pandas数据结构之DataFrame操作
这一次我的学习笔记就不直接用官方文档的形式来写了了,而是写成类似于“知识图谱”的形式,以供日后参考。
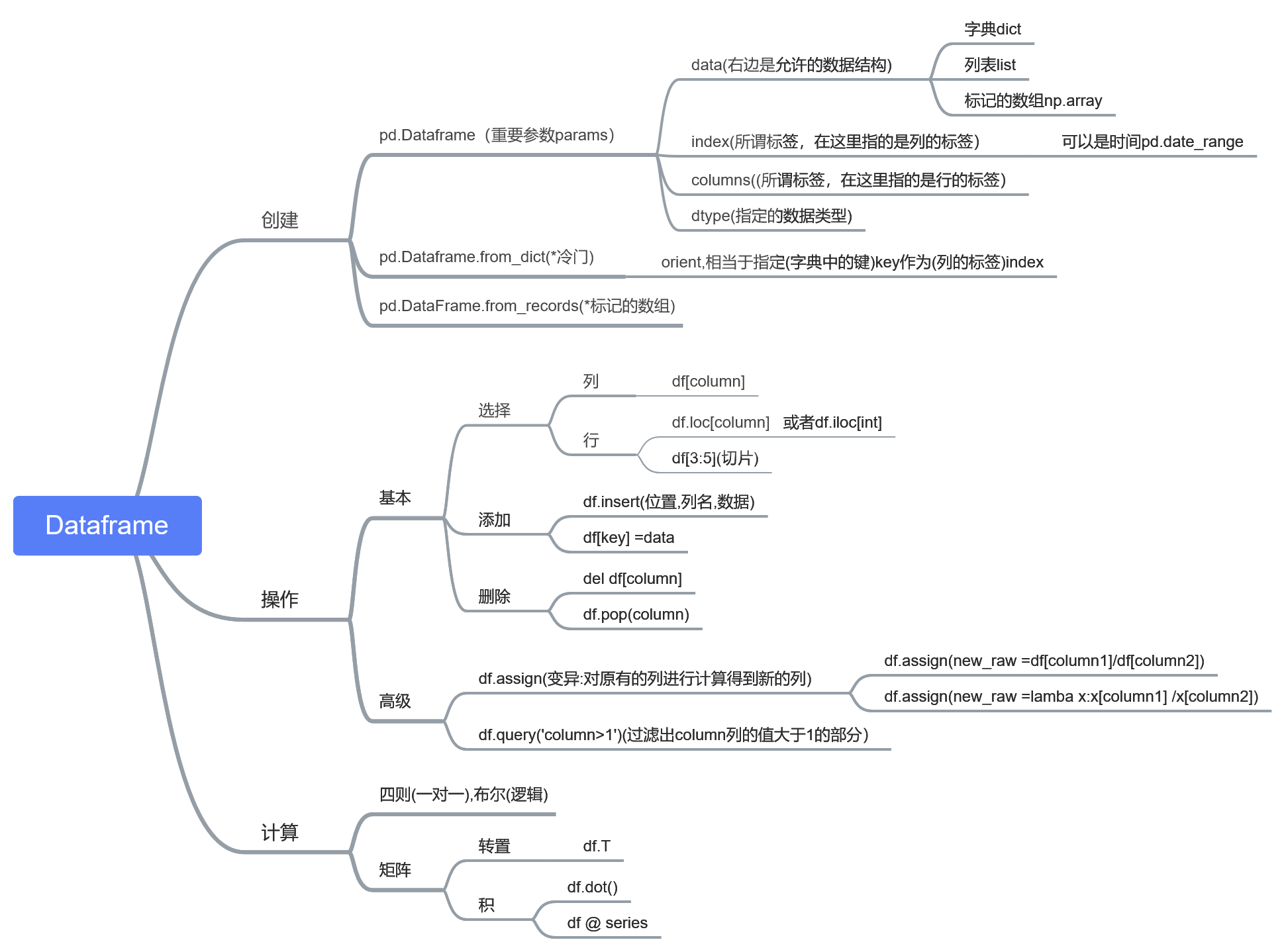
下面是所谓“知识图谱”,有什么用呢?
1.知道有什么操作(英文可以不看)
2.展示本篇笔记的结构
3.以后忘记某个函数某个参数时,方便查询
原来写的地方是,那儿的代码看起来会舒服很多: https://www.yuque.com/u86460/dgt6mu/tlywuc
创建
df.Dataframe(data,index)
1.data类型是字典
字典由series构成
>>> import pandas as pd
>>> #由series构成
>>> d ={'a':pd.Series([1,2,3,4]),'b':pd.Series([4,3,2,1,0])}
>>> df =pd.DataFrame(d)
>>> df
a b
0 1.0 4
1 2.0 3
2 3.0 2
3 4.0 1
4 NaN 0
>>> #指定Series的index(标签)
>>> d ={'a':pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
'b':pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])}
>>> pd.DataFrame(d)
a b
a 1.0 4
b 2.0 3
c 3.0 2
d 4.0 1
f NaN 0
>>> #指定Dataframe的index(列标签)
>>> pd.DataFrame(d,index =['a', 'b', 'c','d','f'])
a b
a 1.0 4
b 2.0 3
c 3.0 2
d 4.0 1
f NaN 0
>>> #指定Dataframe的columns(行标签)
>>> pd.DataFrame(d,index =['a', 'b', 'c','d','f'],columns=['b','c'])
b c
a 4 NaN
b 3 NaN
c 2 NaN
d 1 NaN
f 0 NaN
字典由列表或数组构成
>>> d ={'a':[1,2,3,4],'b':[4,3,2,1]}
>>> pd.DataFrame(d,index=['a', 'b', 'c','d'])
a b
a 1 4
b 2 3
c 3 2
d 4 1
字典的键由元组构成
>>> pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0
2.类型是list
多个的字典构成的列表
>>> d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
>>> pd.DataFrame(d)
a b c
0 1 2 NaN
1 5 10 20.0
多个series构成的列表
>>> d =[pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])]
>>> pd.DataFrame(d)
a b c d f
0 1.0 2.0 3.0 4.0 NaN
1 4.0 3.0 2.0 1.0 0.0
>>> pd.DataFrame(d,index =['a','b'])
a b c d f
a 1.0 2.0 3.0 4.0 NaN
b 4.0 3.0 2.0 1.0 0.0
>>> #每一个series就是一行
3.类型是标记的数组
>>> import numpy as np
>>> #指定数组每一列的数据类型,相当于创建一个模板
>>> data = np.zeros((2,), dtype=[('A', 'i4'),('B', 'f4'),('C', 'a10')])
>>> #为模板赋值
>>> data[:] = [(1,2.,'Hello'), (2,3.,"World")]
>>> pd.DataFrame(data)
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
pd.DataFrame.from_dict(dict)
>>> pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]))
A B
0 1 4
1 2 5
2 3 6
>>> pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]),
orient='index', columns=['one', 'two', 'three'])
one two three
A 1 2 3
B 4 5 6
#orient,相当于指定(字典中的键)key作为(列的标签)index
DataFrame.from_records
>>> pd.DataFrame.from_records(data, index='C')
A B
C
b'Hello' 1 2.0
b'World' 2 3.0
操作
上面创建部分是交互式操作,接下来就直接看代码的的注释,可以自己试着交互
import pandas as pd
import numpy as np
#**创建部分
#df.Dataframe(data,index)
'类型是字典'
#由series构成
d ={'a':pd.Series([1,2,3,4]),'b':pd.Series([4,3,2,1,0])}
d ={'a':pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
'b':pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])} #指定Series的index(标签)
pd.DataFrame(d,index =['a', 'b', 'c','d','f']) #指定Dataframe的index(列标签)
pd.DataFrame(d,index =pd.date_range('2000/1/1',periods=2)) #指定标签为日期
pd.DataFrame(d,index =['a', 'b', 'c','d','f'],columns=['b','c']) #指定Dataframe的columns(行标签)
#字典由列表或数组构成
d ={'a':[1,2,3,4],'b':[4,3,2,1]}
pd.DataFrame(d,index=['a', 'b', 'c','d'])
#字典的键由元组构成
pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A'