

计算机视觉
一、Pyimagesearch Gurus概念理解
模块1:计算机视觉基础
接受在计算机视觉处理中,所需要运用的图像的一些概念。
1.1、加载、显示、保存图像
从本地磁盘上通过imread函数获取图片后,可运用一个变量接收图片。
1、运用cv2.imread("图像路径",读取图片的方法)函数加载图片,返回图片变量。参数2为可选图像,读取图像的方式有多种:
2、运用cv2.imshow("窗口名字",图片变量)
3、运用cv2.imwrite("图像存入的路径与名字",需要存入的图片变量)
1.2、图像基础
1、像素:指图像中我们给定位置的光的"颜色",或“强度”,我们通常用像素来描述图片的大小。
2、像素的两种表示方式:灰度,像素值范围【0,255】。色彩,通常用RGB表示,用红、绿、蓝三个分量表示,每个分量取值范围【0,255】
3、像素网格:用来表示图像中的位置信息
4、访问和操作像素
运用shape函数:1、获取图像的像素的高和宽(h,w)=image.shape[:2]。2、获取图像的部分像素(截取图像) t1=image[0:y,0:x] 参数1:获取图像的高度。参数2:获取图像的宽度
1.3、绘图
绘制画布:np.zeros((300,300,3),dtype="uint8")#参数1:画布长、宽、颜色。参数2:数据类型
画线:cv2.line(image,(x,y),(x1,x2),color,pixel) 参数1:绘制的图像,参数2:线条的起点位置,参数3:线条的终点位置,参数4:绘制线条的颜色(运用RGB颜色),参数5(可选):绘制线条的像素宽度,-1表示填充矩形
画矩形:cv2.rectangle(image,(x,y),(x1,y1),color,pixel) 参数1:绘制的图像,参数2:矩形左上角位置,参数3:矩形右位置,参数4:绘制线条的颜色(运用RGB颜色),参数5(可选):绘制矩形线条的像素宽度,-1表示填充矩形
绘制圆:cv2.circle(image,(x,y),r,white,pixel) 参数1:绘制的图像,参数2:圆心位置,参数2:圆的半径,参数3:绘制圆线条的颜色(运用RGB颜色),参数5:绘制圆形线条的像素宽度,-1表示填充圆形
1.4.1、翻译
指图像的像素的移动
M=np.float32([[1,0,x],[0,1,y]]) 定义翻译矩阵,x表示左右移动像素,正数向右移动,负数向左移动。y表示上下移动像素,正数向下移动,负数向上移动
shifted=cv2.warpAffine(image,M,(image.shape[1],image.shape[0])) 翻译后图像的大小,参数1:被翻译的图像,参数2:定义的翻译的矩阵,参数3:翻译后图像的大下
1.4.2、图像的旋转
M=cv2.getRotationMatrix2D((x,y),Φ,multiple) 定义旋转矩阵,参数1:旋转的中心点,参数2:旋转的角度,参数3:旋转后图像放大的倍数
rotated=cv2.warpAffine(image,M,(w,h)) 旋转图像,参数1:被旋转的图像,参数2:定义的旋转矩阵,参数3:旋转后图像的大小
1.4.3、图像大小调整
resized=cv2.resize(image,dim,interpolation=cv2.INTER_AREA) 图像大小调整函数,参数1:被调整的图像,参数2:调整后图像的大小,参数3:图像变换后的插值方法。不同的插值方法,对图像变大后的处理效果有所不同
插值方法:
cv2.INTER_AREA邻近插值方法:使用邻域光学的增加或减小图像的大小
cv2.INTER_LINEAR双线性插值方法:
cv2.INTER_UBIC和cv2.INTER_LANCZOS4
imutils包中调整图像大小,是长宽等比例调整
imutils.resize(image,width=x,height=y,inter=cv2.INTER_AREA) 参数1:调整的图像,参数2:调整后图像宽度(未填参数3,高将等比例缩放),参数3:调整后图像高度(未填参数2,宽将等比例缩放),参数3:选用插值方法
1.4.4、翻转(图像的镜像)
图像翻转函数:flipped = cv2.flip(image, method) 参数1:被选装的图像,参数2:选装的方法,0:沿x轴翻转,即上下翻转,1:沿y轴方向翻转,即左右翻转,-1:沿俩个方向翻转
1.4.5、图像裁剪
可以运用图像裁剪的方法,将俩正图片进行拼接
t1=image[y:y1,x:x1] 参数1:裁剪图像的高度,y:高度起点位置,y1:高度结束位置;参数2:裁剪图像的宽度,x:宽度起点位置,x1:宽度结束位置
1.4.6、图像算术
项目实例
1、运用二阶矩阵,提取物体的旋转角度

import cv2
import numpy as np
image = cv2.imread("1.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray_show = cv2.resize(gray, (int(gray.shape[1] * 0.25), int(gray.shape[0] * 0.25)))
cv2.imshow("gray_show", gray_show)
cv2.waitKey(0)
blurred = gray
thres =cv2.threshold(blurred, 90, 255, cv2.THRESH_BINARY_INV)[1] #将图片二值化
k = np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]])
thres_image = cv2.dilate(thres.copy(), k, iterations = 8)
thres_show = cv2.resize(thres_image,(int(thres.shape[1]*0.25), int(thres.shape[0]*0.25)))
mask = np.zeros(image.shape[:2], dtype = "uint8")
cv2.imshow("thres_image", thres_show)
cv2.waitKey(0)
biaoji=True
#提取图片中轮廓
(_,cnts,_) =cv2.findContours(thres_image.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
for (j, c) in enumerate(cnts):
area = cv2.contourArea(c)
#根据面积,获取物体轮廓
if area > 85000 or area < 25000:
continue
box = cv2.minAreaRect(c)
(cx, cy), (cw, ch), min_ca = box
print j,cx, cy, min_ca
(x, y, w, h) =cv2.boundingRect(cnts[j])
box =np.int0(cv2.boxPoints(box))
cv2.drawContours(image, [box], -1, (0, 0, 255), 2)
h_half=ch/2
w_half=cw/2
#依据最小包围矩阵,提取物体轮廓,并将物体旋转
M=cv2.getRotationMatrix2D((cx,cy),min_ca,1)
rect_without_angle=cv2.warpAffine(thres_image, M, (image.shape[1], image.shape[0]))[
int(cy - h_half):int(cy + h_half),
int(cx - w_half):int(cx + w_half)]
(_, rect_without_cnts, _) = cv2.findContours(rect_without_angle.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
c_sorted = sorted(rect_without_cnts, key=cv2.contourArea, reverse=True)
moments_c = c_sorted[0]
m = cv2.moments(moments_c)
if biaoji:
xx = m['m10'] / m['m00']
yy = m['m01'] / m['m00']
biaoji=False
a = m['m20'] / m['m00'] - xx * xx
b = m['m11'] / m['m00'] - yy * yy
c = m['m02'] / m['m00'] - yy * yy
print np.arctan2(b, (a - c))
moments_ca = (np.arctan2(b, (a - c))) / 2
moments_ca = moments_ca / 3.1415926 * 180
#依据二阶矩阵与最小包围矩阵旋转角度,分析物体实际旋转角度
if moments_ca>10 and moments_ca<16:
min_ca=min_ca+180
if moments_ca>80 and moments_ca<100:
min_ca=min_ca+90
cv2.putText(image, "n:%d,a:%.2f " % (j, min_ca), (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 3)
#cv2.imshow("rect%d-%.2f"%(j,moments_ca),rect_without_angle)
# image_show = cv2.resize(image, (int(image.shape[1] * 0.25), int(image.shape[0] * 0.25)))
# cv2.imshow("image_show", image_show)
# cv2.waitKey(0)
cv2.imwrite("min_find_angle.jpg", image)
image_show = cv2.resize(image,(int(image.shape[1]*0.25), int(image.shape[0]*0.25)))
cv2.imshow("image_show",image_show)
cv2.waitKey(0)
第一章 计算机视觉基础
1、加载、显示、保存图像
import argparse import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="Path to the image")#读取指定指令,获取图片。参数1:输入指令的头字母,参数2:需要输入的指令 args = vars(ap.parse_args()) image = cv2.imread(args["image"]) #读取指定参数的,读取照片 print "width: %d pixels" % (image.shape[1]) # 获取图像的宽度,横向尺寸,图像坐标系中,第二个参数 print "height: %d pixels" % (image.shape[0] )#获取图像的高度,竖向尺寸,图像坐标系中,第一个参数 注意:读取图像x,y互换 print "channels: %d" % (image.shape[2]) cv2.imshow("Image", image)#显示图片 cv2.imwrite("newimage.jpg", image) #将图片写入指定路径 cv2.waitKey(0)#等待程序结束
2、图像基础
(h, w) = image.shape[:2] #(x,y)像素中的显示,获取图片的高度(x),获取图片的宽度(y) (b, g, r) = image[0, 0] #获取指定位置的像素,存储方式为bgr (cX, cY) = (w / 2, h / 2) #cX:图片的宽度,cY:图片高度 tl = image[0:cY, 0:cX] #获取图片的左上角部分[起始点x坐标:终点x坐标,起点的y坐标:终点y坐标],得出的值分别指高度和宽度 #运用像素指定位置赋值方法,向Background图片上插入图片resized_left for left_x in xrange(0, 500, 1): for left_y in xrange(0, 500, 1):
Background[400 + left_x, 20 + left_y] = resized_left[left_x, left_y]
3、绘图
canvas = np.zeros((300, 300, 3), dtype="uint8") #设置画布尺寸 green = (0, 255, 0)#设置线条颜色 cv2.line(canvas, (0, 0), (300, 300), green) #参数1:指定画布,参数2:线条的开始位置,参数3:线条终点位置,参数4:线条颜色 cv2.line(canvas, (300, 0), (0, 300), red, 3) #参数5:线条像素厚度 cv2.rectangle(canvas, (10, 10), (60, 60), green)#参数1:指定画布,参数2:矩形起点位置,参数3:矩形对角线点的位置,线条颜色 cv2.rectangle(canvas, (50, 200), (200, 225), red, 5)#参数5:线条宽度,负数表示填充矩形 (centerX, centerY) = (canvas.shape[1] / 2, canvas.shape[0] / 2)#设置圆心坐标 white = (255, 255, 255)#设置圆的线条颜色 cv2.circle(canvas, (centerX, centerY), r, white)#参数1:画布,参数2:圆心点,参数3:设置圆的半径,设置画圆的线条颜色 cv2.circle(canvas, tuple(pt), radius, color, -1)#参数4:设置画圆的线条粗细,如果为负数,表示填充圆
4、图像处理
4.1、翻译
M = np.float32([[1, 0, -50], [0, 1, -90]]) #定义翻译矩阵 :参数1:[1,0,x]:x表示像素向左或者向右移动个数,x为负值图像左移,正值为右移定。参数2:[0,1,y]:y表示像素上下移动,y为负值向上移动,正值向下移动。记忆口诀:前左负右正,后上负下正 shifted = cv2.warpAffine(image, M, (image.shape[1],image.shape[0]))#对矩阵进行翻译 参数1:翻译的目标图像,参数2:翻译的矩阵,参数3:翻译后图像大小 #imutils模块的翻译函数 shifted = imutils.translate(image, 0, 100)#参数1:移动的目标图像,参数2:左右移动的值,参数3:上下移动的值
注:不会改变图像大小。
4.2、旋转
注:运用翻译将图片移到中心位置,四周留出黑色边框,在运用旋转(旋转角度为0),可将图片放大
(h, w) = image.shape[:2] #获取图像的高和宽 (cX, cY) = (w / 2, h / 2) #获取图像的中心点 M = cv2.getRotationMatrix2D((cX, cY), 45, 1.0) #设置旋转矩阵,参数1:旋转点 参数2:旋转角度,正值逆时针旋转,负值顺时针选装,参数3:旋转后图像与原始图像的比例,图像原始大小不会发生变化,类似相机焦距变化 rotated = cv2.warpAffine(image, M, (w, h)) #参数1:目标图像,参数2:旋转矩阵,参数3#旋转后的图像尺寸 #imutils模块的旋转函数 rotated = imutils.rotate(image, 180) #参数1:旋转目标图片 参数2:旋转角度 center=(x,y)可以设置旋转点
4.3、图像大小调整
注:改变原始图片的实际大小
r = 150.0 / image.shape[1] #新图像与旧图像的宽比例 注:方便图片按原比例缩放 dim = (150, int(image.shape[0] * r)) #设置新图像的像素尺寸 resized = cv2.resize(image, dim, interpolation=cv2.INTER_AREA) #调整图像大小,返回一个新图像 #运用imutils中的resize函数 resized = imutils.resize(image, width=100) #参数1:目标图像,参数2:设置新图像的宽度,可以为height,运用高度 #运用插值方法缩放大图片,,通过不同的像素填充方法放大图片。 resized = imutils.resize(image, width=image.shape[1] * 3, inter=method)#参数1:目标图片,参数2:处理后图片像素宽(整形),参数3:像素处理方法 """method: cv2.INTER_NEAREST:最近邻内插值 cv2.INTER_LINEAR:双线性插值 cv2.INTER_AREA:区域插值 cv2.INTER_CUBIC:双三次插值 cv2.INTER_LANCZOS4 :双三次插值
4.4、图像翻转
flipped = cv2.flip(image, 1)#水平翻转 flipped = cv2.flip(image, 0)#上下翻转 flipped = cv2.flip(image, -1)#水平翻转后上下翻转
4.5、图像裁剪
face = image[85:250, 85:220] #参数1:裁切高度 x开始位置:x结束位置,参数2:裁切宽度 y开始位置:y结束位置,返回新图片
4.6、图像像素像素值操作
注:修改图片的亮度
M = np.ones(image.shape, dtype = "uint8") * 100 #设置与图片大下相同的矩阵,矩阵填充值为100 added = cv2.add(image, M)#将原始图片与新矩阵相加,像素亮度提高100 M = np.ones(image.shape, dtype = "uint8") * 50#设置与图片大下相同的矩阵,矩阵填充值为50 subtracted = cv2.subtract(image, M)#将原始图片与新矩阵相减,像素亮度降低50
4.7、按位操作
注:主要是黑白图像处理
bitwiseAnd = cv2.bitwise_and(rectangle, circle)#当且仅当俩个相同位置的像素大于0,才返回真 bitwiseOr = cv2.bitwise_or(rectangle, circle)#俩个相同位置的像素有一个大于0,返回真 bitwiseXor = cv2.bitwise_xor(rectangle, circle)#当且仅当俩个相同位置的像素只有一个大于0,才返回真 bitwiseNot = cv2.bitwise_not(circle)#像素值取反
4.8、掩蔽
注:提取图像中感兴趣的部分,遮掩的必须用关键字mask
mask = np.zeros(image.shape[:2], dtype="uint8") #设置掩蔽画布的大小 cv2.rectangle(mask, (0, 90), (290, 450), 255, -1)#设置不掩蔽的地方 masked = cv2.bitwise_and(image, image, mask=mask)#图片显示的区域
4.9、像素分割与合并
(B, G, R) = cv2.split(image) #像素分离图像,B,G,R图像的值为整数,非BGR像素矩阵组成,其值是如何转变的? merged = cv2.merge([B, G, R]) #三个色彩合并,还原为彩色图像,像素由BGR像素矩阵组成 zeros = np.zeros(image.shape[:2], dtype = "uint8")#建立一个二值画布,与各个色彩通道合并,像是各个色彩通道的影响 cv2.imshow("Red", cv2.merge([zeros, zeros, R]))#只有红色的图片 cv2.imshow("Green", cv2.merge([zeros, G, zeros]))#只有绿色的图片 cv2.imshow("Blue", cv2.merge([B, zeros, zeros]))#只有蓝色的图片
问:如何从BGR转换成整数值
5、内核
略
6、形态操作
image = cv2.imread(args["image"]) #打开一张图片 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)#将图片转为二值划 #侵蚀 将前景物体变小,理解成将图像断开裂缝变大(在图片上画上黑色印记,印记越来越大) for i in xrange(0, 3): eroded = cv2.erode(gray.copy(), None, iterations=i + 1)#参数1:需要侵蚀的图像,参数2:结构元素() 参数3:迭代次数,值越大,侵蚀越严重 cv2.imshow("Eroded {} times".format(i + 1), eroded) cv2.waitKey(0) #扩张 将前景物体变大,理解成将图像断开裂缝变小(在图片上画上黑色印记,印记越来越小) for i in xrange(0, 3): dilated = cv2.dilate(gray.copy(), None, iterations=i + 1)#参数1:需要侵蚀的图像,参数2:结构元素() 参数3:迭代次数,值越大,扩张越大 cv2.imshow("Dilated {} times".format(i + 1), dilated) cv2.waitKey(0) #开盘 应用侵蚀以去除小斑点,然后应用扩张以重新生成原始对象的大小,用于消除杂质 kernelSizes = [(3, 3), (5, 5), (7, 7)]#定义结构化元素的宽度和高度 for kernelSize in kernelSizes: kernel = cv2.getStructuringElement(cv2.MORPH_RECT, kernelSize) #参数1:结构化元素的类型 参数2:构造元素的大小 opening = cv2.morphologyEx(gray, cv2.MORPH_OPEN, kernel)#参数1:形态学运算的图像 参数2:形态操作的实际 类型 参数3:内核/结构化元素 cv2.imshow("Opening: ({}, {})".format(kernelSize[0], kernelSize[1]), opening) cv2.waitKey(0) """形态操作实际类型: cv2.MORPH_CLOSE(闭幕):用于封闭对象内的孔或将组件连接在一起 cv2.MORPH_GRADIENT(形态梯度):用于确定图像的特定对象的轮廓 """ #顶帽/黑帽 显示黑色背景上的图像的 明亮区域。适合于灰度图像 rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 5))#定义宽度为13 像素和高度为 5像素的 矩形 结构元素 blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKernel)#参数1:形态学运算的图像 参数2:形态操作的实际 类型 参数3:内核/结构化元素 tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel) #参数1:形态学运算的图像 参数2:形态操作的实际 类型 参数3:内核/结构化元素
7、平滑和模糊
kernelSizes = [(3, 3), (9, 9), (15, 15)] #定义内核大小参数列表,内核越大,模糊越明显 # loop over the kernel sizes and apply an "average" blur to the image for (kX, kY) in kernelSizes: blurred = cv2.blur(image, (kX, kY))#使用平均模糊方法,参数1:模糊对象,参数2:矩阵大小 cv2.imshow("Average ({}, {})".format(kX, kY), blurred) cv2.waitKey(0) """模糊方法: 平均模糊:过度模糊图像并忽略重要的边缘 blurred =cv2.blur(image, (kX, kY)) 高斯:保留更多的图像边缘 blurred =cv2.GaussianBlur(image, (kX, kY), 0)参数1:模糊对象,参数2:矩阵大小 参数3:标准方差 中位数模糊: 图像中去除盐和胡椒,图像中的杂质点 blurred = cv2.medianBlur(image, k)参数1:模糊对象,参数2:中位数值,为整型数据,数据越大图像越模糊 双边模糊: 减少噪音同时仍然保持边缘,我们可以使用双边模糊。双边模糊通过引入两个高斯分布来实现 blurred =cv2.bilateralFilter(image, diameter, sigmaColor, sigmaSpace)参数1:想要模糊的图像。参数2:像素邻域的直径 - 这个直径越大,模糊计算中包含的像素越多。参数3:颜色标准差,模糊时将考虑邻域中的更多颜色,相似颜色的像素才能显
着地影响模糊,参数4:空间标准偏差,更大的值意味着像素越远离中心像素直径 将影响模糊计算。后面3个参数都为整型参数 """
8、照明和色彩空间
#RGB 红、黄、蓝组成的颜色矩阵,每个色度值范围[0,255] image = cv2.imread(args["image"]) for (name, chan) in zip(("B", "G", "R"), cv2.split(image)): cv2.imshow(name, chan) #HSV 色调(H):们正在研究哪种“纯”的颜色。饱和度(S):颜色如何“白,例如纯红,随着零饱和度的颜色是纯白色。价值(V):该值允许我们控制我们的颜色的亮度,零值表示纯黑色 hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) for (name, chan) in zip(("H", "S", "V"), cv2.split(hsv)): cv2.imshow(name, chan) #L * a * b *表 L通道:像素的“亮度”。a通道:源于L通道的中心,在频谱的一端定义纯绿色,另一端定义纯红色。b通道: 也来自于L通道的中心,但是垂直于a通道。 lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB) for (name, chan) in zip(("L*", "a*", "b*"), cv2.split(lab)): cv2.imshow(name, chan) #灰度:转换成灰度级时,每个RGB通道 不是 均匀加权 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
9、阀值
阀值:图像的二值化
image = cv2.imread(args["image"]) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)#将图像二值化 blurred = cv2.GaussianBlur(gray, (7, 7), 0) (T,threshInv)=cv2.threshold(blurred,200,255,cv2.THRESH_BINARY_INV) #参数1:希望阈值的灰度图像。参数2:手动提供我们的T阈值。参数3:设置输出值。参数4:阈值方法(白色背景,黑色图),将像素值小于参数2的值换成参数3输出,大于参数2的值,输出值为0 cv2.imshow("Threshold Binary Inverse", threshInv) (T, thresh) =cv2.threshold(blurred,200,255,cv2.THRESH_BINARY)#参数1:希望阈值的灰度图像。参数2:手动提供我们的T阈值。参数3:设置输出值。参数4:阈值方法(黑背景,白色图),将像素值大于参数2的值换成参数3输出,小于参数2的值,输出值为0。 cv2.imshow("Threshold Binary", thresh) cv2.imshow("Output", cv2.bitwise_and(image, image, mask=threshInv)) #大津方法 参数1:希望阈值的灰度图像。参数2:大津的方法将自动计算出我们的T的最优值。参数3:阈值的输出值,只要给定像素通过阈值测试。参数4:对应于Otsu的阈值法 (T, threshInv) = cv2.threshold(blurred, 0, 255,cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU) #自适应阀值法:参数1:希望阈值的灰度图像。参数2:参数是输出阈值。参数3:自适应阈值法。参数4:阈值方法。参数5:是我们的像素邻域大小。参数6:微调 我们的阈值 thresh=cv2.adaptiveThreshold(blurred,255,cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 25, 15) thresh =threshold_adaptive(blurred,29,offset=5).astype("uint8")* 255 thresh = cv2.bitwise_not(thresh)#阈值适配函数执行自适应阈值
10. 图像处理
10.1、图像渐变
图像渐变:图像梯度主要应用与边缘检测
#Sobel内核 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) gX = cv2.Sobel(gray, ddepth=cv2.CV_64F, dx=1, dy=0) #计算x方向的梯度 gY = cv2.Sobel(gray, ddepth=cv2.CV_64F, dx=0, dy=1) #计算y方向的梯度 gX = cv2.convertScaleAbs(gX) #转换回8位无符号整型 gY = cv2.convertScaleAbs(gY) #转换回8位无符号整型 sobelCombined = cv2.addWeighted(gX, 0.5, gY, 0.5, 0) #将俩个图像组合成单个图像 gX = cv2.Sobel(gray, cv2.CV_64F, 1, 0) #计算x梯度方向 gY = cv2.Sobel(gray, cv2.CV_64F, 0, 1) #计算y梯度方向 mag = np.sqrt((gX ** 2) + (gY ** 2)) #梯度幅度计算:平方梯度的平方根 X和 ÿ 相加 orientation = np.arctan2(gY, gX) * (180 / np.pi) % 180 #梯度方向计算:两个梯度的反正切 idxs = np.where(orientation >= args["lower_angle"], orientation, -1)#手柄选择,参数1: 函数是我们要测试的条件,寻找大于最小提供角度的索引。参数2:要检查的阵列在哪里。参数3:特定值设置为-1。 idxs = np.where(orientation <= args["upper_angle"], idxs, -1) mask = np.zeros(gray.shape, dtype="uint8")#构造一个 掩码 - 所有具有相应idxs 值> -1的坐标 都设置为 255 (即前景)。否则,它们保留为 0(即背景) mask[idxs > -1] = 255
10.2、边缘检测
边缘类型:
步边:阶跃边缘形式当存在来自不连续到另一的一侧的像素强度的突然变化
斜坡边缘:斜坡边缘就像一个阶跃边缘,仅在像素强度的变化不是瞬时的。相反,像素值的变化发生短而有限的距离
岭边:脊边缘是相似于两个结合 斜坡边缘,一个右对另一碰撞
屋顶边:顶部有一个短而有限的高原的边缘不同
边缘检测法:
- 对图像应用高斯平滑来帮助减少噪点。
- 使用Sobel内核计算
 和
和 图像渐变。
图像渐变。 - 应用非最大值抑制来仅保持指向梯度方向的梯度幅度像素的局部最大值。
- 定义和应用
 和
和 阈值滞后阈值
阈值滞后阈值

gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) blurred = cv2.GaussianBlur(gray, (5, 5), 0) wide = cv2.Canny(blurred, 10, 200)#参数1:想要检测边缘的图像。参数2和3:分别提供阈值下限和阈值上限 #自动调整边缘检测参数 #自动调整边缘检测参数函数 def auto_canny(image, sigma=0.33): v = np.median(image) lower = int(max(0, (1.0 - sigma) * v)) upper = int(min(255, (1.0 + sigma) * v)) edged = cv2.Canny(image, lower, upper) return edged #自动调整边缘检测参数函数运用 blurred = cv2.GaussianBlur(gray, (3, 3), 0) auto = imutils.auto_canny(blurred)
11 图像轮廓处理
11.1 查找和绘制轮廓
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) (cnts, _) = cv2.findContours(gray.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)#参数1:需要绘制轮廓的图像。参数2:返回的轮廓数量的标志。参数3:轮廓压缩类型。返回值:第一个值是轮廓本上。第二个值是要检查的轮廓层次结构 clone = image.copy() cv2.drawContours(clone, cnts, -1, (0, 255, 0), 2)#参数1:要绘制轮廓的图像。参数2:使用的轮廓列表。参数3:cnts列表中的轮廓索引,-1表示绘制所有轮廓,0是仅画第一个,1表示绘制第二个轮廓。参数3:绘制轮廓的颜色。参数4:绘制轮廓线的像素 #轮廓单个绘制 for (i, c) in enumerate(cnts): print "Drawing contour #{}".format(i + 1) cv2.drawContours(clone, [c], -1, (0, 255, 0), 2) cv2.imshow("Single Contour", clone) cv2.waitKey(0) #返回所有轮廓外观: (cnts, _) = cv2.findContours(gray.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) #轮廓外观与掩码的一起使用 for c in cnts: # construct a mask by drawing only the current contour mask = np.zeros(gray.shape, dtype="uint8") cv2.drawContours(mask, [c], -1, 255, -1) # show the images cv2.imshow("Image", image) cv2.imshow("Mask", mask) cv2.imshow("Image + Mask", cv2.bitwise_and(image, image, mask=mask)) #补充:运用霍夫找圆心 gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #输出图像大小,方便根据图像大小调节minRadius和maxRadius print(img.shape) #霍夫变换圆检测 circles= cv2.HoughCircles(gray,cv2.HOUGH_GRADIENT,1,100,param1=100,param2=30,minRadius=5,maxRadius=300) #输出返回值,方便查看类型 print(circles) #输出检测到圆的个数 print(len(circles[0])) #根据检测到圆的信息,画出每一个圆 for circle in circles[0]: #圆的基本信息 print(circle[2]) #坐标行列 x=int(circle[0]) y=int(circle[1]) #半径 r=int(circle[2]) #在原图用指定颜色标记出圆的位置 img=cv2.circle(img,(x,y),r,(0,0,255),-1) #显示新图像 cv2.imshow('res',img)
11.2、简单的轮廓属性
质心:质心”或“质心” 是图像中物体的中心 (x,y)坐标
#绘制轮廓质心 (cnts, _) = cv2.findContours(gray.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) clone = image.copy() for c in cnts: # compute the moments of the contour which can be used to compute the # centroid or "center of mass" of the region M = cv2.moments(c) cX = int(M["m10"] / M["m00"]) cY = int(M["m01"] / M["m00"]) # draw the center of the contour on the image cv2.circle(clone, (cX, cY), 10, (0, 255, 0), -1)
面积和周长:轮廓的面积是轮廓轮廓内部的像素数。类似地, 周长 (有时称为 弧长)是轮廓的长度
#获取轮廓的面积与周长 for (i, c) in enumerate(cnts): area = cv2.contourArea(c) perimeter = cv2.arcLength(c, True) print "Contour #%d -- area: %.2f, perimeter: %.2f" % (i + 1, area, perimeter) cv2.drawContours(clone, [c], -1, (0, 255, 0), 2) #计算图像的质心,并在图像上显示轮廓数,以便我们可以将形状与终端输出相关联。 M = cv2.moments(c) cX = int(M["m10"] / M["m00"])#? cY = int(M["m01"] / M["m00"])#? cv2.putText(clone, "#%d" % (i + 1), (cX - 20, cY), cv2.FONT_HERSHEY_SIMPLEX, 1.25, (255, 255, 255), 4)
边框:边界”和“包含”整个图像的轮廓区域
for c in cnts: # fit a bounding box to the contour (x, y, w, h) = cv2.boundingRect(c) cv2.rectangle(clone, (x, y), (x + w, y + h), (0, 255, 0), 2)
旋转边框:
#绘制轮廓的旋转边框 for c in cnts: # fit a rotated bounding box to the contour and draw a rotated bounding box box = cv2.minAreaRect(c)#参数:我们的轮廓。并返回一个包含3个值的元组。元组的第一个值是旋转的边界框的起始 (x,y)坐标。第二个值是边界框的宽度和高度。而最终的值就是我们形状或旋转的角度 box = np.int0(cv2.cv.BoxPoints(box))#宽度和高度以及旋转角转换为一组坐标点 cv2.drawContours(clone, [box], -1, (0, 255, 0), 2)
最小封闭圆:
for c in cnts: ((x, y), radius) = cv2.minEnclosingCircle(c)#返回圆的中心的(x,y)坐标以及圆的 半径 cv2.circle(clone, (int(x), int(y)), int(radius), (0, 255, 0), 2)
装配椭圆:将椭圆拟合到轮廓上很像将轮廓的矩形装配到轮廓上
for c in cnts: if len(c) >= 5: ellipse = cv2.fitEllipse(c) cv2.ellipse(clone, ellipse, (0, 255, 0), 2)
11.3、高级轮廓
长宽比:宽高比=图像宽度/图像宽度
程度:边界框区域=边界框宽度X边框高度
凸海鸥:欧氏空间中的一组 X点,凸包是包含这些X点的最小可能凸集
密实度:坚固度=轮廓面积/凸包面积
#识别‘X’与‘O’ (cnts, _) = cv2.findContours(gray.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)#获取轮廓列表 for (i, c) in enumerate(cnts): area = cv2.contourArea(c)#获取轮廓面积 (x, y, w, h) = cv2.boundingRect(c)#获取轮廓的起始坐标,边界的宽度和高度 hull = cv2.convexHull(c) #获取形状的实际凸包 hullArea = cv2.contourArea(hull)#计算凸包面积 solidity = area / float(hullArea)#获取坚固度 char = "?" #依据坚固度,判断图像的形状 if solidity > 0.9: char = "O" elif solidity > 0.5: char = "X" #绘制轮廓 if char != "?": cv2.drawContours(image, [c], -1, (0, 255, 0), 3) cv2.putText(image, char, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.25, (0, 255, 0), 4) print "%s (Contour #%d) -- solidity=%.2f" % (char, i + 1, solidity) cv2.imshow("Output", image) cv2.waitKey(0)
#识别俄罗斯方块 (cnts, _) = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)#获取图片中的轮廓列表 hullImage = np.zeros(gray.shape[:2], dtype="uint8") for (i, c) in enumerate(cnts): area = cv2.contourArea(c)#获取轮廓面积 (x, y, w, h) = cv2.boundingRect(c)#获取轮廓边界 aspectRatio = w / float(h)#获取宽高比 extent = area / float(w * h)#获取当前轮廓的范围 hull = cv2.convexHull(c) hullArea = cv2.contourArea(hull)# solidity = area / float(hullArea)#获取坚固度,依据坚固度,判断物体形状 cv2.drawContours(hullImage, [hull], -1, 255, -1) cv2.drawContours(image, [c], -1, (240, 0, 159), 3) shape = ""
11.4、轮廓近似
轮廓逼近:一种用减少的点集合减少曲线中的点数的算法,简单的称为分裂合并算法
#检测图像中的正方形 import cv2 image = cv2.imread("images/circles_and_squares.png") gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #获得图像轮廓列表 (cnts, _) = cv2.findContours(gray.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) #循环每个轮廓 for c in cnts: #获取轮廓的周长 peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.01 * peri, True) if len(approx) == 4:#判断处理后的轮廓是否有4个顶点 # draw the outline of the contour and draw the text on the image cv2.drawContours(image, [c], -1, (0, 255, 255), 2) (x, y, w, h) = cv2.boundingRect(approx) cv2.putText(image, "Rectangle", (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 2) cv2.imshow("Image", image) cv2.waitKey(0)
物体轮廓检测:
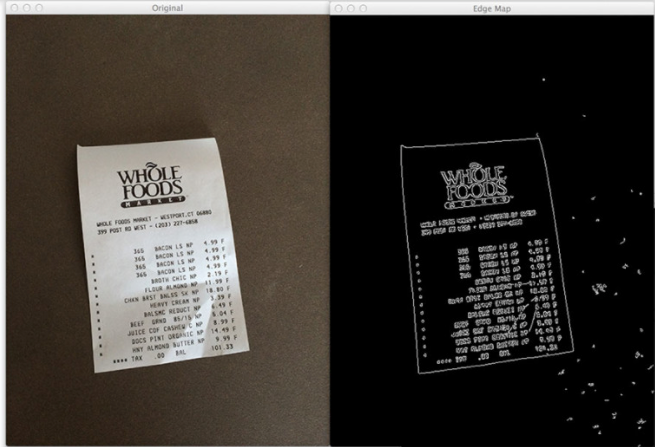
import cv2 image = cv2.imread("images/receipt.png") gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) edged = cv2.Canny(gray, 75, 200) cv2.imshow("Original", image) cv2.imshow("Edge Map", edged) (cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:7] # loop over the contours for c in cnts: peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.01 * peri, True) print "original: {}, approx: {}".format(len(c), len(approx)) if len(approx) == 4: cv2.drawContours(image, [approx], -1, (0, 255, 0), 2) cv2.imshow("Output", image) cv2.waitKey(0)

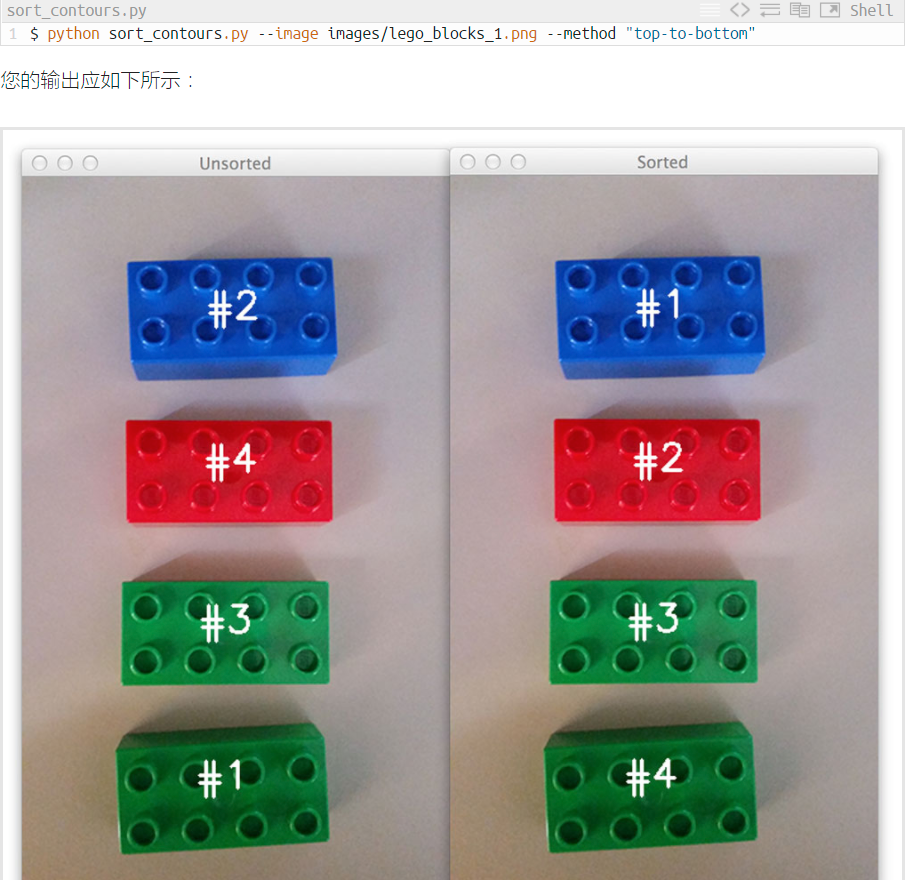
11.5、排列轮廓

import numpy as np import argparse import cv2 #参数1:轮廓列表 参数2:排列方法 def sort_contours(cnts, method="left-to-right"): reverse = False i = 0 if method == "right-to-left" or method == "bottom-to-top": reverse = True if method == "top-to-bottom" or method == "bottom-to-top": i = 1 boundingBoxes = [cv2.boundingRect(c) for c in cnts] (cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes), key=lambda b:b[1][i], reverse=reverse)) return (cnts, boundingBoxes) def draw_contour(image, c, i): M = cv2.moments(c) cX = int(M["m10"] / M["m00"]) cY = int(M["m01"] / M["m00"]) cv2.putText(image, "#{}".format(i + 1), (cX - 20, cY), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 255, 255), 2) return image ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="Path to the input image") ap.add_argument("-m", "--method", required=True, help="Sorting method") args = vars(ap.parse_args()) image = cv2.imread(args["image"]) accumEdged = np.zeros(image.shape[:2], dtype="uint8") for chan in cv2.split(image): chan = cv2.medianBlur(chan, 11) edged = cv2.Canny(chan, 50, 200) accumEdged = cv2.bitwise_or(accumEdged, edged) cv2.imshow("Edge Map", accumEdged) (cnts, _) = cv2.findContours(accumEdged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5] orig = image.copy() for (i, c) in enumerate(cnts): orig = draw_contour(orig, c, i) cv2.imshow("Unsorted", orig) (cnts, boundingBoxes) = sort_contours(cnts, method=args["method"]) for (i, c) in enumerate(cnts): draw_contour(image, c, i) cv2.imshow("Sorted", image) cv2.waitKey(0)



12、直方图
直方图:表示图像中的像素强度
运用cv2.calcHist函数构建直方图
cv2.calcHist(图像,通道,掩码,histSize,范围)
参数详解:
图像:我们要计算的直方图的图像
通道:索引列表,其中指定要计算直方图的通道的索引。
掩码:提供一个掩码,那么只对被掩盖的像素计算一个直方图
histSize:计算直方图时要使用的分组数
范围:可能的像素值的范围
#灰度直方图 from matplotlib import pyplot as plt import argparse import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="Path to the image") args = vars(ap.parse_args()) image = cv2.imread(args["image"]) image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) cv2.imshow("Original", image) hist = cv2.calcHist([image], [0], None, [256], [0, 256]) plt.figure() plt.title("Grayscale Histogram") plt.xlabel("Bins") plt.ylabel("# of Pixels") plt.plot(hist) plt.xlim([0, 256]) hist /= hist.sum() plt.figure() plt.title("Grayscale Histogram (Normalized)") plt.xlabel("Bins") plt.ylabel("% of Pixels") plt.plot(hist) plt.xlim([0, 256]) plt.show()
#颜色直方图 from matplotlib import pyplot as plt import argparse import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="Path to the image") args = vars(ap.parse_args()) image = cv2.imread(args["image"]) cv2.imshow("Original", image) chans = cv2.split(image) colors = ("b", "g", "r") plt.figure() plt.title("'Flattened' Color Histogram") plt.xlabel("Bins") plt.ylabel("# of Pixels") for (chan, color) in zip(chans, colors): hist = cv2.calcHist([chan], [0], None, [256], [0, 256]) plt.plot(hist, color = color) plt.xlim([0, 256]) fig = plt.figure() ax = fig.add_subplot(131) hist = cv2.calcHist([chans[1], chans[0]], [0, 1], None, [32, 32], [0, 256, 0, 256]) p = ax.imshow(hist, interpolation="nearest") ax.set_title("2D Color Histogram for G and B") plt.colorbar(p) ax = fig.add_subplot(132) hist = cv2.calcHist([chans[1], chans[2]], [0, 1], None, [32, 32], [0, 256, 0, 256]) p = ax.imshow(hist, interpolation="nearest") ax.set_title("2D Color Histogram for G and R") plt.colorbar(p) ax = fig.add_subplot(133) hist = cv2.calcHist([chans[0], chans[2]], [0, 1], None, [32, 32], [0, 256, 0, 256]) p = ax.imshow(hist, interpolation="nearest") ax.set_title("2D Color Histogram for B and R") plt.colorbar(p) print "2D histogram shape: %s, with %d values" % ( hist.shape, hist.flatten().shape[0]) hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256]) print "3D histogram shape: %s, with %d values" % ( hist.shape, hist.flatten().shape[0]) plt.show()
#直方图均衡 import argparse import cv2 # construct the argument parser and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="Path to the image") args = vars(ap.parse_args()) # load the image and convert it to grayscale image = cv2.imread(args["image"]) image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # apply histogram equalization to stretch the constrast of our image eq = cv2.equalizeHist(image) # show our images -- notice how the constrast of the second image has # been stretched cv2.imshow("Original", image) cv2.imshow("Histogram Equalization", eq) cv2.waitKey(0)
#直方图和面具 from matplotlib import pyplot as plt import numpy as np import cv2 def plot_histogram(image, title, mask=None): chans = cv2.split(image) colors = ("b", "g", "r") plt.figure() plt.title(title) plt.xlabel("Bins") plt.ylabel("# of Pixels") for (chan, color) in zip(chans, colors): hist = cv2.calcHist([chan], [0], mask, [256], [0, 256]) plt.plot(hist, color=color) plt.xlim([0, 256]) image = cv2.imread("beach.png") cv2.imshow("Original", image) plot_histogram(image, "Histogram for Original Image") mask = np.zeros(image.shape[:2], dtype="uint8") cv2.rectangle(mask, (60, 290), (210, 390), 255, -1) cv2.imshow("Mask", mask) masked = cv2.bitwise_and(image, image, mask=mask) cv2.imshow("Applying the Mask", masked) plot_histogram(image, "Histogram for Masked Image", mask=mask) plt.show()
13、连接分量标签
略
1、什么是基于内容的图像检索
1、构建基于内容的图像检索系统步骤
(1)定义你的图像描述符:在这个阶段你需要决定你想描述的图像的哪个方面。你对图像的颜色感兴趣吗?图像中物体的形状?或者你想表征纹理?
(2)特征提取和索引您的数据集: 现在您已经定义了图像描述符,您的工作是将此图像描述符应用于数据集中的每个图像,从这些图像提取特征并将特征写入存储(例如,CSV文件,RDBMS ,Redis等),以便稍后可以比较它们的相似性。此外,您需要考虑是否将使用任何专门的数据结构来促进更快的搜索。
(3)定义您的相似性度量: 我们现在有一个(可能是指数)特征向量的集合。但你如何比较它们的相似性呢?常用选项包括欧几里得距离,余弦距离和 距离,但实际选择高度依赖于(1)数据集和(2)您提取的特征类型。
距离,但实际选择高度依赖于(1)数据集和(2)您提取的特征类型。
(4)搜索: 最后一步是执行实际搜索。用户将向系统提交查询图像(例如从上传表单或通过移动应用程序),并且您的工作将(1)从该查询图像中提取特征,然后(2)应用您的相似性函数进行比较该查询的功能已针对已编入索引的功能。从那里,你只需根据你的相似度函数返回最相关的结果。
2、CBIR和机器学习/图像分类有何不同
(1)机器学习包括使计算机完成诸如预测,分类,识别等智能人工任务的方法。此外,机器学习管理算法,使计算机能够执行这些智能任务 而不需要明确编程。
CBIR确实利用了一些机器学习技术 - 即降维和聚类,但是CBIR系统不执行任何实际学习。
(2)主要的 区别在于CBIR不 直接试图理解和解释图像的内容。相反,CBIR系统依赖于:
- 通过提取特征向量来量化图像。
- 假设特征向量的比较 - 具有相似特征向量的图像具有相似的视觉内容。
基于这两个组件,图像搜索引擎能够将查询与图像数据集进行比较,并返回最相关的结果,而不必实际“知道”图像的内容。
(3)在机器学习和图像分类中,能够学习和理解图像的内容需要一些训练集的概念 - 一组标记数据用于教计算机数据集中每个可视对象的外观。
(4)CBIR系统不需要标记数据。他们只需拍摄图像数据集,从每幅图像中提取特征,并使数据集可以在视觉上搜索。在某些方面,您可以将CBIR系统视为一种“哑”图像分类器,它没有标签概念来使自己更加智能 - 它仅依赖于(1)从图像中提取的特征和(2)相似性函数用于给用户提供有意义的结果。
2、构建CBIR系统
1、目录结构及作用
|--- pyimagesearch
from __future__ import print_function
from pyimagesearch.cbir.resultsmontage import ResultsMontage
from pyimagesearch.cbir.hsvdescriptor import HSVDescriptor
from pyimagesearch.cbir.searcher import Searcher
import argparse
import imutils
import json
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--index", required = True, help = "Path to where the features index will be stored")
ap.add_argument("-q", "--query", required = True, help = "Path to the query image")
ap.add_argument("-d", "--dataset", required = True, help = "Path to the original dataset directory")
ap.add_argument("-r", "--relevant", required = True, help = "Path to relevant dictionary")
args = vars(ap.parse_args())
desc = HSVDescriptor((4, 6, 3))
montage = ResultsMontage((240, 320), 5, 20)
relevant = json.loads(open(args["relevant"]).read())
queryFilename = args["query"][args["query"].rfind("/") + 1:]
queryRelevant = relevant[queryFilename]
query = cv2.imread(args["query"])
print("[INFO] describing query...")
cv2.imshow("Query", imutils.resize(query, width = 320))
features = desc.describe(query)
print("[INFO] searching...")
searcher = Searcher(args["index"])
results = searcher.search(features, numResults = 20)
for (i, (score, resultID)) in enumerate(results):
print("[INFO] {result_num}.{result} - score:.2f".format(result_num = i + 1, result = resultID, score = score))
result = cv2.imread("{}/{}".format(args["dataset"], resultID))
print ("resultID")
print (resultID)
montage.addResult(result, text = "#{}".format(i + 1), highlight = resultID in queryRelevant)
cv2.imshow("Results", imutils.resize(montage.montage, height = 700))
cv2.imwrite("mo.png",montage.montage)
cv2.waitKey(0)
index.py
from __future__ import print_function
from pyimagesearch.cbir.hsvdescriptor import HSVDescriptor
from imutils import paths
import progressbar
import argparse
import cv2
ap= argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True, help = "Path to the directory that contains the images to be indexed")
ap.add_argument("-i", "--index", required = True, help = "Path to where the features index will be stored")
args = vars(ap.parse_args())
desc = HSVDescriptor((4, 6, 3))
output = open(args["index"], "w")
imagePaths = list(paths.list_images(args["dataset"]))
widgets = ["Indexing:", progressbar.Percentage(), "", progressbar.Bar(), "", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval = len(imagePaths), widgets = widgets)
pbar.start()
for (i, imagePath) in enumerate(imagePaths):
filename = imagePath[imagePath.rfind("/") + 1:]
image = cv2.imread(imagePath)
features = desc.describe(image)
features = [str(x) for x in features]
output.write("{}, {}\n".format(filename, ",".join(features)))
pbar.update(i)
pbar.finish()
print("[INFO] indexed {} images".format(len(imagePaths)))
output.close()
dist.py
import numpy as np
def chi2_distance(histA, histB, eps = 1e-10):
d = 0.5 * np.sum(((histA - histB)**2)/(histA + histB + eps))
return d
hsvdescriptor.py
import numpy as np
import cv2
import imutils
class HSVDescriptor:
def __init__(self, bins):
self.bins = bins
def describe(self, image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
features = []
(h, w) = image.shape[:2]
(cX, cY) = (int(w * 0.5), int(h * 0.5))
segments = [(0, cX, 0, cY), (cX, w, 0, cY), (cX, w, cY, h), (0, cX, cY, h)]
(axesX, axesY) = (int(w * 0.75)//2, int(h * 0.75)//2)
ellipMask = np.zeros(image.shape[:2], dtype = "uint8")
cv2.ellipse(ellipMask, (cX, cY), (axesX, axesY), 0, 0, 360, 255, - 1)
for (startX, endX, startY, endY) in segments:
cornerMask = np.zeros(image.shape[:2], dtype = "uint8")
cv2.rectangle(cornerMask, (startX, startY), (endX, endY), 255, - 1)
cornerMask = cv2.subtract(cornerMask, ellipMask)
hist = self.histogram(image, cornerMask)
features.extend(hist)
hist = self.histogram(image, ellipMask)
features.extend(hist)
return np.array(features)
def histogram(self, image, mask = None):
hist = cv2.calcHist([image], [0, 1, 2], mask, self.bins, [ 0 , 180, 0, 256, 0, 256])
if imutils.is_cv2():
hist = cv2.normalize(hist).flatten()
else:
hist = cv2.normalize(hist, hist).flatten()
return hist
resultsmontage.py
import numpy as np
import cv2
class ResultsMontage:
def __init__(self, imageSize, imagesPerRow, numResults):
self.imageW = imageSize[0]
self.imageH = imageSize[1]
self.imagesPerRow = imagesPerRow
numCols = numResults // imagesPerRow
self.montage = np.zeros((numCols * self.imageW, imagesPerRow * self.imageH, 3), dtype="uint8")
self.counter = 0
self.row = 0
self.col = 0
def addResult(self, image, text = None, highlight = False):
if self.counter != 0 and self.counter %self.imagesPerRow == 0:
self.col = 0
self.row += 1
image = cv2.resize(image, (self.imageH, self.imageW))
(startY, endY) = (self.row * self.imageW, (self.row + 1) * self.imageW)
(startX, endX) = (self.col * self.imageH, (self.col + 1) * self.imageH)
self.montage[startY:endY, startX:endX] = image
if text is not None:
cv2.putText(self.montage, text, (startX + 10, startY + 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 255), 3)
print ("text")
if highlight:
cv2.rectangle(self.montage, (startX + 3, startY + 3), (endX - 3, endY - 3), (0, 255, 0), 4)
print ("hig")
self.col += 1
self.counter +=1
searcher.py
from . import dists
import csv
class Searcher:
def __init__(self, dbPath):
self.dbPath = dbPath
def search(self, queryFeatures, numResults = 10):
results = {}
with open(self.dbPath) as f:
reader = csv.reader(f)
for row in reader:
features = [float(x) for x in row[1:]]
d = dists.chi2_distance(features, queryFeatures)
results[row[0]] = d
f.close()
results=sorted([(v,k) for (k,v) in results.items()])
return results[:numResults]
2、特征提取和索引
1、描述图像的三个方面:
- 颜色: 表征图像颜色的图像描述符试图模拟图像每个通道中像素强度的分布。这些方法包括基本颜色统计,如平均值,标准偏差和偏度,以及颜色直方图,“平面”和多维。
- 纹理: 纹理描述符试图模拟图像中物体的感觉,外观和整体触觉质量。一些(但不是全部)纹理描述符将图像转换为灰度,然后计算灰度共生矩阵(GLCM)并计算该矩阵的统计量,包括对比度,相关性和熵等(Haralick纹理)。更先进的纹理描述符,如局部二进制模式,尝试模型 模式也是如此。甚至还有更高级的纹理描述符,例如傅立叶和小波变换也存在,但仍然使用灰度图像。
- 形状: 绝大多数形状描述符方法依靠提取图像中对象的轮廓(即轮廓)。一旦我们有了轮廓,我们就可以计算简单的统计数据来表征轮廓,这正是Hu Moments和Zernike Moments所做的。这些统计数据可用于表示图像中对象的形状(轮廓)。在机器学习和对象识别的背景下, 面向梯度的直方图 也是一个不错的选择。
2、特征提取的定义
定义: 特征提取 是通过应用图像描述符从数据集中每个图像中提取特征来量化数据集的过程。通常,这些功能存储在磁盘上供 以后使用,并 使用专门的数据结构(例如倒排索引,kd树或随机投影林)进行索引,以加快查询速度。
3、定义相似度
1、常用距离度量
欧几里德:
from scipy.spatial import distance as dists
dists.euclidean(A, B)
曼哈顿/城市大厦
dists.cityblock(A, B)
直方图交点
def histogram_intersection(H1, H2):
return np.sum(np.minimum(H1, H2))
距离
def chi2_distance(histA, histB, eps=1e-10):
return 0.5 * np.sum(((histA - histB) ** 2) / (histA + histB + eps))
chi2_distance(A, B)
余弦
dists.cosine(A, B)
海明
dists.hamming(A, B)
4、提取关键点和局部不变描述符
1、文件结构及作用:
|--- pyimagesearch
#coding=utf-8
from __future__ import print_function
from pyimagesearch.descriptors.detectanddescribe import DetectAndDescribe
from pyimagesearch.indexer.featureindexer import FeatureIndexer
from imutils.feature import FeatureDetector_create, DescriptorExtractor_create
from imutils import paths
import argparse
import imutils
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="Path to the directory that contains the images to be indexed") #图像目录路径
ap.add_argument("-f", "--features-db", required=True,
help="Path to where the features database will be stored")#制定HDF5数据库储存在磁盘上的路径
ap.add_argument("-a", "--approx-images", type=int, default=500,
help="Approximate # of images in the dataset")#该(可选)开关允许我们指定数据集中图像的近似数量
ap.add_argument("-b", "--max-buffer-size", type=int, default=50000,
help="Maximum buffer size for # of features to be stored in memory")#一次一个地写入HDF5的特征向量 效率非常低。相反,将特征向量收集到内存中的一个大数组中然后在缓冲区满时将它们转储到HDF5会更有效。的值 -最大-缓冲器-大小 指定许多如何 特征向量可以被存储在存储器中,直到缓冲器被刷新到HDF5
args = vars(ap.parse_args())
detector = FeatureDetector_create("SURF")#获取关键点
descriptor = DescriptorExtractor_create("RootSIFT")#定义提取关键点特征方法
dad = DetectAndDescribe(detector, descriptor)#获取关键点和关键点特征向量
fi = FeatureIndexer(args["features_db"], estNumImages=args["approx_images"],maxBufferSize=args["max_buffer_size"], verbose=True)
for (i, imagePath) in enumerate(paths.list_images(args["dataset"])):
if i > 0 and i%10 == 0:
fi._debug("processed {} images".format(i), msgType = "[PROGRESS]")
filename = imagePath[imagePath.rfind("/") + 1:]
image = cv2.imread(imagePath)
image = imutils.resize(image, width = 320)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
(kps, descs) = dad.describe(image)
if kps is None or descs is None:
continue
fi.add(filename, kps, descs)
fi.finish()
detectanddescribe.py
import numpy as np
class DetectAndDescribe:
def __init__(self, detector, descriptor):
self.detector = detector
self.descriptor = descriptor
def describe(self, image, useKpList = True):
kps = self.detector.detect(image)
(kps, descs) = self.descriptor.compute(image, kps)
if len(kps) == 0:
return (None, None)
if useKpList:
kps = np.int0([kp.pt for kp in kps])
return (kps, descs)
baseindexer.py
from __future__ import print_function
import numpy as np
import datetime
class BaseIndexer(object):
def __init__(self, dbPath, estNumImages = 500, maxBufferSize = 50000, dbResizeFactor = 2, verbose = True):
self.dbPath = dbPath
self.estNumImages = estNumImages
self.maxBufferSize = maxBufferSize
self.dbResizeFactor = dbResizeFactor
self.verbose = verbose
self.idxs = {}
def _wrieBuffers(self):
pass
def _writeBuffer(self, dataset, datasetName, buf, idxName, sparse = False):
if type(buf) is list:
end = self.idxs[idxName] + len(buf)
else:
end = self.idxs[idxName] + buf.shape[0]
if end > dataset.shape[0]:
self._debug("triggering '{}' db resize".format(datasetName))
self._resizeDataset(dataset, datasetName, baseSize = end)
if sparse:
buf = buf.toarray()
self._debug("writing '{}' buffer".format(datasetName))
dataset[self.idxs[idxName]:end] = buf
def _resizeDataset(self, dataset, dbName, baseSize = 0, finished = 0):
origSize = dataset.shape[0]
if finished > 0:
newSize = finished
else:
newSize = baseSize * self.dbResizeFactor
shape = list(dataset.shape)
shape[0] = newSize
dataset.resize(tuple(shape))
self._debug("old size of '{}':{:,};new size:{:,}".format(dbName, origSize, newSize))
def _debug(self, msg, msgType = "[INFO]"):
if self.verbose:
print("{} {} - {}".format(msgType, msg, datetime.datetime.now()))
@staticmethod
def featureStack(array, accum = None, stackMethod = np.vstack):
if accum is None:
accum = array
else:
accum = stackMethod([accum, array])
return accum
featureindexer.py
#coding=utf-8
from .baseindexer import BaseIndexer
import numpy as np
import h5py
import sys
class FeatureIndexer(BaseIndexer):
def __init__(self, dbPath, estNumImages=500, maxBufferSize=50000, dbResizeFactor=2,verbose=True):
super(FeatureIndexer, self).__init__(dbPath, estNumImages=estNumImages,
maxBufferSize=maxBufferSize, dbResizeFactor=dbResizeFactor,
verbose=verbose)
self.db = h5py.File(self.dbPath, mode="w")
self.imageIDDB = None
self.indexDB = None
self.featuresDB = None
self.imageIDBuffer = []
self.indexBuffer = []
self.featuresBuffer = None
self.totalFeatures = 0
self.idxs = {"index": 0, "features": 0}
def add(self, imageID, kps, features):
start = self.idxs["features"] + self.totalFeatures
end = start + len(features)
self.imageIDBuffer.append(imageID)
self.featuresBuffer = BaseIndexer.featureStack(np.hstack([kps, features]),self.featuresBuffer)
self.indexBuffer.append((start, end))
self.totalFeatures += len(features)
if self.totalFeatures >= self.maxBufferSize:
if None in (self.imageIDDB, self.indexDB, self.featuresDB):
self._debug("initial buffer full")
self._createDatasets()
self._writeBuffers()
def _createDatasets(self):
avgFeatures = self.totalFeatures/float(len(self.imageIDBuffer))
approxFeatures = int(avgFeatures * self.estNumImages)
fvectorSize = self.featuresBuffer.shape[1]
if sys.version_info[0] < 3:
dt = h5py.special_dtype(vlen = unicode)
else:
dt = h5py.special_dtype(vlen = str)
self._debug("creating datasets...")
self.imageIDDB = self.db.create_dataset("image_ids", (self.estNumImages, ), maxshape = (None, ), dtype = dt)
self.indexDB = self.db.create_dataset("index", (self.estNumImages, 2), maxshape = (None, 2), dtype = "int")
self.featuresDB = self.db.create_dataset("features", (approxFeatures, fvectorSize), maxshape = (None, fvectorSize), dtype = "float")
def _writeBuffers(self):
self._writeBuffer(self.imageIDDB, "image_ids", self.imageIDBuffer,"index")
self._writeBuffer(self.indexDB, "index", self.indexBuffer, "index")
self._writeBuffer(self.featuresDB, "features", self.featuresBuffer,"features")
self.idxs["index"] += len(self.imageIDBuffer)
self.idxs["features"] += self.totalFeatures
self.imageIDBuffer = []
self.indexBuffer = []
self.featuresBuffer = None
self.totalFeatures = 0
def finish(self):
if None in (self.imageIDDB, self.indexDB, self.featuresDB):
self._debug("minimum init buffer not reached", msgType = "[WARN]")
self._createDatasets()
self._debug("writing un - empty buffers...")
self._writeBuffers()
self._debug("compacting datasets...")
self._resizeDataset(self.imageIDDB, "image_ids", finished = self.idxs["index"])
self._resizeDataset(self.indexDB, "index", finished = self.idxs["index"])
self._resizeDataset(self.featuresDB, "features", finished = self.idxs["features"])
self.db.close()
5、集群功能组成一个码本
1、文件结构及作用
多添加俩个新文件:cluster_features.py和vocabulary.py
|--- pyimagesearch
#coding=utf-8
from __future__ import print_function
from pyimagesearch.ir.vocabulary import Vocabulary
import argparse
import pickle
ap= argparse.ArgumentParser()
ap.add_argument("-f", "--features-db", required = True, help = "Path to where the features database will be stored")
ap.add_argument("-c", "--codebook", required = True, help = "Path to the output codebook")
ap.add_argument("-k", "--clusters", type = int, default = 64, help = "# of clusters to generate")#小批量k-均值将生成的簇的数量(即可视词)
ap.add_argument("-p", "--percentage",type = float, default = 0.25, help = "Percentage of total features to use when clustering" )
args = vars(ap.parse_args()) # 控制特征向量样本量的大小
voc = Vocabulary(args["features_db"])
vocab = voc.fit(args["clusters"], args["percentage"]) #获得生成的视觉词 - 整个采样和聚类过程由词汇 类抽象
print ("[INFO] storing cluster centers...")
f = open(args["codebook"], "wb")
f.write(pickle.dumps(vocab))
f.close()
vocabulary.py
from __future__ import print_function
from sklearn.cluster import MiniBatchKMeans
import numpy as np
import datetime
import h5py
class Vocabulary:
def __init__(self, dbPath, verbose = True):
self.dbPath = dbPath
self.verbose = verbose
def fit(self, numClusters, samplePercent, randomState = None):
db = h5py.File(self.dbPath)
totalFeatures = db["features"].shape[0]
sampleSize = int(np.ceil(samplePercent * totalFeatures))
print("sampleSize")
print (sampleSize)
idxs = np.random.choice(np.arange(0, totalFeatures), (sampleSize), replace = False)
idxs.sort()
data = []
self._debug("starting sampling...")
for i in idxs:
data.append(db["features"][i][2:])
self._debug("sampled {:,} features from a population of {:,}".format(len(idxs), totalFeatures))
self._debug("clustering with k = {:,}".format(numClusters))
clt = MiniBatchKMeans(n_clusters = numClusters, random_state = randomState)
clt.fit(data)
self._debug("cluster shape:{}".format(clt.cluster_centers_.shape))
db.close()
return clt.cluster_centers_
def _debug(self, msg, msgType = "[INFO]"):
if self.verbose:
print("{} {} - {}".format(msgType, msg, datetime.datetime.now()))
6、可视化码本中的单词
注:在前面构建出关键点和局部不变特征描述符、建立集群码本后方可实现
作用:将码本中K-means分类后的直方图,转化为可视化图片
visuluze_centers.py
#coding=utf-8
from __future__ import print_function
from pyimagesearch.resultsmontage import ResultsMontage
from sklearn.metrics import pairwise
import numpy as np
import progressbar
import argparse
import pickle
import h5py
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True, help = "Path to the directory of indexed images")
ap.add_argument("-f", "--features-db", required = True, help = "Path to the features database")#提取关键和局部不变描述符的数据记路经
ap.add_argument("-c", "--codebook", required = True, help = "Path to the codebook")#可视话词汇表中的视觉词汇路经
ap.add_argument("-o", "--output", required = True, help = "Path to output directory")
args = vars(ap.parse_args())
vocab = pickle.loads(open(args["codebook"], "rb").read())
featuresDB = h5py.File(args["features_db"], mode = "r")
print("[INFO] starting distance distance computations...")
vis = {i:[] for i in np.arange(0, len(vocab))}
widgets = ["Comparing:", progressbar.Percentage(), "", progressbar.Bar(), "", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval = featuresDB["image_ids"].shape[0], widgets = widgets).start()
for (i, imageID) in enumerate(featuresDB["image_ids"]):
(start, end) = featuresDB["index"][i]
rows = featuresDB["features"][start:end]
(kps, descs) = (rows[:, :2], rows[:, 2:])
for (kp, features) in zip(kps, descs):
features = features.reshape(1, - 1)
D = pairwise.euclidean_distances(features, Y = vocab)[0]
for j in np.arange(0, len(vocab)):
topResults = vis.get(j)
topResults.append((D[j], kp, imageID))
topResults = sorted(topResults, key = lambda r:r[0])[:16]
vis[j] = topResults
pbar.update(i)
pbar.finish()
featuresDB.close()
print("[INFO] writing visualizations to file...")
for (vwID, results) in vis.items():
montage = ResultsMontage((64, 64), 4, 16)
for (_, (x, y), imageID) in results:
p = "{}/{}".format(args["dataset"], imageID)
image = cv2.imread(p)
(h, w) = image.shape[:2]
(startX, endX) = (max(0, int(x) - 32), min(w, int(x) + 32))
(startY, endY) = (max(0, int(y) - 32), min(h, int(y) + 32))
roi = image[startY:endY, startX, endX]
montage.addResult(roi)
p = "{}/vis_{}.jpg".format(args["output"], vwID)
cv2.imwrite(p, cv2.cvtColor(montage.montage, cv2.COLOR_BGR2GRAY))
7、矢量量化
7.1、从多个特征到单个直方图
bagofvisualwords.py
from sklearn.metrics import pairwise
from scipy.sparse import csr_matrix
import numpy as np
class BagOfVisualWords:
def __init__(self, codebook, sparse = True):
self.codebook = codebook
self.sparse = sparse
def describe(self, features):
D = pairwise.euclidean_distances(features, Y = self.codebook)
(words, counts) = np.unique(np.argmin(D, axis = 1), return_counts = True)
if self.sparse:
hist = csr_matrix((counts, (np.zeros((len(words), )), words)), shape = (1, len(self.codebook)), dtype = "float")
else:
hist = np.zeros((len(self.codebook), ), dtype = "float")
hist[words] = counts
return hist
quantize_example.py
from __future__ import print_function
from pyimagesearch.ir.bagofvisualwords import BagOfVisualWords
from sklearn.metrics import pairwise
import numpy as np
np.random.seed(42)
vocab = np.random.uniform(size = (3, 6))
features = np.random.uniform(size = (10, 6))
print("[INFO] vocabulary:\n{}\n".format(vocab))
print("[INFO] features:\n{}\n".format(features))
hist = np.zeros((3,), dtype = "int32")
for (i, f) in enumerate(features):
D = pairwise.euclidean_distances(f.reshape(1, -1), Y = vocab)
j = np.argmin(D)
print("[INFO] Closest visual word to feature #{}:{}".format(i, j))
hist[j] += 1
print("[INFO] Updated histogram:{}".format(hist))
bovw = BagOfVisualWords(vocab, sparse = False)
hist = bovw.describe(features)
print("[INFO] BOVW histogram:{}".format(hist))
7.2、形成BOVW
运行命令:python extract_bovw.py --features-db output/features.hdf5 --codebook output/vocab.cpickle --bovw-db output/bovw.hdf5 --idf output/idf.cpickle
extract_bovw.py
from pyimagesearch.ir.bagofvisualwords import BagOfVisualWords
from pyimagesearch.indexer.bovwindexer import BOVWIndexer
import argparse
import pickle
import h5py
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--features-db", required = True, help = "Path to the features database") #关键点和局部不变描述符课程中构建的HDF5数据集的路径。该数据库应包含与数据集中每个图像相关的图像ID,索引和原始关键点/特征向量
ap.add_argument("-c", "--codebook", required = True, help = "Path to the codebook")#我们需要可视化码本的路径
ap.add_argument("-b", "--bovw-db", required = True, help = "Path to where the bag-of-visual-words database will be stored")#将BOVW表示存储在一个单独的HDF5数据库中的路经
ap.add_argument("-d", "--idf", required = True, help = "Path to inverse document frequency counts will be stored")
ap.add_argument("-s", "--max-buffer-size", type = int, default = 500, help = "Maximum buffer size for # of features to be stored in memory")#在写入HDF5数据集之前在内存中管理一个原始特征向量的缓冲区,我们将在这里做同样的事情 - 这次我们将管理一个BOVW直方图缓冲区
args = vars(ap.parse_args())
vocab = pickle.loads(open(args["codebook"], "rb").read())
bovw = BagOfVisualWords(vocab)
featuresDB = h5py.File(args["features_db"], mode = "r")
bi = BOVWIndexer(bovw.codebook.shape[0], args["bovw_db"], estNumImages = featuresDB["image_ids"].shape[0], maxBufferSize = args["max_buffer_size"])
for (i, (imageID, offset)) in enumerate(zip(featuresDB["image_ids"], featuresDB["index"])):
if i > 0 and i%10 == 0:
bi._debug("processed {} images".format(i), msgType = "[PROGRESS]")
features = featuresDB["features"][offset[0]:offset[1]][:, 2:]
hist = bovw.describe(features)
bi.add(hist)
featuresDB.close()
bi.finish()
f = open(args["idf"], "wb")
f.write(pickle.dumps(bi.df(method = "idf")))
f.close()
bovwindexer.py
from .baseindexer import BaseIndexer
from scipy import sparse
import numpy as np
import h5py
class BOVWIndexer(BaseIndexer):
def __init__(self, fvectorSize, dbPath, estNumImages = 500, maxBufferSize = 500, dbResizeFactor = 2, verbose = True):
super(BOVWIndexer, self).__init__(dbPath, estNumImages = estNumImages, maxBufferSize = maxBufferSize, dbResizeFactor = dbResizeFactor, verbose = verbose)
self.db = h5py.File(self.dbPath, mode = "w")
self.bovwDB = None
self.bovwBuffer = None
self.idxs = {"bovw":0}
self.fvectorSize = fvectorSize
self._df = np.zeros((fvectorSize, ), dtype = "float")
self.totalImages = 0
def add(self, hist):
self.bovwBuffer = BaseIndexer.featureStack(hist, self.bovwBuffer, stackMethod = sparse.vstack)
self._df[np.where(hist.toarray()[0] > 0)] += 1
if self.bovwBuffer.shape[0] >= self.maxBufferSize:
if self.bovwDB is None:
self._debug("initial buffer full")
self._createDatasets()
self._writeBuffers()
def _writeBuffers(self):
if self.bovwBuffer is not None and self.bovwBuffer.shape[0] > 0:
self._writeBuffer(self.bovwDB, "bovw", self.bovwBuffer, "bovw", sparse = True)
self.idxs["bovw"] += self.bovwBuffer.shape[0]
self.bovwBuffer = None
def _createDatasets(self):
self._debug("creating datasets...")
self.bovwDB = self.db.create_dataset("bovw", (self.estNumImages, self.fvectorSize), maxshape = (None, self.fvectorSize), dtype = "float")
def finish(self):
if self.bovwDB is None:
self._debug("minimum init buffer not reached", msgType = "[WARN]")
self._createDatasets()
self._debug("writing un-empty buffers...")
self._writeBuffers()
self._debug("compacting datasets...")
self._resizeDataset(self.bovwDB, "bovw", finished = self.idxs["bovw"])
self.totalImage = self.bovwDB.shape[0]
self.db.close()
def df(self, method = None):
if method == "idf":
return np.log(self.totalImages/(1.0 + self._df))
return sel._df
8、反转索引和搜索
8.1、建立倒排索引
1、文件结构
|--- pyimagesearch
import numpy as np
class RedisQueue:
def __init__(self, redisDB):
self.redisDB = redisDB
def add(self, imageIdx, hist):#imageIdx:image_ids中HDF5数据集中图像的索引。hist:从图像中提取的BOVW直方图
p = self.redisDB.pipeline()
for i in np.where(hist > 0)[0]:
p.rpush("vw:{}".format(i), imageIdx)
p.execute()
def finish(self):
self.redisDB.save()
build_redis_index.py
from __future__ import print_function
from pyimagesearch.db.redisqueue import RedisQueue
from redis import Redis
import h5py
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-b", "--bovw-db", required = True, help = "Path to where the bag-of-visual-words database")
args = vars(ap.parse_args())
redisDB = Redis(host = "localhost", port = 6379, db = 0)
rq = RedisQueue(redisDB)
bovwDB = h5py.File(args["bovw_db"], mode = "r")
for (i, hist) in enumerate(bovwDB["bovw"]):
if i > 0 and i%10 == 0:
print("[PROGRESS] processed {} entries".format(i))
rq.add(i, hist)
bovwDB.close()
rq.finish()
8.2 执行搜索
文件目录结构:
|--- pyimagesearch
运行命令:python search.py --dataset ../ukbench --features-db output/features.hdf5 --bovw-db output/bovw.hdf5 --codebook output/vocab.cpickle --relevant ../ukbench/relevant.json --query ../ukbench/ukbench00258.jpg
from __future__ import print_function
from pyimagesearch.descriptors.detectanddescribe import DetectAndDescribe
from pyimagesearch.ir.bagofvisualwords import BagOfVisualWords
from pyimagesearch.ir.searcher import Searcher
from pyimagesearch.ir.dists import chi2_distance
from pyimagesearch.resultsmontage import ResultsMontage
from scipy.spatial import distance
from redis import Redis
from imutils.feature import FeatureDetector_create, DescriptorExtractor_create
import argparse
import pickle
import imutils
import json
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True, help = "Path to the directory of indexed images")
ap.add_argument("-f", "--features-db", required = True, help = "Path to the features database")
ap.add_argument("-b", "--bovw-db", required = True, help = "Path to the bag-of-visual-words database")
ap.add_argument("-c", "--codebook", required = True, help = "Path to relevant dictionary")
ap.add_argument("-i", "--idf", type = str, help = "Path to inverted document frequencies array")
ap.add_argument("-r", "--relevant", required = True, help = "Path to relevant dictionary")
ap.add_argument("-q", "--query", required = True, help = "Path to the query image")
args = vars(ap.parse_args())
detector = FeatureDetector_create("SURF")
descriptor = DescriptorExtractor_create("RootSIFT")
dad = DetectAndDescribe(detector, descriptor)
distanceMetric = chi2_distance
idf = None
if args["idf"] is not None:
idf = pickle.loads(open(args["idf"], "rb").read())
vocab = pickle.loads(open(args["codebook"], "rb").read())
bovw = BagOfVisualWords(vocab)
relevant = json.loads(open(args["relevant"]).read())
queryFilename = args["query"][args["query"].rfind("/") + 1:]
queryRelevant = relevant[queryFilename]
queryImage = cv2.imread(args["query"])
queryImage = imutils.resize(queryImage, width = 320)
queryImage = cv2.cvtColor(queryImage, cv2.COLOR_BGR2GRAY)
(_, descs) = dad.describe(queryImage)
hist = bovw.describe(descs).tocoo()
redisDB = Redis(host = "localhost", port = 6379, db = 0)
searcher = Searcher(redisDB, args["bovw_db"], args["features_db"], idf = idf, distanceMetric = distanceMetric)
sr = searcher.search(hist, numResults = 20)
print("[INFO] search took:{:.2f}s".format(sr.search_time))
montage = ResultsMontage((240, 320), 5, 20)
for (i, (score, resultID, resultIdx)) in enumerate(sr.results):
print("[RESULT] {result_num}.{result} -{score:.2f}".format(result_num = i + 1, result = resultID, score = score))
result = cv2.imread("{}/{}".format(args["dataset"], resultID))
montage.addResult(result, text = "#{}".format(i + 1), highlight = resultID in queryRelevant)
cv2.imshow("Result", imutils.resize(montage.montage, height = 700))
cv2.waitKey(0)
searcher.finish()
searcher.py
from .searchresult import SearchResult
from .dists import chi2_distance
import numpy as np
import datetime
import h5py
class Searcher:
def __init__(self, redisDB, bovwDBPath, featuresDBPath, idf = None, distanceMetric = chi2_distance):
self.redisDB = redisDB
self.idf = idf
self.distanceMetric = distanceMetric
self.bovwDB = h5py.File(bovwDBPath, mode = "r")
self.featuresDB = h5py.File(featuresDBPath, "r")
def search(self, queryHist, numResults = 10, maxCandidates = 200):
startTime = datetime.datetime.now()
candidateIdxs = self.buildCandidates(queryHist, maxCandidates)
candidateIdxs.sort()
hists = self.bovwDB["bovw"][candidateIdxs]
queryHist = queryHist.toarray()
results = {}
if self.idf is not None:
queryHist *= self.idf
for (candidate, hist) in zip(candidateIdxs, hists):
if self.idf is not None:
hist *=self.idf
d = self.distanceMetric(hist, queryHist)
results[candidate] = d
results = sorted([(v, self.featuresDB["image_ids"][k], k)
for (k, v) in results.items()])
results = results = results[:numResults]
return SearchResult(results, (datetime.datetime.now() - startTime).total_seconds())
def buildCandidates(self, hist, maxCandidates):
p = self.redisDB.pipeline()
for i in hist.col:
p.lrange("vw:{}".format(i), 0, -1)
pipelineResults = p.execute()
candidates = []
for results in pipelineResults:
results = [int(r) for r in results]
candidates.extend(results)
(imageIdxs, counts) = np.unique(candidates, return_counts = True)
imageIdxs = [i for (c, i) in sorted(zip(counts, imageIdxs), reverse = True)]
return imageIdxs[:maxCandidates]
def finish(self):
self.bovwDB.close()
self.featuresDB.close()
dists.py
import numpy as np
def chi2_distance(histA, histB, eps = 1e-10):
d = 0.5 * np.sum(((histA - histB)**2)/(histA + histB + eps))
return d
searchersult.py
from collections import namedtuple
SearchResult = namedtuple("SearchResult", ["results", "search_time"])
9、评估
evaluate.py
from __future__ import print_function
from pyimagesearch.descriptors.detectanddescribe import DetectAndDescribe
from pyimagesearch.ir.bagofvisualwords import BagOfVisualWords
from pyimagesearch.ir.searcher import Searcher
from pyimagesearch.ir.dists import chi2_distance
from scipy.spatial import distance
from redis import Redis
from imutils.feature import FeatureDetector_create, DescriptorExtractor_create
import numpy as np
import progressbar
import argparse
import pickle
import imutils
import json
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True, help = "Path to the directory of indexed images")
ap.add_argument("-f", "--features-db", required = True, help = "Path to the features database")
ap.add_argument("-b", "--bovw-db", required=True, help = "Path to the bag-of-visual-words database")
ap.add_argument("-c", "--codebook", required = True, help = "Path to the codebook")
ap.add_argument("-i", "--idf", type = str, help = "Path to inverted document frequencies array")
ap.add_argument("-r", "--relevant", required = True, help = "Path to relevant dictionary")
args = vars(ap.parse_args())
detector = FeatureDetector_create("SURF")
descriptor = DescriptorExtractor_create("RootSIFT")
dad = DetectAndDescribe(detector, descriptor)
distanceMetric = chi2_distance
idf = None
if args["idf"] is not None:
idf = pickle.loads(open(args["idf"], "rb").read())
distanceMetric = distance.cosine
vocab = pickle.loads(open(args["codebook"], "rb").read())
bovw = BagOfVisualWords(vocab)
redisDB = Redis(host = "localhost", port = 6379, db = 0)
searcher = Searcher(redisDB, args["bovw_db"], args["features_db"], idf = idf, distanceMetric = distanceMetric)
relevant = json.loads(open(args["relevant"]).read())
queryIDs = relevant.keys()
accuracies = []
timings = []
widgets = ["Evaluating:", progressbar.Percentage(), "", progressbar.Bar(), "", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval = len(queryIDs), widgets = widgets).start()
for (i, queryID) in enumerate(sorted(queryIDs)):
queryRelevant = relevant[queryID]
p = "{}/{}".format(args["dataset"], queryID)
queryImage = cv2.imread(p)
quertImage = imutils.resize(queryImage, width = 320)
queryImage = cv2.cvtColor(queryImage, cv2.COLOR_BGR2GRAY)
(_, descs) = dad.describe(queryImage)
hist = bovw.describe(descs).tocoo()
sr = searcher.search(hist, numResults = 4)
results = set([r[1] for r in sr.results])
inter = results.intersection(queryRelevant)
accuracies.append(len(inter))
timings.append(sr.search_time)
pbar.update(i)
searcher.finish()
pbar.finish()
accuracies = np.array(accuracies)
timings = np.array(timings)
print("[INFO] ACCURACY:u = {:.2f}, o = {:.2f}".format(accuracies.mean(), accuracies.std()))
print("[INFO] TIMINGS:u = {:.2f}, o = {:.2f}".format(timings.mean(), timings.std()))
第三章 图像描述符(图片分类)
1、图像描述符、特征描述符和特征向量的定义
特征向量:用于表示和量化图像的数字列表,简单理解成将图片转化为一个数字列表表示。特征向量中用来描述图片的各种属性的向量称为特征矢量。
图像描述符:理解成一种算法和方法,控制整个图像如何转变为特征向量。量化是的图像形状,颜色,纹理,或三者的任何组合。输入1个图像时,图像描述符将返回1个特征向量。主要用于图像分类。缺乏区分图像中不同对象的能力。
特征描述符:是一种算法和方法,控制图像部分区域,对部分区域返回多个特征向量。输入1个图像,返回多个特征向量(主要用来处理图像的局部)。主要用于图像匹配(视觉检测),匹配图像中的物品。
2、色彩通道统计
运行命令:python color_channel_stats.py
原理:通过统计图像中的每个色彩通道(及RGB色彩通道),凭据通道值和标准差等方法,量化和表示图像的颜色分布,从而对图像进行分类。(主要运用颜色差异名义,不同场景图片分类)
from scipy.spatial import distance as dist
from imutils import paths
import numpy as np
import cv2
imagePaths = sorted(list(paths.list_images("dinos")))
index = {}
for imagePath in imagePaths:
image = cv2.imread(imagePath)
filename = imagePath[imagePath.rfind("/") + 1:]
(means, stds) = cv2.meanStdDev(image)#计算图像中每个色彩通道的平均值和标准偏差
features = np.concatenate([means, stds]).flatten()#将每个色彩通道的平均值和标准偏差连接在一起,形成我们的特征向量
index[filename] = features
query = cv2.imread(imagePaths[0])
cv2.imshow("Query (trex_01.png)", query)
keys = sorted(index.keys())
for (i, k) in enumerate(keys):
if k == "trex_01.png":
continue
image = cv2.imread(imagePaths[i])
d = dist.euclidean(index["trex_01.png"], index[k])#计算目标图像特征向量与我们数据集中的特征向量之间的欧几里德距离。d越小,颜色通道越相似,图片越相似。
cv2.putText(image, "%.2f" % (d), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2)
cv2.imshow(k, image)
cv2.waitKey(0)
3、彩色直方图
原理:通过颜色的分布,运用机器学习中的K均值聚类运用于聚类颜色直方图。无参考值进行图像分类。(关键是需要对颜色直方图理解)
文件结构:
|--- pyimagesearch
import cv2
import imutils
class LabHistogram:
def __init__(self, bins):
self.bins = bins
def describe(self, image, mask=None):
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
hist = cv2.calcHist([lab], [0, 1, 2], mask, self.bins,
[0, 256, 0, 256, 0, 256])#获取3D直方图
#将图片大小标准化,忽略图片大小对直方图的影响
if imutils.is_cv2():
hist = cv2.normalize(hist).flatten()
else:
hist = cv2.normalize(hist,hist).flatten()
return hist
cluster_histograms.py
from pyimagesearch.descriptors.labhistogram import LabHistogram
from sklearn.cluster import KMeans
from imutils import paths
import numpy as np
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to the input dataset directory")
ap.add_argument("-k", "--clusters", type=int, default=2,
help="# of clusters to generate")#默认设置k值为2,及将图片分为俩类。
args = vars(ap.parse_args())
desc = LabHistogram([8, 8, 8])
data = []
imagePaths = list(paths.list_images(args["dataset"]))
imagePaths = np.array(sorted(imagePaths))
for imagePath in imagePaths:
image = cv2.imread(imagePath)
hist = desc.describe(image)
data.append(hist)#描述符加入到数据集中
#对描述符进行聚类
clt = KMeans(n_clusters=args["clusters"])
labels = clt.fit_predict(data)
for label in np.unique(labels):
#获取每个集群的唯一ID,进行分类
labelPaths = imagePaths[np.where(labels == label)]
#将同一集群的图片输出显示
for (i, path) in enumerate(labelPaths):
image = cv2.imread(path)
cv2.imshow("Cluster {}, Image #{}".format(label + 1, i + 1), image)
cv2.waitKey(0)
cv2.destroyAllWindows()
4、胡默斯
作用:用于物品形状检测,处理二值图片,提取图片中物体的形状。
运行命令:python extract_hu_moments.py
extract_hu_moments.py
import cv2
import imutils
image = cv2.imread("planes.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
moments = cv2.HuMoments(cv2.moments(image)).flatten()
print("ORIGINAL MOMENTS: {}".format(moments))
cv2.imshow("Image", image)
cv2.waitKey(0)
#找到图片中每个物件的行轮廓
cnts = cv2.findContours(image.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
for (i, c) in enumerate(cnts):
(x, y, w, h) = cv2.boundingRect(c)
roi = image[y:y + h, x:x + w]
#提取每个形状的hu_monebts值
moments = cv2.HuMoments(cv2.moments(roi)).flatten()
print("MOMENTS FOR PLANE #{}: {}".format(i + 1, moments))
cv2.imshow("ROI #{}".format(i + 1), roi)
cv2.waitKey(0)
作用:随机生成数据集
运行命令:python generate_images.py --output output
genetate_images.py
import numpy as np
import argparse
import uuid
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="Path to the output directory")
ap.add_argument("-n", "--num-images", type=int, default=500,
help="# of disctrator images to generate")
args = vars(ap.parse_args())
for i in range(0, args["num_images"]):
image = np.zeros((500, 500, 3), dtype="uint8")
(x, y) = np.random.uniform(low=105, high=405, size=(2,)).astype("int0")
r = np.random.uniform(low=25, high=100, size=(1,)).astype("int0")[0]
color = np.random.uniform(low=0, high=255, size=(3,)).astype("int0")
color = tuple(map(int, color))
cv2.circle(image, (x, y), r, color, -1)
cv2.imwrite("{}/{}.jpg".format(args["output"], uuid.uuid4()), image)
image = np.zeros((500, 500, 3), dtype="uint8")
topLeft = np.random.uniform(low=25, high=225, size=(2,)).astype("int0")
botRight = np.random.uniform(low=250, high=400, size=(2,)).astype("int0")
color = np.random.uniform(low=0, high=255, size=(3,)).astype("int0")
color = tuple(map(int, color))
cv2.rectangle(image, tuple(topLeft), tuple(botRight), color, -1)
cv2.imwrite("{}/{}.jpg".format(args["output"], uuid.uuid4()), image)
作用:从数据集中,找出异常形状
运行命令:python find_rectangle.py --dataset output
find_rectangle.py
from sklearn.metrics.pairwise import pairwise_distances
import numpy as np
import argparse
import glob
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True, help="Path to the dataset directory")
args = vars(ap.parse_args())
imagePaths = sorted(glob.glob(args["dataset"] + "/*.jpg"))
data = []
for imagePath in imagePaths:
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 5, 255, cv2.THRESH_BINARY)[1]
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
c = max(cnts, key=cv2.contourArea)
(x, y, w, h) = cv2.boundingRect(c)
roi = cv2.resize(thresh[y:y + h, x:x + w], (50, 50))#忽略图片大小的影响
moments = cv2.HuMoments(cv2.moments(roi)).flatten()
data.append(moments)
D = pairwise_distances(data).sum(axis=1)
i = np.argmax(D) #获取距离最大的图形,圆形距离很小,矩形距离较大
image = cv2.imread(imagePaths[i])
print("Found square: {}".format(imagePaths[i]))
cv2.imshow("Outlier", image)
cv2.waitKey(0)
5、Zernike时刻
运用Zernike矩阵量化图像中的形状。在图片中寻找某个特定的形状
from scipy.spatial import distance as dist
import numpy as np
import mahotas
import cv2
import imutils
def describe_shapes(image):
shapeFeatures = []
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (13, 13), 0)
cv2.imshow("2", blurred)
thresh = cv2.threshold(blurred, 120, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations = 4)
thres = cv2.erode(thresh, None, iterations = 2)
cv2.imshow("1", thres)
cv2.waitKey(0)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
for c in cnts:
mask = np.zeros(image.shape[:2], dtype = "uint8")
cv2.drawContours(mask, [c], -1, 255, -1)
(x, y, w, h) = cv2.boundingRect(c)
roi = mask[y:y + h, x:x + w]
cv2.imshow("roi", roi)
cv2.waitKey(0)
features = mahotas.features.zernike_moments(roi, cv2.minEnclosingCircle(c)[1], degree = 8)
shapeFeatures.append(features)
return(cnts, shapeFeatures)
refImage = cv2.imread("2.jpg")
(_, gameFeatures) = describe_shapes(refImage)
shapesImage = cv2.imread("1.jpg")
(cnts, shapeFeatures) = describe_shapes(shapesImage)
D = dist.cdist(gameFeatures, shapeFeatures)
i = np.argmin(D) #获取最小距离的下标
for (j, c) in enumerate(cnts):
if i != j:
box = cv2.minAreaRect(c)
box = np.int0(cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box))
cv2.drawContours(shapesImage, [box], - 1, (0, 0, 255), 2)
box = cv2.minAreaRect(cnts[i])
box = np.int0(cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box))
cv2.drawContours(shapesImage, [box], - 1, (0, 255, 0), 2)
(x, y, w, h) = cv2.boundingRect(cnts[i])
cv2.putText(shapesImage, "FOUND!", (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 3)
cv2.imshow("Input Image", refImage)
cv2.imshow("Detected Shapes", shapesImage)
cv2.waitKey(0)
6、Haralick纹理功能
依据数据学习,分析纹理,再将数据图片依据纹理分类:
from sklearn.svm import LinearSVC
import argparse
import glob
import mahotas
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--training", required = True, help = "Path to the dataset of textures")
ap.add_argument("-t", "--test", required = True,help = "Path to the test images" )
args = vars(ap.parse_args())
print("[INFO] extracting features...")
data = []
labels = []
for imagePath in glob.glob(args["training"] + "/*.jpg"):
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
texture = imagePath[imagePath.rfind("/") + 1:].split("_")[0]
features = mahotas.features.haralick(image).mean(axis = 0)
data.append(features)
labels.append(texture)
print("[INFO] training model...")
model = LinearSVC(C = 10.0, random_state = 42)
model.fit(data, labels)
print("[INFO] classifying...")
for imagePath in glob.glob(args["test"] + "/*.jpg"):
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
features = mahotas.features.haralick(gray).mean(axis = 0)
print features
pred = model.predict(features.reshape(1, - 1))[0]
print pred
cv2.putText(image, pred, (20, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 3)
cv2.imshow("Image", image)
cv2.waitKey(0)
7、本地二进制模式
原理:LBP 在本地处理像素, 而不是使用灰度共生矩阵。通过量化小区域特征,分析图片的特征向量,再对图片进行分类。
注意点:记住半径r 和点数p的影响也很重要。积分越多p 你品尝,更多的模式,你可以编码,但在同一时间,你增加你的计算成本。另一方面,如果增加半径大小r, 则可以在图像中捕捉较大的纹理细节。但是,如果增加r 而不增加p ,那么您将失去LBP描述符的局部区分能力。
例:时尚索引
文件结构:
|--- pyimagesearch
| |--- __init__.py
| |--- descriptors
| | |---- __init__.py
| | |--- localbinarypatterns.py
|--- search_shirts.py
作用:创建二进制描述符。
localbinarypatterns.py
from skimage import feature
import numpy as np
class LocalBinaryPatterns:
def __init__(self, numPoints, radius): #围绕中心像素的图案半径,半径外围点数,决定计算量
self.numPoints = numPoints
self.radius = radius
def describe(self, image, eps=1e-7):
lbp = feature.local_binary_pattern(image, self.numPoints, self.radius, method="uniform")
(hist, _) = np.histogram(lbp.ravel(), bins=range(0, self.numPoints + 3),
range=(0, self.numPoints + 2))
# normalize the histogram
hist = hist.astype("float")
hist /= (hist.sum() + eps)
# return the histogram of Local Binary Patterns
return hist
作用:测试二进制描述符的纹理特征效果
运行命令:python search_shirts.py --dataset shirts --query queries/query_01.jpg
search_shirts.py:
from __future__ import print_function
from pyimagesearch import LocalBinaryPatterns
from imutils import paths
import numpy as np
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True, help="path to the dataset of shirt images")
ap.add_argument("-q", "--query", required=True, help="path to the query image")
args = vars(ap.parse_args())
desc = LocalBinaryPatterns(24, 8)
index = {}
for imagePath in paths.list_images(args["dataset"]):
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
hist = desc.describe(gray)
filename = imagePath[imagePath.rfind("/") + 1:]
index[filename] = hist
query = cv2.imread(args["query"])
queryFeatures = desc.describe(cv2.cvtColor(query, cv2.COLOR_BGR2GRAY))
cv2.imshow("Query", query)
results = {}
for (k, features) in index.items():
d = 0.5 * np.sum(((features - queryFeatures) ** 2) / (features + queryFeatures + 1e-10))
results[k] = d
results = sorted([(v, k) for (k, v) in results.items()])[:3]#选取前较小距离(相似性)高的,前3个结果
for (i, (score, filename)) in enumerate(results):#将前3个结果显示出来
print("#%d. %s: %.4f" % (i + 1, filename, score))
image = cv2.imread(args["dataset"] + "/" + filename)
cv2.imshow("Result #{}".format(i + 1), image)
cv2.waitKey(0)
8、定向梯度直方图
原理:运用HOG描述符,他主要用于描述图像中物体的结构形状和外观,使其成为物体分类的优秀描述符。但是,由于HOG捕获局部强度梯度和边缘方向,因此它也会产生良好的纹理描述符
知识点:pixels_per_cell中的像素 越多,我们的表示越粗糙。类似地,pixels_per_cell的较小值将产生更细粒度(轮廓更明显)
疑问:1、from sklearn.neighbors import KNeighborsClassifier
解释:http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
运行命令:python recognize_car_logos.py --training car_logos --test test_images
recognize_car_logs.py
from sklearn.neighbors import KNeighborsClassifier
from skimage import exposure
from skimage import feature
from imutils import paths
import argparse
import imutils
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--training", required=True, help="Path to the logos training dataset")
ap.add_argument("-t", "--test", required=True, help="Path to the test dataset")
args = vars(ap.parse_args())
print "[INFO] extracting features..."
data = []
labels = []
for imagePath in paths.list_images(args["training"]): #提取每个标志的hog特征向量
make = imagePath.split("/")[-2]
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edged = imutils.auto_canny(gray)
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
c = max(cnts, key=cv2.contourArea)
(x, y, w, h) = cv2.boundingRect(c)
logo = gray[y:y + h, x:x + w]
logo = cv2.resize(logo, (200, 100))
H = feature.hog(logo, orientations=9, pixels_per_cell=(10, 10),
cells_per_block=(2, 2), transform_sqrt=True, block_norm="L1")
data.append(H)
labels.append(make)
print("[INFO] training classifier...")
model = KNeighborsClassifier(n_neighbors=1) #对特征数据进行K值分类
model.fit(data, labels)
print("[INFO] evaluating...")
for (i, imagePath) in enumerate(paths.list_images(args["test"])):
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
logo = cv2.resize(gray, (200, 100))
(H, hogImage) = feature.hog(logo, orientations=9, pixels_per_cell=(10, 10),
cells_per_block=(2, 2), transform_sqrt=True, block_norm="L1", visualise=True)
pred = model.predict(H.reshape(1, -1))[0]
hogImage = exposure.rescale_intensity(hogImage, out_range=(0, 255))
hogImage = hogImage.astype("uint8")
cv2.imshow("HOG Image #{}".format(i + 1), hogImage)
cv2.putText(image, pred.title(), (10, 35), cv2.FONT_HERSHEY_SIMPLEX, 1.0,
(0, 255, 0), 3)
cv2.imshow("Test Image #{}".format(i + 1), image)
cv2.waitKey(0)
9、关键点检测
9.1、FAST关键点检测
原理:必须有至少Ñ沿着连续像素圆形周边具有半径- R是所有或者亮或更暗比中心像素由阈值t
疑问:是否可以修改参数,半径-R和N值?
运行命令:python fast_keypoint.py
fast_keypoint.py
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("FAST")
kps = detector.detect(gray)
else:
detector = cv2.FastFeatureDetector_create()
kps = detector.detect(gray, None)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.2Harris关键点检测
原理:将分别在x和y方向上对该区域中的梯度值求和:
^ {2}") 和
和 ^ {2}")
如果这两个值都足够“大”,那么我们可以将该区域定义为角落。该过程针对输入图像中的每个像素完成。这种方法是有效的,因为红色圆圈内的区域会有大量的水平和垂直梯度 - 当发生这种情况时,我们知道我们找到了一个角落.
疑问:1、harris函数的参数的作用:
• img - 数据类型为 float32 的输入图像。
• blockSize - 角点检测中要考虑的领域大小。
• ksize - Sobel 求导中使用的窗口大小
• k - Harris 角点检测方程中的自由参数,取值参数为 [0,04,0.06].
2、harris什么时候被调用?
harris_keypoint.py
from __future__ import print_function
import numpy as np
import cv2
import imutils
def harris(gray, blockSize=2, apetureSize=3, k=0.1, T=0.02):
gray = np.float32(gray)
H = cv2.cornerHarris(gray, blockSize, apetureSize, k)
kps = np.argwhere(H > T * H.max())
kps = [cv2.KeyPoint(pt[1], pt[0], 3) for pt in kps]
return kps
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("HARRIS")
kps = detector.detect(gray)
else:
kps = harris(gray)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
# show the image
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.3、GFTT关键点检测
原理:提出了以下R的计算来表明一个地区是否是一个角落:") 在这种情况下,我们只是取特征值分解分量的最小值。如果这个值R大于我们的阈值T (即
在这种情况下,我们只是取特征值分解分量的最小值。如果这个值R大于我们的阈值T (即 ),那么我们可以将该区域标记为拐角。(在harris基础上改进)
),那么我们可以将该区域标记为拐角。(在harris基础上改进)
from __future__ import print_function
import numpy as np
import cv2
import imutils
def gftt(gray, maxCorners=0, qualityLevel=0.01, minDistance=1,
mask=None, blockSize=3, useHarrisDetector=False, k=0.04):
kps = cv2.goodFeaturesToTrack(gray, maxCorners, qualityLevel,
minDistance, mask=mask, blockSize=blockSize,
useHarrisDetector=useHarrisDetector, k=k)
return [cv2.KeyPoint(pt[0][0], pt[0][1], 3) for pt in kps]
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("GFTT")
kps = detector.detect(gray)
else:
kps = gftt(gray)
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
print("# of keypoints: {}".format(len(kps)))
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.4、DoG关键点检测器
通过对图像缩放变化,寻找角点,获取的角点绘制出来的圆有大小区别。
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
else:
detector = cv2.xfeatures2d.SIFT_create()
(kps, _) = detector.detectAndCompute(gray, None)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.5、Fast_Hessian关键点检测
作用:类似于高斯差分,快速Hessian关键点检测器用于定位图像中可重复的“斑点”状区域。这些区域可能是边缘,角落或两者
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("SURF")
kps = detector.detect(gray)
else:
detector = cv2.xfeatures2d.SURF_create()
(kps, _) = detector.detectAndCompute(gray, None)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.6、STAR关键点检测
运用情况:用于检测图像中的“斑点”状区域
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("STAR")
kps = detector.detect(gray)
else:
detector = cv2.xfeatures2d.StarDetector_create()
kps = detector.detect(gray)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.7、MSER关键点检测
作用:MSER检测器用于检测图像中的“斑点”状结构。假设这些区域很小,具有相对相同的像素强度,并且被对比像素包围
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect MSER keypoints in the image
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("MSER")
kps = detector.detect(gray)
else:
detector = cv2.MSER_create()
kps = detector.detect(gray, None)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.8、密集关键点检测
作用:浓密检测器 将图像中的每个k像素标记为关键点
from __future__ import print_function
import numpy as np
import argparse
import cv2
import imutils
def dense(image, step, radius):
kps = []
for x in range(0, image.shape[1], step):
for y in range(0, image.shape[0], step):
kps.append(cv2.KeyPoint(x, y, radius * 2))
return kps
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--step", type=int, default=28, help="step (in pixels) of the dense detector")
args = vars(ap.parse_args())
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
kps = []
radii = (4, 8, 12)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("Dense")
detector.setInt("initXyStep", args["step"])
rawKps = detector.detect(gray)
else:
rawKps = dense(gray, args["step"], 1)
for rawKp in rawKps:
for r in radii:
kp = cv2.KeyPoint(x=rawKp.pt[0], y=rawKp.pt[1], _size=r * 2)
kps.append(kp)
print("# dense keypoints: {}".format(len(rawKps)))
print("# dense + multi radii keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 1)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.9、BRISK关键点检测器
运用情况:多尺度版本
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("BRISK")
kps = detector.detect(gray)
else:
detector = cv2.BRISK_create()
kps = detector.detect(gray, None)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
9.10、ORB关键点检测器的运用
作用:ORB用于检测图像中的角点
from __future__ import print_function
import numpy as np
import cv2
import imutils
image = cv2.imread("next.png")
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("ORB")
kps = detector.detect(gray)
else:
detector = cv2.ORB_create()
kps = detector.detect(gray, None)
print("# of keypoints: {}".format(len(kps)))
for kp in kps:
r = int(0.5 * kp.size)
(x, y) = np.int0(kp.pt)
cv2.circle(image, (x, y), r, (0, 255, 255), 2)
cv2.imshow("Images", np.hstack([orig, image]))
cv2.waitKey(0)
10、局部不变描述符
10.1、SIFT
作用:检测关键点并从图像中提取SIFT特征向量
from __future__ import print_function
import argparse
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("SIFT")
extractor = cv2.DescriptorExtractor_create("SIFT")
kps = detector.detect(gray)
(kps, descs) = extractor.compute(gray, kps)
else:
detector = cv2.xfeatures2d.SIFT_create()
(kps, descs) = detector.detectAndCompute(gray, None)
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
10.2、RootSIFT
作用:定义RootSIFT检测器,获取关键点特征
rootsift.py
import numpy as np
import cv2
import imutils
class RootSIFT:
def __init__(self):
if imutils.is_cv2():
self.extractor = cv2.DescriptorExtractor_create("SIFT")
else:
self.extractor = cv2.xfeatures2d.SIFT_create()
def compute(self, image, kps, eps=1e-7):
if imutils.is_cv2:
(kps, descs) = self.extractor.compute(image, kps)
else:
(kps, descs) = self.extractor.detectAndCompute(image, None)
if len(kps) == 0:
return ([], None)
descs /= (descs.sum(axis=1, keepdims=True) + eps)
descs = np.sqrt(descs)
return (kps, descs)
作用:从图像中提取RootSIFT描述符
extract_rpptsift.py
from __future__ import print_function
from pyimagesearch.descriptors import RootSIFT
import argparse
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("SIFT")
extractor = RootSIFT()
kps = detector.detect(gray)
else:
detector = cv2.xfeatures2d.SIFT_create()
extractor = RootSIFT()
(kps, _) = detector.detectAndCompute(gray, None)
(kps, descs) = extractor.compute(gray, kps)
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
10.3、SURF
作用:SURF的第一步是选择围绕关键点的图像的矩形区域。在关键点检测阶段确定区域的确切大小
extract_surf.py
from __future__ import print_function
import argparse
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("SURF")
extractor = cv2.DescriptorExtractor_create("SURF")
kps = detector.detect(gray)
(kps, descs) = extractor.compute(gray, kps)
else:
detector = cv2.xfeatures2d.SURF_create()
(kps, descs) = detector.detectAndCompute(gray, None)
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
10.4、实值特征匹配
知识点:提取关键点的图像坐标,例:ksp[0].pt
运行命令:1、python draw_matches.py --first jp_01.png --second jp_02.png --detector SURF --extractor SIFT
2、python draw_matches.py --first jp_01.png --second jp_02.png --detector SURF --extractor RootSIFT
3、python draw_matches.py --first jp_01.png --second jp_02.png --detector SURF --extractor SURF
#coding=utf-8
from __future__ import print_function
import numpy as np
import argparse
import cv2
from imutils.feature.factories import FeatureDetector_create, DescriptorExtractor_create, DescriptorMatcher_create
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--first", required = True, help = "Path to first image") #提取关键点和特征向量的第一幅图像的路经
ap.add_argument("-s", "--second", required = True, help = "Path to second image")#提取关键点和特征向量的第二幅图像的路经
ap.add_argument("-d", "--detector", type = str, default="SURF", help = "Kepyoint detector to use.Options ['BRISK', 'DENSE', 'DOG', 'SIFT', 'FAST', 'FASTHESSIAN', 'SURF', 'GFTT','HARRIS', 'MSER', 'ORB', 'STAR']")#用于在俩个图像执行关键点检测的关键点的检测器
ap.add_argument("-e", "--extractor", type = str, default = "SIFT", help = "Keypoint detector to use.Options['RootSIFT', 'SIFT', 'SURF']")#关键点区域提取局部不变描述符
ap.add_argument("-m", "--matcher", type = str, default ="BruteForce", help = "Feature matcher to use. Options ['BruteForce', 'BruteForce-SL2', 'BruteForce-L1','FlannBased']")#寻找没对描述符最小距离方法
#ap.add_argument("-v", "--visualize", type = str, default = "Yes", help="Whether the visualiz image should be shown. Options ['Yes', 'No', 'Each']")
ap.add_argument("-v", "--visualize", type = str, default = "Yes", help="Whether the visualiztion image should be shown. Options ['Yes', 'No', 'Each']")#绘制对关键点和描述符之间的匹配
args = vars(ap.parse_args())
if args["detector"] == "DOG":
detector = FeatureDetector_create("SIFT")
elif args["detector"] == "FASTHESSIAN":
detector = FeatureDetector_create("SURF")
else:
detector = FeatureDetector_create(args["detector"])
extractor = DescriptorExtractor_create(args["extractor"])#提取关键点区域的特征描述符
matcher = DescriptorMatcher_create(args["matcher"])
imageA = cv2.imread(args["first"])
imageB = cv2.imread(args["second"])
grayA = cv2.cvtColor(imageA, cv2.COLOR_BGR2GRAY)
grayB = cv2.cvtColor(imageB, cv2.COLOR_BGR2GRAY)
#提取关键点
kpsA = detector.detect(grayA)
kpsB = detector.detect(grayB)
#提取关键的局部特征描述符
(kpsA, featuresA) = extractor.compute(grayA, kpsA)
(kpsB, featuresB) = extractor.compute(grayB, kpsB)
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
if rawMatches is not None:
for m in rawMatches:
#筛选符合条件的关键点
if len(m) == 2 and m[0].distance < m[1].distance*0.8:
matches.append((m[0].trainIdx, m[0].queryIdx))
print("# of keypoints from first image:{}".format(len(kpsA)))
11、二进制描述符
11.1、ORB
from __future__ import print_function
import argparse
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("ORB")
extractor = cv2.DescriptorExtractor_create("ORB")
kps = detector.detect(gray)
(kps, descs) = extractor.compute(gray, kps)
else:
detector = cv2.ORB_create()
(kps, descs) = detector.detectAndCompute(gray, None)
# show the shape of the keypoints and local invariant descriptors array
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
11.2、BRISK
from __future__ import print_function
import argparse
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("BRISK")
extractor = cv2.DescriptorExtractor_create("BRISK")
kps = detector.detect(gray)
(kps, descs) = extractor.compute(gray, kps)
else:
detector = cv2.BRISK_create()
(kps, descs) = detector.detectAndCompute(gray, None)
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
11.3、BRIEF
from __future__ import print_function
import argparse
import cv2
import imutils
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("FAST")
extractor = cv2.DescriptorExtractor_create("BRIEF")
else:
detector = cv2.FastFeatureDetector_create()
extractor = cv2.xfeatures2d.BriefDescriptorExtractor_create()
kps = detector.detect(gray)
(kps, descs) = extractor.compute(gray, kps)
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
from __future__ import print_function
import argparse
import cv2
import imutils
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if imutils.is_cv2():
detector = cv2.FeatureDetector_create("FAST")
extractor = cv2.DescriptorExtractor_create("FREAK")
kps = detector.detect(gray)
(kps, descs) = extractor.compute(gray, kps)
else:
detector = cv2.FastFeatureDetector_create()
extractor = cv2.xfeatures2d.FREAK_create()
kps = detector.detect(gray, None)
(kps, descs) = extractor.compute(gray, kps)
print("[INFO] # of keypoints detected: {}".format(len(kps)))
print("[INFO] feature vector shape: {}".format(descs.shape))
自定义对象检测器
1、模板匹配
运行指令:python template_matching.py --source 3.jpg --template 2.jpg
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--source", required=True, help="Path to the source image")
ap.add_argument("-t", "--template", required=True, help="Path to the template image")
args = vars(ap.parse_args())
source = cv2.imread(args["source"])
template = cv2.imread(args["template"])
(tempH, tempW) = template.shape[:2]
result = cv2.matchTemplate(source, template, cv2.TM_CCOEFF) #参数1:源图像 参数2:模板图像 参数3:模板匹配方法
(minVal, maxVal, minLoc, (x, y)) = cv2.minMaxLoc(result) #获取最佳匹配的(x,y)坐标
cv2.rectangle(source, (x, y), (x + tempW, y + tempH), (0, 255, 0), 2) #在源图像上绘制边框
2、训练自己的物体探测器
作用:结合caltech101数据集,结合.mat文件,训练对象检测器,生成SVM线性支持向量机
train_detector.py
运行指令:python train_detector.py --class stop_sign_images --annotations stop_sign_annotations \
from __future__ import print_function
from imutils import paths
from scipy.io import loadmat
from skimage import io
import argparse
import dlib
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--class", required=True,
help="Path to the CALTECH-101 class images")#要训练一个对象检测器的具体CALTECH-101(数据集)类的路径
ap.add_argument("-a", "--annotations", required=True,
help="Path to the CALTECH-101 class annotations")#指定我们正在训练的特定类的边界框的路径(caltech101数据集中对应的.mat文件夹)
ap.add_argument("-o", "--output", required=True,
help="Path to the output detector")#输出分类器的路径
args = vars(ap.parse_args())
print("[INFO] gathering images and bounding boxes...")
options = dlib.simple_object_detector_training_options()
images = []
boxes = []
for imagePath in paths.list_images(args["class"]):#循环输入需要被训练的图像
imageID = imagePath[imagePath.rfind("/") + 1:].split("_")[1]
imageID = imageID.replace(".jpg", "")
p = "{}/annotation_{}.mat".format(args["annotations"], imageID)
annotations = loadmat(p)["box_coord"]#从路径中提取图像ID,然后使用图像ID ,从磁盘加载相应的 注释(即边界框)
bb = [dlib.rectangle(left=long(x), top=long(y), right=long(w), bottom=long(h))
for (y, h, x, w) in annotations]#构 矩形 对象来表示边界框
boxes.append(bb)
images.append(io.imread(imagePath))#更新边界当前图像框和添加图片到列表中,在DLIB库将需要的两个图像和函数加载到训练分类器中
test_detector.py
运行指令:python test_detector.py --detector output/stop_sign_detector.svm --testing stop_sign_testing
作用:测试自定义对象检测器效果
from imutils import paths
import argparse
import dlib
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--detector", required=True, help="Path to trained object detector")#训练出的SVM线性检测器
ap.add_argument("-t", "--testing", required=True, help="Path to directory of testing images")#包含停止标志图像进行测试的目录的路径
args = vars(ap.parse_args())
detector = dlib.simple_object_detector(args["detector"])
for testingPath in paths.list_images(args["testing"]):#循环测试需要测试的图像
image = cv2.imread(testingPath)
boxes = detector(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
for b in boxes:
(x, y, w, h) = (b.left(), b.top(), b.right(), b.bottom())
cv2.rectangle(image, (x, y), (w, h), (0, 255, 0), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
3.1、图像金字塔
目录:

作用:指图像按一定比例缩放,并且返回。
知识点:关键字 yield 返回并不结束,理解为延迟返回结果
helper.py:
import imutils
#自定义金字塔函数
def pyramid(image, scale=1.5, minSize=(30, 30)): #参数1:源图像 参数2:每次缩放比例 参数3:设置最小尺寸
yield image #定义为金字塔原图像
while True:
w = int(image.shape[1] / scale)
image = imutils.resize(image, width=w) #设置长宽按比例缩放
if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]:#判断缩放的图片是否满足需求
break
yield image
#定义滑动穿口函数
def sliding_window(image, stepSize, windowSize):#参数1:要检查的对象 参数2:每次跳过多少像素,参数3:每次窗口要检查的大小
for y in xrange(0, image.shape[0], stepSize): for x in xrange(0, image.shape[1], stepSize): yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
test_pyramid.py
示例:python test_pyramid.py --image florida_trip.png --scale 1.5
#对金字塔函数的使用
from pyimagesearch.object_detection.helpers import pyramid import argparse import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="path to the input image") ap.add_argument("-s", "--scale", type=float, default=1.5, help="scale factor size") #每次图像缩小比例 args = vars(ap.parse_args()) image = cv2.imread(args["image"]) for (i, layer) in enumerate(pyramid(image, scale=args["scale"])): cv2.imshow("Layer {}".format(i + 1), layer) cv2.waitKey(0)
3.2、滑动窗户
test_sliding_window.py
作用:金字塔与滑动窗口的联合的运用
运行指令:python test_sliding_window.py --image florida_trip.png --width 64 --height 64
from pyimagesearch.object_detection.helpers import sliding_window
from pyimagesearch.object_detection.helpers import pyramid
import argparse
import time
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="path to the input image")#需要处理的图像
ap.add_argument("-w", "--width", type=int, help="width of sliding window")#滑动窗口的宽度
ap.add_argument("-t", "--height", type=int, help="height of sliding window")#滑动窗口的高度
ap.add_argument("-s", "--scale", type=float, default=1.5, help="scale factor size")#图像金字塔的调整大小因子
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
(winW, winH) = (args["width"], args["height"])
for layer in pyramid(image, scale=args["scale"]):
for (x, y, window) in sliding_window(layer, stepSize=32, windowSize=(winW, winH)):
if window.shape[0] != winH or window.shape[1] != winW:
continue
clone = layer.copy()
cv2.rectangle(clone, (x, y), (x + winW, y + winH), (0, 255, 0), 2)
cv2.imshow("Window", clone)
cv2.waitKey(1)
time.sleep(0.025)
4.1构建自定义检测框架的6个步骤
哈尔级联的问题(Viola-Jones探测器(2)):OpenCV中检测到面孔/人物/对象/任何东西,将花费大量时间调整cv2.detectMultiScale参数。
Viola-Jones探测器不是我们唯一的物体检测选择。我们可以使用关键点对象检测,局部不变描述符和一系列的视觉词模型。
六步框架:
步骤1:从想要检测的对象的训练数据中取样p个正样本,并从这些样本中提取HOG描述符。将提取对象的边界框(包括图像的训练数据),然后在该ROI上计算HOG特征,HOG功能将作为正面例子。
步骤2:负面训练集不包含任何要检测的对象,并从这些样品中提取HOG描述为好。实践中负面样本远远大于正样本
步骤3:在正负样本上训练线性支持向量机。
步骤4:应用硬阴极开采。对于负面训练集中的每个图像和每个图像的每个可能的比例(即图像金字塔),应用滑动窗口技术将窗口滑过图像。减少我们最终检测器中的假阳性数量。
步骤5:采取在硬阴极开采阶段发现的假阳性样本,以其置信度(即概率)进行排序,并使用这些阴性样本重新训练分类器
步骤6:分类器现在已经受过培训,可以应用于测试数据集。再次,就像在步骤4中,对于测试集中的每个图像,并且对于图像的每个比例,应用滑动窗口技术。在每个窗口中,提取HOG描述符并应用分类器。如果分类器以很大的概率检测到对象,记录窗口的边界框。完成扫描图像后,应用非最大抑制来删除冗余和重叠的边界框。
扩展和其他方法:
在物体检测中使用HOG+线性SVM方法简单易懂。与使用的标准6步框架略有不同。
第一个变化是关于HOG滑动窗口和非最大抑制方法。代替从提取特征的二者的正和负数据集,所述方法DLIB优化HOG滑动窗口使得上的错误的数目 的每个训练图像。这意味着 整个 训练图像都用于(1)提取正例,和(2) 从图像的所有其他区域提取 负样本。这完全减轻 了负面培训的需要和强烈的消极采矿的要求。这是Max-Margin Object 检测方法如此之快的原因之一 。
其次,在实际的训练阶段,dlib也考虑到非最大的压制。我们通常只应用NMS来获得最终的边界框,但在这种情况下,我们实际上可以在训练阶段使用NMS。这有助于减少误报 实质上并再次减轻了硬负开采的需要。
最后,dlib使用非常精确的算法来找到分离两个图像类的最优超平面。该方法比许多其他最先进的对象检测器获得更高的精度(具有较低的假阳性率)。
5、准备实验和培训数据
框架的完整目录结构:(pyimagesearch同级目录还有conf目录存放json文件,datasets目录,存放数据集)

实验配置:运用JSON配置文件
json配置文件优势:
1、不需要明确定义一个永无止尽的命令行参数列表,只需要提供的是我们配置文件的路径。
2、配置文件允许将所有相关参数整合到一个 位置。
3、确保我们不会忘记为每个Python脚本使用哪些命令行选项。所有选项将在我们的配置文件中定义。
4、允许我们为每个要创建的对象检测器配置一个配置文件 。这是一个巨大的优势,允许我们通过修改单个文件来定义对象检测器 。
cars.json:
{
#######
# DATASET PATHS
#######
"image_dataset": "datasets/caltech101/101_ObjectCategories/car_side",#我们的“正例”图像的路径,需要训练的基础数据
"image_annotations": "datasets/caltech101/Annotations/car_side",#包含与image_dataset中每个图像相关联的边界框的目录的路径
"image_distractions": "datasets/sceneclass13",#不包含我们想要检测的对象的任何示例的“否定示例”
}
explore_dims.py
作用:在caltech101数据中提取.mat文件信息,遍历所有图片轮廓信息,同时获取滑动活动窗口尺寸
涉及到知识点:1、处理caltech101数据集方法及提取.mat文件信息
2、用用golb.golb()函数遍历文件夹中的文件方法
运行指令:python explore_dims.py --conf conf/cars.json
from __future__ import print_function
from pyimagesearch.utils import Conf
from scipy import io
import numpy as np
import argparse
import glob
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True, help="path to the configuration file")
args = vars(ap.parse_args())
conf = Conf(args["conf"])#加载配置文件
widths = []#初始化检测对象的宽度
heights = []#初始化检测对象的高度
for p in glob.glob(conf["image_annotations"] + "/*.mat"):#循环检测对象的注释文件
(y, h, x, w) = io.loadmat(p)["box_coord"][0]
widths.append(w - x)
heights.append(h - y)#加载每个检测对象的注释文件相关联的边界框,并更新相应的宽度和高度列表。
#计算平均宽度和高度
(avgWidth, avgHeight) = (np.mean(widths), np.mean(heights))
print("[INFO] avg. width: {:.2f}".format(avgWidth))
print("[INFO] avg. height: {:.2f}".format(avgHeight))
print("[INFO] aspect ratio: {:.2f}".format(avgWidth / avgHeight))
conf.py:解析命令行参数
作用:解析car.json文件的类
python内置函数__getitem__的作用:
在类中定义了__getitem__()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。当实例对象做P[key]运算时,就会调用类中的__getitem__()方法
import commentjson as json
class Conf:
def __init__(self, confPath):
conf = json.loads(open(confPath).read())
self.__dict__.update(conf)
def __getitem__(self, k):
return self.__dict__.get(k, None)
6、构建HOG描述符
cars.json:
{
#######
# DATASET PATHS
#######
"image_dataset": "datasets/caltech101/101_ObjectCategories/car_side",
"image_annotations": "datasets/caltech101/Annotations/car_side",
"image_distractions": "datasets/sceneclass13",
#######
# FEATURE EXTRACTION
#######
"features_path": "output/cars/car_features.hdf5",
"percent_gt_images": 0.5,
"offset": 5,
"use_flip": true,
"num_distraction_images": 500,
"num_distractions_per_image": 10,
#######
# HISTOGRAM OF ORIENTED GRADIENTS DESCRIPTOR 使用的方向梯度直方图
#######
"orientations": 9,
"pixels_per_cell": [4, 4], #能被滑动窗口尺寸整除
"cells_per_block": [2, 2],
"normalize": true,
#######
# OBJECT DETECTOR 定义滑动窗口大小
#######
"window_step": 4,
"overlap_thresh": 0.3,
"pyramid_scale": 1.5,
"window_dim": [96, 32],
"min_probability": 0.7
}
dataset.py
作用:定义h5py数据库运用的方法
涉及到知识点:1、对h5py数据库的运用
疑问:create_dataset()函数参数作用:
参数:数据库的名字,参数2:数据库维度,参数3:数据类型
扩展:h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称。
import numpy as np
import h5py
#从磁盘上的数据集加载特征向量和标签
def dump_dataset(data,labels,path,datasetName,writeMethod="w"):#参数1:要写入HDF5数据集的特征向量列表。参数2:标签,与每个特征向量相关联的标签列表。参数3:HDF5数据集在磁盘上的存储位置。参数5:HDF5文件中数据集的名称。参数5:HDF5数据集的写入方法
db = h5py.File(path, writeMethod)
dataset = db.create_dataset(datasetName, (len(data), len(data[0]) + 1), dtype="float")
dataset[0:len(data)] = np.c_[labels, data]
db.close()
def load_dataset(path, datasetName):#加载与datasetName相关联的特征向量和标签
db = h5py.File(path, "r")
(labels, data) = (db[datasetName][:, 0], db[datasetName][:, 1:])
db.close()
return (data, labels)
helpers.py:
作用:返回每张图片的ROI,(最小包围矩阵)
import imutils
import cv2
def crop_ct101_bb(image, bb, padding=10, dstSize=(32, 32)):
(y, h, x, w) = bb
(x, y) = (max(x - padding, 0), max(y - padding, 0))
roi = image[y:h + padding, x:w + padding]
roi = cv2.resize(roi, dstSize, interpolation=cv2.INTER_AREA)
return roi
extract_features.py:
作用:提取图片的hog特征向量,为SVC数据分类提供数据
涉及到知识点:1、运用imutils中的paths模块遍历文件
疑惑:1、 progressbar模块的作用:
创建一个进度条显示对象
widgets可选参数含义:
'Progress: ' :设置进度条前显示的文字
Percentage() :显示百分比
Bar('#') : 设置进度条形状
ETA() : 显示预计剩余时间
Timer() :显示已用时间
2、HOG函数的详解
https://blog.csdn.net/zhazhiqiang/article/details/20221143
https://baike.baidu.com/item/HOG/9738560?fr=aladdin
3、random.sample函数作用?
sample(seq, n) 从序列seq中选择n个随机且独立的元素;
4、random.choice函数的作用?
choice(seq) 从序列seq中返回随机的元素
random模块拓展:
1 )、random() 返回0<=n<1之间的随机实数n;
2)、getrandbits(n) 以长整型形式返回n个随机位;
3)、shuffle(seq[, random]) 原地指定seq序列;
5、sklearn.feature_extraction.image模块中extract_patches_2d函数的作用?
6)提示信息:Default value of `block_norm`==`L1` is deprecated and will be changed to `L2-Hys` in v0.15 比Py中特征少?
运行指令:python extract_features.py --conf conf/cars.json
# import the necessary packages
from __future__ import print_function
from sklearn.feature_extraction.image import extract_patches_2d
from pyimagesearch.object_detection import helpers
from pyimagesearch.descriptors import HOG
from pyimagesearch.utils import dataset
from pyimagesearch.utils import Conf
from imutils import paths
from scipy import io
import numpy as np
import progressbar
import argparse
import random
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True, help="path to the configuration file")
args = vars(ap.parse_args())
conf = Conf(args["conf"])#加载配置文件
#调用函数初始化HOG描述符
hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]),
cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"])
data = []
labels = []
#随机抽取车测试图
trnPaths = list(paths.list_images(conf["image_dataset"]))
trnPaths = random.sample(trnPaths, int(len(trnPaths) * conf["percent_gt_images"]))
print("[INFO] describing training ROIs...")
widgets = ["Extracting: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(trnPaths), widgets=widgets).start()
#训练每个图像
for (i, trnPath) in enumerate(trnPaths):
image = cv2.imread(trnPath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
imageID = trnPath[trnPath.rfind("_") + 1:].replace(".jpg", "")#提取文件名
p = "{}/annotation_{}.mat".format(conf["image_annotations"], imageID)
bb = io.loadmat(p)["box_coord"][0]
roi = helpers.crop_ct101_bb(image, bb, padding=conf["offset"], dstSize=tuple(conf["window_dim"]))
#确定我们是否应该使用ROI的水平翻转作为额外的训练数据
rois = (roi, cv2.flip(roi, 1)) if conf["use_flip"] else (roi,)
#中提取HOG特征,并更新 数据 和 标签 列表
for roi in rois:
features = hog.describe(roi)
data.append(features)
labels.append(1)
pbar.update(i)
dstPaths = list(paths.list_images(conf["image_distractions"]))
pbar = progressbar.ProgressBar(maxval=conf["num_distraction_images"], widgets=widgets).start()
print("[INFO] describing distraction ROIs...")
#训练负图像样本
for i in np.arange(0, conf["num_distraction_images"]):
image = cv2.imread(random.choice(dstPaths))
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
patches = extract_patches_2d(image, tuple(conf["window_dim"]),
max_patches=conf["num_distractions_per_image"])
for patch in patches:
features = hog.describe(patch)
data.append(features)
labels.append(-1)
pbar.update(i)
pbar.finish()
print("[INFO] dumping features and labels to file...")
dataset.dump_dataset(data, labels, conf["features_path"], "features")
7、初始训练阶段
car.json:
{
#######
# DATASET PATHS
#######
"image_dataset": "datasets/caltech101/101_ObjectCategories/car_side",
"image_annotations": "datasets/caltech101/Annotations/car_side",
"image_distractions": "datasets/sceneclass13",
#######
# FEATURE EXTRACTION
#######
"features_path": "output/cars/car_features.hdf5",
"percent_gt_images": 0.5,
"offset": 5,
"use_flip": true,
"num_distraction_images": 500,
"num_distractions_per_image": 10,
#######
# HISTOGRAM OF ORIENTED GRADIENTS DESCRIPTOR
#######
"orientations": 9,
"pixels_per_cell": [4, 4],
"cells_per_block": [2, 2],
"normalize": true,
#######
# OBJECT DETECTOR
#######
"window_step": 4,
"overlap_thresh": 0.3,
"pyramid_scale": 1.5,
"window_dim": [96, 32],
"min_probability": 0.7,
#######
# LINEAR SVM
#######
"classifier_path": "output/cars/model.cpickle",#分类器被储存的位置
"C": 0.01,
}
train_model.py
作用:对获取的图像hog特征向量,运用SVC线性分类处理
疑问:1、sklearn函数模块详解?
2、args["hard_negatives"]参数作用?
3、numpy.stack()函数作业用:
改变列表数据维度
参数1:列表数据,参数2:设置列表维度
4、numpy.hstack()函数作用
水平(按列顺序)把数组给堆叠起来,vstack()函数正好和它相反
参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。
运行指令:python train_model.py --conf conf/cars.json
from __future__ import print_function
from pyimagesearch.utils import dataset
from pyimagesearch.utils import Conf
from sklearn.svm import SVC
import numpy as np
import argparse
import cPickle
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True,
help="path to the configuration file")
ap.add_argument("-n", "--hard-negatives", type=int, default=-1,
help="flag indicating whether or not hard negatives should be used")
args = vars(ap.parse_args())
print("[INFO] loading dataset...")
conf = Conf(args["conf"])
(data, labels) = dataset.load_dataset(conf["features_path"], "features")#抓取提取的特征向量和标签
if args["hard_negatives"] > 0:
print("[INFO] loading hard negatives...")
(hardData, hardLabels) = dataset.load_dataset(conf["features_path"], "hard_negatives")
data = np.vstack([data, hardData])
labels = np.hstack([labels, hardLabels])
print("[INFO] training classifier...")
model = SVC(kernel="linear", C=conf["C"], probability=True, random_state=42)
model.fit(data, labels)
print("[INFO] dumping classifier...")
f = open(conf["classifier_path"], "w")
f.write(cPickle.dumps(model))#将分类器转储成档
f.close()
objectdetector.py:
作用:经过滑动窗口和金字塔处理后的图像,提取符合概率的轮廓列表。
疑惑:改变概率参数,符合要求的轮廓数量没有发生改变?
pyramid函数(3.1)、sliding_window函数(3.2)写到helpers.py中
iimport helpers
class ObjectDetector:
def __init__(self, model, desc):
self.model = model
self.desc = desc
def detect(self, image, winDim, winStep=4, pyramidScale=1.5, minProb=0.7):#image:需要检测的图像,winDim:滑动窗口尺寸大小
boxes = []
probs = []
for layer in helpers.pyramid(image, scale=pyramidScale, minSize=winDim):#循环金子塔中的图像
scale = image.shape[0] / float(layer.shape[0])
for (x, y, window) in helpers.sliding_window(layer, winStep, winDim):
(winH, winW) = window.shape[:2]
if winH == winDim[1] and winW == winDim[0]:
features = self.desc.describe(window).reshape(1, -1)
prob = self.model.predict_proba(features)[0][1]
if prob > minProb:
(startX, startY) = (int(scale * x), int(scale * y))
endX = int(startX + (scale * winW))
endY = int(startY + (scale * winH))
boxes.append((startX, startY, endX, endY))
probs.append(prob)
return (boxes, probs)
test_model_no_nms.py(与pyimagesearch同级目录下)
作用:测试通过轮廓列表寻找到轮廓是否正确
疑问:
1、sklearn.svm模块中SVC的详解
参数解释链接:https://blog.csdn.net/szlcw1/article/details/52336824
2、提示错误信息:Default value of `block_norm`==`L1` is deprecated and will be changed to `L2-Hys` in v0.15
运行指令:python test_model_no_nms.py --conf conf/cars.json--image datasets/caltech101/101_ObjectCategories/car_side/image_0004.jpg
from pyimagesearch.object_detection import ObjectDetector
from pyimagesearch.descriptors import HOG
from pyimagesearch.utils import Conf
import imutils
import argparse
import cPickle
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True, help="path to the configuration file")
ap.add_argument("-i", "--image", required=True, help="path to the image to be classified")
args = vars(ap.parse_args())
conf = Conf(args["conf"])
model = cPickle.loads(open(conf["classifier_path"]).read()) #SVC线性值
hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]),
cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"]) #hog特征向量值提取方法
od = ObjectDetector(model, hog)
image = cv2.imread(args["image"])
image = imutils.resize(image, width=min(260, image.shape[1]))
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
(boxes, probs) = od.detect(gray, conf["window_dim"], winStep=conf["window_step"],
pyramidScale=conf["pyramid_scale"], minProb=conf["min_probability"])
for (startX, startY, endX, endY) in boxes:
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
问题1:修改感兴趣概率,获取的敏感区域一样?
8、非最大抑制
作用:解决重叠边界框,寻找到最佳匹配轮廓
nms.py(object_detection目录下):
疑问:1、numpy模块中argsort()函数的作用:
获取数组从小到的大索引值
2、numpy模块中concatenate()函数作用:
对数组进行拼接
3、while里面对idx的处理逻辑?语法规则?
讲解示例:https://blog.csdn.net/scut_salmon/article/details/79318387
nms.py
import numpy as np
def non_max_suppression(boxes, probs, overlapThresh):#参数1:边界框列表,参数2:每个框相关的概率,参数3:重叠的阀值
if len(boxes) == 0:#判断边界框列表是否为空
return []
if boxes.dtype.kind == "i":
boxes = boxes.astype("float")#将边界框数据由整型转换成浮点型
#获取边界框每个角的坐标
pick = []
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
#获取边界框的面积
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(probs)
#获取列表的长度,并将其保留在边框列表中
while len(idxs) > 0:
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
#获取边最大坐标的界框和最小的坐标边界宽
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
# 计算重叠比例
overlap = (w * h) / area[idxs[:last]]
idxs = np.delete(idxs, np.concatenate(([last],
np.where(overlap > overlapThresh)[0])))
return boxes[pick].astype("int")
test_model.py(与pyimagesearch目录同级):
作用:测试解决重叠轮廓的边界效果
运行指令:python test_model.py --conf conf/cars.json--image datasets/caltech101/101_ObjectCategories/car_side/image_0004.jpg
from pyimagesearch.object_detection import non_max_suppression
from pyimagesearch.object_detection import ObjectDetector
from pyimagesearch.descriptors import HOG
from pyimagesearch.utils import Conf
import numpy as np
import imutils
import argparse
import cPickle
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True, help="path to the configuration file")
ap.add_argument("-i", "--image", required=True, help="path to the image to be classified")
args = vars(ap.parse_args())
conf = Conf(args["conf"])
model = cPickle.loads(open(conf["classifier_path"]).read())
hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]),
cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"])
od = ObjectDetector(model, hog)
image = cv2.imread(args["image"])
image = imutils.resize(image, width=min(260, image.shape[1]))
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
(boxes, probs) = od.detect(gray, conf["window_dim"], winStep=conf["window_step"],
pyramidScale=conf["pyramid_scale"], minProb=conf["min_probability"])
pick = non_max_suppression(np.array(boxes), probs, conf["overlap_thresh"])
orig = image.copy()
for (startX, startY, endX, endY) in boxes:
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 0, 255), 2)
for (startX, startY, endX, endY) in pick:
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
cv2.imshow("Original", orig)
cv2.imshow("Image", image)
cv2.waitKey(0)
9、坚硬的负面特征采集
作用:训练与需要提取的特征完全不相关的特征,一般是物体的背面场景,所以一般应用sceneclass13数据集,训练负面特征变量,减少误判情况。将负面数据也写入h5py数据库中。
运行指令:python hard_negative_mine.py --conf conf/cars.json
hard_negative_mine.py
from __future__ import print_function
from pyimagesearch.object_detection.objectdetector import ObjectDetector
from pyimagesearch.descriptors.hog import HOG
from pyimagesearch.utils import dataset
from pyimagesearch.utils.conf import Conf
from imutils import paths
import numpy as np
import progressbar
import argparse
import cPickle
import random
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required = True, help = "path to the configuration file")
args = vars(ap.parse_args())
conf =Conf(args["conf"])
data =[]
model =cPickle.loads(open(conf["classifier_path"]).read())
hog =HOG(orientations = conf["orientations"], pixelsPerCell = tuple(conf["pixels_per_cell"]),
cellsPerBlock = tuple(conf["cells_per_block"]), normalize = conf["normalize"])
od = ObjectDetector(model, hog)
dstPaths = list(paths.list_images(conf["image_distractions"]))
dstPaths =random.sample(dstPaths, conf["hn_num_distraction_images"])
widgets = ["Mining:", progressbar.Percentage(), " ", progressbar.Bar(), "", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval = len(dstPaths), widgets = widgets).start()
myindex = 0
for (i, imagePath) in enumerate(dstPaths):
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
(boxes, probs) = od.detect(gray, conf["window_dim"], winStep = conf["hn_window_step"], pyramidScale = conf["hn_pyramid_scale"], minProb = conf["hn_min_probability"])
for (prob, (startX, startY, endX, endY)) in zip(probs, boxes):
roi = cv2.resize(gray[startY:endY, startX:endX], tuple(conf["window_dim"]), interpolation = cv2.INTER_AREA)
features = hog.describe(roi)
data.append(np.hstack([[prob], features]))
pbar.update(i)
pbar.finish()
print("[INFO] sorting by probability...")
data = np.array(data)
data = data[data[:, 0].argsort()[::-1]]
print("[INFO] dmping hard negatives to file...")
dataset.dump_dataset(data[:, 1:], [-1] * len(data), conf["features_path"], "hard_negatives", writeMethod = "a")
10、重新训练对象检测器
作用:将坚硬的负面特征加入到SVM中,减少虚假轮廓的出现
运行指令:python train_model.py --conf conf/cars.json --hard-negatives 1
train_model.py
from __future__ import print_function
from pyimagesearch.utils import dataset
from pyimagesearch.utils.conf import Conf
from sklearn.svm import SVC
import argparse
import pickle
import numpy as np
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required = True, help = "path to the configuration file")
ap.add_argument("-n", "--hard-negatives", type = int, default = -1, help="flag indicating whether or not hard negatives should be used")
args = vars(ap.parse_args())
print("[INFO] loading dataset...")
conf = Conf(args["conf"])
(data, labels) = dataset.load_dataset(conf["features_path"], "features")
if args["hard_negatives"] > 0:
print("[INFO] loading hard negatives...")
(hardData,hardLabels) = dataset.load_dataset(conf["features_path"], "hard_negatives")
data = np.vstack([data, hardData])
labels = np.hstack([labels, hardLabels])
print("[INFO] training classifier...")
model = SVC(kernel = "linear", C = conf["C"], probability = True, random_state = 42)
model.fit(data, labels)
print("[INFO] dumping classifier...")
f = open(conf["classifier_path"], "wb")
f.write(pickle.dumps(model))
f.close()
11、imglab的运用
前期准备工作:生成xml文件,运用imglab生成器,选取特征轮廓。
步骤1:imglab -c 文件夹路径 生成xml文件路径 步骤2:imglab xml文件 手动框选特征区域
作用:将提取图片的边界框,并且将其特征运用svm分类。
运行指令:python train_detector.py --xml face_detector/faces_annotations.xml --detector face_detector/detector.svm
from __future__ import print_function
import argparse
import dlib
ap = argparse.ArgumentParser()
ap.add_argument("-x", "--xml", required = True, help = "path to input XML file")
ap.add_argument("-d", "--detector", required = True, help = "path to output director")
args = vars(ap.parse_args())
print("[INFO] training detector....")
options = dlib.simple_object_detector_training_options()
options.C = 1.0
options.num_threads = 4
options.bei_verbose = True
dlib.train_simple_object_detector(args["xml"], args["detector"], options)
print("[INFO] training accuracy:{}".format(dlib.test_simple_object_detector(args["xml"], args["detector"])))
detector = dlib.simple_object_detector(args["detector"])
win = dlib.image_window()
win.set_image(detector)
dlib.hit_enter_to_continue()
test_detector.py
作用:测试训练出来SVM线性向量
运行指令:python test_detector.py --detector face_detector/detector.svm--testing face_detector/testing
from imutils import paths
import argparse
import dlib
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--detector", required = True, help = "Path to train object detector")
ap.add_argument("-t", "--testing", required = True, help = "Path to directory of testing images")
args = vars(ap.parse_args())
detector = dlib.simple_object_detector(args["detector"])
for testingPath in paths.list_images(args["testing"]):
image = cv2.imread(testingPath)
boxes = detector(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
for b in boxes:
(x, y, w, h) = (b.left(), b.top(), b.right(), b.bottom())
cv2.rectangle(image, (x, y), (w, h), (0, 255, 0), 2)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)