
MySQL 底层原理+优化
一、索引的底层数据结构与算法
1、什么是索引?
索引是帮助MySQL高效获取数据的排好序的数据结构。
2、索引的数据结构
-
B+Tree(B-Tree变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
-
叶子节点包含所有索引字段
-
叶子节点用指针连接,提高区间访问的性能
-
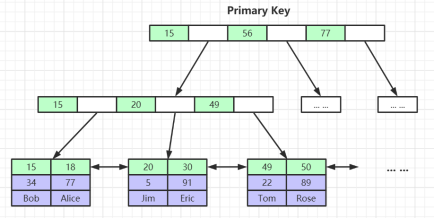
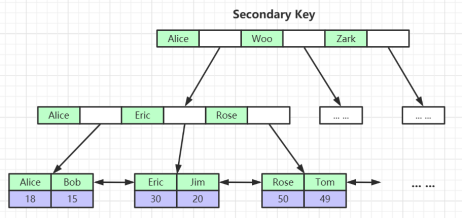
MyISAM索引文件和数据文件是分离的(非聚集)
-
InnoDB索引实现(聚集)
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
-
叶节点包含了完整的数据记录
- 建议InnoDB表必须建主键,并且推荐使用整型的自增主键
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
![]()
![]()
-
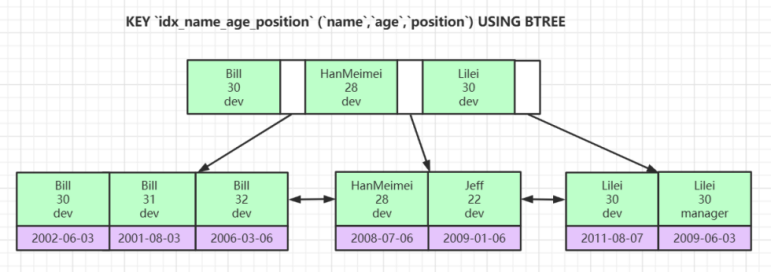
联合索引数据结构
![]()
二、Explain工具使用
1、explain?
在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL
-
explain extended+show warnings:会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings 命令可以得到优化后的查询语句
-
explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
2、explain中的列

-
id:
有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
-
select_type:
对应行是简单还是复杂的查询
-
simple:简单查询。查询不包含子查询和union
-
primary:复杂查询中最外层的 select
-
subquery:包含在 select 中的子查询(不在 from 子句中)
-
derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
-
union:在 union 中的第二个和随后的 select
-
-
table这一列表示 explain 的一行正在访问哪个表。
-
type:
-
system > const > eq_ref > ref > range > index > ALL,一般来说要保证达到range级别
- const, system:mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。
-
eq_ref:primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。
-
ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
-
range:范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行。
-
index:扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
-
ALL:即全表扫描,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
- possible_keys:显示查询可能使用哪些索引来查找。
- key:实际采用哪个索引来优化对该表的访问。
- key_len:通过这个值可以算出具体使用了索引中的哪些列。
-
- 字符串:char(n):3n , varchar(n): 3n + 2 ,加的2字节用来存储字符串长度,因为varchar是变长字符串
-
- 数值类型:tinyint:1 smallint:2 int:4 bigint:8字节
-
- 时间类型:date:3 timestamp:4 datetime:8
- ref:这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
- rows:这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
- Extra:这一列展示的是额外信息。常见的重要值如下:
-
Using index:使用覆盖索引
-
Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖
-
Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
-
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
-
Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
-
Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段是
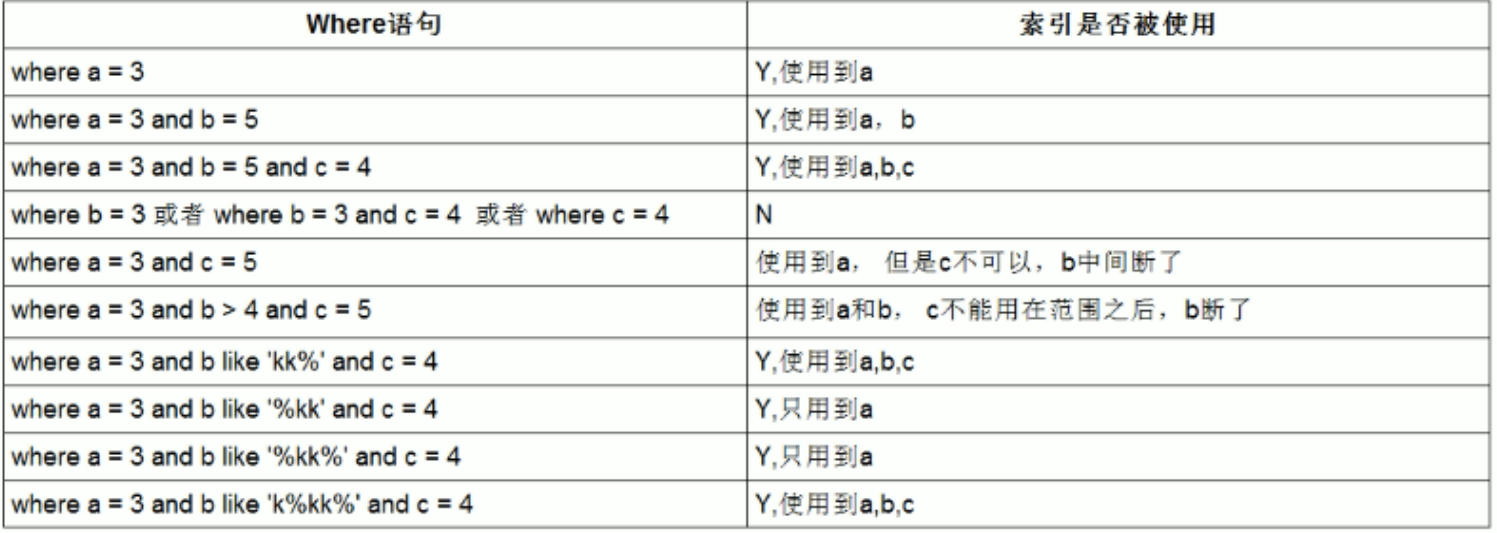
3、优化建议
三、bin-log归档
1、如果误删了数据库,可以使用bin-log进行归档
- Binlog在MySql的Server层实现
- bin-log为逻辑日志,记录每条语句的原始逻辑
- bin-log不限大小,追加写入,不会覆盖以前日志
2、开启bin-log
#配置开启binlog,my.conf log‐bin=/usr/local/mysql/data/binlog/mysql‐bin #注意5.7以及更高版本需要配置本项: server‐id=123454(自定义,保证唯一性); #binlog格式,有3种statement,row,mixed binlog‐format=ROW #表示每1次执行写入就与硬盘同步,会影响性能,为0时表示,事务提交时mysql不做刷盘操作,由系统决定 sync‐binlog=1
bin-log 命令
1 mysql> show variables like '%log_bin%'; 查看bin‐log是否开启 2 mysql> flush logs; 会多一个最新的bin‐log日志 3 mysql> show master status; 查看最后一个bin‐log日志的相关信息 4 mysql> reset master; 清空所有的bin‐log日志
查看bin-log内容
1 mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin. 000001 查看binlog内容
数据归档操作
1 从bin‐log恢复数据 2 恢复全部数据 3 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(数据库名) 4 恢复指定位置数据 5 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults ‐‐start‐position="408" ‐‐stop‐position="731" /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(数据库) 6 恢复指定时间段数据 7 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 ‐‐stop‐date= "2018‐03‐02 12:00:00" ‐‐start‐date= "2019‐03‐02 11:55:00"|mysql ‐uroot ‐p test(数 据库)
四、性能调优
1、索引设计原则
1、代码先行,索引后上
2、联合索引尽量覆盖条件
3、不要在小基数字段上建立索引
4、长字符串我们可以采用前缀索引
5、where与order by冲突时优先where
6、基于慢sql查询做优化
2、索引下推(like'Lilei%')
可以在索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效的减少回表次数。
为什么范围查找Mysql没有用索引下推优化?
是Mysql认为范围查找过滤的结果集过大,like KK% 在绝大多数情况来看,过滤后的结果集比较小,所以这里Mysql选择给 likeKK% 用了索引下推优化,当然这也不是绝对的,有时like KK% 也不一定就会走索引下推。
3、Order by与Group by优化
1、优化例子
- 利用最左前缀法则:中间字段不能断,因此查询用到了name索引,从key_len=74也能看出,age索引列用在排序过程中,因为Extra字段里没有using filesort
![]()
-
从explain的执行结果来看:key_len=74,查询使用了name索引,由于用了position进行排序,跳过了age,出现了Using filesort。
![]()
-
查找只用到索引name,age和position用于排序,无Using filesort。
![]()
- 和Case 3中explain的执行结果一样,但是出现了Using filesort,因为索引的创建顺序为name,age,position,但是排序的时候age和position颠倒位置了。
![]()
- 与Case 4对比,在Extra中并未出现Using filesort,因为age为常量,在排序中被优化,所以索引未颠倒,不会出现Using filesort
![]()





- 虽然排序的字段列与索引顺序一样,且order by默认升序,这里position desc变成了降序,导致与索引的排序方式不同,从而产生Using filesort。Mysql8以上版本有降序索引可以支持该种查询方式。
![]()
-
对于排序来说,多个相等条件也是范围查询
![]()
-
可以用覆盖索引优化
![]()


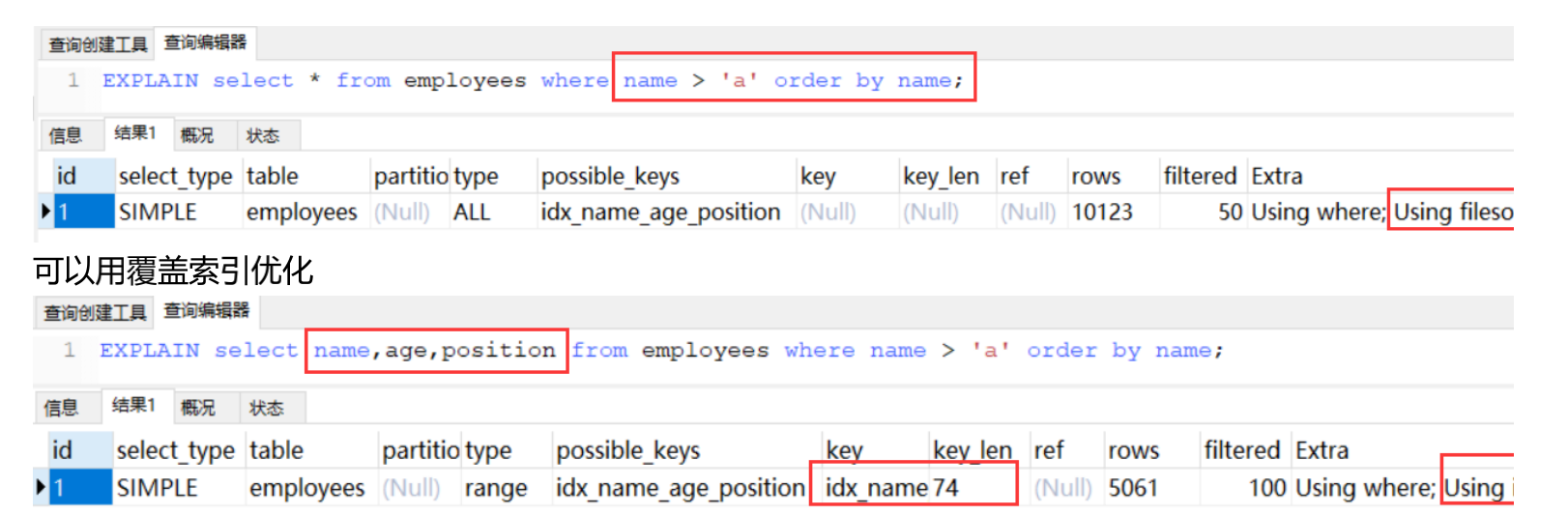
2、优化总结
4、分页查询优化
很多分页查询的sql实现 ,看似只查询了 10 条记录,实际这条 SQL 是先读取 10010条记录,然后抛弃前 10000 条记录,然后读到后面 10 条想要的数据。因此要查询一张大表比较靠后的数据,执行效率是非常低的。
mysql> select * from employees limit 10000,10;
常见技巧:
1、根据自增且连续的主键排序的分页查询
![]()
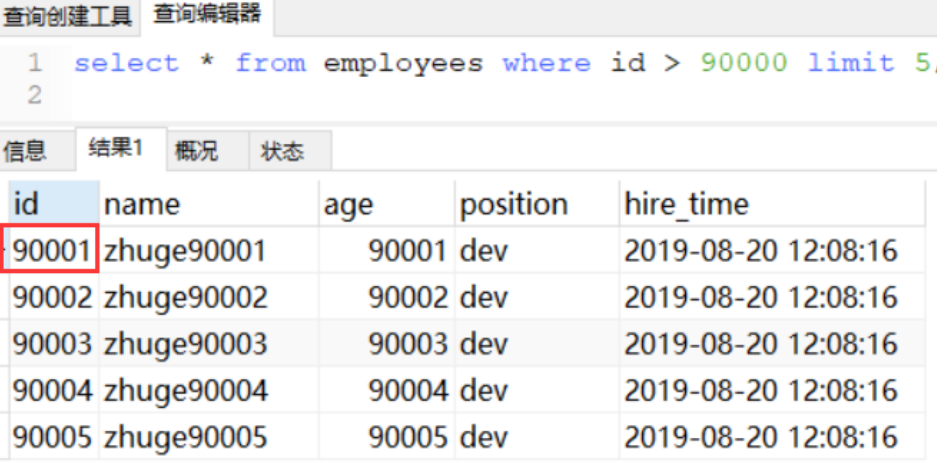
满足以下两个条件:
-
- 主键自增且连续
-
- 果是按照主键排序的
2、根据非主键字段排序的分页查询
select * from employees ORDER BY name limit 90000,5; (没有使用name索引) select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id; (使用了索引,并且时间减少了一半以上)
3、Join关联查询优化
3.1 标关联常见的两种算法
-
-
- 嵌套循环连接 Nested-Loop Join(NLJ) 算法 (走索引)
一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集。 - Block Nested-Loop Join 算法(不走索引)
把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比。对于关联sql的优化关联字段加索引:让mysql做join操作时尽量选择NLJ算法小表驱动大表:写多表连接sql时如果明确知道哪张表是小表可以用straight_join写法固定连接驱动方式,省去mysql优化器自己判断的时间
- 嵌套循环连接 Nested-Loop Join(NLJ) 算法 (走索引)
-
3.2 in和exsits优化
select * from A where id in (select id from B)
in:当B表的数据集小于A表的数据集时,in优于exists
exists:当A表的数据集小于B表的数据集时,exists优于in
3.3 count(*)查询优化
5、阿里Mysql规范解读
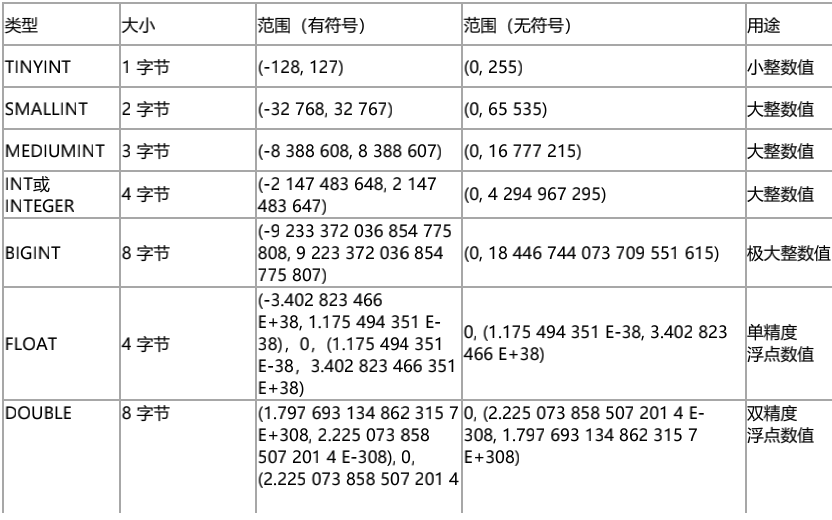
1、数值类型
![]()
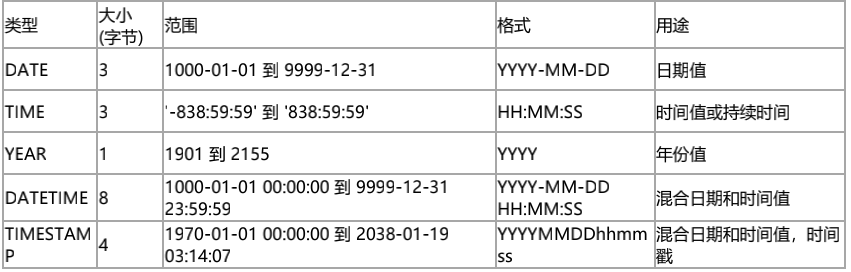
2、日期和时间
![]()
3、字符串
![]()
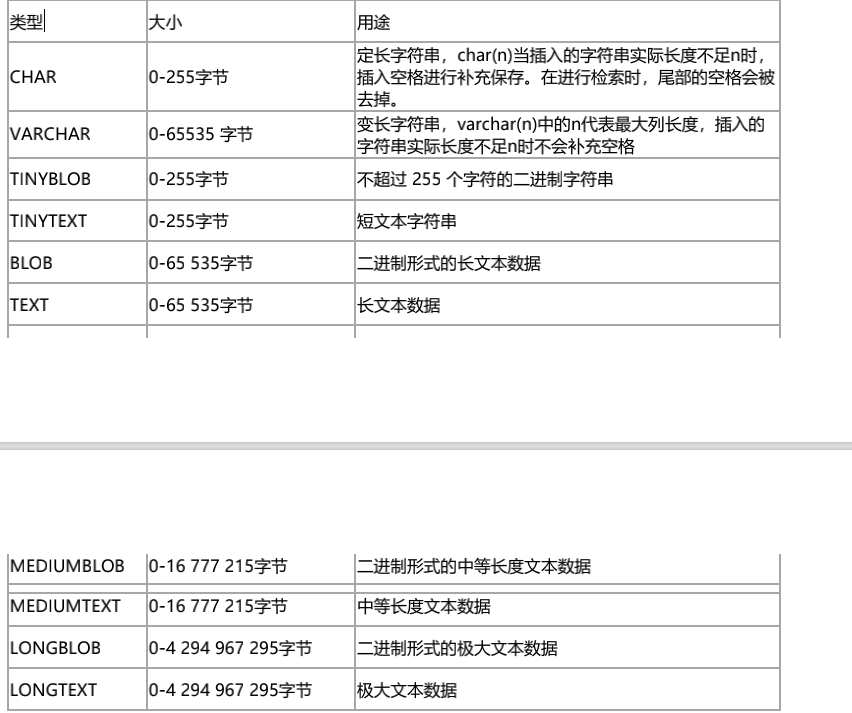
优化建议
2、事务的隔离级别
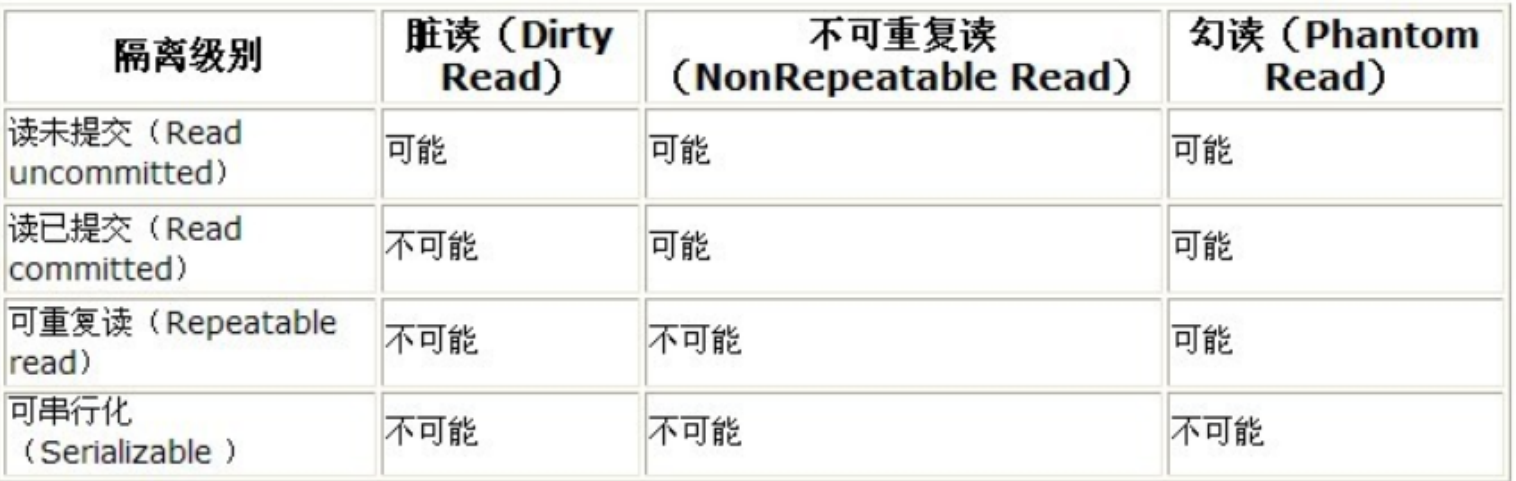
3、锁
结论1
锁优化建议

 浙公网安备 33010602011771号
浙公网安备 33010602011771号