mapreduce流程
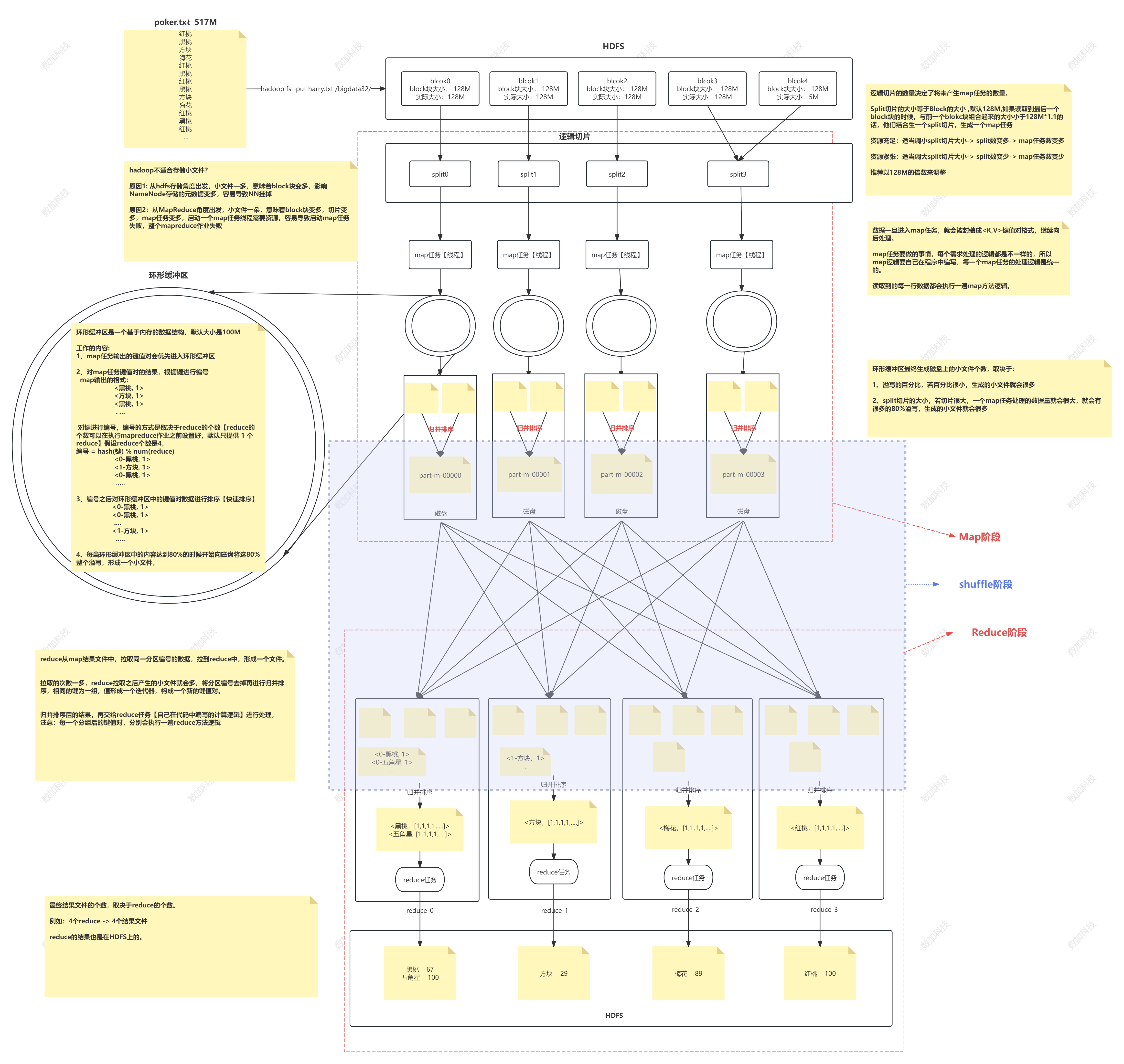
- 逻辑切片
1、逻辑切片对block块进行切分,切分的结果将影响map任务的数量
2、split切片的大小默认是128M,与block块大小一样,一个block块会有一个切片
3、如果读取到最后一个block块时会与前一个block进行合并,合并后的大小如果大于1281.1将会各自生成一个切片,合并后的大小如果小于1281.1,就会只生成一个切片
- map任务
1、数据进入到map任务会被封装成<k,v>键值对的格式
2、map任务要做的事,每个需求的处理逻辑是不一样的,所以map任务的逻辑需要自己在程序中编写
3、每读取到的一行数据都会执行一遍map逻辑
- 环形缓冲区
概述
1、被map任务处理过的数据要写入磁盘中,直接写入磁盘的话,当map任务生成的数据过多时会来不及写入磁盘,环形缓冲区可以解决这个问题
2、环形缓冲区是一个基于内存的数据结构,默认大小是100M
工作内容
1、map任务输出的键值对会先进入到环形缓冲区
2、对map任务的键值对结果根据建进行编号【编号取决于reduce的个数,reduce的个数可以在执行mapreduce作业之前自己设置,默认只提供一个reduce】
3、编号之后对缓冲区的键值对数据进行排序【快速排序】
4、当环形缓冲区的数据内容达到80%的时候开始向磁盘将这80%的数据整个溢写到磁盘,形成一个小文件
小文件写到磁盘后
会把每个map任务产生小文件合并成一个,合并的过程中排序归并排序,【将编号一样的排在一起】
环形缓冲区最终在磁盘上小文件的数量
1、溢写的百分比,百分比越小,生成的小文件越多
2、split切片的大小,切片越大,map任务处理的数据量越多,就会有很多的80%溢写,生成的小文件就越多
- reduce阶段
1、reduce从每个map结果文件中拉取分区编号相同的数据,形成一个文件
2、拉取的次数多,形成的小文件就多,这时会把分区编号去掉然后把小文件合并,合并的过程中使用归并排序,相同的键为一组,值生成一个迭代器,构成一个新的键值对
3、归并排序后的结果交给reduce任务【reduce任务的逻辑需要自己编写】进行处理
4、每一个分组后的键值对,都会执行一遍reduce方法的逻辑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号