交叉熵(Cross-Entropy)损失
损失函数和误差函数
在大多数时候,损失函数和误差函数代表了差不多的意思,但他们仍有细微的差别。误差函数计算我们的模型偏离正确预测的程度。损失函数对误差进行操作,以量化得到一个特定大小或特定方向的误差。
Sigmoid
Softmax
Sigmoid常被用来处理二分类问题。对于多分类问题,我们常使用softmax函数将各个类的分数指数化,以落在\([0,1]\)的区间内。
假设有n个类,对应的线性分数分别为\(A_{1}, A_{2},...,A_{n}\),各个类的概率为
交叉熵(Cross-Entropy)
克劳德-香农在他1948年的论文《A Mathematical Theory of Communication》中提出了信息熵的概念。根据香农的说法,一个随机变量的熵是该变量的可能结果中固有的"information"、"surprise "或 "uncertainty "的平均水平。
随机变量的熵与误差函数有关。不确定性的平均水平指的是误差。
交叉熵建立在信息论熵的思想上,测量给定随机变量/事件集的两个概率分布的差异。交叉熵可以应用于二分类和多分类问题。
二元交叉熵
假设我们需要判断一个学生是否能通过SAT考试。对象是四个学生。有两个模型,A和B。
在深度学习中,模型对每个输入应用线性回归,即输入特征的线性组合。
- A和B都对四个学生应用线性回归函数\(f(x)=wx+b\),以产生线性分数。
- 使用Sigmoid函数将线性分数转化成概率。
下图展现了四个学生通过或未通过的概率。红色的数字代表未通过的概率,蓝色的数字代表通过的概率。蓝色区域代表模型预测通过,红色表示未通过/失败。
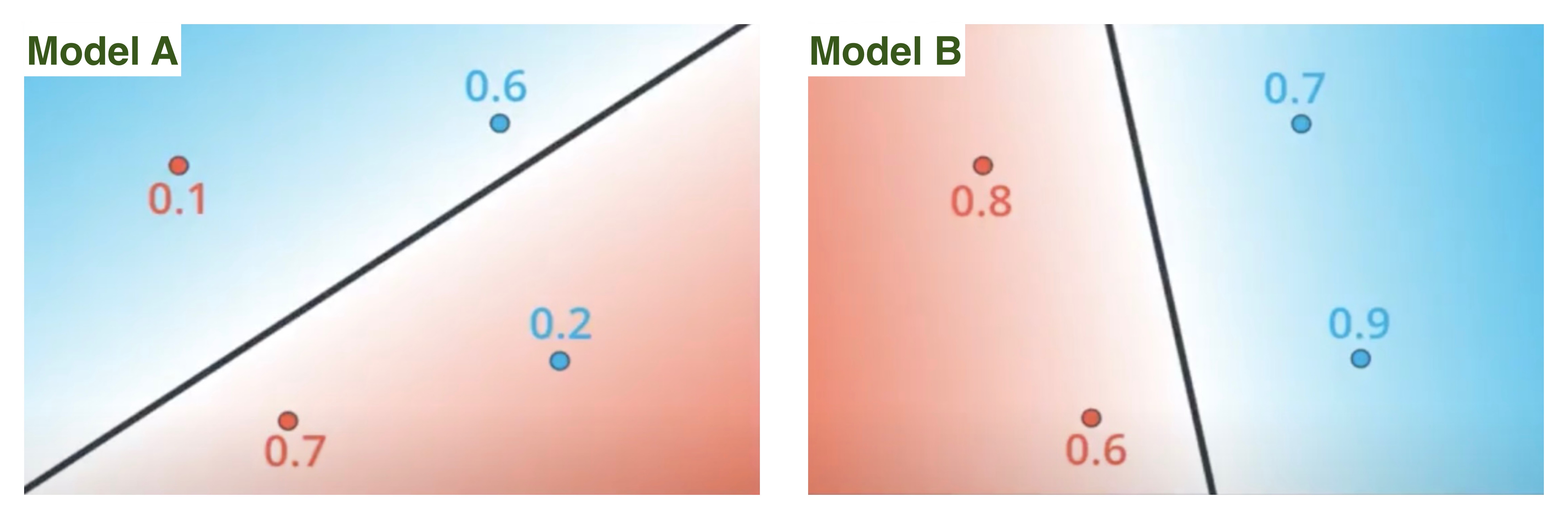
上图显示,模型B比模型A表现得更好,因为它能正确地将所有学生归入各自的区域(蓝色数字都落在蓝色区域,红色亦然)。所有概率的乘积决定了一个模型的最大可能性。
BTW,两个(或多个)独立事件同时发生的概率是通过乘以事件的单独概率来计算的。
我们计算模型的总概率:
模型B的总概率(乘积概率)比A的好。当我们有几个项目需要预测时,乘积概率的效果更好,但现实生活中的模型预测并非如此。例如,如果我们有一个1000名学生的班级,那么无论模型有多好,乘积概率总是会更接近于0。如果我们也改变一个概率,产品将发生巨大的变化,并给人错误的印象,认为模型表现良好。因此,我们需要使用对数函数将乘积转化为总和。
对于模型A:
对于模型B:
0和1之间的数字的对数将总是负的。我们将采取预测概率的负对数。
模型A的负对数:
模型B的负对数:
交叉熵损失是每个对象的预测概率的负对数之和。模型A的交叉熵损失是\(2.073\)且模型B的交叉熵损失是\(0.505\)。交叉熵可以很好地衡量每个模型的有效程度。
对于模型B,
| Stu 1 | Stu 2 | Stu 3 | Stu 4 | |
|---|---|---|---|---|
| 概率 | \(P1=0.8\) (未通过的概率) |
\(P2=0.6\) (未通过的概率) |
\(P3=0.7\) (通过的概率) |
\(P4=0.4\) (通过的概率) |
| 通过的概率 | \(1-P1\) | \(1-P2\) | \(P3\) | \(P4\) |
| 是否通过 | \(y_1=0\) | \(y_2=0\) | \(y_3=1\) | \(y_4=1\) |
\(y_i=0\)表示未通过,\(1\)表示通过。
下面是使用激活函数的交叉熵。

其中\(s_i\)是分数,\(f\)是当前的激活函数sigmoid,\(y_i\)是目标预测值。
对于单个观察值,二元交叉熵的计算公式如下。例如,计算学生3的交叉熵为\(-\)\(y_{i}log(P3)\)\(-\) \((1-y_{i})log(1-P3)\)
对二分类的交叉熵求和:
对二分类的交叉熵求均值:
利用Pytorch实践:
import torch
import torch.nn as nn
# 利用pytorch随机生成特征X和标签y
X = torch.randn(10)
y = torch.randint(2, (10, ), dtype=torch.float)
print(X)
print(y)
tensor([ 1.0818, 0.8817, 0.7702, 0.6109, -1.1537, 1.2832, 1.4260, -1.3606,
0.3080, -3.0263])
tensor([0., 1., 1., 1., 1., 1., 0., 0., 1., 0.])
# 离散特征值连续化(利用sigmoid)
X_con_val = torch.sigmoid(X)
X_con_val
tensor([0.7468, 0.7072, 0.6836, 0.6481, 0.2398, 0.7830, 0.8063, 0.2041, 0.5764,
0.0463])
1 - compute the cross-entropy loss using nn.BCELoss()
binary_ce_loss_mean = nn.BCELoss()(X_con_val, y)
binary_ce_loss_sum = nn.BCELoss(reduction="sum")(X_con_val, y)
print("平均交叉熵", binary_ce_loss_mean)
print("交叉熵之和", binary_ce_loss_sum)
平均交叉熵 tensor(0.6675)
交叉熵之和 tensor(6.6749)
2 - compute the cross-entropy loss manually
import numpy as np
def calc_bce_per_ob(f_s, yy):
# 计算单个观察值的交叉熵
s = 0
s += yy*np.log(f_s) + (1-yy)*np.log(1-f_s)
return -s
def calc_total_ce(X_con, y):
s = 0
for f_s, yy in zip(np.array(X_con), np.array(y)):
s += calc_bce_per_ob(f_s, yy)
print("平均交叉熵")
print(s/10)
print("交叉熵之和")
print(s)
calc_total_ce(X_con_val, y)
平均交叉熵
0.6674873688939831
交叉熵之和
6.67487368893983
多元分类交叉熵
我们将多类交叉熵用于多类分类问题。例如,我们创建一个模型,预测水果的类型/类别。我们有三种类型的水果(橙子、苹果、柠檬)放在不同的容器中。另外,每个容器的概率之和应该为1,例如,对于容器X,\(p_1+p_2+p_3=1\)
| 水果 | 容器A的概率 | 容器B的概率 | 容器C的概率 | 容器X的概率 |
|---|---|---|---|---|
| 橘子 | 0.7 | 0.3 | 0.1 | \(p_1\) |
| 苹果 | 0.2 | 0.4 | 0.5 | \(p_2\) |
| 柠檬 | 0.1 | 0.3 | 0.4 | \(p_3\) |
| 容器A | 容器B | 容器C | |
|---|---|---|---|
| 正确的水果类型 | 橘子 | 柠檬 | 柠檬 |
| 预测成功的概率 | 0.7 | 0.3 | 0.4 |
交叉熵损失是每个对象的预测概率的负对数之和,我们可以得到当前的交叉熵损失为
另外,还可以对每个容器(对象)计算交叉熵。假设类\((1,2,3)\)为\(i\),容器\((A,B,C)\)为\(j\)
我们为每个观察值的每个类别标签单独计算损失,并将结果相加,那么总交叉熵为
Reference
https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
https://neptune.ai/blog/cross-entropy-loss-and-its-applications-in-deep-learning

 浙公网安备 33010602011771号
浙公网安备 33010602011771号