

第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 完成项目论文查重并进行性能测试 |
githup地址:https://github.com/ironman-wu/3122004753
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 50 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 400 | 500 |
| Analysis | 需求分析(包括学习新技术) | 200 | 240 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 5 | 10 |
| Coding Standard | 代码规范 | 20 | 15 |
| Design | 具体设计 | 40 | 45 |
| Coding | 具体编码 | 240 | 300 |
| Code Review | 代码复审 | 50 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 120 | 90 |
| Test Report | 测试报告 | 120 | 90 |
| Size Measurement | 计算工作量 | 5 | 10 |
| Postmortem & Process Improve Plan | 事后总结,并提交过程改进计划 | 10 | 10 |
| ToTal | 合计 | 1335 | 1470 |
2.函数设计及流程图
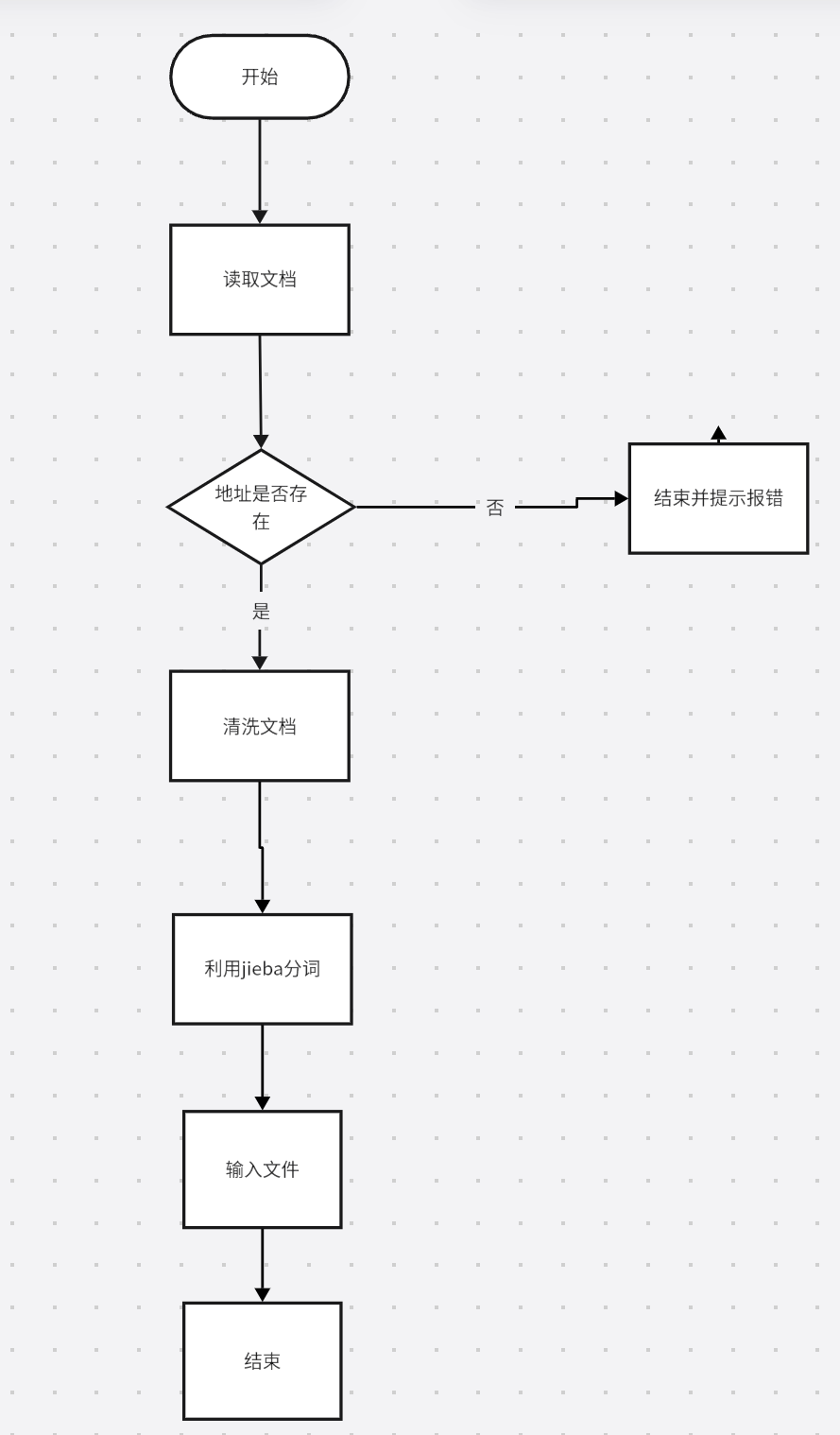
3.算法分析
1.文本清洗:清洗掉文档中的标点符号
2.分词:利用jieba库对文档进行分词
3.统计高频词:对分词后的文档进行统计并排序
4.计算余弦相似度:利用余弦公式计算值,值越大则越不相似,值越小则越相似
4.接口设计
1.read_clean_file:
- 作用:读取文档,并且进行清洗
- 报错:若路径不存在,则警告并停止程序
2.merge_keywords:
- 将原文文件和抄袭文件中的高频词提取并合并在一个集合中
3.sort_keywords:
- 将原文文件和抄袭文件中的高频词按照由merge_keywords中得到的集合排序
4.word_frequency:
- 将读出的文档进行分词并统计高频词
5.cosine_similarity
- 计算余弦值
5.分析并消除所有的警告

6.性能分析


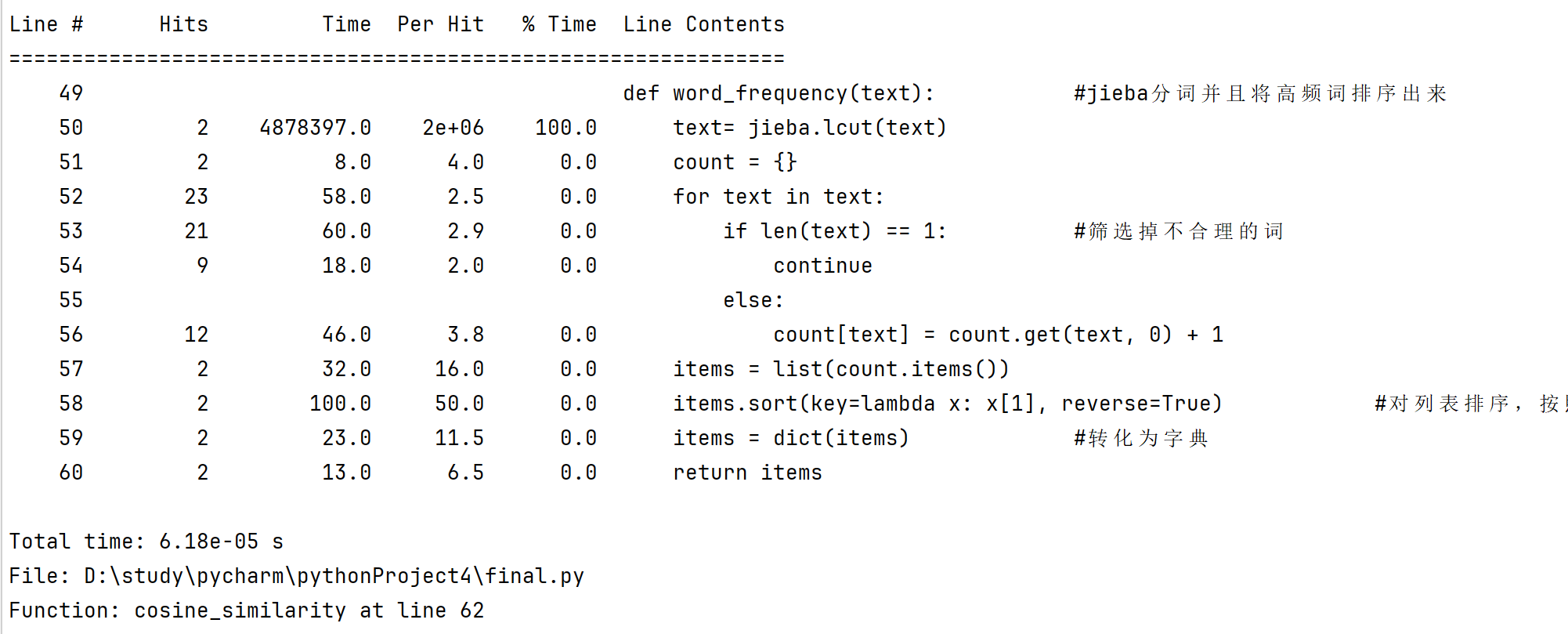



由性能分析可知:耗时最长的函数为:word_frequency()中的jieba.lcut()
代码覆盖率

测试情况
1.若输入的答案路径缺失:

2,若输入的原文文件路径缺失

3.若输入的抄袭文件路径缺失

4.若输入的路径不存在

5.若原文文件与自身相比
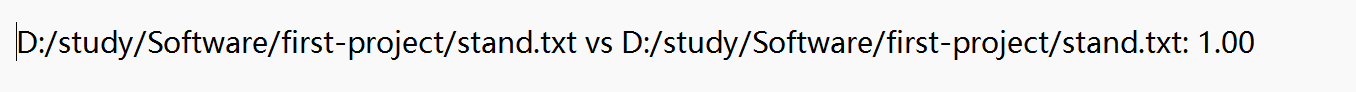
6.若原文文件与空白文件相比

7.若原文文件与部分相同文件相比

单元测试
点击查看代码
class TestMyFunction(unittest.TestCase):
def test_read_clean_file(self):
path = 'D:/study/pycharm/pythonProject4/Unit_tests'
result = read_clean_file(path)
self.assertEqual(result, "这是一个测试用例")
def test_merge_keywords(self):
result = merge_keywords(text_x={'我们':4,'现在':1,'很好':2},text_y={'我们':2,'未来':8,'不错':9})
self.assertEqual(result,{'我们','现在','未来','很好','不错'})
def test_sort_keywords(self):
result = sort_keywords({'我们':3,'陪着':8,'她们':9},{'他们':2,'陪着':2,'我们':2},{'我们','他们','她们','陪着'})
self.assertEqual(result,({'我们':3,'陪着':8,'她们':9,'他们':0},{'他们':2,'陪着':2,'我们':2,'她们':0}))
def test_word_frequency(self):
result = word_frequency('我们上学开心我们')
self.assertEqual(result,{'我们':2,'上学':1,'开心':1})
def test_cosine_similarity(self):
result = cosine_similarity({'谁的':3,'书本':3,},{'他们':2,'陪着':2},{'谁的','他们','陪着','书本'})
self.assertEqual(result,0)


