PoseFormer
Pipeline
2D skeleton sequence --> Spatial Transformer --> Temporal Transformer --> Regression Head.
2D skeleton sequence
\(X\in R^{f\times (2J)}\), \(f\): 接受帧数, 感受野; \(J\): 关节点数; \(2\): 2D空间\((x, y)\).
\(x^i \in R^{1\times (2J)}\), 单个骨架关节点坐标向量.
Spatial Transformer
The spatial transformer module is to extract a high dimension feature embedding
from a single frame.
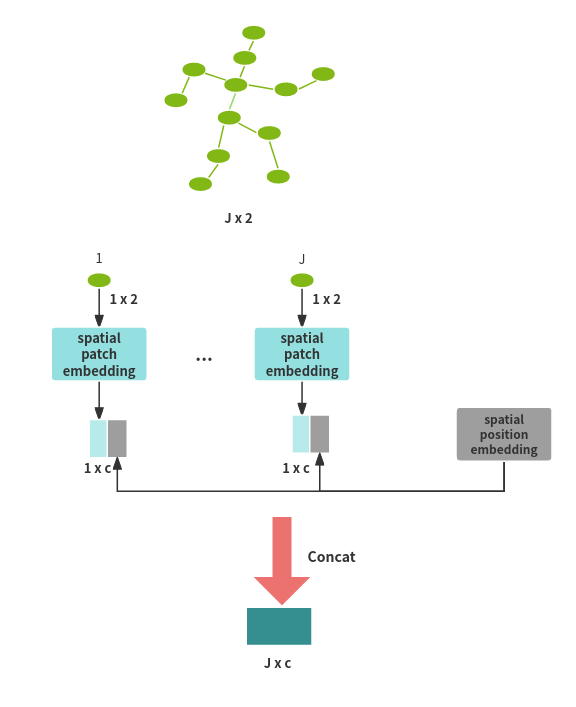
Spatial emedding(joint embedding)
对于单帧2D姿态\(x\in R^{1\times (2J)}\), Spatial Transformer Module把每个2D坐标\((x, y)\)作为
一个patch(ViT), 用一个线性投影将2D坐标投影至高纬空间. 接着加上表示关节位置信息的embedding,
作为输入交给Spatial Transformer学习关节点间空间信息.
\(x_i \in R^{1\times (2J)}\) -- linear transformation --> \(x_i \in R^{J\times c}\) -- positional embeddomh --> \(z_0^i \in R^{J\times C}\)
\(z_0 = [p^1E; p^2E; ...; p^JE] + E_{Spos}\), 其中\(p\)表示单个2D坐标\((x, y)\),
\(E\)表示线性投影矩阵, \(E_{Spos}\)表示positional embedding.
Self-attention
将\(z_0\in R^{f\times c}\)作为输入进入Spatial Transformer模块, 由\(L\)个ViT模块堆叠而成.
\(z'_l = MSA(LN(z_{l-1})) + Z_{l - 1}, l = 1, 2, ..., L\)
\(z_l = MLP(LN(Z'_l) + Z'_l), l = 1, 2, ..., L\)
\(Y = LN(Z_L)\)
其中\(LN()\)表示layer normalization, \(Y\in R^(f\times c)\), 与输入维度相同.
即先对输入进行多头注意力, 再进入全连接. 每个输入进入网络前先进行层归一化, 输出网络后残差连接.
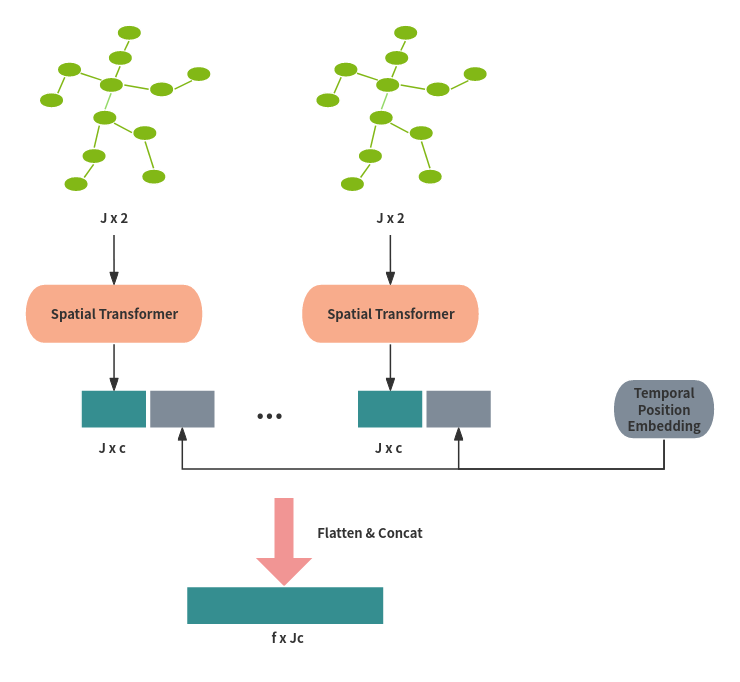
Temporal Transformer
The goal of the temporal transformer module is to model dependencies across the
sequence of frames.
对于第\(i\)帧2D骨架经过Spatial Transformer后输出为\(z_L^i \in R^{J\times c}\), 将其
压缩为向量\(z^i\in R^{1\times (Jc)}\). 将\(f\)个(感受野)向量连接concatenate, 加上表示
帧位置信息的position embedding作为输入
\(Z_0 = [z_L^1; z_L^2; ..., z_L^f] + E_{Tpos}, Z_0\in R^{f\times (Jc)}\).
将\(Z_0\)输入\(L\)层相同的ViT模块(与Spatial Transformer相同), 得到输出\(Y\in R^{f\times (Jc)}\).
Regression Head
由于最终预测中间一帧的3D骨架, 首先需要将输出维度缩减为\(f\times (Jc) --> 1\times (Jc)\).
本方法通过对帧维度(\(f\))进行可训练的带权平均weighted mean操作实现. 最后, 使用一个简单的
\(MLP\), 得到最终输出\(y\in R^{1\times (3J)}\), 代表3D骨架坐标向量.
Code
Spatial Transformer与Temporal Transformer均以ViT作为blocks串联作为模块.
Spatial Transformer的输入为\(J\times c\), \(J\)表示关节点个数, \(c\)表示Spatial embedding的维度.
(关节点作为token)此时\(B\times F\)作为batch size, 其中\(B\)是mini batch数, \(F\)是感受野, 即2D骨架序列长度.
Spatial Transformer的输入为\(F\times Jc\), 将骨架信息作为token, \(B\)作为Batch size.
import math
import logging
from functools import partial
from collections import OrderedDict
from einops import rearrange, repeat
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# qkv: [3, B, num_heads, N, C // num_heads]
q, k, v = qkv[0], qkv[1], qkv[2] # [B, num_heads, N, C // num_heads] make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x) # linear, C -- > C
x = self.proj_drop(x)
return x
# ViT
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
# dim 单个输入向量的长度 N个向量组成矩阵 B个batch
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PoseTransformer(nn.Module):
def __init__(self, num_frame=9, num_joints=17, in_chans=2, out_dim=17*3, spatial_embed_dim=32, depth=4,
num_heads=8, mlp_ratio=2., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.2, norm_layer=None):
""" ##########hybrid_backbone=None, representation_size=None,
Args:
num_frame (int, tuple): input frame number
num_joints (int, tuple): joints number
in_chans (int): number of input channels, 2D joints have 2 channels: (x,y)
embed_dim_ratio (int): embedding dimension ratio
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
qk_scale (float): override default qk scale of head_dim ** -0.5 if set
drop_rate (float): dropout rate
attn_drop_rate (float): attention dropout rate
drop_path_rate (float): stochastic depth rate
norm_layer: (nn.Module): normalization layer
"""
super().__init__()
self.out_dim = out_dim
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
temporal_embed_dim = spatial_embed_dim * num_joints #### temporal embed_dim is num_joints * spatial embedding dim ratio
#out_dim = num_joints * 3 #### output dimension is num_joints * 3
### spatial patch embedding (x, y) --> embedding
self.Spatial_patch_to_embedding = nn.Linear(in_chans, spatial_embed_dim)
# 1 x J x embedding. add as joint position info
self.Spatial_pos_embed = nn.Parameter(torch.zeros(1, num_joints, spatial_embed_dim))
self.Temporal_pos_embed = nn.Parameter(torch.zeros(1, num_frame, temporal_embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.Spatial_blocks = nn.ModuleList([
Block(
dim=spatial_embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.Temporal_blocks = nn.ModuleList([
Block(
dim=temporal_embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.Spatial_norm = norm_layer(spatial_embed_dim)
self.Temporal_norm = norm_layer(temporal_embed_dim)
####### A easy way to implement weighted mean
self.weighted_mean = torch.nn.Conv1d(in_channels=num_frame, out_channels=1, kernel_size=1)
self.head = nn.Sequential(
nn.LayerNorm(temporal_embed_dim),
nn.Linear(temporal_embed_dim , out_dim),
)
def Spatial_forward_features(self, x):
# input shape: B x 2 x F x J
b, _, f, j = x.shape
# B x 2 x F x J --> BF x J x 2
x = rearrange(x, 'b c f j -> (b f) j c', )
# BF x J x 2 --> BF x J x c, 2 -- Linear Transformation --> c
x = self.Spatial_patch_to_embedding(x)
x += self.Spatial_pos_embed # pos_embed: a matrix (J x c)
x = self.pos_drop(x)
# BF x J x c --> BF x J x c, J x c as input to ViT. c as token, BF as batch size
for blk in self.Spatial_blocks:
x = blk(x)
x = self.Spatial_norm(x)
# BF x J x c --> B x F x Jc
x = rearrange(x, '(b f) j c -> b f (j c)', f=f)
return x
def Temporal_forward_features(self, x):
b = x.shape[0]
x += self.Temporal_pos_embed # pos_embed: matrix (F x Jc)
x = self.pos_drop(x)
# B x F x Jc --> B x F x Jc, F x Jc as input, Js as token, B as batch size
for blk in self.Temporal_blocks:
x = blk(x)
x = self.Temporal_norm(x)
# B x F x Jc --> B x 1 x Jc. average of F frames
x = self.weighted_mean(x)
# B x 1 x Jc --> B x 1 x Jc
x = x.view(b, 1, -1)
return x
def forward(self, x):
# B x F x J x 2 --> B x 2 x F x J
x = x.permute(0, 3, 1, 2)
b, _, _, _ = x.shape
j = self.out_dim // 3
# B x 2 x F x J --> B x F x Jc, c is spatial embedding dimension
x = self.Spatial_forward_features(x)
# B x F x Jc --> B x 1 x Jc
x = self.Temporal_forward_features(x)
# B x 1 x Jc --> B x 1 x 3J
x = self.head(x) # Jc --> 3J. spatial embedding --> 3 D joints
# B x 1 x 3J --> B x 1 x J x 3
x = x.view(b, 1, j, -1) # batch size, 1, j, 3 (1, j, 3): center frame joints
return x
if __name__ == '__main__':
model = PoseTransformer(num_frame=27)
input = torch.randn(27, 27, 17, 2)
output = model(input)
print(output.shape)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号