Mysql----基础
一 数据库是什么
之前所学,数据要永久保存,比如用户注册的用户信息,都是保存于文件中,而文件只能存在于某一台机器上。
如果我们不考虑从文件中读取数据的效率问题,并且假设我们的程序所有的组件都运行在一台机器上,那么用文件存取数据,并没有问题
但需要考虑的问题是:程序的执行效率依赖于承载它的硬件,而一台机器机器的性能总归是有限的,受限于目前的硬件水平,垂直扩展是有极限的。于是我们只能通过水平扩展来增强我们系统的整体性能,这就需要我们将程序的各个组件分布于多台机器去执行。
需要注意的是,虽然我们将程序的各个组件分布到各台机器,但各组件仍然是一个整体,言外之意,所有组件的数据还是要共享的。但每台机器上的组件都只能操作本机的文件,这就导致了数据必然不一致。
于是我们想到了将数据与应用程序分离:把文件存放于一台机器,然后将多台机器通过网络去访问这台机器上的文件,即共享这台机器上的文件,共享则意味着竞争,会发生数据不安全,需要加锁处理。。。。
为了远程访问并处理这台共享机器上的文件,我们必须为我们的程序额外写一段代码,完成如下功能:
#1.远程连接 #2.打开文件 #3.读写(加锁) #4.关闭文件
我们写任何程序都需要有这段代码,于是我们提取这段代码,写成一个专门的处理软件,这就是mysql等数据库管理软件的由来,但mysql解决的不仅仅是数据共享的问题,还有查询效率,安全性等一系列问题,总之,把程序员从数据管理中解脱出来,专注于自己的程序逻辑的编写。
二 数据库概述
1 什么是数据(Data)
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字、图片,图像、声音、语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机
在计算机中描述一个事物,就需要抽取这一事物的典型特征,组成一条记录,就相当于文件里的一行内容,如:
1 egon,male,18,1999,山东,计算机系,2017,oldboy
单纯的一条记录并没有任何意义,如果我们按逗号作为分隔,依次定义各个字段的意思
1 name,sex,age,birth,born_addr,major,entrance_time,school #字段 2 egon,male,18,1999,山东,计算机系,2017,oldboy #记录
这样我们就可以了解egon,性别为男,年龄18岁,出生于1999年,出生地为山东,2017年考入老男孩计算机系
2 什么是数据库(DataBase,简称DB)
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的
过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用
数据库是长期存放在计算机内、有组织、可共享的数据即可。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种 用户共享
3 什么是数据库管理系统(DataBase Management System 简称DBMS)
在了解了Data与DB的概念后,如何科学地组织和存储数据,如何高效获取和维护数据成了关键
这就用到了一个系统软件---数据库管理系统
如MySQL、Oracle、SQLite、Access、MS SQL Server
mysql主要用于大型门户,例如搜狗、新浪等,它主要的优势就是开放源代码,因为开放源代码这个数据库是免费的,他现在是甲骨文公司的产品。
oracle主要用于银行、铁路、飞机场等。该数据库功能强大,软件费用高。也是甲骨文公司的产品。
sql server是微软公司的产品,主要应用于大中型企业,如联想、方正等。
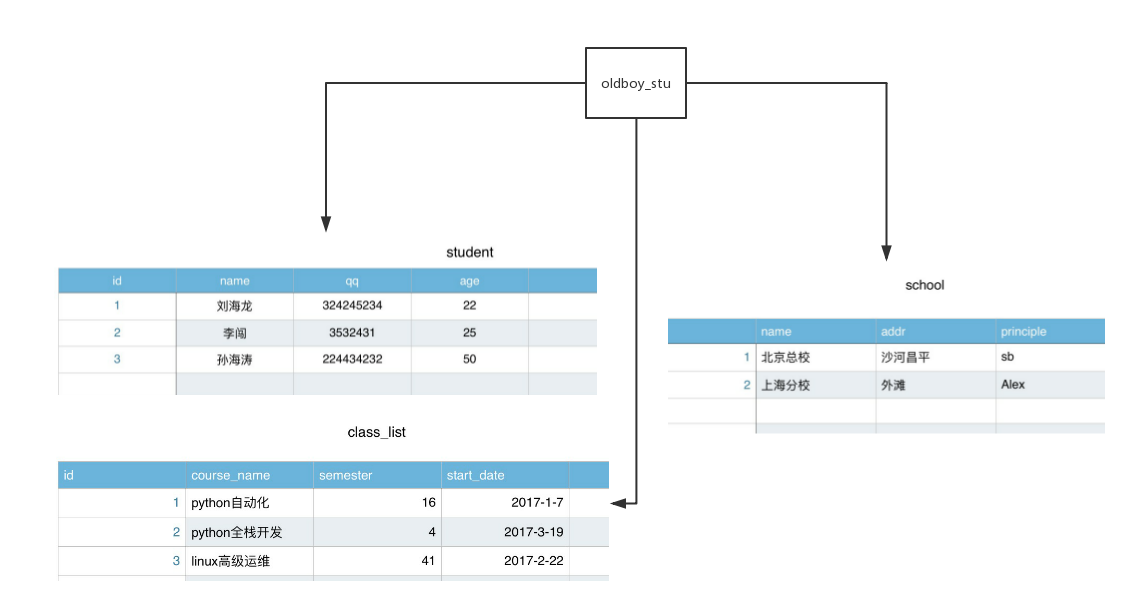
4 数据库服务器、数据管理系统、数据库、表与记录的关系(重点理解!!!)
记录:1 刘海龙 324245234 22(多个字段的信息组成一条记录,即文件中的一行内容)
表:student,scholl,class_list(即文件)
数据库:oldboy_stu(即文件夹)
数据库管理系统:如mysql(是一个软件)
数据库服务器:一台计算机(对内存要求比较高)
总结:
数据库服务器---运行--->数据库管理软件
数据库管理软件--->管理--->数据库
数据库---组织--->表,即文件夹---组织--->文件
表---存放--->多条记录,即文件---存放--->多行内容
5 数据库管理技术的发展历程(了解)
一 人工管理阶段
20世纪50年代中期以前,计算机主要用于科学计算。
当时的硬件水平:外存只有纸带、卡片、磁带,没有磁盘等直接存取的存储设备
当时的软件状况:没有操作系统,没有管理数据的软件,数据的处理方式是批处理。
人工管理数据具有以下特点:
1 数据不保存:计算机主要用于科学计算,数据临时用,临时输入,不保存
2 应用程序管理数据:数据要有应用程序自己管理,应用程序需要处理数据的逻辑+物理结构,开发负担很重
3 数据不共享:一组数据只对应一个程序,多个程序之间涉及相同数据时,必须各自定义,造成数据大量冗余
4 数据不具有独立性:数据的逻辑结构或物理结构发生变化后,必须对应用程序做出相应的修改,开发负担进一步加大

二 文件系统阶段
20世纪50年代后期到60年代中期
硬件水平:有了磁盘、磁鼓等可直接存取的存储设备
软件水平:有了操作系统,并且操作系统中已经有了专门的数据管理软件,即文件系统;处理方式上不仅有了批处理,而且能够联机实时处理
文件系统管理数据具有以下优点:
1 数据可以长期保存:计算机大量用于数据处理,因而数据需要长期保存,进行增删改查操作
2 由文件系统管理数据:文件系统这个软件,把数据组织成相对独立的数据文件,利用按文件名,按记录进行存取。实现了记录内的结构性,但整体无结构。并且程序与数据之间由文件系统提供存取方法进行转换,是应用程序与数据之间有了一定的独立性,程序员可以不必过多考虑物理细节。
文件系统管理数据具有以下缺点:
1 数据共享性差,冗余度大:一个文件对应一个应用程序,不同应用有相同数据时,也必须建立各自的文件,不能共享相同的数据,造成数据冗余,浪费空间,且相同的数据重复存储,各自管理,容易造成数据不一致性
2 数据独立性差:一旦数据的逻辑结构改变,必须修改应用程序,修改文件结构的定义。应用程序的改变,也将引起文件的数据结构的改变。因此数据与程序之间缺乏独立性。可见,文件系统仍然是一个不具有弹性的无结构的数据集合,即文件之间是孤立的,不能反映现实世界事物之间的内存联系。

三 数据系统阶段
20世纪60年代后期以来,计算机用于管理的规模越来越大,应用越来越广泛,数据量急剧增长,同时多种应用,多种语言互相覆盖地共享数据结合要求越来越强烈
硬件水平:有了大容量磁盘,硬件架构下降
软件水平:软件价格上升(开发效率必须提升,必须将程序员从数据管理中解放出来),分布式的概念盛行。
数据库系统的特点:
1 数据结构化(如上图odboy_stu)
2 数据共享,冗余度低,易扩充
3 数据独立性高
4 数据由DBMS统一管理和控制
a:数据的安全性保护
b:数据的完整性检查
c:并发控制
d:数据库恢复
三 mysql介绍
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
mysql是什么???
mysql就是一个socekt服务端
客户端软件
mysql自带
python模块
其他类型的数据库???
sqllite,db2,oracle,access,sql server,MySQL
分两大类:
关系型:上面这一坨,注意:sql语句通用
非关系型:mongodb,redis,memcache
四 下载安装
Linux版本
#二进制rpm包安装 yum -y install mysql-server mysql
(1)
1.解压tar包 cd /software tar -xzvf mysql-5.6.21-linux-glibc2.5-x86_64.tar.gz mv mysql-5.6.21-linux-glibc2.5-x86_64 mysql-5.6.21 2.添加用户与组 groupadd mysql useradd -r -g mysql mysql chown -R mysql:mysql mysql-5.6.21 3.安装数据库 su mysql cd mysql-5.6.21/scripts ./mysql_install_db --user=mysql --basedir=/software/mysql-5.6.21 --datadir=/software/mysql-5.6.21/data 4.配置文件 cd /software/mysql-5.6.21/support-files cp my-default.cnf /etc/my.cnf cp mysql.server /etc/init.d/mysql vim /etc/init.d/mysql #若mysql的安装目录是/usr/local/mysql,则可省略此步 修改文件中的两个变更值 basedir=/software/mysql-5.6.21 datadir=/software/mysql-5.6.21/data 5.配置环境变量 vim /etc/profile export MYSQL_HOME="/software/mysql-5.6.21" export PATH="$PATH:$MYSQL_HOME/bin" source /etc/profile 6.添加自启动服务 chkconfig --add mysql chkconfig mysql on 7.启动mysql service mysql start 8.登录mysql及改密码与配置远程访问 mysqladmin -u root password 'your_password' #修改root用户密码 mysql -u root -p #登录mysql,需要输入密码 mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'your_password' WITH GRANT OPTION; #允许root用户远程访问 mysql>FLUSH PRIVILEGES; #刷新权限
(2)
1. 解压 tar zxvf mariadb-5.5.31-linux-x86_64.tar.gz mv mariadb-5.5.31-linux-x86_64 /usr/local/mysql //必需这样,很多脚本或可执行程序都会直接访问这个目录 2. 权限 groupadd mysql //增加 mysql 属组 useradd -g mysql mysql //增加 mysql 用户 并归于mysql 属组 chown mysql:mysql -Rf /usr/local/mysql // 设置 mysql 目录的用户及用户组归属。 chmod +x -Rf /usr/local/mysql //赐予可执行权限 3. 拷贝配置文件 cp /usr/local/mysql/support-files/my-medium.cnf /etc/my.cnf //复制默认mysql配置 文件到/etc目录 4. 初始化 /usr/local/mysql/scripts/mysql_install_db --user=mysql //初始化数据库 cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql //复制mysql服务程序 到系统目录 chkconfig mysql on //添加mysql 至系统服务并设置为开机启动 service mysql start //启动mysql 5. 环境变量配置 vim /etc/profile //编辑profile,将mysql的可执行路径加入系统PATH export PATH=/usr/local/mysql/bin:$PATH source /etc/profile //使PATH生效。 6. 账号密码 mysqladmin -u root password 'yourpassword' //设定root账号及密码 mysql -u root -p //使用root用户登录mysql use mysql //切换至mysql数据库。 select user,host,password from user; //查看系统权限 drop user ''@'localhost'; //删除不安全的账户 drop user root@'::1'; drop user root@127.0.0.1; select user,host,password from user; //再次查看系统权限,确保不安全的账户均被删除。 flush privileges; //刷新权限 7. 一些必要的初始配置 1)修改字符集为UTF8 vi /etc/my.cnf 在[client]下面添加 default-character-set = utf8 在[mysqld]下面添加 character_set_server = utf8 2)增加错误日志 vi /etc/my.cnf 在[mysqld]下面添加: log-error = /usr/local/mysql/log/error.log general-log-file = /usr/local/mysql/log/mysql.log 3) 设置为不区分大小写,linux下默认会区分大小写。 vi /etc/my.cnf 在[mysqld]下面添加: lower_case_table_name=1 修改完重启:#service mysql restart
Window版本
1、下载
|
1
2
3
|
MySQL Community Server 5.7.16http://dev.mysql.com/downloads/mysql/ |
2、解压
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\mysql-5.7.16-winx64
3、初始化
MySQL解压后的 bin 目录下有一大堆的可执行文件,执行如下命令初始化数据:
|
1
2
3
|
cd c:\mysql-5.7.16-winx64\binmysqld --initialize-insecure |
4、启动MySQL服务
执行命令从而启动MySQL服务
|
1
2
3
4
5
|
# 进入可执行文件目录cd c:\mysql-5.7.16-winx64\bin# 启动MySQL服务mysqld |
5、启动MySQL客户端并连接MySQL服务
由于初始化时使用的【mysqld --initialize-insecure】命令,其默认未给root账户设置密码
|
1
2
3
4
5
6
7
|
# 进入可执行文件目录cd c:\mysql-5.7.16-winx64\bin# 连接MySQL服务器mysql -u root -p# 提示请输入密码,直接回车 |
输入回车,见下图表示安装成功:

到此为止,MySQL服务端已经安装成功并且客户端已经可以连接上,以后再操作MySQL时,只需要重复上述4、5步骤即可。但是,在4、5步骤中重复的进入可执行文件目录比较繁琐,如想日后操作简便,可以做如下操作。
a. 添加环境变量
将MySQL可执行文件添加到环境变量中,从而执行执行命令即可
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】--> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】如:C:\Program Files (x86)\Parallels\Parallels Tools\Applications;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;C:\Python27;C:\Python35;C:\mysql-5.7.16-winx64\bin如此一来,以后再启动服务并连接时,仅需:
# 启动MySQL服务,在终端输入mysqld# 连接MySQL服务,在终端输入:mysql-u root-pb. 将MySQL服务制作成windows服务
上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题:
注意:--install前,必须用mysql启动命令的绝对路径
# 制作MySQL的Windows服务,在终端执行此命令:"c:\mysql-5.7.16-winx64\bin\mysqld"--install# 移除MySQL的Windows服务,在终端执行此命令:"c:\mysql-5.7.16-winx64\bin\mysqld"--remove注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
# 启动MySQL服务net start mysql# 关闭MySQL服务net stop mysql

五 mysql软件基本管理
1. 启动查看

[root@egon ~]# systemctl start mariadb #启动 [root@egon ~]# systemctl enable mariadb #设置开机自启动 Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service. [root@egon ~]# ps aux |grep mysqld |grep -v grep #查看进程,mysqld_safe为启动mysql的脚本文件,内部调用mysqld命令 mysql 3329 0.0 0.0 113252 1592 ? Ss 16:19 0:00 /bin/sh /usr/bin/mysqld_safe --basedir=/usr mysql 3488 0.0 2.3 839276 90380 ? Sl 16:19 0:00 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mariadb/mariadb.log --pid-file=/var/run/mariadb/mariadb.pid --socket=/var/lib/mysql/mysql.sock [root@egon ~]# netstat -an |grep 3306 #查看端口 tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN [root@egon ~]# ll -d /var/lib/mysql #权限不对,启动不成功,注意user和group drwxr-xr-x 5 mysql mysql 4096 Jul 20 16:28 /var/lib/mysql
安装完mysql 之后,登陆以后,不管运行任何命令,总是提示这个 mac mysql error You must reset your password using ALTER USER statement before executing this statement. 解决方法: step 1: SET PASSWORD = PASSWORD('your new password'); step 2: ALTER USER 'root'@'localhost' PASSWORD EXPIRE NEVER; step 3: flush privileges;
2. 登录,设置密码
初始状态下,管理员root,密码为空,默认只允许从本机登录localhost 设置密码 [root@egon ~]# mysqladmin -uroot password "123" 设置初始密码 由于原密码为空,因此-p可以不用 [root@egon ~]# mysqladmin -uroot -p"123" password "456" 修改mysql密码,因为已经有密码了,所以必须输入原密码才能设置新密码 命令格式: [root@egon ~]# mysql -h172.31.0.2 -uroot -p456 [root@egon ~]# mysql -uroot -p [root@egon ~]# mysql 以root用户登录本机,密码为空
3. 忘记密码
方法一:删除授权库mysql,重新初始化
[root@egon ~]# rm -rf /var/lib/mysql/mysql #所有授权信息全部丢失!!! [root@egon ~]# systemctl restart mariadb [root@egon ~]# mysql
方法二:启动时,跳过授权库
[root@egon ~]# vim /etc/my.cnf #mysql主配置文件
[mysqld]
skip-grant-table
[root@egon ~]# systemctl restart mariadb
[root@egon ~]# mysql
MariaDB [(none)]> update mysql.user set password=password("123") where user="root" and host="localhost";
MariaDB [(none)]> flush privileges;
MariaDB [(none)]> \q
[root@egon ~]# #打开/etc/my.cnf去掉skip-grant-table,然后重启
[root@egon ~]# systemctl restart mariadb
[root@egon ~]# mysql -u root -p123 #以新密码登录
windows平台下,5.7版本mysql,破解密码的两种方式:
关闭mysql #2 在cmd中执行:mysqld --skip-grant-tables #3 在cmd中执行:mysql #4 执行如下sql: update mysql.user set authentication_string=password('') where user = 'root'; flush privileges; #5 tskill mysqld #6 重新启动mysql
#1. 关闭mysql,可以用tskill mysqld将其杀死 #2. 在解压目录下,新建mysql配置文件my.ini #3. my.ini内容,指定 [mysqld] skip-grant-tables #4.启动mysqld #5.在cmd里直接输入mysql登录,然后操作 update mysql.user set authentication_string=password('') where user='root and host='localhost'; flush privileges; #6.注释my.ini中的skip-grant-tables,然后启动myqsld,然后就可以以新密码登录了
4. 在windows下,为mysql服务指定配置文件
#在mysql的解压目录下,新建my.ini,然后配置 #1. 在执行mysqld命令时,下列配置会生效,即mysql服务启动时生效 [mysqld] ;skip-grant-tables port=3306 character_set_server=utf8 #解压的目录 basedir=E:\mysql-5.7.19-winx64 #data目录 datadir=E:\my_data #在mysqld --initialize时,就会将初始数据存入此处指定的目录,在初始化之后,启动mysql时,就会去这个目录里找数据 #2. 针对客户端命令的全局配置,当mysql客户端命令执行时,下列配置生效 [client] port=3306 default-character-set=utf8 user=root password=123 #3. 只针对mysql这个客户端的配置,2中的是全局配置,而此处的则是只针对mysql这个命令的局部配置 [mysql] ;port=3306 ;default-character-set=utf8 user=egon password=4573 #!!!如果没有[mysql],则用户在执行mysql命令时的配置以[client]为准
六 初识sql语句
有了mysql这个数据库软件,就可以将程序员从对数据的管理中解脱出来,专注于对程序逻辑的编写
mysql服务端软件即mysqld帮我们管理好文件夹以及文件,前提是作为使用者的我们,需要下载mysql的客户端,或者其他模块来连接到mysqld,然后使用mysql软件规定的语法格式去提交自己命令,实现对文件夹或文件的管理。该语法即sql语句
#1. 操作文件夹 增:create database db1 charset utf8; 查:show databases; 改:alter database db1 charset latin1; 删除: drop database db1; #2. 操作文件 先切换到文件夹下:use db1 增:create table t1(id int,name char); 查:show tables 改:alter table t1 modify name char(3); alter table t1 change name name1 char(2); 删:drop table t1; #3. 操作文件中的内容/记录 增:insert into t1 values(1,'egon1'),(2,'egon2'),(3,'egon3'); 查:select * from t1; 改:update t1 set name='sb' where id=2; 删:delete from t1 where id=1; 清空表: delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。 truncate table t1;数据量大,删除速度比上一条快,且直接从零开始, auto_increment 表示:自增 primary key 表示:约束(不能重复且不能为空);加速查找
七 初识授权
#授权表 user #该表放行的权限,针对:所有数据,所有库下所有表,以及表下的所有字段 db #该表放行的权限,针对:某一数据库,该数据库下的所有表,以及表下的所有字段 tables_priv #该表放行的权限。针对:某一张表,以及该表下的所有字段 columns_priv #该表放行的权限,针对:某一个字段 #按图解释: user:放行db1,db2及其包含的所有 db:放行db1,及其db1包含的所有 tables_priv:放行db1.table1,及其该表包含的所有 columns_prive:放行db1.table1.column1,只放行该字段
权限操作;
#创建用户 create user 'egon'@'1.1.1.1' identified by '123'; create user 'egon'@'192.168.1.%' identified by '123'; create user 'egon'@'%' identified by '123'; #授权:对文件夹,对文件,对文件某一字段的权限 查看帮助:help grant 常用权限有:select,update,alter,delete all可以代表除了grant之外的所有权限 #针对所有库的授权:*.* grant select on *.* to 'egon1'@'localhost' identified by '123'; #只在user表中可以查到egon1用户的select权限被设置为Y #针对某一数据库:db1.* grant select on db1.* to 'egon2'@'%' identified by '123'; #只在db表中可以查到egon2用户的select权限被设置为Y #针对某一个表:db1.t1 grant select on db1.t1 to 'egon3'@'%' identified by '123'; #只在tables_priv表中可以查到egon3用户的select权限 #针对某一个字段: mysql> select * from t3; +------+-------+------+ | id | name | age | +------+-------+------+ | 1 | egon1 | 18 | | 2 | egon2 | 19 | | 3 | egon3 | 29 | +------+-------+------+ grant select (id,name),update (age) on db1.t3 to 'egon4'@'localhost' identified by '123'; #可以在tables_priv和columns_priv中看到相应的权限 mysql> select * from tables_priv where user='egon4'\G *************************** 1. row *************************** Host: localhost Db: db1 User: egon4 Table_name: t3 Grantor: root@localhost Timestamp: 0000-00-00 00:00:00 Table_priv: Column_priv: Select,Update 1 row in set (0.00 sec) mysql> select * from columns_priv where user='egon4'\G *************************** 1. row *************************** Host: localhost Db: db1 User: egon4 Table_name: t3 Column_name: id Timestamp: 0000-00-00 00:00:00 Column_priv: Select *************************** 2. row *************************** Host: localhost Db: db1 User: egon4 Table_name: t3 Column_name: name Timestamp: 0000-00-00 00:00:00 Column_priv: Select *************************** 3. row *************************** Host: localhost Db: db1 User: egon4 Table_name: t3 Column_name: age Timestamp: 0000-00-00 00:00:00 Column_priv: Update 3 rows in set (0.00 sec) #删除权限 revoke select on db1.* to 'alex'@'%';
一 知识储备
MySQL数据库基本操作知识储备
数据库服务器:一台计算机(对内存要求比较高)
数据库管理系统:如mysql,是一个软件
数据库:oldboy_stu,相当于文件夹
表:student,scholl,class_list,相当于一个具体的文件
记录:1 刘海龙 324245234 22,相当于文件中的一行内容
二 初识SQL语言
SQL(Structured Query Language 即结构化查询语言)
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型:
DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT
DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
四 创建数据库
1 语法(help create database)
CREATE DATABASE 数据库名 charset utf8;
2 数据库命名规则:
可以由字母、数字、下划线、@、#、$ 区分大小写 唯一性 不能使用关键字如 create select 不能单独使用数字 最长128位
五 数据库相关操作
1 查看数据库 show databases; show create database db1; select database(); 2 选择数据库 USE 数据库名 3 删除数据库 DORP DATABASE 数据库名; 4 修改数据库 alter database db1 charset utf8;
一 什么是存储引擎
mysql中建立的库===>文件夹
库中建立的表===>文件
现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方
法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和
操作此表的类型)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql
数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据
自己的需要编写自己的存储引擎
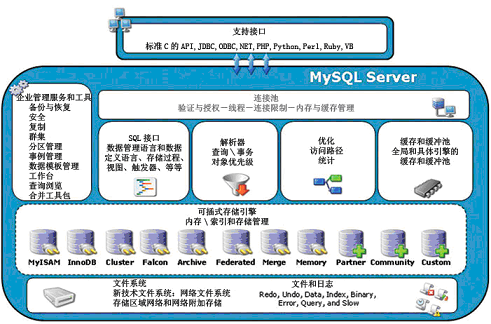
SQL 解析器、SQL 优化器、缓冲池、存储引擎等组件在每个数据库中都存在,但不是每 个数据库都有这么多存储引擎。MySQL 的插件式存储引擎可以让存储引擎层的开发人员设 计他们希望的存储层,例如,有的应用需要满足事务的要求,有的应用则不需要对事务有这 么强的要求 ;有的希望数据能持久存储,有的只希望放在内存中,临时并快速地提供对数据 的查询。
二 mysql支持的存储引擎
MariaDB [(none)]> show engines\G #查看所有支持的存储引擎 MariaDB [(none)]> show variables like 'storage_engine%'; #查看正在使用的存储引擎
MySQL存储引擎介绍
InnoDB 存储引擎 支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其 特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。 InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。 InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。 对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。 InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。 #MyISAM 存储引擎 不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。 #NDB 存储引擎 2003 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。 #Memory 存储引擎 正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。 #Infobright 存储引擎 第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。 #NTSE 存储引擎 网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。 #BLACKHOLE 黑洞存储引擎,可以应用于主备复制中的分发主库。 MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
三 使用存储引擎
方法1:建表时指定
MariaDB [db1]> create table innodb_t1(id int,name char)engine=innodb; MariaDB [db1]> create table innodb_t2(id int)engine=innodb; MariaDB [db1]> show create table innodb_t1; MariaDB [db1]> show create table innodb_t2;
方法2:在配置文件中指定默认的存储引擎
/etc/my.cnf [mysqld] default-storage-engine=INNODB innodb_file_per_table=1
查看
[root@egon db1]# cd /var/lib/mysql/db1/ [root@egon db1]# ls db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd
一 创建表
语法: create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); 注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的

建表
ariaDB [(none)]> create database db1 charset utf8;
MariaDB [(none)]> use db1;
MariaDB [db1]> create table t1(
-> id int,
-> name varchar(50),
-> sex enum('male','female'),
-> age int(3)
-> );
MariaDB [db1]> show tables; #查看db1库下所有表名
MariaDB [db1]> desc t1;
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum('male','female') | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
MariaDB [db1]> select id,name,sex,age from t1;
Empty set (0.00 sec)
MariaDB [db1]> select * from t1;
Empty set (0.00 sec)
MariaDB [db1]> select id,name from t1;
Empty set (0.00 sec)
往表中插数据
MariaDB [db1]> insert into t1 values
-> (1,'egon',18,'male'),
-> (2,'alex',81,'female')
-> ;
MariaDB [db1]> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | egon | 18 | male |
| 2 | alex | 81 | female |
+------+------+------+--------+
MariaDB [db1]> insert into t1(id) values
-> (3),
-> (4);
MariaDB [db1]> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | egon | 18 | male |
| 2 | alex | 81 | female |
| 3 | NULL | NULL | NULL |
| 4 | NULL | NULL | NULL |
+------+------+------+--------+
解决乱码问题
mysql> create database db1 charset latin1;
mysql> use db1;
mysql> create table t1(name varchar(20));
mysql> show create table t1; #查看表,发现表默认与数据db1的字符编码一致
mysql> insert into t1 values('林'); #插入中文出错,因为latin1不支持中文
ERROR 1366 (HY000):
mysql>
#解决方法一:删除库db1,重建db1,字符编码指定为utf8
#解决方法二:修改
mysql> alter table t1 charset utf8; #修改表t1的编码
mysql> insert into t1 values('林'); #虽然t1的编码改了,但是t1的字段name仍然是按照latin1编码创建的
ERROR 1366 (HY000):
mysql> alter table t1 modify name varchar(20); #需要重新定义下字段name
mysql> insert into t1 values('林');
mysql> select * from t1;
+------+
| name |
+------+
| 林 |
+------+
ps:不要忘记将数据库编码也改成utf8,这样以后在该数据库下创建表时,都默认utf8编码了
配置文件解决乱码问题
#1. 修改配置文件
[mysqld]
default-character-set=utf8
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
#mysql5.5以上:修改方式有所改动
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
#2. 重启服务
#3. 查看修改结果:
\s
show variables like '%char%'
二 查看表结构
MariaDB [db1]> describe t1; #查看表结构,可简写为desc 表名
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum('male','female') | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
MariaDB [db1]> show create table t1\G; #查看表详细结构,可加\
数据类型:
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己 的宽度,但宽度是可选的。
1:数字:整型:tinyint int bigint
(1)create table t1(id tinyint);
(2)create table t2(id int);
(3)create table t3(id bigint);
浮点型:float:在位数比较短的情况下使用。----不精确
double:在位数比较长的情况下使用。----不精确
decimal:推荐使用---精确
#浮点型测试
0.1231233123412 3123213123123123
float:0.1231233123412 0000000000000000
double:0.1231233123412 3123213123100000
decimal:
#测试
create table t4(salary float(5,2));
insert into t4 values (3.73555);
insert into t4 values (-3.73555);
insert into t4 values (-1111.73555);
insert into t4 values (-111.73555);
2:字符串:
char():浪费空间,存取速度快。
varchar:精准,节省空间,存取速度慢。
char与varchar测试()
create table t6(name char(4));
insert into t6 values('alexsb');
insert into t6 values('欧德博爱');
insert into t6 values('艾利克斯a');
create table t7(x char(5),y varchar(5));
#insert into t7 values('abcdef','abc');
#insert into t7 values('abc','abc');
#insert into t7 values('abc','abcdef');
insert into t7 values('abc','abc'); #char_length :查看字符的长度
insert into t7 values('你好啊','好你妹'); #char_length :查看字符的长度
#了解
insert into t7 values('你好啊','好你妹'); #length:查看字节的长度
#注意两点:
insert into t7 values('abc ','abc '); #length:查看字节的长度
select * from t7 where y='abc '; #去掉末尾的空格然后去比较
3:日期类型:
datetime: 2017-09-06 10:39:49---年月日时分秒
data:2017-09-06 ----年月日
time:10:39:49 ----时间
year:2017----年
日期类型
create table student(
id int,
name char(5),
born_date date,
born_year year,
reg_time datetime,
class_time time
);
insert into student values(1,'alex',now(),now(),now(),now());
insert into student values(1,'alex','2017-09-06','2017','2017-09-06 10:39:00','08:30:00');
#了解
insert into student values(1,'alex','2017-09-06',2017,'2017-09-06 10:39:00','08:30:00');
insert into student values(1,'alex','2017/09/06',2017,'2017-09-06 10:39:00','08:30:00');
insert into student values(1,'alex','20170906',2017,'20170906103900','083000');
4:枚举与集合:
enum:枚举----规定一个范围,可有多个值,但是为该字段传值时只能取给字段范围的一个。
例如:性别
set :集合---- 规定一个范围,可有多个值,但是为该字段传值时只能取给字段范围的多个。
枚举与集合
create table student1(
id int primary key auto_increment,
name char(5),
sex enum('male','female'),
hobbies set('music','read','study','coding')
);
insert into student1(name,sex,hobbies) values('egon','None','asdfasdfasdf');
insert into student1(name,sex,hobbies) values('egon','male','music,read');
表的完整性约束:
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
primary key(PK)-------标识该字段为该表的主键,可以唯一的标识记录。(不为0,且为1)
foreign key(fk)--------标识该字段为该表的外键;
not null--------------标识该字段
UNIQUE KEY (UK) ---------------标识该字段的值是唯一的
AUTO_INCREMENT ----------------标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT------------------------------ 为该字段设置默认值
UNSIGNED---------------------------- 无符号
ZEROFILL------------------------------ 使用0填充
一 介绍
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录 FOREIGN KEY (FK) 标识该字段为该表的外键 NOT NULL 标识该字段不能为空 UNIQUE KEY (UK) 标识该字段的值是唯一的 AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键) DEFAULT 为该字段设置默认值 UNSIGNED 无符号 ZEROFILL 使用0填充
说明:
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值
2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值
sex enum('male','female') not null default 'male'
age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20
3. 是否是key
主键 primary key
外键 foreign key
索引 (index,unique...)
二 not null与default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1(
nid int not null defalut 2,
num int not null
)
==================not null====================
mysql> create table t1(id int); #id字段默认可以插入空
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t1 values(); #可以插入空
mysql> create table t2(id int not null); #设置字段id不为空
mysql> desc t2;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t2 values(); #不能插入空
ERROR 1364 (HY000): Field 'id' doesn't have a default value
==================default====================
#设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
mysql> create table t3(id int default 1);
mysql> alter table t3 modify id int not null default 1;
==================综合练习====================
mysql> create table student(
-> name varchar(20) not null,
-> age int(3) unsigned not null default 18,
-> sex enum('male','female') default 'male',
-> hobby set('play','study','read','music') default 'play,music'
-> );
mysql> desc student;
+-------+------------------------------------+------+-----+------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------------------------+------+-----+------------+-------+
| name | varchar(20) | NO | | NULL | |
| age | int(3) unsigned | NO | | 18 | |
| sex | enum('male','female') | YES | | male | |
| hobby | set('play','study','read','music') | YES | | play,music | |
+-------+------------------------------------+------+-----+------------+-------+
mysql> insert into student(name) values('egon');
mysql> select * from student;
+------+-----+------+------------+
| name | age | sex | hobby |
+------+-----+------+------------+
| egon | 18 | male | play,music |
三 unique
============设置唯一约束 UNIQUE===============
方法一:
create table department1(
id int,
name varchar(20) unique,
comment varchar(100)
);
方法二:
create table department2(
id int,
name varchar(20),
comment varchar(100),
constraint uk_name unique(name)
);
mysql> insert into department1 values(1,'IT','技术');
Query OK, 1 row affected (0.00 sec)
mysql> insert into department1 values(1,'IT','技术');
ERROR 1062 (23000): Duplicate entry 'IT' for key 'name'
复制代码
复制代码
mysql> create table t1(id int not null unique);
Query OK, 0 rows affected (0.02 sec)
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.00 sec)
复制代码
复制代码
create table service(
id int primary key auto_increment,
name varchar(20),
host varchar(15) not null,
port int not null,
unique(host,port) #联合唯一
);
mysql> insert into service values
-> (1,'nginx','192.168.0.10',80),
-> (2,'haproxy','192.168.0.20',80),
-> (3,'mysql','192.168.0.30',3306)
-> ;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into service(name,host,port) values('nginx','192.168.0.10',80);
ERROR 1062 (23000): Duplicate entry '192.168.0.10-80' for key 'host'
四 primary key
primary key字段的值不为空且唯一
一个表中可以:
单列做主键
多列做主键(复合主键)
但一个表内只能有一个主键primary key
============单列做主键=============== #方法一:not null+unique create table department1( id int not null unique, #主键 name varchar(20) not null unique, comment varchar(100) ); mysql> desc department1; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | NO | UNI | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec) #方法二:在某一个字段后用primary key create table department2( id int primary key, #主键 name varchar(20), comment varchar(100) ); mysql> desc department2; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.00 sec) #方法三:在所有字段后单独定义primary key create table department3( id int, name varchar(20), comment varchar(100), constraint pk_name primary key(id); #创建主键并为其命名pk_name mysql> desc department3; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec)
==================多列做主键================
create table service(
ip varchar(15),
port char(5),
service_name varchar(10) not null,
primary key(ip,port)
);
mysql> desc service;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| ip | varchar(15) | NO | PRI | NULL | |
| port | char(5) | NO | PRI | NULL | |
| service_name | varchar(10) | NO | | NULL | |
+--------------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> insert into service values
-> ('172.16.45.10','3306','mysqld'),
-> ('172.16.45.11','3306','mariadb')
-> ;
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into service values ('172.16.45.10','3306','nginx');
ERROR 1062 (23000): Duplicate entry '172.16.45.10-3306' for key 'PRIMARY'
五 auto_increment
约束字段为自动增长,被约束的字段必须同时被key约束
#不指定id,则自动增长
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
);
mysql> desc student;
+-------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | YES | | male | |
+-------+-----------------------+------+-----+---------+----------------+
mysql> insert into student(name) values
-> ('egon'),
-> ('alex')
-> ;
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
| 2 | alex | male |
+----+------+------+
#也可以指定id
mysql> insert into student values(4,'asb','female');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(7,'wsb','female');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+--------+
| id | name | sex |
+----+------+--------+
| 1 | egon | male |
| 2 | alex | male |
| 4 | asb | female |
| 7 | wsb | female |
+----+------+--------+
#对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
mysql> delete from student;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> insert into student(name) values('ysb');
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 8 | ysb | male |
+----+------+------+
#应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(name) values('egon');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
+----+------+------+
1 row in set (0.00 sec)
mysql> create table student( -> id int primary key auto_increment, -> name varchar(20), -> sex enum('male','female') default 'male' -> ); mysql> alter table student auto_increment=3; mysql> show create table student; ....... ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 mysql> insert into student(name) values('egon'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 3 | egon | male | +----+------+------+ row in set (0.00 sec) mysql> show create table student; ....... ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 #也可以创建表时指定auto_increment的初始值,注意初始值的设置为表选项,应该放到括号外 create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' )auto_increment=3; #设置步长 sqlserver:自增步长 基于表级别 create table t1( id int。。。 )engine=innodb,auto_increment=2 步长=2 default charset=utf8 mysql自增的步长: show session variables like 'auto_inc%'; #基于会话级别 set session auth_increment_increment=2 #修改会话级别的步长 #基于全局级别的 set global auth_increment_increment=2 #修改全局级别的步长(所有会话都生效) #!!!注意了注意了注意了!!! If the value of auto_increment_offset is greater than that of auto_increment_increment, the value of auto_increment_offset is ignored. 翻译:如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略 比如:设置auto_increment_offset=3,auto_increment_increment=2 mysql> set global auto_increment_increment=5; Query OK, 0 rows affected (0.00 sec) mysql> set global auto_increment_offset=3; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'auto_incre%'; #需要退出重新登录 +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' ); mysql> insert into student(name) values('egon1'),('egon2'),('egon3'); mysql> select * from student; +----+-------+------+ | id | name | sex | +----+-------+------+ | 3 | egon1 | male | | 8 | egon2 | male | | 13 | egon3 | male | +----+-------+------+
六 foreign key
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
解决方法:
我们完全可以定义一个部门表
然后让员工信息表关联该表,如何关联,即foreign key
#表类型必须是innodb存储引擎,且被关联的字段,即references指定的另外一个表的字段,必须保证唯一 create table department( id int primary key, name varchar(20) not null )engine=innodb; #dpt_id外键,关联父表(department主键id),同步更新,同步删除 create table employee( id int primary key, name varchar(20) not null, dpt_id int, constraint fk_name foreign key(dpt_id) references department(id) on delete cascade on update cascade )engine=innodb; #先往父表department中插入记录 insert into department values (1,'欧德博爱技术有限事业部'), (2,'艾利克斯人力资源部'), (3,'销售部'); #再往子表employee中插入记录 insert into employee values (1,'egon',1), (2,'alex1',2), (3,'alex2',2), (4,'alex3',2), (5,'李坦克',3), (6,'刘飞机',3), (7,'张火箭',3), (8,'林子弹',3), (9,'加特林',3) ; #删父表department,子表employee中对应的记录跟着删 mysql> delete from department where id=3; mysql> select * from employee; +----+-------+--------+ | id | name | dpt_id | +----+-------+--------+ | 1 | egon | 1 | | 2 | alex1 | 2 | | 3 | alex2 | 2 | | 4 | alex3 | 2 | +----+-------+--------+ #更新父表department,子表employee中对应的记录跟着改 mysql> update department set id=22222 where id=2; mysql> select * from employee; +----+-------+--------+ | id | name | dpt_id | +----+-------+--------+ | 1 | egon | 1 | | 3 | alex2 | 22222 | | 4 | alex3 | 22222 | | 5 | alex1 | 22222 | +----+-------+--------
1 foreign key 表2
则表1的多条记录对应表2的一条记录,即多对一
利用foreign key的原理我们可以制作两张表的多对多,一对一关系
多对多:
表1的多条记录可以对应表2的一条记录
表2的多条记录也可以对应表1的一条记录
一对一:
表1的一条记录唯一对应表2的一条记录,反之亦然
分析时,我们先从按照上面的基本原理去套,然后再翻译成真实的意义,就很好理解了
#一对多或称为多对一 三张表:出版社,作者信息,书 一对多(或多对一):一个出版社可以出版多本书 关联方式:foreign key
=====================多对一=====================
create table press(
id int primary key auto_increment,
name varchar(20)
);
create table book(
id int primary key auto_increment,
name varchar(20),
press_id int not null,
foreign key(press_id) references press(id)
on delete cascade
on update cascade
);
insert into press(name) values
('北京工业地雷出版社'),
('人民音乐不好听出版社'),
('知识产权没有用出版社')
;
insert into book(name,press_id) values
('九阳神功',1),
('九阴真经',2),
('九阴白骨爪',2),
('独孤九剑',3),
('降龙十巴掌',2),
('葵花宝典',3)
;
#多对多 三张表:出版社,作者信息,书 多对多:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多 关联方式:foreign key+一张新的表
=====================多对多=====================
create table author(
id int primary key auto_increment,
name varchar(20)
);
#这张表就存放作者表与书表的关系,即查询二者的关系查这表就可以了
create table author2book(
id int not null unique auto_increment,
author_id int not null,
book_id int not null,
constraint fk_author foreign key(author_id) references author(id)
on delete cascade
on update cascade,
constraint fk_book foreign key(book_id) references book(id)
on delete cascade
on update cascade,
primary key(author_id,book_id)
);
#插入四个作者,id依次排开
insert into author(name) values('egon'),('alex'),('yuanhao'),('wpq');
#每个作者与自己的代表作如下
1 egon:
1 九阳神功
2 九阴真经
3 九阴白骨爪
4 独孤九剑
5 降龙十巴掌
6 葵花宝典
2 alex:
1 九阳神功
6 葵花宝典
3 yuanhao:
4 独孤九剑
5 降龙十巴掌
6 葵花宝典
4 wpq:
1 九阳神功
insert into author2book(author_id,book_id) values
(1,1),
(1,2),
(1,3),
(1,4),
(1,5),
(1,6),
(2,1),
(2,6),
(3,4),
(3,5),
(3,6),
(4,1)
;
#一对一 两张表:学生表和客户表 一对一:一个学生是一个客户,一个客户有可能变成一个学校,即一对一的关系 关联方式:foreign key+unique
#一定是student来foreign key表customer,这样就保证了:
#1 学生一定是一个客户,
#2 客户不一定是学生,但有可能成为一个学生
create table customer(
id int primary key auto_increment,
name varchar(20) not null
);
create table student(
id int primary key auto_increment,
name varchar(20) not null,
class_name varchar(20) not null default 'python自动化',
level int default 1,
customer_id int unique, #该字段一定要是唯一的
foreign key(customer_id) references customer(id) #外键的字段一定要保证unique
on delete cascade
on update cascade
);
#增加客户
insert into customer(name) values
('李飞机'),
('王大炮'),
('守榴弹'),
('吴坦克'),
('赢火箭'),
('战地雷')
;
#增加学生
insert into student(name,customer_id) values
('李飞机',1),
('王大炮',2)
;
七 作业
练习:账号信息表,用户组,主机表,主机组
#用户表
create table user(
id int not null unique auto_increment,
username varchar(20) not null,
password varchar(50) not null,
primary key(username,password)
);
insert into user(username,password) values
('root','123'),
('egon','456'),
('alex','alex3714')
;
#用户组表
create table usergroup(
id int primary key auto_increment,
groupname varchar(20) not null unique
);
insert into usergroup(groupname) values
('IT'),
('Sale'),
('Finance'),
('boss')
;
#主机表
create table host(
id int primary key auto_increment,
ip char(15) not null unique default '127.0.0.1'
);
insert into host(ip) values
('172.16.45.2'),
('172.16.31.10'),
('172.16.45.3'),
('172.16.31.11'),
('172.10.45.3'),
('172.10.45.4'),
('172.10.45.5'),
('192.168.1.20'),
('192.168.1.21'),
('192.168.1.22'),
('192.168.2.23'),
('192.168.2.223'),
('192.168.2.24'),
('192.168.3.22'),
('192.168.3.23'),
('192.168.3.24')
;
#业务线表
create table business(
id int primary key auto_increment,
business varchar(20) not null unique
);
insert into business(business) values
('轻松贷'),
('随便花'),
('大富翁'),
('穷一生')
;
#建关系:user与usergroup
create table user2usergroup(
id int not null unique auto_increment,
user_id int not null,
group_id int not null,
primary key(user_id,group_id),
foreign key(user_id) references user(id),
foreign key(group_id) references usergroup(id)
);
insert into user2usergroup(user_id,group_id) values
(1,1),
(1,2),
(1,3),
(1,4),
(2,3),
(2,4),
(3,4)
;
#建关系:host与business
create table host2business(
id int not null unique auto_increment,
host_id int not null,
business_id int not null,
primary key(host_id,business_id),
foreign key(host_id) references host(id),
foreign key(business_id) references business(id)
);
insert into host2business(host_id,business_id) values
(1,1),
(1,2),
(1,3),
(2,2),
(2,3),
(3,4)
;
#建关系:user与host
create table user2host(
id int not null unique auto_increment,
user_id int not null,
host_id int not null,
primary key(user_id,host_id),
foreign key(user_id) references user(id),
foreign key(host_id) references host(id)
);
insert into user2host(user_id,host_id) values
(1,1),
(1,2),
(1,3),
(1,4),
(1,5),
(1,6),
(1,7),
(1,8),
(1,9),
(1,10),
(1,11),
(1,12),
(1,13),
(1,14),
(1,15),
(1,16),
(2,2),
(2,3),
(2,4),
(2,5),
(3,10),
(3,11),
(3,12)
;
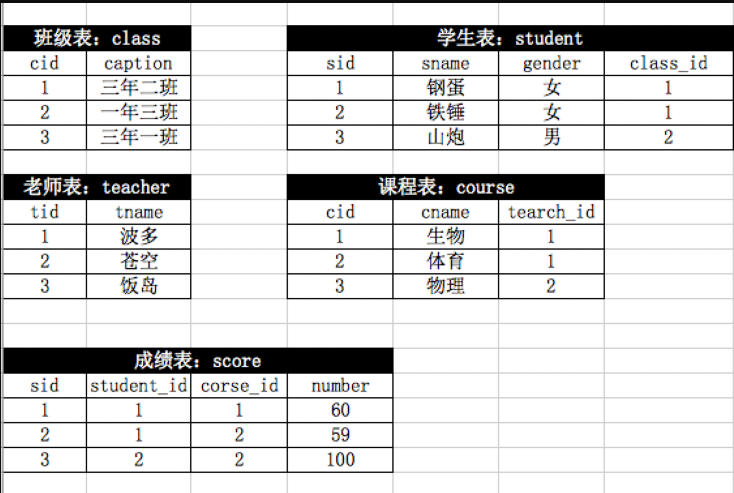
作业:
五 修改表ALTER TABLE
语法:
1. 修改表名
ALTER TABLE 表名
RENAME 新表名;
2. 增加字段
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…],
ADD 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] FIRST;
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;
3. 删除字段
ALTER TABLE 表名
DROP 字段名;
4. 修改字段
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
示例:
1. 修改存储引擎
mysql> alter table service
-> engine=innodb;
2. 添加字段
mysql> alter table student10
-> add name varchar(20) not null,
-> add age int(3) not null default 22;
mysql> alter table student10
-> add stu_num varchar(10) not null after name; //添加name字段之后
mysql> alter table student10
-> add sex enum('male','female') default 'male' first; //添加到最前面
3. 删除字段
mysql> alter table student10
-> drop sex;
mysql> alter table service
-> drop mac;
4. 修改字段类型modify
mysql> alter table student10
-> modify age int(3);
mysql> alter table student10
-> modify id int(11) not null primary key auto_increment; //修改为主键
5. 增加约束(针对已有的主键增加auto_increment)
mysql> alter table student10 modify id int(11) not null primary key auto_increment;
ERROR 1068 (42000): Multiple primary key defined
mysql> alter table student10 modify id int(11) not null auto_increment;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
6. 对已经存在的表增加复合主键
mysql> alter table service2
-> add primary key(host_ip,port);
7. 增加主键
mysql> alter table student1
-> modify name varchar(10) not null primary key;
8. 增加主键和自动增长
mysql> alter table student1
-> modify id int not null primary key auto_increment;
9. 删除主键
a. 删除自增约束
mysql> alter table student10 modify id int(11) not null;
b. 删除主键
mysql> alter table student10
-> drop primary key;
六 复制表
复制表结构+记录 (key不会复制: 主键、外键和索引) mysql> create table new_service select * from service; 只复制表结构 mysql> select * from service where 1=2; //条件为假,查不到任何记录 Empty set (0.00 sec) mysql> create table new1_service select * from service where 1=2; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> create table t4 like employees;
七 删除表
DROP TABLE 表名;
--------------------------------------------------------------------------表操作------------------------------------------------------------------------------------------------------------------------
一 介绍
MySQL数据操作: DML
========================================================
在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括
- 使用INSERT实现数据的插入
- UPDATE实现数据的更新
- 使用DELETE实现数据的删除
- 使用SELECT查询数据以及。
========================================================
本节内容包括:
插入数据
更新数据
删除数据
查询数据
二 插入数据INSERT
1. 插入完整数据(顺序插入)
语法一:
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n);
语法二:
INSERT INTO 表名 VALUES (值1,值2,值3…值n);
2. 指定字段插入数据
语法:
INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…);
3. 插入多条记录
语法:
INSERT INTO 表名 VALUES
(值1,值2,值3…值n),
(值1,值2,值3…值n),
(值1,值2,值3…值n);
4. 插入查询结果
语法:
INSERT INTO 表名(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2
WHERE …;
三 更新数据UPDATE
语法:
UPDATE 表名 SET
字段1=值1,
字段2=值2,
WHERE CONDITION;
示例:
UPDATE mysql.user SET password=password(‘123’)
where user=’root’ and host=’localhost’;
四 删除数据DELETE
语法:
DELETE FROM 表名
WHERE CONITION;
示例:
DELETE FROM mysql.user
WHERE password=’’;
练习:
更新MySQL root用户密码为mysql123
删除除从本地登录的root用户以外的所有用户
五 查询数据SELECT
单表查询:
查询语法
关键字的执行优先级
简单查询
单条件查询:WHERE
分组查询:GROUP BY
HAVING
查询排序:ORDER BY
限制查询的记录数:LIMIT
使用聚合函数查询
使用正则表达式查询
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
#插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
二 查询语法
SELECT 字段1,字段2... FROM 表名
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
三 关键字的执行优先级(重点)
重点中的重点:关键字的执行优先级 from where group by having select distinct order by limit
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.按照select后的字段得到一张新的虚拟表,如果有聚合函数,则将组内数据进行聚合
5.将4的结果过滤:having,如果有聚合函数也是先执行聚合再having过滤
6.查出结果:select
7.去重
8.将结果按条件排序:order by
9.限制结果的显示条数
四 简单查询
#简单查询
SELECT id,name,sex,age,hire_date,post,post_comment,salary,office,depart_id
FROM employee;
SELECT * FROM employee;
SELECT name,salary FROM employee;
#避免重复DISTINCT
SELECT DISTINCT post FROM employee;
#通过四则运算查询
SELECT name, salary*12 FROM employee;
SELECT name, salary*12 AS Annual_salary FROM employee;
SELECT name, salary*12 Annual_salary FROM employee;
#定义显示格式
CONCAT() 函数用于连接字符串
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary
FROM employee;
CONCAT_WS() 第一个参数为分隔符
SELECT CONCAT_WS(':',name,salary*12) AS Annual_salary
FROM employee;
1 查出所有员工的名字,薪资,格式为
<名字:egon> <薪资:3000>
2 查出所有的岗位(去掉重复)
3 查出所有员工名字,以及他们的年薪,年薪的字段名为annual_year
select concat('<名字:',name,'> ','<薪资:',salary,'>') from employee;
select distinct depart_id from employee;
select name,salary*12 annual_salary from employee;
五 WHERE约束
强调:where是一种约束条件,mysql会拿着where指定的条件去表中取数据,而having则是在取出数据后进行过滤
where字句中可以使用:
1. 比较运算符:> < >= <= <> !=
2. between 80 and 100 值在10到20之间
3. in(80,90,100) 值是10或20或30
4. like 'egon%'
pattern可以是%或_,
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
#1:单条件查询
SELECT name FROM employee
WHERE post='sale';
#2:多条件查询
SELECT name,salary FROM employee
WHERE post='teacher' AND salary>10000;
#3:关键字BETWEEN AND
SELECT name,salary FROM employee
WHERE salary BETWEEN 10000 AND 20000;
SELECT name,salary FROM employee
WHERE salary NOT BETWEEN 10000 AND 20000;
#4:关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS)
SELECT name,post_comment FROM employee
WHERE post_comment IS NULL;
SELECT name,post_comment FROM employee
WHERE post_comment IS NOT NULL;
SELECT name,post_comment FROM employee
WHERE post_comment=''; 注意''是空字符串,不是null
ps:
执行
update employee set post_comment='' where id=2;
再用上条查看,就会有结果了
#5:关键字IN集合查询
SELECT name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ;
SELECT name,salary FROM employee
WHERE salary IN (3000,3500,4000,9000) ;
SELECT name,salary FROM employee
WHERE salary NOT IN (3000,3500,4000,9000) ;
#6:关键字LIKE模糊查询
通配符’%’
SELECT * FROM employee
WHERE name LIKE 'eg%';
通配符’_’
SELECT * FROM employee
WHERE name LIKE 'al__';
小练习:
1. 查看岗位是teacher的员工姓名、年龄 2. 查看岗位是teacher且年龄大于30岁的员工姓名、年龄 3. 查看岗位是teacher且薪资在9000-1000范围内的员工姓名、年龄、薪资 4. 查看岗位描述不为NULL的员工信息 5. 查看岗位是teacher且薪资是10000或9000或30000的员工姓名、年龄、薪资 6. 查看岗位是teacher且薪资不是10000或9000或30000的员工姓名、年龄、薪资 7. 查看岗位是teacher且名字是jin开头的员工姓名、年薪
select name,age from employee where post = 'teacher'; select name,age from employee where post='teacher' and age > 30; select name,age,salary from employee where post='teacher' and salary between 9000 and 10000; select * from employee where post_comment is not null; select name,age,salary from employee where post='teacher' and salary in (10000,9000,30000); select name,age,salary from employee where post='teacher' and salary not in (10000,9000,30000); select name,salary*12 from employee where post='teacher' and name like 'jin%'
六 分组查询:GROUP BY
大前提:可以按照任意字段分组,但分完组后,只能查看分组的那个字段,要想取的组内的其他字段信息,需要借助函数
单独使用GROUP BY关键字分组
SELECT post FROM employee GROUP BY post;
注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数
GROUP BY关键字和GROUP_CONCAT()函数一起使用
SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post;#按照岗位分组,并查看组内成员名
SELECT post,GROUP_CONCAT(name) as emp_members FROM employee GROUP BY post;
GROUP BY与聚合函数一起使用
select post,count(id) as count from employee group by post;#按照岗位分组,并查看每个组有多少人
强调:
如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义 多条记录之间的某个字段值相同,该字段通常用来作为分组的依据
#参考链接:http://www.ywnds.com/?p=8184 #分组查询的常见问题: mysql> select id,count from tt group by id; ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.tt.count' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by #查看MySQL 5.7默认的sql_mode如下: mysql> select @@global.sql_mode; ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION #去掉ONLY_FULL_GROUP_BY模式,如下操作: mysql> set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'; #!!!注意 ONLY_FULL_GROUP_BY的语义就是确定select target list中的所有列的值都是明确语义,简单的说来,在ONLY_FULL_GROUP_BY模式下,target list中的值要么是来自于聚集函数的结果,要么是来自于group by list中的表达式的值。
小练习:
1. 查询岗位名以及岗位包含的所有员工名字 2. 查询岗位名以及各岗位内包含的员工个数 3. 查询公司内男员工和女员工的个数 4. 查询岗位名以及各岗位的平均薪资 5. 查询岗位名以及各岗位的最高薪资 6. 查询岗位名以及各岗位的最低薪资 7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
#题1:分组 mysql> select post,group_concat(name) from employee group by post; +-----------------------------------------+---------------------------------------------------------+ | post | group_concat(name) | +-----------------------------------------+---------------------------------------------------------+ | operation | 张野,程咬金,程咬银,程咬铜,程咬铁 | | sale | 歪歪,丫丫,丁丁,星星,格格 | | teacher | alex,wupeiqi,yuanhao,liwenzhou,jingliyang,jinxin,成龙 | | 老男孩驻沙河办事处外交大使 | egon | +-----------------------------------------+---------------------------------------------------------+ #题目2: mysql> select post,count(id) from employee group by post; +-----------------------------------------+-----------+ | post | count(id) | +-----------------------------------------+-----------+ | operation | 5 | | sale | 5 | | teacher | 7 | | 老男孩驻沙河办事处外交大使 | 1 | +-----------------------------------------+-----------+ #题目3: mysql> select sex,count(id) from employee group by sex; +--------+-----------+ | sex | count(id) | +--------+-----------+ | male | 10 | | female | 8 | +--------+-----------+ #题目4: mysql> select post,avg(salary) from employee group by post; +-----------------------------------------+---------------+ | post | avg(salary) | +-----------------------------------------+---------------+ | operation | 16800.026000 | | sale | 2600.294000 | | teacher | 151842.901429 | | 老男孩驻沙河办事处外交大使 | 7300.330000 | +-----------------------------------------+---------------+ #题目5 mysql> select post,max(salary) from employee group by post; +-----------------------------------------+-------------+ | post | max(salary) | +-----------------------------------------+-------------+ | operation | 20000.00 | | sale | 4000.33 | | teacher | 1000000.31 | | 老男孩驻沙河办事处外交大使 | 7300.33 | +-----------------------------------------+-------------+ #题目6 mysql> select post,min(salary) from employee group by post; +-----------------------------------------+-------------+ | post | min(salary) | +-----------------------------------------+-------------+ | operation | 10000.13 | | sale | 1000.37 | | teacher | 2100.00 | | 老男孩驻沙河办事处外交大使 | 7300.33 | +-----------------------------------------+-------------+ #题目七 mysql> select sex,avg(salary) from employee group by sex; +--------+---------------+ | sex | avg(salary) | +--------+---------------+ | male | 110920.077000 | | female | 7250.183750 | +--------+---------------+
七 使用聚合函数查询
先from找到表
再用where的条件约束去表中取出记录
然后进行分组group by,没有分组则默认一组
然后进行聚合
最后select出结果
示例:
SELECT COUNT(*) FROM employee;
SELECT COUNT(*) FROM employee WHERE depart_id=1;
SELECT MAX(salary) FROM employee;
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;
八 HAVING过滤
HAVING与WHERE在语法上是一样的
select * from employee where salary > 10000; select * from employee having salary > 10000;
HAVING与WHERE不一样的地方在于!!!!!!
#!!!执行优先级从高到低:where > group by > 聚合函数 > having #1. Where 是一个约束声明,使用Where约束来自数据库的数据,Where是在结果返回之前起作用的(先找到表,按照where的约束条件,从表(文件)中取出数据),Where中不能使用聚合函数。 #2. Having是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作(先找到表,按照where的约束条件,从表(文件)中取出数据,然后group by分组,如果没有group by则所有记录整体为一组,然后执行聚合函数,然后使用having对聚合的结果进行过滤),在Having中可以使用聚合函数。 #3. having可以放到group by之后,而where只能放到group by之前 #4. 在查询过程中聚合语句(sum,min,max,avg,count)要比having子句优先执行。而where子句在查询过程中执行优先级高于聚合语句。
验证不同之处
#验证之前再次强调:执行优先级从高到低:where > group by > 聚合函数 > having select count(id) from employee where salary > 10000; #正确,分析:where先执行,后执行聚合count(id),然后select出结果 select count(id) from employee having salary > 10000;#错误,分析:先执行聚合count(id),后执行having过滤,无法对id进行salary>10000的过滤 #以上两条sql的顺序是 1:找到表employee--->用where过滤---->没有分组则默认一组执行聚合count(id)--->select执行查看组内id数目 2:找到表employee--->没有分组则默认一组执行聚合count(id)---->having 基于上一步聚合的结果(此时只有count(id)字段了)进行salary>10000的过滤,很明显,根本无法获取到salary字段
其他需要注意的问题
select post,group_concat(name) from employee group by post having salary > 10000;#错误,分组后无法直接取到salary字段 select post,group_concat(name) from employee group by post having avg(salary) > 10000;
小练习: 1. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 3. 查询各岗位平均薪资大于10000的岗位名、平均工资 4. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
题1: mysql> select post,group_concat(name),count(id) from employee group by post having count(id) < 2; +-----------------------------------------+--------------------+-----------+ | post | group_concat(name) | count(id) | +-----------------------------------------+--------------------+-----------+ | 老男孩驻沙河办事处外交大使 | egon | 1 | +-----------------------------------------+--------------------+-----------+ #题目2: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ #题目3: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000; +-----------+--------------+ | post | avg(salary) | +-----------+--------------+ | operation | 16800.026000 | +-----------+--------------+
九 查询排序:ORDER BY
按单列排序
SELECT * FROM employee ORDER BY salary;
SELECT * FROM employee ORDER BY salary ASC;
SELECT * FROM employee ORDER BY salary DESC;
按多列排序:先按照age排序,如果年纪相同,则按照薪资排序
SELECT * from employee
ORDER BY age,
salary DESC;
小练习:
1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列
#题目1 mysql> select * from employee ORDER BY age asc,hire_date desc; #题目2 mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ #题目3 mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | teacher | 151842.901429 | | operation | 16800.026000 | +-----------+---------------+
十 限制查询的记录数:LIMIT
示例:
SELECT * FROM employee ORDER BY salary DESC
LIMIT 3; #默认初始位置为0
SELECT * FROM employee ORDER BY salary DESC
LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
SELECT * FROM employee ORDER BY salary DESC
LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
十一 使用正则表达式查询
SELECT * FROM employee WHERE name REGEXP '^ale';
SELECT * FROM employee WHERE name REGEXP 'on$';
SELECT * FROM employee WHERE name REGEXP 'm{2}';
小结:对字符串匹配的方式
WHERE name = 'egon';
WHERE name LIKE 'yua%';
WHERE name REGEXP 'on$';
多表查询
一 介绍
本节主题
多表连接查询
复合条件连接查询
子查询
准备表
company.employee
company.department
#建表
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
#查看表结构和数据
mysql> desc department;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> desc employee;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
mysql> select * from department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
mysql> select * from employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
二 多表连接查询
#重点:外链接语法
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
1 交叉连接:不适用任何匹配条件。生成笛卡尔积
mysql> select * from employee,department; +----+------------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+------------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 1 | egon | male | 18 | 200 | 201 | 人力资源 | | 1 | egon | male | 18 | 200 | 202 | 销售 | | 1 | egon | male | 18 | 200 | 203 | 运营 | | 2 | alex | female | 48 | 201 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 2 | alex | female | 48 | 201 | 202 | 销售 | | 2 | alex | female | 48 | 201 | 203 | 运营 | | 3 | wupeiqi | male | 38 | 201 | 200 | 技术 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 202 | 销售 | | 3 | wupeiqi | male | 38 | 201 | 203 | 运营 | | 4 | yuanhao | female | 28 | 202 | 200 | 技术 | | 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 4 | yuanhao | female | 28 | 202 | 203 | 运营 | | 5 | liwenzhou | male | 18 | 200 | 200 | 技术 | | 5 | liwenzhou | male | 18 | 200 | 201 | 人力资源 | | 5 | liwenzhou | male | 18 | 200 | 202 | 销售 | | 5 | liwenzhou | male | 18 | 200 | 203 | 运营 | | 6 | jingliyang | female | 18 | 204 | 200 | 技术 | | 6 | jingliyang | female | 18 | 204 | 201 | 人力资源 | | 6 | jingliyang | female | 18 | 204 | 202 | 销售 | | 6 | jingliyang | female | 18 | 204 | 203 | 运营 | +----+------------+--------+------+--------+------+--------------+
2 内连接:只连接匹配的行
#找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了正确的结果 #department没有204这个部门,因而employee表中关于204这条员工信息没有匹配出来 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id; +----+-----------+------+--------+--------------+ | id | name | age | sex | name | +----+-----------+------+--------+--------------+ | 1 | egon | 18 | male | 技术 | | 2 | alex | 48 | female | 人力资源 | | 3 | wupeiqi | 38 | male | 人力资源 | | 4 | yuanhao | 28 | female | 销售 | | 5 | liwenzhou | 18 | male | 技术 | +----+-----------+------+--------+--------------+ #上述sql等同于 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
3 外链接之左连接:优先显示左表全部记录
#以左表为准,即找出所有员工信息,当然包括没有部门的员工 #本质就是:在内连接的基础上增加左边有右边没有的结果 mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id; +----+------------+--------------+ | id | name | depart_name | +----+------------+--------------+ | 1 | egon | 技术 | | 5 | liwenzhou | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 6 | jingliyang | NULL | +----+------------+--------------+
4 外链接之右连接:优先显示右表全部记录
#以右表为准,即找出所有部门信息,包括没有员工的部门 #本质就是:在内连接的基础上增加右边有左边没有的结果 mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id; +------+-----------+--------------+ | id | name | depart_name | +------+-----------+--------------+ | 1 | egon | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 5 | liwenzhou | 技术 | | NULL | NULL | 运营 | +------+-----------+--------------+
5 全外连接:显示左右两个表全部记录
全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果 #注意:mysql不支持全外连接 full JOIN #强调:mysql可以使用此种方式间接实现全外连接 select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id ; #查看结果 +------+------------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+------------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | liwenzhou | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | jingliyang | female | 18 | 204 | NULL | NULL | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+------------+--------+------+--------+------+--------------+ #注意 union与union all的区别:union会去掉相同的纪录
三 符合条件连接查询
#示例1:以内连接的方式查询employee和department表,并且employee表中的age字段值必须大于25,即找出公司所有部门中年龄大于25岁的员工
select employee.name,employee.age from employee,department
where employee.dep_id = department.id
and age > 25;
#示例2:以内连接的方式查询employee和department表,并且以age字段的升序方式显示
select employee.id,employee.name,employee.age,department.name from employee,department
where employee.dep_id = department.id
and age > 25
order by age asc;
四 子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。 #2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 #3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 #4:还可以包含比较运算符:= 、 !=、> 、<等
1 带IN关键字的子查询
#查询employee表,但dep_id必须在department表中出现过
select * from employee
where dep_id in
(select id from department);
2 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询平均年龄在25岁以上的部门名
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
#查看不足1人的部门名
select name from department
where id in
(select dep_id from employee group by dep_id having count(id) <=1);
3 带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。
而是返回一个真假值。True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
