从原理上理解MySQL的优化建议
从原理上理解MySQL的优化建议
预备知识
B+树索引
-
mysql的默认存储引擎InnoDB使用B+树来存储数据的,所以在分析优化建议之前,了解一下B+树索引的基本原理。 -
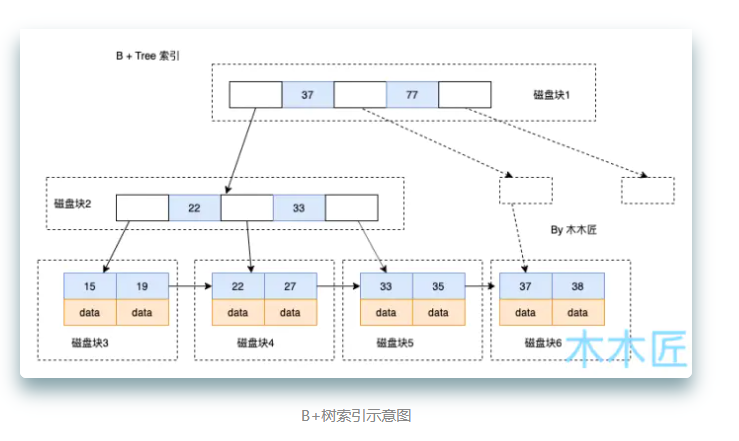
-
上图是一个B+树索引示意图,每个节点表示一个磁盘块,也可以理解为数据库中的页。
-
分析下B+树索引的查找过程,如果我要查询主键为35的数据,索引会怎么走?
- 首先会判断35小于根节点37,继续查询左子树
- 判断35大于22和33,那么进入右子树,找到了叶子节点33
- 继续遍历找到35
- 最后取出其data即可
-
在索引的情况下,查询35只用了3次IO操作,这是非常高效的
-
在真实场景下,3层的B+树可以表示上百万的数据,如果上百万的数据查找只需要3次IO,性能提升将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次IO,显然成本非常非常高
-
上图也是体现了只要 维持树的高度足够低,IO操作就会足够少,IO次数少,查询性能就会高
Explain执行计划

-
各个字段的含义
-
id:Query Optimizer所选定的执行计划中的查询编号 -
select_type:所使用的查询类型,主要有几种查询类型:SIMPLE 除子查询或者UNION查询之外的其他查询 PRIMARY 子查询中的最外层查询,注意并不是主键查询 UNION UNION语句中第二个 SELECT 开始的后面所有 SELECT,第一个 SELECT 为 PRIMARY DEPENDENT UNION 子查询中的 UNION,且为 UNION 中从第二个 SELECT 开始的后面所有 SELECT ,同样依赖于外部查询的结果集 SUBQUERY子查询内层查询的第一个 SELECT,结果不依赖于外部查询结果集 DEPENDENT SUBQUERY子查询内层查询的第一个 SELECT,结果依赖于外部查询结果集 类型名称 说明 -
table:显示执行这一步所访问的数据库中的表的名称
-
partitions:查询分区表匹配的分区,非分区表显示为NULL
-
type:查询表所使用的的方式,类型如下
类型名称 说明 all 全表扫描 const读常量,最多只有一条记录匹配,由于是常量,所以实际上只要读一次 system 系统表,表中只要一条数据,他是特殊的 const类型eq_ref最多会匹配一条结果,一般是通过主键或者唯一索引来访问 ref join语句中被驱动标的索引查询 full_text 使用full_text索引 index 全索引扫描 index_merge 查询中同时使用两个(或者多个)索引,然后对索引结果进行merge之后再读表数据 range 索引范围扫描,经常出现在比较条件中,如:<, > ,BETWEEN 等
-
-
他们的性能由好到差依次是:
system > const > eq_ref > ref > full_text > ref_or_null > unique_subquery > index_subquery > range > index_merge > index > all -
possible_keys: 查询可能用到的索引
-
key_len: 用到的索引长度
-
ref: 展示将那些列或者常量与命中的索引比较
-
rows: 执行这次查询扫描的行数
-
filtered: 过滤行数百分比,最大值是100,当显示100时候,表示没有过滤行, rows显示了检查的估计行数,乘以过滤百分比将显示与下表连接的行数。例如,如果行数为1000,过滤条件为50.00(50%),则与下表联接的行数为1000×50%= 500
-
extra: 执行查询额外的条件
为什么建议使用自增主键
为什么?
- 当我们每次建立表的时候都在考虑是用表的自增主键呢?还是用
uuid呢?但是从性能考虑我们还是建议使用自增 Id,为什么呢?主要是由于MySQLB+ 树索引性质决定的,数据的新增是要更新索引的,也就是要更新 B+ 树。换句话说,使用自增Id 和 非自增 Id 哪种更新 B+ 树更快,成本更低,谁就是更优的选择。我们来模拟下自增 Id 插入和非自增 Id 插入情况。
自增主键与非自增的比较
-
自增Id 插入情况: 我们在一个已经有10条数据的 B + 数上插入2条数据,分别是10和11,我们看看树是如何变化的。
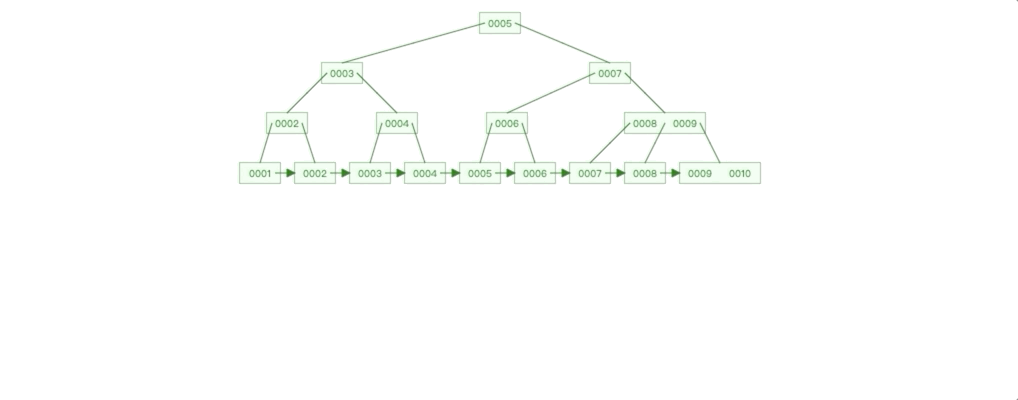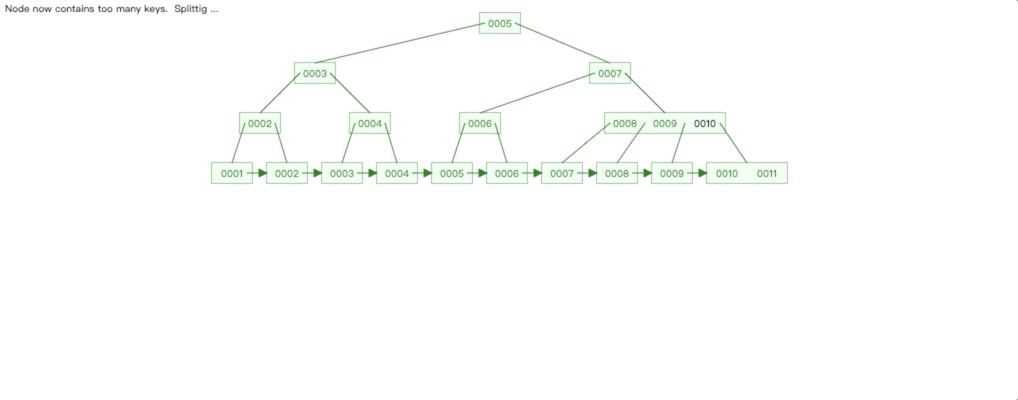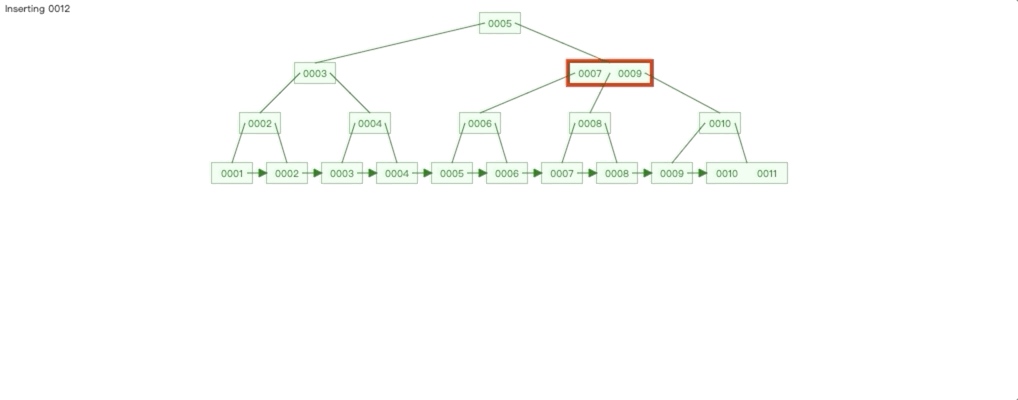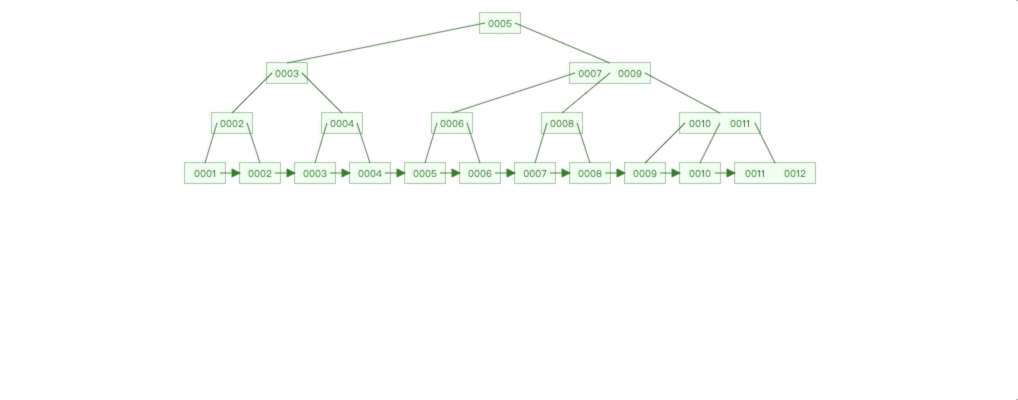
我们这里可以发现两个特点:
1. 自增的数据插入影响的范围永远只有最右的子树,要么直接在子树插入节点,要么就是子树分裂,影响其父节点。
2. 除了最右子树,其他子树的节点都是满的。
3. 上面两个特点有什么影响呢?我们根据前面 B+ 树索引示意图可以知道,每个点都是一个磁盘块,操作每个节点相当于进行一次 IO,由于每次插入影响的节点只有最右子树,那么磁盘 IO 的范围就可控;最重要一点是除最右子树,其他子树的节点都是满的,这种情况,叶子节点数据的物理连续性会更好, 根据局部性原理,查询性能也会更高
-
非自增 Id 插入情况
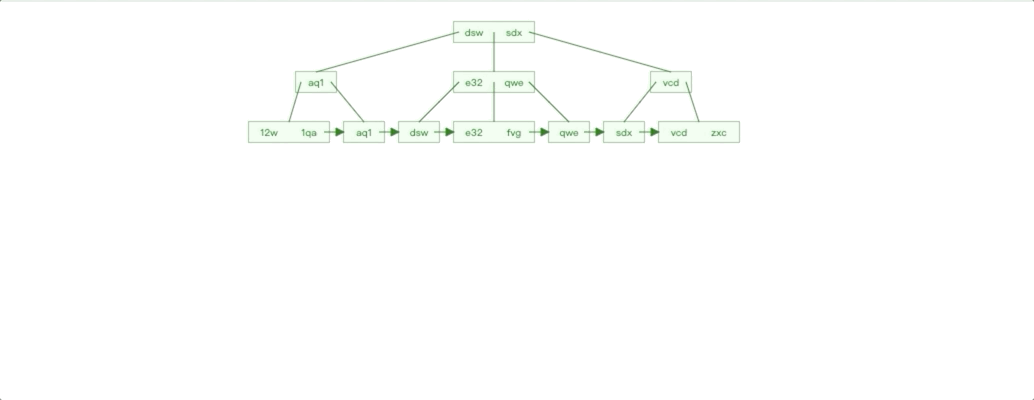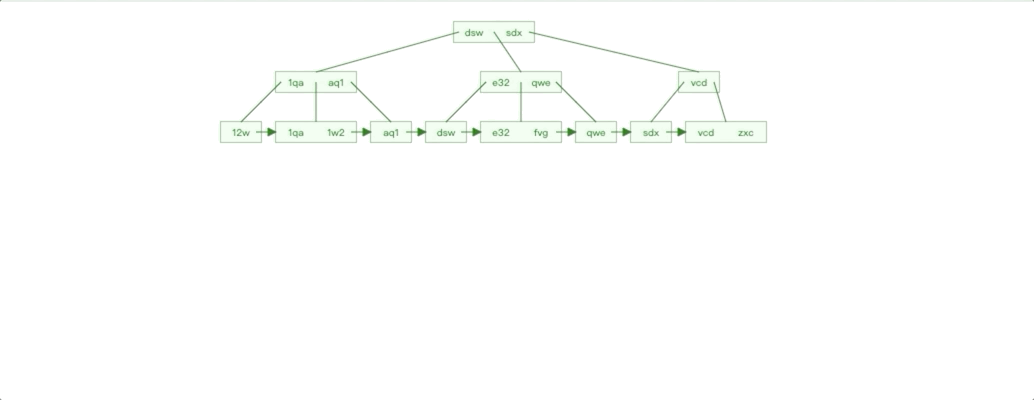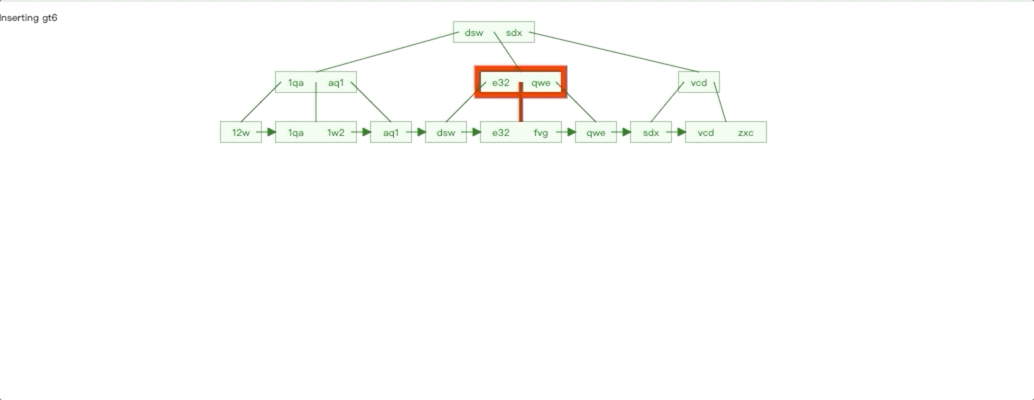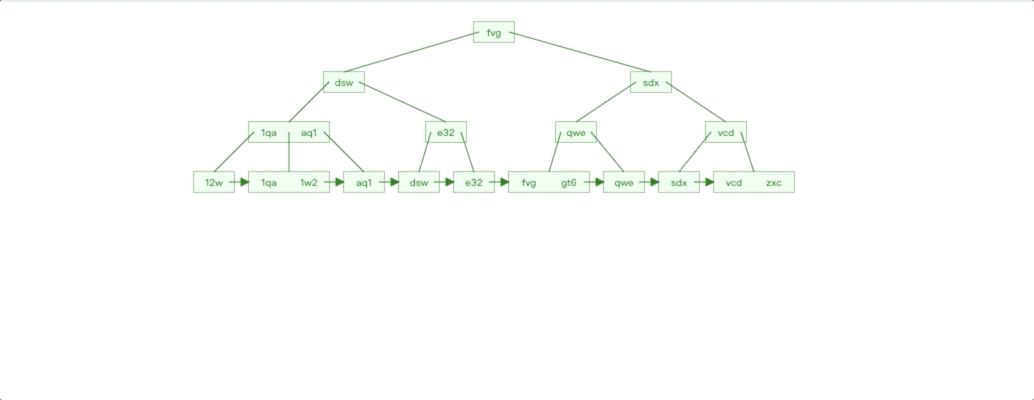
非自增 Id 插入特点对比自增 Id 插入我们很容易就能知道:
-
插入影响节点不可控,无法预知。
-
每个子树都存在叶子节点不满的情况
-
按照之前的分析思路,我们也就知道了非自增 Id 插入有什么性能劣势了。由于插入数据影响节点不可控,导致节点分裂的情况就会更频繁,节点分裂也是 IO 操作,性能自然受到影响。子树的叶子节点不满,会导致叶子节点物理连续性不好。最后如果我们是
UUID的话,Id 过长,会占用节点空间,每个页能存储的节点变少,页分裂变多,性能也会受到影响。这也是为什么建议使用自增主键的原因
-
为什么不要使用 select * 查询
为什么
-
我们能想到很直观的理由就是,数据库要帮你翻译成每个字段名去查询,接着查询多余的字段会占用内存,带宽等资源。这确实是一个理由,而且这个理由很重要
-
但是我这里想说的是另外一个原因,覆盖索引
总结
-
本文从原理上分析了我们日常的两点建议,为什么建议使用自增主键?为什么不建议使用 select * 查询?其实主要最终的原因还是和索引相关,既然我们用索引来提高我们的效率就要充分利用它,下面是知识点总结:
1、B+ 树查询的效率高低是受其树高影响,树的高度越低,查询IO次数越少,性能相对也就越高。
2、执行计划的类型由好到差依次是:
system > const > eq_ref > ref > full_text > ref_or_null > unique_subquery > index_subquery > range > index_merge > index > all。3、自增主键的好处就是连续,插入维护的成本相对较低,同时子树的叶子节点大部分是满节点,物理连续性好,查询性能更优。
4、
UUID主键长度过长,导致单个子节点存储的主键变少,更平凡的出发页分裂,影响性能,这也是为什么建议索引不要太长的原因。5、覆盖索引是很好的优化技巧,可以让查询直接通过索引返回数据,而不用回表,减少IO,提升性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号