
在“基于金山云平台的Hadoop集群部署(一)- Hadoop基础环境搭建”基础上,我们继续部署Hadoop软件。
首先,金山云平台提供了KMR产品(一个可伸缩的通用数据计算和分析平台,它以Apache Hadoop 和Apache Spark两大数据计算框架为基础,通过自动调度弹性计算服务,可快速构建分布式数据分析系统);可能是基于以上原因,金山提供的centOS7.0镜像yum源里并没有Hadoop的安装包,需要我们从官网上下载;当然我们也可以通过配置个性化的yum源,下载相应的资源。
下面是安装Hadoop软件并利用Hadoop自带wordcount示例演示的具体步骤:
一、 创建本地hadoop文件夹
利用#mkdir hadoop 命令在usr文件夹下创建文件夹,用于存放hadoop的下载、解压缩等相关文件,并进入hadoop文件夹。

二、 下载hadoop压缩包到hadoop文件夹内
本次集群搭建,选择的是hadoop的2.8.0版本,下载地址为http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
使用命令wget -c http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz 下载该文件到本地的hadoop文件夹:

三、 解压hadoop文件利用tar –xvf hadoop-2.8.0.tar.gz解压压缩包,得到hadoop-2.8.0文件夹。

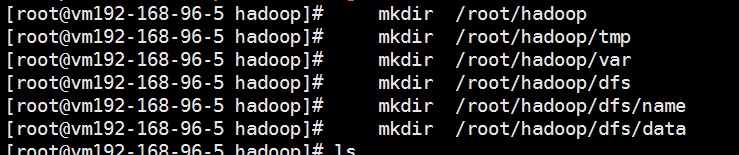
四、 建立hadoop集群需要的工作文件夹
利用以下命令在本地建立一些列文件夹,用作hadoop集群的工作目录。
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
五、 配置hadoop的java工作路径
在hadoop-2.8.0/etc/hadoop/hadoop-env.sh文件中,配置hadoop的java工作路径。

本机的工作路径如下: /lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre

六、 配置core-site.xml文件
core-site.xml文件是hadoop集群的全局控制文件。
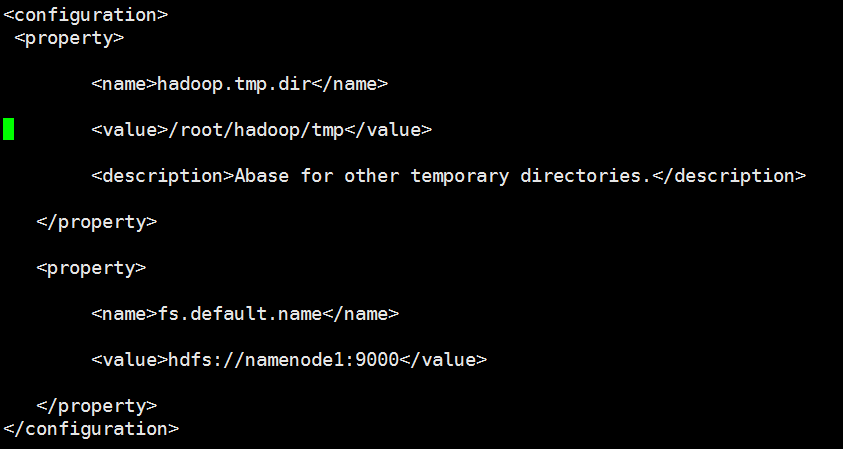
利用 vi /usr/hadoop/hadoop-2.8.0/etc/Hadoop/core-site.xml命令修改相关配置,在<configuration>和</configuration>标签之内添加进如下内容:
<property>
<name> hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description></property>
<property>
<name>fs.default.name< /name>
<value>hdfs://namenode1:9000< /value>
</property>
七、 配置hdfs-site.xml文件
hdfs-site.xml文件用来配置HDFS的保存副本数量、位置等存储的配置选项。
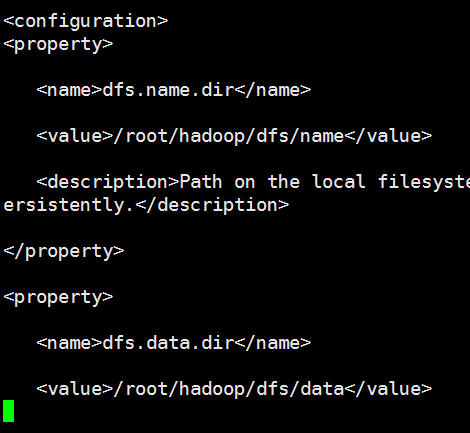
利用 vi /usr/hadoop/hadoop-2.8.0/etc/Hadoop/hdfs-site.xml命令修改相关配置,在<configuration>和</configuration>标签之内添加进如下内容:
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode
stores the namespace and transactions logs persistently.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
八、 配置mapred-site.xml
mapred-site.xml文件用来配置MP运算位置及其他相关选项。
首先利用命令cp hadoop-2.8.0/etc/hadoop/mapred-site.xml.template
hadoop-2.8.0/etc/hadoop/mapred-site.xml从mapred-site.xml.
template复制出一个mapred-site.xml文件。

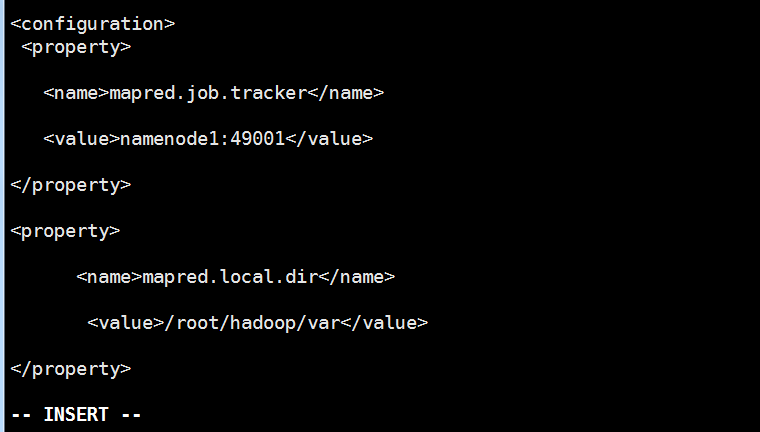
利用 vi /usr/hadoop/hadoop-2.8.0/etc/Hadoop/mapred-site.xml命令修改相关配置,在<configuration>和</configuration>标签之内添加进如下内容:
<property>
<name>mapred.job.tracker</name>
<value>namenode1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
九、 配置slaves文件
利用 vi /usr/hadoop/hadoop-2.8.0/etc/Hadoop/slaves命令修改相关配置,将localhost修改为如下内容:
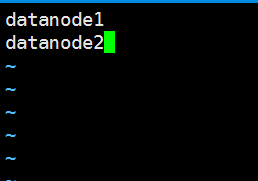
配置完后,整个集群即认为datanode为slaves节点。
十、 配置yarn-site.xml文件
yarn-site.xml文件用来配置hadoop的资源管理和任务调度。
利用 vi /usr/hadoop/hadoop-2.8.0/etc/Hadoop/mapred-site.xml命令修改相关配置,在<configuration>和</configuration>标签之内添加进如下内容:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode1
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048< /value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>

十一、 在每一个节点上(包含namenode与datanode)做相同的配置
十二、 配置Hadoop集群
12.1 初始化集群
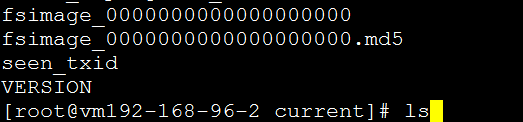
切换到namenode节点,进入hadoop-2.8.0目录,利用bin/hadoop namenode -format命令初始化hadoop集群:

成功后可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内已经存放了一些配置文件则表示初始化成功:
12.2 启动集群
利用sbin/ start-dfs.sh启动HDFS服务,利用sbin/ start-yarn.sh启动yarn服务。
十三、 利用hadoop自带示例测试集群
13.1 本地建立文件夹
利用mkdir input命令在/usr/hadoop文件夹内建立本地input文件夹:

13.2 文件夹中放入要上传到hadoop的文件
在input文件夹内创建2个文件,本示例为test1.txt和test2.txt,在文件中随便输入一些字符:

13.3 上传文件到hadoop集群
利用bin/hadoop fs -mkdir /root及bin/hadoop fs -mkdir /root/in命令与bin/hadoop fs -mkdir /root/out命令,在hadoop集群上创建/root/in与root/out文件夹;其中/root/in文件夹是用作集群上保存文件的位置,而/root/out文件夹是用作集群输出结果保存的位置;
利用bin/hadoop fs -put /usr/hadoop/input/ /root/in/;将本地的input文件夹及内容上传到集群的/root/in/文件夹中,成功后可以利用bin/hadoop fs -ls /root/in/input命令查询出集群中的文件信息:

从信息中已经可以看到,test1.txt和test2.txt已经上传到集群中。
13.4 运行wordcount示例
利用bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /root/in/input /root/out/output1 命令,统计文件中各单词的个数:
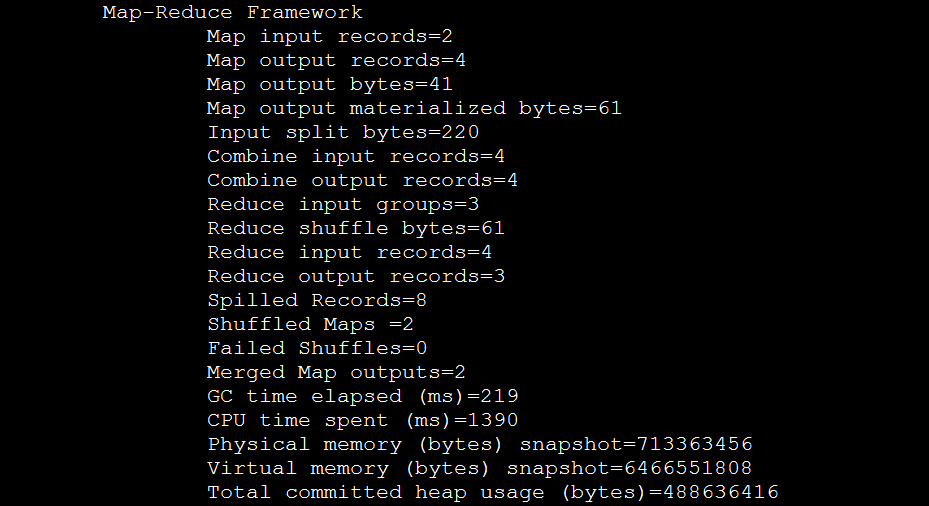

如果有以上信息,则表示运行成功。
以上为hadoop的集群搭建简单的过程,以后的系列中会继续介绍Hadoop其他组件(Spark、Hive、Pig、HUE…)的安装配置,并部署更复杂的集群,进行相关测试。

