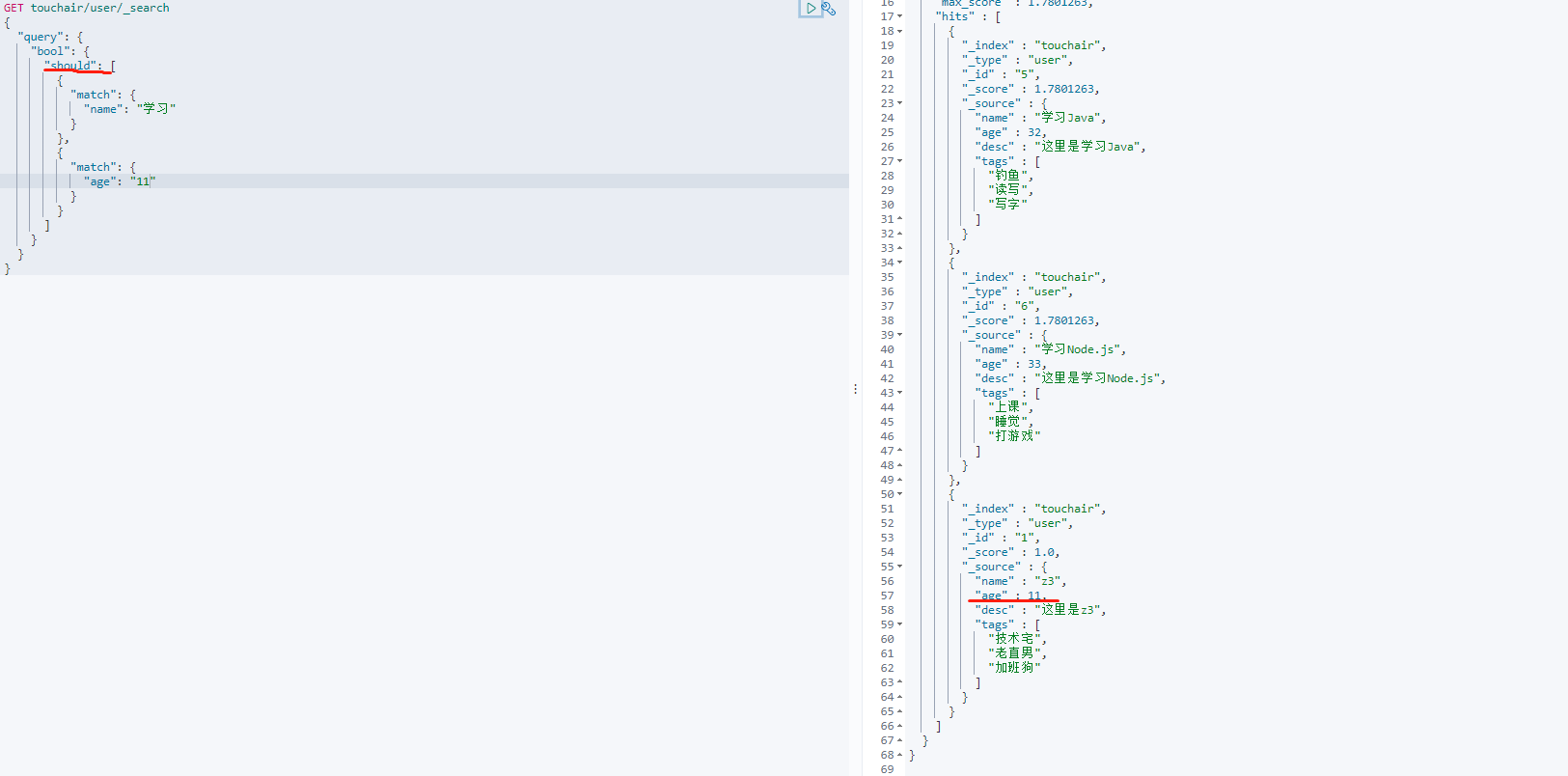
-
must_not等价于MySQL not 操作GET touchair/user/_search { "query": { "bool": { "must_not": [ { "match": { "age": 33 } } ] } } }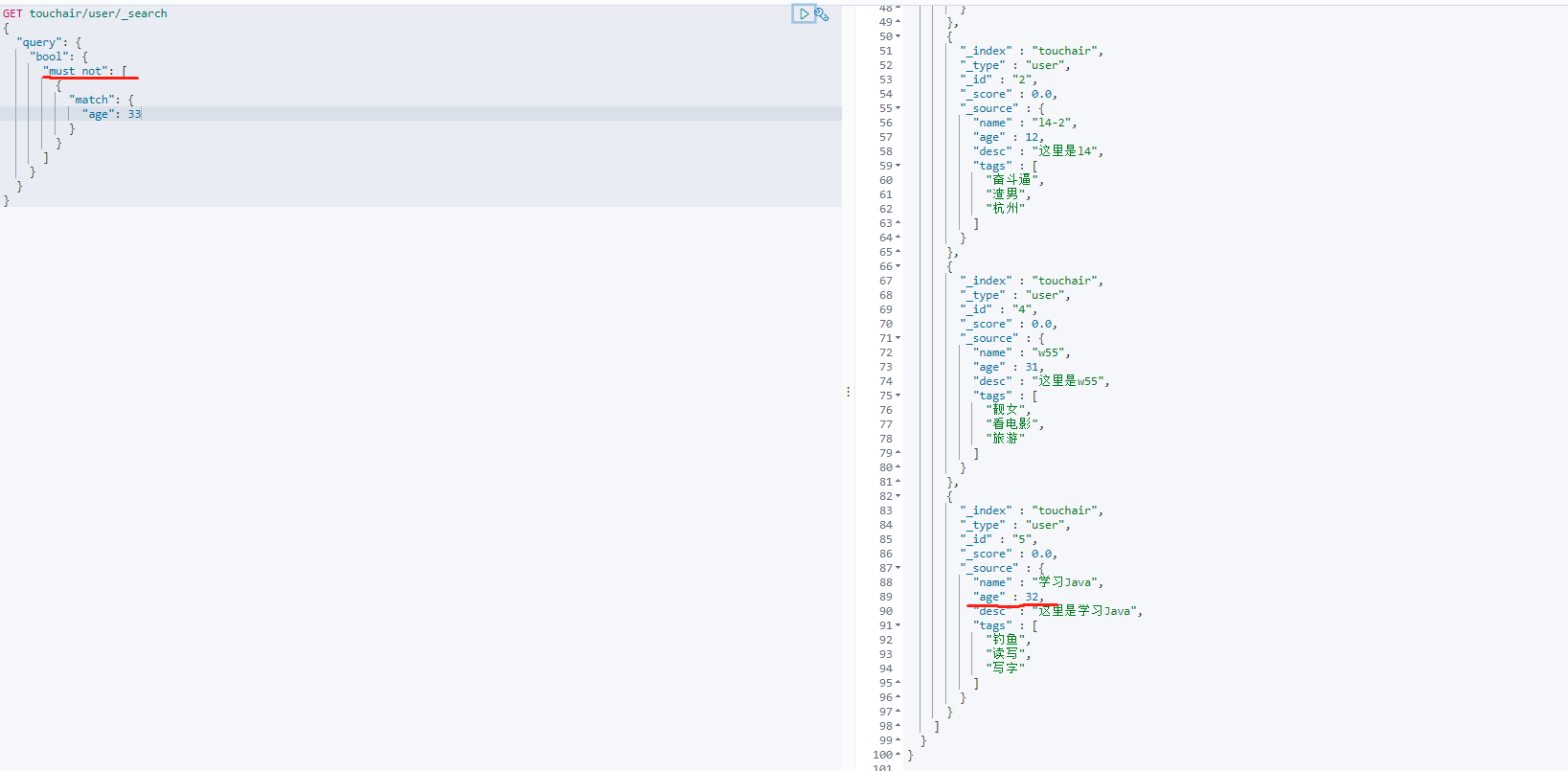
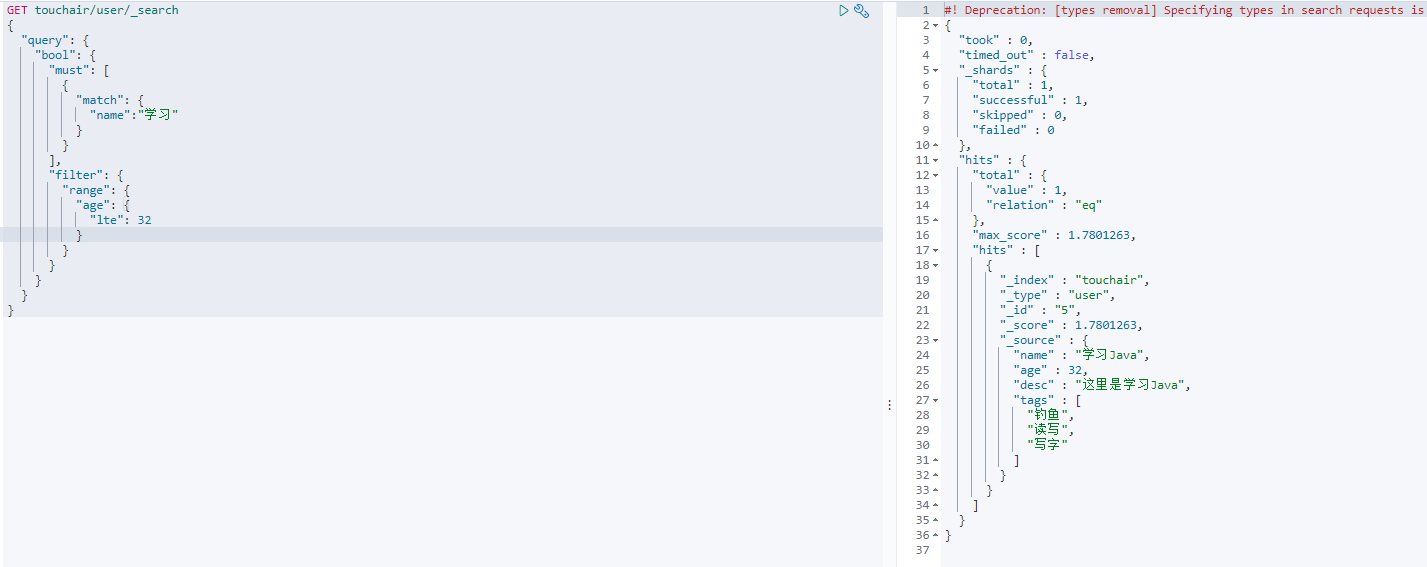
匹配数据过滤 filter
- range 区间
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
GET touchair/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name":"学习"
}
}
],
"filter": {
"range": {
"age": {
"lte": 32
}
}
}
}
}
}
多条件查询 match
-
match 等价于 like
GET touchair/user/_search { "query": { "match": { "tags": "男 技术" } } }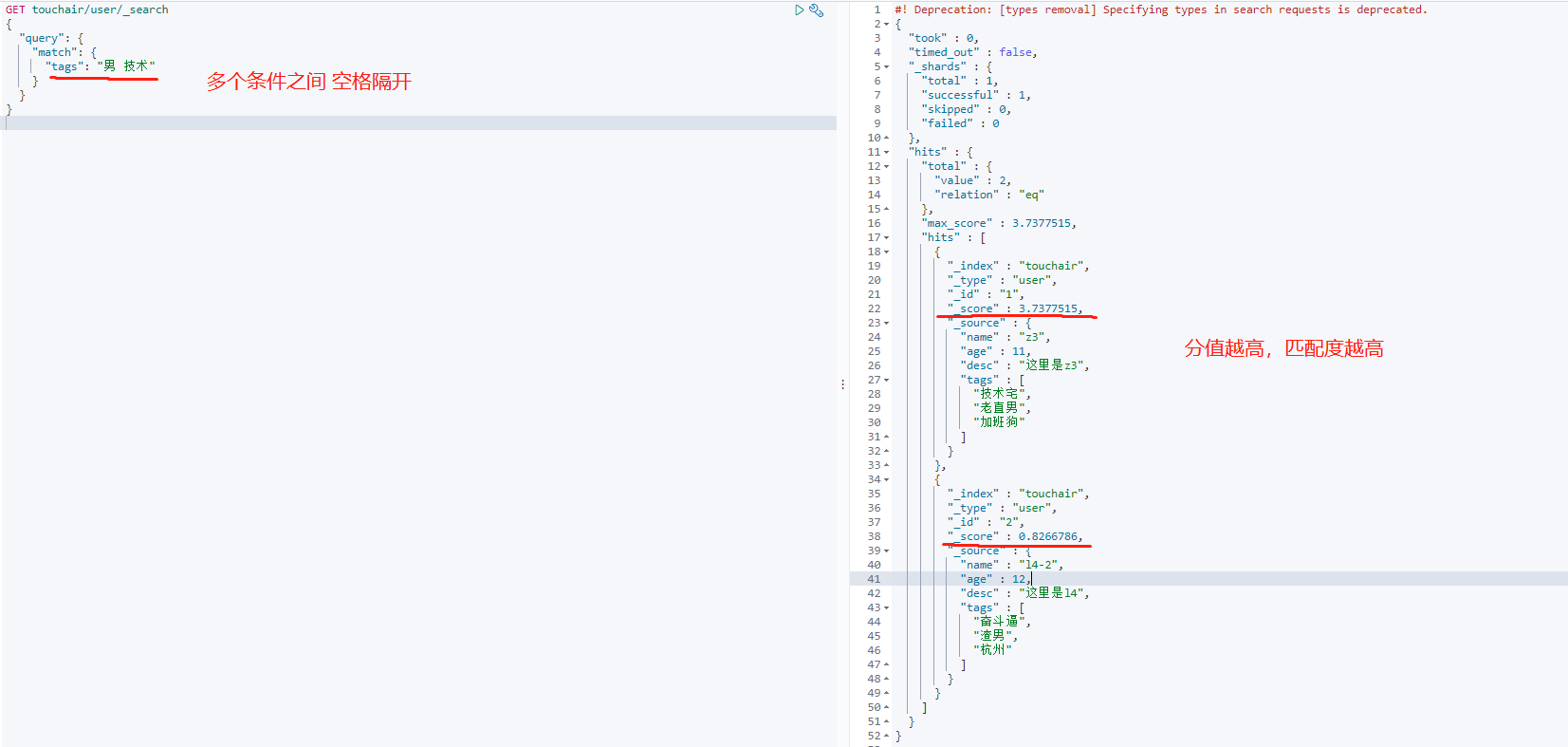
精确查询 term
-
等价于 equals
-
查询是直接通过倒排索引指定的词条进行精确查找的
-
keyword类型字段 只能被精确查找
关于分词:
trem,直接查询精确地
match,会使用分词器解析(先分析文档,在通过分析的文档进行查询)两个类型
text类型会被分词器分割
keyword不会被分割 只能被精确查找
高亮查询
-
highlightGET touchair/user/_search { "query": { "match": { "name": "学习" } }, "highlight": { "fields": { "name":{} } } }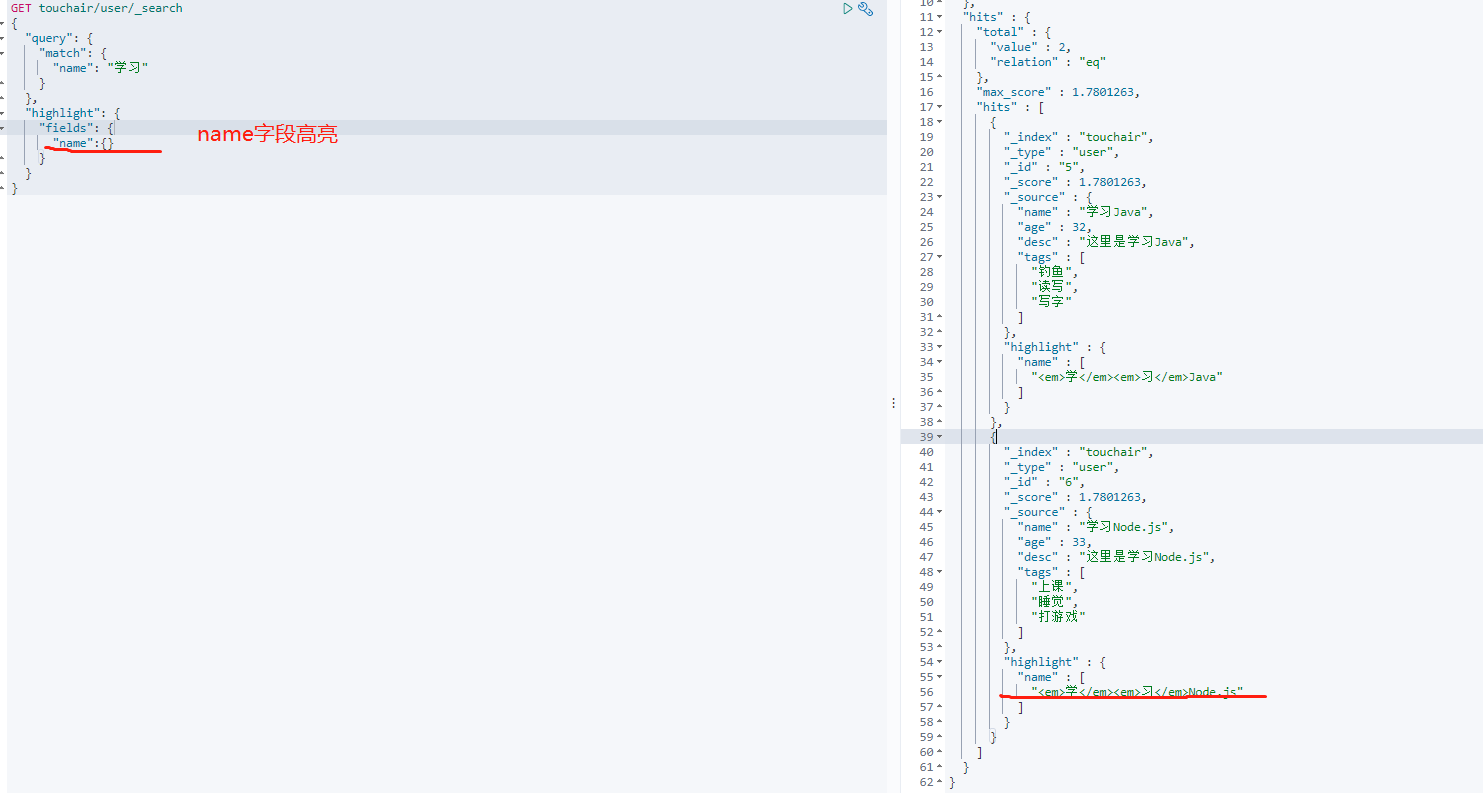
-
自定义高亮包围的标签
GET touchair/user/_search { "query": { "match": { "name": "学习" } }, "highlight": { "pre_tags": "<p class='key',style='color:red'>", "post_tags": "</p>", "fields": { "name":{} } } }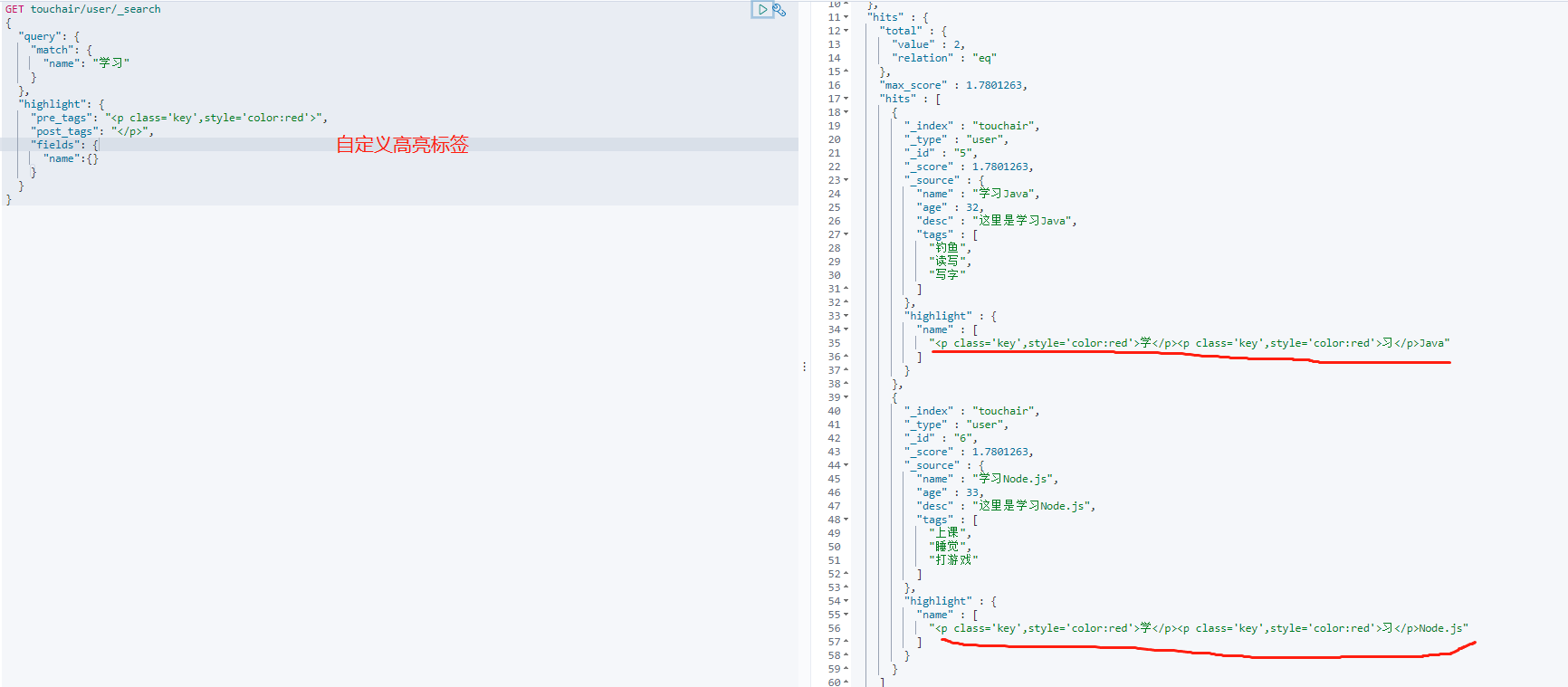
Term与Match区别
- Term查询不会对字段进行分词查询,会采用精确匹配(Equals)
- Match会根据该字段的分词器,进行分词查询(Like)
ES集成SpringBoot
官方文档
文档地址
maven依赖
-
pom.xml
-
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.6.2</version> </dependency>
初始化
创建项目
- 新建springboot项目
- 选择依赖 --- 最主要的NoSQL中的 ElasticSearch
API调用测试
索引的操作
创建索引
判断索引是否存在
获取索引
删除索引
文档的CRUD
创建文档
获取文档
更新文档
删除文档
批量插入文档
文档查询(*)
-
SearchRequest 搜索请求 SearchSourceBuilder 条件构造 highlighter 高亮 matchAllQuery 匹配所有 termQuery() 精确查找 -
测试类代码
package com.touchair.elk; import cn.hutool.json.JSONUtil; import com.touchair.elk.pojo.User; import org.assertj.core.util.Lists; import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteRequest; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.get.GetRequest; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.support.master.AcknowledgedResponse; import org.elasticsearch.action.update.UpdateRequest; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.indices.CreateIndexRequest; import org.elasticsearch.client.indices.CreateIndexResponse; import org.elasticsearch.client.indices.GetIndexRequest; import org.elasticsearch.client.indices.GetIndexResponse; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.index.query.MatchAllQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.boot.test.context.SpringBootTest; import javax.annotation.Resource; import java.io.IOException; import java.util.ArrayList; import java.util.concurrent.TimeUnit; @SpringBootTest class ElkApplicationTests { public static final String INDEX_NAME = "java_touchair_index"; @Resource @Qualifier("restHighLevelClient") private RestHighLevelClient restHighLevelClient; /** * 测试创建索引 * * @throws IOException */ @Test void testCreateIndex() throws IOException { //创建索引的请求 CreateIndexRequest indexRequest = new CreateIndexRequest("java_touchair_index"); //客户端执行请求 IndicesClient,请求后获取响应 CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(indexRequest, RequestOptions.DEFAULT); System.out.println(createIndexResponse.toString()); } /** * 测试 获取索引 * * @throws IOException */ @Test void testGetIndex() throws IOException { GetIndexRequest getIndexRequest = new GetIndexRequest("java_touchair_index"); boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT); if (exists) { GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(getIndexRequest, RequestOptions.DEFAULT); System.out.println(getIndexResponse); } else { System.out.println("索引不存在"); } } /** * 测试 删除索引 * * @throws IOException */ @Test void testDeleteIndex() throws IOException { DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("test2"); AcknowledgedResponse acknowledgedResponse = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT); System.out.println(acknowledgedResponse.isAcknowledged()); } /** * 测试 文档创建 * * @throws IOException */ @Test void testAddDocument() throws IOException { //创建对象 User user = new User("java", 23); //创建请求 IndexRequest indexRequest = new IndexRequest("java_touchair_index"); //规则 put /java_touchair_index/_doc/1 indexRequest.id("1"); indexRequest.timeout(TimeValue.timeValueSeconds(1)); //将数据放入请求 indexRequest.source(JSONUtil.toJsonPrettyStr(user), XContentType.JSON); //客户端发送请求,获取 IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.out.println(indexResponse.toString()); System.out.println(indexResponse.status()); } /** * 测试 获取文档 * * @throws IOException */ @Test void testGetDocument() throws IOException { //判断文档是否存在 get /index/_doc/1 GetRequest getRequest = new GetRequest(INDEX_NAME, "1"); // //不获取返回的 _source 的上下文了 // getRequest.fetchSourceContext(new FetchSourceContext(false)); // getRequest.storedFields("_none_"); boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT); if (exists) { GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); System.out.println(getResponse.toString()); //打印文档内容 //返回的全部内容和命令行结果一模一样 System.out.println(getResponse.getSourceAsString()); } else { System.out.println("文档不存在"); } } /** * 测试 更新文档信息 * * @throws IOException */ @Test void testUpdateDocument() throws IOException { UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "1"); updateRequest.timeout("1s"); User user = new User("ES搜索引擎", 24); updateRequest.doc(JSONUtil.toJsonPrettyStr(user), XContentType.JSON); UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT); System.out.println(updateResponse.status()); } /** * 测试 删除文档 * * @throws IOException */ @Test void testDeleteDocument() throws IOException { DeleteRequest deleteRequest = new DeleteRequest(INDEX_NAME, "1"); deleteRequest.timeout("1s"); DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); System.out.println(deleteResponse.getResult()); } /** * 特殊 ,真实项目一般都是批量插入数据 * * @throws IOException */ @Test void testBulkRequest() throws IOException { BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("10s"); ArrayList<User> userList = Lists.newArrayList(); userList.add(new User("Java", 11)); userList.add(new User("javaScript", 12)); userList.add(new User("Vue", 13)); userList.add(new User("Mysql", 14)); userList.add(new User("Docker", 15)); userList.add(new User("MongoDB", 16)); userList.add(new User("Redis", 17)); userList.add(new User("Tomcat", 18)); for (int i = 0; i < userList.size(); i++) { //批量更新和批量删除 只需在这里修改对应的请求即可 bulkRequest.add(new IndexRequest(INDEX_NAME) .id("" + i + 1) .source(JSONUtil.toJsonPrettyStr(userList.get(i)), XContentType.JSON)); } BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); System.out.println((bulkResponse.hasFailures())); //是否失败 返回false 则成功 } /** * 查询 * SearchRequest 搜索请求 * searchSourceBuilder 条件构造 * highlighter 高亮 * matchAllQuery 匹配所有 * termQuery() 精确查找 * * @throws IOException */ @Test void testSearch() throws IOException { SearchRequest searchRequest = new SearchRequest(INDEX_NAME); //构建搜索条件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //查询条件,可以使用QueryBuilders工具 快速查询 //QueryBuilders.matchAllQuery 匹配所有 //QueryBuilders.termQuery() 精确查找 // TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("age", 11); MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery(); searchSourceBuilder.query(matchAllQueryBuilder); searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // searchSourceBuilder.highlighter(); // searchSourceBuilder.size(); // searchSourceBuilder.from(); searchRequest.source(searchSourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); for (SearchHit searchHits : searchResponse.getHits().getHits()) { System.out.println(searchHits.getSourceAsMap()); } } }
仿商城搜索
-
爬取网页数据
-
分页搜索
-
高亮
-
效果图
分布式日志收集
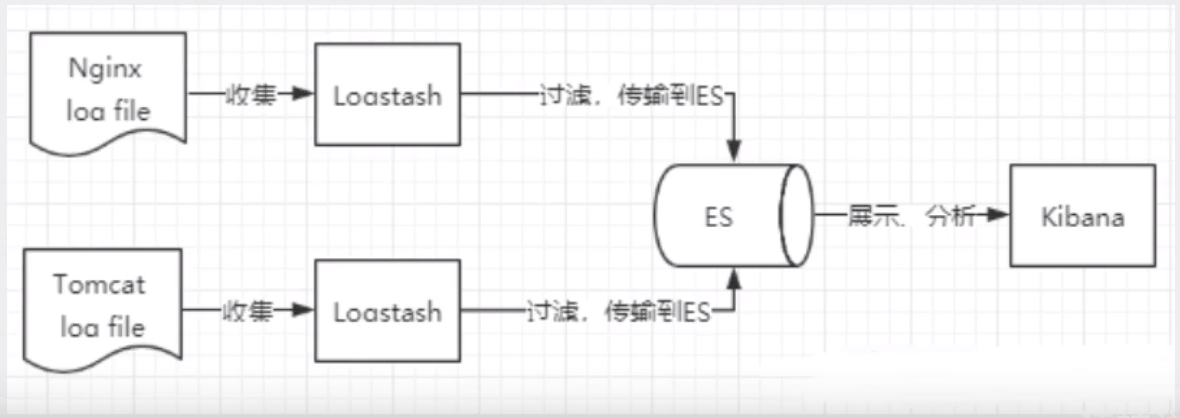
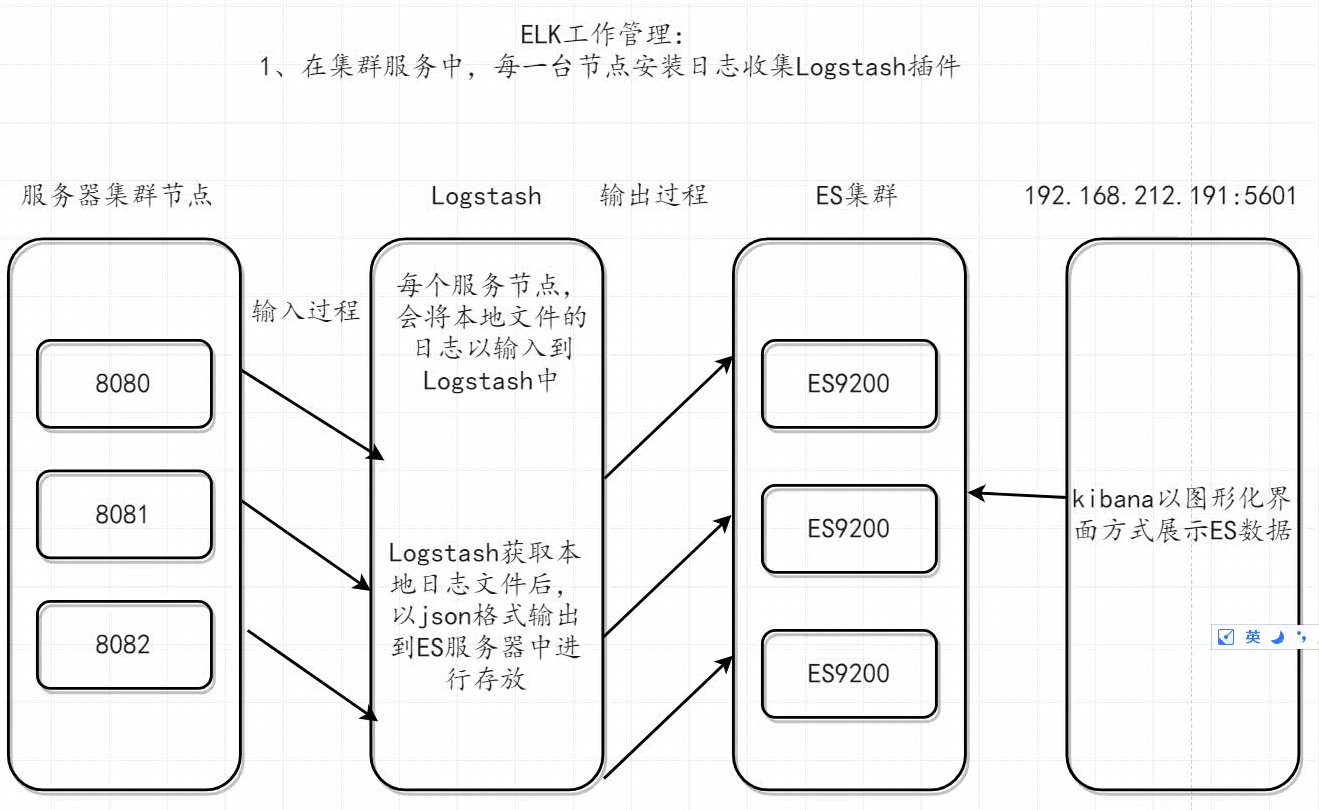
ELK分布式日志收集原理(*)
-
每台服务器集群节点安装Logstash日志收集系统插件
-
每台服务器节点将日志输入到Logstash中
-
Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearc中
-
浏览器安装使用Kibana查询日志信息
环境安装
- 1、安装ElasticSearch
- 2、安装Logstash
- 3、安装Kibana
Logstash
介绍
-
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,Logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各个节点日志进行过滤、修改等操作再一并发往ElasticSearch中
-
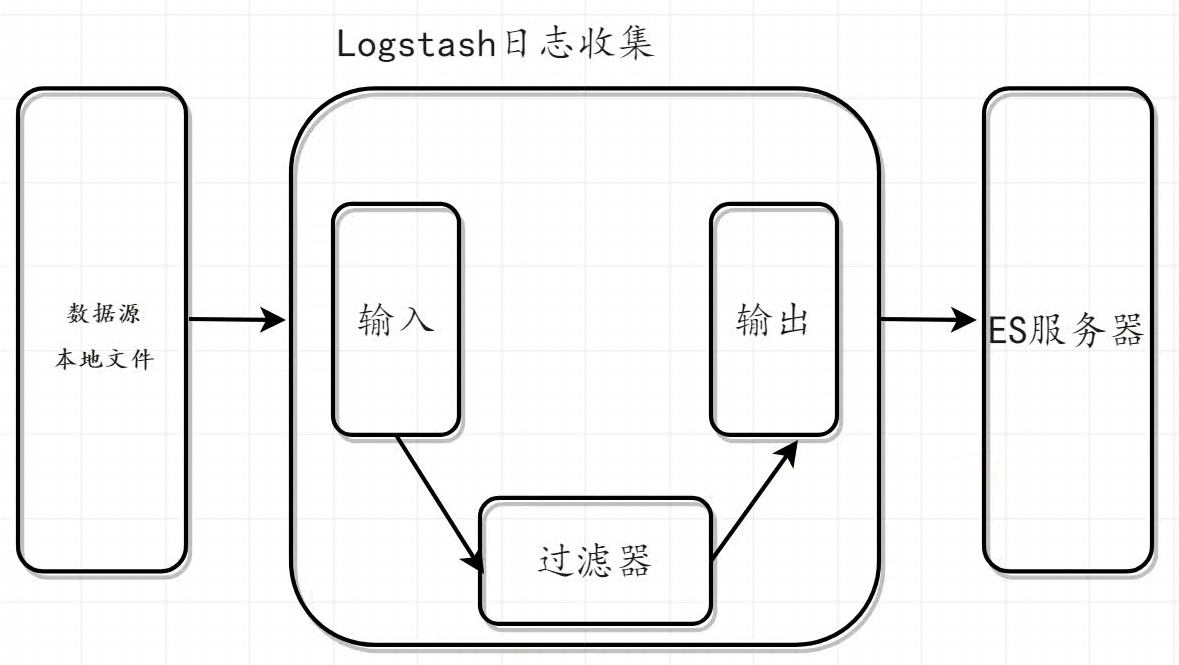
核心流程:
- Logstash事件处理有三个阶段:input-->filters-->outputs
- 是一个接收、处理、转发日志的工具
- 支持系统日志、webserver日志、错误日志、应用日志,总之包括所有可以抛出来的日志类型
Logstash环境搭建
- 下载地址
- 解压
Logstash测试
-
将elsaticsearch的日志输入进logstash
-
进入logstash的config目录下,创建touchair.conf
-
添加以下内容并保存
input { # 从文件读取日志信息,输送到控制台 file{ path => "/usr/local/elk/elasticsearch-7.6.1/logs/elasticsearch.log" #以JSON格式读取日志 codec => "json" type => "elasticsearch" start_position =>"beginning" } } output { # 标准输出 #stdout{} # 输出进行格式化,采用Ruby库来解析日志 stdout { codec => rubydebug } } -
启动logstash,观察控制台 logstash的bin目录下
./logstash -f ../config/touchair.conf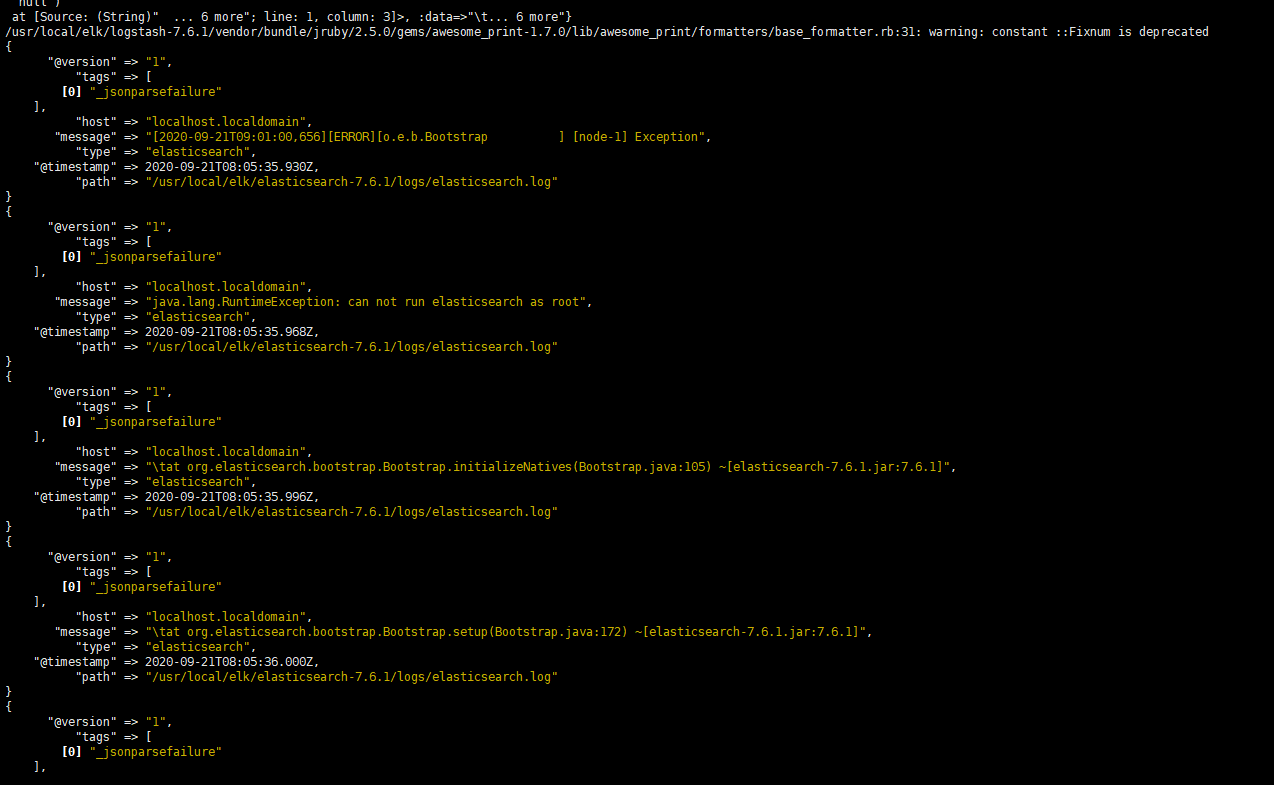
-
将日志输出到ES中
-
创建并修改 touchair.es.conf文件
input { # 从文件读取日志信息,输送到控制台 file{ path => "/usr/local/elk/elasticsearch-7.6.1/logs/elasticsearch.log" #以JSON格式读取日志 codec => "json" type => "elasticsearch" start_position =>"beginning" } } output { # 标准输出 #stdout{} # 输出进行格式化,采用Ruby库来解析日志 stdout { codec => rubydebug } elasticsearch { hosts => ["192.168.83.133:9200"] index => "es-%{+YYYY.MM.dd}" } } -
启动logstash
./logstash -f ../config/touchair.es.conf
Logstash整合Springboot
单行
-
# tcp -> Logstash -> Elasticsearch pipeline. input { tcp { mode => "server" host => "0.0.0.0" port => 4560 codec => json_lines } } output { elasticsearch { hosts => ["192.168.83.133:9200"] index => "robot-java-%{+YYYY.MM.dd}" } }
运行日志多行才能准确定位问题
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => multiline{
pattern => "^\["
negate => false
what => "next"
}
}
}
filter {
json {
source => "message"
}
mutate {
add_field => {
"language" => "%{[type]}"
}
}
}
output{
if [language]=="java" {
elasticsearch {
hosts => ["172.17.0.8:9200"]
index => "robot-java-%{+YYYY.MM.dd}"
}
}
if [language]=="ros" {
elasticsearch {
hosts => ["172.17.0.8:9200"]
index => "robot-ros-%{+YYYY.MM.dd}"
}
}
if [language]=="rec" {
elasticsearch {
hosts => ["172.17.0.8:9200"]
index => "robot-rec-%{+YYYY.MM.dd}"
}
}
}
ELK docker部署
安装ElasticSearch
拉取镜像
docker pull elasticsearch:7.6.1
运行容器
- 运行命令创建启动容器:
docker run -d --name es -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" elasticsearch:7.6.1
- 将配置文件、数据目录拷出来做挂载
docker cp es:/usr/share/elasticsearch/config/ /var/elk/elasticsearch/config
docker cp es:/usr/share/elasticsearch/data/ /var/elk/elasticsearch/data
-
设置允许跨域访问
-
vim /var/elk/elasticsearch/config/elasticsearch.yml #添加这2行 http.cors.enabled: true http.cors.allow-origin: "*"
-
-
销毁容器,重新以挂载方式运行
#销毁
docker rm -f es
#挂载配置文件
docker run -d --name es -p 9200:9200 -p 9300:9300 \
-v /var/elk/elasticsearch/config/:/usr/share/elasticsearch/config/ \
-v /var/elk/elasticsearch/data/:/usr/share/elasticsearch/data/ \
-e "discovery.type=single-node" \
elasticsearch:7.6.1
-
访问宿主机ip的9200端口,查看是否启动成功
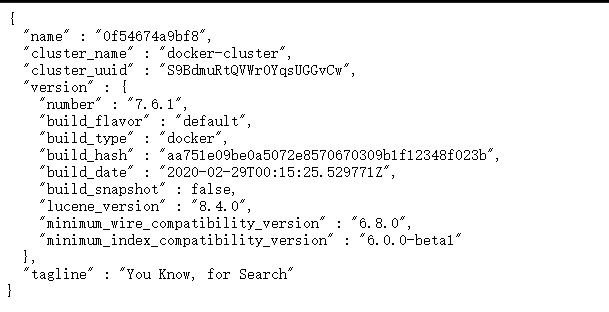
安装Kibana
拉取镜像
docker pull kibana:7.6.1
运行容器
-
先运行容器
docker run -d --name kibana -p 5601:5601 kibana:7.6.1 -
拷出配置文件,后面做挂载
# 拷贝 docker cp kibana:/usr/share/kibana/config/ /var/elk/kibana/config #查看es容器的内部ip docker exec -it es ifconfig #修改配置 vim kibana.yml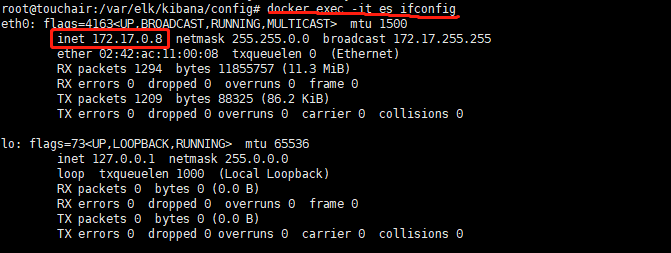
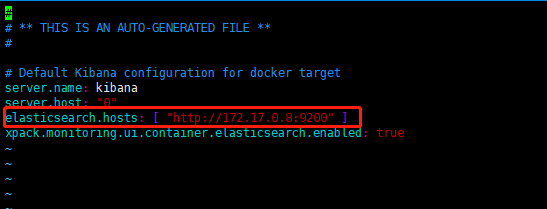
-
挂载运行
# 先销毁容器 docker rm -f kibana # 运行容器 docker run -d --name kibana -p 5601:5601 \ -v /var/elk/kibana/config:/usr/share/kibana/config \ kibana:7.6.1 -
宿主机ip:5601,查看kibana图形化界面
安装LogStash
拉取镜像
docker pull logstash:7.6.1
运行容器
-
先运行容器
docker run --name logstash -d -p 4560:4560 -p 9600:9600 logstash:7.6.1 -
拷出配置文件,后面做挂载
docker cp logstash:/usr/share/logstash/config /var/elk/logstash/config-
添加自定义的conf 文件
input { tcp { mode => "server" host => "0.0.0.0" port => 4560 codec => multiline{ pattern => "^\[" negate => false what => "next" } } } filter { json { source => "message" } mutate { add_field => { "language" => "%{[type]}" } } } output{ if [language]=="java" { elasticsearch { hosts => ["172.17.0.8:9200"] index => "robot-java-%{+YYYY.MM.dd}" } } if [language]=="ros" { elasticsearch { hosts => ["172.17.0.8:9200"] index => "robot-ros-%{+YYYY.MM.dd}" } } if [language]=="rec" { elasticsearch { hosts => ["172.17.0.8:9200"] index => "robot-rec-%{+YYYY.MM.dd}" } } } -
修改配置文件 logstash.yml
vim logstash.yml
-
-
挂载运行
#删除容器 docker rm -f logstash #重新启动容器 docker run --name logstash -d -p 4560:4560 -p 9600:9600 \ -v /var/elk/logstash/config:/usr/share/logstash/config \ logstash:7.6.1 \ -f /usr/share/logstash/config/robot.conf
一旦ES容器内部IP变化,需改动kibana.yml 以及logstash.yml和自定义的conf文件中的ES服务地址,并重启kibana和Logstash

 浙公网安备 33010602011771号
浙公网安备 33010602011771号