MongoDB基础篇&集群篇
MongoDB基础篇&集群篇
-
MongoDB用起来-快速上手&集群和安全系列
-
基础篇目标:
- 能理解MongoDB的业务场景,熟悉MongoDB的简介、特点和体系结构、数据类型等
- 能够在windows和Linux下安装和启动MongoDB、图形化管理界面Compass的安装使用
- 掌握MongoDB基本常用命令实现数据的CRUD
- 掌握MongoDB的索引类型、索引管理、执行计划
- 使用Spring Data MongoDB完成文章评论业务的开发
-
集群篇目标:
- MongoDB的副本集:操作、主要概念、故障转移、选举规则
- MongoDB的分片集群:概念、优缺点、操作、分片策略、故障转移
- MongoDB的安全认证
MongoDB基础篇
1. MongoDB相关概念
1.1业务应用场景
-
传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。
-
解释:“三高”需求:
- High performance - 对数据库高并发读写的需求
- Huge Storage - 对海量数据的高效率存储和访问的需求
- High Scalability && High Availability- 对数据库的高可扩展性和高可用性的需求
-
而MongoDB可应对“三高”要求,具体应用场景如下:
- 社交场景,使用 MongoDB 存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
- 视频直播,使用 MongoDB 存储用户信息、点赞互动信息等
-
这些应用场景中,数据操作方面的共同特点是:
-
数据量大
-
写入操作频繁(读写都很频繁)
-
价值较低的数据,对事务性要求不高
对于这样的数据,我们更适合使用MongoDB来实现数据的存储
-
什么时候选择MongoDB
-
在架构选型上,除了上述的三个特点外,如果你还犹豫是否要选择它?可以考虑以下的一些问题:
- 应用不需要事务及复杂 join 支持
- 新应用,需求会变,数据模型无法确定,想快速迭代开发
- 应用需要2000-3000以上的读写QPS(更高也可以)
- 应用需要TB甚至 PB 级别数据存储
- 应用发展迅速,需要能快速水平扩展
- 应用要求存储的数据不丢失
- 应用需要99.999%高可用
- 应用需要大量的地理位置查询、文本查询
如果上述有1个符合,可以考虑 MongoDB,2个及以上的符合,选择 MongoDB 绝不会后悔
-
相对MySQL,可以以更低的成本解决问题(包括学习、开发、运维等成本)
1.2MongoDB简介
- MongoDB是一个开源、高性能、无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是NoSQL数据库产品中的一种。是最像关系型数据库(MySQL)的非关系型数据库
- 它支持的数据结构非常松散,是一种类似于 JSON 的 格式叫BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活
- MongoDB中的记录是一个文档,它是一个由字段和值对(fifield:value)组成的数据结构。MongoDB文档类似于JSON对象,即一个文档认为就是一个对象。字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档、普通数组和文档数组
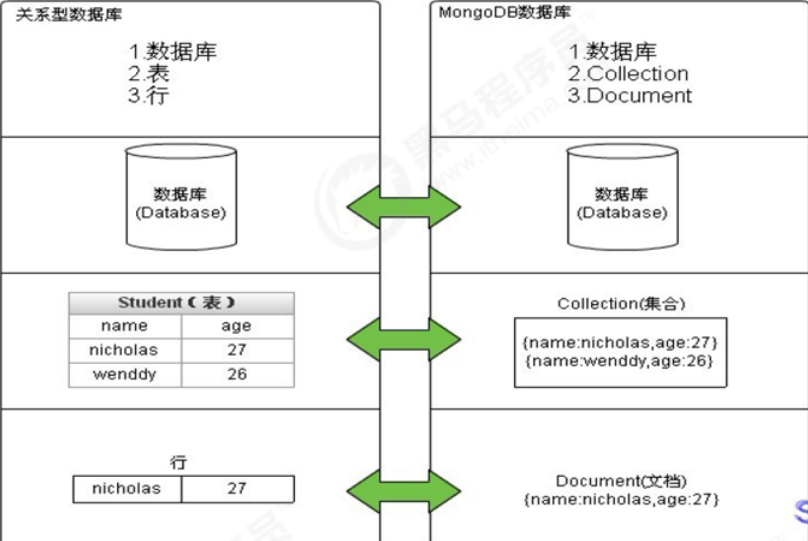
1.3体系结构
MySQL和MongoDB对比
-
-
SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数据库 table collection 表/集合 row document 记录/文档 column field 字段/域 index index 索引 table joins 表连接/MongoDB不支持 嵌入文档 MongoDB通过嵌入式文档来替代多表连接 primary key primary key 主键/MongoDB自动将_id字段设为主键
1.4数据模型
-
MongoDB的最小存储单位就是文档(document)对象。文档(document)对象对应于关系型数据库的行。数据在MongoDB中以BSON(Binary-JSON)文档的格式存储在磁盘上
- BSON(Binary Serialized Document Format)是一种类json的一种二进制形式的存储格式,简称Binary JSON。BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型
- BSON采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想
- Bson中,除了基本的JSON类型:string,integer,boolean,double,null,array和object,mongo还使用了特殊的数据类型。这些类型包括date,object id,binary data,regular expression 和code。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详细信息
-
BSON数据类型参考列表:
| 数据类型 | 描述 | 举例 |
|---|---|---|
| 字符串 | UTF-8字符串都可表示为字符串类型的数据 | |
| 对象id | 对象id是文档的12字节的唯一 ID | |
| 布尔值 | 真或者假:true或者false | {"x":true}+ |
| 数组 | 值的集合或者列表可以表示成数组 | |
| 32位整数 | 类型不可用。JavaScript仅支持64位浮点数,所以32位整数会被自动转换 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
| 64位整数 | 不支持这个类型。shell会使用一个特殊的内嵌文档来显示64位整数 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
| 64位浮点数 | shell中的数字就是这一种类型 | |
| null | 表示空值或者未定义的对象 | |
| undefifined | 文档中也可以使用未定义类型 | |
| 符号 | shell不支持,shell会将数据库中的符号类型的数据自动转换成字符串 | |
| 正则表达式 | 文档中可以包含正则表达式,采用JavaScript的正则表达式语法 | |
| 代码 | 文档中还可以包含JavaScript代码 | {"x" : function() {/* …… */}} |
| 二进制数据 | 二进制数据可以由任意字节的串组成,不过shell中无法使用 | |
| 最大值/最小值 | BSON包括一个特殊类型,表示可能的最大值。shell中没有这个类型 |
- 提示:
- shell默认使用64位浮点型数值。{“x”:3.14}或{“x”:3}。对于整型值,可以使用NumberInt(4字节符号整数)或NumberLong(8字节符号整数),
1.5MongoDB的特点
高性能
- MongoDB提供高性能的数据持久性。特别是对嵌入式数据模型的支持减少了数据库系统上的I/O活动。索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。(文本索引解决搜索的需求、TTL索引解决历史数据自动过期的需求、地理位置索引可用于构建各种 O2O 应用)
- mmapv1、wiredtiger、mongorocks(rocksdb)、in-memory 等多引擎支持满足各种场景需求
- Gridfs解决文件存储的需求
高可用性
- MongoDB的复制工具称为副本集(replica set),它可提供自动故障转移和数据冗余
高扩展性
- MongoDB提供了水平可扩展性作为其核心功能的一部分
- 分片将数据分布在一组集群的机器上。(海量数据存储,服务能力水平扩展)
- 从3.4开始,MongoDB支持基于片键创建数据区域。在一个平衡的集群中,MongoDB将一个区域所覆盖的读写只定向到该区域内的那些片
丰富的查询支持
- MongoDB支持丰富的查询语言,支持读和写操作(CRUD),比如数据聚合、文本搜索和地理空间查询等
其他特点
- 无模式(动态模式)
- 灵活的文档模型
2. 单机部署(Linux)
2.1 下载
官网
版本选择
-
MongoDB的版本命名规范如:x.y.z;
y为奇数时表示当前版本为开发版,如:1.5.2、4.1.13;
y为偶数时表示当前版本为稳定版,如:1.6.3、4.0.10;
z是修正版本号,数字越大越好
-
详细信息:版本选择
2.2安装
1.解压缩
- tar -zxvf mongodb-linux-x86_64-4.0.10.tgz
2.移动解压后的文件夹到指定的目录中
- mv mongodb-linux-x86_64-4.0.10 /usr/local/mongodb
3.新建几个目录,存储数据和日志
-
#数据存储目录 mkdir -p /mongodb/single/data/db #日志存储目录 mkdir -p /mongodb/single/log
4.新建并修改配置文件
-
vim /mongodb/single/mongod.conf
-
一定要注意空格
-
内容:
systemLog: #MongoDB发送所有日志输出的目标指定为文件 ##The path of the log file to which mongod or mongos should send all diagnostic logging information destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/single/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 ##The directory where the mongod instance stores its data.Default Value is "/data/db". dbPath: "/mongodb/single/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true net: #服务实例绑定的IP,默认是localhost bindIp: localhost,192.168.83.133 #bindIp #绑定的端口,默认是27017 port: 27017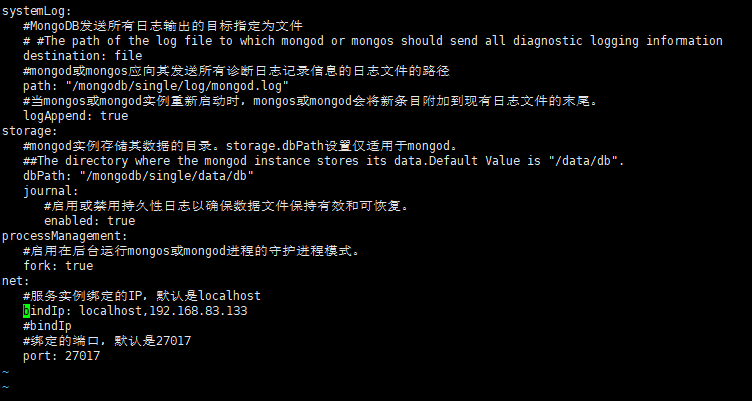
-
5.启动MongoDB服务
- /usr/local/mongodb/bin/mongod -f /mongodb/single/mongod.conf

- 注意:如果启动后不是 successfully ,则是启动失败,原因基本上就是配置文件有问题
- 通过进程查看服务是否启动成功
- ps -ef|grep mongod

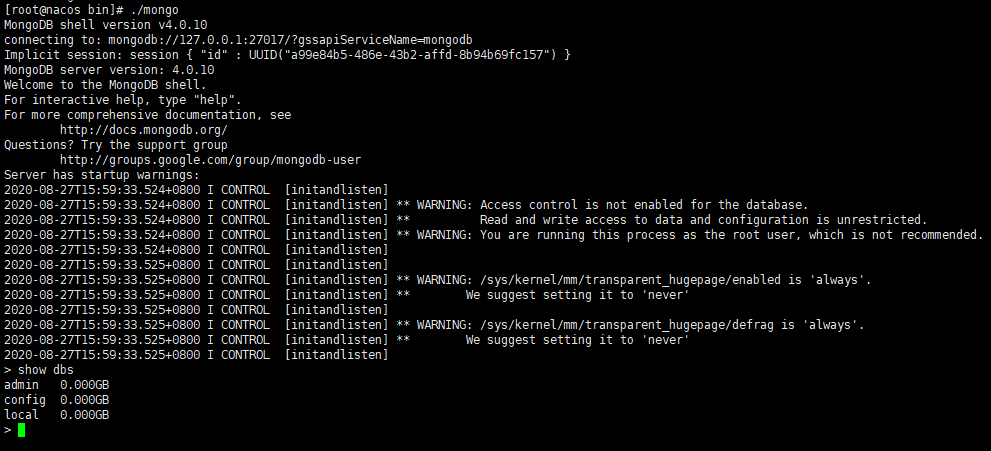
6.测试连接
-
通过mongo命令测试
-
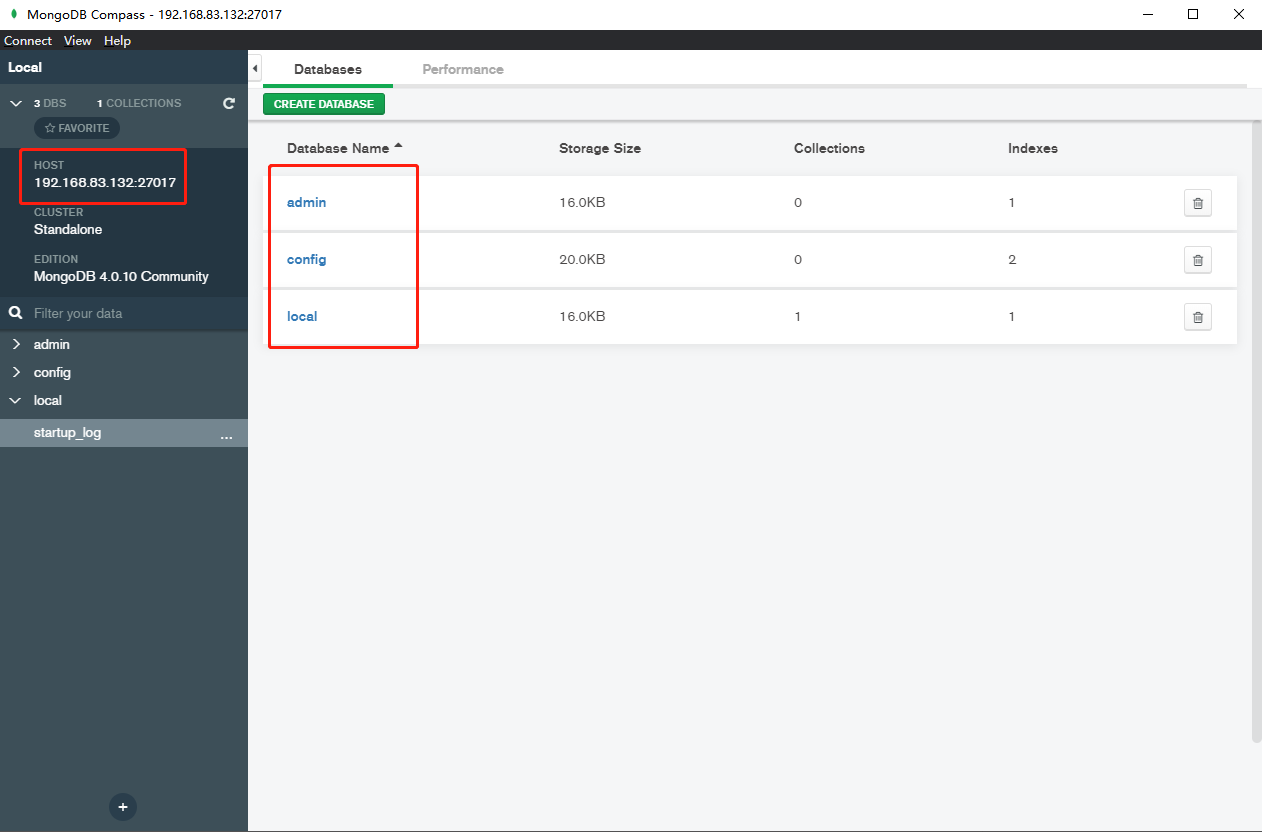
通过compass工具测试
-
注意:防火墙状态设置
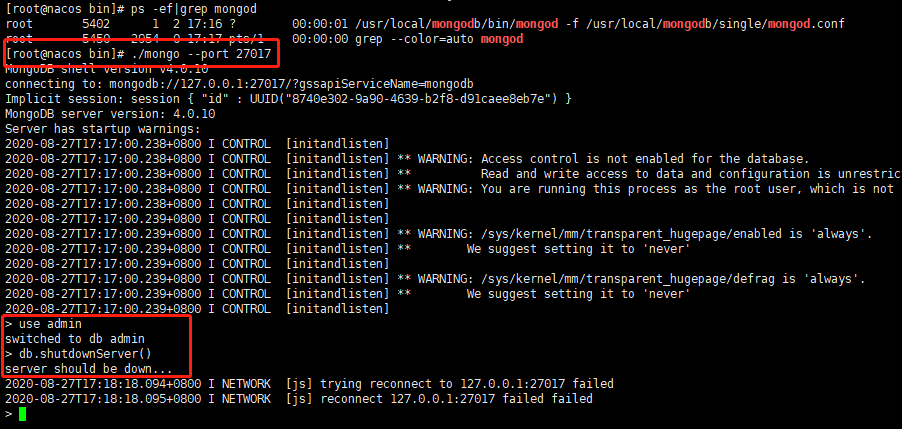
7.服务停止
-
通过mongo客户端中的shutdownServer命令来关闭服务
-
#客户端登录服务,注意,这里通过localhost登录,如果需要远程登录,必须先登录认证才行。 mongo --port 27017 #切换到admin库 use admin #关闭服务 db.shutdownServer() -
3. 基本常用命令(*)
3.1案例需求
-
存放文章评论的数据存放到MongoDB中,数据结构参考如下:
-
数据库:articledb
-
专栏文章评论 comment 字段名称 字段含义 字段类型 备注 _id ID ObjectId或String Mongo的主键字段 articleid 文章ID String content 评论内容 String userid 评论人ID String nickname 评论人昵称 String createdatetime 评论的日期时间 Date likenum 点赞数 Int32 replynum 回复数 Int32 state 状态 String 0:不可见;1可见 parentid 上级ID String 如果为0表示文章的顶级评论
-
-
3.2 数据库操作
3.2.1 选择和创建数据库
-
选择和创建数据库的语法格式
use 数据库名称 -
如果数据库不存在则自动创建,例如,以下语句创建articledb数据库
use articledb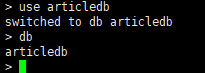
注:这时articledb存在在内存中,还未持久化到磁盘,所有show dbs不会看到articledb
-
查看拥有权限的所有的数据库
show dbs 或 show databases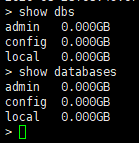
注意:在MongoDB中,集合只有在内容插入后才会创建!创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建
-
查看当前正在使用的数据库命令
dbMongoDB中默认的数据库为test,如果你没有选择数据库,集合将存放在test数据库中
-
另外,数据库名可以是满足以下条件的任意UTF-8字符串
不能是空字符串("")。
不得含有' '(空格)、.、$、/、\和\0 (空字符)。
应全部小写。
最多64字节。
-
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
confifig: 当Mongo用于分片设置时,confifig数据库在内部使用,用于保存分片的相关信息。
3.2.2 数据库的删除
-
MongoDB删除数据库的语法格式如下:
db.dropDatabase()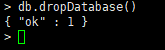
提示:主要用来删除已经持久化的数据库
3.3 集合操作
- 集合,类似关系型数据库中的表,可以显示的创建,也可以隐式的创建
- 集合的命名规范:
- 集合名不能是空字符串""
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾
- 集合名不能以"system."开头,这是为系统集合保留的前缀
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$
3.3.1 集合的显示创建(了解)
-
基本语法格式:
db.createCollection(name) -
示例:创建一个名为mycollection的集合
db.createCollection("mycollection") -
查看当前库中的表
show tables 或 show collections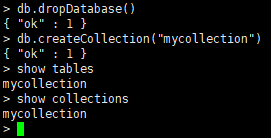
3.3.2 集合的隐式创建
-
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合,详见 3.4.1文档的插入
-
提示:通常我们使用隐式创建文档即可。
3.3.3 集合的删除
-
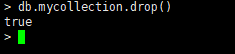
语法格式:
db.集合名.drop() -
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false
3.4 文档基本的CRUD
- 文档(document)的数据结构和 JSON 基本一样,所有存储在集合中的数据都是 BSON 格式
3.4.1 文档的插入
-
单个文档插入
-
使用insert()或save()方法向集合中插入文档,语法如下:
db.collectionName.insert( <document or array of documents>, { writeConcern: <document>, ordered: <boolean> } ) -
参数说明:
Parameter Type Description document document or array 要插入到集合中的文档或文档数组(json格式) writeConcern document Optional. A document expressing the write concern. Omit to use the default write concern,See Write Concern.Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern ordered boolean 可选。如果为真,则按顺序插入数组中的文档,如果其中一个文档出现错误,MongoDB将返回而不处理数组中的其余文档。如果为假,则执行无序插入,如果其中一个文档出现错误,则继续处理数组中的主文档。在版本2.6+中默认为true -
示例:向comment的集合中插入一条测试数据
db.comment.insert({"articleid":"100000","content":"今天天气真好,阳光明 媚","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null}) -
提示:
- comment集合如果不存在,则会隐式创建
- mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了
- 插入当前日期使用 new Date()
- 插入的数据没有指定 _id ,会自动生成主键值
- 如果某字段没值,可以赋值为null,或不写该字段
-
WriteResult({ "nInserted" : 1 }) 说明插入一条数据成功
-
说明:
- 文档中的键/值对是有序的
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)
- MongoDB区分类型和大小写
- MongoDB的文档不能有重复的键
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
-
注意文档键命名规范
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾
- 和$有特别的意义,只有在特定环境下才能使用
- 以下划线"_"开头的键是保留的(不是严格要求的)。

-
-
批量插入
-
语法
db.collection.insertMany( [ <document 1> , <document 2>, ... ], { writeConcern: <document>, ordered: <boolean> } ) -
示例:批量插入多条文章评论
db.comment.insertMany([ {"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我 他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08- 05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"}, {"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔 悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"}, {"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船 长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"}, {"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯 撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"}, {"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫 嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08- 06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"} ]);
-
插入时指定了 _id ,则主键就是该值,
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉
因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理
-
3.4.2 文档的基本查询
-
基本语法
db.collectionName.find(<query>, [projection]) -
参数说明
-
Parameter Type Description query document 可选。使用查询运算符指定选择筛选器。若要返回集合中的所有文档,请省略此参数或传递空文档({}) projection document 可选。指定要在与查询筛选器匹配的文档中返回的字段(投影)。若要返回匹配文档中的所有字段,请省略此参数
-
-
示例:
-
查询所有
db.comment.find() 或 db.comment.find({})这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型
如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型
-
按条件查询(所有)
-
查询userid为1003的记录——只 要在find()中添加参数即可,参数也是json格式,如下:
-
db.comment.find({"userid":"1003"}) -

-
-
按条件查询(唯一)
-
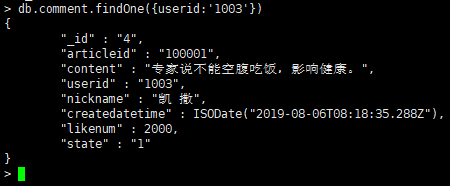
如果你只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现,语法和fifind一样
-
查询用户编号是1003的记录,但只最多返回符合条件的第一条记录
-
db.comment.findOne({userid:'1003'}) -
-
-
投影查询(Projection Query,默认 _id 会显示
-
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)
-
查询结果只显示 _id、userid、nickname ,默认 _id 会显示
-
db.comment.find({userid:"1003"},{userid:1,nickname:1}) -

-
-
投影查询(Projection Query,不显示_id
-
查询结果只显示 、userid、nickname ,不显示 _id
-
db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0}) -

-
-
查询所有,选择字段展示
-
查询所有数据,但只显示 _id、userid、nickname
-
db.comment.find({},{userid:1,nickname:1}) -

-
-
3.4.3 文档的更新
-
基本语法
db.collection.update(query, update, options) //或 db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document>, collation: <document>, arrayFilters: [ <filterdocument1>, ... ], hint: <document|string> // Available starting in MongoDB 4.2 } ) -
参数
Parameter Type Description query document 更新的选择条件。可以使用与fifind()方法中相同的查询选择器,类似sql update查询内where后面的。在3.0版中进行了更改:当使用upsert:true执行update()时,如果查询使用点表示法在_id字段上指定条件,则MongoDB将拒绝插入新文档。 multi boolean 可选。如果设置为true,则更新符合查询条件的多个文档。如果设置为false,则更新一个文档。默认值为false update document or pipeline 要应用的修改。该值可以是:包含更新运算符表达式的文档,或仅包含:对的替换文档,或在MongoDB 4.2中启动聚合管道 upsert boolean 可选。如果设置为true,则在没有与查询条件匹配的文档时创建新文档。默认值为false,如果找不到匹配项,则不会插入新文档 writeConcern document 可选。表示写问题的文档。抛出异常的级别 collation document 可选。指定要用于操作的校对规则。校对规则允许用户为字符串比较指定特定于语言的规则,例如字母大小写和重音标记的规则 arrayFilters array 可选。一个筛选文档数组,用于确定要为数组字段上的更新操作修改哪些数组元素。在更新文档中,使用[标识符])都必须指定一个对应的数组筛选器文档。也就是说,不能为同一标识符指定多个数组筛选器文档。3.6版 hint document or String 可选。指定用于支持查询谓词的索引的文档或字符串。该选项可以采用索引规范文档或索引名称字符串。如果指定的索引不存在,则说明操作错误。例如,请参阅版本4中的“为更新操作指定提示。 主要关注前四个参数即可
-
示例
-
覆盖修改
-
修改_id为1的记录,点赞量为1001
-
db.comment.update({_id:"1"},{likenum:NumberInt(1002)}) -

-
执行后会发现,这条文档除了likenum字段其它字段都不见了
-
-
局部修改
-
为了解决这个问题,需要使用修改器$set来实现,修改_id为2的记录,回复数为889
-
db.comment.update({_id:"2"},{$set:{replynum:NumberInt(889)}}) -

-
-
批量修改
-
更新所有userid为 1003 的用户的昵称为 mongodb
-
//默认只修改第一条数据 db.comment.update({userid:"1003"},{$set:{nickname:"mongodb"}}) //修改所有符合条件的数据 db.comment.update({userid:"1003"},{$set:{nickname:"mongodb"}},{multi:true}) -

-
如果不加参数 {multi:true},则只更新符合条件的第一条记录
-
-
列值增长的修改
-
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现
-
需求:id为3的用户的点赞数,每次递增1
-
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})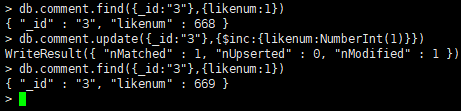
-
-
3.4.4 删除文档
-
基本语法
db.集合名称.remove(条件) -
如果删除_id=1的记录,输入以下语句
db.comment.remove({_id:"1"}) -
以下语句可以将数据全部删除,请慎用
db.comment.remove({})
3.5 文档的分页查询
3.5.1 统计查询
-
统计查询使用count()方法,基本语法:
db.collction.count(query,options) -
参数
Parameter Type Description query document 查询选择条件 options document 可选,用于修改计数的额外选项 -
示例
-
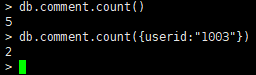
统计comment集合的所有记录数
db.comment.count() -
按条件统计记录数
db.comment.count({userid:"1003"}) -
-
3.5.2 分页列表查询
-
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据
-
基本语法
db.comment.find().limit(Number).skip(Number) -
如果你想返回指定条数的记录,可以在fifind方法后调用limit来返回结果(TopN),默认值20;
skip方法同样接受一个数字参数作为跳过的记录条数,(前N个不要),默认值是0
-
分页查询:需求:每页2个,第二页开始:跳过前两条数据,接着值显示3和4条数据
-
//第一页 显示头两条 db.comment.find().limit(2).skip(2) //第二页 显示3和4 db.comment.find().limit(2).skip(2) //第三页显示第五条 db.comment.find().limit(2).skip(4) -

-
3.5.3 排序查询
-
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列
-
基本语法
db.COLLECTION_NAME.find().sort({KEY:1}) 或 db.COLLECTION_NAME.find().sort(排序方式) -
对userid降序排列,并对访问量进行升序排列
-
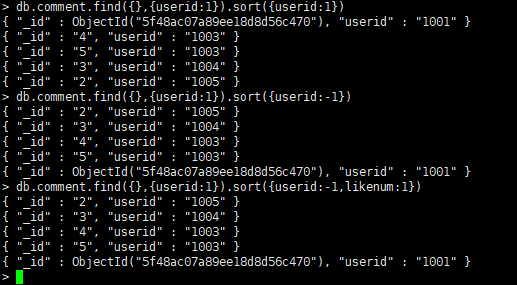
-
注:skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。
3.6 文档的更多查询
3.6.1 正则的复杂查询
-
MongoDB的模糊查询是通过正则表达式的方式实现的
-
基本语法
db.collection.find({field:/正则表达式/}) 或 db.集合.find({字段:/正则表达式/}) -
提示:正则表达式是js的语法,直接量的写法
-
查询评论内容包含“开水”的所有文档
db.comment.find({content:/开水/})
-
要查询评论的内容中以“专家”开头的
db.comment.find({content:/^专家/})
3.6.2 比较查询
-
<, <=, >, >= 这些操作符也是很常用的
-
基本语法
db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value -
查询评论点赞数量大于700的记录
db.comment.find({likenum:{$gt:NumberInt(700)}})
3.6.3 包含查询
-
包含使用$in操作符
-
示例:查询评论的集合中userid字段包含1003或1004的文档
db.comment.find({userid:{$in:["1003","1004"]}})
-
不包含使用$nin操作符
-
示例:查询评论集合中userid字段不包含1003和1004的文档
-
db.comment.find({userid:{$nin:["1003","1004"]}})
3.6.4 条件连接查询
- 同时满足 $and
-
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相 当于SQL的and)
-
基本语法
$and:[ { },{ },{ } ] -
示例:查询评论集合中likenum大于等于700 并且小于2000的文档
-
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lte:NumberInt(2000)}}]}) -

- 或者关系 $or
-
两个以上条件之间是或者的关系,我们使用 $or 操作符进行关联
-
基本语法
$or:[ { },{ },{ } ] -
示例:查询评论集合中userid为1003,或者点赞数小于1000的文档记录
db.comment.find({$or:[{userid:"1003"},{likenum:{$lt:NumberInt(1000)}}]})
3.7 文档间的关系(*)
3.7.1 一对一(one to one)
- 居民身份证(一个居民 对应 一个身份证号)
- 在MongoDB,可以通过内嵌文档的形式体现出一对一的关系

3.7.2 一对多(one to many)
-
用户和订单、文章和评论
-
也可使使用内嵌文档,属性变数组(不推荐)
-
_id 设为属性(*)
-
创建用户、订单集合
//创建users集合 db.users.insert([{username:"xqz"},{username:"zt"}]) //查看用户_id db.users.find() //创建订单集合 db.order.insert({list:["手表","电脑"],user_id:ObjectId("5f4ca33961f254cef4dd0388")}) db.order.insert({list:["西瓜","牛奶"],user_id:ObjectId("5f4ca33961f254cef4dd0388")})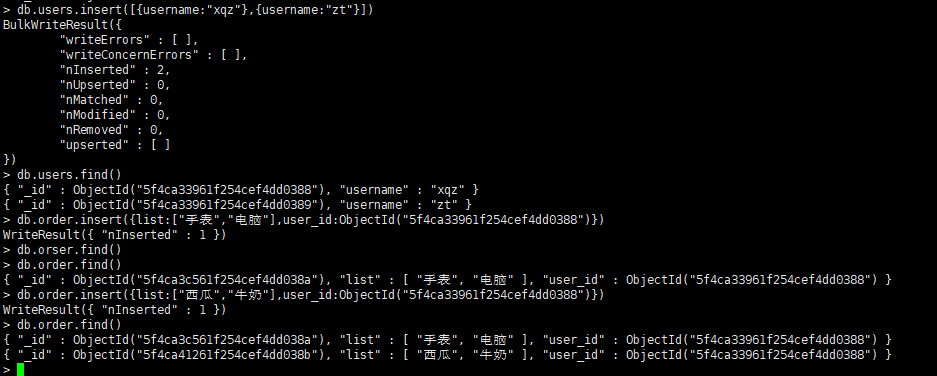
-
查找用户xqz的订单
var user_id=db.users.findOne({username:"xqz"})._id db.order.find({user_id:user_id})
-
3.7.3 多对多(many to many)
-
商品和商品分类、老师和学生
-
类比一对多的_id ,属性变为_ _id 数组
-
创建老师和学生的集合
-
db.teachers.insert([{name:"missLee"},{name:"老师A"},{name:"老师B"}]) //查看老师_id db.teachers.find() //创建学生集合 db.students.insert({stuname:"学生1",tech_ids:[ObjectId("5f4ca7a161f254cef4dd038c"),ObjectId("5f4ca7a161f254cef4dd038d")]}) db.students.insert({stuname:"学生2",tech_ids:[ObjectId("5f4ca7a161f254cef4dd038c"),ObjectId("5f4ca7a161f254cef4dd038e")]}) db.students.insert({stuname:"学生3",tech_ids:[ObjectId("5f4ca7a161f254cef4dd038d"),ObjectId("5f4ca7a161f254cef4dd038e")]}) //查看students db.students.find() -
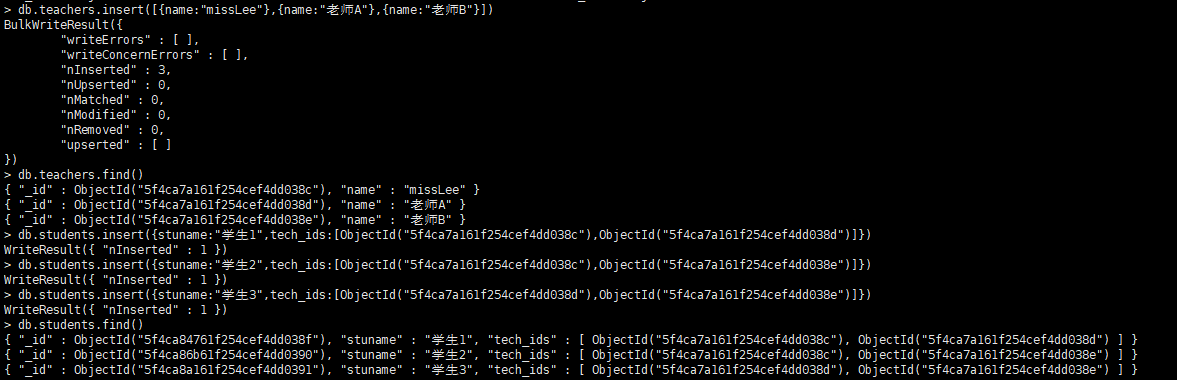
-
3.8 常用命令小结
-
选择切换数据库:use articledb 插入数据:db.comment.insert({bson数据}) 查询所有数据:db.comment.find() 条件查询数据:db.comment.find({条件}) 查询符合条件的第一条记录:db.comment.findOne({条件}) 查询符合条件的前几条记录:db.comment.find({条件}).limit(条数) 查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数) 修改数据:db.comment.update({条件},{修改后的数据}) 或db.comment.update({条件},{$set:{要修改部分的字段:数据}) 修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}}) 删除数据:db.comment.remove({条件}) 统计查询:db.comment.count({条件}) 模糊查询:db.comment.find({字段名:/正则表达式/}) 条件比较运算:db.comment.find({字段名:{$gt:值}}) 包含查询:db.comment.find({字段名:{$in:[值1,值2]}})或db.comment.find({字段名:{$nin:[值1,值2]}}) 条件连接查询:db.comment.find({$and:[{条件1},{条件2}]})或db.comment.find({$or:[{条件1},{条件2}]})
4. 索引-Index
4.1 概述
-
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的
-
如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数。
-
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
-
了解:MongoDB索引使用B树数据结构(确切的说是B-Tree,MySQL是B+Tree)
4.2 索引的类型
4.2.1 单字段索引
- MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引(Single Field Index)
- 对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引
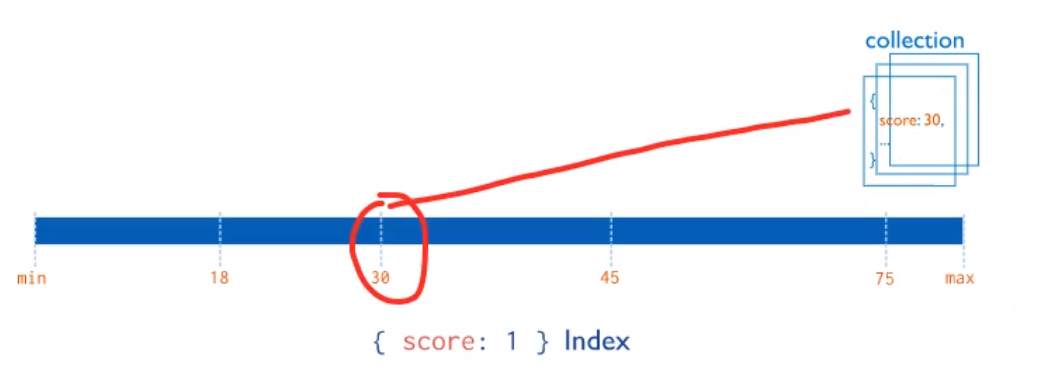
4.2.2 复合索引
- MongoDB还支持多个字段的用户定义索引,即复合索引(Compound Index)
- 复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由 { userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序

4.2.3 其他索引
- 地理空间索引(Geospatial Index)、文本索引(Text Indexes)、哈希索引(Hashed Indexes)
- 地理空间索引(Geospatial Index):为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面几何的二维球面索引
- 文本索引(Text Indexes):MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”),而将集合中的词作为词干,只存储根词
- 哈希索引(Hashed Indexes):为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的值分布更加随机,但只支持相等匹配,不支持基于范围的查询
4.3 索引的管理操作
4.3.1 索引的查看
-
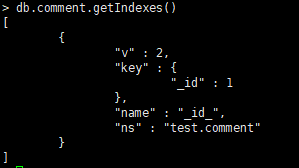
返回一个集合中的所有索引的数组
-
基本语法
db.collection.getIndexes() -
-
默认_id索引:
MongoDB在创建集合的过程中,在 _id 字段上创建一个唯一的索引,默认名字为 id ,该索引可防止客户端插入两个具有相同值的文档,您不能在_id字段上删除此索引。
注意:该索引是唯一索引,因此值不能重复,即 _id 值不能重复的。在分片集群中,通常使用 _id 作为片键
4.3.2 索引的创建
-
基本语法:
db.collection.createIndex(keys,options) -
参数
Parameter Type Description keys document 包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型。对于字段上的升序索引,请指定值1;对于降序索引,请指定值-1。比如: {字段:1或-1} ,其中1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。另外,MongoDB支持几种不同的索引类型,包括文本、地理空间和哈希索引 options document 可选。包含一组控制索引创建的选项的文档。有关详细信息,请参见选项详情列表 -
options(更多选项)列表
- unique Boolean 建立的索引是否唯一,默认为false
- name String 索引的名称,如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称
-
单字段索引示例:对userid字段建立索引
db.comment.createIndex({userid:1})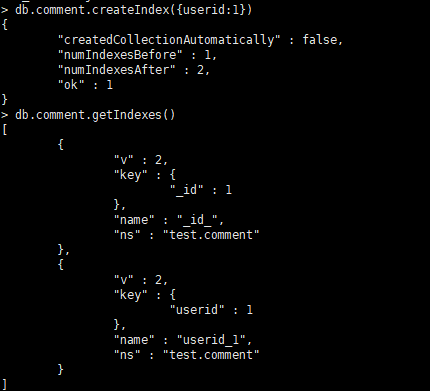
-
复合索引示例:对 userid 和 nickname 同时建立复合(Compound)索引
db.comment.createIndex({userid:1,nickname:-1})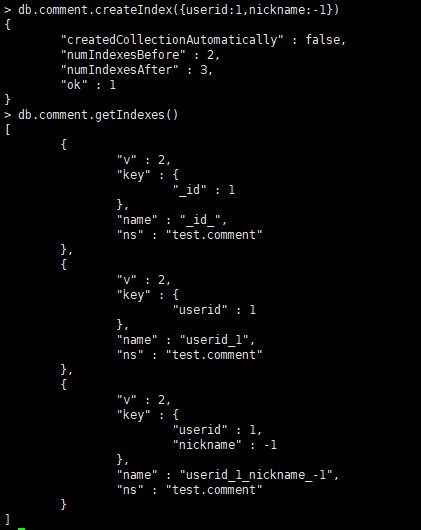
4.3.3 索引的移除
-
可以移除指定的索引,或移除所有索引
-
基本语法
db.collection.dropIndex(index)指定要删除的索引,可以通过索引名称或者索引规范文档指定索引,若要删除文本索引,请指定索引名称
-
示例:删除comment集合中userid字段上的升序索引
db.comment.drop({userid:1})删除所有索引
db.collection.dropIndexes() -
提示:_id 的字段的索引是无法删除的,只能删除非 _id 字段的索引。
4.4 索引的使用
4.4.1 执行计划
-
分析查询性能(Analyze Query Performance)通常使用执行计划(解释计划、Explain Plan)来查看查询的情况,如查询耗费的时间、是否基于索引查询等
-
那么通常想知道建立的索引是否有效,效果如何,都需要通过执行计划查看
-
基本语法
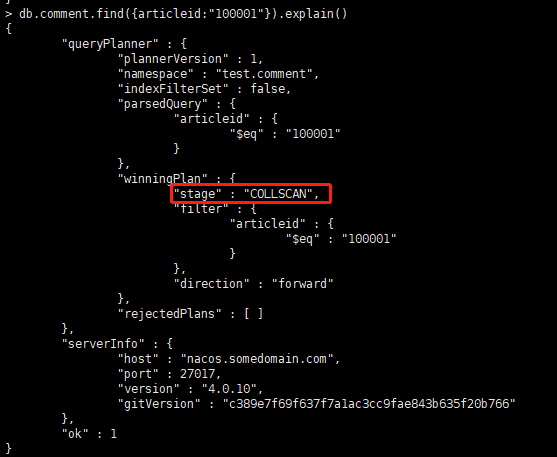
db.collection.find(query,options).explain(options)-
stage:"COLLSCAN" 全集合扫描
-
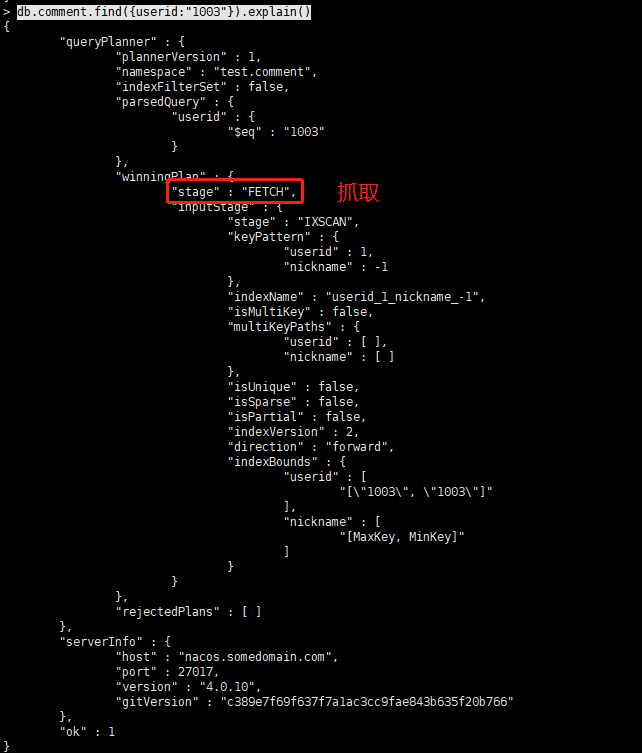
添加索引之后
db.comment.find({userid:"1003"}).explain()stage:"FETCH"
-
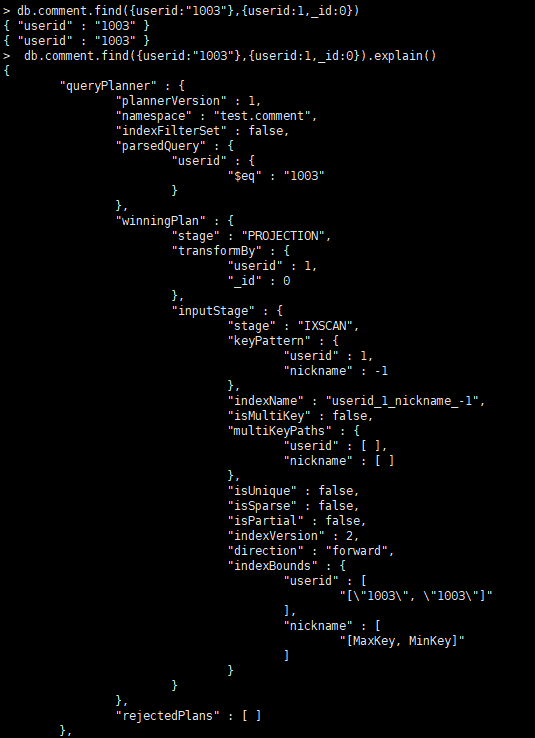
4.4.2 涵盖的查询
-
Covered Queries
-
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。 这些覆盖的查询可以非常有效
-

-
5. 文章评论(练习)
5.1 需求分析
- 基本增删改查API
- 根据文章id查询评论
- 评论点赞
5.2 表结构分析
-
专栏文章评论 comment 字段名称 字段含义 字段类型 备注 _id ID ObjectId或String Mongo的主键字段 articleId 文章id String content 评论内容 String userid 评论人Id String nickname 评论人昵称 String createdatetime 创建日期 Date likenum 点赞数 Int32 replynum 回复数 Int32 state 状态 String 0:不可见;1:可见 parentid 上级id String 如果为0表示文章的顶级评论
5.3 技术选型
5.3.1 mongodb-driver(了解)
- mongodb-driver是mongo官方推出的java连接mongoDB的驱动包,相当于JDBC驱动。我们通过一个入门的案例来了解mongodb-driver的基本使用
- 官方驱动说明和下载
- 官方驱动示例文档
5.3.2 SpringDataMongoDB
- SpringData家族成员之一,用于操作MongoDB的持久层框架,封装了底层的mongodb-driver
- 官网
5.4 文章微服务模块搭建
-
新建mavne工程
-
编写pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.0.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>org.example</groupId> <artifactId>com.touchair.article</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> </dependencies> </project> -
创建application.yml
server: port: 7777 spring: #数据源配置 data: mongodb: # 主机地址 host: 192.168.83.133 # 默认端口是27017 port: 27017 # 数据库 database: test #也可以使用uri连接 # uri: mongodb://192.168.83.133:27017/test -
创建启动类ArticleMain
@SpringBootApplication public class ArticleMain { public static void main(String[] args) { SpringApplication.run(ArticleMain.class, args); } } -
启动项目,看是否能正常启动
-
创建实体类 包下建包po用于存放实体类 com.touchair.article.po.Comment
//把一个java类声明为mongodb的文档,可以通过collection参数指定这个类对应的文档。 // @Document(collection="mongodb 对应 collection 名") // 若未加 @Document ,该 bean save 到 mongo 的 comment collection // 若添加 @Document ,则 save 到 comment collection //可以省略,如果省略,则默认使用类名小写映射集合 @Document(collection="comment") @Getter @Setter @ToString //复合索引 @CompoundIndex( def = "{'userid': 1, 'nickname': -1}") public class Comment implements Serializable { /** * 主键标识,该属性的值会自动对应mongodb的主键字段"_id",如果该属性名就叫“id”,则该注解可以省略,否则必须写 */ @Id private String id; /** * 该属性对应mongodb的字段的名字,如果一致,则无需该注解 * 吐槽内容 */ @Field("content") private String content; /** * 发布日期 */ private Date publishtime; /** * 发布人ID */ @Indexed private String userid; /** * 昵称 */ private String nickname; /** * 评论的日期时间 */ private LocalDateTime createdatetime; /** * 点赞数 */ private Integer likenum; /** * 回复数 */ private Integer replynum; /** * 状态 */ private String state; /** * 上级ID */ private String parentid; /** * 文章id */ private String articleid; }说明:索引可以大大提升查询效率,一般在查询字段上添加索引,索引的添加可以通过Mongo的命令来添加,也可以在Java的实体类中通过注解添加;
单字段索引注解@Indexed
复合索引注解@CompoundIndex
-
创建数据访问接口 com.touchair.article.dao.CommentRepository
public interface CommentRepository extends MongoRepository<Comment,String> { /** * 自定义接口 根据父级id 返回分页结果 * @param parentid * @param pageable * @return */ Page<Comment> findByParentid(String parentid, Pageable pageable); } -
创建评论业务层接口以及实现类 com.touchair.article.service.CommentService、com.touchair.article.service.impl.CommentServiceImpl
public interface CommentService { /** * 查询所有评论 * @return */ List<Comment> findCommentList(); /** * 保存评论 *如果需要自定义主键,可以在这里指定主键;如果不指定主键,MongoDB会自动生成主键 * @param comment */ void saveComment(Comment comment); /** * 更新评论 * * @param comment */ void updateComment(Comment comment); /** * 根据id删除评论 * * @param id */ void deleteCommentById(String id); /** * 根据id查询评论 * * @param id * @return */ Comment findCommentById(String id); /** * 根据父级id 获取分页结果 * * @param parentid * @param page * @param size * @return */ Page<Comment> findCommentListByParentid(String parentid, int page, int size); /** * 点赞数增加 * * @param id */ void updateContentLikenum(String id); }@Service public class CommentServiceImpl implements CommentService { @Resource private CommentRepository commentRepository; @Override public List<Comment> findCommentList() { return commentRepository.findAll(); } @Override public void saveComment(Comment comment) { commentRepository.save(comment); } @Override public void updateComment(Comment comment) { commentRepository.save(comment); } @Override public void deleteCommentById(String id) { commentRepository.deleteById(id); } @Override public Comment findCommentById(String id) { return commentRepository.findById(id).get(); } @Override public Page<Comment> findCommentListByParentid(String parentid, int page, int size) { return commentRepository.findByParentid(parentid, PageRequest.of(page-1, size)); } @Override public void updateContentLikenum(String id) { //查询条件 Query query = Query.query(Criteria.where("_id").is(id)); //更新对象 Update update=new Update(); //局部更新,相当于$set // update.set(key,value) // 递增$inc // update.inc("likenum",1) update.inc("likenum"); //参数1:查询对象 // 参数2:更新对象 // 参数3:集合的名字或实体类的类型Comment.class mongoTemplate.updateFirst(query, update, Comment.class); } } -
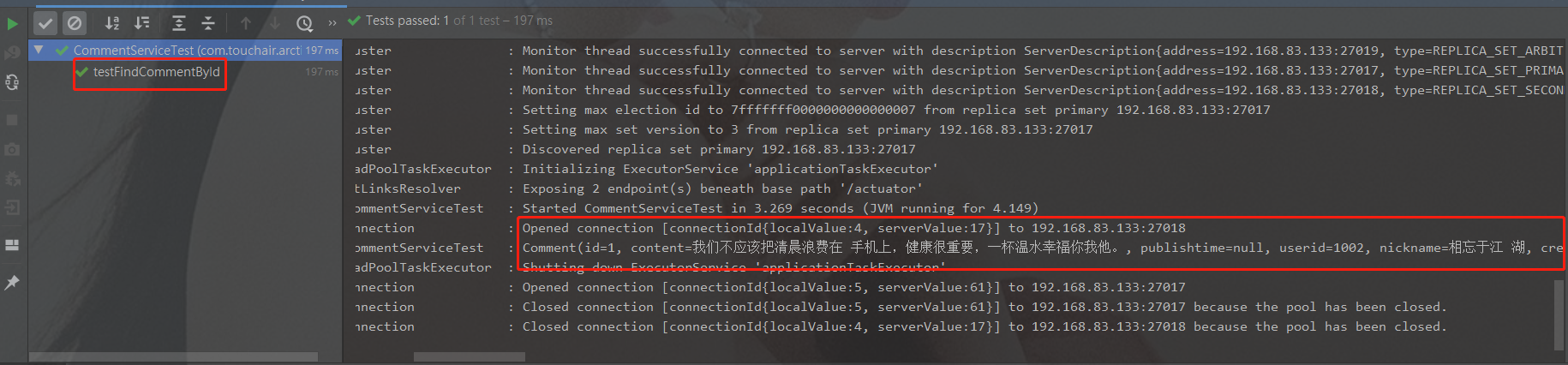
创建Junit测试类 com.touchair.article.CommentServiceTest
//集成JUnit @RunWith(SpringRunner.class) //测试环境初始化 @SpringBootTest(classes = ArticleMain.class) @Slf4j public class CommentServiceTest { @Resource private CommentService commentService; /** * 测试获取集合所有文档记录 */ @Test public void testFindCommentList(){ log.info(commentService.findCommentList().toString()); } /** * 测试根据id获取文档记录 */ @Test public void testFindCommentById(){ log.info(commentService.findCommentById("1").toString()); } /** * 测试新增一个评论 */ @Test public void testSaveComment(){ Comment comment=new Comment(); comment.setArticleid("100012"); comment.setContent("带父级的测试数据3"); comment.setCreatedatetime(LocalDateTime.now()); comment.setUserid("10012"); comment.setNickname("mongodb parentid test"); comment.setState("1"); comment.setLikenum(0); comment.setReplynum(0); comment.setParentid("3"); commentService.saveComment(comment); } /** * 测试根据父级id返回分页结果 */ @Test public void testFindCommentListByParentid(){ Page<Comment> commentListByParentid = commentService.findCommentListByParentid("3", 1, 2); log.info(commentListByParentid.getContent().toString()); log.info(commentListByParentid.getTotalElements()+""); log.info(commentListByParentid.getTotalPages()+""); } /** * 测试点赞数+1 */ @Test public void testUpdateContentLikenum(){ commentService.updateContentLikenum("1"); } }
5.5 根据上级id查询文章评论的分页列表
- findCommentListByParentid
5.6 MongoTemplate实现评论点赞
-
CommentService 新增updateCommentThumbupToIncrementingOld方法
/*** 点赞-效率低 * @param id */ public void updateCommentThumbupToIncrementingOld(String id) { Comment comment = CommentRepository.findById(id).get(); comment.setLikenum(comment.getLikenum()+1); CommentRepository.save(comment); }以上方法虽然实现起来比较简单,但是执行效率并不高,因为我只需要将点赞数加1就可以了,没必要查询出所有字段修改后再更新所有字段(蝴蝶效应)
-
可以使用MongoTemplate类来实现对某列的操作
-
public void updateContentLikenum(String id) { //查询条件 Query query = Query.query(Criteria.where("_id").is(id)); //更新对象 Update update=new Update(); //局部更新,相当于$set // update.set(key,value) // 递增$inc // update.inc("likenum",1) update.inc("likenum"); //参数1:查询对象 // 参数2:更新对象 // 参数3:集合的名字或实体类的类型Comment.class mongoTemplate.updateFirst(query, update, Comment.class); } -
测试结果
-
MongoDB集群和安全
6. 副本集-Replica Sets(*)
6.1 简介
-
MongoDB中的副本集(Replica Set)是一组维护相同数据集的mongod服务。 副本集可提供冗余和高
可用性,是所有生产部署的基础
也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异
步同步,从而使多台机器拥有同一数据的多个副本,并且当主库当掉时在不需要用户干预的情况下自动
切换其他备份服务器做主库。而且还可以利用副本服务器做只读服务器,实现读写分离,提高负载
-
冗余和数据可用性
复制提供冗余并提高数据可用性。 通过在不同数据库服务器上提供多个数据副本,复制可提供一定级别
的容错功能,以防止丢失单个数据库服务器
在某些情况下,复制可以提供增加的读取性能,因为客户端可以将读取操作发送到不同的服务上, 在不
同数据中心维护数据副本可以增加分布式应用程序的数据位置和可用性。 您还可以为专用目的维护其他
副本,例如灾难恢复,报告或备份
-
MongoDB中的复制
副本集是一组维护相同数据集的mongod实例。 副本集包含多个数据承载节点和可选的一个仲裁节点。
在承载数据的节点中,一个且仅一个成员被视为主节点,而其他节点被视为次要(从)节点
主节点接收所有写操作。 副本集只能有一个主要能够确认具有{w:“most”}写入关注的写入; 虽然在某
些情况下,另一个mongod实例可能暂时认为自己也是主要的。主要记录其操作日志中的数据集的所有
更改,即oplog辅助(副本)节点复制主节点的oplog并将操作应用于其数据集,以使辅助节点的数据集反映主节点的数据集。 如果主要人员不在,则符合条件的中学将举行选举以选出新的主要人员
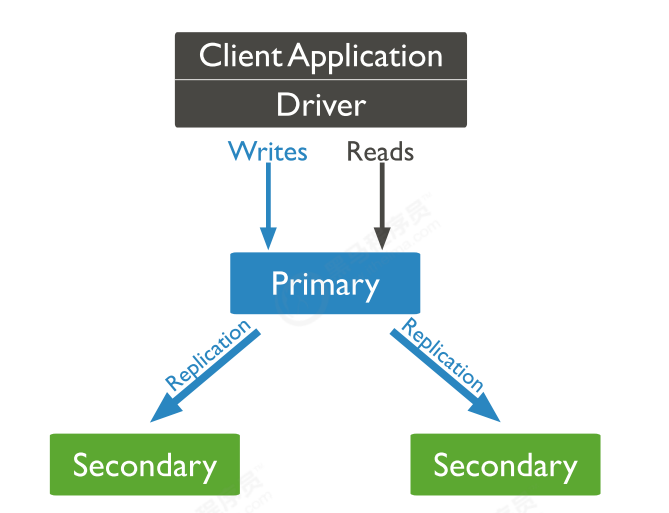
-
主从复制和副本集区别
主从集群和副本集最大的区别就是副本集没有固定的“主节点”;整个集群会选出一个“主节点”,当其挂
掉后,又在剩下的从节点中选中其他节点为“主节点”,副本集总有一个活跃点(主、primary)和一个或多
个备份节点(从、secondary)
-
6.2 副本集的三个角色
-
副本集有两种类型三种角色
-
两种类型
- 主节点(Primary)类型:数据操作的主要连接点,可读写
- 次要(辅助、从)节点(Secondaries)类型:数据冗余备份节点,可以读或选举
-
三种角色
- 主要成员(Primary):主要接受所有写操作,就是主节点
- 副本成员(Replicate):从节点通过复制操作以维护相同的数据集,即备份数据,不可写操作,但可以读操作(需额外配置),默认是一种从节点类型
- 仲裁者(Arbiter):不保留任何数据的副本,只具有投票选举作用。当然也可以将冲裁服务器维护为一个副本集的一部分,即副本成员同时也可以是仲裁者,也是一种从节点类型
-
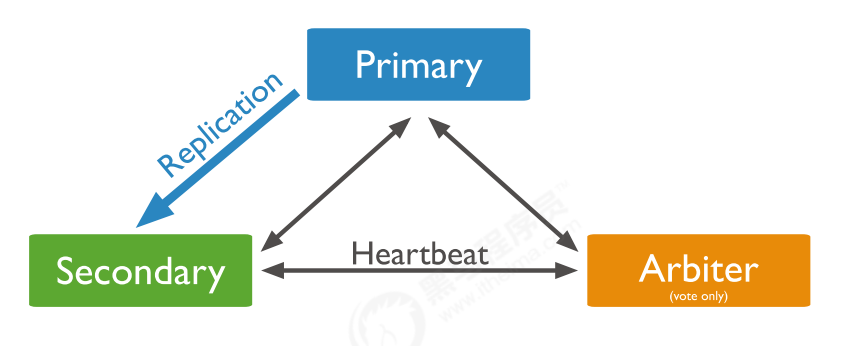
-
关于仲裁者的额外说明:
您可以将额外的mongod实例添加到副本集作为仲裁者。 仲裁者不维护数据集。 仲裁者的目的是通过
响应其他副本集成员的心跳和选举请求来维护副本集中的仲裁。 因为它们不存储数据集,所以仲裁器可
以是提供副本集仲裁功能的好方法,其资源成本比具有数据集的全功能副本集成员更便宜。
如果您的副本集具有偶数个成员,请添加仲裁者以获得主要选举中的“大多数”投票。 仲裁者不需要专用
硬件。
仲裁者将永远是仲裁者,而主要人员可能会退出并成为次要人员,而次要人员可能成为选举期间的主要
人员
如果你的副本+主节点的个数是偶数,建议加一个仲裁者,形成奇数,容易满足大多数的投票
如果你的副本+主节点的个数是奇数,可以不加仲裁者
6.3 副本集架构目标
-
一主一副本一仲裁
-
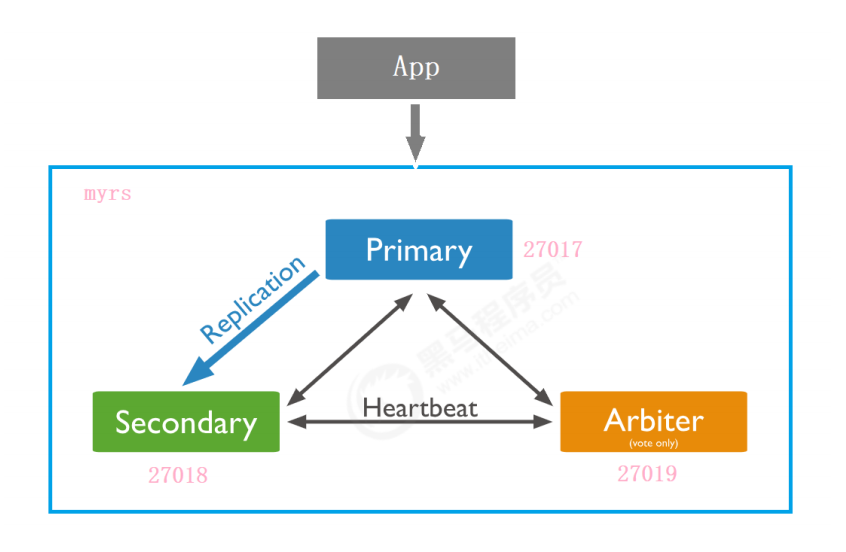
6.4 副本集的创建
6.4.1 第一步:创建主节点
-
建立存放数据和日志的目录
#-----------myrs #主节点 mkdir -p /mongodb/replica_sets/myrs_27017/log \ & mkdir -p /mongodb/replica_sets/myrs_27017/data/db -
新建或修改配置文件
vim /mongodb/replica_sets/myrs_27017/mongod.conf -
myrs_27017 mongod.conf(注意空格)
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/replica_sets/myrs_27017/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 dbPath: "/mongodb/replica_sets/myrs_27017/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/replica_sets/myrs_27017/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27017 replication: #副本集的名称 replSetName: myrs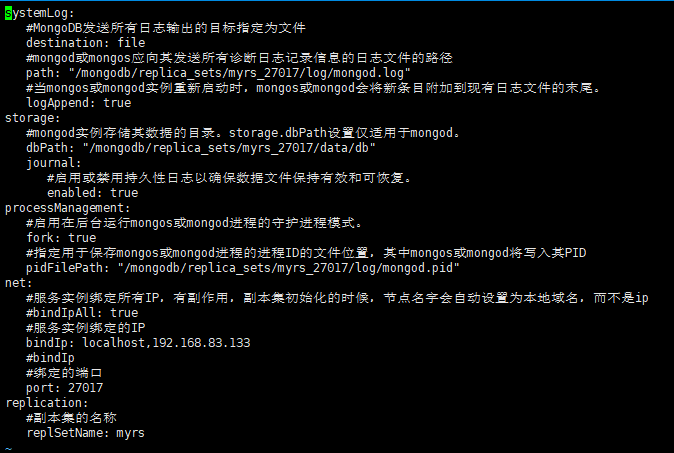
6.4.2 第二步:创建副本节点
-
建立存放数据和日志的目录 27018
#副本节点 mkdir -p /mongodb/replica_sets/myrs_27018/log \ & mkdir -p /mongodb/replica_sets/myrs_27018/data/db -
新建或修改配置文件
vim /mongodb/replica_sets/myrs_27018/mongod.conf -
myrs_27018 mongod.conf(注意空格)
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/replica_sets/myrs_27018/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 dbPath: "/mongodb/replica_sets/myrs_27018/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/replica_sets/myrs_27018/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27018 replication: #副本集的名称 replSetName: myrs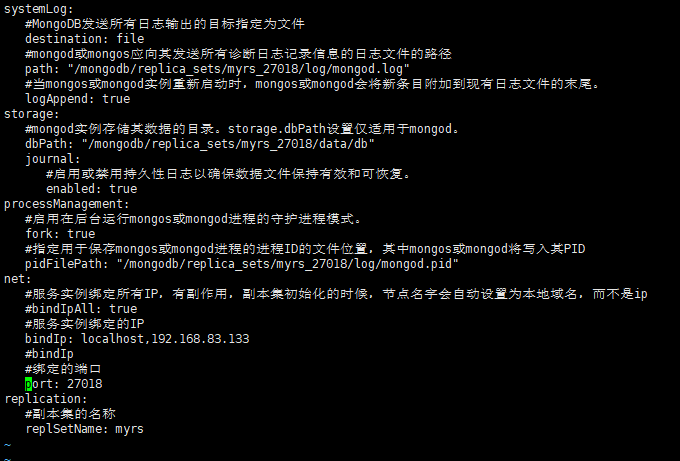
6.4.3 第三步:创建冲裁节点
-
建立存放数据和日志的目录 27019
#-----------myrs #仲裁节点 mkdir -p /mongodb/replica_sets/myrs_27019/log \ & mkdir -p /mongodb/replica_sets/myrs_27019/data/db -
仲裁节点,新建或修改配置文件
vim /mongodb/replica_sets/myrs_27019/mongod.conf -
myrs_27019 mongod.conf
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/replica_sets/myrs_27019/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 dbPath: "/mongodb/replica_sets/myrs_27019/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/replica_sets/myrs_27019/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27019 replication: #副本集的名称 replSetName: myrs
6.4.4 第四步:初始化配置副本集和主节点
-
启动三个节点
-
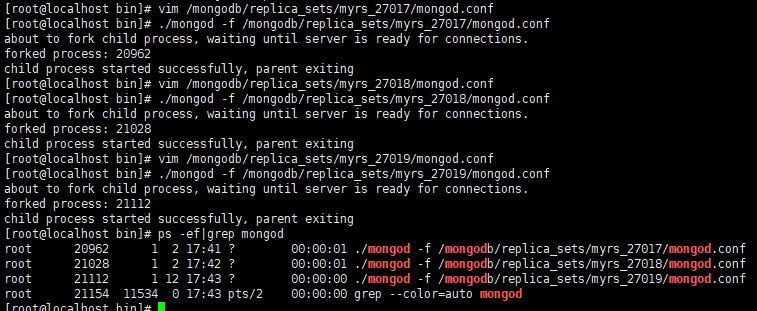
./mongod -f /mongodb/replica_sets/myrs_27017/mongod.conf ./mongod -f /mongodb/replica_sets/myrs_27018/mongod.conf ./mongod -f /mongodb/replica_sets/myrs_27019/mongod.conf ps -ef|grep mongod -
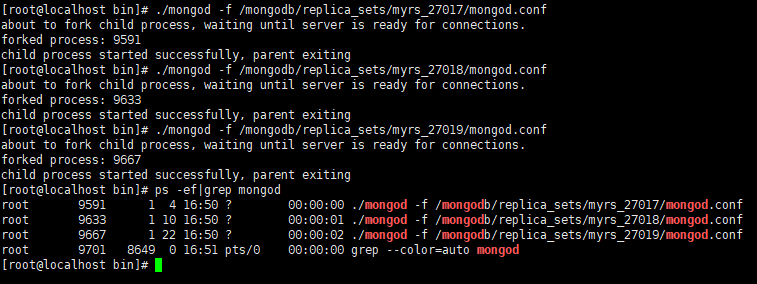
-
使用客户端命令连接任意一个节点,但这里尽量要连接主节点(27017节点)
./mongo --port 27017连接上之后,很多命令无法使用,,比如 show dbs 等,必须初始化副本集才行
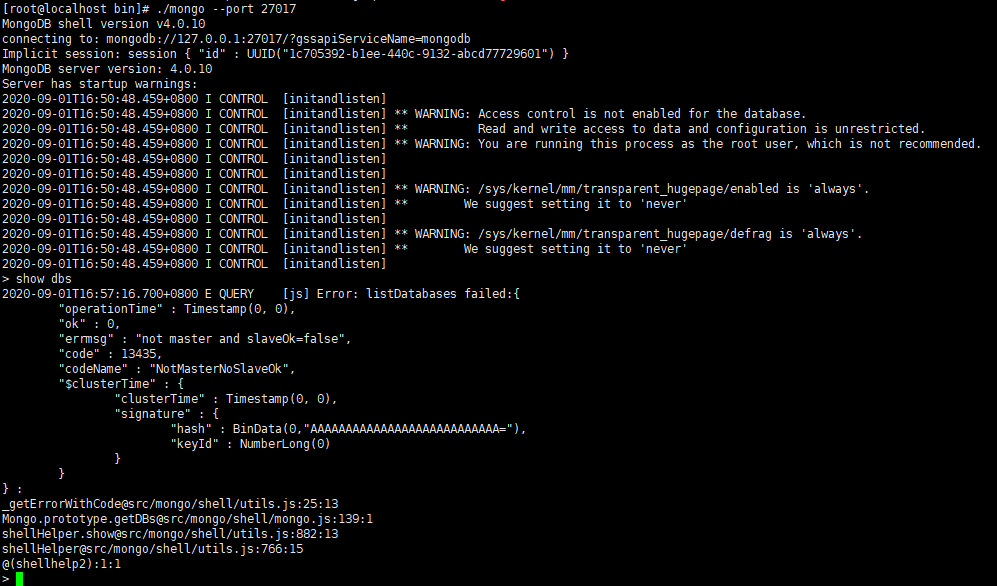
-
准备初始化新的副本集
语法:
rs.initiate(configuration)使用默认配置初始化副本集:
rs.initiate()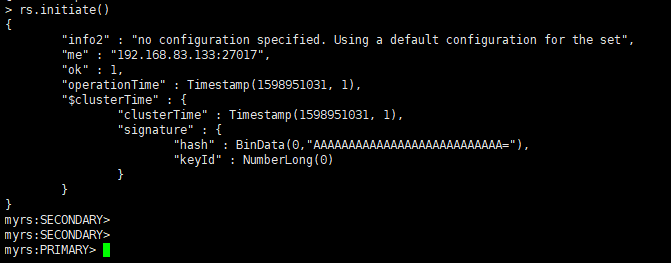
6.4.5 查看副本集配置
-
返回包含当前副本集配置的文档
-
语法:
rs.conf(configuration) -
使用默认,查看主节点配置:
rs.conf()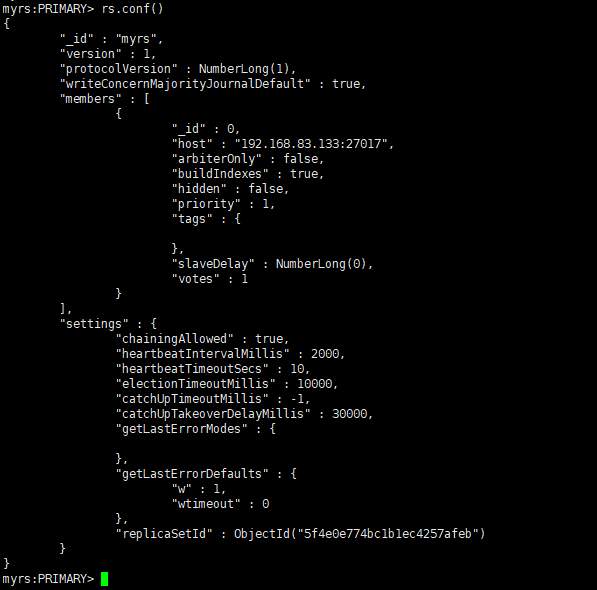
-
说明
-
"_id" : "myrs" :副本集的配置数据存储的主键值,默认就是副本集的名字
-
"members" :副本集成员数组,此时只有一个: "host" : "192.168.83.133:27017" ,该成员不
是仲裁节点: "arbiterOnly" : false ,优先级(权重值): "priority" : 1
-
"settings" :副本集的参数配置
-
-
rs.status()查看节点当前运行状态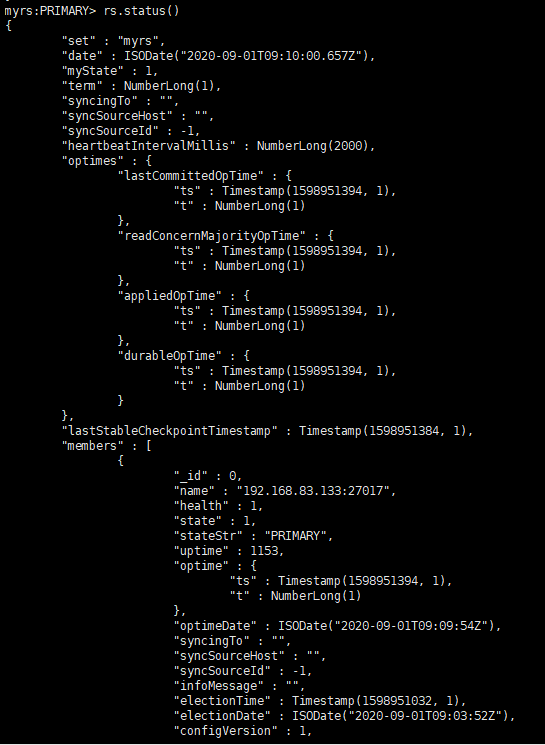
6.4.6 添加副本从节点
-
在主节点添加从节点,将其它成员加入到副本集
-
语法:
rs.add(host,arbiterOnly) -
参数解释说明
-
host Stirng or Document 要添加到副本集的新成员。 指定为字符串或配置文档:1)如
果是一个字符串,则需要指定新成员的主机名和可选的端口号;2)如果是一个文档,请指定在members数组中找到的副本集成员配置文档。 您必须在成员配置文档中指定主机字段。有关文档配置字段的说明,详见下方文档:主机成员的配置文档
-
arbiterOnly boolean 可选的。 仅在
值为字符串时适用。 如果为true,则添 加的主机是仲裁者
-
-
rs.add("192.168.83.133:27018")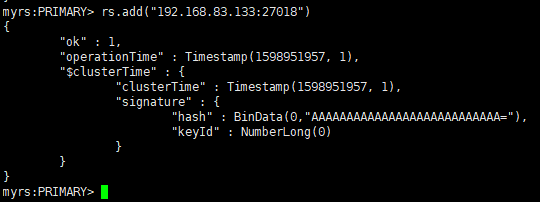
"ok" : 1 :说明添加成功
-
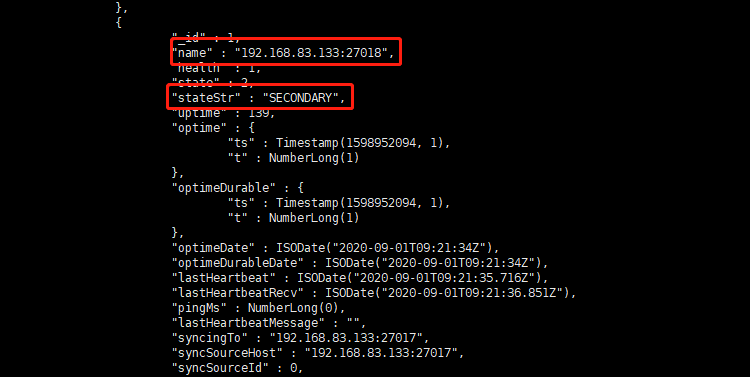
查看副本集状态
rs.status()"name" : "192.168.83.133:27018" 是第二个节点的名字,其角色是 "stateStr" : "SECONDARY"
6.4.7 添加仲裁从节点
-
添加一个仲裁节点到副本集
-
语法:rs.addArb(host)
-
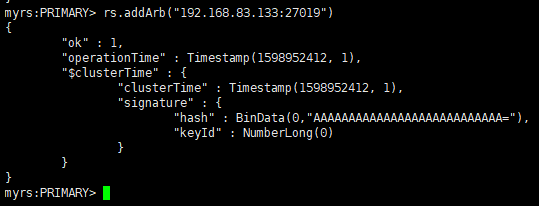
"ok" : 1 :说明添加成功
-
查看副本集状态
rs.status()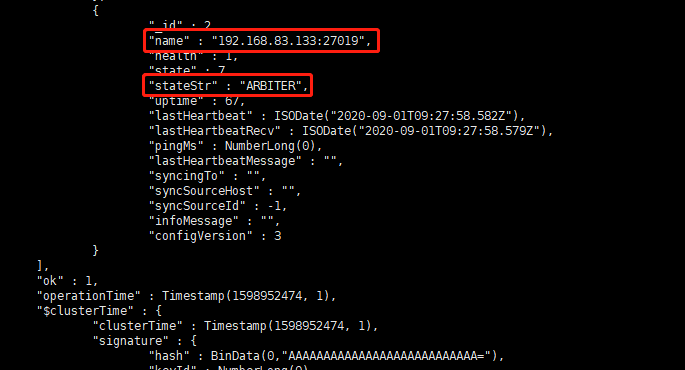
6.5 副本集的数据读写操作
-
目标:测试三个不同角色的节点的数据读写情况
-
登录主节点27017,写入和读取数据
use articledb db.comment.insert({"articleid":"100000","content":"今天天气真好,阳光 明媚","userid":"1001","nickname":"Rose","createdatetime":new Date()}) db.comment.find()
-
登录从节点27018
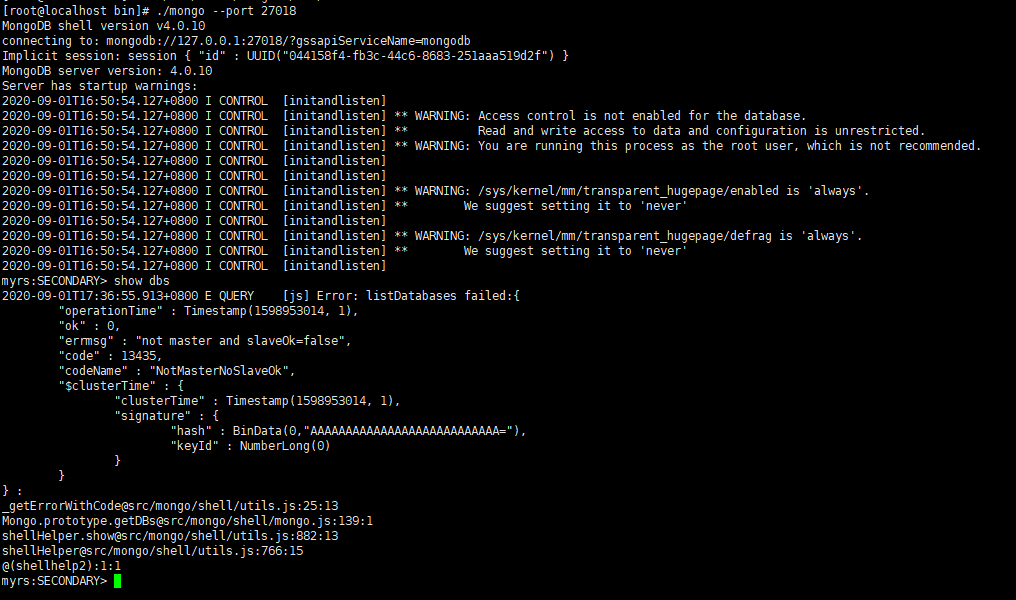
发现,不能读取集合的数据。当前从节点只是一个备份,不是奴隶节点,无法读取数据,写当然更不
行。因为默认情况下,从节点是没有读写权限的,可以增加读的权限,但需要进行设置
-
设置读操作权限:设置为奴隶节点,允许在从成员上运行读的操作
语法
rs.slaveOk() #或 rs.slaveOk(true)该命令是 db.getMongo().setSlaveOk() 的简化命令
-
执行成功,具备读的权限,但仍然不允许插入
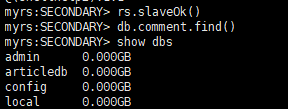

-
现在可实现了读写分离,让主插入数据,让从来读取数据
-
取消作为奴隶节点的读权限:
rs.slaveOk(false) -
仲裁者节点,不存放任何业务数据的,可以登录查看
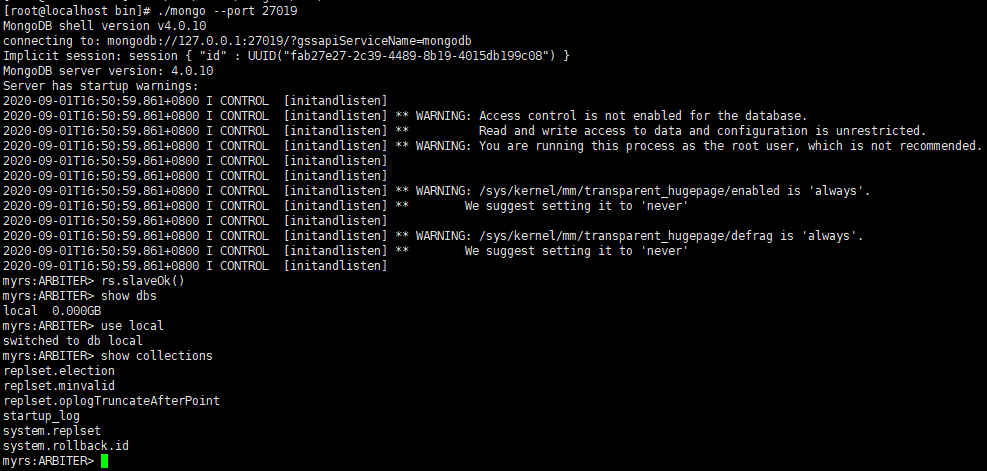
6.6 主节点的选举规则
-
MongoDB在副本集中,会自动进行主节点的选举,主节点选举的触发条件
- 主节点故障
- 主节点网络不可达(默认心跳信息为10秒)
- 人工干预(rs.stepDown(600))
-
一旦触发选举,就要根据一定规则来选主节点,选举规则是根据票数来决定谁获胜
-
票数最高,且获得了“大多数”成员的投票支持的节点获胜
“大多数”的定义为:假设复制集内投票成员数量为N,则大多数为 N/2 + 1。例如:3个投票成员,
则大多数的值是2。当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary,
复制集将无法提供写服务,处于只读状态
-
若票数相同,且都获得了“大多数”成员的投票支持的,数据新的节点获胜
数据的新旧是通过操作日志oplog来对比的
-
在获得票数的时候,优先级(priority)参数影响重大
可以通过设置优先级(priority)来设置额外票数。优先级即权重,取值为0-1000,相当于可额外增加
0-1000的票数,优先级的值越大,就越可能获得多数成员的投票(votes)数。指定较高的值可使成员
更有资格成为主要成员,更低的值可使成员更不符合条件。
默认情况下,优先级的值是1
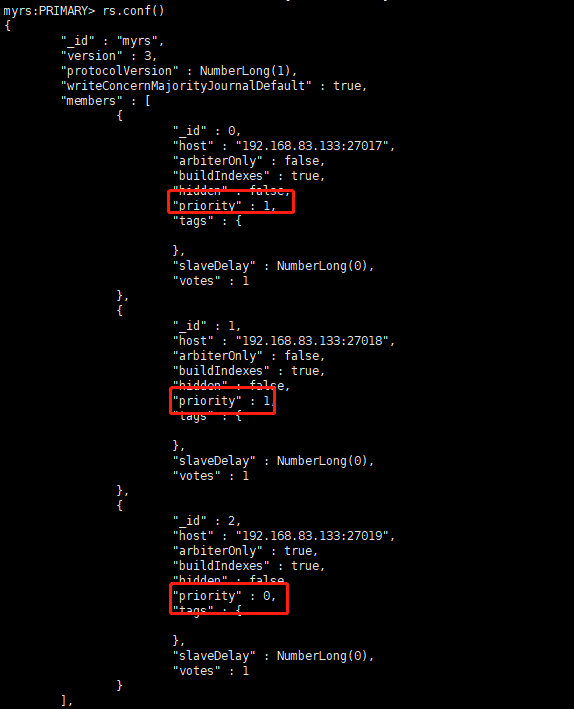
可以看出,主节点和副本节点的优先级各为1,即,默认可以认为都已经有了一票。但选举节点,优先
级是0,(要注意是,官方说了,选举节点的优先级必须是0,不能是别的值。即不具备选举权,但具有
投票权)
-
6.7 故障测试(*)
6.7.1 副本节点故障测试
-
关闭27018副本节点
-
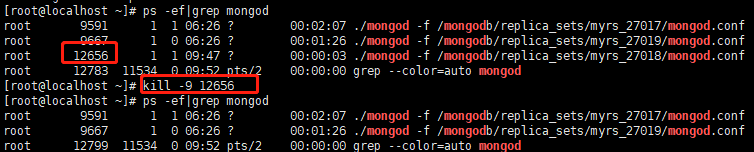
-
主节点和仲裁节点对27018的心跳失败,因为主节点还在,因此没有触发投票选举
-
如果此时,主节点写入数据
db.comment.insert({"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在 手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江 湖","createdatetime":new Date("2019-08- 05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"})主节点插入读取一切正常

-
再次启动从节点,会发现主节点写入的数据会自动同步到从节点
再次启动27018服务

副本节点数据自动同步

-
6.7.2 主节点故障测试
-
关闭27017主节点,触发投票选举
-
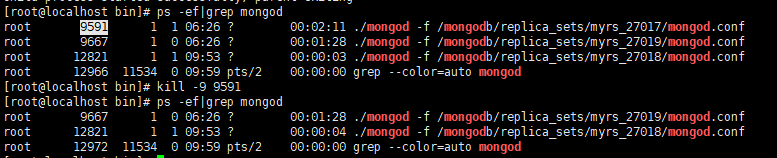
-

-
发现,从节点和仲裁节点对27017的心跳失败,当失败超过10秒,此时因为没有主节点了,会自动发起
投票。而副本节点只有27018,因此,候选人只有一个就是27018,开始投票。27019向27018投了一票,27018本身自带一票,因此共两票,超过了“大多数”27019是仲裁节点,没有选举权,27018不向其投票,其票数是0
-
-
结果:27018成为主节点,具备读写功能
-
27018 退出重新进入,会发现自动转为主节点
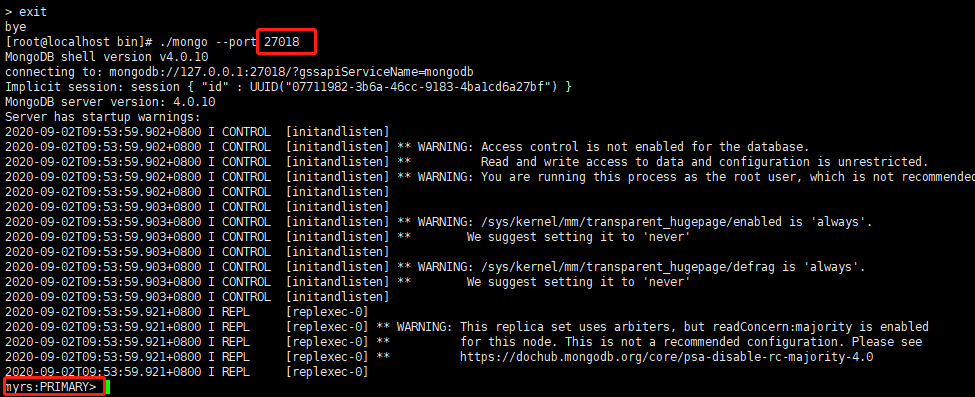
-
读写成功

-
这时候再次启动之前宕机的主节点21017,发现27017变成了从节点,27018仍保持主节点。登录27017节点,发现是从节点了,数据自动从27018同步,从而实现高可用

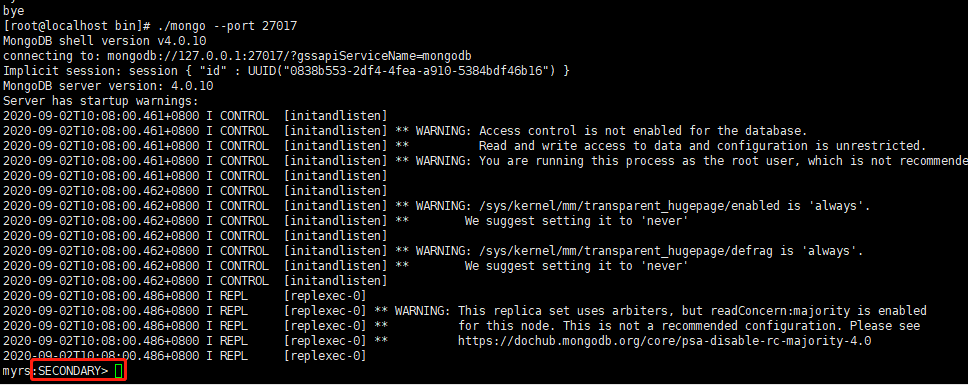
-
6.7.3 仲裁节点和主节点故障
-
先关掉仲裁节点27019,再关掉现在的主节点27018

-
登录27017后,发现,27017仍然是从节点,副本集中没有主节点了,导致此时,副本集是只读状态,
无法写入
为什么不选举了?因为27017的票数,没有获得大多数,即没有大于等于2,它只有默认的一票(优先级是1)如果要触发选举,随便加入一个成员即可

-
如果只加入27019仲裁节点成员,则主节点一定是27017,因为没得选了,仲裁节点不参与选举,
但参与投票
先启动27019仲裁节点

27017从节点升级为主节点
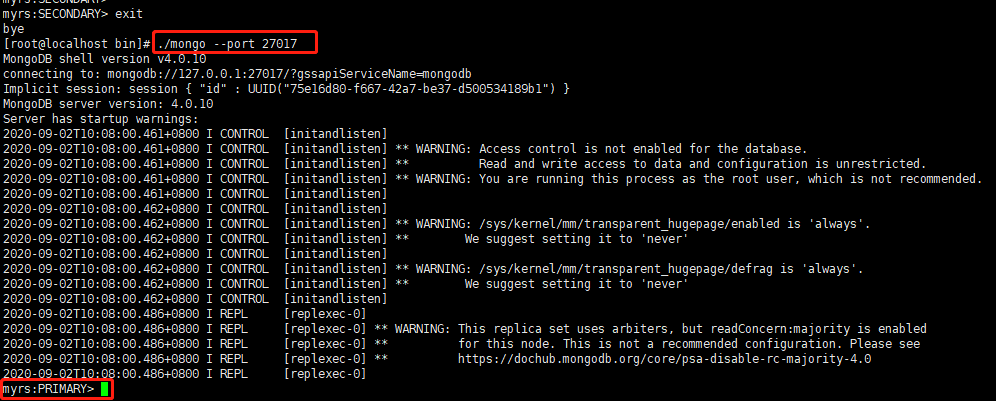
-
如果只加入27018节点,会发起选举。因为27017和27018都是两票,则按照谁数据新,谁当主节
点
只启动27018,触发选举

数据较新的当选主节点

-
6.7.4 仲裁节点和从节点故障
-
先关掉仲裁节点27019,再关掉现在的副本节点27018

-
10秒后,27017主节点自动降级为副本节点(服务降级)
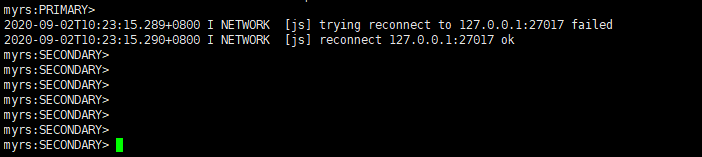
-
副本集不可写数据了,已经故障了
6.8 Compass工具连接副本集
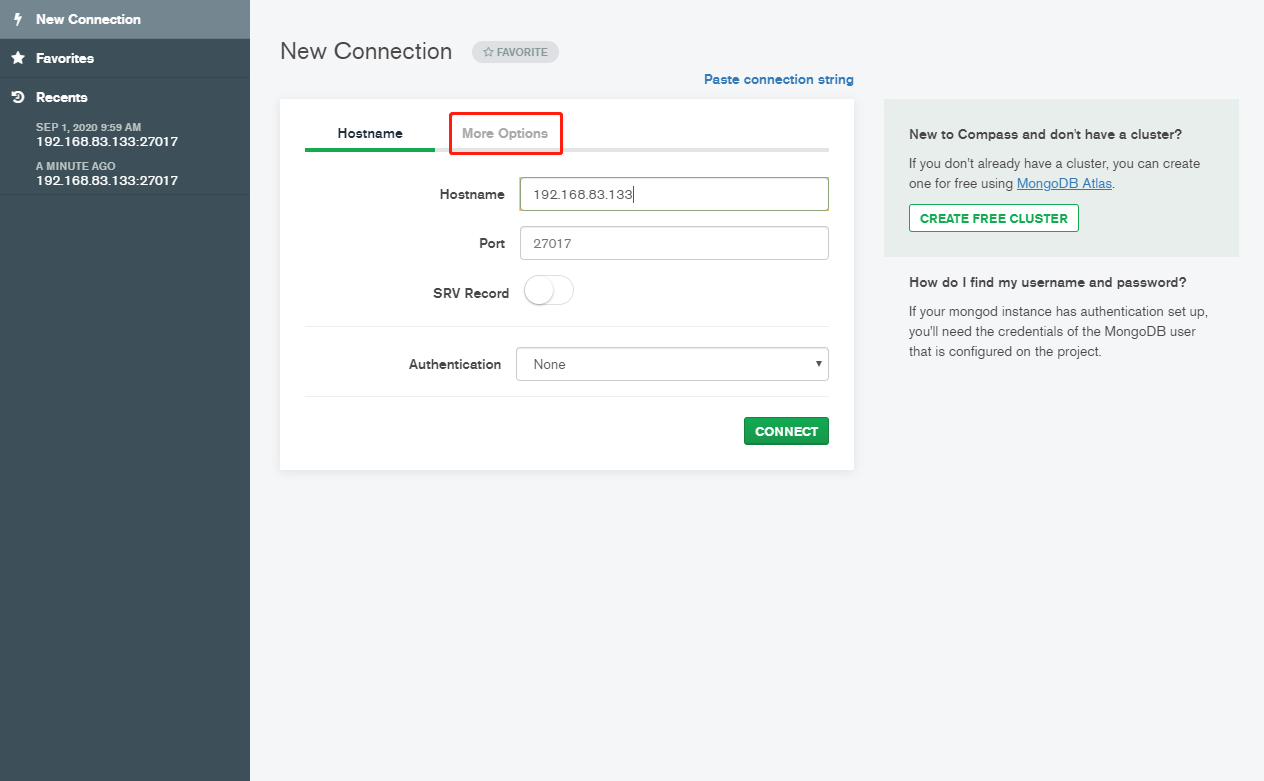
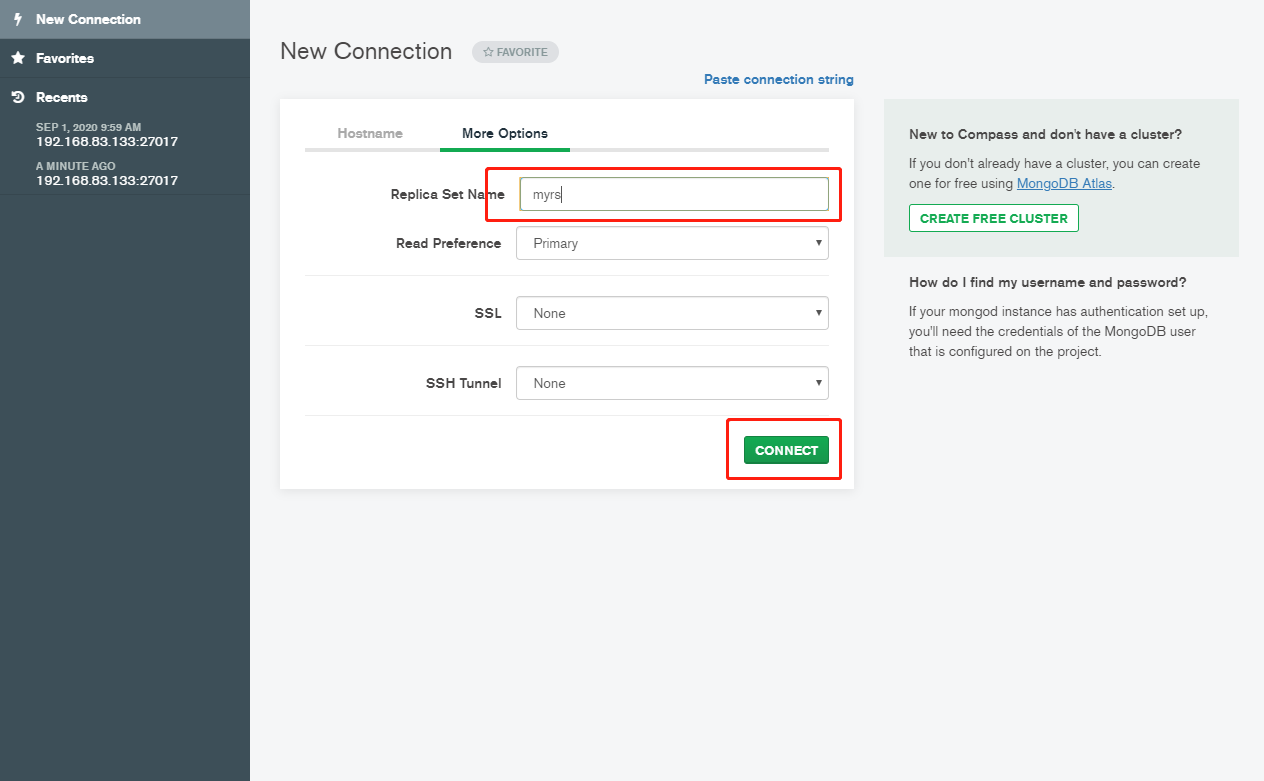
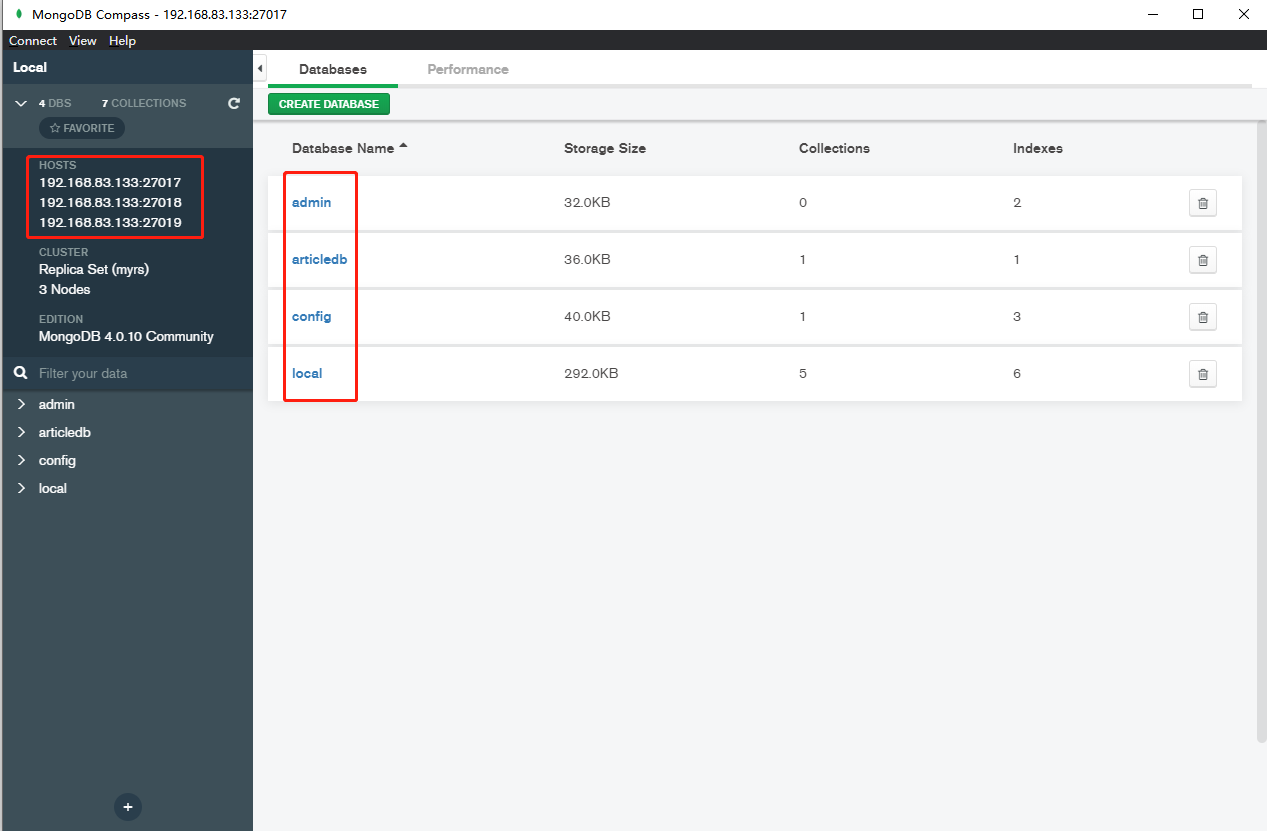
6.9 SpringDataMongoDB连接副本集(*)
-
副本集语法
mongodb://host1,host2,host3/articledb? connect=replicaSet&slaveOk=true&replicaSet=副本集名字- slaveOk=true:开启副本节点读的功能,可实现读写分离
- connect=replicaSet:自动到副本集中选择读写的主机如果slaveOK是打开的,则实现了读写分离
-
完整的连接字符串的参考(了解)
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]] [/[database][?options]]- mongodb:// 这是固定的格式,必须要指定
- username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登陆这个数据库
- host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址
- portX 可选的指定端口,如果不填,默认为27017
- /database 如果指定username:password@,连接并验证登陆指定数据库。若不指定,默认打开test 数据库
- ?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值name=value键值对之间通过&或;(分号)隔开
-
示例:连接 replicaset 三台服务器 (端口 27017, 27018, 和27019),直接连接第一个服务器,无论是replica
set一部分或者主服务器或者从服务器,写入操作应用在主服务器 并且分布查询到从服务器
server: port: 7777 spring: #数据源配置 data: mongodb: # # 主机地址 # host: 192.168.83.133 # # 默认端口是27017 # port: 27017 # # 数据库 # database: test # 副本集的连接字符串 uri: mongodb://192.168.83.133:27017,192.168.83.133:27018,192.168.83.133:27019/articledb?connect=replicaSet&slaveOk=true&replicaSet=myrs注意:主机必须是副本集中所有的主机,包括主节点、副本节点、仲裁节点
-
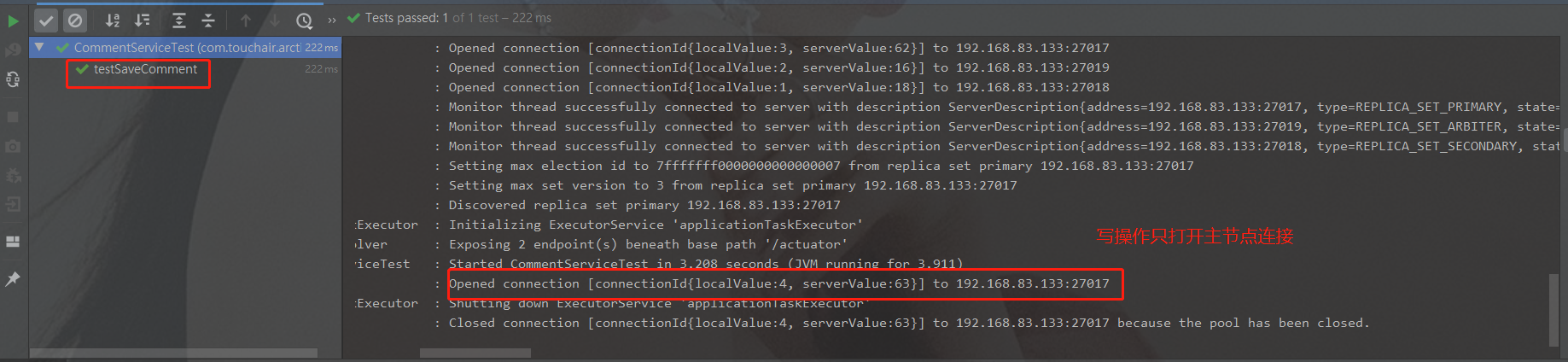
SpringDataMongoDB自动实现了读写分离:
- 写操作时,只打开主节点连接
- 读操作是,同时打开主节点和从节点连接,但使用从节点获取数据
- 写操作时,只打开主节点连接
7. 分片集群-Sharded Cluster(*)
7.1 分片概念
-
分片(sharding)是一种跨多台机器分布数据的方法, MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署
-
换句话说:分片(sharding)是指将数据拆分,将其分散存在不同的机器上的过程。有时也用分区(partitioning)来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以储存更多的数据,处理更多的负载
-
具有大型数据集或高吞吐量应用程序的数据库系统可以会挑战单个服务器的容量。例如,高查询率会耗尽服务器的CPU容量。工作集大小大于系统的RAM会强调磁盘驱动器的I / O容量
-
有两种解决系统增长的方法:垂直扩展和水平扩展
- 垂直扩展意味着增加单个服务器的容量,例如使用更强大的CPU,添加更多RAM或增加存储空间量。可用技术的局限性可能会限制单个机器对于给定工作负载而言足够强大。此外,基于云的提供商基于可用的硬件配置具有硬性上限。结果,垂直缩放有实际的最大值
- 水平扩展意味着划分系统数据集并加载多个服务器,添加其他服务器以根据需要增加容量。虽然单个机器的总体速度或容量可能不高,但每台机器处理整个工作负载的子集,可能提供比单个高速大容量服务器更高的效率。扩展部署容量只需要根据需要添加额外的服务器,这可能比单个机器的高端硬件的总体成本更低。权衡是基础架构和部署维护的复杂性增加
-
MongoDB支持通过分片进行水平扩展
- 以低价服务器成本,获取更高性能
7.2 分片集群包含的组件
- MongoDB分片集群包含以下组件:
- 分片(存储):每个分片包含分片数据的子集,每个分片都可以部署为副本集
- mongos(路由):mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口
- config-servers(“调度”的配置):配置服务器存储集群的元数据和配置设置,从MongoDB 3.4开始,必须将配置服务器部署为副本集(CSRS)
- 分片集群中组件交互图解
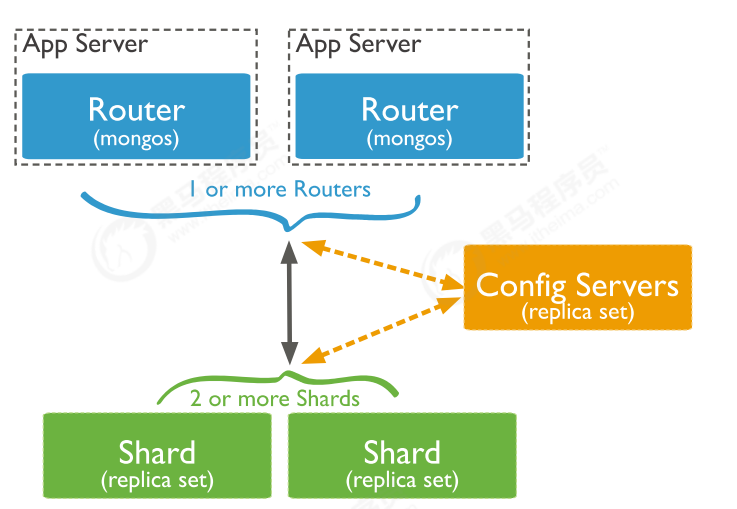
- MongoDB在集合级别对数据进行分片,将集合数据分布在集群中的分片上
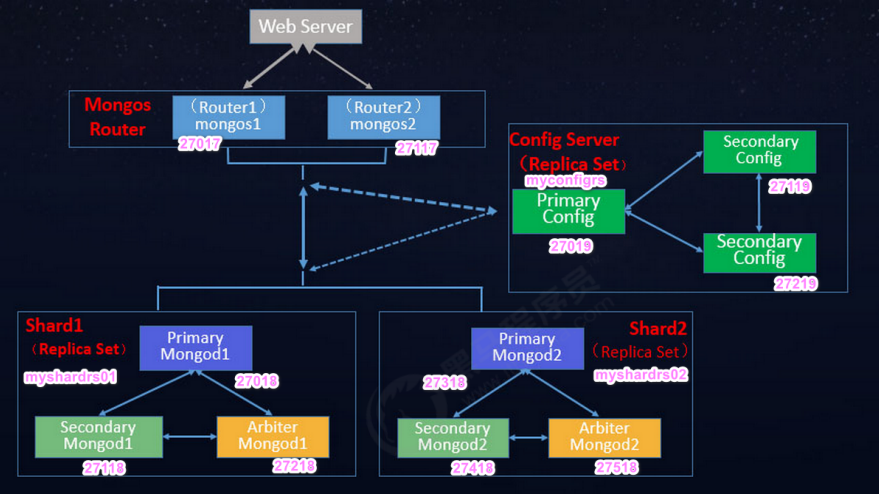
7.3 分片集群架构目标
- 两个分片节点副本集(3+3)+一个配置节点副本集(3)+两个路由节点(2),共11个服务节点
7.4 分片节点副本集的创建
7.4.1 第一套副本集
-
准备存放数据和日志的目录
#-----------myshardrs01 mkdir -p /mongodb/sharded_cluster/myshardrs01_27018/log \ & mkdir -p /mongodb/sharded_cluster/myshardrs01_27018/data/db \ & mkdir -p /mongodb/sharded_cluster/myshardrs01_27118/log \ & mkdir -p /mongodb/sharded_cluster/myshardrs01_27118/data/db \ & mkdir -p /mongodb/sharded_cluster/myshardrs01_27218/log \ & mkdir -p /mongodb/sharded_cluster/myshardrs01_27218/data/db -
新建或修改配置文件
vim /mongodb/sharded_cluster/myshardrs01_27018/mongod.confmyshardrs01_27018:
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/sharded_cluster/myshardrs01_27018/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 dbPath: "/mongodb/sharded_cluster/myshardrs01_27018/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/sharded_cluster/myshardrs01_27018/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27018 replication: #副本集的名称 replSetName: myshards01 sharding: #分片角色 clusterRole: shardsvr设置sharding.clusterRole需要mongod实例运行复制。 要将实例部署为副本集成员,请使用replSetName设置并指定副本集的名称 两种role:configsvr、shardsvr
-
同样的操作 重复27118、27218 主要改端口号
vim /mongodb/sharded_cluster/myshardrs01_27118/mongod.confvim /mongodb/sharded_cluster/myshardrs01_27218/mongod.conf -
启动第一套副本集:一主一副本一仲裁
-
依次启动
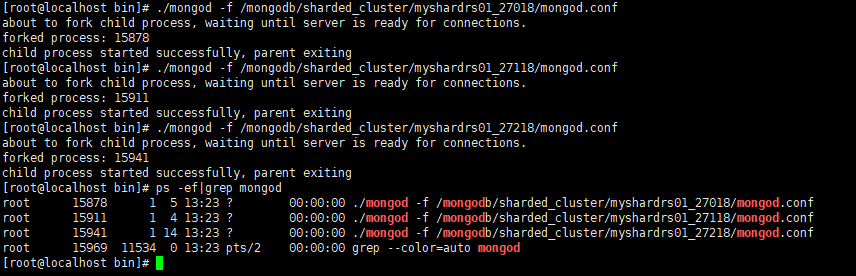
-
初始化副本集和创建主节点,使用客户端命令连接任意一个节点,但这里尽量要连接主节点
(1)执行初始化副本集命令
rs.initiate()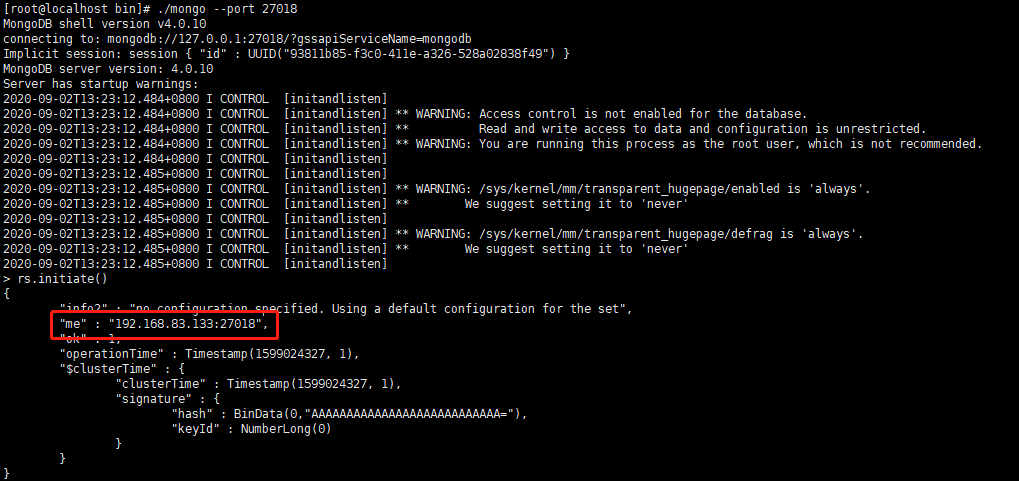
(2)主节点配置查看
rs.status()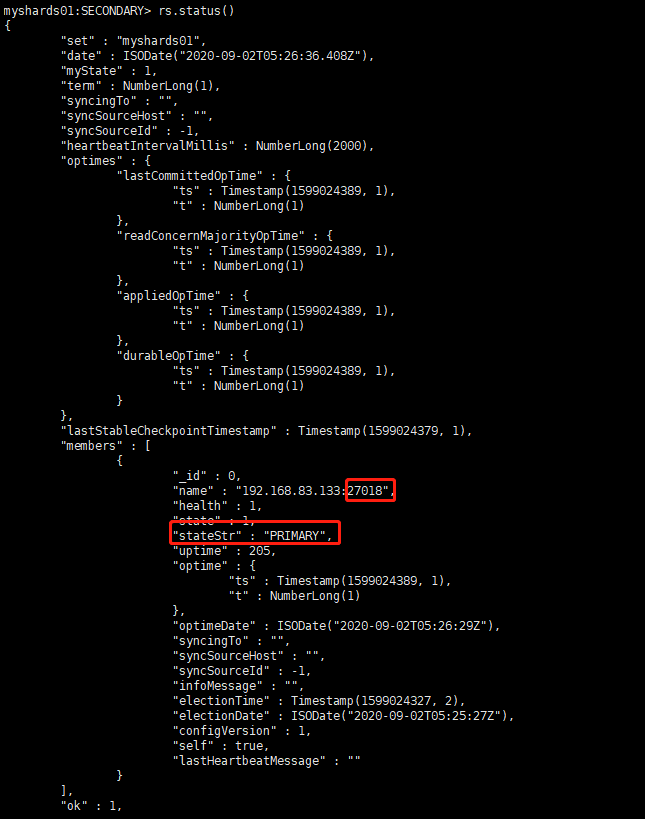
(3)添加副本节点和仲裁节点
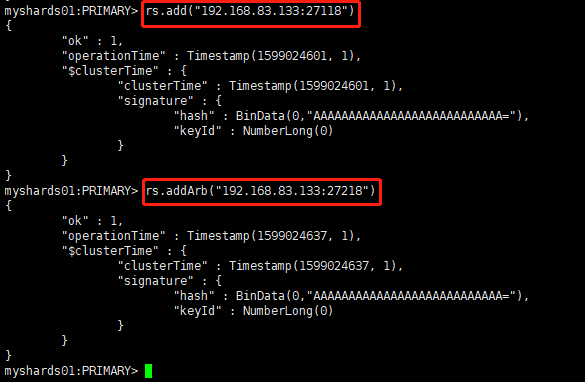
-
-
查看副本集配置情况
rs.conf(),出现如下效果则配置完成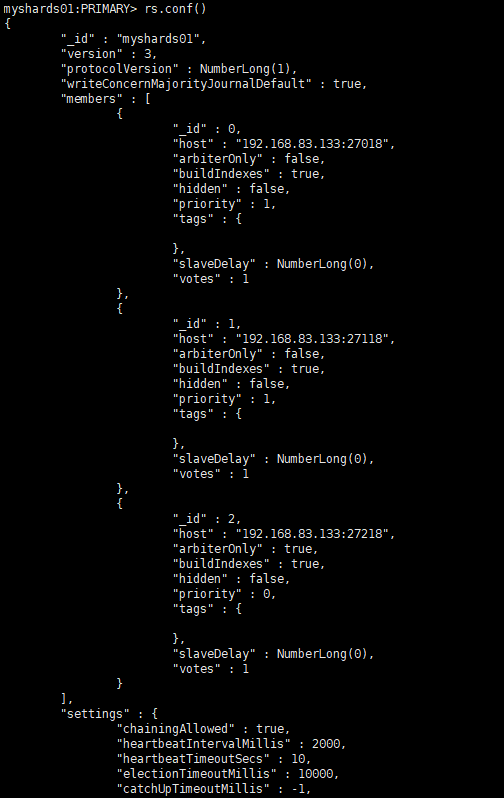
7.4.2 第二套副本集
-
准备存放数据和日志的目录
#-----------myshardrs02 mkdir -p /mongodb/sharded_cluster/myshardrs02_27318/log \ & mkdir -p /mongodb/sharded_cluster/myshardrs02_27318/data/db \ & mkdir -p /mongodb/sharded_cluster/myshardrs02_27418/log \ & mkdir -p /mongodb/sharded_cluster/myshardrs02_27418/data/db \ & mkdir -p /mongodb/sharded_cluster/myshardrs02_27518/log \ & mkdir -p /mongodb/sharded_cluster/myshardrs02_27518/data/db -
新建或修改配置文件
vim /mongodb/sharded_cluster/myshardrs02_27318/mongod.confvim /mongodb/sharded_cluster/myshardrs02_27418/mongod.confvim /mongodb/sharded_cluster/myshardrs02_27518/mongod.confmyshardrs02_27318:
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/sharded_cluster/myshardrs02_27318/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 dbPath: "/mongodb/sharded_cluster/myshardrs02_27318/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/sharded_cluster/myshardrs02_27318/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27318 replication: #副本集的名称 replSetName: myshards02 sharding: #分片角色 clusterRole: shardsvrmyshardrs02_27418、myshardrs02_27518 重复上述操作
-
启动第二套副本集:一主一副本一仲裁
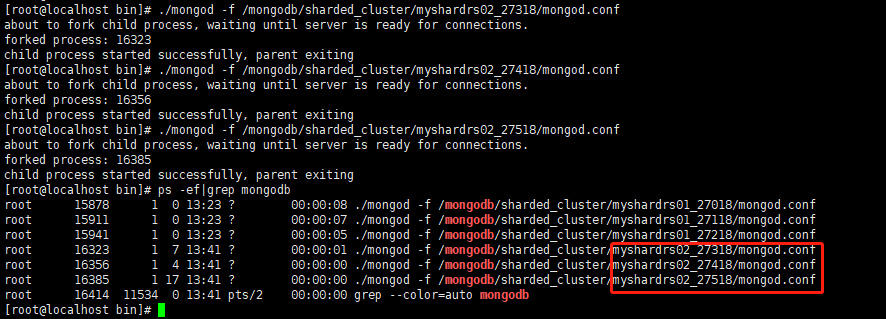
-
(1)初始化副本集和创建主节点:使用客户端命令连接任意一个节点,但这里尽量要连接主节点
执行初始化副本集命令:
rs.initiate()查看副本集情况(节选内容):
rs.status() -
(2)主节点配置查看:
rs.conf() -
(3)添加副本节点和仲裁节点如下
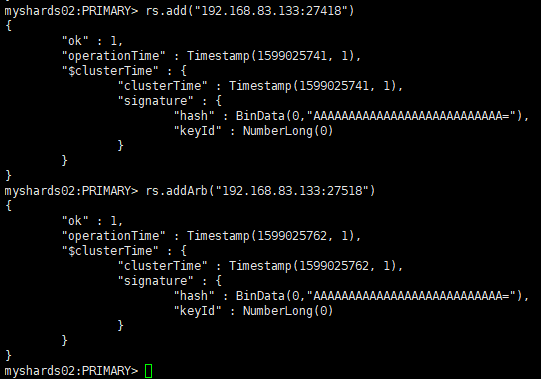
-
查看副本集的配置情况
rs.conf()rs.status()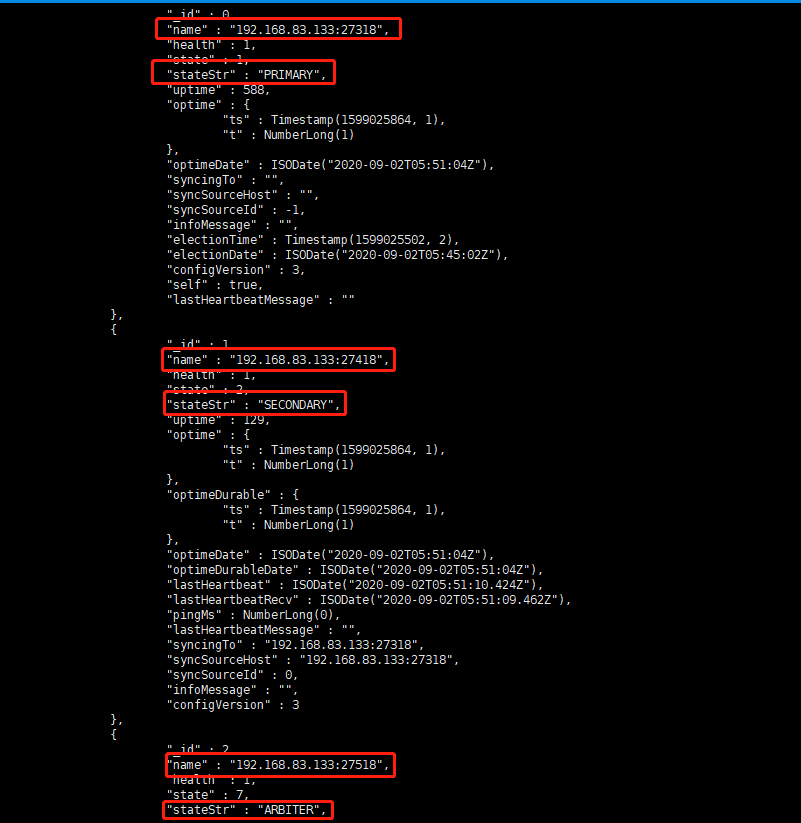
7.5 配置节点副本集的创建
-
准备存放数据和日志的目录
#-----------configrs #建立数据节点data和日志目录 mkdir -p /mongodb/sharded_cluster/myconfigrs_27019/log \ & mkdir -p /mongodb/sharded_cluster/myconfigrs_27019/data/db \ & mkdir -p /mongodb/sharded_cluster/myconfigrs_27119/log \ & mkdir -p /mongodb/sharded_cluster/myconfigrs_27119/data/db \ & mkdir -p /mongodb/sharded_cluster/myconfigrs_27219/log \ & mkdir -p /mongodb/sharded_cluster/myconfigrs_27219/data/db -
新建或修改配置文件
vim /mongodb/sharded_cluster/myconfigrs_27019/mongod.confvim /mongodb/sharded_cluster/myconfigrs_27119/mongod.confvim /mongodb/sharded_cluster/myconfigrs_27219/mongod.confmyconfifigrs_27019/mongod.conf
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/sharded_cluster/myconfigrs_27019/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true storage: #mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。 dbPath: "/mongodb/sharded_cluster/myconfigrs_27019/data/db" journal: #启用或禁用持久性日志以确保数据文件保持有效和可恢复。 enabled: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/sharded_cluster/myconfigrs_27019/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27019 replication: #副本集的名称 replSetName: myconfigrs sharding: #分片角色 clusterRole: configsvr -
myconfifigrs_27119/mongod.conf 、myconfifigrs_27219/mongod.conf 同样配置即可
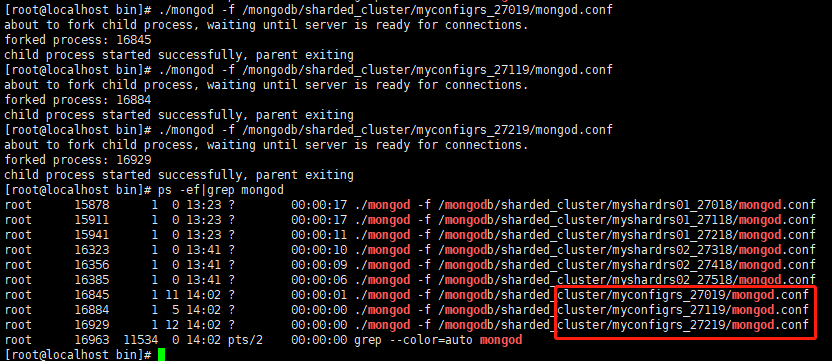
-
依次启动三个mongod服务
-
(1)初始化副本集和创建主节点
- 使用客户端命令连接任意一个节点,但这里尽量要连接主节点
- 执行初始化副本集命令:
rs.initiate() - 查看副本集情况(节选内容):
rs.status()
-
添加两个副本节点
-
rs.add("192.168.83.133:27119") rs.add("192.168.83.133:27219") rs.status() -
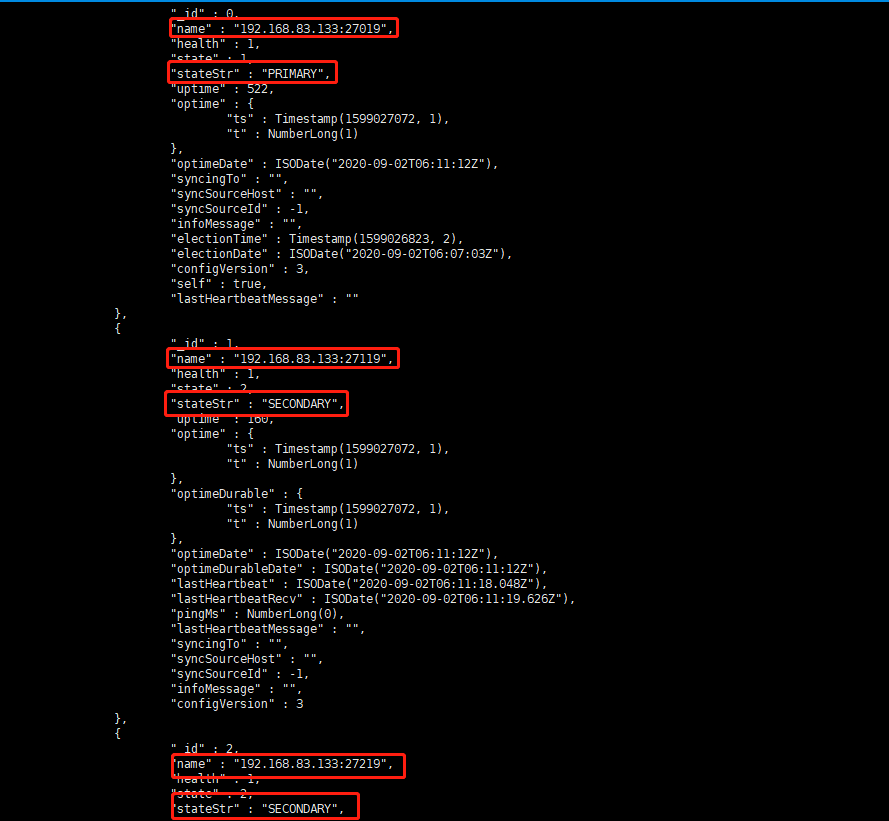
-
7.6 路由节点的创建和操作
7.6.1 第一个路由节点的创建和连接
-
准备存放数据和日志的目录
#-----------mongos01 mkdir -p /mongodb/sharded_cluster/mymongos_27017/log -
新建或修改配置文件:mymongos_27017/mongos.conf
vi /mongodb/sharded_cluster/mymongos_27017/mongos.confsystemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/sharded_cluster//mymongos_27017/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/sharded_cluster//mymongos_27017/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27017 sharding: #指定配置节点副本集 configDB: myconfigrs/192.168.83.133:27019,192.168.83.133:27119,192.168.83.133:27219 -
启动mongos服务
-
./mongos -f /mongodb/sharded_cluster/mymongos_27017/mongos.conf -

-
-
客户端登录mongos,此时可以查看库,但写不进数据
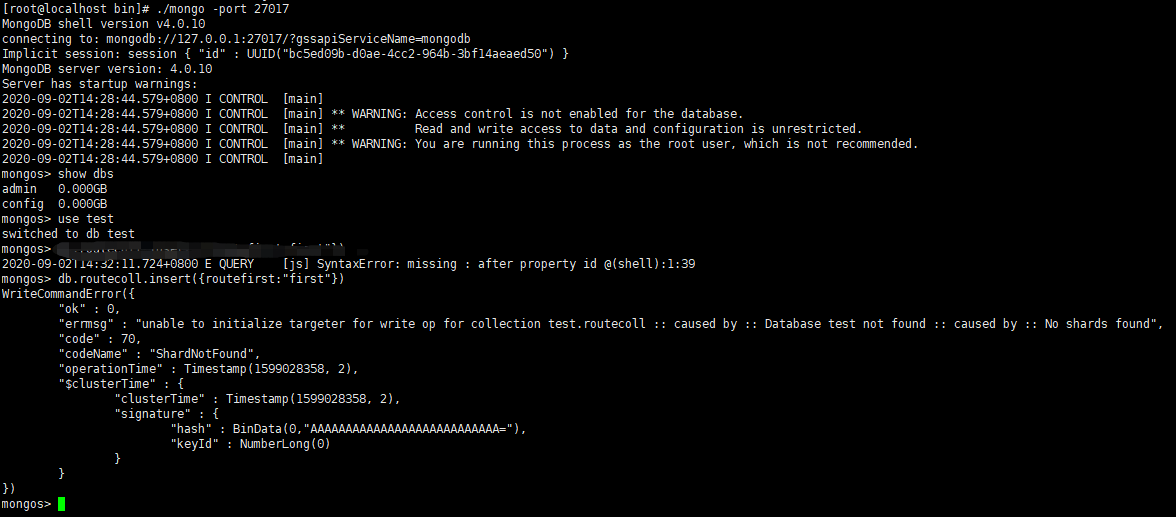
原因:通过路由节点操作,现在只是连接了配置节点,还没有连接分片数据节点,因此无法写入业务数据
-
7.6.2 在路由节点上进行分片配置操作
-
(1)使用命令添加分片,语法:
sh.addShard("IP:Port")- 将第一套分片副本集添加进来
sh.addShard("myshards01/192.168.83.133:27018,192.168.83.133:27118,192.168.83.133:27218")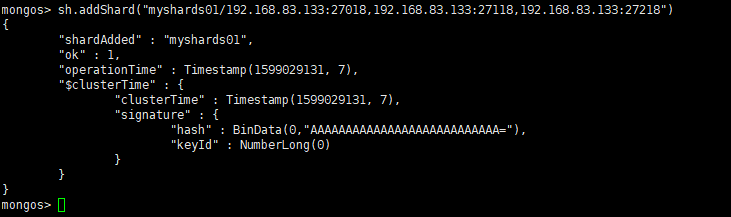
-
查看分片状态情况:
sh.status()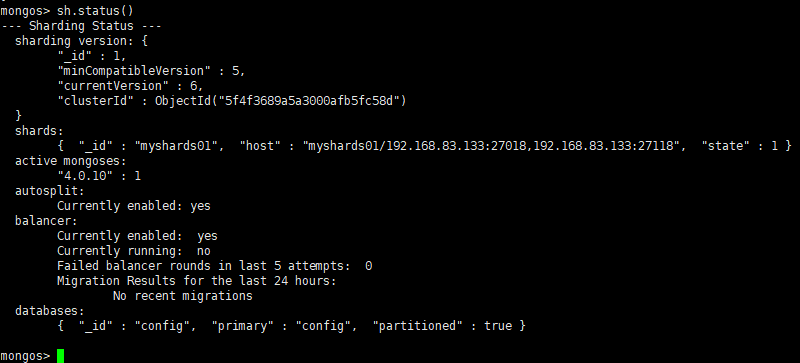
-
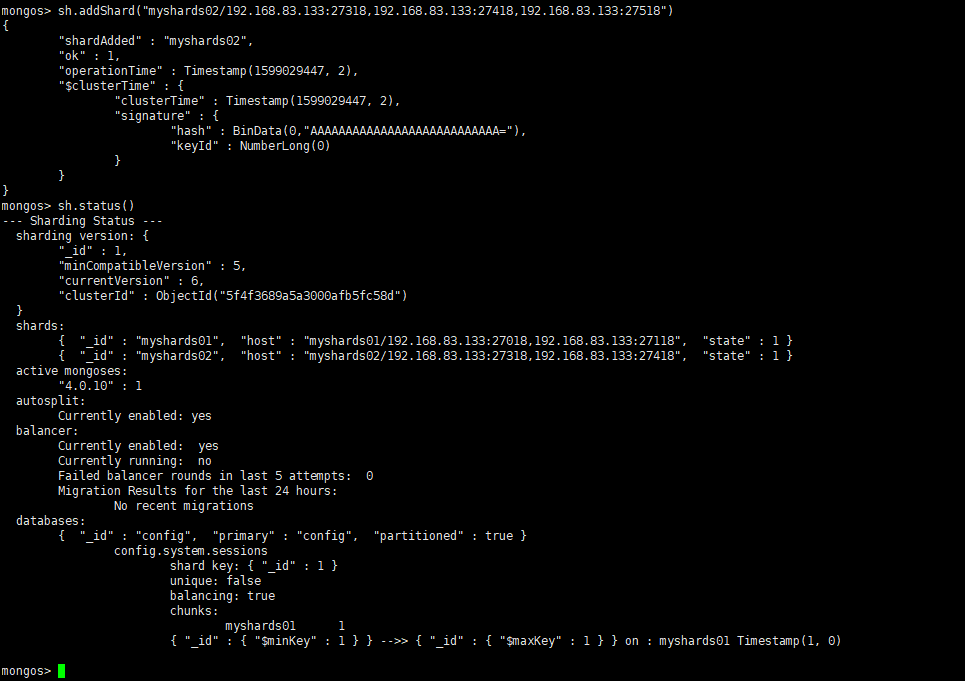
继续将第二套分片副本集添加进来
sh.addShard("myshards02/192.168.83.133:27318,192.168.83.133:27418,192.168.83.133:27518")
- 提示:如果添加分片失败,需要先手动移除分片,检查添加分片的信息的正确性后,再次添加分片
移除分片
use admin db.runCommand( { removeShard: "myshards02" } )注意:如果只剩下最后一个shard,是无法删除的移除时会自动转移分片数据,需要一个时间过程,完成后,再次执行删除分片命令才能真正删除
-
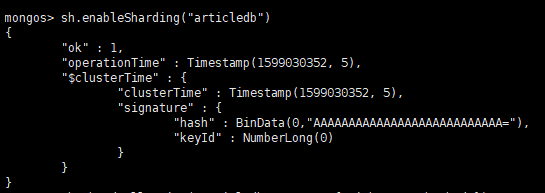
(2)开启分片功能
- sh.enableSharding("库名")、sh.shardCollection("库名.集合名",{"key":1})
-
(3)集合分片
-
对集合分片,你必须使用 sh.shardCollection() 方法指定集合和分片键
-
语法:
sh.shardCollection(namespace,key,unique) -
对集合进行分片时,你需要选择一个 片键(Shard Key) , shard key 是每条记录都必须包含的,且建立了
索引的单个字段或复合字段,MongoDB按照片键将数据划分到不同的 数据块 中,并将 数据块 均衡地分布
到所有分片中.为了按照片键划分数据块,MongoDB使用 基于哈希的分片方式(随机平均分配)或者基
于范围的分片方式(数值大小分配)
用什么字段当片键都可以,如:nickname作为片键,但一定是必填字段
-
分片规则
-
分片规则一:哈希策略
对于 基于哈希的分片 ,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块.在使用基于哈希分片的系统中,拥有”相近”片键的文档 很可能不会 存储在同一个数据块中,因此数据的分
离性更好一些
示例:使用nickname作为片键,根据其值的哈希值进行数据分片
sh.shardCollection("articledb.comment",{"nickname":"hashed"})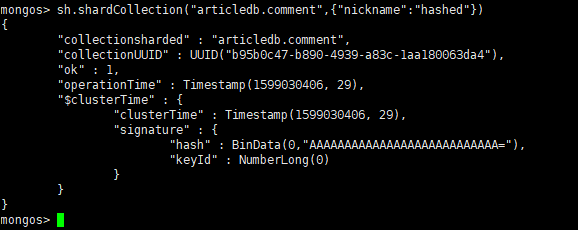
查看分片状态:
sh.status()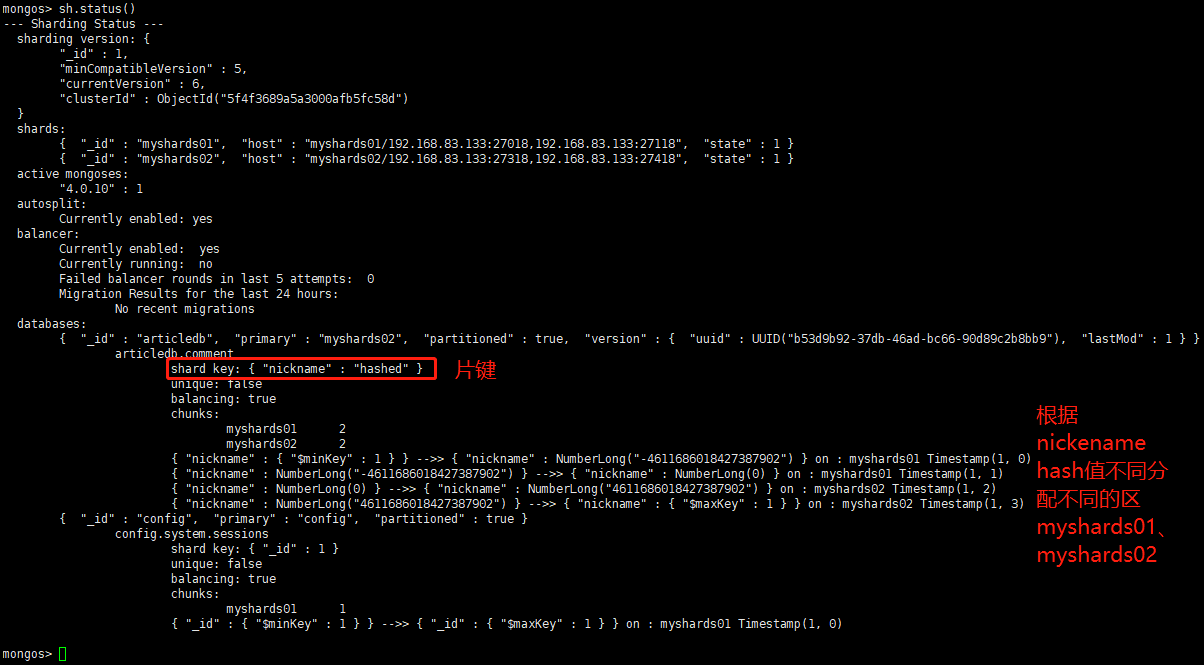
-
分片规则二:范围策略
对于 基于范围的分片 ,MongoDB按照片键的范围把数据分成不同部分.假设有一个数字的片键:想象一个从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点.MongoDB把这条直线划分为更短的不重叠的片段,并称之为 数据块 ,每个数据块包含了片键在一定范围内的数据.在使用片键做范围划分的系统中,拥有”相近”片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中.
示例:使用作者年龄字段作为片键,按照年龄的值进行分片
sh.shardCollection("articledb.author",{"age":1})查看分片状态:
sh.status()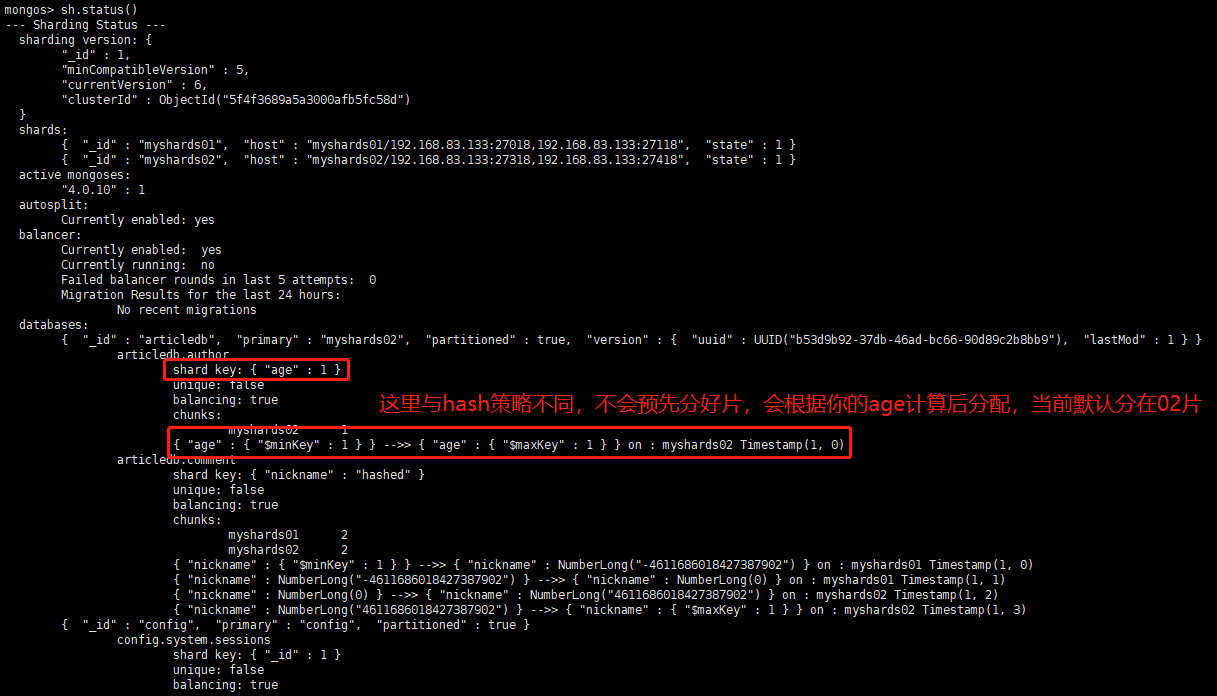
-
注意的是:
1)一个集合只能指定一个片键,否则报错。
2)一旦对一个集合分片,分片键和分片值就不可改变。 如:不能给集合选择不同的分片键、不能更新分片键的值
3)根据age索引进行分配数据
-
-
基于范围的分片方式与基于哈希的分片方式性能对比
- 基于范围的分片方式提供了更高效的范围查询,给定一个片键的范围,分发路由可以很简单地确定哪数据块存储了请求需要的数据,并将请求转发到相应的分片中.不过,基于范围的分片会导致数据在不同分片上的不均衡,有时候,带来的消极作用会大于查询性能的积极作用.比如,如果片键所在的字段是线性增长的,一定时间内的所有请求都会落到某个固定的数据块中,最终导致分布在同一个分片中.在这种情况下,一小部分分片承载了集群大部分的数据,系统并不能很好地进行扩展.
- 与此相比,基于哈希的分片方式以范围查询性能的损失为代价,保证了集群中数据的均衡.哈希值的随机性使数据随机分布在每个数据块中,因此也随机分布在不同分片中.但是也正由于随机性,一个范围查询很难确定应该请求哪些分片,通常为了返回需要的结果,需要请求所有分片
- 如无特殊情况,一般推荐使用 Hash Sharding
- 而使用 _id 作为片键是一个不错的选择,因为它是必有的,你可以使用数据文档 _id 的哈希作为片键。这个方案能够是的读和写都能够平均分布,并且它能够保证每个文档都有不同的片键所以数据块能够很精细
- 似乎还是不够完美,因为这样的话对多个文档的查询必将命中所有的分片。虽说如此,这也是一种比较好的方案了
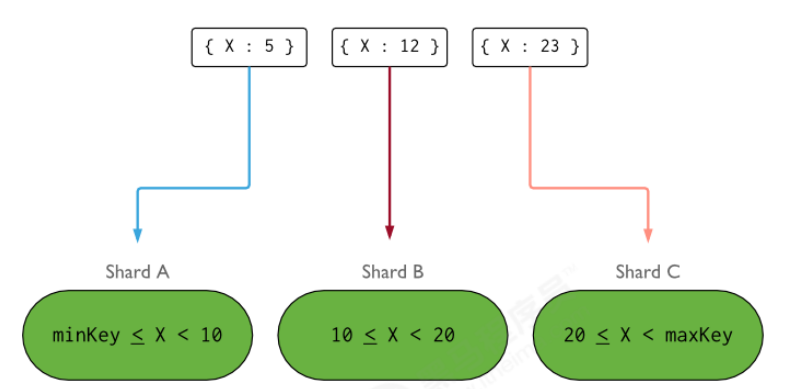
- 理想化的 shard key 可以让 documents 均匀地在集群中分布
-
7.6.3 分片后插入数据测试
-
(1)测试一(哈希规则):登录mongos后,向comment循环插入1000条数据
use articledb for(var i=0;i<=1000;i++){db.comment.insert({_id:i+"",nickname:"BoBo"+i})} db.comment.count() -
提示:js的语法,因为mongo的shell是一个JavaScript的shell
-
注意:从路由上插入的数据,必须包含片键,否则无法插入
-
测试结果
- 分别登录两个片的主节点,统计文档数量 当前一共1001条
- 第一个分片副本集
db.comment.count(),508条。注意切换数据库到articledb下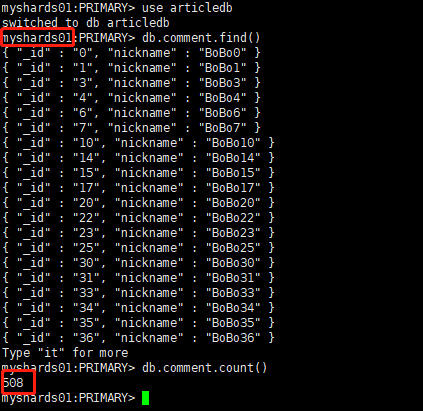
- 第二个分片副本集
db.comment.count()493条。注意切换数据库到articledb下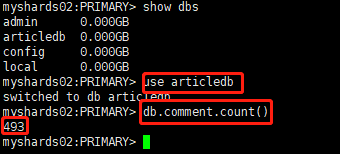
-
结论
- 可以看到,1000条数据近似均匀的分布到了2个shard上。是根据片键的哈希值分配的。这种分配方式非常易于水平扩展:一旦数据存储需要更大空间,可以直接再增加分片即可,同时提升了性能
- 使用db.comment.stats()查看单个集合的完整情况,mongos执行该命令可以查看该集合的数据分片的情况
- 使用sh.status()查看本库内所有集合的分片信息
-
(2)测试二(范围规则):登录mongs后,向comment循环插入20000条数据做测试
-
注意:如果查看状态发现没有分片,则可能是由于以下原因造成了:
1)系统繁忙,正在分片中。
2)数据块(chunk)没有填满,默认的数据块尺寸(chunksize)是64M,填满后才会考虑向其他片的
-
数据块填充数据,因此,为了测试,可以将其改小,这里改为1M,操作如下
use config db.settings.save( { _id:"chunksize", value: 1 } ) -
测试完再改回来
db.settings.save( { _id:"chunksize", value: 64 } )
-
-
//插入数据 use articledb for(var i=1;i<=20000;i++) {db.author.save({"name":"BoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoBoB oBoBoBoBoBoBoBoBo"+i,"age":NumberInt(i%120)})}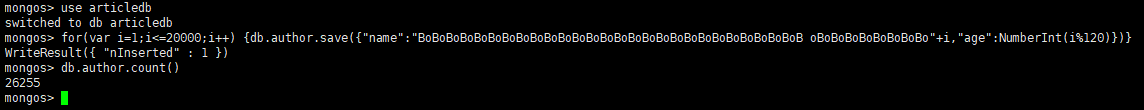
-
查看2个分片副本集的数据情况
- 第一个分片副本集myshards01,7681条数据

- 第二个分片副本集myshards02,18574条

- 第一个分片副本集myshards01,7681条数据
7.6.4 再增加一个路由节点
-
准备存放数据和日志的目录
#-----------mongos02 mkdir -p /mongodb/sharded_cluster/mymongos_27117/log -
新建或修改配置文件
vi /mongodb/sharded_cluster/mymongos_27117/mongos.conf -
mymongos_27117/mongos.conf
systemLog: #MongoDB发送所有日志输出的目标指定为文件 destination: file #mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径 path: "/mongodb/sharded_cluster//mymongos_27117/log/mongod.log" #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。 logAppend: true processManagement: #启用在后台运行mongos或mongod进程的守护进程模式。 fork: true #指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID pidFilePath: "/mongodb/sharded_cluster//mymongos_27117/log/mongod.pid" net: #服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip #bindIpAll: true #服务实例绑定的IP bindIp: localhost,192.168.83.133 #bindIp #绑定的端口 port: 27117 sharding: #指定配置节点副本集 configDB: myconfigrs/192.168.83.133:27019,192.168.83.133:27119,192.168.83.133:27219 -
启动mongos服务
./mongos -f /mongodb/sharded_cluster/mymongos_27117/mongos.conf
-
使用mongo客户端登录27117,发现,第二个路由无需配置,因为分片配置都保存到了配置服务器了
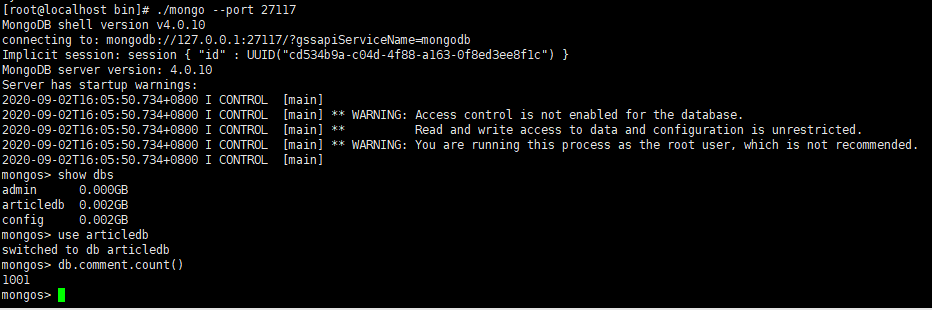
6.7 SpringDataMongoDB连接分片集群
-
多个路由的时候的SpringDataMongoDB的客户端配置参考如下
server: port: 7777 spring: #数据源配置 data: mongodb: # # 主机地址 # host: 192.168.83.133 # # 默认端口是27017 # port: 27017 # # 数据库 # database: test # 副本集的连接字符串 #uri: mongodb://192.168.83.133:27017,192.168.83.133:27018,192.168.83.133:27019/articledb?connect=replicaSet&slaveOk=true&replicaSet=myrs #连接路由字符串 uri: mongodb://192.168.83.133:27017,192.168.83.133:27117/articledb -
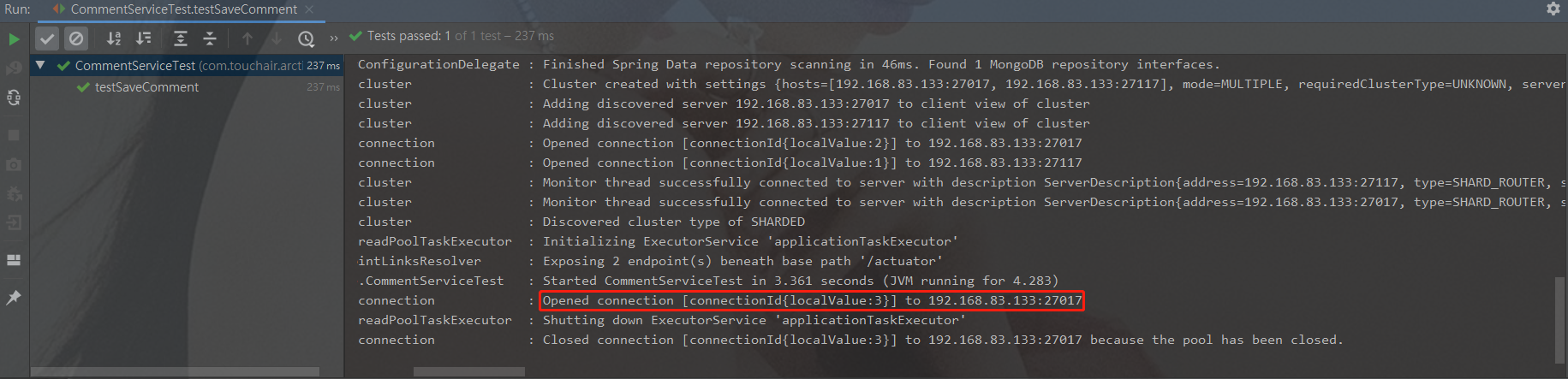
通过日志发现,写入数据的时候,会选择一个路由写入
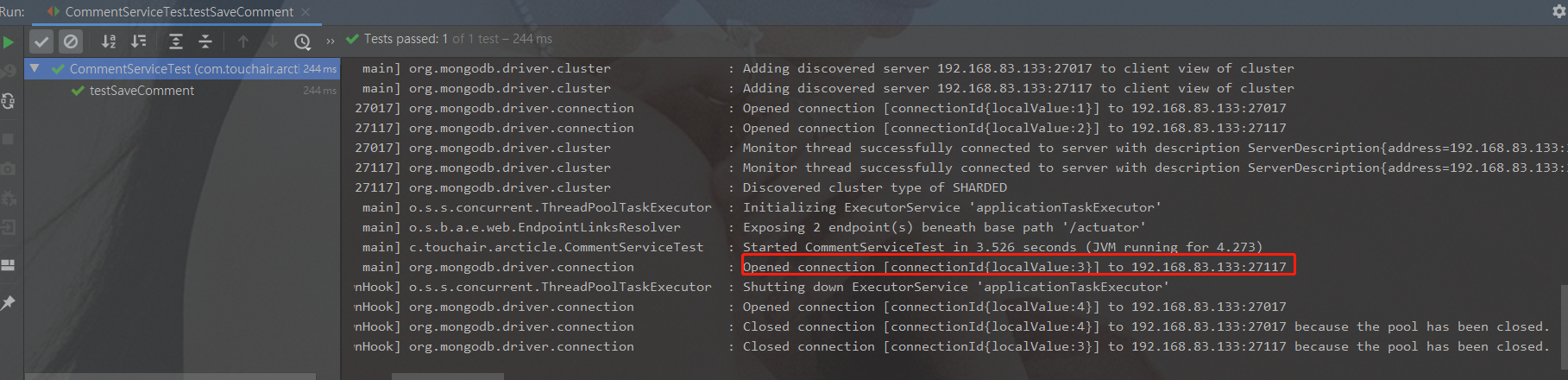
7. 安全认证
7.1 MongoDB的用户和角色权限简介
-
默认情况下,MongoDB实例启动运行时是没有启用用户访问权限控制的,也就是说,在实例本机服务器上都可以随意连接到实例进行各种操作,MongoDB不会对连接客户端进行用户验证,这是非常危险的
-
mongodb官网上说,为了能保障mongodb的安全可以做以下几个步骤:
1)使用新的端口,默认的27017端口如果一旦知道了ip就能连接上,不太安全
2)设置mongodb的网络环境,最好将mongodb部署到公司服务器内网,这样外网是访问不到的,公司内部访问使用vpn等
3)开启安全认证,认证要同时设置服务器之间的内部认证方式,同时要设置客户端连接到集群的账号密码认证方式
-
为了强制开启用户访问控制(用户验证),则需要在MongoDB实例启动时使用选项 --auth 或在指定启动配置文件中添加选项 auth=true
-
相关概念
-
1)启用访问控制:
MongoDB使用的是基于角色的访问控制(Role-Based Access Control,RBAC)来管理用户对实例的访问
通过对用户授予一个或多个角色来控制用户访问数据库资源的权限和数据库操作的权限,在对用户分配角色之前,用户无法访问实例,在实例启动时添加选项 --auth 或指定启动配置文件中添加选项 auth=true
-
2)角色:
在MongoDB中通过角色对用户授予相应数据库资源的操作权限,每个角色当中的权限可以显式指定,也可以通过继承其他角色的权限,或者两都都存在的权限。
-
3)权限:权限由指定的数据库资源(resource)以及允许在指定资源上进行的操作(action)组成
- 资源(resource)包括:数据库、集合、部分集合和集群;
- 操作(action)包括:对资源进行的增、删、改、查(CRUD)操作。
-
-
在角色定义时可以包含一个或多个已存在的角色,新创建的角色会继承包含的角色所有的权限。在同一个数据库中,新创建角色可以继承其他角色的权限,在 admin 数据库中创建的角色可以继承在其它任意数据库中角色的权限
-
常用的内置角色
- 数据库用户角色:read、readWrite
- 所有数据库用户角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- 数据库管理角色:dbAdmin、dbOwner、userAdmin
- 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager
- 备份恢复角色:backup、restore
- 超级用户角色:root
- 内部角色:system
-
常用的角色权限描述
- read:可以读取指定数据库中的任何数据
- readWrite:可以读写指定数据库中任何数据,包括创建、重命名、删除集合
- userAdmin:可以在指定数据库创建和修改用户
- root:超级权限
7.2 单实例环境
- 目标:对单实例的MongoDB服务开启安全认证,这里的单实例指的是未开启副本集或分片的MongoDB实例
7.2.1 关闭已开启的服务(可选)
-
增加mongod的单实例的安全认证功能,可以在服务搭建的时候直接添加,也可以在之前搭建好的服务上添加
-
停止服务的方式有两种:快速关闭和标准关闭
-
快速关闭方法(快速,简单,数据可能会出错):通过系统的kill命令直接杀死进程
kill -2 pID -
标准的关闭方法(数据不容易出错,但麻烦):通过mongo客户端中的shutdownServer命令来关闭服务
//客户端登录服务,注意,这里通过localhost登录,如果需要远程登录,必须先登录认证才行。 mongo --port 27017 //#切换到admin库 use admin //关闭服务 db.shutdownServer()
-
-
补充:如果一旦是因为数据损坏,则需要进行如下操作(了解)
-
(1)删除lock文件
rm -f /mongodb/single/data/db/*.lock -
(2)修复数据
/usr/local/mongodb/bin/mongod --repair --dbpath=/mongodb/single/data/db
-
7.2.2 添加用户和权限
-
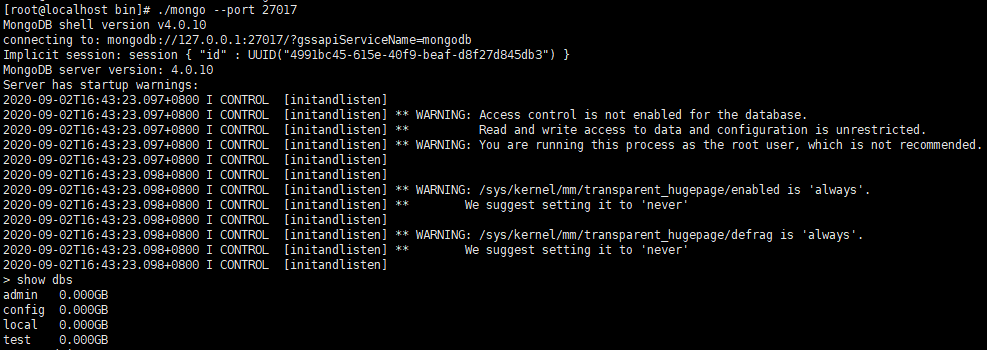
启动single 单机模式的mongod服务

-
客户端连接27017
-
在操作用户时,启动mongod服务时尽量不要开启授权
-
创建两个管理员用户,一个是系统的超级管理员 myroot ,一个是admin库的管理用户 myadmin
-
//切换到admin库 use admin //创建系统超级用户 myroot,密码:123456,设置角色:root db.createUser({user:"myroot",pwd:"123456",roles:["root"]}) //创建专门用来管理admin库的账号 myadmin,只用来作为用户权限的管理 db.createUser({user:"myadmin",pwd:"123456",roles:[{role:"userAdminAnyDatabase",db:"admin"}]}) //查看已经创建了的用户情况 db.system.users.find() //删除用户 db.dropUser("myadmin") //修改密码 db.changeUserPassword("myroot", "123456") -

-
-
提示
-
1)本案例创建了两个用户,分别对应超管和专门用来管理用户的角色,事实上,你只需要一个用户即可。如果你对安全要求很高,防止超管泄漏,则不要创建超管用户
-
2)和其它数据库(MySQL)一样,权限的管理都差不多一样,也是将用户和权限信息保存到数据库对应的表中。Mongodb存储所有的用户信息在admin 数据库的集合system.users中,保存用户名、密码和数据库信息。
-
3)如果不指定数据库,则创建的指定的权限的用户在所有的数据库上有效,如
-
-
认证测试
//切换到admin use admin //密码输错,failed db.auth("myroot","12345") //密码正确 db.auth("myroot","123456")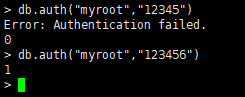
-
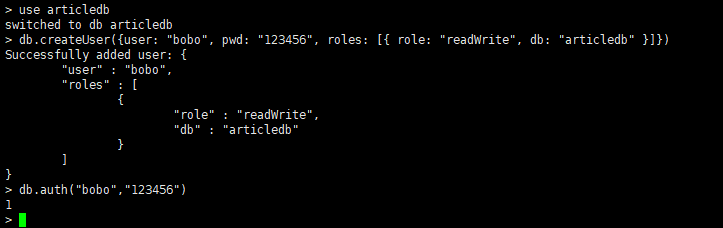
创建普通用户
-
创建普通用户可以在没有开启认证的时候添加,也可以在开启认证之后添加,但开启认证之后,必须使
用有操作admin库的用户登录认证后才能操作。底层都是将用户信息保存在了admin数据库的集合
-
//创建(切换)将来要操作的数据库articledb, use articledb //创建用户,拥有articledb数据库的读写权限readWrite,密码是123456 db.createUser({user: "bobo", pwd: "123456", roles: [{ role: "readWrite", db: "articledb" }]}) //测试是否可用 db.auth("bobo","123456") -
-
-
提示:如果开启了认证后,登录的客户端的用户必须使用admin库的角色,如拥有root角色的myadmin用
户,再通过myadmin用户去创建其他角色的用户
7.2.3 服务端开启认证和客户端连接登录
-
关闭已经启动的服务
-
有两种方式开启权限认证启动服务:一种是参数方式,一种是配置文件方式
-
参数方式

-
配置文件
vim /mongodb/single/mongod.confsecurity: #开启授权认证 authorization: enabled
-
-
有两种认证方式,一种是先登录,在mongo shell中认证;一种是登录时直接认证
-
先连接再认证
-
db.auth("muroot","123456")
-
-
连接时直接认证
-
./mongo --port 27017 --authenticationDatabase admin -u myroot -p 123456 -
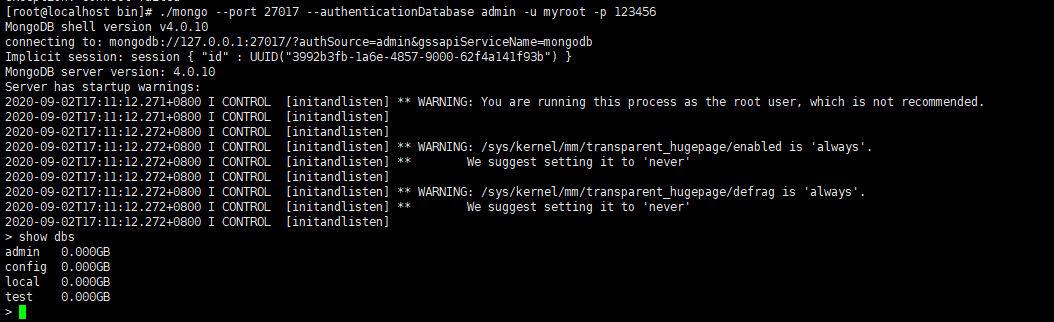
-
提示:
-u :用户名
-p :密码
--authenticationDatabase :指定连接库。当登录是指定用户名密码时,必须指定对应的数据库
-
-
7.2.4 SpringDataMongoDB连接认证
- 使用用户名和密码连接到 MongoDB 服务器,你必须使用'username:password@hostname/dbname' 格式,'username'为用户名,'password' 为密码
- 目标:使用用户bobo使用密码 123456 连接到MongoDB 服务上
7.3 副本集环境
7.3.1 前言
- 对于搭建好的mongodb副本集,为了安全,启动安全认证,使用账号密码登录
- 副本集环境使用之前搭建好的
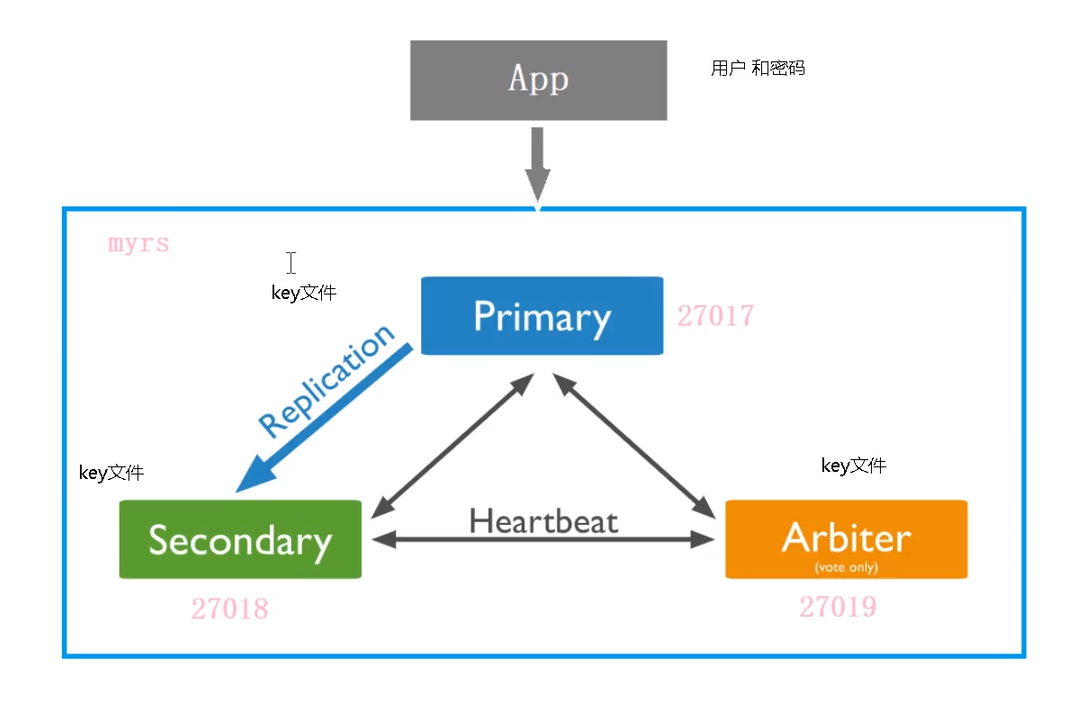
- 对副本集执行访问控制需要配置两个方面
- 副本集和共享集群的各个节点成员之间使用内部身份验证,可以使用密钥文件或x.509证书。密钥文件比较简单,本文使用密钥文件,官方推荐如果是测试环境可以使用密钥文件,但是正式环境,官方推x.509证书。原理就是,集群中每一个实例彼此连接的时候都检验彼此使用的证书的内容是否相同,只有证书相同的实例彼此才可以访问
- 使用客户端连接到mongodb集群时,开启访问授权。对于集群外部的访问。如通过可视化客户端,或者通过代码连接的时候,需要开启授权
- 在keyfifile身份验证中,副本集中的每个mongod实例都使用keyfifile的内容作为共享密码,只有具有正确密钥文件的mongod或者mongos实例可以连接到副本集。密钥文件的内容必须在6到1024个字符之间,并且在unix/linux系统中文件所有者必须有对文件至少有读的权限
7.3.2 关闭已开启的副本集服务(可选)
- 关闭之前测试使用的单机mongod服务
7.3.3 通过主节点添加一个管理员账号
-
依次启动副本集服务
-
只需要在主节点上添加用户,副本集会自动同步
-
开启认证之前,创建超管用户:myroot,密码:123456

7.3.4 创建副本集认证的key文件
-
第一步:生成一个key文件到当前文件夹
-
可以使用任何方法生成密钥文件。例如,以下操作使用openssl生成密码文件,然后使用chmod来更改文件权限,仅为文件所有者提供读取权限
-
openssl rand -base64 90 -out ./mongo.keyfile chmod 400 ./mongo.keyfile ll mongo.keyfile -
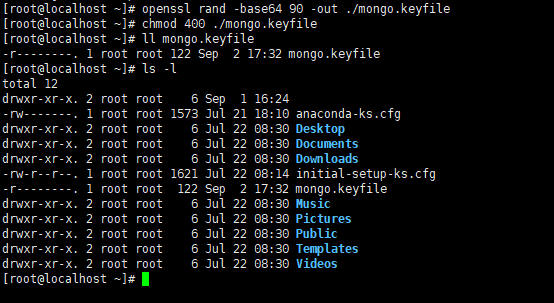
-
-
提示:
所有副本集节点都必须要用同一份keyfifile,一般是在一台机器上生成,然后拷贝到其他机器上,且必须有读的权限,否则将来会报错: permissions on /mongodb/replica_sets/myrs_27017/mongo.keyfile are too open
一定要保证密钥文件一致,文件位置随便。但是为了方便查找,建议每台机器都放到一个固定的位置,都放到和配置文件一起的目录中,这里将该文件分别拷贝到多个目录中
cp mongo.keyfile /mongodb/replica_sets/myrs_27017 cp mongo.keyfile /mongodb/replica_sets/myrs_27018 cp mongo.keyfile /mongodb/replica_sets/myrs_27019
7.3.5 修改配置文件指定keyfile
-
分别编辑几个服务的mongod.conf文件,添加相关内容:
/mongodb/replica_sets/myrs_27017/mongod.conf
security: #KeyFile鉴权文件 keyFile: /mongodb/replica_sets/myrs_27017/mongo.keyfile #开启认证方式运行 authorization: enabled- /mongodb/replica_sets/myrs_27018/mongod.conf、/mongodb/replica_sets/myrs_27019/mongod.conf 同样添加配置
-
修改完配置,依次启动副本集服务
7.3.6 SpringDataMongoDB连接副本集
-
yml文件
server: port: 7777 spring: #数据源配置 data: mongodb: # # 主机地址 # host: 192.168.83.133 # # 默认端口是27017 # port: 27017 # # 数据库 # database: test #用户名 # username: bobo #密码 # password: 123456 # 副本集的连接字符串 #uri: mongodb://192.168.83.133:27017,192.168.83.133:27018,192.168.83.133:27019/articledb?connect=replicaSet&slaveOk=true&replicaSet=myrs #连接路由字符串 #uri: mongodb://192.168.83.133:27017,192.168.83.133:27117/articledb #单机有认证的情况下,也使用字符串连接 #uri: mongodb://bobo:123456@192.168.83.133:27017/articledb #副本集有认证的情况下,字符串连接 uri: mongodb://myroot:123456@192.168.83.133:27017,192.168.83.133:27018,192.168.83.133:2 7019/articledb?connect=replicaSet&slaveOk=true&replicaSet=myrs
7.4 分片集群环境认证
-
一定要保证密钥文件一致,文件位置随便。但是为了方便查找,建议每台机器都放到一个固定的位置,
都放到和配置文件一起的目录中。这里将该文件分别拷贝到多个目录中
echo '/mongodb/sharded_cluster/myshardrs01_27018/mongo.keyfile /mongodb/sharded_cluster/myshardrs01_27118/mongo.keyfile /mongodb/sharded_cluster/myshardrs01_27218/mongo.keyfile /mongodb/sharded_cluster/myshardrs02_27318/mongo.keyfile /mongodb/sharded_cluster/myshardrs02_27418/mongo.keyfile /mongodb/sharded_cluster/myshardrs02_27518/mongo.keyfile /mongodb/sharded_cluster/myconfigrs_27019/mongo.keyfile /mongodb/sharded_cluster/myconfigrs_27119/mongo.keyfile /mongodb/sharded_cluster/myconfigrs_27219/mongo.keyfile /mongodb/sharded_cluster/mymongos_27017/mongo.keyfile /mongodb/sharded_cluster/mymongos_27117/mongo.keyfile' | xargs -n 1 cp -v /root/mongo.keyfile -
分片副本集操作 同副本集
-
不同:/mongos.conf mongos服务的配置文件 添加认证
security: #KeyFile鉴权文件 keyFile: /mongodb/sharded_cluster/mymongos_27017/mongo.keyfile -
不需要authorization:enabled的配置。原因是,副本集加分片的安全认证需要配置两方面的,副本集各个节点之间使用内部身份验证,用于内部各个mongo实例的通信,只有相同keyfifile
才能相互访问。所以都要开启 keyFile: /mongodb/sharded_cluster/mymongos_27117/mongo.keyfile ,然而对于所有的mongod,才是真正的保存数据的分片。mongos只做路由,不保存数据。所以所有的mongod开启访问数据的授权authorization:enabled。这样用户只有账号密码正确才能访问到数据
-
SpringDataMongoDB连接认证
server: port: 7777 spring: #数据源配置 data: mongodb: # # 主机地址 # host: 192.168.83.133 # # 默认端口是27017 # port: 27017 # # 数据库 # database: test #用户名 # username: bobo #密码 # password: 123456 # 副本集的连接字符串 #uri: mongodb://192.168.83.133:27017,192.168.83.133:27018,192.168.83.133:27019/articledb?connect=replicaSet&slaveOk=true&replicaSet=myrs #连接路由字符串 #uri: mongodb://192.168.83.133:27017,192.168.83.133:27117/articledb #单机有认证的情况下,也使用字符串连接 #uri: mongodb://bobo:123456@192.168.83.133:27017/articledb #副本集有认证的情况下,字符串连接 #uri: mongodb://myroot:123456@192.168.83.133:27017,192.168.83.133:27018,192.168.83.133:2 7019/articledb?connect=replicaSet&slaveOk=true&replicaSet=myrs # 分片集群有认证的情况下,字符串连接 uri: mongodb://myroot:123456@192.168.83.133:27017,192.168.83.133:27117/articledb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号