
面试总结
周五去了一趟深圳某互联网金融面试,很遗憾吧,没过,听到没过的时候心都碎了,毕竟还是很想去这家公司的,之后还不要脸的问了“能不能再聊聊”,下楼之后,被二面的经理叫回来说跟架构师聊聊,依旧没过。。。面试官很好,还给了很多建议,还说要是有合适的会给你联系的。回想一下,只能怪自己真的太不争气了,没有借口!!!基础!基础!基础!
1. 重写equals为什么要重写hashCode
这个,,,真是个意外,好久没看到过这个问题了,而且好久没重写过equals了,面试官还问“这不是面试常考题么”,额,我还是太菜。
主要有两点:
(1)不被重写(原生)的hashCode值是根据内存地址换算出来的一个值。
(2)不被重写(原生)的equals方法是严格判断一个对象是否相等的方法(object1 == object2)。
常考题还有“==”跟“equals”的区别
2. JVM中survivor区存在的意义是啥
在任何时候,总有一个survivor space是empty的,在下一次coping collection时,会将eden和另一个survivor space里的live object copy到这个里面。
live objects在两个survivor space里copy来copy去,直到对象old enough可以放到tenured generation里(copy 过去的)
因为在垃圾收集的时候需要将dead object清理掉,如果只有一个survivor区,那么这个survivor区里的dead object在清理掉之后就会产生内存碎片,为了避免内存碎片那么必须将live object移动来移动去,这样就会损失性能。
如果有两个survivor区,按照上面的说法,就不会存在内存碎片的问题。
参考:
为什么新生代内存需要有两个Survivor区
3. minor gc、major gc、full gc使用了哪种垃圾回收算法,为什么
先来讲一下这几个算法的特性吧
复制:1.将内存分为两块,只用一块,另一块用来讲这一块的对象复制;2.不会产生内存碎片
标记-清除:1.从引用根节点开始标记所有被引用的对象;2.遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
标记-整理:1.从根节点开始标记所有被引用对象;2.遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
说的有点不够形象,还是用对比的表格来展示吧。
~|Mark-Sweep|Mark-Compact|Copying
-|-|-|-|-
速度|中等|最慢|最快
空间开销|少(但会堆积碎片)|少(不堆积碎片)|通常需要活对象的2倍大小(不堆积碎片)
移动对象|否|是|是
新生代的Minor GC触发条件:Copying算法就是扫描出存活的对象,并复制到一块新的完全未使用的空间中,对应于新生代,就是在Eden和FromSpace或ToSpace之间copy。所有的Minor GC都会触发全世界的暂停(stop-the-world)
老年代的GC(Major GC/Full GC):老年代与新生代不同,老年代对象存活的时间比较长、比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并、要么标记出来便于下次进行分配,总之目的就是要减少内存碎片带来的效率损耗。
4. mq中的queue和topic有什么区别
有点懵逼,mq只是简单的了解一下,没想到会到这点。。。留张图先,后续写篇大文
参考:ActiveMQ——activemq的详细说明,queue、topic的区别(精选)
5. 线程池中shutdown、shutdownNow、isShutdown、isTerminated、awaitTermination的使用场景
好久线程池这一块了,有点搞乱
shutdown在终止前允许执行以前提交的任务
shutdownNow试图停止当前正执行的task,并返回尚未执行的task的list
isShutDown当调用shutdown()方法后返回为true。
isTerminated当调用shutdown()方法后,并且所有提交的任务完成后返回为true
awaitTermination当等待超过设定时间时,会监测ExecutorService是否已经关闭,若关闭则返回true,否则返回false
6. 使用new ThreadPoolExecutor()中里面的几个参数含义以及使用场景(maximumPoolSize超了会怎样)
这题。。。细,太细了
int corePoolSize 核心线程数,核心线程会一直存活,即使没有任务需要执行
int maximumPoolSize 最大线程数
long keepAliveTime 线程空闲时间
TimeUnit unit 指定keepAliveTime的单位,如TimeUnit.SECONDS。当将allowCoreThreadTimeOut设置为true时对corePoolSize生效。
BlockingQueue<Runnable> workQueue 线程池中的任务队列
ThreadFactory threadFactory 线程工厂,提供创建新线程的功能。
RejectedExecutionHandler handler 当线程池中的资源已经全部使用,添加新线程被拒绝时,会调用
corePoolSize、maximumPoolSize之间的关系
1.如果线程数量<=核心线程数量,那么直接启动一个核心线程来执行任务,不会放入队列中。
2.如果线程数量>核心线程数,但<=最大线程数,并且任务队列是LinkedBlockingDeque的时候,超过核心线程数量的任务会放在任务队列中排队。
3.如果线程数量>核心线程数,但<=最大线程数,并且任务队列是SynchronousQueue的时候,线程池会创建新线程执行任务,这些任务也不会被放在任务队列中。这些线程属于非核心线程,在任务完成后,闲置时间达到了超时时间就会被清除。
4.如果线程数量>核心线程数,并且>最大线程数,当任务队列是LinkedBlockingDeque,会将超过核心线程的任务放在任务队列中排队。也就是当任务队列是LinkedBlockingDeque并且没有大小限制时,线程池的最大线程数设置是无效的,他的线程数最多不会超过核心线程数。
5.如果线程数量>核心线程数,并且>最大线程数,当任务队列是SynchronousQueue的时候,会因为线程池拒绝添加任务而抛出异常。
参考:
ThreadPoolExecutor线程池参数设置技巧
Java多线程-线程池ThreadPoolExecutor构造方法和规则
7. ConcurrentHashMap中Segment的作用,还有用了什么锁
此问题保留,改天看源码写文章。。。。
8. tail -f中f的含义
-c, --bytes=N 输出最后N个字节
-F 等同于--follow=name --retry,**根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪**
-f, --follow[={name|descriptor}] 根据文件描述符进行追踪,当文件改名或被删除,追踪停止; -f, --follow以及 --follow=descriptor 都是相同的意思
-n, --lines=N 输出最后N行,而非默认的最后10行
--max-unchanged-stats=N 参看texinfo文档(默认为5)
--max-consecutive-size-changes=N 参看texinfo文档(默认为200)
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
-v, --verbose 总是输出给出文件名的首部
--help 显示帮助信息后退出
--version 输出版本信息后退出
9. df -h中h的含义
我有点慌,df --help看了下我还是记不住那么多。。。
-a, --all 全部文件系统列表
-B, --block-size=SIZE 使用SIZE大小的Blocks
-h, --human-readable 以可读性较高的方式来显示信息
-H, --si 与-h参数相同,但在计算时是以1000 Bytes为换算单位而非1024 Bytes;
-i, --inodes 显示inode的信息;
-k 指定区块大小为1024字节;跟--block-size=1K一样
-l, --local 仅显示本地端的文件系统;
--no-sync 在取得磁盘使用信息前,不要执行sync指令,此为预设值;
-P, --portability 使用POSIX的输出格式;
--sync 在取得磁盘使用信息前,先执行sync指令;
-t, --type=TYPE 仅显示指定文件系统类型的磁盘信息;
-T, --print-type 显示文件系统的类型;
-x, --exclude-type=TYPE 不要显示指定文件系统类型的磁盘信息;
-v (ignored)
--help display this help and exit
--version output version information and exit
10. fastdfs原理
这个真的没有深入研究的,写在简历上是希望通过引入新技术(之前一直用的JDK1.6写的FTP文件服务器),给团队带来贡献的,结果没有说出来,相当于挖了个坑把自己埋了,好尴尬,先在这放张图,有空再深入研究下了。
11. 分布式锁原理与实现方式,如果保持一致性,秒杀架构中会加1000把锁?
分布式锁是最近刚开始看的问题,知道目前通常实现方式有三种:1.数据库的共享锁;2.Redis;3.ZooKeeper,其中Redis的实现方式核心是setnx(set if not exist),只看过一点点Redisson的源码。面试的时候被问到了,有点慌的其实,毕竟公司没有项目用到分布式锁这种东西,面试官还不一直不信,问我“那你们提工单的时候如果处理点击多次的情况”。
此问题保留,后续会写一篇RedissonLock源码的文章。
参考:
Redisson
基于Redis实现分布式锁,Redisson使用及源码分析
12. threadlocal有何缺陷
Java中的ThreadLocal 变量用于将变量同当前线程绑定,每个线程都有自己独立的ThreadLocal变量。这些变量通常用于保存一些变量的状态信息,譬如用户信息这种在整个应用中都使用的到并且你不想在每个方法中都重新声明。hreadLocal对Key使用到了弱引用,但是为了保证不再内存泄露,在每次set.get的时候主动对keynull的entry做遍历回收。虽然不会造成内存泄露,但是因为只有在每次set,get的时候才会对entry做keynull的判断,从而释放内存,所以可能使大对象在内存中存活很长一段时间,从而占用内存。所以,我们在使用完ThreadLocal里的对象后最好能手动remove一下,或者至少调用下ThreadLocal.set(null)。
参考:
Java并发编程:深入剖析ThreadLocal
ThreadLocal内存泄露
ThreadLocal内存泄露分析
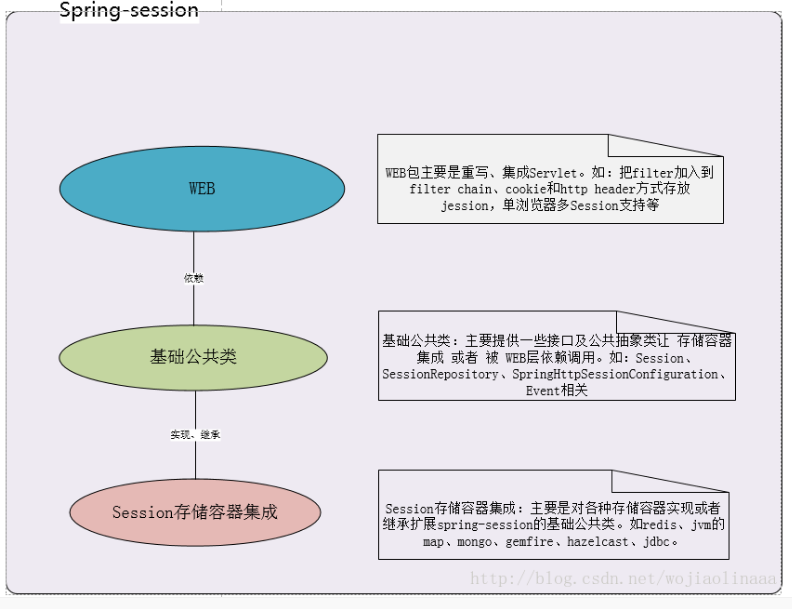
13. cookie和session的原理,分布式场景下如何保持唯一。
这个问题,一开始我觉得自己理解还是足够的,毕竟自己做过网站,爬虫还做了不少,但是说出来的时候,跟自己想象中的很不一样,这里再次总结一下吧。由于HTTP是无状态的协议,一旦数据交换完毕,客户端和服务器的连接就会关闭,如果需要重新连接,那么久必须发起新的会话。所以,在客户端和服务器中保存相关的信息是通过cookie和session来实现的。简单的来说,session存储于服务端,cookie存在于客户端,每次会话时服务器会在内存中开辟一小块内存空间记录会话,session的运行依赖于session id(tomcat中叫jsessionid),而session id是存储在cookie中的,如果浏览器禁用了cookie,那么session也会失效,以大部分登录网站为例,可以试试登录之后禁用cookie,刷新页面,登录信息没了,之后是再怎么登录也登录不进去。所以,需要记录的点是:
1.session存储在服务端,cookie存储在客户端(浏览器);
2.服务端中记录唯一会话标示用的是session id,tomcat中叫做jsessionid,cookie中保存session id,发送请求的时候携带sessionid
3.session存放的位置一般放在服务器的内存中,分布式环境下一般都是用spring-session和redis构建。
4.cookie安全性差,一般采用加密。而且不能跨域。
分布式环境下如何保存,公司采用的还是memcache,新项目都换成了redis集群。公司的不是我负责的,但是,我自己的项目用到了spring-session和redis,可是面试的时候,不知道怎么了,没有发挥出来,我也是醉了。
参考:
Cookie和session详解
COOKIE和SESSION有什么区别?
spring-session简介、使用及实现原理
14. 你对你们公司项目有什么深入的理解么?
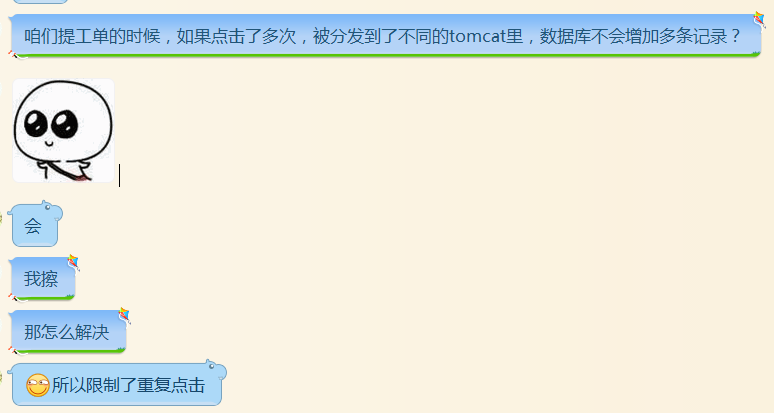
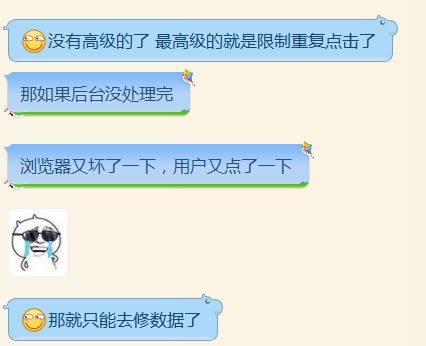
这个问题。。。本质上挺好,但是,我们公司的项目真的没有技术含量,面试官不信,我都不知道该怎么回答了,说我们公司项目很牛逼?但是牛逼在哪里?全都是增删改查的项目,缓存还用的ehcache,而且用缓存的地方及其少,JDK还用的1.6。。。把我们部门的项目给公司其他部门看,别人说,我以为我这边的项目已经够烂了,没想到还有更烂的,不想看你们的。离职前还问了我们组技术最好的项目有没有技术深度高一点的东西,想了半会,跟我说没有,我又问了,提工单的时候如何保持一致性的,下面是聊天记录,可以看下。其实我也超想挖掘项目中比较高深的东西,但是,我们做的就是业务系统,我有啥办法啊。。。
公司的防止重复提交方法,点击一次后让它不可点击。如果浏览器坏了发送了两次请求,需要人工干预。
list[i].disabled = false;
下面是聊天记录:

总结:
都是基础,真恨自己平时没总结,一心只想看架构,结果地基都没打好,导致面试的时候,楼全面崩塌了。。。。好好反思吧。。。
BTY:
本人目前已离职,如果觉得我还行,,,,,希望各位大佬内推,B轮融资以上的就更好了。。。哦对,坐标深圳。
个人网站:http://www.wenzhihuai.com/
我的简历:http://www.wenzhihuai.com/myresume.html
GitHub:https://github.com/Zephery

您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号