
pytest_2


fixture夹具


conftest.py
- scope="session"必须写在conftest.py里
- conftest.py为固定写法,不可修改名字
- 使用conftest.py文件方法无需导入
- 函数作用于当前文件夹及下属文件夹


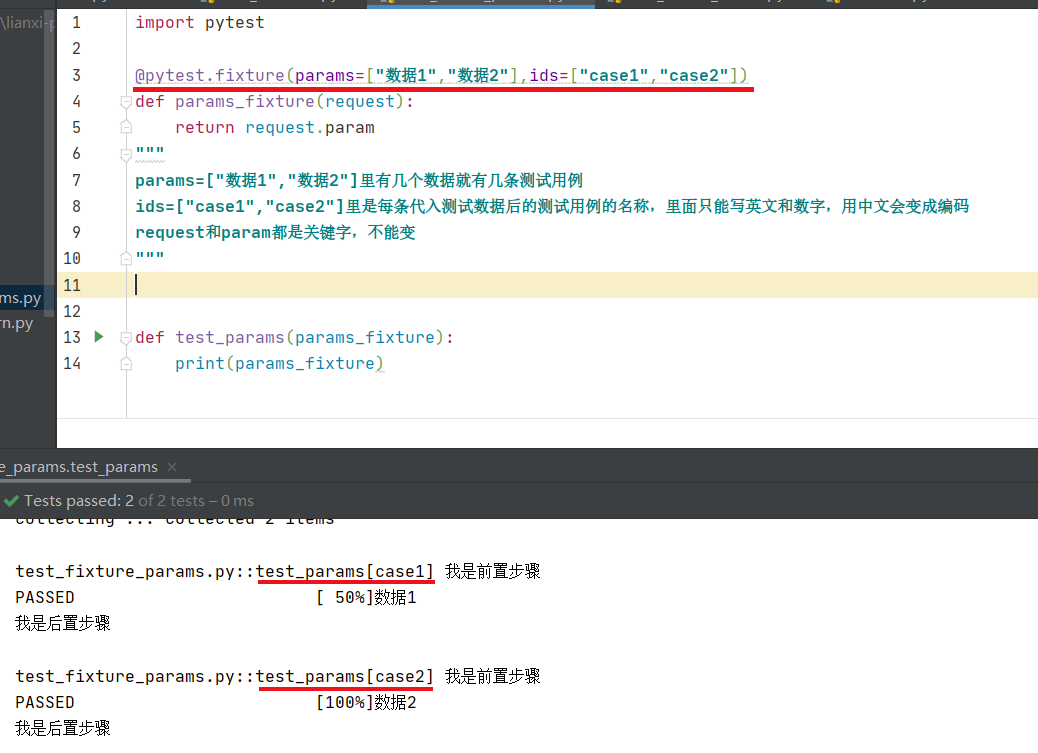
利用fixture写前置和后置
@pytest.fixture(scope="function",autouse=True) def func(): print("我是前置步骤") yield "白"#加上yield后面就能写后置步骤了,“白”可以去掉,在这里只是想说yield能传东西出去,与return相比,传出东西后后续步骤依然会执行 print("我是后置步骤")

参数化

parametrize

import pytest # 单参数,单次循环 @pytest.mark.parametrize("a", ["单参数"]) def test_parametrize(a): print("我是" + a) # 单参数,多次循环 #每赋值一次,运行一条测试用例 @pytest.mark.parametrize("name", ["安其拉","黄忠","大乔"]) def test_parametrize(name): print('我是' + name) """ 多参数: 注意!只要参数数量大于1,则每一组参数对应的值都应在[]内打上()/[] """ #两个参数,[]内打上()元组 @pytest.mark.parametrize("name,word", [("安其拉","火烧屁屁咯"),("黄忠","周日被我射熄火了")]) def test_parametrize(name,word): print(f'{name}的台词是{word}') #两个参数,[]内打上[]列表 @pytest.mark.parametrize("name,word", [["安其拉","火烧屁屁咯"],["黄忠","周日被我射熄火了"]]) def test_parametrize(name,word): print(f'{name}的台词是{word}')
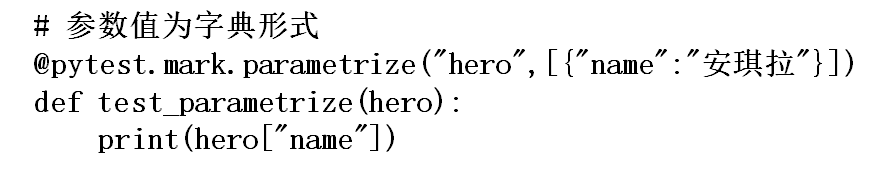
#[]内打上{}字典。参数值为字典形式,只能是一个参数 @pytest.mark.parametrize("name", [{'names':"安其拉"},{'names':"黄忠"}]) def test_parametrize(name): print(name['names']) """ 两个参数用字典的话,像上面那样取值就会报错 @pytest.mark.parametrize("name,word", [{'name':"安其拉",'word':"火烧屁屁咯"},{'name':"黄忠",'word':"周日被我射熄火了"}]) def test_parametrize(name,word): print(name['name'],word['word']) -------------------------------------------------------------------------------------- 只能像下面那样取值,但这不就回归只有一个参数了吗_(:з」∠)_,所以字典格式的话大概就只支持一个参数吧 @pytest.mark.parametrize("hero", [{'name':"安其拉",'word':"火烧屁屁咯"},{'name':"黄忠",'word':"周日被我射熄火了"}]) def test_parametrize(hero): print(hero['name'],hero['word']) """ @pytest.mark.parametrize("hero", [{'name':"安其拉",'word':"火烧屁屁咯"},{'name':"黄忠",'word':"周日被我射熄火了"}]) def test_parametrize(hero): print(hero['name'],hero['word'])
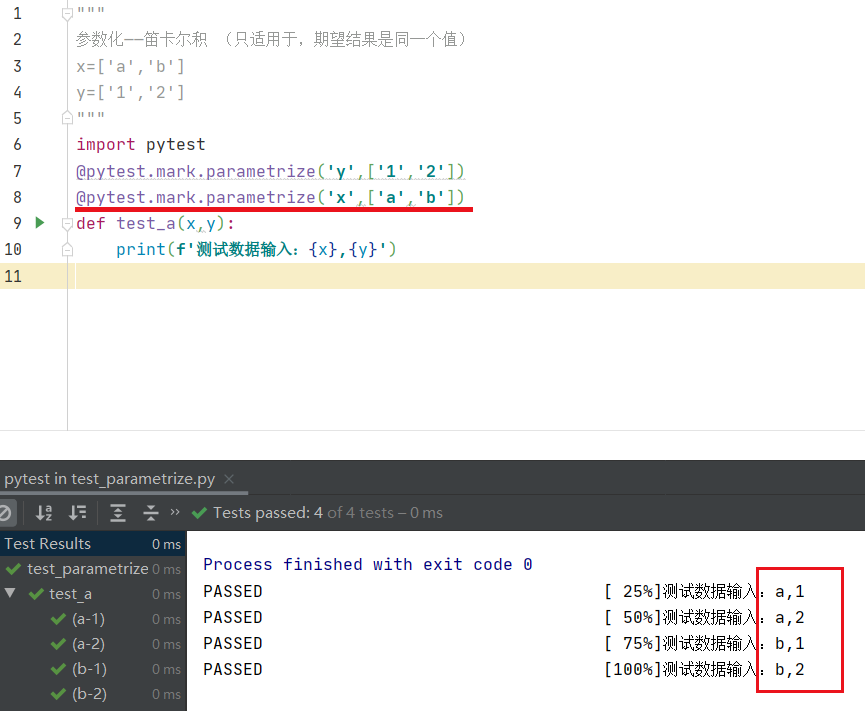
多个参数化,即参数化叠加时,运行测试用例如下图会得出执行4个用例:因为x中的每个元素都与y中的每个元素组合了一次
yaml



Python中像字符串、布尔值、int等,都属于纯量。


装PyYAML包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PyYAML
#data.yaml
person:
- name: 上海-${random_name()}-测试组
age: ${age()}
sex: 男
- name: 上海-${random_name()}-测试组
age: ${age()}
sex: 男
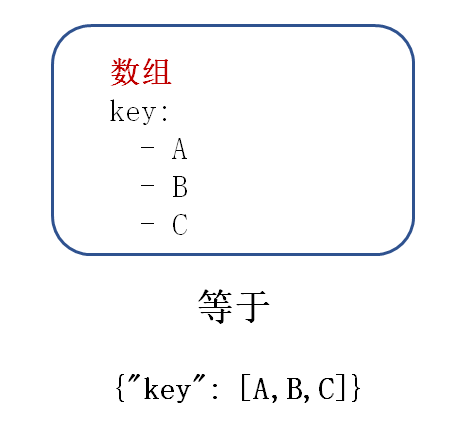
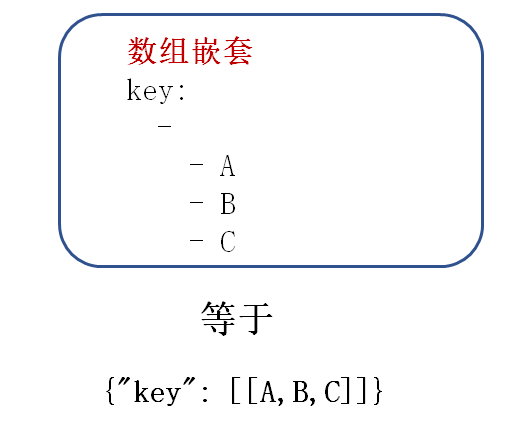
hero: name: 安其拉 word: 火焰是我最喜欢的玩具 hp: 445.5 hero2: {name: 安其拉, word: 火焰是我最喜欢的玩具, hp: 445.5} #hero=hero2 heros_name: - 安其拉 - 黄忠 - 小乔 heros: - name: 黄忠 word: 周日被我射熄火了 hp: 440 heros_name_list: - - 安其拉 - 黄忠 - 小乔
heros_name_word:
- - 黄忠
- 周日被我射熄火了
- - 安其拉
- 火焰是我最喜欢的玩具
mobile_belong_post:
#手机号,appkey
- [13456755448,0c818521d38759e1]
mobile_belong_get:
#手机号,appkey
- [13456755448,0c818521d38759e1]
- [13000000000,0c818521d38759e1]
import yaml #1.打开yaml文件,限定编码方式,防止中文乱码。此处使用相对路径。
f = open("../config/data.yaml", encoding="utf-8")
#2.读取yaml文件 data = yaml.safe_load(f) print(data) print(data['hero']) print(data['hero2']) print(data['heros_name']) print(data['heros']) print(data['heros_name_list'])
#然后右键运行这个文件
python解析yaml

读取可以直接用: yaml.safe_load(f)
写入数据:yaml.dump(data=old_value, stream=f, allow_unicode=True, sort_keys=False)
#data:写入的数据, stream:文件, allow_unicode=True:遵循unicode编码, sort_keys=False:不设置的话默认为Ture指依据26个字母来给内容排序,False的话就会按照追加的顺序进行排序
yaml和parametrize参数化结合
注意:在 Python 中,相对路径是相对于当前工作目录而言的,而不是相对于代码文件所在的路径。
因此,在不同的文件中调用相同的代码时可能会出现路径错误。
绝对路径:它是描述从盘符开始到目标文件位置的完整路径。绝对路径虽然不会在其他文件调用时产生路径错误但过于死板,文件本身稍微改动下位置就不行了
所以,另一种方法是使用 os.path 模块动态获取文件路径
所以,用os.path改写上面的读yaml文件代码
#utils/read_data.py import yaml,os #视频上以逗号隔开拼接的路径,如下行,但直接用路径符也可以,如下下行 #path = os.path.join(os.path.dirname(os.path.dirname(os.path.realpath(__file__))),"config","data.yaml") path = os.path.join(os.path.dirname(os.path.dirname(os.path.realpath(__file__))),"config/data.yaml") def read_data(): # 1.打开yaml文件,限定编码方式,防止中文乱码 f = open(path, encoding="utf-8") # 2.读取yaml文件 data = yaml.safe_load(f) return data get_data = read_data()
然后参数化
""" testcases/test_parametrize_yaml.py, 在这个文件中调用上个文件读取的yaml数据进行参数化 单参数多次循环取出三个测试数据,[安其拉,黄忠,小乔],运行三条测试用例 双参数多次循环取出两组测试数据,[[黄忠,周日被我射熄火了],[安其拉,火焰是我最喜欢的玩具]] """ import pytest from utils.read_data import get_data # 单参数多次循环 @pytest.mark.parametrize("name", get_data['heros_name']) def test_parametrize_02(name): print(name) # 双参数多次循环 @pytest.mark.parametrize("name, word", get_data['heros_name_word']) def test_parametrize_03(name, word): print(name, word)
利用python自带函数eval(str)会自动运行str表达式实现yaml文件内用函数,安装Faker库造假数据
""" utils/yaml_utils.py 涉及python自带函数 isinstance(data,dict)——-————判断数据是否为该类型 for key,value in data.items(): ——————字典独有的 str(value)———————————————————将各种值转换为字符串 eval(str(value))————————eval()里只能是字符串格式,但若字符串里有表达式/函数,会自动运行输出,如eval('1+2')————3,是个int str(value).index('$') 字符串的索引/下标,运行完是int,字符串的下标从0开始数,所以字符串的长度=字符串最后一个下标数字+1 str(value)[start+1:end] 字符串的切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串(取出来的原则就是顾头不顾腚,所以想取出来的时候去掉头就需要在开始的索引+1)。 len(str)——————获得字符串的长度数字 random.randint(10, 100) """ import random def func_yaml(data): if isinstance(data,dict): for key,value in data.items(): if '${' and '}' in str(value): start = str(value).index('$') end = str(value).index('}') func_name = str(value)[start+2:end] data[key] = str(value)[0:start]+str(eval(func_name))+ str(value)[end+1:len(str(value))] print(len(str(value))) return data """ 安装Faker库 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Faker 可以生成各种各样的伪造数据,如:姓名、身份证、手机号、银行卡 """ from faker import Faker fake = Faker(locale="zh-CN") def random_name(): return fake.name() def age(): return random.randint(10, 100) if __name__ == '__main__': data = {'name': '上海-${random_name()}-测试', 'age':'${age()}', 'sex': '男'} print(func_yaml(data))
#testcases/test_person.py ,结合参数化 import pytest from utils.read_data import get_data from utils.yaml_util import func_yaml @pytest.mark.parametrize("data",get_data["person"]) def test_person(data): print(func_yaml(data))
利用python反射: getattr(实例化类,'类的函数名')(函数的参数)实现yaml文件内用函数
如标题的 getattr() ,getattr(ExtractUtil(),'get_extract_value')(func_params) 通过‘函数名’获取成员方法/启动成员方法
还可以通过‘类变量’获取类变量,以及通过‘成员变量’获得成员变量
getattr大概指南如下:具体查看https://zhuanlan.zhihu.com/p/576254496 class Person(): # 定义类变量 guoJi = "china" def __init__(self,name,age,id): self.name = name self.age = age self.id = id
def my_info(self,English): my_name = self.name + English
print(my_name)
# 创建类的对象 xiao_wang = Person("小王",23,"101010") print(Person.guoJi) # 反射获取类变量 print(getattr(Person, 'guoJi')) # 反射获取成员变量 print(getattr(xiao_wang,"name")) # 反射获取成员方法,返回方法是一个引用地址,要想执行该方法,需要在后面加上小括号 getattr(xiao_wang,"my_info")(English)
代码分层

pip install -i https://pypi.tuna.tsinghua.edu.cn/simple configparser



 浙公网安备 33010602011771号
浙公网安备 33010602011771号